Всем привет, меня зовут Сергей Емельянчик. Я являюсь руководителем компании Аудит-Телеком, главным разработчиком и автором системы Veliam. Решил написать статью о том, как мы с другом создавали аутсорсинговую компанию, написали программное обеспечения для себя и впоследствии начали распространять его всем желающим по системе SaaS. О том, как я категорически не верил в то, что это возможно. В статье будет не только рассказ, но и технические подробности того как создавался продукт Veliam. Включая некоторые куски исходного кода. Расскажу о том какие ошибки совершали и как их потом исправляли. Были сомнения, публиковать ли такую статью. Но я подумал, что лучше сделать это, получить фидбэк и исправиться, чем не публиковать статью и думать о том, что было бы если…
Работал я в одной компании ИТ сотрудником. Компания была весьма большой с разветвленной сетевой структурой. Не буду останавливаться на своих должностных обязанностях, скажу лишь, что в них точно не входила разработка чего-либо.
У нас был мониторинг, но чисто из академического интереса хотелось попробовать написать свой простейший. Идея была такая: хотелось, чтобы это было в вебе, чтобы можно было легко без установки каких-либо клиентов зайти и посмотреть, что происходит с сетью с любого устройства, включая мобильное устройство через Wi-Fi, а еще очень хотелось быстро понимать в каком помещении расположено оборудование которое “захандрило”, т.к. были весьма жесткие требования к времени реагирования на подобные проблемы. В итоге в голове родился план написать простенькую веб страничку, на которой был фоном jpeg со схемой сети, вырезать на этой картинке сами устройства с их IP адресами, а поверх картинки в нужных координатах показывать уже динамический контент в виде зеленого или мигающего красного IP адреса. Задача поставлена, приступаем.
Ранее я занимался программированием на Delphi, PHP, JS и очень поверхностно C++. Довольно неплохо знаю работу сетей. VLAN, Routing (OSPF, EIGRP, BGP), NAT. Этого было достаточно для того, чтобы написать прототип примитивного мониторинга самостоятельно.
Написал задуманное на PHP. Сервер Apache и PHP был на Windows т.к. Linux для меня в тот момент был чем-то непонятным и очень сложным, как оказалось позже, я сильно ошибался и во многих местах Linux куда проще Windows, но это тема отдельная и мы все знаем сколько холиваров на эту тему. Планировщик задач Windows дергал с небольшим интервалом (точно не помню, но что-то вроде одного раза в три секунды) PHP скрипт, который опрашивал все объекты банальным пингом и сохранял состояние в файл.
Да-да, работа с БД в тот момент тоже для меня была не освоена. Я не знал, что можно параллелить процессы, и проход по всем узлам сети занимал длительное время, т.к. это происходило в один поток. Особенно проблемы возникали тогда, когда несколько узлов были недоступны, т.к. каждый из них задерживал на себе скрипт на 300 мс. На стороне клиента была простая зацикленная функция, которая с интервалом несколько секунд скачивала обновленную информацию с сервера Ajax запросом и обновляла интерфейс. Ну и далее после 3-х неудачных пингов подряд, если на компьютере была открыта веб страница с мониторингом, играла веселенькая композиция.
Когда все получилось, я очень вдохновился результату и думал, что можно прикрутить туда еще (в силу своих знаний и возможностей). Но мне всегда не нравились системы с миллионом графиков, которые как я тогда считал, да и считаю по сей день, в большинстве случаев ненужными. Хотел туда прикручивать только то, что мне реально бы помогало в работе. Данный принцип по сей день сохраняется как основополагающий при разработке Veliam. Далее, я понял, что было бы очень классно, если бы не нужно было держать открытым мониторинг и знать о проблемах, а когда она случилась, уже тогда открывать страницу и смотреть где этот проблемный узел сети расположен и что с ним дальше делать. Электронную почту как-то тогда не читал, попросту не пользовался. Наткнулся в интернете, что есть СМС шлюзы, на которые можно отправить GET или POST запрос, и они пришлют мне на мобильный телефон СМС с текстом, который я напишу. Я сразу понял, что очень хочу этого. И начал изучать документацию. Спустя некоторое время мне удалось, и теперь я получал смс о проблемах на сети на мобильник с названием “упавшего объекта”. Хоть система и была примитивной, но она была написана мною самим, а самое главное, что меня тогда мотивировало к ее развитию — это то, что это прикладная программа, которая реально помогает мне в работе.
И вот настал день, когда на работе упал один из интернет-каналов, а мой мониторинг мне никак не дал об этом понять. Так как гугловские DNS до сих пор отлично пинговались. Пришло время подумать, как можно мониторить, что канал связи жив. Были разные идеи как это сделать. Не ко всему оборудованию у меня был доступ. Приходилось придумать как можно понимать какой из каналов жив, но при этом не имея возможности каким-либо образом посмотреть это на самом сетевом оборудовании. Тогда коллега подкинул идею, что возможно, трассировка маршрута до публичных серверов может отличаться в зависимости от того по какому каналу связи сейчас осуществляется выход в интернет. Проверил, так и оказалось. Были разные маршруты при трассировке.
Так появился еще один скрипт, а точней трассировка зачем-то была добавлена в конец того же скрипта, который пинговал все устройства в сети. Ведь это еще один долгий процесс, который выполнялся в том же потоке и тормозил работу всего скрипта. Но тогда это не было так очевидно. Но так или иначе, он делал свое дело, в коде было жестко прописано какая должна была быть трассировка у каждого из каналов. Так стала работать система, которая уже мониторила (громко сказано, т.к. не было сбора каких-то метрик, а просто пинг) сетевые устройства (роутеры, коммутаторы, wi-fi и т.д.) и каналы связи с внешним миром. Исправно приходили СМС и на схеме было всегда хорошо видно где проблема.
Дальше, в повседневной работе приходилось заниматься кроссировкой. И каждый раз заходить на Cisco коммутаторы для того, чтобы посмотреть какой интерфейс нужно использовать надоело. Как было бы классно тыкнуть на мониторинге на объект и увидеть список его интерфейсов с описаниями. Это бы сэкономило мне время. Причем в этой схеме не надо было бы запускать Putty или SecureCRT вводить учетки и команды. Просто ткнул в мониторинге, увидел, что надо и пошел делать свою работу. Начал искать как можно взаимодействовать с коммутаторами. На вскидку попалось сразу 2 варианта: SNMP или заходить на коммутатор по SSH, вводить необходимые мне команды и парсить результат. SNMP отмел из-за сложности реализации, мне не терпелось получить результат. с SNMP пришлось бы долго копаться в MIB, на основе этих данных формировать данные об интерфейсах. Есть замечательная команда в CISCO
Она показывает, как раз то что мне нужно для кроссировок. К чему мучиться с SNMP, когда я просто хочу видеть вывод этой команды, подумал я. Спустя некоторое время, я реализовал такую возможность. Нажимал на веб странице на объект. Срабатывало событие, по которому AJAXом клиент обращался к серверу, а тот в свою очередь подключался по SSH к нужному мне коммутатору (учетные данные были зашиты в код, не было желания облагораживать, делать какие-то отдельные менюшки где можно было бы менять учетки из интерфейса, нужен был результат и побыстрей) вводил туда вышеуказанную команду и отдавал обратно в браузер. Так я начал видеть по одному клику мышки информацию по интерфейсам. Это было крайне удобно, особенно когда приходилось смотреть эту информацию на разных коммутаторах сразу.
Мониторинга каналов на основе трассировки оказался в итоге не самой лучшей идеей, т.к. иногда проводились работы на сети, и трассировка могла меняться и мониторинг начинал мне вопить о том, что есть проблемы с каналом. Но потратив кучу времени на анализ, понимал, что все каналы работают, а мой мониторинг меня обманывает. В итоге, попросил коллег, которые управляли каналообразующими коммутаторами присылать мне просто syslog, когда менялось состояние видимости соседей (neighbor). Соответственно, это было гораздо проще, быстрей и правдивей, чем трассировка. Пришло событие вида neighbor lost, и я сразу делаю оповещение о падении канала.
Дальше, появились выводы по клику на объект еще несколько команд и добавился SNMP для сбора некоторых метрик, ну и на этом по большому счету все. Более система никак не развивалась. Она делала все что мне было нужно, это был хороший инструмент. Многие читатели, наверное, мне скажут, что для решения этих задач уже куча софта в интернете. Но на самом деле, бесплатных таких продуктов я тогда не нагуглил и уж очень хотелось развивать скилл программирования, а что может лучше толкать к этому, чем реальная прикладная задача. На этом первая версия мониторинга была закончена и более не модифицировалась.
Шло время, я начал подрабатывать параллельно в других компаниях, благо рабочий график позволял мне это делать. Когда работаешь в разных компаниях, очень быстро растет скилл в различных областях, хорошо развивается кругозор. Есть компании, в которых, как принято говорить, ты и швец, и жнец, и на дуде игрец. С одной стороны, это сложно, с другой стороны если не лениться, ты становишься специалистом широкого профиля и это позволяет быстрей и эффективней решать задачи потому, что ты знаешь, как работает смежная область.
Мой друг Павел (тоже айтишник) постоянно пытался меня сподвигнуть на свой бизнес. Было бесчисленное число идей с различными вариантами своего дела. Это обсуждалось не один год. И в итоге ни к чему не должно было прийти потому, что я скептик, а Павел фантазер. Каждый раз, когда он предлагал какую-то идею, я всегда в нее не верил, и отказывался участвовать. Но уж очень нам хотелось открыть свой бизнес.
Наконец, мы смогли найти вариант, устраивающий нас обоих и заняться тем, что мы умеем. В 2016 году, мы решили создать IT компанию, которая будет помогать бизнесу с решением IT задач. Это развертывание ИТ систем (1С, сервер терминалов, почтовый сервер и т.д.), их сопровождение, классический HelpDesk для пользователей и администрирование сети.
Откровенно говоря, в момент создания компании, я в нее не верил примерно на 99,9%. Но каким-то образом Павел смог меня заставить попробовать, и забегая вперед, он оказался прав. Мы скинулись с Павлом по 300 000 рублей, зарегистрировали новое ООО “Аудит-Телеком”, сняли крохотный офис, наделали крутых визиток, ну в общем как и, наверное, большинство неопытных, начинающих бизнесменов и начали искать клиентов. Поиск клиентов — это вообще отдельная история. Возможно мы напишем отдельную статью в рамках корпоративного блога, если это кому-то будет интересно. Холодные звонки, листовки, и прочее. Результатов это не давало никаких. Как я уже читаю сейчас, из многих историй о бизнесе, так или иначе многое зависит от удачи. Нам повезло. и буквально через пару недель после создания фирмы, к нам обратился мой брат Владимир, который и привел к нам первого клиента. Не буду утомлять деталями работы с клиентами, статья не об этом, скажу лишь, что мы поехали на аудит, выявили критические места и эти места сломались пока принималось решение о том сотрудничать ли с нами на постоянной основе в качестве аутсорсеров. После этого сразу было принято положительное решение.
Далее, в основном по сарафану через знакомых, начали появляться и другие компании на обслуживании. Helpdesk был в одной системе. Подключения к сетевому оборудованию и серверам в другой, а точнее у кого как. Кто-то сохранял ярлыки, кто-то пользовался адресными книгами RDP. Мониторинг еще одна отдельная система. Работать команде в разрозненных системах очень неудобно. Теряется из вида важная информация. Ну, например, стал недоступен терминальный сервер у клиента. Сразу поступают заявки от пользователей этого клиента. Специалист службы поддержки заводит заявку (она поступила по телефону). Если бы инциденты и заявки регистрировались в одной системе, то специалист поддержки сразу бы видел в чем проблема у пользователя и сказал ему об этом, параллельно уже подключаясь к нужному объекту для отработки ситуации. Все в курсе тактической обстановки и слаженно работают. Мы не нашли такой системы, где все это объединено. Стало понятно, что пора делать свой продукт.
Понятно было, что та система, которая была написана ранее совершенно не подходит под текущие задачи. Ни в плане функционала ни в плане качества. И было принято решение писать систему с нуля. Графически это должно было уже выглядеть совсем иначе. Это должно была быть иерархическая система, что бы можно было быстро и удобно открывать нужный объект у нужного клиента. Схема как в первой версией была в текущем случае абсолютно не оправдана, т.к. клиенты разные и вовсе не имело значения в каких помещениях стоит оборудование. Это было уже переложено на документацию.
Итак, задачи:
Задачи поставлены, начинаем писать. Попутно обрабатывая заявки от клиентов. На тот момент нас уже было 4 человека. Начали писать сразу обе части и центральный сервер, и сервер для установки к клиентам. К этому моменту Linux был уже не чужим для нас и было принято решение, что виртуальные машины, которые будут стоять у клиентов будут на Debian. Не будет никаких установщиков, просто сделаем проект серверной части на одной конкретной виртуальной машине, а потом просто будем ее клонировать к нужному клиенту. Это была очередная ошибка. Позже стало понятно, что в такой схеме абсолютно не проработан механизм апдейтов. Т.е. мы добавляли какую-то новую фичу, а потом была целая проблема распространять ее на все серверы клиентов, но к этому вернемся позже, все по порядку.
Сделали первый прототип. Он умел пинговать необходимые нам сетевые устройства клиентов и серверы и посылать эти данные к нам на центральный сервер. А он в свою очередь обновлял эти данные в общей массе на центральном сервере. Я тут буду писать не только историю о том, как и что удавалось, но и какие дилетантские ошибки совершались и как потом приходилось за это платить временем. Так вот, все дерево объектов хранилось в одном единственном файле в виде сериализованного объекта. Пока мы подключили к системе несколько клиентов, все было более-менее нормально, хотя и иногда были какие-то артефакты, которые были совершенно непонятны. Но когда мы подключили к системе десяток серверов, начались твориться чудеса. Иногда, непонятно по какой причине, все объекты в системе просто исчезали. Тут важно отметить, что серверы, которые были у клиентов, присылали данные на центральный сервер каждые несколько секунд посредством POST запроса. Внимательный читатель и опытный программист уже догадался, что возникала проблема множественного доступа к тому самому файлу в котором хранился сериализованный объект из разных потоков одновременно. И как раз, когда это происходило, проявлялись чудеса с исчезновением объектов. Файл попросту становился пустым. Но это все обнаружилось не сразу, а только в процессе эксплуатации с несколькими серверами. За это время был добавлен функционал по сканированию портов (серверы присылали на центральный не только информацию о доступности устройств, но и об открытых на них портах). Сделано это было путем вызова команды:
результаты часто были неправильными и выполнялось сканирование очень долго. Совсем забыл о пинге, он выполнялся через fping:
Это все тоже не было распараллелено и поэтому процесс был очень долгий. Позже в fping уже передавался сразу весь список необходимых для проверки IP адресов и обратно получили готовый список тех, кто откликнулся. В отличии от нас, fping умел параллелить процессы.
Еще одной частой рутинной работой была настройка каких-то сервисов через WEB. Ну, например, ECP от MS Exchange. По большому счету это всего лишь ссылка. И мы решили, что нужно дать возможность нам добавлять такие ссылки прямо в систему, чтобы не искать в документации или еще где-то в закладках как зайти на ECP конкретного клиента. Так появилось понятие ресурсных ссылок для системы, их функционал доступен и по сей день и не претерпел изменений, ну почти.
Одной из задач было быстрое и удобное подключение к серверам, которых стало уже много (не одна сотня) и перебирать миллионы заранее сохраненных RDP ярлыков было крайне неудобным. Нужен был инструмент. Есть в интернете софт, который представляет из себя что-то типа адресной книги для таких RDP подключений, но они не интегрированы с системой мониторинга, и учетки не сохранить. Каждый раз вводить учетки для разных клиентов это сущий ад, когда в день ты подключаешься не один десяток раз на разные серверы. С SSH дела обстоят чуть лучше, есть много хорошего софта в котором есть возможность раскладывать такие подключения по папочкам и запоминать учетки от них. Но есть 2 проблемы. Первая — для подключений RDP и SSH мы не нашли единую программу. Вторая — если я в какой-то момент не нахожусь за своим компьютером и мне надо быстро подключиться, или я просто переустановил систему, мне придется лезть в документацию, чтобы смотреть учетку от этого клиента. Это неудобно и пустая трата времени.
Нужная нам иерархическая структура по серверам клиентов уже имелась в нашем внутреннем продукте. Нужно было только придумать как прикрутить туда быстрые подключения к нужному оборудованию. Для начала, хотя бы внутри своей сети.
С учетом того, что клиентом в нашей системе выступал браузер, который не имеет доступа к локальным ресурсам компьютера, чтобы просто взять и какой-то командой запустить нужное нам приложение, было придумано сделать все через “Windows custom url scheme”. Так появился некий “плагин” к нашей системе, который просто включал в свой состав Putty и Remote Desktop Plus и при установке просто регистрировал URI схемы в Windows. Теперь, когда мы хотели подключиться к объекту по RDP или SSH, мы нажимали это действие в нашей системе и срабатывала работа Custom URI. Запускался стандартный mstsc.exe встроенный в Windows или putty, который шел в состав “плагина”. Беру слово плагин в кавычки, потому, что это не является плагином браузера в классическом смысле.
Это было уже хотя бы что-то. Удобная адресная книга. Причем в случае с Putty, все было вообще хорошо, ему в качестве входных параметров можно было подать и IP подключения и логин и пароль. Т.е. к Linux серверам в своей сети мы уже подключались одним кликом без ввода паролей. Но с RDP не все так просто. В стандартный mstsc нельзя подать учетные данные в качестве параметров. На помощь пришел Remote Desktop Plus. Он позволял это делать. Сейчас мы уже обходимся без него, но долгое время он был верным помощником в нашей системе. С HTTP(S) сайтами все просто, такие объекты просто открывались в браузере и все. Удобно и практично. Но это было счастье только во внутренней сети.
Так как подавляющее число проблем мы решали удаленно из офиса, самым простым было сделать VPN’ы до клиентов. И тогда из нашей системы можно было подключаться и к ним. Но все равно было несколько неудобно. Для каждого клиента нужно было держать на каждом компьютере кучу запомненных VPN соединений и перед подключением к какому-либо, надо было включать соответствующий VPN. Таким решением мы пользовались достаточно продолжительное время. Но количество клиентов увеличивается, количество VPN’ов тоже и все это начало напрягать и нужно было что-то с этим делать. Особенно наворачивались слезы на глазах после переустановки системы, когда нужно было вбивать заново десятки VPN подключений в новом профиле винды. Хватит это терпеть, сказал я и начал думать, что можно с этим сделать.
Так повелось, что у всех клиентов в качестве маршрутизаторов были устройства всем известной фирмы Mikrotik. Они весьма функциональны и удобны для выполнения практически любых задач. Из минусов — их “угоняют”. Мы эту проблему решили просто, закрыв все доступы извне. Но нужно было как-то иметь к ним доступ, не приезжая к клиенту на место, т.к. это долго. Мы просто сделали до каждого такого микротика тоннели и выделили их в отдельный пул. без какой-либо маршрутизации, чтобы не было объединения своей сети с сетями клиентов и их сетей между собой.
Родилась идея сделать так, чтобы при нажатии на нужный мне объект в системе, центральный сервер мониторинга, зная учетные записи от SSH всех клиентских микротиков, подключался к нужному, создавал правило проброса до нужного хоста с нужным портом. Тут сразу несколько моментов. Решение не универсальное — будет работать только для микротика, как так синтаксис команд у всех роутеров свой. Так же такие пробросы потом надо было как-то удалять, а серверная часть нашей системы по сути не могла отслеживать каким-либо образом закончил ли я свой сеанс работы по RDP. Ну и такой проброс — это дырище для клиента. А за универсальностью мы и не гнались, т.к. продукт использовался только внутри нашей компании и выводить его в паблик даже мыслей не было.
Каждая из проблем была решена по-своему. Когда создавалось правило, то проброс этот был доступен только для одного конкретного внешнего IP адреса (с которого было инициализировано подключение). Так что дыры в безопасности удалось избежать. Но при каждом таком подключении, добавлялось правило на микротик на страницу NAT и не очищалось. А всем известно, что чем больше там правил, тем сильнее нагружается процессор роутера. Да и в целом, я не мог принять такое, что я зайду однажды на какой-то микротик, а там сотни мертвых никому не нужных правил.
Раз наш сервер не может отслеживать состояние подключения, пусть микротик отслеживает их сам. И написал скрипт, который постоянно отслеживал все правила проброса с определенным описанием (description) и проверял есть ли TCP подключение подходящее правило. Если такового не было уже некоторое время, то вероятно подключение уже завершено и проброс этот можно удалять. Все получилось, скрипт хорошо работал.
Наверняка его можно было сделать красивей, быстрей и т.д., но он работал, не нагружал микротики и отлично справлялся. Мы наконец-то смогли подключаться к серверам и сетевому оборудованию клиентов просто одним нажатием мышки. Не поднимая VPN и не вводя пароли. С системой стало реально очень удобно работать. Время на обслуживание сокращалось, а все мы тратили время на работу, а не на то чтобы подключиться к нужным объектам.
У нас было настроено резервное копирование всех микротиков на FTP. И в целом все было хорошо. Но когда нужно было достать бэкап, но надо было открывать этот FTP и искать его там. Система где все роутеры заведены у нас есть, общаться с устройствами по SSH мы умеем. Чего бы нам не сделать так, что система сама будет ежедневно забирать со всех микротиков бэкапы, подумал я. И принялся реализовывать. Подключились, сделали бэкап и забрали его в хранилище.
Бэкап снимается в двух видах — бинарник и текстовый конфиг. Бинарник помогает быстро ресторить нужный конфиг, а текстовый позволяет понимать, что надо делать, если произошла вынужденная замена оборудования и бинарник на него залить нельзя. В итоге получили еще один удобный функционал в системе. Причем, при добавлении новых микротиков не надо было ничего настраивать, просто добавил объект в систему и задал для него учетку от SSH. Дальше система сама занималась съемом бэкапов. В текущей версии SaaS Veliam этого функционала пока нет, но скоро портируем его.
Выше я уже писал о том, что появлялись артефакты. Иногда просто исчезал весь список объектов в системе, иногда при редактировании объекта, информация не сохранялась и приходилось по три раза переименовывать объект. Это жутко раздражало всех. Исчезновение объектов происходило редко, и легко восстанавливалось путем восстановления этого самого файла, а вот фейл при редактировании объектов это прям было часто. Вероятно, я изначально не сделал это через БД потому, что в уме не укладывалось как можно дерево со всеми связями держать в плоской таблице. Она же плоская, а дерево иерархическое. Но хорошее решение множественного доступа, а в последствии (при усложнении системы) и транзакционного — это СУБД. Я же наверняка не первый кто столкнулся с этой проблемой. Полез гуглить. Оказалось, что уже все придумано до меня и есть несколько алгоритмов, которые строят дерево из плоской таблицы. Посмотрев на каждый, я реализовал один из них. Но это уже была новая версия системы, т.к. по сути переписывать из-за этого пришлось весьма много. Результат был закономерен, проблемы рандомного поведения системы ушли. Кто-то может сказать, что ошибки весьма дилетантские (однопоточные скрипты, хранение информации к которой был множественный одновременный доступ из разных потоков в файле и т.д.) в сфере разработке программного обеспечения. Может так и есть, но моя основная работа была администрирование, а программирование было побочным для души, и у меня попросту не было опыта работы в команде программистов, там, где такие элементарные вещи мне подсказали бы сразу старшие товарищи. Поэтому я все эти шишки набивал самостоятельно, но очень хорошо усвоил материал. А еще, свое дело — это и встречи с клиентами, и действия направленные на попытку раскрутки фирмы, и куча административных вопросов внутри компании и многое-многое другое. Но так или иначе, то что было уже — было востребовано. Ребята и я сам использовали продукт в повседневной работе. Были и откровенно неудачные идеи, и решения, на которые было потрачено время, а в итоге стало понятно, что это нерабочий инструмент и им никто не пользовался и это не попало в Veliam.
Не лишним будет упомянуть как формировался HelpDesk. Это вообще отдельная история, т.к. в Veliam это уже 3-я совершенно новая версия, которая отличается от всех предыдущих. Сейчас это простая система, интуитивно понятная без лишних рюшек и финтифлюшек с возможностью интегрироваться с доменом, а также с возможностью доступа к этому же профилю пользователя из любого места по ссылке из письма. И что самое важное, есть возможность из любой точки (дома я или в офисе) подключиться к заявителю по VNC прямо из заявки без VPN или пробросов портов. Расскажу, как мы к этому пришли, что было до этого и какие ужасные решения были.
Мы подключались к пользователям через всем известный TeamViewer. На всех компьютерах, пользователей которых мы обслуживаем установлен ТВ. Первое, что мы сделали не так, и впоследствии убрали это — привязка каждого клиента ХД по железу. Как пользователь заходил в систему ХД для того, чтобы оставить заявку? Всем на компьютеры, помимо ТВ была установлена специальная утилита, написанная на Lazarus (тут многие округлят глаза, и возможно даже полезут гуглить что это такое, но лучше всего из компилируемых языков я знал Delphi, а Lazarus это почти тоже самое, только бесплатное). В общем пользователь запускал у себя специальный батник, который запускал эту утилиту, та в свою очередь считывала HWID системы и после этого запускался браузер и происходила авторизация. Зачем это было сделано? В некоторых компаниях, подсчет обслуживаемых пользователей ведется поштучно, и цена обслуживания за каждый месяц формируется исходя из количества людей. Это понятно, скажете вы, но зачем привязка к железу. Очень просто, некоторые индивиды, приходили домой и делали с домашнего ноутбука заявку в стиле “сделайте мне тут все красиво”. Помимо считывания HWID системы, утилита вытаскивала из реестра текущий ID Teamviewer’а и так же передавала к нам. У Teamviewer есть API для интеграции. И мы сделали эту интеграцию. Но была одна загвоздка. Через эти API нельзя подключиться к компьютеру пользователя, когда он явно не инициирует эту сессию и после попытки подключиться к нему он должен еще нажать “подтвердить”. На тот момент, нам показалось логичным, что без спроса пользователя никто не должен подключаться, а раз человек за компьютером, то он и сессию инициирует и утвердительно ответит на запрос удаленного подключения. Все оказалось не так. Заявители забывали нажать инициацию сессии, и приходилось им в телефонном разговоре это говорить. Это тратило время и нервировало обе стороны процесса. Более того, отнюдь не редкость такие моменты, когда человек оставляет заявку, но подключиться разрешает только тогда, когда он уходит на обед. Ибо проблема не критичная и не хочет, чтобы его рабочий процесс прерывался. Соответственно, он не нажмет никаких кнопок для разрешения подключиться. Так и появился дополнительный функционал при авторизации в HelpDesk — считывание ID Teamviwer’а. Мы знали постоянный пароль, который использовался при установке Teamviwer. Точней, его знала только система, так как он был вшит в установщик, и в нашу систему. Соответственно была кнопка подключения из заявки по нажатию на которую не нужно было ничего ждать, а сразу открывался Teamviewer и происходил коннект. В итоге стало два вида возможных подключений. Через официальный API Teamviewer и наш самопальный. К моему удивлению, первым почти сразу перестали пользоваться, хоть и было указание пользоваться им только в особых случаях и когда пользователь сам дает на это добро. Все же безопасность сейчас подавай. Но оказалось, что заявителям это не нужно. Они все абсолютно не против, что к ним подключаются без кнопки подтверждения. А раз так, то и в дальнейшем функционал подключения через API был упразднен за ненадобностью.
Давно уже начал напрашиваться вопрос ускорения прохода сканера сети на предмет открытости заранее определенного списка портов и простая пропинговка объектов сети. Тут само собой первое решение, которое приходит в голову — многопоточность. Так как основное время, которое тратится на пинг — это ожидание возврата пакета, и следующий пинг не может начаться пока не вернется предыдущий пакет, в компаниях у которых даже 20+ серверов плюс сетевого оборудования это уже работало довольно медленно. Суть в том, что один пакет может и пропасть, не уведомлять же об этом сразу системного администратора. Он просто такой спам очень быстро перестанет воспринимать. Значит надо пинговать каждый объект еще не один раз прежде чем делать вывод о недоступности. Если не вдаваться уж совсем в подробности, то надо параллелить потому, что если этого не сделать, то скорей всего, системный администратор будет узнавать о проблеме от клиента, а не от системы мониторинга.
Сам по себе PHP из коробки не умеет многопоточность. Умеет многопроцессность, можно форкать. Но, у меня уже по сути был написан механизм опроса и хотелось сделать так, чтобы я один раз считал все нужные мне узлы из БД, пропинговал все сразу, дождался ответа от каждого и только после этого сразу писал данные. Это экономит на количестве запросов на чтение. В эту идею отлично укладывалась многопоточность. Для PHP есть модуль PThreads, который позволяет делать реальную многопоточность, правда пришлось изрядно повозиться, чтобы настроить это на PHP 7.2, но дело было сделано. Сканирование портов и пинг стали быстрыми. И вместо, к примеру 15 секунд на круг раньше, на этот процесс стало уходить 2 секунды. Это был хороший результат.
Как появился функционал сбора различных метрик и характеристик железа? Все просто. Нам иногда заказывают просто аудит текущей ИТ инфраструктуры. Ну и тоже самое необходимо для ускорения проведения аудита нового клиента. Нужно было что-то, что позволит прийти в среднюю или крупную компанию и быстро сориентироваться, что у них вообще есть. Пинг во внутренней сети блокируют, на мой взгляд, только те, кто сам себе хочет усложнить жизнь, и таких по нашему опыту немного. Но и такие встречаются. Соответственно, можно быстро отсканировать сети на наличие устройств простым пингом. Дальше можно их добавить и просканировать на предмет открытых портов, которые нас интересуют. По сути этот функционал уже был, необходимо только было добавить команду с центрального сервера на подчиненный, чтобы тот просканировал заданные сети и добавил в список все что найдет. Забыл упомянуть, предполагалось, что у нас уже есть готовый образ с настроенной системой (подчиненный сервер мониторинга) который мы могли просто раскатать у клиента при аудите и подцепить его к своему облаку.
Но результат аудита обычно включает в себя кучу различной информации и одна из них это — что вообще за устройства в сети. В первую очередь нас интересовали Windows серверы и рабочие станции Windows в составе домена. Так как в средних и крупных компаниях отсутствие домена — это, наверное, исключение из правил. Что бы говорить на одном языке, средняя, в моем представлении, это 100+ человек. Нужно было придумать способ как собрать данные со всех виндовых машин и серверов, зная их IP и учетную запись доменного администратора, но при этом не устанавливая на каждую из них какой-то софт. На помощь приходит интерфейс WMI. Windows Management Instrumentation (WMI) в дословном переводе — инструментарий управления Windows. WMI — это одна из базовых технологий для централизованного управления и слежения за работой различных частей компьютерной инфраструктуры под управлением платформы Windows. Взято из вики. Далее пришлось опять повозиться, с тем, чтобы собрать wmic (это клиент WMI) для Debian. После того как все было готово оставалось просто опрашивать через wmic нужные узлы на предмет нужной информации. Через WMI можно достать с Windows компьютера почти любую информацию, и более того, через него можно еще и управлять компьютером, ну, например, отправить в перезагрузку. Так появился сбор информации о Windows станциях и серверах в нашей системе. Плюсом к этому шла и текущая информация о текущих показателях загруженности системы. Их мы запрашиваем почаще, а информацию по железу пореже. После этого, проводить аудит стало немного приятней.
Мы сами ежедневно пользуемся системой, и она всегда открыта у каждого технического сотрудника. И мы подумали, что можно и с другими поделиться тем, что уже есть. Система была еще совсем не готова к тому, чтобы ее распространять. Необходимо было переработать очень многое, что бы локальная версия превратилась в SaaS. Это и изменения различных технических аспектов в работе системы (удаленные подключения, служба поддержки), и анализа модулей на предмет лицензирования, и шардирование баз данных клиентов, и масштабирование каждого из сервисов, и разработка систем автообновлений для всех частей. Но об этом будет вторая часть статьи.
Вторая часть
Предыстория
Работал я в одной компании ИТ сотрудником. Компания была весьма большой с разветвленной сетевой структурой. Не буду останавливаться на своих должностных обязанностях, скажу лишь, что в них точно не входила разработка чего-либо.
У нас был мониторинг, но чисто из академического интереса хотелось попробовать написать свой простейший. Идея была такая: хотелось, чтобы это было в вебе, чтобы можно было легко без установки каких-либо клиентов зайти и посмотреть, что происходит с сетью с любого устройства, включая мобильное устройство через Wi-Fi, а еще очень хотелось быстро понимать в каком помещении расположено оборудование которое “захандрило”, т.к. были весьма жесткие требования к времени реагирования на подобные проблемы. В итоге в голове родился план написать простенькую веб страничку, на которой был фоном jpeg со схемой сети, вырезать на этой картинке сами устройства с их IP адресами, а поверх картинки в нужных координатах показывать уже динамический контент в виде зеленого или мигающего красного IP адреса. Задача поставлена, приступаем.
Ранее я занимался программированием на Delphi, PHP, JS и очень поверхностно C++. Довольно неплохо знаю работу сетей. VLAN, Routing (OSPF, EIGRP, BGP), NAT. Этого было достаточно для того, чтобы написать прототип примитивного мониторинга самостоятельно.
Написал задуманное на PHP. Сервер Apache и PHP был на Windows т.к. Linux для меня в тот момент был чем-то непонятным и очень сложным, как оказалось позже, я сильно ошибался и во многих местах Linux куда проще Windows, но это тема отдельная и мы все знаем сколько холиваров на эту тему. Планировщик задач Windows дергал с небольшим интервалом (точно не помню, но что-то вроде одного раза в три секунды) PHP скрипт, который опрашивал все объекты банальным пингом и сохранял состояние в файл.
system(“ping -n 3 -w 100 {$ip_address}“);
Да-да, работа с БД в тот момент тоже для меня была не освоена. Я не знал, что можно параллелить процессы, и проход по всем узлам сети занимал длительное время, т.к. это происходило в один поток. Особенно проблемы возникали тогда, когда несколько узлов были недоступны, т.к. каждый из них задерживал на себе скрипт на 300 мс. На стороне клиента была простая зацикленная функция, которая с интервалом несколько секунд скачивала обновленную информацию с сервера Ajax запросом и обновляла интерфейс. Ну и далее после 3-х неудачных пингов подряд, если на компьютере была открыта веб страница с мониторингом, играла веселенькая композиция.
Когда все получилось, я очень вдохновился результату и думал, что можно прикрутить туда еще (в силу своих знаний и возможностей). Но мне всегда не нравились системы с миллионом графиков, которые как я тогда считал, да и считаю по сей день, в большинстве случаев ненужными. Хотел туда прикручивать только то, что мне реально бы помогало в работе. Данный принцип по сей день сохраняется как основополагающий при разработке Veliam. Далее, я понял, что было бы очень классно, если бы не нужно было держать открытым мониторинг и знать о проблемах, а когда она случилась, уже тогда открывать страницу и смотреть где этот проблемный узел сети расположен и что с ним дальше делать. Электронную почту как-то тогда не читал, попросту не пользовался. Наткнулся в интернете, что есть СМС шлюзы, на которые можно отправить GET или POST запрос, и они пришлют мне на мобильный телефон СМС с текстом, который я напишу. Я сразу понял, что очень хочу этого. И начал изучать документацию. Спустя некоторое время мне удалось, и теперь я получал смс о проблемах на сети на мобильник с названием “упавшего объекта”. Хоть система и была примитивной, но она была написана мною самим, а самое главное, что меня тогда мотивировало к ее развитию — это то, что это прикладная программа, которая реально помогает мне в работе.
И вот настал день, когда на работе упал один из интернет-каналов, а мой мониторинг мне никак не дал об этом понять. Так как гугловские DNS до сих пор отлично пинговались. Пришло время подумать, как можно мониторить, что канал связи жив. Были разные идеи как это сделать. Не ко всему оборудованию у меня был доступ. Приходилось придумать как можно понимать какой из каналов жив, но при этом не имея возможности каким-либо образом посмотреть это на самом сетевом оборудовании. Тогда коллега подкинул идею, что возможно, трассировка маршрута до публичных серверов может отличаться в зависимости от того по какому каналу связи сейчас осуществляется выход в интернет. Проверил, так и оказалось. Были разные маршруты при трассировке.
system(“tracert -d -w 500 8.8.8.8”);
Так появился еще один скрипт, а точней трассировка зачем-то была добавлена в конец того же скрипта, который пинговал все устройства в сети. Ведь это еще один долгий процесс, который выполнялся в том же потоке и тормозил работу всего скрипта. Но тогда это не было так очевидно. Но так или иначе, он делал свое дело, в коде было жестко прописано какая должна была быть трассировка у каждого из каналов. Так стала работать система, которая уже мониторила (громко сказано, т.к. не было сбора каких-то метрик, а просто пинг) сетевые устройства (роутеры, коммутаторы, wi-fi и т.д.) и каналы связи с внешним миром. Исправно приходили СМС и на схеме было всегда хорошо видно где проблема.
Дальше, в повседневной работе приходилось заниматься кроссировкой. И каждый раз заходить на Cisco коммутаторы для того, чтобы посмотреть какой интерфейс нужно использовать надоело. Как было бы классно тыкнуть на мониторинге на объект и увидеть список его интерфейсов с описаниями. Это бы сэкономило мне время. Причем в этой схеме не надо было бы запускать Putty или SecureCRT вводить учетки и команды. Просто ткнул в мониторинге, увидел, что надо и пошел делать свою работу. Начал искать как можно взаимодействовать с коммутаторами. На вскидку попалось сразу 2 варианта: SNMP или заходить на коммутатор по SSH, вводить необходимые мне команды и парсить результат. SNMP отмел из-за сложности реализации, мне не терпелось получить результат. с SNMP пришлось бы долго копаться в MIB, на основе этих данных формировать данные об интерфейсах. Есть замечательная команда в CISCO
show interface statusОна показывает, как раз то что мне нужно для кроссировок. К чему мучиться с SNMP, когда я просто хочу видеть вывод этой команды, подумал я. Спустя некоторое время, я реализовал такую возможность. Нажимал на веб странице на объект. Срабатывало событие, по которому AJAXом клиент обращался к серверу, а тот в свою очередь подключался по SSH к нужному мне коммутатору (учетные данные были зашиты в код, не было желания облагораживать, делать какие-то отдельные менюшки где можно было бы менять учетки из интерфейса, нужен был результат и побыстрей) вводил туда вышеуказанную команду и отдавал обратно в браузер. Так я начал видеть по одному клику мышки информацию по интерфейсам. Это было крайне удобно, особенно когда приходилось смотреть эту информацию на разных коммутаторах сразу.
Мониторинга каналов на основе трассировки оказался в итоге не самой лучшей идеей, т.к. иногда проводились работы на сети, и трассировка могла меняться и мониторинг начинал мне вопить о том, что есть проблемы с каналом. Но потратив кучу времени на анализ, понимал, что все каналы работают, а мой мониторинг меня обманывает. В итоге, попросил коллег, которые управляли каналообразующими коммутаторами присылать мне просто syslog, когда менялось состояние видимости соседей (neighbor). Соответственно, это было гораздо проще, быстрей и правдивей, чем трассировка. Пришло событие вида neighbor lost, и я сразу делаю оповещение о падении канала.
Дальше, появились выводы по клику на объект еще несколько команд и добавился SNMP для сбора некоторых метрик, ну и на этом по большому счету все. Более система никак не развивалась. Она делала все что мне было нужно, это был хороший инструмент. Многие читатели, наверное, мне скажут, что для решения этих задач уже куча софта в интернете. Но на самом деле, бесплатных таких продуктов я тогда не нагуглил и уж очень хотелось развивать скилл программирования, а что может лучше толкать к этому, чем реальная прикладная задача. На этом первая версия мониторинга была закончена и более не модифицировалась.
Создание компании Аудит-Телеком
Шло время, я начал подрабатывать параллельно в других компаниях, благо рабочий график позволял мне это делать. Когда работаешь в разных компаниях, очень быстро растет скилл в различных областях, хорошо развивается кругозор. Есть компании, в которых, как принято говорить, ты и швец, и жнец, и на дуде игрец. С одной стороны, это сложно, с другой стороны если не лениться, ты становишься специалистом широкого профиля и это позволяет быстрей и эффективней решать задачи потому, что ты знаешь, как работает смежная область.
Мой друг Павел (тоже айтишник) постоянно пытался меня сподвигнуть на свой бизнес. Было бесчисленное число идей с различными вариантами своего дела. Это обсуждалось не один год. И в итоге ни к чему не должно было прийти потому, что я скептик, а Павел фантазер. Каждый раз, когда он предлагал какую-то идею, я всегда в нее не верил, и отказывался участвовать. Но уж очень нам хотелось открыть свой бизнес.
Наконец, мы смогли найти вариант, устраивающий нас обоих и заняться тем, что мы умеем. В 2016 году, мы решили создать IT компанию, которая будет помогать бизнесу с решением IT задач. Это развертывание ИТ систем (1С, сервер терминалов, почтовый сервер и т.д.), их сопровождение, классический HelpDesk для пользователей и администрирование сети.
Откровенно говоря, в момент создания компании, я в нее не верил примерно на 99,9%. Но каким-то образом Павел смог меня заставить попробовать, и забегая вперед, он оказался прав. Мы скинулись с Павлом по 300 000 рублей, зарегистрировали новое ООО “Аудит-Телеком”, сняли крохотный офис, наделали крутых визиток, ну в общем как и, наверное, большинство неопытных, начинающих бизнесменов и начали искать клиентов. Поиск клиентов — это вообще отдельная история. Возможно мы напишем отдельную статью в рамках корпоративного блога, если это кому-то будет интересно. Холодные звонки, листовки, и прочее. Результатов это не давало никаких. Как я уже читаю сейчас, из многих историй о бизнесе, так или иначе многое зависит от удачи. Нам повезло. и буквально через пару недель после создания фирмы, к нам обратился мой брат Владимир, который и привел к нам первого клиента. Не буду утомлять деталями работы с клиентами, статья не об этом, скажу лишь, что мы поехали на аудит, выявили критические места и эти места сломались пока принималось решение о том сотрудничать ли с нами на постоянной основе в качестве аутсорсеров. После этого сразу было принято положительное решение.
Далее, в основном по сарафану через знакомых, начали появляться и другие компании на обслуживании. Helpdesk был в одной системе. Подключения к сетевому оборудованию и серверам в другой, а точнее у кого как. Кто-то сохранял ярлыки, кто-то пользовался адресными книгами RDP. Мониторинг еще одна отдельная система. Работать команде в разрозненных системах очень неудобно. Теряется из вида важная информация. Ну, например, стал недоступен терминальный сервер у клиента. Сразу поступают заявки от пользователей этого клиента. Специалист службы поддержки заводит заявку (она поступила по телефону). Если бы инциденты и заявки регистрировались в одной системе, то специалист поддержки сразу бы видел в чем проблема у пользователя и сказал ему об этом, параллельно уже подключаясь к нужному объекту для отработки ситуации. Все в курсе тактической обстановки и слаженно работают. Мы не нашли такой системы, где все это объединено. Стало понятно, что пора делать свой продукт.
Продолжение работы над своей системой мониторинга
Понятно было, что та система, которая была написана ранее совершенно не подходит под текущие задачи. Ни в плане функционала ни в плане качества. И было принято решение писать систему с нуля. Графически это должно было уже выглядеть совсем иначе. Это должно была быть иерархическая система, что бы можно было быстро и удобно открывать нужный объект у нужного клиента. Схема как в первой версией была в текущем случае абсолютно не оправдана, т.к. клиенты разные и вовсе не имело значения в каких помещениях стоит оборудование. Это было уже переложено на документацию.
Итак, задачи:
- Иерархическая структура;
- Какая-то серверная часть, которую можно поместить у клиента в виде виртуальной машины для сбора необходимых нам метрик и посылки на центральный сервер, который будет все это обобщать и показывать нам;
- Оповещения. Такие, которые нельзя пропустить, т.к. на тот момент не было возможности кому-то сидеть и только смотреть в монитор;
- Система заявок. Начали появляться клиенты, у которых мы обслуживали не только серверное и сетевое оборудование, но и рабочие станции;
- Возможность быстро подключаться к серверам и оборудованию из системы;
Задачи поставлены, начинаем писать. Попутно обрабатывая заявки от клиентов. На тот момент нас уже было 4 человека. Начали писать сразу обе части и центральный сервер, и сервер для установки к клиентам. К этому моменту Linux был уже не чужим для нас и было принято решение, что виртуальные машины, которые будут стоять у клиентов будут на Debian. Не будет никаких установщиков, просто сделаем проект серверной части на одной конкретной виртуальной машине, а потом просто будем ее клонировать к нужному клиенту. Это была очередная ошибка. Позже стало понятно, что в такой схеме абсолютно не проработан механизм апдейтов. Т.е. мы добавляли какую-то новую фичу, а потом была целая проблема распространять ее на все серверы клиентов, но к этому вернемся позже, все по порядку.
Сделали первый прототип. Он умел пинговать необходимые нам сетевые устройства клиентов и серверы и посылать эти данные к нам на центральный сервер. А он в свою очередь обновлял эти данные в общей массе на центральном сервере. Я тут буду писать не только историю о том, как и что удавалось, но и какие дилетантские ошибки совершались и как потом приходилось за это платить временем. Так вот, все дерево объектов хранилось в одном единственном файле в виде сериализованного объекта. Пока мы подключили к системе несколько клиентов, все было более-менее нормально, хотя и иногда были какие-то артефакты, которые были совершенно непонятны. Но когда мы подключили к системе десяток серверов, начались твориться чудеса. Иногда, непонятно по какой причине, все объекты в системе просто исчезали. Тут важно отметить, что серверы, которые были у клиентов, присылали данные на центральный сервер каждые несколько секунд посредством POST запроса. Внимательный читатель и опытный программист уже догадался, что возникала проблема множественного доступа к тому самому файлу в котором хранился сериализованный объект из разных потоков одновременно. И как раз, когда это происходило, проявлялись чудеса с исчезновением объектов. Файл попросту становился пустым. Но это все обнаружилось не сразу, а только в процессе эксплуатации с несколькими серверами. За это время был добавлен функционал по сканированию портов (серверы присылали на центральный не только информацию о доступности устройств, но и об открытых на них портах). Сделано это было путем вызова команды:
$connection = @fsockopen($ip, $port, $errno, $errstr, 0.5);
результаты часто были неправильными и выполнялось сканирование очень долго. Совсем забыл о пинге, он выполнялся через fping:
system("fping -r 3 -t 100 {$this->ip}");
Это все тоже не было распараллелено и поэтому процесс был очень долгий. Позже в fping уже передавался сразу весь список необходимых для проверки IP адресов и обратно получили готовый список тех, кто откликнулся. В отличии от нас, fping умел параллелить процессы.
Еще одной частой рутинной работой была настройка каких-то сервисов через WEB. Ну, например, ECP от MS Exchange. По большому счету это всего лишь ссылка. И мы решили, что нужно дать возможность нам добавлять такие ссылки прямо в систему, чтобы не искать в документации или еще где-то в закладках как зайти на ECP конкретного клиента. Так появилось понятие ресурсных ссылок для системы, их функционал доступен и по сей день и не претерпел изменений, ну почти.
Работа ресурсных ссылок в Veliam
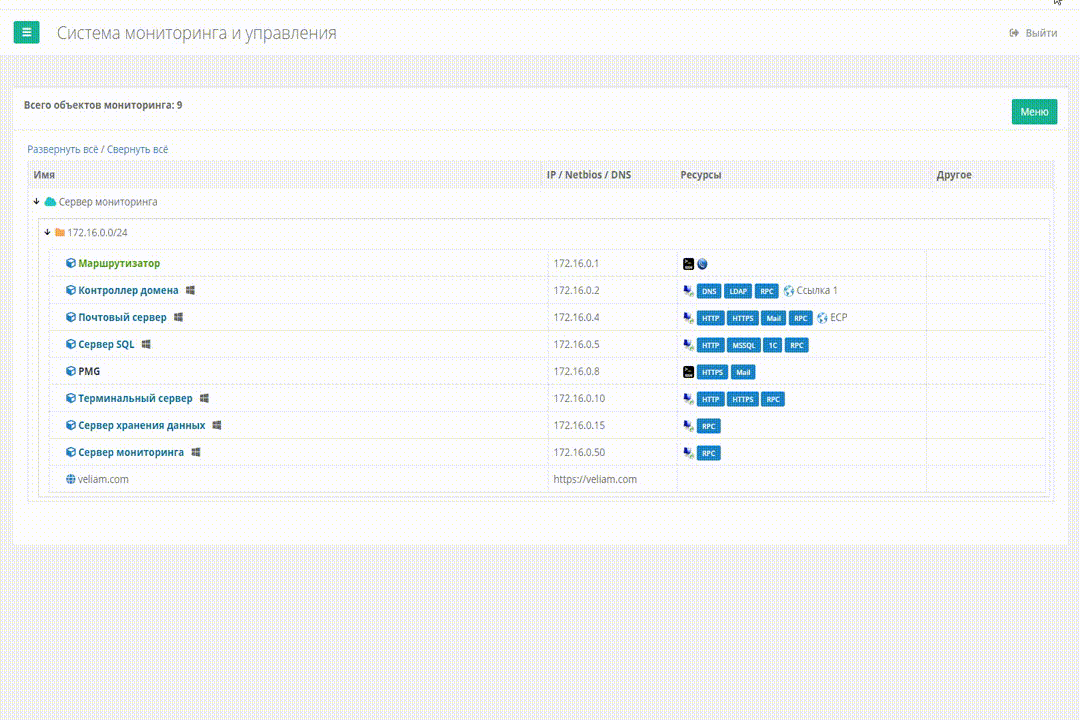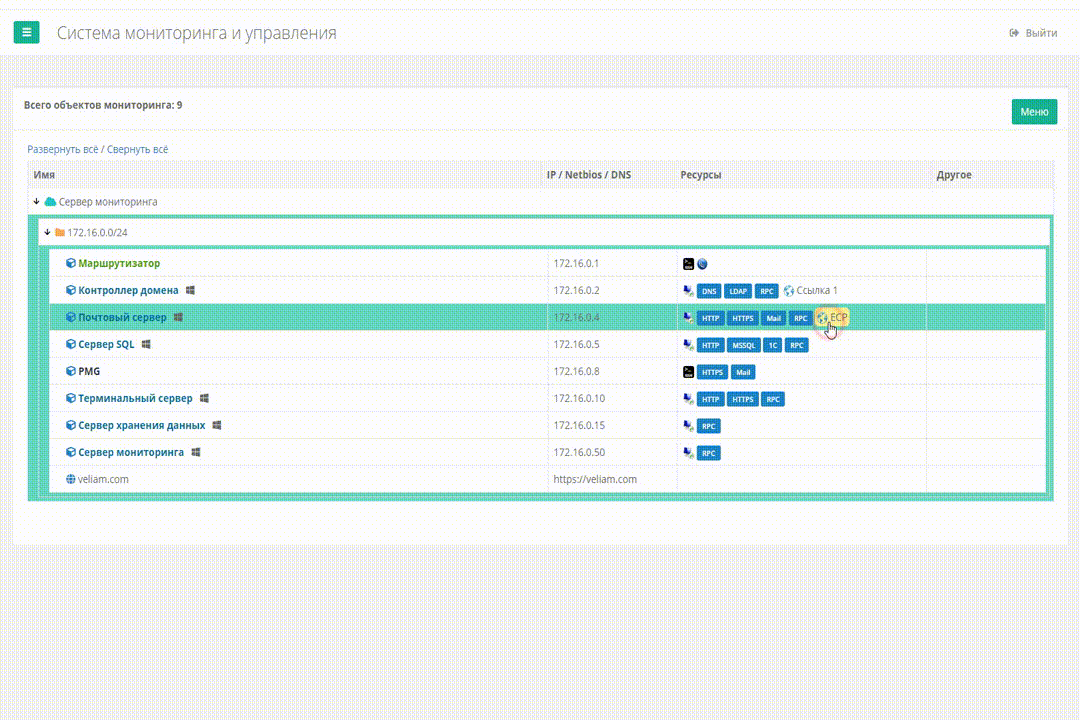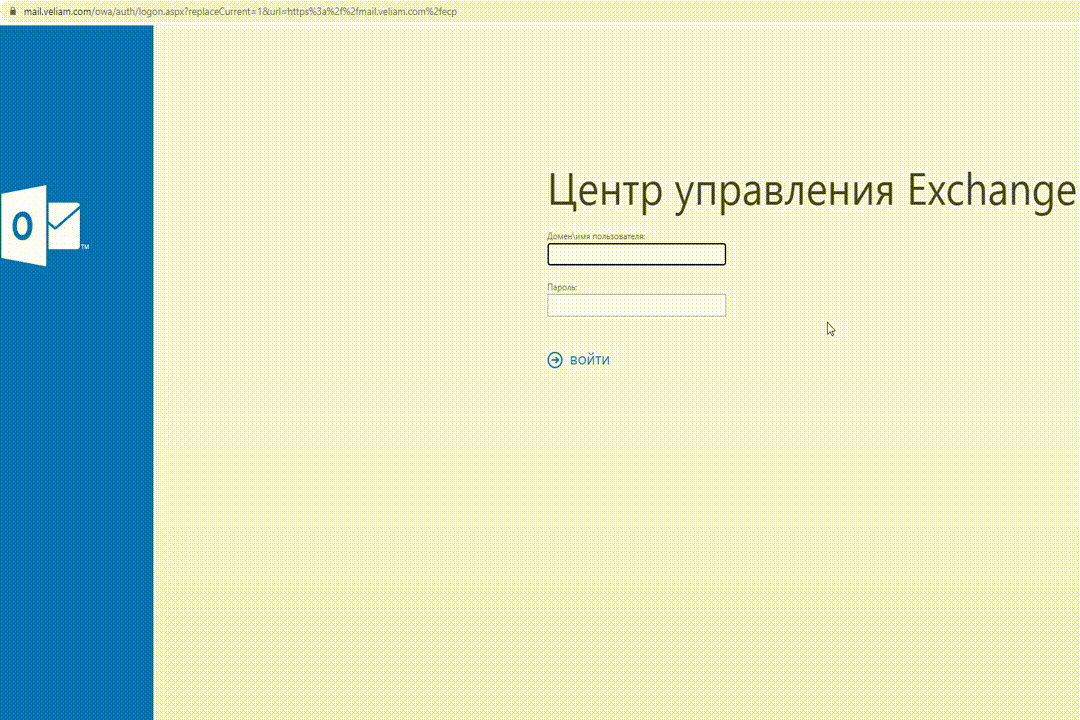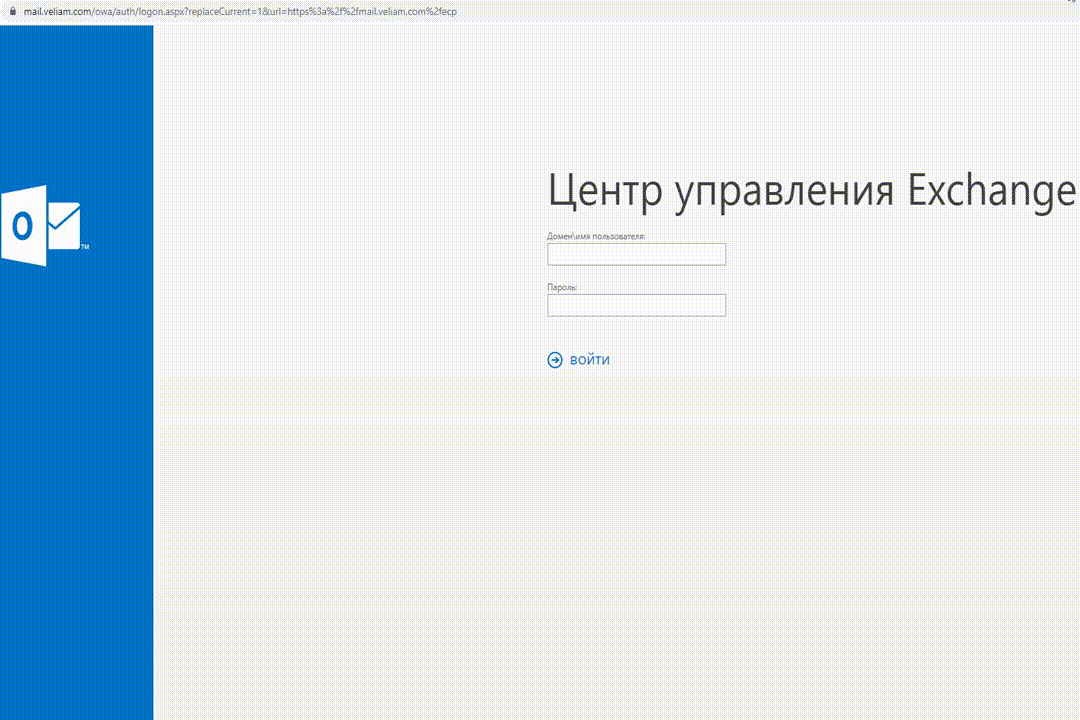
Удаленные подключения
Вот как это выглядит в деле в текущей версии Veliam
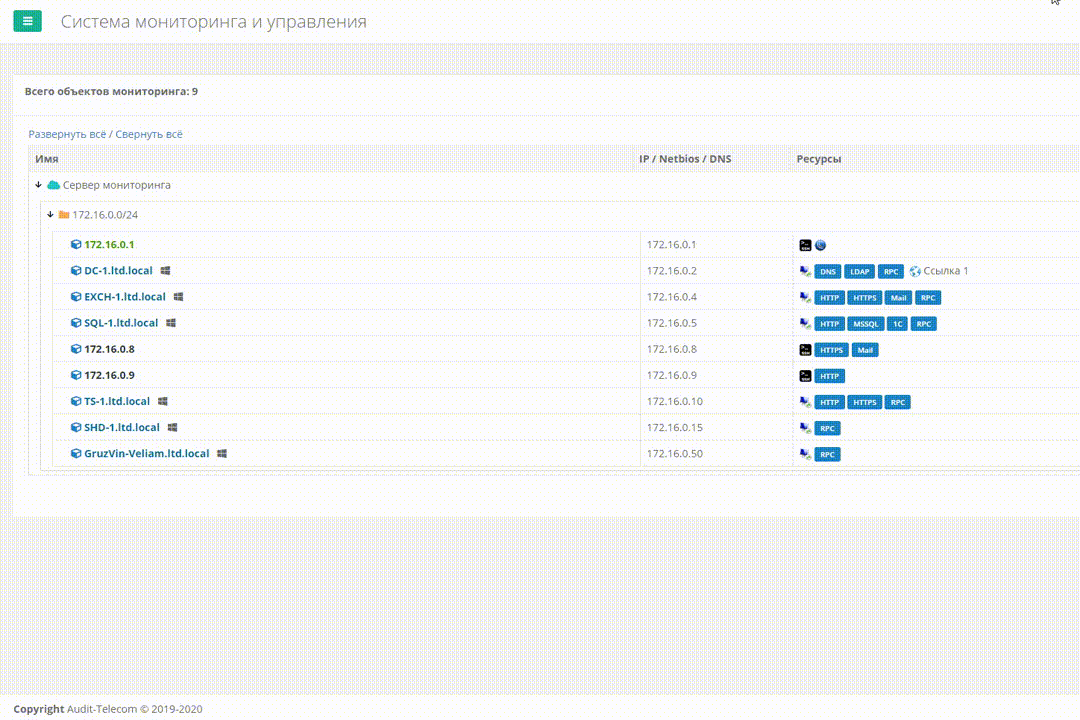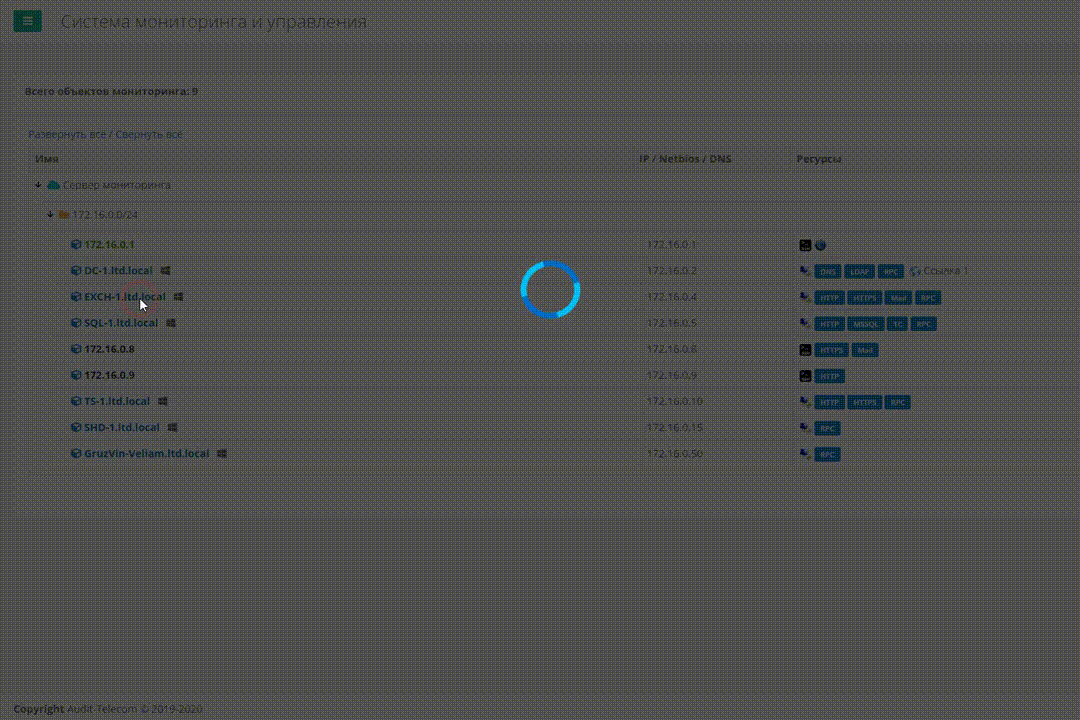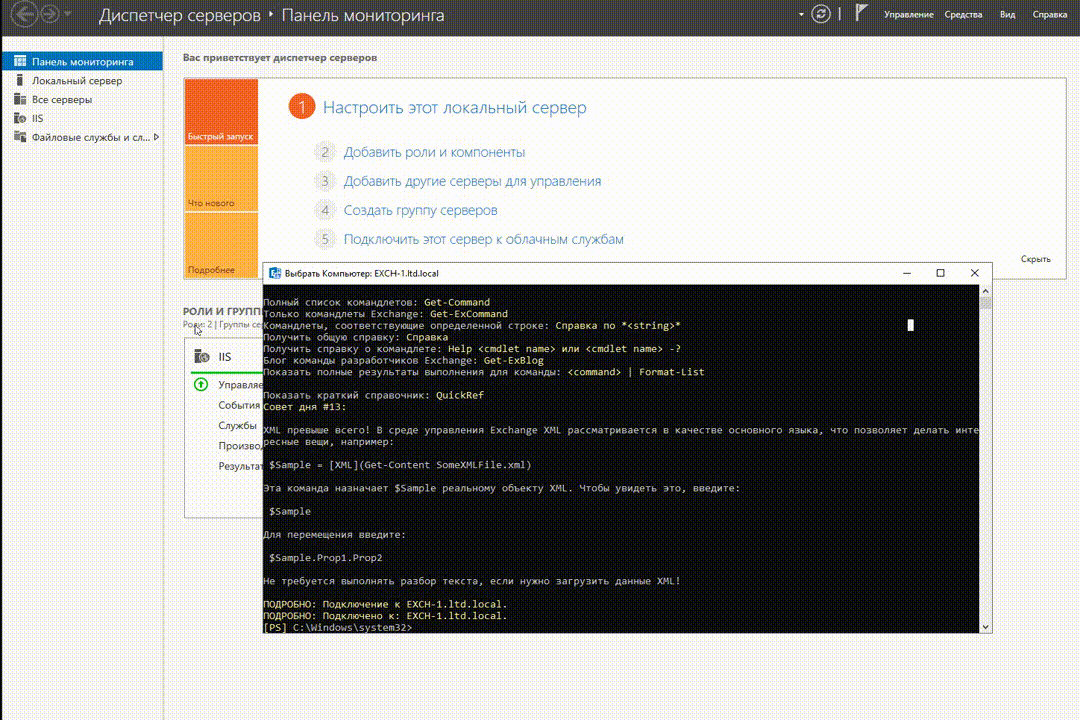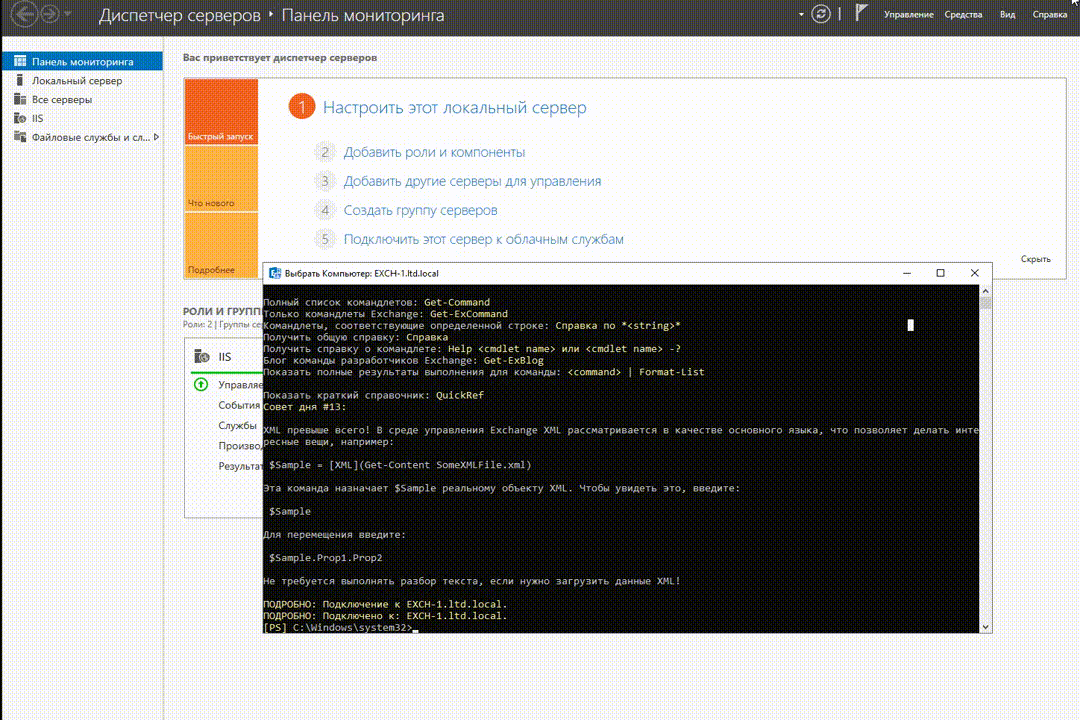
Одной из задач было быстрое и удобное подключение к серверам, которых стало уже много (не одна сотня) и перебирать миллионы заранее сохраненных RDP ярлыков было крайне неудобным. Нужен был инструмент. Есть в интернете софт, который представляет из себя что-то типа адресной книги для таких RDP подключений, но они не интегрированы с системой мониторинга, и учетки не сохранить. Каждый раз вводить учетки для разных клиентов это сущий ад, когда в день ты подключаешься не один десяток раз на разные серверы. С SSH дела обстоят чуть лучше, есть много хорошего софта в котором есть возможность раскладывать такие подключения по папочкам и запоминать учетки от них. Но есть 2 проблемы. Первая — для подключений RDP и SSH мы не нашли единую программу. Вторая — если я в какой-то момент не нахожусь за своим компьютером и мне надо быстро подключиться, или я просто переустановил систему, мне придется лезть в документацию, чтобы смотреть учетку от этого клиента. Это неудобно и пустая трата времени.
Нужная нам иерархическая структура по серверам клиентов уже имелась в нашем внутреннем продукте. Нужно было только придумать как прикрутить туда быстрые подключения к нужному оборудованию. Для начала, хотя бы внутри своей сети.
С учетом того, что клиентом в нашей системе выступал браузер, который не имеет доступа к локальным ресурсам компьютера, чтобы просто взять и какой-то командой запустить нужное нам приложение, было придумано сделать все через “Windows custom url scheme”. Так появился некий “плагин” к нашей системе, который просто включал в свой состав Putty и Remote Desktop Plus и при установке просто регистрировал URI схемы в Windows. Теперь, когда мы хотели подключиться к объекту по RDP или SSH, мы нажимали это действие в нашей системе и срабатывала работа Custom URI. Запускался стандартный mstsc.exe встроенный в Windows или putty, который шел в состав “плагина”. Беру слово плагин в кавычки, потому, что это не является плагином браузера в классическом смысле.
Это было уже хотя бы что-то. Удобная адресная книга. Причем в случае с Putty, все было вообще хорошо, ему в качестве входных параметров можно было подать и IP подключения и логин и пароль. Т.е. к Linux серверам в своей сети мы уже подключались одним кликом без ввода паролей. Но с RDP не все так просто. В стандартный mstsc нельзя подать учетные данные в качестве параметров. На помощь пришел Remote Desktop Plus. Он позволял это делать. Сейчас мы уже обходимся без него, но долгое время он был верным помощником в нашей системе. С HTTP(S) сайтами все просто, такие объекты просто открывались в браузере и все. Удобно и практично. Но это было счастье только во внутренней сети.
Так как подавляющее число проблем мы решали удаленно из офиса, самым простым было сделать VPN’ы до клиентов. И тогда из нашей системы можно было подключаться и к ним. Но все равно было несколько неудобно. Для каждого клиента нужно было держать на каждом компьютере кучу запомненных VPN соединений и перед подключением к какому-либо, надо было включать соответствующий VPN. Таким решением мы пользовались достаточно продолжительное время. Но количество клиентов увеличивается, количество VPN’ов тоже и все это начало напрягать и нужно было что-то с этим делать. Особенно наворачивались слезы на глазах после переустановки системы, когда нужно было вбивать заново десятки VPN подключений в новом профиле винды. Хватит это терпеть, сказал я и начал думать, что можно с этим сделать.
Так повелось, что у всех клиентов в качестве маршрутизаторов были устройства всем известной фирмы Mikrotik. Они весьма функциональны и удобны для выполнения практически любых задач. Из минусов — их “угоняют”. Мы эту проблему решили просто, закрыв все доступы извне. Но нужно было как-то иметь к ним доступ, не приезжая к клиенту на место, т.к. это долго. Мы просто сделали до каждого такого микротика тоннели и выделили их в отдельный пул. без какой-либо маршрутизации, чтобы не было объединения своей сети с сетями клиентов и их сетей между собой.
Родилась идея сделать так, чтобы при нажатии на нужный мне объект в системе, центральный сервер мониторинга, зная учетные записи от SSH всех клиентских микротиков, подключался к нужному, создавал правило проброса до нужного хоста с нужным портом. Тут сразу несколько моментов. Решение не универсальное — будет работать только для микротика, как так синтаксис команд у всех роутеров свой. Так же такие пробросы потом надо было как-то удалять, а серверная часть нашей системы по сути не могла отслеживать каким-либо образом закончил ли я свой сеанс работы по RDP. Ну и такой проброс — это дырище для клиента. А за универсальностью мы и не гнались, т.к. продукт использовался только внутри нашей компании и выводить его в паблик даже мыслей не было.
Каждая из проблем была решена по-своему. Когда создавалось правило, то проброс этот был доступен только для одного конкретного внешнего IP адреса (с которого было инициализировано подключение). Так что дыры в безопасности удалось избежать. Но при каждом таком подключении, добавлялось правило на микротик на страницу NAT и не очищалось. А всем известно, что чем больше там правил, тем сильнее нагружается процессор роутера. Да и в целом, я не мог принять такое, что я зайду однажды на какой-то микротик, а там сотни мертвых никому не нужных правил.
Раз наш сервер не может отслеживать состояние подключения, пусть микротик отслеживает их сам. И написал скрипт, который постоянно отслеживал все правила проброса с определенным описанием (description) и проверял есть ли TCP подключение подходящее правило. Если такового не было уже некоторое время, то вероятно подключение уже завершено и проброс этот можно удалять. Все получилось, скрипт хорошо работал.
Кстати вот он:
global atmonrulecounter {"dontDelete"="dontDelete"}
:foreach i in=[/ip firewall nat find comment~"atmon_script_main"] do={
local dstport [/ip firewall nat get value-name="dst-port" $i]
local dstaddress [/ip firewall nat get value-name="dst-address" $i]
local dstaddrport "$dstaddress:$dstport"
#log warning message=$dstaddrport
local thereIsCon [/ip firewall connection find dst-address~"$dstaddrport"]
if ($thereIsCon = "") do={
set ($atmonrulecounter->$dstport) ($atmonrulecounter->$dstport + 1)
#:log warning message=($atmonrulecounter->$dstport)
if (($atmonrulecounter->$dstport) > 5) do={
#log warning message="Removing nat rules added automaticaly by atmon_script"
/ip firewall nat remove [/ip firewall nat find comment~"atmon_script_main_$dstport"]
/ip firewall nat remove [/ip firewall nat find comment~"atmon_script_sub_$dstport"]
set ($atmonrulecounter->$dstport) 0
}
} else {
set ($atmonrulecounter->$dstport) 0
}
}
Наверняка его можно было сделать красивей, быстрей и т.д., но он работал, не нагружал микротики и отлично справлялся. Мы наконец-то смогли подключаться к серверам и сетевому оборудованию клиентов просто одним нажатием мышки. Не поднимая VPN и не вводя пароли. С системой стало реально очень удобно работать. Время на обслуживание сокращалось, а все мы тратили время на работу, а не на то чтобы подключиться к нужным объектам.
Резервное копирование Mikrotik
У нас было настроено резервное копирование всех микротиков на FTP. И в целом все было хорошо. Но когда нужно было достать бэкап, но надо было открывать этот FTP и искать его там. Система где все роутеры заведены у нас есть, общаться с устройствами по SSH мы умеем. Чего бы нам не сделать так, что система сама будет ежедневно забирать со всех микротиков бэкапы, подумал я. И принялся реализовывать. Подключились, сделали бэкап и забрали его в хранилище.
Код скрипта на PHP для снятия бэкапа с микротика:
<?php
$IP = '0.0.0.0';
$LOGIN = 'admin';
$PASSWORD = '';
$BACKUP_NAME = 'test';
$connection = ssh2_connect($IP, 22);
if (!ssh2_auth_password($connection, $LOGIN, $PASSWORD)) exit;
ssh2_exec($connection, '/system backup save name="atmon" password="atmon"');
stream_get_contents($connection);
ssh2_exec($connection, '/export file="atmon.rsc"');
stream_get_contents($connection);
sleep(40); // Waiting bakup makes
$sftp = ssh2_sftp($connection);
// Download backup file
$size = filesize("ssh2.sftp://$sftp/atmon.backup");
$stream = fopen("ssh2.sftp://$sftp/atmon.backup", 'r');
$contents = '';
$read = 0;
$len = $size;
while ($read < $len && ($buf = fread($stream, $len - $read))) {
$read += strlen($buf);
$contents .= $buf;
}
file_put_contents ($BACKUP_NAME . ‘.backup’,$contents);
@fclose($stream);
sleep(3);
// Download RSC file
$size = filesize("ssh2.sftp://$sftp/atmon.rsc");
$stream = fopen("ssh2.sftp://$sftp/atmon.rsc", 'r');
$contents = '';
$read = 0;
$len = $size;
while ($read < $len && ($buf = fread($stream, $len - $read))) {
$read += strlen($buf);
$contents .= $buf;
}
file_put_contents ($BACKUP_NAME . ‘.rsc’,$contents);
@fclose($stream);
ssh2_exec($connection, '/file remove atmon.backup');
ssh2_exec($connection, '/file remove atmon.rsc');
?>
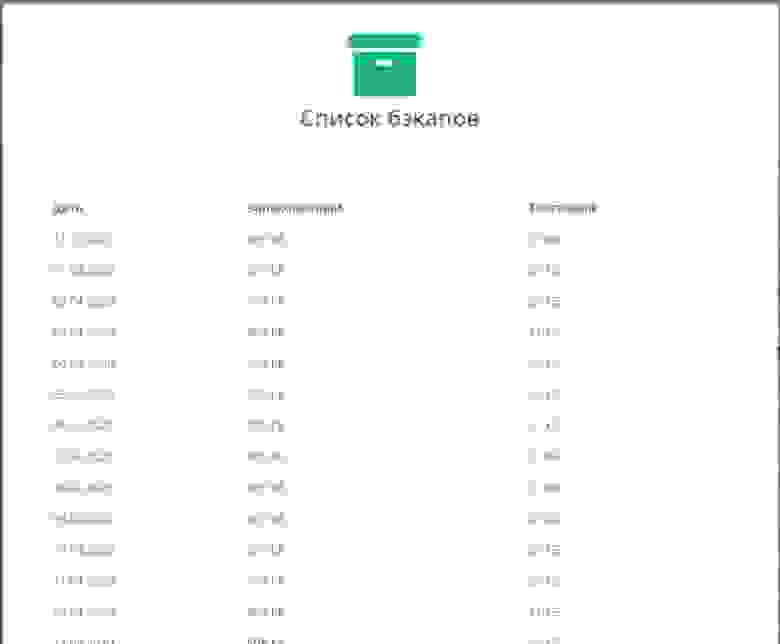
Бэкап снимается в двух видах — бинарник и текстовый конфиг. Бинарник помогает быстро ресторить нужный конфиг, а текстовый позволяет понимать, что надо делать, если произошла вынужденная замена оборудования и бинарник на него залить нельзя. В итоге получили еще один удобный функционал в системе. Причем, при добавлении новых микротиков не надо было ничего настраивать, просто добавил объект в систему и задал для него учетку от SSH. Дальше система сама занималась съемом бэкапов. В текущей версии SaaS Veliam этого функционала пока нет, но скоро портируем его.
Скрины как это выглядело во внутренней системе

Переход на нормальное хранение в базе данных
Выше я уже писал о том, что появлялись артефакты. Иногда просто исчезал весь список объектов в системе, иногда при редактировании объекта, информация не сохранялась и приходилось по три раза переименовывать объект. Это жутко раздражало всех. Исчезновение объектов происходило редко, и легко восстанавливалось путем восстановления этого самого файла, а вот фейл при редактировании объектов это прям было часто. Вероятно, я изначально не сделал это через БД потому, что в уме не укладывалось как можно дерево со всеми связями держать в плоской таблице. Она же плоская, а дерево иерархическое. Но хорошее решение множественного доступа, а в последствии (при усложнении системы) и транзакционного — это СУБД. Я же наверняка не первый кто столкнулся с этой проблемой. Полез гуглить. Оказалось, что уже все придумано до меня и есть несколько алгоритмов, которые строят дерево из плоской таблицы. Посмотрев на каждый, я реализовал один из них. Но это уже была новая версия системы, т.к. по сути переписывать из-за этого пришлось весьма много. Результат был закономерен, проблемы рандомного поведения системы ушли. Кто-то может сказать, что ошибки весьма дилетантские (однопоточные скрипты, хранение информации к которой был множественный одновременный доступ из разных потоков в файле и т.д.) в сфере разработке программного обеспечения. Может так и есть, но моя основная работа была администрирование, а программирование было побочным для души, и у меня попросту не было опыта работы в команде программистов, там, где такие элементарные вещи мне подсказали бы сразу старшие товарищи. Поэтому я все эти шишки набивал самостоятельно, но очень хорошо усвоил материал. А еще, свое дело — это и встречи с клиентами, и действия направленные на попытку раскрутки фирмы, и куча административных вопросов внутри компании и многое-многое другое. Но так или иначе, то что было уже — было востребовано. Ребята и я сам использовали продукт в повседневной работе. Были и откровенно неудачные идеи, и решения, на которые было потрачено время, а в итоге стало понятно, что это нерабочий инструмент и им никто не пользовался и это не попало в Veliam.
Служба поддержки — HelpDesk
Не лишним будет упомянуть как формировался HelpDesk. Это вообще отдельная история, т.к. в Veliam это уже 3-я совершенно новая версия, которая отличается от всех предыдущих. Сейчас это простая система, интуитивно понятная без лишних рюшек и финтифлюшек с возможностью интегрироваться с доменом, а также с возможностью доступа к этому же профилю пользователя из любого места по ссылке из письма. И что самое важное, есть возможность из любой точки (дома я или в офисе) подключиться к заявителю по VNC прямо из заявки без VPN или пробросов портов. Расскажу, как мы к этому пришли, что было до этого и какие ужасные решения были.
Мы подключались к пользователям через всем известный TeamViewer. На всех компьютерах, пользователей которых мы обслуживаем установлен ТВ. Первое, что мы сделали не так, и впоследствии убрали это — привязка каждого клиента ХД по железу. Как пользователь заходил в систему ХД для того, чтобы оставить заявку? Всем на компьютеры, помимо ТВ была установлена специальная утилита, написанная на Lazarus (тут многие округлят глаза, и возможно даже полезут гуглить что это такое, но лучше всего из компилируемых языков я знал Delphi, а Lazarus это почти тоже самое, только бесплатное). В общем пользователь запускал у себя специальный батник, который запускал эту утилиту, та в свою очередь считывала HWID системы и после этого запускался браузер и происходила авторизация. Зачем это было сделано? В некоторых компаниях, подсчет обслуживаемых пользователей ведется поштучно, и цена обслуживания за каждый месяц формируется исходя из количества людей. Это понятно, скажете вы, но зачем привязка к железу. Очень просто, некоторые индивиды, приходили домой и делали с домашнего ноутбука заявку в стиле “сделайте мне тут все красиво”. Помимо считывания HWID системы, утилита вытаскивала из реестра текущий ID Teamviewer’а и так же передавала к нам. У Teamviewer есть API для интеграции. И мы сделали эту интеграцию. Но была одна загвоздка. Через эти API нельзя подключиться к компьютеру пользователя, когда он явно не инициирует эту сессию и после попытки подключиться к нему он должен еще нажать “подтвердить”. На тот момент, нам показалось логичным, что без спроса пользователя никто не должен подключаться, а раз человек за компьютером, то он и сессию инициирует и утвердительно ответит на запрос удаленного подключения. Все оказалось не так. Заявители забывали нажать инициацию сессии, и приходилось им в телефонном разговоре это говорить. Это тратило время и нервировало обе стороны процесса. Более того, отнюдь не редкость такие моменты, когда человек оставляет заявку, но подключиться разрешает только тогда, когда он уходит на обед. Ибо проблема не критичная и не хочет, чтобы его рабочий процесс прерывался. Соответственно, он не нажмет никаких кнопок для разрешения подключиться. Так и появился дополнительный функционал при авторизации в HelpDesk — считывание ID Teamviwer’а. Мы знали постоянный пароль, который использовался при установке Teamviwer. Точней, его знала только система, так как он был вшит в установщик, и в нашу систему. Соответственно была кнопка подключения из заявки по нажатию на которую не нужно было ничего ждать, а сразу открывался Teamviewer и происходил коннект. В итоге стало два вида возможных подключений. Через официальный API Teamviewer и наш самопальный. К моему удивлению, первым почти сразу перестали пользоваться, хоть и было указание пользоваться им только в особых случаях и когда пользователь сам дает на это добро. Все же безопасность сейчас подавай. Но оказалось, что заявителям это не нужно. Они все абсолютно не против, что к ним подключаются без кнопки подтверждения. А раз так, то и в дальнейшем функционал подключения через API был упразднен за ненадобностью.
Переход на многопоточность в Linux
Давно уже начал напрашиваться вопрос ускорения прохода сканера сети на предмет открытости заранее определенного списка портов и простая пропинговка объектов сети. Тут само собой первое решение, которое приходит в голову — многопоточность. Так как основное время, которое тратится на пинг — это ожидание возврата пакета, и следующий пинг не может начаться пока не вернется предыдущий пакет, в компаниях у которых даже 20+ серверов плюс сетевого оборудования это уже работало довольно медленно. Суть в том, что один пакет может и пропасть, не уведомлять же об этом сразу системного администратора. Он просто такой спам очень быстро перестанет воспринимать. Значит надо пинговать каждый объект еще не один раз прежде чем делать вывод о недоступности. Если не вдаваться уж совсем в подробности, то надо параллелить потому, что если этого не сделать, то скорей всего, системный администратор будет узнавать о проблеме от клиента, а не от системы мониторинга.
Сам по себе PHP из коробки не умеет многопоточность. Умеет многопроцессность, можно форкать. Но, у меня уже по сути был написан механизм опроса и хотелось сделать так, чтобы я один раз считал все нужные мне узлы из БД, пропинговал все сразу, дождался ответа от каждого и только после этого сразу писал данные. Это экономит на количестве запросов на чтение. В эту идею отлично укладывалась многопоточность. Для PHP есть модуль PThreads, который позволяет делать реальную многопоточность, правда пришлось изрядно повозиться, чтобы настроить это на PHP 7.2, но дело было сделано. Сканирование портов и пинг стали быстрыми. И вместо, к примеру 15 секунд на круг раньше, на этот процесс стало уходить 2 секунды. Это был хороший результат.
Быстрый аудит новых компаний
Как появился функционал сбора различных метрик и характеристик железа? Все просто. Нам иногда заказывают просто аудит текущей ИТ инфраструктуры. Ну и тоже самое необходимо для ускорения проведения аудита нового клиента. Нужно было что-то, что позволит прийти в среднюю или крупную компанию и быстро сориентироваться, что у них вообще есть. Пинг во внутренней сети блокируют, на мой взгляд, только те, кто сам себе хочет усложнить жизнь, и таких по нашему опыту немного. Но и такие встречаются. Соответственно, можно быстро отсканировать сети на наличие устройств простым пингом. Дальше можно их добавить и просканировать на предмет открытых портов, которые нас интересуют. По сути этот функционал уже был, необходимо только было добавить команду с центрального сервера на подчиненный, чтобы тот просканировал заданные сети и добавил в список все что найдет. Забыл упомянуть, предполагалось, что у нас уже есть готовый образ с настроенной системой (подчиненный сервер мониторинга) который мы могли просто раскатать у клиента при аудите и подцепить его к своему облаку.
Но результат аудита обычно включает в себя кучу различной информации и одна из них это — что вообще за устройства в сети. В первую очередь нас интересовали Windows серверы и рабочие станции Windows в составе домена. Так как в средних и крупных компаниях отсутствие домена — это, наверное, исключение из правил. Что бы говорить на одном языке, средняя, в моем представлении, это 100+ человек. Нужно было придумать способ как собрать данные со всех виндовых машин и серверов, зная их IP и учетную запись доменного администратора, но при этом не устанавливая на каждую из них какой-то софт. На помощь приходит интерфейс WMI. Windows Management Instrumentation (WMI) в дословном переводе — инструментарий управления Windows. WMI — это одна из базовых технологий для централизованного управления и слежения за работой различных частей компьютерной инфраструктуры под управлением платформы Windows. Взято из вики. Далее пришлось опять повозиться, с тем, чтобы собрать wmic (это клиент WMI) для Debian. После того как все было готово оставалось просто опрашивать через wmic нужные узлы на предмет нужной информации. Через WMI можно достать с Windows компьютера почти любую информацию, и более того, через него можно еще и управлять компьютером, ну, например, отправить в перезагрузку. Так появился сбор информации о Windows станциях и серверах в нашей системе. Плюсом к этому шла и текущая информация о текущих показателях загруженности системы. Их мы запрашиваем почаще, а информацию по железу пореже. После этого, проводить аудит стало немного приятней.
Решение о распространении ПО
Мы сами ежедневно пользуемся системой, и она всегда открыта у каждого технического сотрудника. И мы подумали, что можно и с другими поделиться тем, что уже есть. Система была еще совсем не готова к тому, чтобы ее распространять. Необходимо было переработать очень многое, что бы локальная версия превратилась в SaaS. Это и изменения различных технических аспектов в работе системы (удаленные подключения, служба поддержки), и анализа модулей на предмет лицензирования, и шардирование баз данных клиентов, и масштабирование каждого из сервисов, и разработка систем автообновлений для всех частей. Но об этом будет вторая часть статьи.
Update
Вторая часть
