Привет всем, немного информации "из под капота" дата инженерного цеха Альфастрахования — что будоражит наши технические умы.

Apache Spark — замечательный инструмент, позволяющий просто и очень быстро обрабатывать большие объемы данных на достаточно скромных вычислительных ресурсах (я имею в виду кластерную обработку).
Традиционно, в процессе ad hoc обработки данных используется jupyter notebook. В комбинации со Spark-ом это позволяет нам манипулировать долго живущими дата фреймами (распределением ресурсов занимается Spark, дата фреймы "живут" где-то в кластере, время их жизни ограничено временем жизни Spark контекста).
После переноса обработки данных в Apache Airflow время жизни дата фреймов сильно сокращается — Spark контекст "живет" в пределах одного оператора Airflow. Как это обойти, зачем обходить и при чем здесь Livy — читайте под катом.
Давайте рассмотрим совсем-совсем простой пример: предположим нам нужно денормализовать данные в большой таблице и сохранить результат в другой таблице для дальнейшей обработки (типичный элемент конвейера обработки данных).
Как бы мы это делали:
- загрузили данные в dataframe (выборка из большой таблицы и справочников)
- посмотрели "глазами" на результат (правильно ли получилось)
- сохранили dataframe в таблицу Hive (например)
По результатам анализа нам может потребоваться вставить на втором шаге какую-то специфическую обработку (словарную замену или еще что-то). С точки зрения логики мы имеем три шага
- шаг 1: загрузка
- шаг 2: обработка
- шаг 3: сохранение
В jupyter notebook у нас так и получается — мы можем сколь угодно долго обрабатывать загруженные данные, отдав Spark-у управление ресурсами.
Вполне логично ожидать, что такое разбиение удастся перенести в Airflow. То есть иметь граф примерно такого вида

К сожалению, это невозможно при использовании комбинации Airflow + Spark: каждый оператор Airflow исполняется в своем python интерпретаторе, поэтому кроме всего прочего каждый оператор должен как-то "персистить" результаты своей деятельности. Тем самым наша обработка "сжимается" в один шаг — "денормализовать данные".
Как можно "вернуть" в Airflow гибкость jupyter notebook? Понятно, что приведенный пример "того не стоит" (может быть, даже наоборот — получается хороший понятный шаг обработки). Но все же — как сделать так, чтобы операторы Airflow могли выполняться в одном Spark контексте над общим пространством dataframe-ов?
Приветствуем Livy
На помощь приходит еще один продукт экосистемы Hadoop — Apache Livy.
Не буду пытаться здесь описать — что это за "зверь" такой. Если совсем кратко и черно-бело — Livy позволяет "инжектить" python код в программу, которую исполняет driver:
- сначала мы создаем сессию работы с Livy
- после этого у нас есть возможность исполнять произвольный код на python-е в этой сессии (очень похоже на идеологию jupyter/ipython)
И к всему этому есть REST API.
Возвращаясь к нашей простенькой задаче: с помощью Livy мы можем сохранить изначальную логику нашей денормализации
- на первом шаге (первом операторе нашего графа) мы загрузим и выполним код загрузки данных в dataframe
- на втором шаге (втором операторе) — выполним код необходимой дополнительной обработки этого dataframe
- на третьем шаге — код сохранения dataframe-а в таблицу
Что в терминах Airflow может выглядеть так:
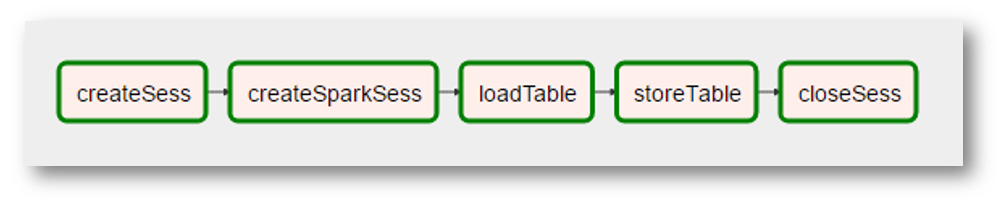
(поскольку картинка вполне реальный скриншот, то добавились дополнительные "реалии" — создание Spark контекста стало отдельной операцией со странным названием, "обработка" данных пропала, потому что не нужна, и т.п.)
Если обобщить — мы получаем
- универсальный Airflow оператор, который выполняет код на python-е в сессии Livy
- возможность "организовывать" код на python-е в достаточно сложные графы (на то и Airflow)
- возможность заняться оптимизациями более высокого уровня, например, в каком порядке нужно выполнять наши преобразования с тем, чтобы Spark смог максимально долго держать общие данные в памяти кластера
Типичный конвейер подготовки данных для моделирования содержит порядка 25 запросов по 10 таблицам, очевидно, что некоторые таблицы используются чаще других (те самые "общие данные") и есть что пооптимизировать.
Что дальше
Техническая возможность опробована, думаем дальше — как технологичнее перевести наши трансформации в эту парадигму. И как подступиться к упомянутой выше оптимизации. Мы еще в начале этой части нашего пути — когда будет что-то интересное, обязательно поделимся.
