
Источник изображения: AnnaElli
Система «Антиплагиат» работает с текстами на разных языках. Большинство работ, поступающих на проверку, написаны на русском, английском или казахском языках. Сейчас индекс «Антиплагиата» содержит документы более чем на 50 языках.
Полноценную поддержку на всех этапах обработки документа имеют 15 из них. В ближайшее время планируем серьезно расширить этот список. Наши неутомимые исследователи учатся переводить даже с фантастических языков. Языки текста важны на нескольких этапах обработки документа.
Знать язык нужно для следующих операций:
- разбиение текста на слова;
- поиск и исправления технических обходов;
- слияние переносов;
- обработка апострофов и других знаков пунктуации;
- подсчет текстовых статистик;
- поиск заимствований.
Языки текста нам нужно знать не в общем, а в точности до слова. Важной особенностью является еще и то, что не все пользователи хотят качественной обработки своих трудов и нередко бывает, что их тексты «сопротивляются». Про разные способы технических изменений текста и методы борьбы с ними подробно написано здесь. Именно разного рода технические изменения текста и не позволяют нам использовать готовые решения без доработок, и самое неприятное из таких изменений – замена символов на похожие по написанию.
Существующие решения
Сходу изобретать велосипед не стали, а сравнили несколько схожих библиотек распознавания языков NTextCat / CLD3 /CLD2. И остановили свой выбор на CLD2 по нескольким весомым для нас причинам:
- быстрее аналогов (~200 док/c);
- не уступает по качеству определения другим библиотекам;
- возвращает проценты и блоки языков (начало и конец языкового фрагмента в тексте);
- можно задавать ожидаемые языки; имея такую подсказку, определитель работает лучше, но это не значит, что он ограничится только этим списком;
- есть C# обертка и положительный опыт использования;
- поддерживает довольно много языков (более 80).
Вполне ожидаемо, что все наши проблемы и задачи ни один из этих пакетов не решает, доработки все же понадобятся.
Текст сопротивляется
Тексты, для которых нужно определить язык, в основном милые и пушистые большие и грамотно написанные. Определители языков такие любят. И все же некоторые из них содержат детали, затрудняющие точное определение языков:
- вставки слов/словосочетаний неосновного языка (термины, имена собственные, обозначения и так далее) встречаются довольно часто и порой “подгребаются” под основной язык;
- наличие в тексте нескольких языков с часто чередующимися короткими фрагментами;
- большое количество формул, аббревиатур, схем…;
- омоглифы — вишенка на торте, большое количество омоглифов не оставляет шансов автоматическому определителю языков понять, на каком же языке текст.
Результат определения языков текста CLD2 в зависимости от количества омоглифов в тексте
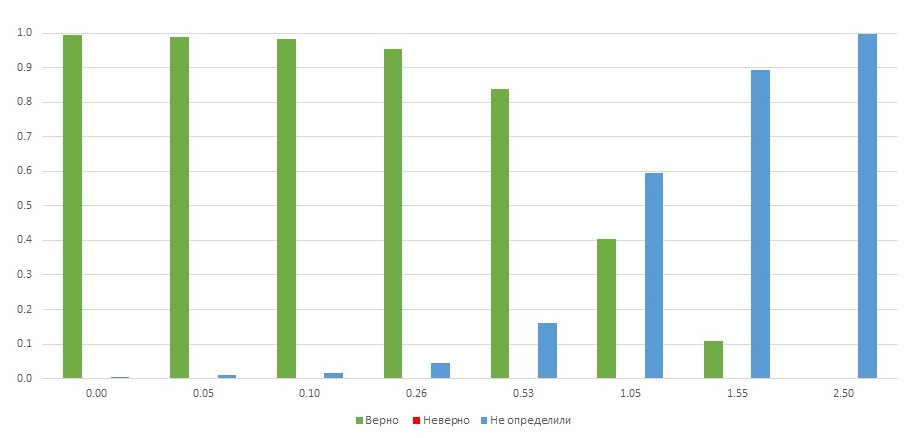
По вертикали отложена доля текста, по горизонтали – отношение количества омоглифов к количеству слов в тексте. Если в тексте присутствует один замененный символ на два слова, доля текста, на которой язык определился верно, начинает резко падать. При трех омоглифах на два слова почти на всем тексте язык не определен. Правда, есть и хорошая новость: для русского, английского и казахского языков случаи неверного определения языка крайне редки.
Для решения этой и других проблем, с которыми не справляется CLD2, мы разработали эвристический алгоритм. Это алгоритм использует многократный запуск CLD2, определение языка слов с помощью словарей и статистические методы.
Общая схема
Вход: текст и список языков (этот список может быть пуст).
Шаг 1: Определяем языки текста с помощью CLD2.
Шаг 2: Если качество определения языков устраивает, то переходим на шаг 4.
Шаг 3: Процедура множественного запуска CLD2.
Шаг 4: Доопределение языков с помощью эвристик.
На первом шаге все просто: отдали текст библиотеке, получили языковые блоки, отобрали значимые по проценту вхождения в текст языки. Все фрагменты, на которых определился язык, не поддерживаемый системой, мы запоминаем и в дальнейшем эти части текста обрабатываем способом «по умолчанию».
Оцениваем, что же вышло (шаг 2)
Результат первого шага оцениваем, исходя из покрытия текста найденными языковыми блоками. Стоит выкинуть из учета блоки длиной в 1-2 символа (CLD2 некоторые языки определяет по принадлежности символа к алфавиту). На данном шаге хочется понять, можно ли улучшить результат в общем. В случае, когда язык определился коротенькими фрагментами или доля текста, где язык не определен, велика, скорее всего, с текстом что-то не так и нужно пробовать исправить текст для улучшения результата работы CLD2.
Если долго мучиться… (шаг 3)
Шаг 3.0: Формируем список возможных языков из тех, что определили на первом шаге, и тех, что получили на вход.
Шаг 3.1:
Цикл по списку языков:
- Берем очередной язык из списка и во всех частях текста, где язык не определился (тут смотрим по самой первой попытке определить языки, т.е. результат первого шага), заменяем омоглифы из предположения, что текст в этих фрагментах на текущем языке.
- Определяем языки на полученном тексте с помощью CLD2 и запоминаем результат.
Шаг 3.2: Формируем языковые фрагменты из всех полученных результатов, включая самый первый. Если для некоторого фрагмента текста ровно в одной из итераций определился язык, то этот язык фиксируем, иначе считаем, что для этого фрагмента язык не определен.
Шаг 3.3: Для каждого фрагмента с зафиксированным языком заменяем омоглифы в соответствии с его языком. Еще раз отдаем текст CLD2 и полученный результат считаем текущим.

С точностью до слова (шаг 4)
Итак, к этому шагу уже имеются языковые фрагменты текста, которые получены либо на первом, либо на третьем шаге. Фрагменты различных языков могут пересекаться. Таким образом мы имеем не разбиение, а покрытие текста языковыми блоками, для каждого из которых выполнено что-то одно:
- язык определен, и он из списка поддерживаемых системой;
- язык определен, но он системой не поддерживается;
- язык не определен.
Дальше нам понадобится разбивать текст на токены (аналоги слов языка). Разбивать на токены можно по-разному. В общем случае это зависит от языка текста. В тех языках, с которыми мы сейчас работаем, слова разделяются пробелами и переносами строк. Для определения языка слова на этом этапе мы разделяем на токены не только по пробелам и переходам на новую строку, но и при смене буквенных символов на небуквенные и наоборот. Пример: «Самолет «Су-27».» Получим 4 токена: «Самолет», «"», «СУ», «-27".».
Поиск единичных вставок для блоков первого типа
Там, где язык определится и система с ним знакома, для нас остается опасность единичных вставок слов языка, отличного от языка фрагмента. Чаще всего это слова на английском языке. Для того, чтобы найти такие «затерявшиеся» слова, разобьем текст на токены и проанализируем каждый в отдельности. Коротенькие токены, длиной 1-2 символа, пропускаем. Анализируем токен посимвольно. Если все символы содержатся в алфавите языка фрагмента, то для него ничего не делаем. Если токен целиком состоит из символов другого алфавита, то добавляем фрагмент языка, соответствующего этому токену. На самом деле все очень просто — видим, что у слова в русском фрагменте не все буквы русские, а все казахские, значит, у этого слова будет два возможных языка: русский и казахский.
Второй случай нам неинтересен, и мы ничего с такими фрагментами текста больше не делаем.
Доопределение языка токенов для блоков третьего типа
Теперь хотелось бы понять, как быть с той частью текста, для которой язык не определился. Эту часть мы также разбиваем на токены и для каждого пытаемся определить язык. Поиск подходящего языка ведем только среди тех языков, что в тексте уже нашлись, и тех, что передал пользователь.
Сначала мы пытаемся найти слово в словаре какого-то языка. Прежде всего заменяем омоглифы и приводим слово к нормальной форме, в предположении конкретного языка из списка возможных, потом проверяем, входит ли оно в словарь этого языка. Слово входит в словарь — добавляем фрагмент, соответствующий этому слову. Здесь также может получиться несколько языков для одного слова. Для коротких слов (менее 4 символов) много ложных срабатываний, особенно в родственных языках, поэтому такие слова пропускаем.
В том случае, если поиск по словарям ничего не дал, пытаемся получить хоть какую-то информацию о языке этого слова с помощью символьных статистик. Считаем, сколько символов из слова принадлежит тому или иному алфавиту и возвращаем значимые языки.
Пример текста с большим количеством омоглифов
В этом небольшом кусочке чуть больше одного омоглифа на слово. Вот какой результат показал CLD2:

Голубым отмечены слова, для которых определился казахский язык. Фиолетовым — английский. Розовым — русский, правда, пока он не нашелся.
Такой результат нас не устраивает, и алгоритм пытается решить проблему с помощью замены омоглифов и многократного вызова CLD2.
В примере дан кириллический вариант казахского, где многие символы совпадают с символами русского языка, поэтому при замене омоглифов в предположении казахского и в предположении русского получаем одинаковые варианты определения языковых фрагментов.

Теперь заменим омоглифы в предположении, что неопределенные фрагменты на английском.

После этого понятно, что с «Кун» по «барады» определили символы казахского языка, с «Том» — «деревянную» – русского, с «Jim» — «him» – английского, а у слова «кадушку» язык не определен, потому что оно попало и в русский, и английский фрагменты. Перед последним запуском CLD2 заменяем омоглифы в тех фрагментах, для которых определили язык.
Итоговый результат:
Слово «Том» переметнулось. Да, так случается на границах похожих (для CLD2) языков и, возможно, стоит решать эту проблему отдельно.
Пример определения языка в тексте с часто чередующимися словами разных языков
В этом примере CLD2 почти ничего не нашел, а многократный запуск результат не улучшил. Определение языка слов по принадлежности к словарю дало хороший результат. Язык оставшиеся слов определили с помощью статистического метода. Розовым отмечен русский язык, фиолетовым — английский.

Что же в результате?
Конечно, хотелось понять, имеет ли смысл городить весь этот огород. Мы добросовестно нагенерили тестовые примеры из кусочков реальных текстов с разнообразными параметрами: длина текста, длины языковых фрагментов, частота вставки слов языков отличных от языка фрагмента, частота чередования языков, доля омоглифов. Для этих примеров нам была известна языковая разметка (сами же нагенерили!). В эксперименте мы ориентировались на языки большинства документов, присылаемых на проверку в системе «Антиплагиат»: русский, английский и казахский. Из полученных результатов мы выделили параметры, которые больше всего влияют на качество определения языка, и уже на них отлаживали фазы алгоритма. Наиболее значительные отклонения в качестве получаются при изменении количества омоглифов в тексте и при очень частом чередовании языков (длина языковых фрагментов не превышает пяти слов). Нам было важно понять, насколько устойчив статистически тот результат, что мы видим на отдельных примерах. На графике показана доля слов, для которых язык определился верно.
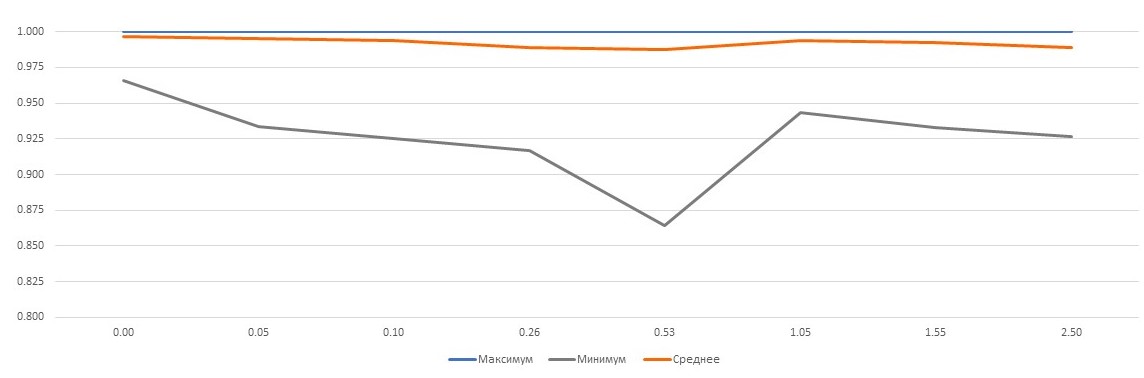
По горизонтали – отношение количества омоглифов к количеству слов в тексте. По вертикали – доля слов. Нижний график – худший результат по выборке. В среднем язык текстов определяется довольно хорошо даже на такой сложной выборке.
На данный момент нас устраивает качество результата, но с увеличением количества языков проблемы неизбежны. Во-первых, CLD2 игнорирует переданные в него языки, если их более 5. Во-вторых, эвристики определения языка слова по принадлежности к словарю и по символьным статистикам будут работать плохо при увеличении количества языков, допустимых для документа. Решение этих проблем нам еще предстоит. Если вы сталкивались с подобными задачами, то было бы интересно узнать о ваших идеях и подходах.
Комментируйте, критикуйте, восхищайтесь...
