Из Википедии веб-краулер или паук – бот, который с просматривает всемирную паутину, как правило, с целью индексации. Поисковики и другие веб-сайты используют краулеры для обновления своего содержимого или индексации содержимого других сайтов.
Давайте начнем!!
Metasploit
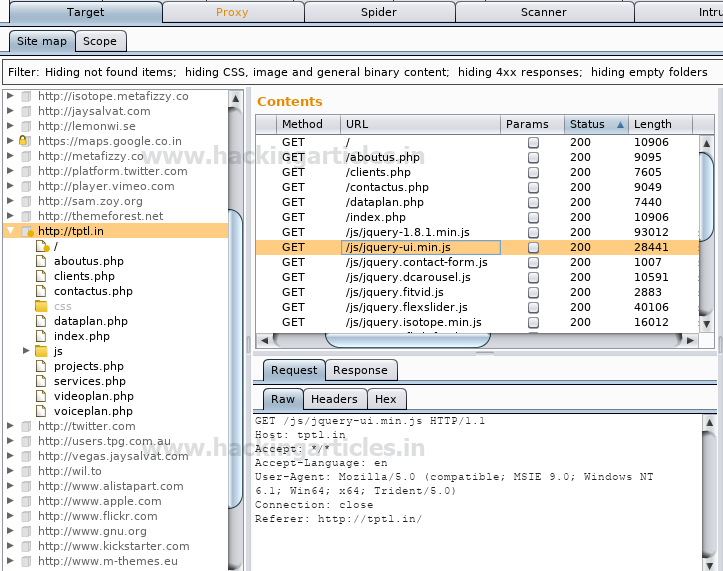
Вспомогательный поисковый модуль Metasploit представляет собой модульный поисковый робот, который будет использоваться вместе с wmap или автономно.
use auxiliary/crawler/msfcrawler
msf auxiliary(msfcrawler) > set rhosts www.example.com
msf auxiliary(msfcrawler) > exploitВидно, что был запущен сканер, с помощью которого можно найти скрытые файлы на любом веб-сайте, например:
Что невозможно сделать вручную при помощи браузера.
Httrack
HTTrack — это бесплатный краулер и автономный браузер с открытым исходным кодом. Он позволяет полностью скачать веб-сайт, рекурсивно строя все каталоги
получая:
- HTML
- изображения
- другие файлы
HTTrack упорядочивает относительную структуру ссылок исходного сайта.
Введем следующую команду внутри терминала
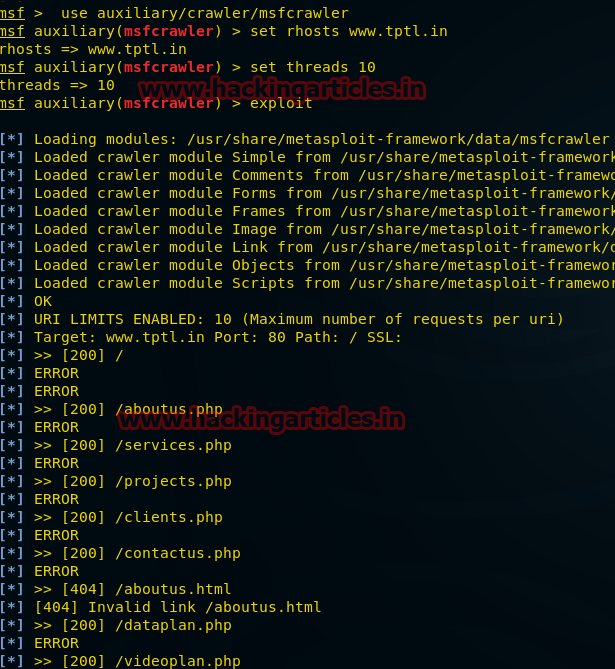
httrack http://tptl.in –O /root/Desktop/fileОн сохранит вывод в заданном каталоге /root/Desktop/file

На скриншоте можно увидеть, что Httrack скачал немало информации о веб-сайте, среди которой много:
- html
- JavaScript файлов
Black Widow
Представляет собой загрузчик веб-сайтов и офлайн браузер. Обнаруживает и отображает подробную информацию для выбранной пользователем веб-страницы. Понятный интерфейс BlackWidow с логическими вкладками достаточно прост, но обилие скрытых возможностей может удивить даже опытных пользователей. Просто введите желаемый URL и нажмите Go. BlackWidow использует многопоточность для быстрой загрузки всех файлов и проверки ссылок. Для небольших веб-сайтов операция занимает всего несколько минут.
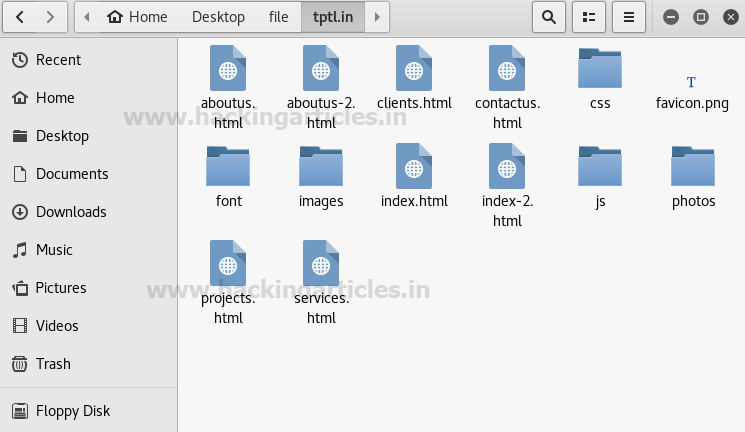
Введем свой URL http://tptl.in в поле адрес и нажмем «Go».

Нажимаем кнопку «Start», расположенную слева, чтобы начать сканирование URL-адресов, а также выбираем папку для сохранения выходного файла. На скриншоте видно, что просматривался каталог C:\Users\RAJ\Desktop\tptl, чтобы сохранить в нем выходной файл.
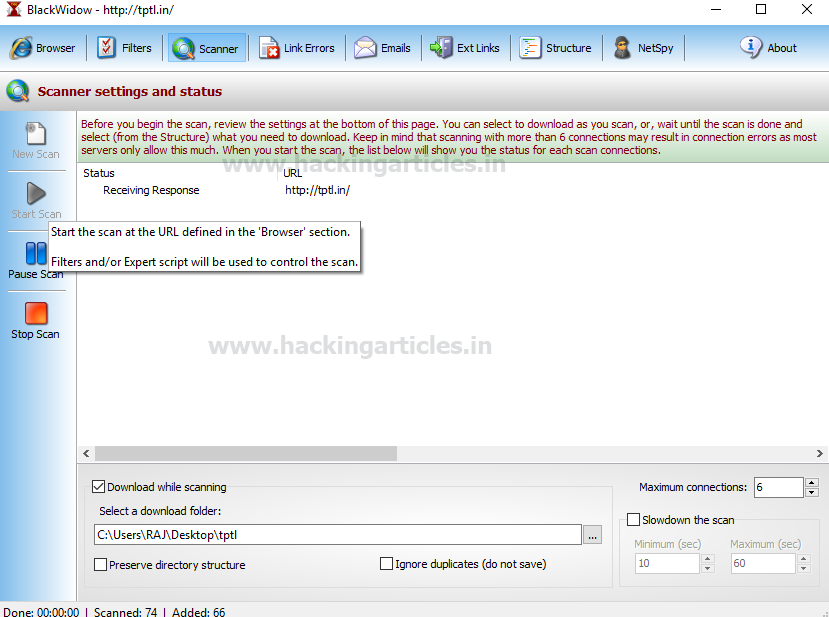
В каталоге tptl теперь будут храниться все данные веб-сайта:
- изображения
- контент
- html
- php
- JavaScript файлы
Website Ripper Copier
Website Ripper Copier (WRC) — это универсальная высокоскоростная программа-загрузчик веб-сайтов. WRC может загружать файлы веб-сайтов на локальный диск для просмотра в автономном режиме, извлекать файлы веб-сайтов определенного размера и типа, такие как:
- Изображения
- Видео
- Аудио
Также WRC может извлекать большое количество файлов в качестве диспетчера загрузки с поддержкой возобновления.
Вдобавок WRC является средством проверки ссылок на сайты, проводником и веб-браузером с вкладками, предотвращающим всплывающие окна. Website Ripper Copier — единственный инструмент для загрузки веб-сайтов, который может:
- возобновлять прерванные загрузки из:
- HTTP
- HTTPS
- FTP-соединений
- получать доступ к сайтам, которые защищены паролями
- поддерживать веб-файлы cookie
- анализировать скрипты
- обновлять полученные сайты или файлы
- запускать более пятидесяти потоков извлечения
Скачать его можно здесь.
Выбираем «websites for offline browsing».
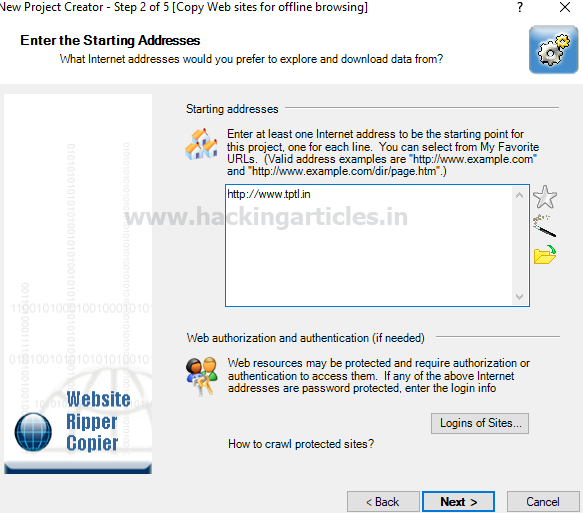
Вводим URL-адрес веб-сайта как http://tptl.in и нажимаем «next».
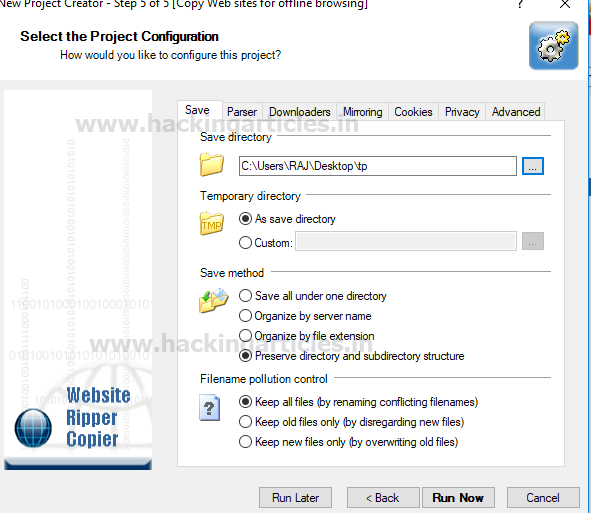
Указываем путь к каталогу, чтобы сохранить результат, после чего жмём «run now».
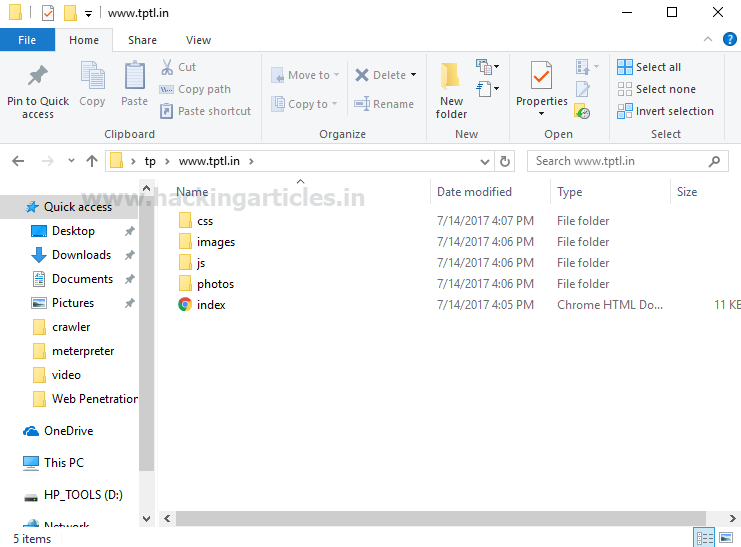
При открытии выбранного каталога tp, внутри него будут файлы:
- CSS
- php
- html
- js
Burp Suite Spider
Burp Suite Spider – это инструмент для автоматического сканирования веб-приложений, более подробно о котором уже писали на habr. В большинстве случаев желательно отображать приложения вручную, но с помощью Burp Spider данный процесс можно автоматизировать, что упростит работу с очень большими приложениями или при нехватке времени.
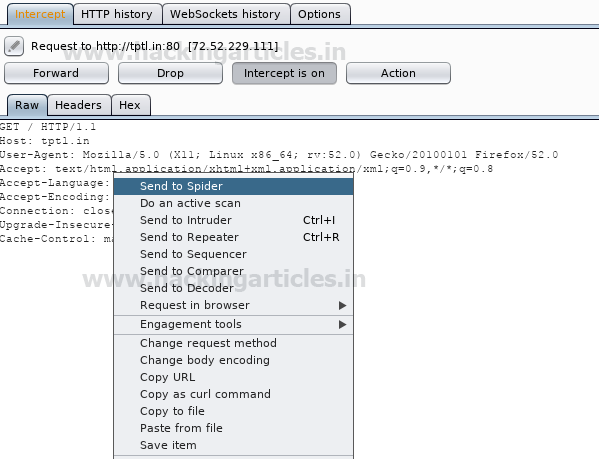
На скриншоте видно, что http-запрос был отправлен "пауку" с помощью контекстного меню.
Веб-сайт был добавлен на карту сайта под целевой вкладкой в качестве новой области для веб-сканирования, в результате которого была собрана информация в форме:
- Php
- Html
- Js