
Клиент банка может совершить до нескольких тысяч транзакций по дебетовым и кредитным картам за год. Банк же в свою очередь сохраняет всю история пользовательских операций на своей стороне. В итоге образуется огромный объем данных, достаточный для того, чтобы на текущий момент его можно было смело называть модным словом BigData. Дата-сайентисты обожают, когда для решения задачи доступен большой объем информации, так как все методы машинного обучения сводятся к выявлению зависимостей между данными и целевой переменной — чем больше объем данных и богаче признаковое описание, тем более сложные зависимости можно обнаружить за счет увеличения сложности моделей.
Благодаря высокой плотности транзакционной истории становится возможным моделирование множества целевых переменных, в том числе наиболее ценных для банка: выход клиента в дефолт, интерес к кредитным продуктам, доход клиента.
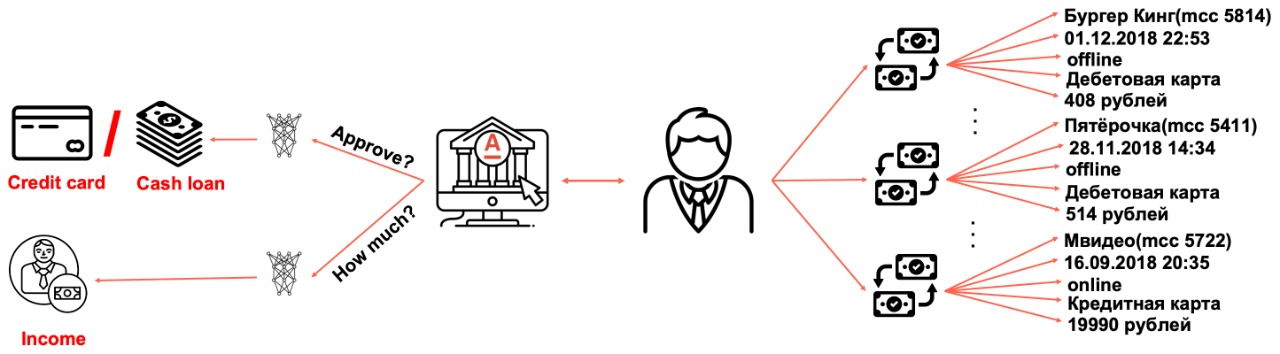
В рамках соревнования Альфа-Баттл 2.0 на boosters.pro участникам предлагалось решить задачу кредитного скоринга, используя только транзакционные данные клиента за предшествующий год. После соревнования была организована песочница, являющаяся копией соревнования, но без ограничения по времени и без денежных призов. Датасет соревнования можно использовать в научных публикациях, дипломных и курсовых работах.
Описание данных
Участникам соревнования был предоставлен датасет по 1.5 миллионам выдач кредитных продуктов. К каждому объекту выборки было подтянуто признаковое описание в виде истории клиентских транзакций глубиной в год. Дополнительно был представлен тип выданного продукта. Обучающая выборка состоит из выдач за период в N дней, тестовая выборка содержит выдачи за последующий период в K дней. Всего в датасете содержалось 450 миллионов транзакций, объемом порядка 6 гигабайт в формате parquet. Понимая, что такой объем данных может стать серьезным порогом для входа, мы разбили датасет на 120 файлов и реализовали методы пакетной предобработки данных, что позволило решать задачу соревнования с личного ноутбука.
Каждая карточная транзакция была представлена в виде набора из 19 признаков. Выкладывая большой объем данных в открытый доступ, мы были вынуждены скрыть значения признаков, поставив им в соответствие номера категорий.
Признаки карточных транзакций
название признака | описание | Кол-во уникальных значений |
currency | Идентификатор валюты транзакции | 11 |
operation_kind | Идентификатор типа транзакции | 7 |
card_type | Уникальный идентификатор типа карты | 175 |
operation_type | Идентификатор типа операции по пластиковой карте | 22 |
operation_type_group | Идентификатор группы карточных операций, например, дебетовая карта или кредитная карта | 4 |
ecommerce_flag | Признак электронной коммерции | 3 |
payment_system | Идентификатор типа платежной системы | 7 |
income_flag | Признак списания/внесения денежных средств на карту | 3 |
mcc | Уникальный идентификатор типа торговой точки | 108 |
country | Идентификатор страны транзакции | 24 |
city | Идентификатор города транзакции | 163 |
mcc_category | Идентификатор категории магазина транзакции | 28 |
day_of_week | День недели, когда транзакция была совершена | 7 |
hour | Час, когда транзакция была совершена | 24 |
days_before | Количество дней до даты выдачи кредита | 23 |
weekofyear | Номер недели в году, когда транзакция была совершена | 53 |
hour_diff | Количество часов с момента прошлой транзакции для данного клиента | 10 |
amnt | Нормированная сумма транзакции. 0.0 - соответствует пропускам | inf |
Целевой переменной в соревновании была бинарная величина, соответствующая флагу дефолта по кредитному продукту. Метрикой для оценки качества решений была выбрана AUC ROC.
Базовый подход к решению задачи
Каждый объект выборки представлен в виде многомерного временного ряда, состоящего из вещественных и категориальных признаков. Задачу классификации временных рядов можно решать классическим подходом, состоящим из генерации огромного количества признаков с последующим отбором наиболее значимых и стабильных. Очевидными агрегациями вещественных признаков являются: среднее, медиана, сумма, минимум, максимум, дисперсия по фиксированным временным отрезкам.
В случае категориальных признаков можно использовать счетчики вхождений каждого значения каждой категориальной переменной или пойти дальше и использовать вектора из матричных разложений или основанных на них методах: LDA, BigARTM. Последний из которых позволяет получить векторное представление сразу для всех категориальных признаков за счет поддержи мультимодальности. Признаки можно отобрать на основе важности, полученной популярным методом permutaion importance или менее популярным target permutation. С базовым подходом, приносящим 0.752 AUC ROC на public LB, можно ознакомиться на git.
Архитектура нейронной сети

Решать задачу классификации многомерных временных рядов можно методами, используемыми в классификации текстов, если мысленно заменить каждое слово текста набором категориальных признаков. В области обработки естественного языка принято ставить каждому слову в соответствие числовой вектор, размерности сильно меньше, чем размера словаря. Обычно вектора слов предобучают на огромном корпусе текстовых документов методами обучения без учителя: word2vec, FastText, BERT, GPT-3. Основной мотивацией предобучения являются огромное количество параметров, которое нужно выучить в виду большого размера словаря и обычно небольшого размеченного датасета для решения прикладной задачи. В данной задаче ситуация обратная: менее 200 уникальных значений для каждой категориальной переменной и большой размеченный датасет.
Резюмируя вышесказанное, векторного представление для каждого категориального признака можно получить, используя стандартный Embedding Layer, работающий по следующему алгоритму: в начале задается желаемый размер векторного представления, затем инициализируется LookUp матрица из некоторого распределения, далее ее веса учатся вместе с остальной сетью методом backpropagation. Размер эмбеддинга обычно выбирается равным или меньше половины числа уникальных значений категориального признака. Любой вещественный признак можно перевести в категориальный операцией бинаризации. Вектор для каждой транзакции получается из конкатенации эмбеддингов, соответствующих значениям ее категориальных признаков.
Далее последовательность векторов транзакций отправим в BiLSTM для моделирования временных зависимостей. Затем избавимся от пространственной размерности при помощи конкатенации GlobalMaxPool1D и GlobalAveragePool1D для последовательностей векторов из рекуррентного и эмбеддинг-слоев. В итоге, предварительно пропустив полученный вектор через промежуточный полносвязный слой, остается добавить полносвязный слой с sigmoid для решения задачи бинарной классификации.
Обучение нейронной сети
Рассмотрим архитектуру нейронной сети, предложенную участникам соревнования в качестве продвинутого бейзлайна. Она несущественно отличается от вышеописанной и содержит сотни тысяч обучаемых параметров. Тяжелые модели склонны переобучаться, запоминая обучающую выборку и показывая низкое качество на новых объектах. На курсах по машинному обучению учат использовать L1 и L2 регуляризацию в контексте логистической регрессии для борьбы с переобучением, будем использовать это знание и установим коэффициенты регуляризации для всех параметров нейронной сети. Не забудем использовать Dropout перед полносвязным слоем и SpatialDropout1D после эмбеддинг-слоя, также стоит помнить что всегда можно облегчить сеть, уменьшив размеры скрытых слоев.
Мы обладаем ограниченным количеством вычислительных ресурсов, поэтому возникает нативное желание использовать их наиболее эффективным образом, ускоряя каждый цикл обучения модели, тестируя большее количество гипотез. Косвенным признаком того, что обучение нейронной сети можно ускорить, является низкая утилизация видеокарты. Обычно проблема кроется в неоптимальной генерации батчей. В первую очередь стоит убедиться в том, что ваш генератор имеет асинхронную реализацию с поддержкой механизма очереди. В случае работы с последовательностями следует посмотреть на распределение их длин.

Из графика видно, что распределение находится в семействе экспоненциальных, это приводит при стратегии паддинга до максимальной длины к увеличению объема входных данных в нейронную сеть на три порядка. Простым решением данной проблемы, ускоряющим обучение в 3 раза, является подход Sequence Bucketing, предлагающий нарезать датасет на группы-бакеты в зависимости от их длины и семплировать батчи из одного бакета. При обучении рекуррентных слоев рекомендуется задавать такой набор параметров сети, при котором поддерживается cudnn-реализация, ускоряющая обучение в этой задаче в пять раз.
Допустим, ваша сеть одновременно учится быстро и не переобучается. Предлагаем проверить, что вы используете все идеи из следующего списка, для получения наилучшего качества:
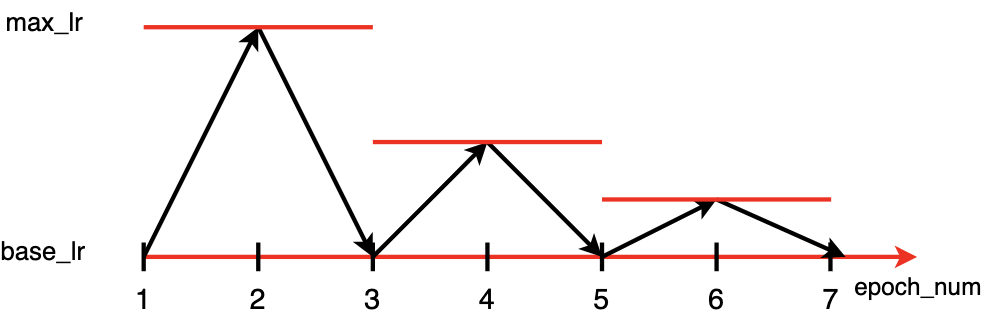
Cyclical Learning Rate благодаря стратегии изменения LR позволяет не переобучаться на первой эпохе за счет низкого базового LR и не застревать в локальных минимумах за счет пилообразной-затухающей стратегии. Гиперпараметры base_lr и max_lr можно задать при помощи алгоритма LRFinder. Дополнительно стоит обратить внимание на One Cycle Policy и Super-Convergence.
Макроэкономические показатели и платежное поведение клиентов могут измениться за N дней, за которые собрана обучающая выборка, относительно последующих K дней, отведенных для теста. В качестве простой стратегии моделирования смещения по времени можно использовать экспоненциальное затухание для весов объектов в зависимости от времени.
Обучив одно дерево, авторы случайного леса и градиентного бустинга не ограничились, в случае обучение нейронных сетей лучше идти по аналогичному сценарию и обучать ансамбль из нейронных сетей, используя различные подмножества объектов для обучения и меняя гиперпараметры архитектуры.
Каждая транзакция описывается большим количеством признаков, отбор признаков может улучишь качество модели.

Можно закрепить все полученные теоретические знания на практике, сделав сабмит в песочнице соревнования.
Продакшн
Транзакции в hadoop обновляются раз в день, поэтому online-обработка не требуется, в худшем случае нужно успевать прогонять pipeline за 24 часа. Pipeline реализован в виде DAG на airflow, состоящем из следующих этапов:
Дозагрузка и агрегация новых данных на pyspasrk. В модели используется история транзакции по каждому пользователю за предыдущий год. Оптимальным сценарием является поддержание исторических предобработанных данных на момент предыдущего запуска модели с добавлением новых данных. На выходе: относительно-компактный parquet-датафрейм.
Предсказание на python с использованием одного из фреймворка: tensorfow, pytorch. На выходе: tsv-таблица, содержащая id и множество полей с предсказаниями моделей.
Выгрузка предсказаний в hadoop и на вход финальной модели.
Нейронные сети, обученные только на транзакционных данных, незначительно проигрывают классическими алгоритмам, использующим явные сигналы из всех доступных банку данных, в том числе транзакции и данные бюро кредитных историй. К счастью, модель имеет ортогональную составляющую и встраивается в бизнес-процесс в виде аддитивной добавки к действующим моделям. Простой подход в смешивании классических методов моделирования с нейросетями позволяет независимо разрабатывать модели и значительно сокращает сроки внедрения.
В заключение подчеркну, что описанный подход в статье можно использовать для классификации любых временных рядов схожей структуры.
Оставайтесь на связи, подписывайтесь на Телеграмм-канале «Нескучный Data Science».
