Продолжаю свой цикл статей, посвященный конвертации различных текстовых файлов с помощью решений, реализованных на языке C#.
С момента моей последней публикации «Конвертация xls в xlsx и xml на C#» прошло более полугода, за которые я успел сменить как работодателя, так и пересмотреть свои взгляды на некоторые аспекты коммерческой разработки. Сейчас, работая в международной компании с совершенно иным подходом к разработке ПО (ревью кода, юнит-тестирование, команда автотестеров, строгое соблюдение СМК, заботливый менеджер, очаровательная HR и прочие корпоративные плюшки), я начинаю понимать, почему некоторые из комментаторов интересовались целесообразностью предлагаемых мной велокостылей, когда на рынке есть очень достойные готовые решения, например, от e-iceblue. Но давайте не забывать, что ситуации бывают разные, компании – тем более, и если потребность в решении какой-то задачи с использованием определенного инструментария возникла у одного человека, то со значительной долей вероятности она возникнет и у другого.
Итак, дано:
- Неопределенное множество файлов в формате .doc, которые нужно конвертировать в xml (например, для парсинга и организации автоматизированной навигации внутри текста), желательно с сохранением форматирования.
- На сервере памяти чуть больше, чем у рыбки, а на процессоре уже можно жарить яичницу, да и у компании нет лишней лицензии на Word, поэтому конвертация должна происходить без запуска каких-либо офисных приложений.
- Сервис должен быть написан на языке C# и в последующем интегрирован в код другого продукта.
- На решение задачи два дня и две ночи, которые истекли вчера.
Поехали!
- Во-первых, нужно сразу уяснить, что старые офисные форматы файлов, такие как .doc и .xls, являются бинарными, и достать что-нибудь человекочитаемое из них без использования текстовых редакторов/процессоров не получится. Прочитать об этом можно в официальной документации. Если есть желание поковыряться поглубже, посчитать нолики с единичками и узнать, что они означают, то лучше сразу перейти сюда.
- Во-вторых, несмотря на наличие бесплатных решений для работы с .doc, большинство из них написаны на Python, Ruby и чем угодно еще, но не C#.
- В-третьих, найденное мной решение, а именно библиотека b2xtranslator, является единственным доступным бесплатным инструментом такого рода, еще и написана при поддержке Microsoft, если верить вот этому источнику. Если вдруг вы встречали какие-нибудь аналоги данной библиотеки, пожалуйста, напишите об этом в комментариях. Даже это душеспасительное решение не превратит .doc в .xml, однако поможет нам превратить его в .docx, с которым мы уже умеем работать.
Довольно слов – давайте к делу
Установка b2xtranslator
Для работы нам понадобиться библиотека b2xtranslator. Ее можно подключить через менеджера пакетов NuGet.

Однако я настоятельно рекомендую скачать ее из официального git-репозитория по следующим причинам:
- a) Библиотека представляет собой комбайн, работающий с различными бинарными офисными документами (.doc, .xls, .ppt), что может быть избыточным
- b) Проект достаточно долго не обновляется и вам, возможно, придется доработать его напильником
- c) Задача, с которой я столкнулся, как раз потребовала внесения некоторых изменений в работу библиотеки, а также изучения ее алгоритмов и используемых структур для успешной интеграции в свое решение
Для дальнейшей работы нам понадобиться подключить в свое решение два проекта из библиотеки: b2xtranslator\Common\b2xtranslator.csproj и b2xtranslator\Doc\b2xtranslator.doc.csproj
Конвертация .doc в .docx
Конвертация документов строится по следующему алгоритму:
1. Инициализация дескриптора для конвертируемого файла.
Для этого необходимо создать экземпляр класса StructuredStorageReader, конструктор которого в качестве аргумента может принимать или путь до файла, или последовательность байтов (Stream), что делает его крайне удобным при работе с файлами, загружаемыми по сети. Также обращаю внимание, что так как библиотека b2xtranslator является комбайном для конвертации бинарных офисных форматов в современный OpenXML, то независимо от того, какой формат мы хотим конвертировать (.ppt, .xls или .doc) инициализация дескриптора всегда будет происходить с помощью указанного класса (StructuredStorageReader).
StructuredStorageReader reader = new StructuredStorageReader(docPath);2. Парсинг бинарного .doc файла с помощью объекта класса WordDocument, конструктор которого в качестве аргумента принимает объект типа StructuredStorageReader.
WordDocument doc = new WordDocument(reader);3. Создание объекта, который будет хранить данные для файла в формате .docx.
Для этого используется статический метод cs public static WordprocessingDocument Create(string fileName, OpenXmlPackage.DocumentType type) класса WordprocessingDocument. В первом аргументе указываем имя нового файла (вместе с путем), а вот во втором мы должны выбрать тип файла, который должен получиться на выходе:
- a. Document (обычный документ с расширением .docx);
- b. MacroEnabledDocument (файл, содержащий макросы, с расширением .docm);
- c. Template (файл шаблонов word с расширением .dotx);
- d. MacroEnabledTemplate (файл с шаблоном word, содержащий макросы. Имеет расширение .dotm).
WordprocessingDocument docx = WordprocessingDocument.Create(docxPath, DocumentType.Document);4. Конвертация данных из бинарного формата в формат OpenXML и их запись в объект типа WordprocessingDocument.
За выполнение указанной процедуры отвечает статический метод
public static void Convert(WordDocument doc, WordprocessingDocument docx)класса Converter, который заодно и записывает получившийся результат в файл.
Converter.Convert(doc, docx);В результате у вас должен получиться вот такой код:
using b2xtranslator.StructuredStorage.Reader;
using b2xtranslator.DocFileFormat;
using b2xtranslator.OpenXmlLib.WordprocessingML;
using b2xtranslator.WordprocessingMLMapping;
using static b2xtranslator.OpenXmlLib.OpenXmlPackage;
namespace ConverterToXml.Converters
{
public class DocToDocx
{
public void ConvertToDocx(string docPath, string docxPath)
{
StructuredStorageReader reader = new StructuredStorageReader(docPath);
WordDocument doc = new WordDocument(reader);
WordprocessingDocument docx = WordprocessingDocument.Create(docxPath, DocumentType.Document);
Converter.Convert(doc, docx);
}
}
}Внимание!
Если вы используете платформу .Net Core 3 и выше в своем решении, обратите внимание на целевые среды для подключенных проектов b2xtranslator. Так как библиотека была написана довольно давно и не обновляется с 2018 года, по умолчанию она собирается под .Net Core 2.
Чтобы сменить целевую среду, щелкните правой кнопкой мыши по проекту, выберите пункт «Свойства» и поменяйте целевую рабочую среду. В противном случае вы можете столкнуться с проблемой невозможности конвертации файлов .doc, содержащих в себе таблицы.
Я не стал разбираться, почему так происходит, но энтузиастам могу подсказать, что причину стоит искать в 40 строчке файла «~\b2xtranslator\Doc\WordprocessingMLMapping\MainDocumentMapping.cs» в момент обработки таблицы.
Кроме того, рекомендую собирать все проекты и само решение под 64-битную платформу во избежание всяких непонятных ошибок.
Сохранение результата в поток байтов
Так как моей целью при использовании данного решения была конвертация .doc в .xml, а не в .docx, предлагаю вовсе не сохранять промежуточный OpenXML файл, а записать его в виде потока байтов. К сожалению, b2xtranslator не предоставляет нам подходящих методов, но это довольно легко исправить:
В абстрактном классе OpenXmlPackage (см. ~\b2xtranslator\Common\OpenXmlLib\OpenXmlPackage.cs) давайте создадим виртуальный метод:
public virtual byte[] CloseWithoutSavingFile()
{
var writer = new OpenXmlWriter();
MemoryStream stream = new MemoryStream();
writer.Open(stream);
this.WritePackage(writer);
writer.Close();
byte[] docxStreamArray = stream.ToArray();
return docxStreamArray;
}По большому счету, данный метод будет заменять собой метод Close(). Вот его исходный код:
public virtual void Close()
{
// serialize the package on closing
var writer = new OpenXmlWriter();
writer.Open(this.FileName);
this.WritePackage(writer);
writer.Close();
}Скажем спасибо разработчикам библиотеки за то, что не забыли перегрузить метод Open(), который может принимать или имя файла, или поток байтов. Однако, библиотечный метод Close(), который как раз и отвечает за запись результата в файл, вызывается в методе Dispose() в классе OpenXmlPackage. Чтобы ничего лишнего не поломать и не заморачиваться с архитектурой фабрик (тем более в чужом проекте), я предлагаю просто закомментировать код внутри метода Dispose() и вызвать метод CloseWithoutSavingFile(), но уже внутри нашего метода после вызова Converter.Convert(doc, docx).
Для сохранения результата конвертации вызываем вместо docx.Close() метод docx.CloseWithoutSavingFile():
public MemoryStream ConvertToDocxMemoryStream(Stream stream)
{
StructuredStorageReader reader = new StructuredStorageReader(stream);
WordDocument doc = new WordDocument(reader);
var docx = WordprocessingDocument.Create("docx", DocumentType.Document);
Converter.Convert(doc, docx);
return new MemoryStream(docx.CloseWithoutSavingFile());
}Теперь библиотека b2xtranslator будет возвращать сконвертированный из формата .doc в .docx файл в виде потока байтов. Даже если у вас нет цели получить на выходе .xml, такой метод может оказаться более подходящим для дальнейшей работы с файлами, тем более что стрим всегда можно сохранить в виде файла там, где вам надо.
Для тех, кому все-таки очень хочется получить на выходе .xml документ, еще и с сохраненной структурой, предлагаю дойти до кухни, сварить кофе покрепче, добавить в него рюмку коньяка и приготовиться к приключению на 20 минут.
Конвертация .doc в .xml

Теперь, когда, казалось бы, можно воспользоваться классом-конвертором DocxToXml, работа которого была описана вот в этой статье, нас поджидает сюрприз, связанный с особенностями работы b2xtranslator.
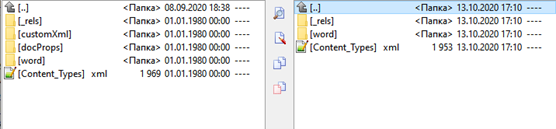
Давайте посмотрим на результат работы библиотеки повнимательнее и сравним с оригинальным .docx файлом, из которого был экспортирован .doc файл для конвертации. Для этого достаточно изменить расширение сравниваемых файлов с .docx на .zip. Вот отличия, которые мы увидим, заглянув внутрь архивов:
1. В результате конвертации в новом .docx файле (справа) отсутствуют папки customXml и docProps.
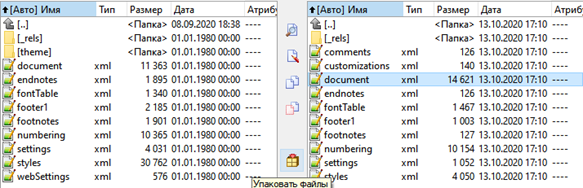
2. Внутри папки word, мы также найдем определенные отличия, перечислять которые я, конечно же, не буду:
3. Естественно, что и метаданные, по которым осуществляется навигация внутри документа, также отличаются. Например, на представленном скрине и далее оригинальный .docx слева, сгенерированный b2xtranslator – cправа.
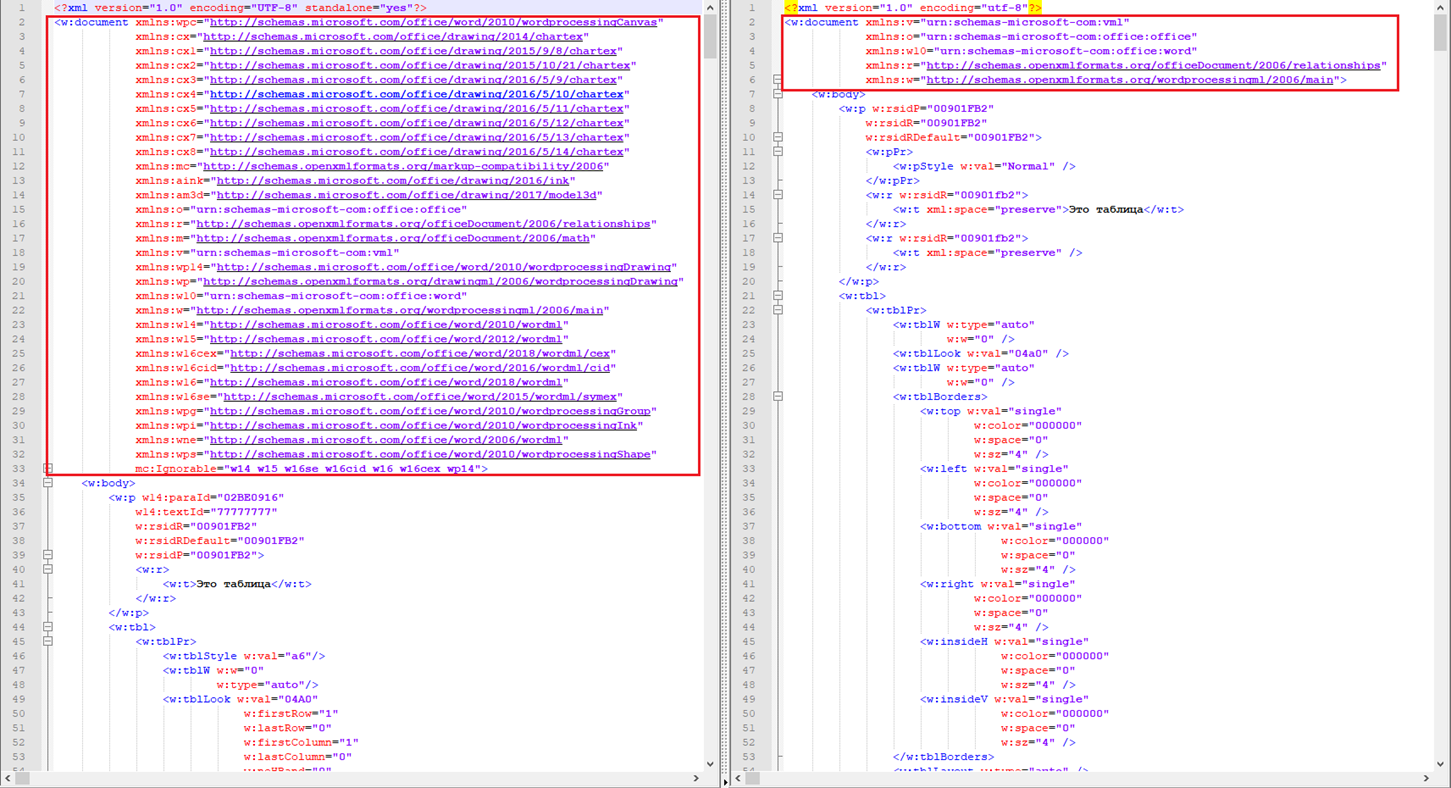
Налицо явное отличие в атрибутах тега “w:document”, но этим отличия не заканчиваются. Всю "мощь" библиотеки мы ощутим, когда захотим обработать списки и при этом:
- a. Сохранить их нумерацию
- b. Не потерять структуру вложенности
- c. Отделить один список от другого
Давайте сравним файлы document.xml для вот этого списка:
1.1 Первый.Первый
1.2 Первый.Второй
1.2.1 Первый.Второй.Первый
1.2.2 Первый.Второй.Второй
Какая-то строчка
1.2.3 Первый.Второй.Третий
2. Второй
2.1 Второй.ПервыйВот так будет выглядеть .xml для первого элемента списка.
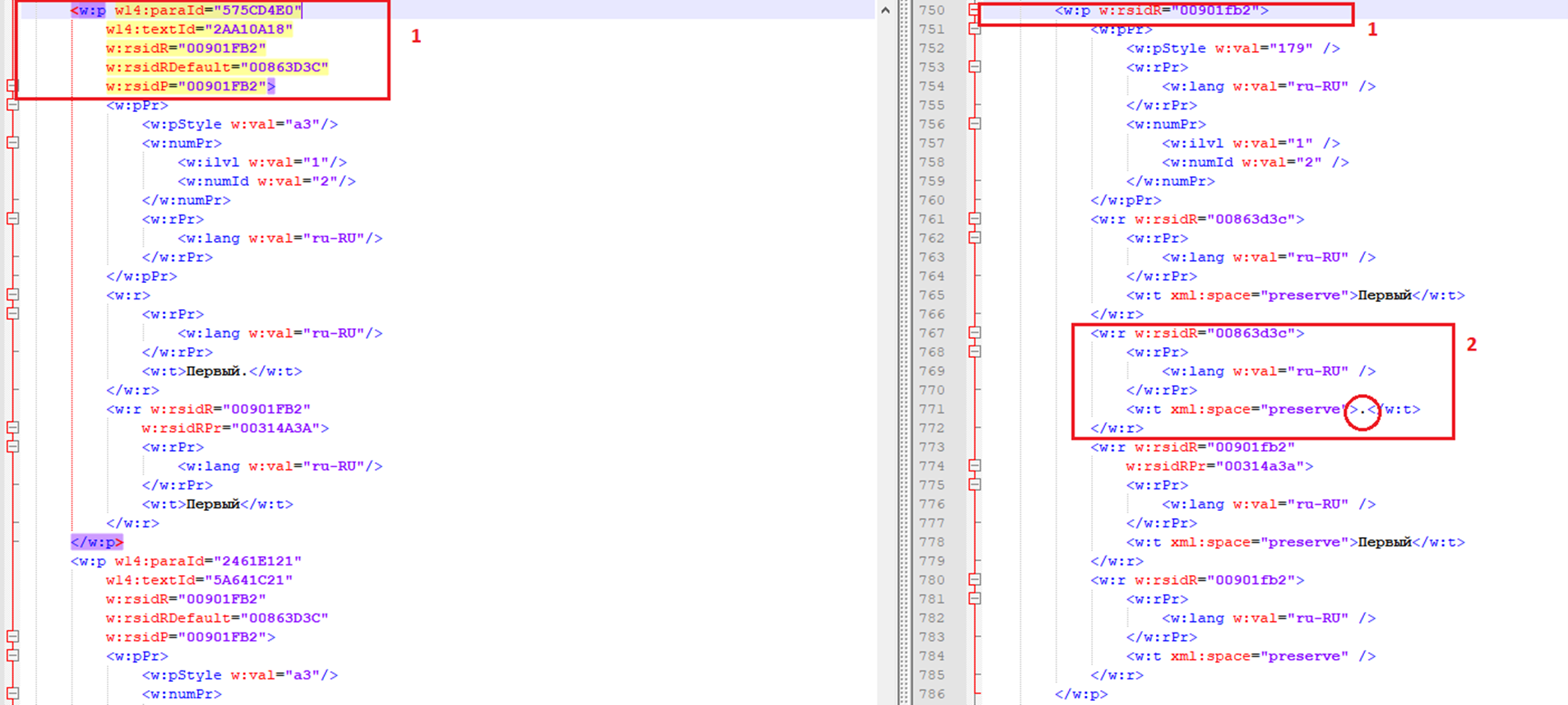
-Во-первых, мы видим, что сама структура документов несколько отличается (например, точка внутри строк рассматривается как отдельный элемент, что, как оказалось, совсем не страшно).
-Во-вторых, у тегов остался только один атрибут (w:rsidR), а вот w:rsidR, w14:textId, w:rsidRDefault, w:paraId и w:rsidP пропали. Все эти особенности приводят к тому, что наш класс-конвертер DocxToXml(про него подробно можно почитать здесь) подавится и поднимет лапки вверх с ошибкой NullReferenceException, что указывает на отсутствие индексирования параграфов внутри документа.
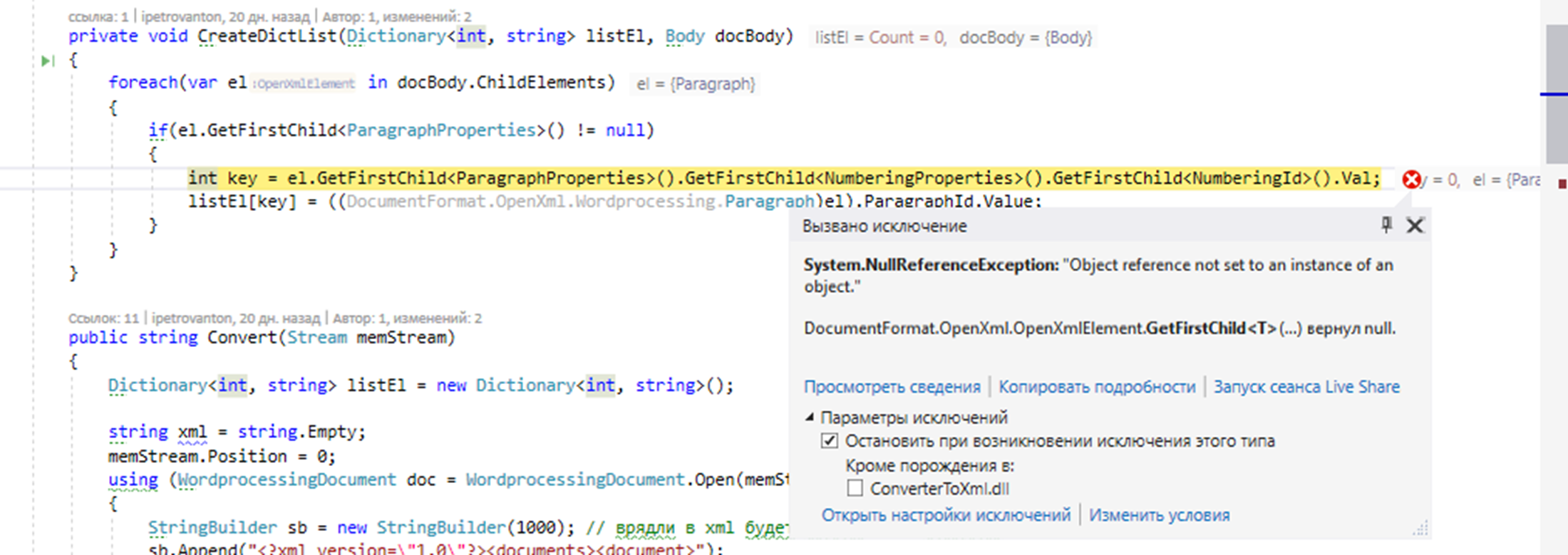
Вместе с тем, если мы попытаемся такой файл отрыть в Word, то увидим, что все хорошо отображается, а таблицы и списки покоятся на своих местах! Магия!
В общем, когда в поисках решения я потратил N часов на чтение документации, мои красные от дебагера глаза омылись горькими слезами, а один лишь запах кофе стремился показать коллегам мой дневной рацион, решение было найдено!
Исходя из документации к формату doc и алгоритмов работы b2xtranslator, можно сделать вывод, что исторически в бинарных офисных текстовых документах отсутствовала индексация по параграфам*. Возникает задача расставить необходимые теги в нужных местах.
За индекс параграфа отвечает атрибут тега paraId, о чем прямо написано здесь. Данный атрибут относится к пространству имен w14, о чем можно догадаться при изучении document.xml из архива .docx. В принципе, на скринах выше вы это тоже видите. Объявление пространства имен в .xml выглядит так:
xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing"Теперь давайте заставим b2xtranslator добавлять это пространство имен и идентификатор каждому параграфу. Для этого в файле “~\b2xtranslator\Common\OpenXmlLib\ContentTypes.cs” после 113 строки добавим вот эту строчку:
public const string WordprocessingML2010 = "http://schemas.microsoft.com/office/word/2010/wordml";Кстати, если посмотрите на комментарии в коде, то увидите, что в этом блоке как раз располагаются поддерживаемые пространства имен для вордовых документов:

Далее наша задача – заставить библиотеку вставлять в начало файла ссылку на данное пространство имен. Для этого в файле “~\b2xtranslator\Doc\WordprocessingMLMapping\MainDocumentMapping.cs” в 24 строке вставим код:
this._writer.WriteAttributeString("xmlns", "w14", null, OpenXmlNamespaces.WordprocessingML2010);Разработчики библиотеки также позаботились о документации:

Теперь дело за малым – заставить b2xtranslator индексировать параграфы. В качестве индексов предлагаю использовать рандомно сгенерированные GUID – может быть, это несколько тяжеловато, но зато надежно!

Переходим в файл “~\b2xtranslator\Doc\WordprocessingMLMapping\DocumentMapping.cs” и в 504 и 505 строки вставляем вот этот код:
this._writer.WriteAttributeString("w14", "paraId", OpenXmlNamespaces.WordprocessingML2010, Guid.NewGuid().ToString());
this._writer.WriteAttributeString("w14", "textId", OpenXmlNamespaces.WordprocessingML2010, "77777777");Что касается второй строчки, в которой мы добавляем каждому тегу параграфа атрибут w14:textId = "77777777", то тут можно лишь сказать, что без этого атрибута ничего работать не будет. Для пытливых умов вот ссылка на документацию.
Если серьезно, то, как я понимаю, атрибут используется, когда текст разделен на разные блоки, внутри которых происходит индексация тегов, которые могут иметь одинаковый Id внутри одного документа. Видимо, для этих случаев используется дополнительная индексация текстовых блоков. Однако, так как мы используем GUID, который в несколько раз больше индексов, используемых в вордовских документах по умолчанию, то генерацией отдельных индексов для текстовых блоков можно и пренебречь.
Вот теперь мы получили .docx-файл, пригодный для дальнейшего преобразования в .xml. Подробнее о том, как работать с ним дальше, вы можете прочитать в этой статье или воспользоваться уже выложенным на github-решением.

В заключение, если у вас на проекте есть возможность воспользоваться платным надежным софтом, то этот путь скорее всего не для вас. Однако же, если вы энтузиаст, пишете свой pet-проект и уважительно относитесь к авторским правам, а также если ваш проект находится в стадии прототипирования и пока не готов к покупке дорогостоящих лицензий, а разработку продолжать надо, то, мне кажется, этот вариант может вам очень даже подойти! Тем более, что у вас есть возможность воспользоваться готовым решением и не заливать свои краснющие зенки визином, изучая документацию и особенности работы некоторых, на первый взгляд, сомнительных решений.
Наконец, бонус для тех, кто хочет разобраться, что значат все эти бесконечные теги и их атрибуты в документах .docx и как они мапаются на бинарный .doc: советую заглянуть в файл “~\b2xtranslator\Doc\DocFileFormat\CharacterProperties.cs”, а также посмотреть спецификацию для docx и doc.
