«Подбор гиперпараметров». Если у вас в голове при произнесении этой фразы прокатились несколько панических атак и непроизвольно задергался глаз, а, возможно, и рука в инстинктивном желании перевернуть стол с криками «Да ну его, этот ваш дата сайнс» (нецензурную брань оставим за скобками), значит вы, как и я, хоть раз пытались обучить наивный байес мало-мальски тяжелую модель на большом объеме данных.

Источник изображения: thecode.media
Размер батча, learning rate, размер того слоя, размер сего слоя, вероятность dropout-a. Страшно? Уже представляете часы (дни) ожидания? А это я еще про количество голов у трансформеров не говорил…

Источник изображения: imgflip.com/memegenerator
Короче говоря, подбор гиперпараметров – это всегда боль любого датасаентолога. При этом известно, что пренебрежение этой процедурой может привести к большой потере в качестве или в производительности при решении любой задачи анализа данных, а в случае если вы предлагаете какой-то инновационный подход, то к построению слабого бейзлайна (this).
Процедуры RandomSearch и GridSearch известны нам всем из любого начального курса по машинному обучению. Однако немногие знают, или, по крайней мере, немногие используют при решении своих задач более изощренные методы оптимизации гиперпараметров. Мне давно было интересно разобраться, как работают подобные методы и действительно ли они дают существенный выигрыш во времени по сравнению с классикой. В данной статье я быстренько пройдусь по вышеупомянутым GridSearch и RandomSearch, постараюсь привести интуитивное объяснение, как работают байесовские алгоритмы оптимизации гиперпараметров, а также протестирую несколько существующих фреймворков (hyperopt, scikit-optimize, optuna) на одной из задач NLP.
Постановка задачи
Для начала стоит отметить, что алгоритмы оптимизации гиперпараметров работают с моделью, как с черным ящиком (с оракулом, если вам ближе язык оптимизации): им неважно, как работает модель, важно только значение функционала качества модели, обученной с рассматриваемыми гиперпараметрами. Поставим задачу более формально, описав её ДНК (Дано, Найти, Критерий (здравствуйте, Константин Вячеславович)).
Дано
Пространство гиперпараметров  где
где  – пространство
– пространство  -го параметра. Данные
-го параметра. Данные  .
.
Найти

где  измеряет функцию потерь модели
измеряет функцию потерь модели  , обученной при гиперпараметрах
, обученной при гиперпараметрах  на
на  и провалидированной на
и провалидированной на  [1].
[1].
Критерий
Тут уже есть расхождения. Если мы говорим о простых Grid/RandomSearch, то в качестве критерия здесь выступает просто функционал качества решаемой задачи (accuracy, cross-entropy, mse, ...). В байесовской оптимизации используются вероятностные (Surprise!) критерии, более конкретно о них поговорим в соответствующем разделе.
GridSearch, RandomSearch
Собственно, смысл этих подходов описан в их названии. «GridSearch» дословно обозначает «поиск по сетке», то есть «тупой экспоненциальный перебор всех узлов сетки параметров». Для RandomSearch всё слегка хитрее: он не просто перебирает все узлы сетки, а семплирует очередную точку на каждом шаге оптимизации.
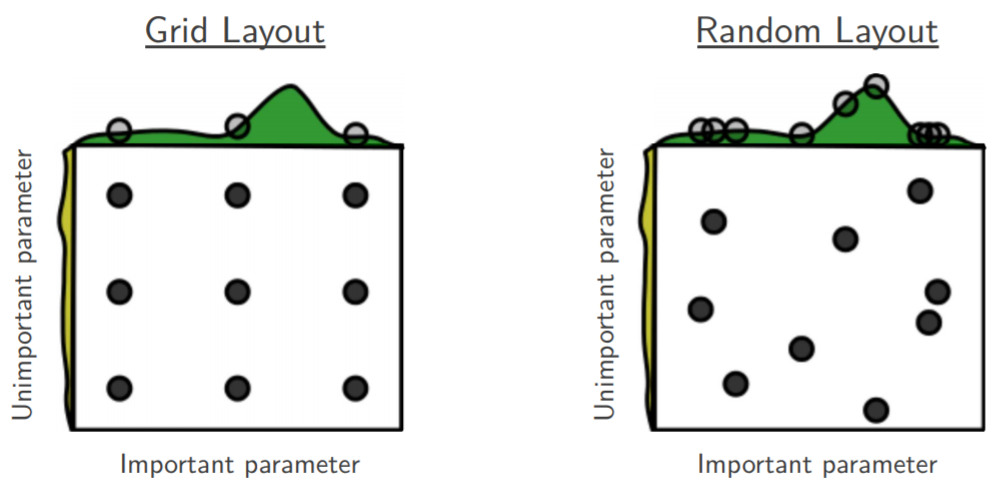
Источник изображения: www.jmlr.org
Думаю, многие видели подобную картинку в доказательство превосходства RandomSearch. Поиск по сетке слишком завязан на координатах, которые вы ему подаете на вход. Случайный поиск же менее зависим от человека и вполне может попасть в точку пространства, которая ближе к оптимуму (конечно, если эти точки распределены не категориально [спойлер: в наших экспериментах они распределены категориально]).
Bayesian optimization
По сути, байесовский подход – это модификация случайного поиска. Подумайте сами: как бы вы могли улучшить RandomSearch? Очевидно, что хочется чаще семплировать в окрестности тех точек, которые дают больший прирост в качестве. Собственно, так же подумали и байесиане байесологи свидетели Байеса исследователи байесовской статистики и байесовской оптимизации. Был предложен подход, основанный на идее, что для выбора лучшей области пространства гиперпараметров следует учитывать историю уже рассмотренных точек, в которых были обучены модели и получены значения целевой функции. Данный метод оптимизации гиперпараметров получил название SMBO (Sequential Model-Based Optimization).
Sequential Model-Based Optimization (SMBO)

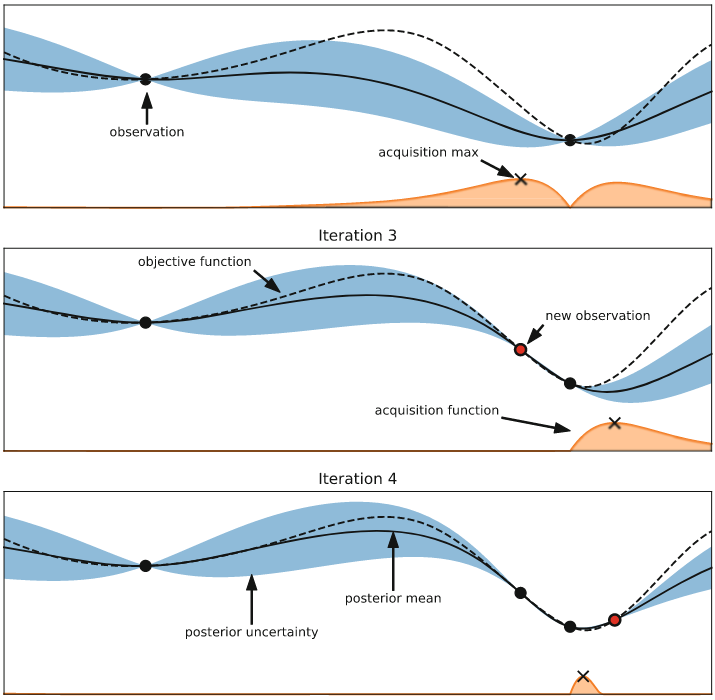
Источник изображения: [3]
SMBO включает в себя два ключевых ингредиента: вероятностная суррогатная модель (surrogate model) ( в приведенном выше алгоритме) и функция выбора (acquisition function) следующей точки (
в приведенном выше алгоритме) и функция выбора (acquisition function) следующей точки ( в приведенном выше алгоритме). На каждой итерации суррогатная модель обучается по всем полученным ранее выходам целевой функции. Таким образом, мы стараемся получить более дешевую аппроксимацию целевой функции. Далее функция выбора, используя предсказательное распределение суррогатной модели, оценивает «пользу» различных следующих точек, балансируя между использованием уже имеющейся информации и «разведыванием» новой области пространства (exploration vs exploitation). [1]
в приведенном выше алгоритме). На каждой итерации суррогатная модель обучается по всем полученным ранее выходам целевой функции. Таким образом, мы стараемся получить более дешевую аппроксимацию целевой функции. Далее функция выбора, используя предсказательное распределение суррогатной модели, оценивает «пользу» различных следующих точек, балансируя между использованием уже имеющейся информации и «разведыванием» новой области пространства (exploration vs exploitation). [1]
Источник изображения: [1]
Если проводить аналогию с обычной задачей машинного обучения, то функция выбора – это функция качества для мета-алгоритма SMBO, а суррогатная модель – это модель, которую мы получаем на выходе этого мета-алгоритма. Примерами функции выбора могут служить Expected Improvement, Probability of Improvement и т.п. Здесь и далее будет использоваться Expected Improvement, если не оговорено иное:

где
•  – некоторый порог значения функционала качества,
– некоторый порог значения функционала качества,
•  – суррогатная вероятностная модель получения
– суррогатная вероятностная модель получения  при выбранных гиперпараметрах и истории
при выбранных гиперпараметрах и истории  . [2]
. [2]
Таким образом, после некоторого количества итераций SMBO мы получаем какую-то аппроксимацию  нашей целевой функции . При этом, значения стоит получить гораздо дешевле, чем значения
нашей целевой функции . При этом, значения стоит получить гораздо дешевле, чем значения  .
.
Если говорить о суррогатных моделях, одними из наиболее популярных являются гауссовские процессы (Gaussian Processes (GP)) и парзеновские деревья (Tree-Structured Parzen Estimators (TPE)).

Источник изображения: twitter.com
Согласен, остановимся на этом чуть подробнее.
Gaussian Processes
При использовании гауссовских процессов целевая функция аппроксимируется в виде апостериорного распределения значений при выбранных параметрах и известной истории (). В качестве априорного распределения выбирается нормальное с константным матожиданием и изменяемой функцией ковариации:  .
.
Tree Parzen Estimators
В отличие от GP, которые напрямую моделируют  , данная стратегия моделирует
, данная стратегия моделирует  и
и  . Для этого априорные вероятности распределения каждого из гиперпараметров заменяются на их непараметрические аналоги. При этом, подобные замены позволяют использовать все имеющиеся точки пространства, моделируя сразу несколько распределений:
. Для этого априорные вероятности распределения каждого из гиперпараметров заменяются на их непараметрические аналоги. При этом, подобные замены позволяют использовать все имеющиеся точки пространства, моделируя сразу несколько распределений:

Стоит заметить, что в GP все точки из области  просто отбрасывались при использовании апостериорной вероятности в EI.
просто отбрасывались при использовании апостериорной вероятности в EI.
Алгоритм выбирает как некоторый  -квантиль среди всех полученных (в отличие от гауссовских процессов, где обычно выбирается как наименьшее значение лосса (функционала качества) из всей истории). В итоге можно показать [3], что
-квантиль среди всех полученных (в отличие от гауссовских процессов, где обычно выбирается как наименьшее значение лосса (функционала качества) из всей истории). В итоге можно показать [3], что

Из формулы можно увидеть, что для максимизации EI необходимо с высокой вероятностью брать точки из  и с низкой – из
и с низкой – из  . Подобный компромисс как раз решает проблему «exploration vs. exploitation».
. Подобный компромисс как раз решает проблему «exploration vs. exploitation».
В статье [3], где был впервые представлен TPE, приводилось его сравнение с GP, где TPE показал себя сильно лучше.
Эксперименты
Постановка эксперимента
Данные
Для эксперимента решено было взять задачу sentiment-analysis на датасете Large Movie Reviews Dataset. Датасет представляет собой сбалансированную выборку отрицательных и положительных отзывов о фильмах с imdb. В данном эксперименте нашей целью стояло не получение SOTA (state-of-the-art)-качества на конкретной задаче, а сравнение существующих фреймворков для оптимизации гиперпараметров с точки зрения конечного качества, удобства и скорости работы. Поэтому для преобразования слов в векторные представления мы взяли базовые предобученные 300-мерные fasttext эмбеддинги для английского языка, для 16 миллиардов токенов. При этом токенизация производилась простым TweetTokenizer из nltk без какой-либо дополнительной предобработки слов.
Модель и обучение

Источник изображения: habr.com
Мы выбрали модель на основе LSTM из pytorch со следующими конфигурируемыми гиперпараметрами:
- hidden_size – размер скрытого слоя,
- num_layers – количество слоев,
- bidirectional – является ли сеть двунаправленной.
Помимо этого, я также изменял
- lr – learining rate,
- batch_size – размер батча.
Изначально еще хотелось покрутить dropout, но для уменьшения мощности пространства гиперпараметров решено было зафиксировать его на значении 0.5. Как уже говорилось, в данной статье мы не гнались за SOTA-качеством. Поэтому распределение каждого из параметров было решено сделать категориальным с одинаковыми вероятностями (проще говоря, представить в виде сетки) для еще большего уменьшения мощности пространства. Вся сетка гиперпараметров выглядит следующим образом:
params_grid = {
'hidden_size': [64, 128, 256, 512],
'num_layers': [1, 2],
'dropout': [0.5],
'bidirectional': [True, False],
'batch_size': [64, 256],
'lr': [1e-3, 1e-2, 1e-1]
}
Чтобы не переобучать все модели для каждого отдельного оптимизатора (а каждый оптимизатор может еще и несколько раз оказываться в одинаковых точках пространства), было решено разбить эксперимент на 3 этапа:
- Обучение всех возможных моделей
- Оптимизация гиперпараметров на уже обученных моделях
- Проверка качества конечной модели на тестовой выборке
На первом этапе во время обучения кешируется куча всего, в том числе качество модели на валидационной и тестовой выборках и время обучения/теста модели. Обучение происходит в течение 20 эпох.
На втором этапе при попадании в очередную точку пространства мы просто подгружаем уже имеющееся у нас accuracy на валидации, учитывая потраченное на обучение время. Стоит отметить, что часто возникает ситуация, что оптимизатор приходит несколько раз в одну и ту же точку пространства. В таких случаях мы полагаем, что модель бы у нас уже была обучена, и не учитываем время обучения повторно.
На третьем этапе мы получаем уже закешированное качество конечной модели на тесте, учитывая время, потраченное на тест во время 1 этапа.
Рассмотренные фреймворки
В качестве бейзлайнов для сравнения я взял, собственно RandomSearch и GridSearch, написав их оптимизаторы собственноручно (см. github).
Для сравнения всех методов было решено отслеживать:
- общее время работы
- количество итераций алгоритма
- качество конечной модели на тесте
Помимо этого, я приведу плюсы и минусы каждого из фреймворков, выявленные мной в процессе экспериментирования с каждым из них, именно с точки зрения удобства, не качества решения задачи.
hyperopt
Судя по тому, что работа над фреймворком ведется аж с 2013 года при практически полном отсутствии документации, развивается он не слишком бойко (а, возможно, вообще доживает свой век). Также на сайте документации есть любопытная фраза: "Hyperopt has been designed to accommodate Bayesian optimization algorithms based on Gaussian processes and regression trees, but these are not currently implemented", то бишь изначально запланированные алгоритмы так и не были реализованы. Также в документации есть про распараллеливание с помощью MongoDB, Apache Spark, но подробно в это не вникал.
Еще при инициализации пространства можно создавать «условные параметры», позволяя это пространства представлять в виде дерева: в зависимости от того, по какой ветви дерева пойдет алгоритм, на выходе будут разные виды гиперпараметров. Так можно, к примеру, перебирать не только гиперпараметры к конкретному классификатору, но и рассматривать разные классификаторы. В зависимости от выбранного классификатора будут перебираться разные группы гиперпараметров.
Суррогатные функции
- TPE
- Adaptive TPE (не разбирал, если честно, поэтому рассматривать здесь не буду, извините)
Функции выбора
- EI (неизменяемо)
Плюсы
- Можно найти вдоволь разобранных примеров в интернете
- Функционал не слишком богатый, так что сконструировать какой-нибудь тестовый пример (
 ) и на нем протестировать всё, что вас интересует, не слишком сложно
) и на нем протестировать всё, что вас интересует, не слишком сложно - Можно отслеживать дополнительную информацию на каждом шаге с помощью класса Trials
Минусы
- Практически полное отсутствие документации, как уже было сказано, отнюдь не помогает в постижении данного фреймворка
- Способен только минимизировать, что надо учитывать при подаче ему функции качества
- Не слишком очевиден синтаксис описания пространства гиперпараметров (особенно с использованием условных параметров)
scikit-optimize
Из байесовских подходов есть только GP, но также реализованы методы на основе решающих деревьев. Хорошая документация (в стиле старшего брата scikit-learn), также есть несколько разобранных примеров и много примеров от других энтузиастов в интернете.
Суррогатные функции
- Decision Trees
- Gradient Boosted Trees
- GP
Функции выбора
- LCB (Lower Confidence Bound)
- EI
- PI (Probability of Improvement)
- gp_hedge – взвешенный выбор на основе трех вышеприведенных функций
- EIps – EI, которое принимает во внимание также время, потраченное на данной итерации (вылетает на NotImplementedError)
- PIps – то же для PI (вылетает на NotImplementedError)
Плюсы
- Большой выбор функций выбора
- Функционал не слишком богатый, так что сконструировать какой-нибудь тестовый пример () и на нем протестировать всё, что вас интересует, не слишком сложно
- Можно найти вдоволь разобранных примеров в интернете
- Неплохая документация
Минусы
- Нет отслеживания дополнительной информации на каждом шаге
- Способен только минимизировать, что надо учитывать при подаче ему функции качества
optuna
Наиболее молодой из представленных здесь фреймворков: статью о нем опубликовали в 2019 году. Хорошая документация. Помимо байесовских алгоритмов, есть возможность прунинга пространства гиперпараметров (удаления плохих точек из рассмотрения). По умолчанию удаляет точки, в которых модель дает качество ниже медианы из уже рассмотренных.
Суррогатные функции
- TPE
- CMA-ES (основан на эволюционном алгоритме)
- также есть RandomSearch, GridSearch
Функции выбора
- EI (настраиваем внутри TPESampler)
Плюсы
- Хорошая документация
- Define-by-run: возможность динамически описывать пространство параметров во время работы оптимизатора, что позволяет строить такое же древовидное пространство, как и в hyperopt
- Возможность явно задавать, нужно максимизировать или минимизировать функцию качества
- Pruning: удаление «плохих» точек пространства из рассмотрения.
- Есть возможность отслеживать дополнительные данные с помощью Trial.add_user_attr (у меня в коде этого нет, так как не сразу заметил)
Минусы
- Не слишком очевидно с первого взгляда, какие алгоритмы реализованы внутри библиотеки: нужно либо смотреть статью, либо больше времени проводить, бродя по документации (но вы уже дочитали до этого места, так что этот минус отпадает для вас)
Результаты
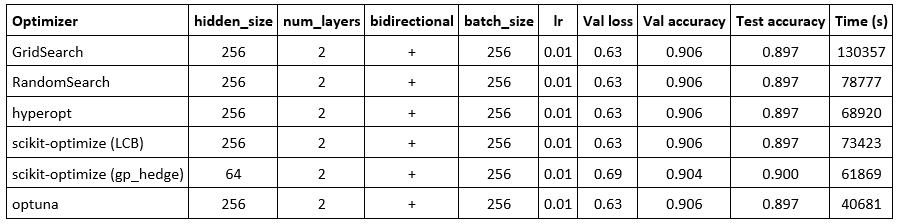
Как видно, почти все оптимизаторы приходят в одну и ту же точку, в которой accuracy на валидации является максимальным (GridSearch иначе и не мог). При этом лучшее время показывает optuna: он более чем в 3 раза быстрее полного перебора и более, чем в 1.5 раза быстрее, чем hyperopt, несмотря на то, что в обоих случаях используется TPE и EI.
Стоит прокомментировать, почему я включил scikit-optimize дважды. Я экспериментировал со всеми функциями выбора. EIps и PIps, видимо, еще не реализованы ввиду вылетающего exception. Все остальные функции, кроме LCB, приходят в одинаковую точку, в которой качество на тесте выше, а качество на валидации ниже, чем у LCB. Тут следует напомнить, что наш оптимизатор работает с моделью как с черным ящиком. Цель оптимизатора заключается в нахождении точки пространства гиперпараметров, в которой соответствующая модель даст наибольшее качество именно на валидации. Поэтому то, что большинство функций выбора приводят алгоритм в точку пространства, где качество на тесте выше, является, скорее, результатом переобучения нейросети и ошибки оптимизатора scikit-optimize. Функция gp_hedge была выбрана как показавшая наилучшее время среди остальных, приходящих в ту же точку.
Дальше приведу несколько графиков. Под skopt подразумевается scikit-optimize (LCB), если что.
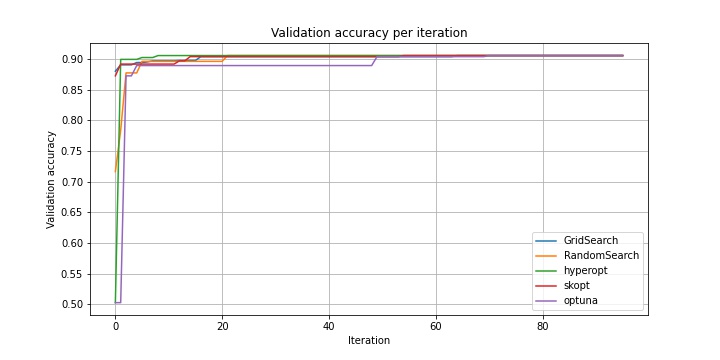
Как видно, все алгоритмы на первых итерациях ведут себя приблизительно одинаково. Поэтому рассмотрим изменение качества после 5 итерации.

Как можно увидеть, hyperopt одним из первых достигает наилучшей точки пространства. Однако посмотрим еще на зависимость общего времени, потраченного на обучение моделей от итерации.

Как видно из таблицы и из приведенного графика, hyperopt сильно проигрывает optuna по времени. Сначала я грешил на прунинг, но без него результат оказался идентичным. Судя по всему, TPE в hyperopt больше «разведывает» неизвестную область пространства, в связи с чем чаще натыкается на неизвестные ранее точки, следовательно, тратит больше времени на обучение. Думаю, можно подкрутить параметры как optuna в сторону exploration, так и hyperopt в сторону exploitation, но из коробки они работают так.
Выводы
Ситуация по результатам эксперимента несколько спорная, хотя перевес явно в сторону optuna. Также, по моим субъективным ощущениям, этот фреймворк явно выигрывает у hyperopt. Но посмотрим на них в сравнении.
Почему optuna?
- Его плюсы перевешивают плюсы hyperopt, а единственный минус, по сути, отсутствует. Также, из коробки по времени на большом числе итераций он сходится быстрее к лучшему решению, если правильно всё закешировать
- Хорошая документация, и вкатиться будет довольно просто
- Фреймворк молодой и, судя по github, активно развивается, в отличие от hyperopt
- Pruning. В моем эксперименте он не зажег, но, уверен, если покопаться, он может внести дополнительный вклад в производительность
Почему hyperopt?
- Если вы прожженный байесовский оптимизатор и уже имели дело с этим фреймворком, а также хотите, чтобы из коробки всё работало за малое число итераций, то, возможно, пока не стоит перекатываться в optuna
- Второй пункт не придумал
Заключение
Надеюсь, мне удалось более-менее простым языком объяснить принцип работы оптимизаторов гиперпараметров. А если и не удалось, то я хотя бы разобрал несколько фреймворков. Код доступен на github.
Спасибо за внимание!
Список использованных источников
1. Feurer, Matthias, and Frank Hutter. «Hyperparameter optimization.» In Automated Machine Learning, pp. 3-33. Springer, Cham, 2019.
2. Koehrsen, Will. «A conceptual explanation of bayesian hyperparameter optimization for machine learning.» (2018).
3. Bergstra, James S., Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. «Algorithms for hyper-parameter optimization.» In Advances in neural information processing systems, pp. 2546-2554. 2011.
4. Akiba, Takuya, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. «Optuna: A next-generation hyperparameter optimization framework.» In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2623-2631. 2019.
5. krasserm.github.io/2018/03/21/bayesian-optimization
6. krasserm.github.io/2018/03/19/gaussian-processes
