Проблема автоматического поиска текста на изображениях существует достаточно давно, как минимум с начала девяностых годов прошлого века. Они могли запомниться старожилам повсеместным распространением ABBYY FineReader, умеющим переводить сканы документов в их редактируемые варианты.
Сканеры, подключённые к персональным компьютерам, отлично работают в компаниях, но прогресс не стоит на месте, и мир захватили мобильные устройства. Круг задач работы с текстом тоже поменялся. Теперь текст нужно искать не на идеально прямых листах А4 с чёрным текстом на белом фоне, а на различных визитках, красочных меню, вывесках магазинов и много ещё на чём, что человек может встретить в джунглях современного города.

Реальный пример работы нашей нейросети. Картинка кликабельна.
При таком разнообразии условий представления текста рукописные алгоритмы уже не справляются. Здесь на помощь нам приходят нейронные сети с их способностью обобщения. В этом посте мы расскажем о нашем подходе к созданию архитектуры нейросети, которая с хорошим качеством и высокой скоростью детектирует текст на сложных изображениях.
Мобильные устройства накладывают к выбору подхода дополнительные ограничения:
Самое простое решение задачи поиска текста, которое приходит в голову, – это взять самую лучшую сеть со специализирующихся на этой задаче соревнований по ICDAR (International Conference on Document Analysis and Recognition) и делов-то! К сожалению, такие сети добиваются качества за счёт своей громоздкости и сложности вычислений, и годятся только в качестве облачного решения, что не отвечает пунктам 1 и 2 наших требований. А что, если взять большую сеть, работающую хорошо в сценариях, которые нам требуется покрыть, и попробовать её уменьшить? Этот подход уже более интересен.
Baoguang Shi и соавторы в своей нейронной сети SegLink [1] предложили следующее:
Синими квадратами на изображении ниже показаны области видимости пикселей выходных слоёв нейронной сети разных масштабов, которые «видят» хотя бы часть слова.

Примеры сегментов и линков
SegLink в качестве своей основы использует известную архитектуру VGG-16. Предсказание сегментов и линков в ней ведётся на 6 масштабах. В качестве первого эксперимента мы начали с реализации оригинальной архитектуры. Оказалось, что сеть содержит 23 миллиона параметров (весов), которые нужно хранить в файле размером 88 мегабайт. Если создавать приложение на основе VGG, то оно станет одним и первых кандидатов на удаление при нехватке места, да и сам поиск текста работать будет очень медленно, поэтому сети нужно срочно худеть.

Архитектура сети SegLink
Уменьшать размер сети можно просто изменяя в ней количество слоёв и каналов или меняя сами свёртки и связи между ними. Mark Sandler и сотоварищи как раз вовремя подобрали архитектуру в своей сети MobileNetV2 [2] так, что она быстро работает на мобильных устройствах, занимает мало места, да ещё особо не отстаёт по качеству работы от той же VGG. Секрет скорости работы и уменьшения потребления памяти заключается в трёх основных шагах:

Базовый блок MobileNetV2
Используя вышеобозначенные подходы, мы пришли к следующей структуре сети:

Итоговая сеть поиска текста
Шаг свёртки (stride) и базовое количество каналов в слоях (channels) указаны в виде s<stride>c<channels> соответственно. Например, s2c32 означает 32 канала со сдвигом 2. Действительное количество каналов в слоях свёртки получается путём умножения их базового количества на масштабирующий коэффициент α, позволяющий быстро симулировать разную «толщину» сети. Ниже представлена таблица с количеством параметров в сети в зависимости от α.

Тип блока:
В качестве функции активации в блоках используется ReLU6.

Выходной слой имеет 31 канал:
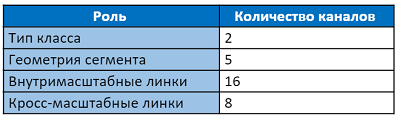
Первые два канала выходного слоя голосуют за принадлежность пикселя к тексту и не тексту. Следующие пять каналов содержат информацию для точного воссоздания геометрии сегмента: сдвиги в вертикальном и горизонтальном направлениях относительно положения пикселя, множители для ширины и высоты (так как сегмент обычно не квадратный) и угол поворота. 16 значений внутриканальных линков указывают, есть ли связь между восемью соседними пикселями в том же масштабе. Последние 8 каналов говорят нам о наличии линков к четырём пикселям предыдущего масштаба (предыдущий масштаб всегда в 2 раза больше). Каждые 2 значения сегментов, внутри- и кросс-масштабных линков нормализованы softmax функцией. Выход к самому первому масштабу не имеет кросс-масштабных линков.
Сеть предсказывает, принадлежат ли конкретный сегмент и его соседи к тексту. Осталось собрать их в слова.
Для начала объединим все сегменты, которые связаны линками. Для этого составим граф, где вершины — все сегменты на всех масштабах, а ребра – линки. Затем найдём связные компоненты графа. Для каждой компоненты теперь можно вычислить охватывающий прямоугольник слова следующим образом:
Итоговое решение получило название FaSTExt: Fast and Small Text Extractor [3]
Сама сеть и её параметры выбирались для хорошей работы на большой внутренней выборке, которая отражает основной сценарий использования приложения на телефоне – навёл камеру на объект с текстом и сделал фото. Оказалось, что большая сеть с α=1 обходит по качеству вариант с α=0,5 всего на 2%. Данной выборки в открытом доступе нет, поэтому для наглядности пришлось обучить сеть на публичной выборке ICDAR2013, в которой условия съёмки схожи с нашими. Выборка очень маленькая, поэтому сеть предварительно обучили на огромном количестве синтетических данных из SynthText in the Wild Dataset. Процесс предобучения занял около 20 дней вычислений для каждого эксперимента на GTX 1080 Ti, поэтому работу сети на публичных данных проверили только для вариантов α=0,75, 1 и 2.
В качестве оптимизатора была использована AMSGrad версия Adam.
Функции ошибки:
По качеству работы сети на целевом сценарии можно сказать, что она не сильно отстаёт от конкурентов по качеству, даже некоторых обгоняет. MS – это тяжелые многомасштабные варианты сетей конкурентов.

* В статье по EAST не было результатов на нужной нам выборке, поэтому эксперимент мы провели сами.
На изображении снизу представлен пример работы FaSTExt на изображениях из ICDAR2013. В первой строке видно, что засвеченные буквы слова ESPMOTO не были размечены, но при этом сеть смогла их найти. Менее ёмкий вариант с α=0,75 справился с мелким текстом хуже, чем более «толстые» версии. На нижней строке снова видны огрехи разметки в выборке с потерянным текстом в отражении. FaSTExt при этом такой текст видит.

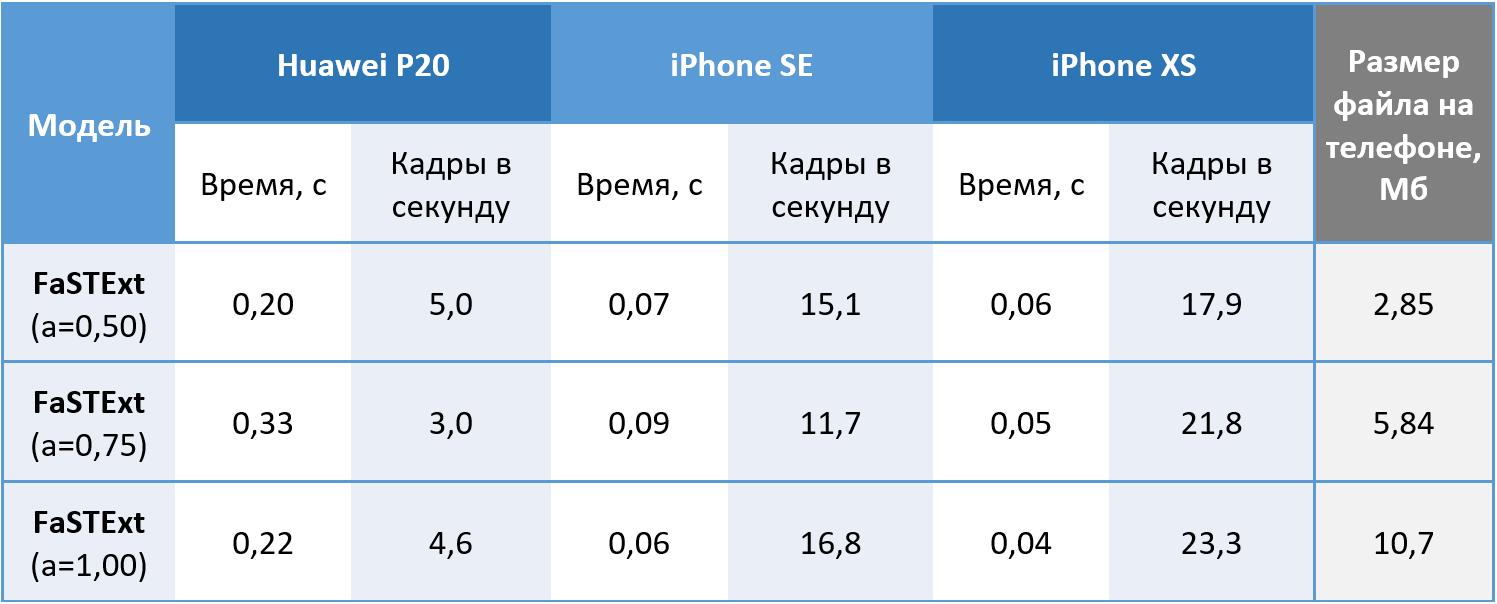
Итак, сеть свои задачи выполняет. Осталось проверить, а можно ли её на самом деле применять в телефонах? Модели запускались на цветных изображениях 512х512 на Huawei P20, используя CPU, и на iPhone SE и iPhone XS, используя GPU, т. к. наша система машинного обучения пока позволяет задействовать GPU только на iOS. Значения получены усреднением 100 запусков. На Android получилось добиться приемлемой для нашей задачи скорости в 5 кадров в секунду. На iPhone XS проявился интересный эффект с уменьшением среднего времени, необходимого для вычислений при усложнении сети. Современный iPhone детектирует текст с минимальной задержкой, что можно назвать победой.

[1] B. Shi, X. Bai и S. Belongie, «Detecting Oriented Text in Natural Images by Linking Segments,» Hawaii, 2017. link
[2] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov и L.-C. Chen, «MobileNetV2: Inverted Residuals and Linear Bottlenecks,» Salt Lake City, 2018. link
[3] A. Filonenko, K. Gudkov, A. Lebedev, N. Orlov и I. Zagaynov, «FaSTExt: Fast and Small Text Extractor,» в 8th International Workshop on Camera-Based Document Analysis & Recognition, Sydney, 2019. link
[4] Z. Zhang, C. Zhang, W. Shen, C. Yao, W. Liu и X. Bai, «Multi-oriented text detection with fully convolutional networks,» Las Vegas, 2016. link
[5] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He и J. Liang, «EAST: An Efficient and Accurate Scene Text Detector,» в 2017 IEEE Conference on Computer Vision and Pattern, Honolulu, 2017. link
[6] M. Liao, Z. Zhu, B. Shi, G.-s. Xia и X. Bai, «Rotation-Sensitive Regression for Oriented Scene Text Detection,» в 2018 IEEE/CVF Conference on Computer Vision and Pattern, Salt Lake City, 2018. link
[7] X. Liu, D. Liang, S. Yan, D. Chen, Y. Qiao и J. Yan, «Fots: Fast oriented text spotting with a unified network,» в 2018 IEEE/CVF Conference on Computer Vision and Pattern, Salt Lake City, 2018. link
Computer Vision Group
Сканеры, подключённые к персональным компьютерам, отлично работают в компаниях, но прогресс не стоит на месте, и мир захватили мобильные устройства. Круг задач работы с текстом тоже поменялся. Теперь текст нужно искать не на идеально прямых листах А4 с чёрным текстом на белом фоне, а на различных визитках, красочных меню, вывесках магазинов и много ещё на чём, что человек может встретить в джунглях современного города.

Реальный пример работы нашей нейросети. Картинка кликабельна.
Основные требования и ограничения
При таком разнообразии условий представления текста рукописные алгоритмы уже не справляются. Здесь на помощь нам приходят нейронные сети с их способностью обобщения. В этом посте мы расскажем о нашем подходе к созданию архитектуры нейросети, которая с хорошим качеством и высокой скоростью детектирует текст на сложных изображениях.
Мобильные устройства накладывают к выбору подхода дополнительные ограничения:
- Не всегда у пользователей есть возможность использовать мобильную сеть для связи с сервером по причине дорогого трафика в роуминге или вопросов секретности. Значит, решения вроде Google Lens здесь не помогут.
- Раз мы ориентируемся на локальную обработку данных, то было бы неплохо, чтобы наше решение:
- Занимало мало памяти;
- Работало быстро, используя технические возможности смартфона.
- Текст может быть повёрнут и находиться на случайном фоне.
- Слова могут быть сильно вытянутыми. У свёрточных нейронных сетей область видимости ядра свёртки обычно не покрывает вытянутое слово целиком, поэтому потребуется какая-то хитрость, чтобы это ограничение обойти.

- Размеры текста на одной фотографии могут быть разными:



Решение
Самое простое решение задачи поиска текста, которое приходит в голову, – это взять самую лучшую сеть со специализирующихся на этой задаче соревнований по ICDAR (International Conference on Document Analysis and Recognition) и делов-то! К сожалению, такие сети добиваются качества за счёт своей громоздкости и сложности вычислений, и годятся только в качестве облачного решения, что не отвечает пунктам 1 и 2 наших требований. А что, если взять большую сеть, работающую хорошо в сценариях, которые нам требуется покрыть, и попробовать её уменьшить? Этот подход уже более интересен.
Baoguang Shi и соавторы в своей нейронной сети SegLink [1] предложили следующее:
- Находить не целые слова сразу (зелёные области на изображении a), а их части, названные сегментами, с предсказанием их поворота, наклона и сдвига. Позаимствуем эту идею.
- Искать сегменты слов нужно сразу на нескольких масштабах, чтобы соответствовать требованию 5. Сегменты показаны зелёными прямоугольниками на изображении b.
- Дабы избавить человека от придумывания, как же эти сегменты объединить, мы просто заставим нейронную сеть предсказывать связи (линки) между относящимися к одному слову сегментами
а. в пределах одного масштаба (красные линии на изображении c)
b. и между масштабами (красные линии на изображении d), решая проблему пункта 4 требований.
Синими квадратами на изображении ниже показаны области видимости пикселей выходных слоёв нейронной сети разных масштабов, которые «видят» хотя бы часть слова.

Примеры сегментов и линков
SegLink в качестве своей основы использует известную архитектуру VGG-16. Предсказание сегментов и линков в ней ведётся на 6 масштабах. В качестве первого эксперимента мы начали с реализации оригинальной архитектуры. Оказалось, что сеть содержит 23 миллиона параметров (весов), которые нужно хранить в файле размером 88 мегабайт. Если создавать приложение на основе VGG, то оно станет одним и первых кандидатов на удаление при нехватке места, да и сам поиск текста работать будет очень медленно, поэтому сети нужно срочно худеть.

Архитектура сети SegLink
Секрет нашей диеты
Уменьшать размер сети можно просто изменяя в ней количество слоёв и каналов или меняя сами свёртки и связи между ними. Mark Sandler и сотоварищи как раз вовремя подобрали архитектуру в своей сети MobileNetV2 [2] так, что она быстро работает на мобильных устройствах, занимает мало места, да ещё особо не отстаёт по качеству работы от той же VGG. Секрет скорости работы и уменьшения потребления памяти заключается в трёх основных шагах:
- Количество каналов с картами признаков на входе в блок уменьшается точечной свёрткой на всю глубину (т. н. bottleneck) без функции активации.
- Классическая свёртка заменена на поканальную сепарабельную свёртку. Для такой свёртки требуется и меньше весов, и меньше вычислений.
- Карты признаков после bottleneck пробрасываются ко входу следующего блока для суммирования без дополнительных свёрток.
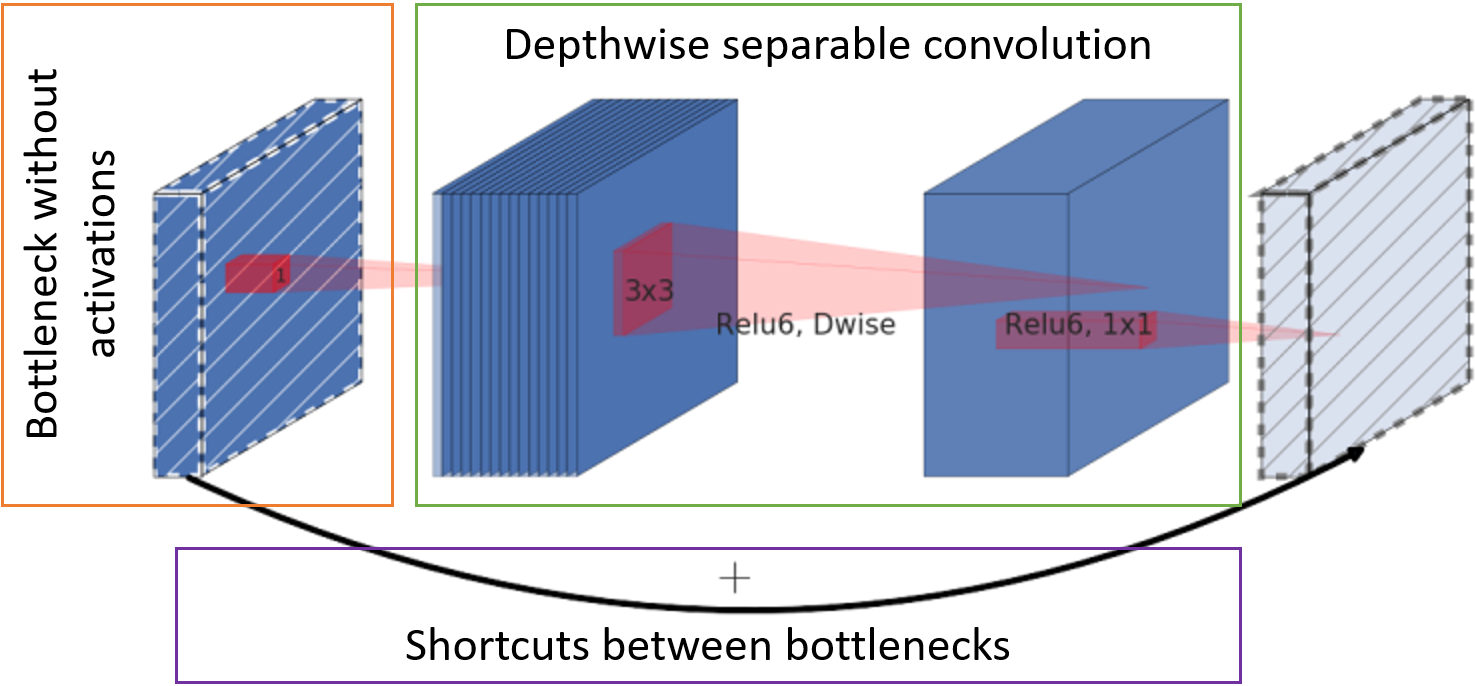
Базовый блок MobileNetV2
Итоговая нейронная сеть
Используя вышеобозначенные подходы, мы пришли к следующей структуре сети:
- Используем сегменты и линки из SegLink
- Заменяем VGG на менее прожорливую MobileNetV2
- Уменьшаем количество масштабов поиска текста с 6 до 5 ради скорости работы

Итоговая сеть поиска текста
Расшифровка значений в блоках архитектуры сети
Шаг свёртки (stride) и базовое количество каналов в слоях (channels) указаны в виде s<stride>c<channels> соответственно. Например, s2c32 означает 32 канала со сдвигом 2. Действительное количество каналов в слоях свёртки получается путём умножения их базового количества на масштабирующий коэффициент α, позволяющий быстро симулировать разную «толщину» сети. Ниже представлена таблица с количеством параметров в сети в зависимости от α.

Тип блока:
- Conv2D – полноценная операция свёртки;
- D-wise Conv — поканальная сепарабельная свёртка;
- Blocks – группа блоков MobileNetV2;
- Output – свёртка для получения выходного слоя. Численные значения типа NxN указывают на размер рецептивного поля пикселя.
В качестве функции активации в блоках используется ReLU6.

Выходной слой имеет 31 канал:
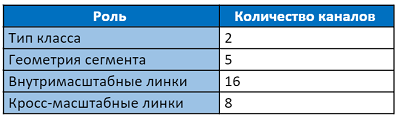
Первые два канала выходного слоя голосуют за принадлежность пикселя к тексту и не тексту. Следующие пять каналов содержат информацию для точного воссоздания геометрии сегмента: сдвиги в вертикальном и горизонтальном направлениях относительно положения пикселя, множители для ширины и высоты (так как сегмент обычно не квадратный) и угол поворота. 16 значений внутриканальных линков указывают, есть ли связь между восемью соседними пикселями в том же масштабе. Последние 8 каналов говорят нам о наличии линков к четырём пикселям предыдущего масштаба (предыдущий масштаб всегда в 2 раза больше). Каждые 2 значения сегментов, внутри- и кросс-масштабных линков нормализованы softmax функцией. Выход к самому первому масштабу не имеет кросс-масштабных линков.
Сборка слов
Сеть предсказывает, принадлежат ли конкретный сегмент и его соседи к тексту. Осталось собрать их в слова.
Для начала объединим все сегменты, которые связаны линками. Для этого составим граф, где вершины — все сегменты на всех масштабах, а ребра – линки. Затем найдём связные компоненты графа. Для каждой компоненты теперь можно вычислить охватывающий прямоугольник слова следующим образом:
- Посчитаем угол поворота слова θ
- Или как среднее значение предсказаний угла поворота сегментов, если их достаточно много,
- Или как угол поворота линии, полученной регрессией по точкам центров сегментов, если сегментов мало.
- Центр слова выбирается как центр масс центральных точек сегментов.
- Развернём все сегменты на -θ, чтобы расположить их горизонтально. Найдём границы слова.
- Левая и правая границы слова выбираются как границы самых левого и правого сегментов соответственно.
- Для получения верхней границы слова сегменты сортируются по высоте расположения верхней грани, отсекаются 20% самых высоких из них, и выбирается значение первого сегмента из списка, оставшегося после фильтрации.
- Нижняя граница получается из самых низких сегментов с отсечением 20% самых низких по аналогии с верхней границей.
- Повернём получившийся прямоугольник обратно на θ.
Итоговое решение получило название FaSTExt: Fast and Small Text Extractor [3]
Время экспериментов!
Детали обучения
Сама сеть и её параметры выбирались для хорошей работы на большой внутренней выборке, которая отражает основной сценарий использования приложения на телефоне – навёл камеру на объект с текстом и сделал фото. Оказалось, что большая сеть с α=1 обходит по качеству вариант с α=0,5 всего на 2%. Данной выборки в открытом доступе нет, поэтому для наглядности пришлось обучить сеть на публичной выборке ICDAR2013, в которой условия съёмки схожи с нашими. Выборка очень маленькая, поэтому сеть предварительно обучили на огромном количестве синтетических данных из SynthText in the Wild Dataset. Процесс предобучения занял около 20 дней вычислений для каждого эксперимента на GTX 1080 Ti, поэтому работу сети на публичных данных проверили только для вариантов α=0,75, 1 и 2.
В качестве оптимизатора была использована AMSGrad версия Adam.
Функции ошибки:
- Кросс-энтропия для классификации сегментов и линков;
- Функция потерь Хьюбера для геометрии сегментов.
Результаты
По качеству работы сети на целевом сценарии можно сказать, что она не сильно отстаёт от конкурентов по качеству, даже некоторых обгоняет. MS – это тяжелые многомасштабные варианты сетей конкурентов.

* В статье по EAST не было результатов на нужной нам выборке, поэтому эксперимент мы провели сами.
На изображении снизу представлен пример работы FaSTExt на изображениях из ICDAR2013. В первой строке видно, что засвеченные буквы слова ESPMOTO не были размечены, но при этом сеть смогла их найти. Менее ёмкий вариант с α=0,75 справился с мелким текстом хуже, чем более «толстые» версии. На нижней строке снова видны огрехи разметки в выборке с потерянным текстом в отражении. FaSTExt при этом такой текст видит.

Итак, сеть свои задачи выполняет. Осталось проверить, а можно ли её на самом деле применять в телефонах? Модели запускались на цветных изображениях 512х512 на Huawei P20, используя CPU, и на iPhone SE и iPhone XS, используя GPU, т. к. наша система машинного обучения пока позволяет задействовать GPU только на iOS. Значения получены усреднением 100 запусков. На Android получилось добиться приемлемой для нашей задачи скорости в 5 кадров в секунду. На iPhone XS проявился интересный эффект с уменьшением среднего времени, необходимого для вычислений при усложнении сети. Современный iPhone детектирует текст с минимальной задержкой, что можно назвать победой.
Список литературы
[1] B. Shi, X. Bai и S. Belongie, «Detecting Oriented Text in Natural Images by Linking Segments,» Hawaii, 2017. link
[2] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov и L.-C. Chen, «MobileNetV2: Inverted Residuals and Linear Bottlenecks,» Salt Lake City, 2018. link
[3] A. Filonenko, K. Gudkov, A. Lebedev, N. Orlov и I. Zagaynov, «FaSTExt: Fast and Small Text Extractor,» в 8th International Workshop on Camera-Based Document Analysis & Recognition, Sydney, 2019. link
[4] Z. Zhang, C. Zhang, W. Shen, C. Yao, W. Liu и X. Bai, «Multi-oriented text detection with fully convolutional networks,» Las Vegas, 2016. link
[5] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He и J. Liang, «EAST: An Efficient and Accurate Scene Text Detector,» в 2017 IEEE Conference on Computer Vision and Pattern, Honolulu, 2017. link
[6] M. Liao, Z. Zhu, B. Shi, G.-s. Xia и X. Bai, «Rotation-Sensitive Regression for Oriented Scene Text Detection,» в 2018 IEEE/CVF Conference on Computer Vision and Pattern, Salt Lake City, 2018. link
[7] X. Liu, D. Liang, S. Yan, D. Chen, Y. Qiao и J. Yan, «Fots: Fast oriented text spotting with a unified network,» в 2018 IEEE/CVF Conference on Computer Vision and Pattern, Salt Lake City, 2018. link
Computer Vision Group
