Комментарии 15
Куда пропадают люди старше 40?
Многие в мобилках стартовали довольно рано, со студенчества, так что сейчас как раз 30-35. И кстати из первоначальной команды многие остались. iOS-разработчик, например (на фото в «мега-кубикле»), который еще с эпохи Symbian с нами, тим-лид — с начала Android-разработки, маркетинг-менеджер, например, сейлз-маркетинг менеджер. Короче, все более-менее на месте, до 40 ещё многие не дожили )
В других отделах типа десктопа или RnD
В других отделах типа десктопа или RnD
Это все прекрасно.
Но есть вопросы:
1. Почему качественные фото страниц, сделанные со смартфона — распознаются на порядок хуже, чем сканы этих же страниц?
Одно только это делает использование смартфона для этих целей бессмысленным.
2. Как работают алгоритмы, если в результате распознавания предпочтение отдается варианту «лапа Римский»?
Но есть вопросы:
1. Почему качественные фото страниц, сделанные со смартфона — распознаются на порядок хуже, чем сканы этих же страниц?
Одно только это делает использование смартфона для этих целей бессмысленным.
2. Как работают алгоритмы, если в результате распознавания предпочтение отдается варианту «лапа Римский»?
1. Если кратко, то прогресс распознавания сканов и накопленный багаж знаний и библиотек дял них гораздо больший, чем фотографий. Плюс всё это с десктопов и С++ тяжело переносить напрямую в мобилки. Но с развитием нейросетей процесс прям радикально упрощается, так что в течение этого года я ожидаю прям ощутимого прогресса.
2. Ну конечно же мы используем словари для проверки, без них будет совсем плохо, но качество распознавание — это такая область обидная. Вот видишь же текст, всё же тут понятно, а тупая машина делает такие дурацкие ошибки, как же так. К сожалению, по большей части машина пока довольно глупая, потому что ориентируется на слова, а не смысл. Но и тут есть прогресс: End-2-End распознавание, которое сейчас тоже набирает обороты, поможет с такими ошибками справиться. Тоже ждём обновлений в этом году.
2. Ну конечно же мы используем словари для проверки, без них будет совсем плохо, но качество распознавание — это такая область обидная. Вот видишь же текст, всё же тут понятно, а тупая машина делает такие дурацкие ошибки, как же так. К сожалению, по большей части машина пока довольно глупая, потому что ориентируется на слова, а не смысл. Но и тут есть прогресс: End-2-End распознавание, которое сейчас тоже набирает обороты, поможет с такими ошибками справиться. Тоже ждём обновлений в этом году.
Плюс всё это с десктопов и С++ тяжело переносить напрямую в мобилки.
Мы пробовали вариант с передачей фото со смартфона в FR14 Corporate — результат был не лучше.
На мой взгляд — там основная проблема с предобработкой изображения.
Желательно, что бы в результате такой обработки удалялся фон (включая просвечивающие через бумагу символы с оборотной стороны страницы и учитывались места сгиба страниц возле переплета и по краям.
Со сканером проще — там есть какой-никакой прижим книги к стеклу (рукой, например :).
При съемке со смартфона это сделать значительно сложнее.
и да, еще раз:
с десктопов и С++ тяжело переносить напрямую в мобилки
Как там дела с ABBYY FineReader for Mac? Уже добавили OCR-редактор?
(в моей версии его нет)
машина пока довольно глупая, потому что ориентируется на слова, а не смысл
Возможно, это неправильное сравнение — но у Гугла переводчик уже учитывает контекст предложения.
Вот мы с вами в одну сторону думаем. Предобработки хорошие — это прям № 1 приоритет. И тут тоже нейросеточки сильно помогают.
По FineReader Mac работы довольно много ещё. Но команда там тоже увеличивается, так что ждём.
А по поводу смысла — у нас тоже есть волшебные собственные NLP-технологии, которые надо правильно подрядить помогать распознаванию. К сожалению, пока сложностей много. Мы рассчитываем на кардинальное улучшение базового OCR в первую очередь, а потом уже будем добавлять морфологию.
По FineReader Mac работы довольно много ещё. Но команда там тоже увеличивается, так что ждём.
А по поводу смысла — у нас тоже есть волшебные собственные NLP-технологии, которые надо правильно подрядить помогать распознаванию. К сожалению, пока сложностей много. Мы рассчитываем на кардинальное улучшение базового OCR в первую очередь, а потом уже будем добавлять морфологию.
Предобработки хорошие — это прям № 1 приоритет
Необходимость хорошей предобработки видна буквально невооруженным глазом )
После неудачного распознавания «в лоб» — я отправил снимок в графический редактор, где убрал все лишнее (выходящее за пределы распознаваемого текста)
Этот вариант был распознан с заметно меньшим количеством ошибок — что, в общем, странно, так как области распознавания в обоих случаях были выделены одни и те же.
(Полагаю, что «обрезание» сильно помогло программе предобработки изображения)
Похоже на то, что в новую версию FineReader следует дополнить элементарными функциями графического редактора — при использовании Редактора изображений добавить возможность вручную обрезать изображение по выделению, убрать/вернуть цвет, повысить яркость и контрастность отдельной страницы — и дать возможность после всего этого произвести предобработку изображения.
При сканировании офисных документов формата А4 без такого редактирования вполне можно обойтись, при обработке снимков со смартфона — уже нет.
Интересная идея. Передам команде FineReader
В FineReader OCR редакторе есть Редактор изображений, в котором доступны перечисленные опции. Их можно применять автоматически или вручную, на отдельную страницу, четные/нечетные или на все страницы проекта. Прикладываю скрины, как войти в Редактор + пара примеров результата.
вход в редактор:
все опции:
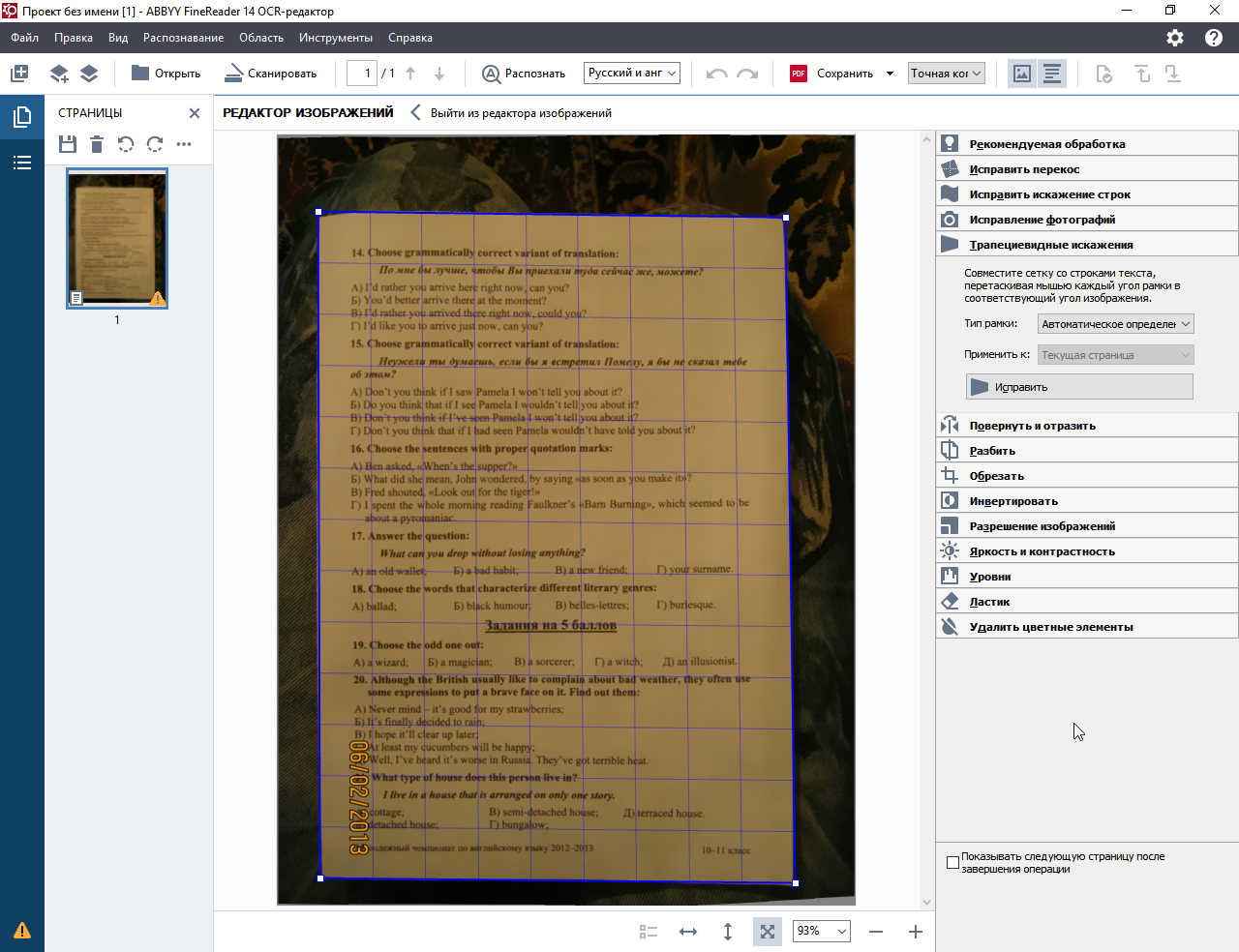
кроп:
цвет фона до:
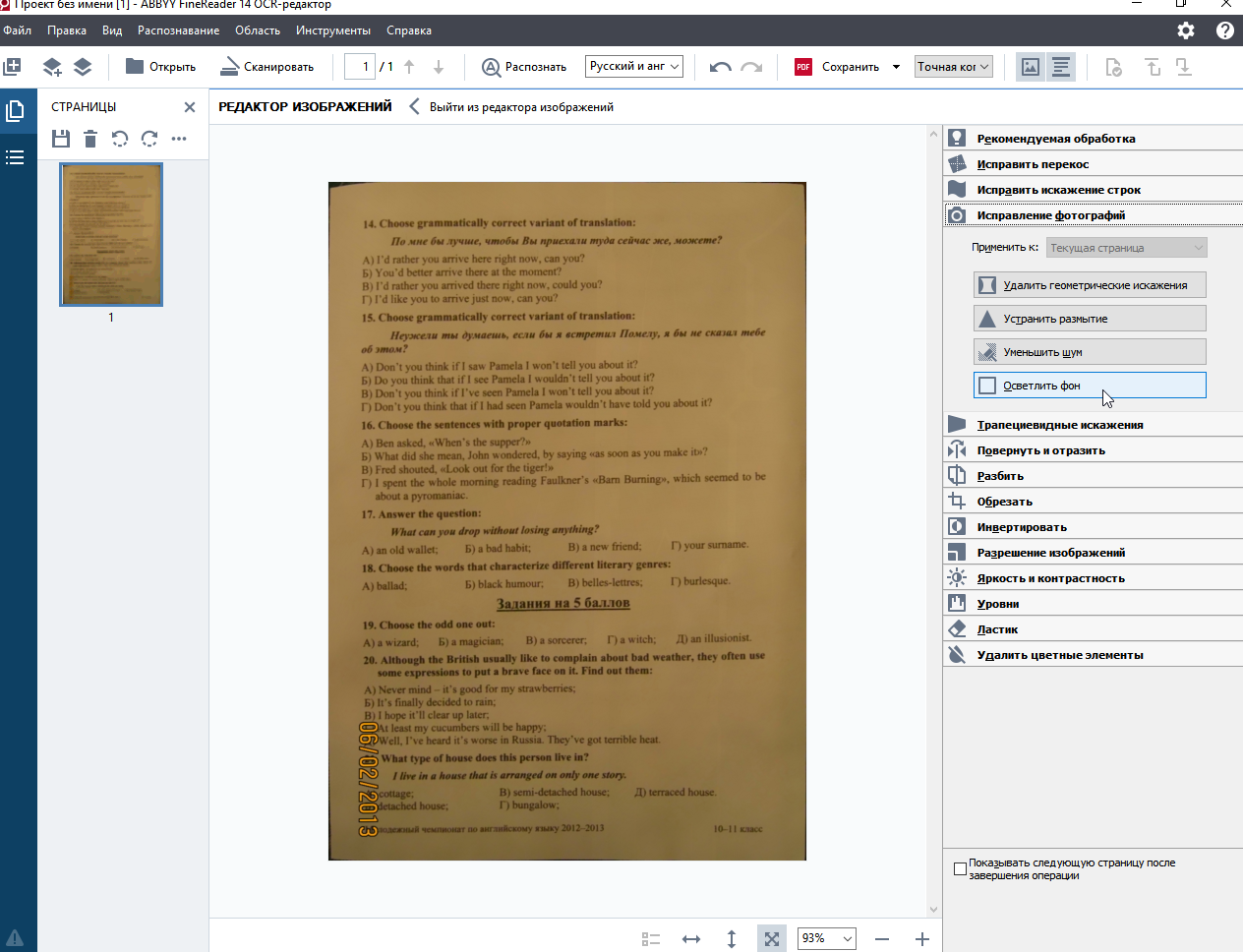
цвет фона после:
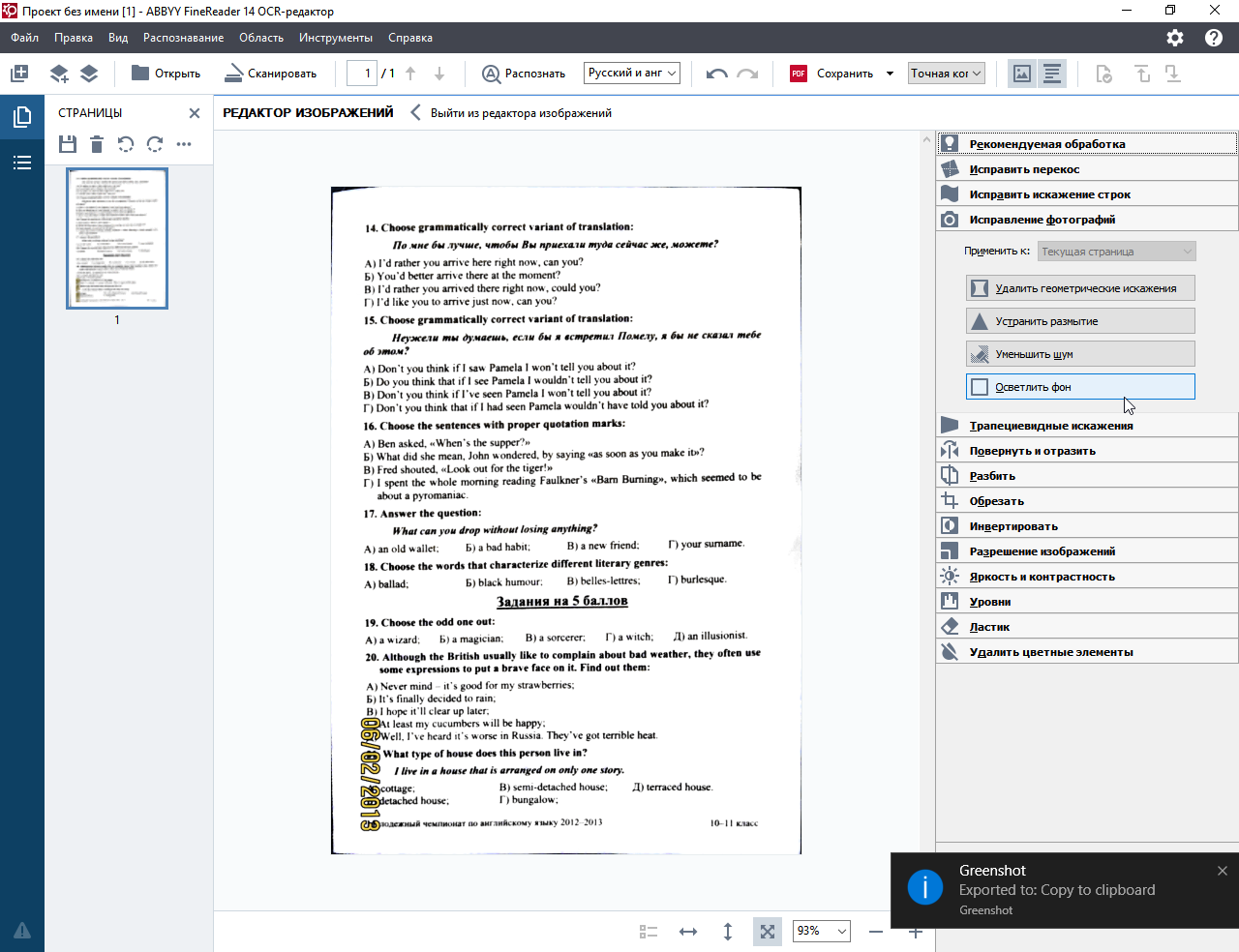
Это подходит для вашей задачи, или вы имели в виду другое?
вход в редактор:

все опции:

кроп:

цвет фона до:
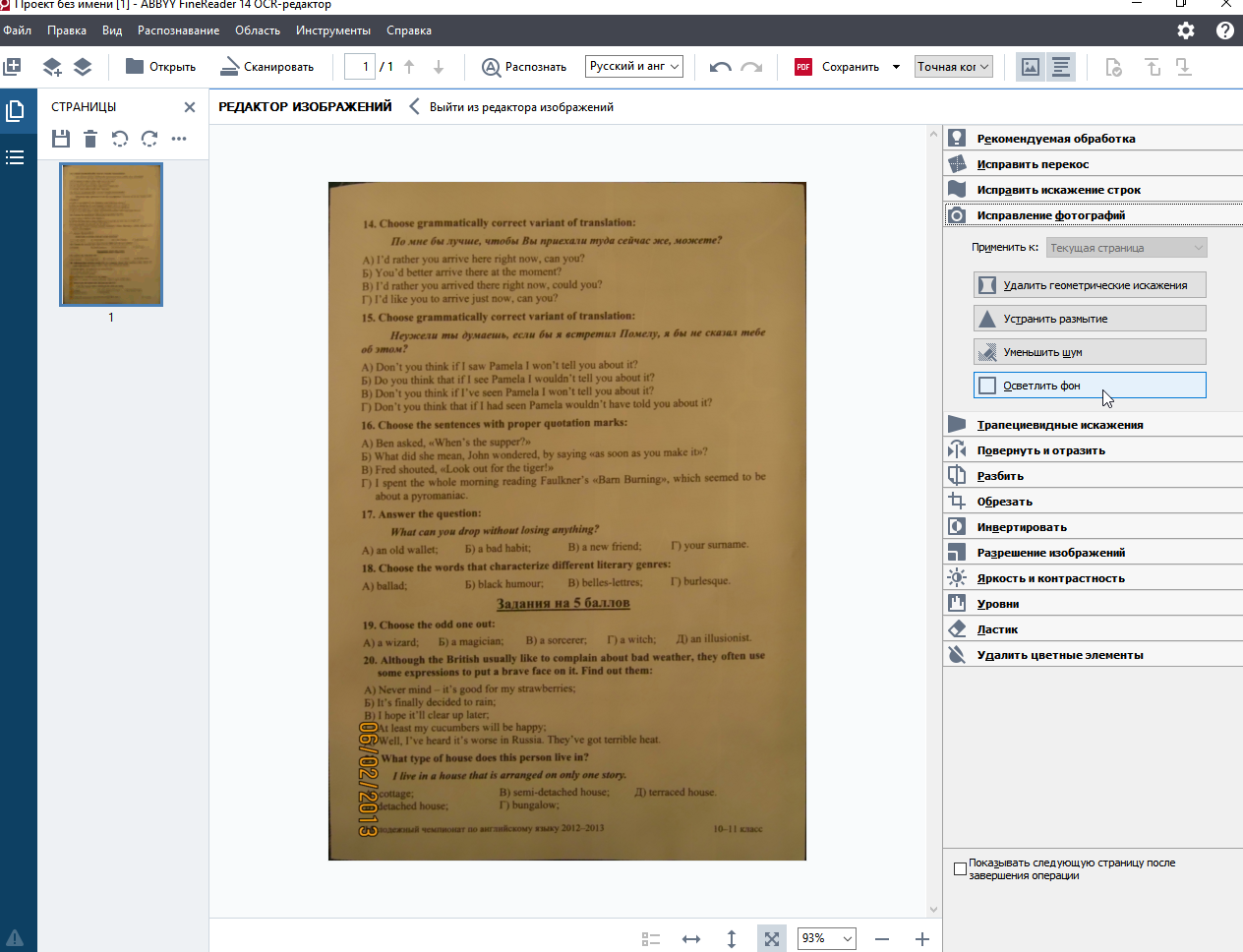
цвет фона после:

Это подходит для вашей задачи, или вы имели в виду другое?
Блин, опечаток-то опечаток… Бежал на демо, не успел нормально посмотреть. Не судите строго )
А Compreno вы уже закопали?
Compreno живее всех живых! Эта технология вошла в состав NLP-возможностей нашей флагманской FlexiCapture. Она например Сбербанку помогает вот в этом кейсе www.abbyy.com/ru-ru/news/2019/01/sberbank-ispolzuet-intellektualnye-tekhnologii-abbyy-dlya-monitoringa-kreditnyh-riskov
А что случилось с Lingvo для iOS?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Зачем разработчикам ABBYY Mobile нейросети, музей и Random Coffee