
Каждая следующая версия ABBYY FineReader становится всё более интуитивно понятной. В частности, в последние версии включена система встроенных сценариев, которые дают возможность выполнить стандартные последовательности действий за несколько щелчков мышью. Так мы стараемся облегчить работу с программой для большинства наших пользователей. И, тем не менее, FineReader обладает рядом возможностей, которые не лежат на поверхности, но могут быть полезны пользователям «продвинутым». О нескольких таких возможностях мы расскажем в этом посте.
Начнем с функции создания языков в ABBYY FineReader 10 Professional Edition. Для чего и кому это нужно? В основном, для тех, кто занимается распознаванием текста, содержащего много специфических конструкций, например, артикулов, небуквенных символов, аббревиатур или цифр. На первый взгляд кажется, что такие случаи бывают редко, но мы довольно часто сталкиваемся с подобными вопросами от наших пользователей. Например, интересный случай был описан на форуме FineReader, где пользователю нужно было распознать книгу по покеру, в которой, разумеется, встречались символы-масти. Чтобы решить проблему с корректным отображением мастей, мы посоветовали создать в программе новый язык. Эта процедура облегчает работу с подобными документами и значительно сокращает время их обработки. Сам процесс создания не займет много времени и не требует специфических знаний, здесь просто нужно быть внимательным. Чтобы вам легче было разобраться, мы покажем, как это делается.
Основной диалог, в котором настраиваются параметры нового языка, вызывается из меню Сервис -> Редактор языков нажатием кнопки Новый…. Язык создается на основе одного из существующих, поэтому перед тем как редактировать свойства нового языка, выберите тот, который будет принят за основу. Если текст, который вы будете распознавать, на русском языке, его и стоит выбрать в качестве базового. Открываем окно Свойства языка.
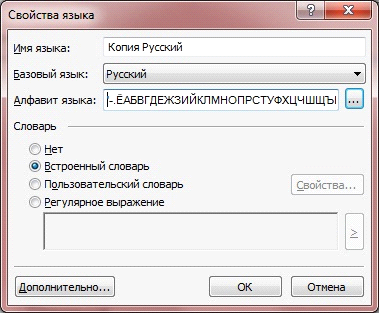 "
"Нетрудно догадаться, что начинать данный процесс придется с создания алфавита. Нажимаем кнопку редактирования и попадаем в диалог с широкими возможностями для создания собственного алфавита: здесь можно добавить любые символы из более чем шестидесяти наборов – от привычной кириллицы до специальных математических и декоративных. Находим нужные символы, добавляем их в алфавит и закрываем окно редактирования.
Кроме возможности добавления символов в алфавит, существует обратная процедура – исключение ненужных символов. Например, если вы распознаете книгу 60-70 годов выпуска, то имеет смысл убрать из языка распознавания такие символы, как & # @. Так мы поможем программе исключить ненужные варианты при распознавании нечётко пропечатанных букв.
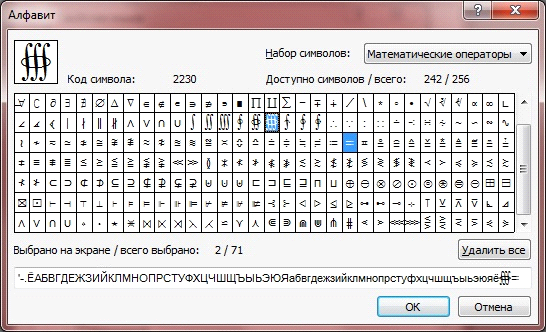
После того как работа с алфавитом завершена, нужно выбрать словарь, который будет использоваться системой при распознавании и проверке, и указать дополнительные свойства (например, символы, которые могут встречаться в начале и конце слова и т.д.). Теперь FineReader готов к распознаванию вашего текста.
Когда вы создавали новый язык, наверняка заметили вторую опцию, доступную в диалоге Редактор языков – «Создать новую группу языков». Пригодится она тем, кому приходится распознавать документы, тексты которых составлены одновременно на нескольких нетрадиционных языках одновременно. Например, вам внезапно понадобилось распознать научную диссертацию, составленную на языках аймара, конго и зулу…
Сразу напомню, что в программе есть и предопределённые группы языков. Они используются для распознания документов, составленных на двух-трех распространенных языках, например, на русском и английском, или на английском, немецком и французском и т.д. Для таких документов создавать новую группу каждый раз совсем не обязательно. А если вам вдруг понадобится сочетание китайского упрощенного и простых химических формул, или английского и того, который вы ранее создали сами, то вам сюда. Смело устанавливайте флажок на опцию «Создать новую группу языков» и из предложенного списка выбирайте и добавляйте нужные вам языки. Не забудьте придумать оригинальное название для вновь созданной группы – тогда вы сможете использовать ее в следующий раз.
Следующая возможность – «Распознавание с обучением» – пригодится, когда нужно распознать текст, напечатанный декоративным шрифтом. В таких случаях составить алфавит из имеющихся символов просто физически невозможно, но зато вы сможете создать свой эталон букв, которые будут использованы в тексте, и с их помощью распознать декоративный шрифт. Еще эту возможность удобно использовать при распознавании текста с большим количеством сложных математических формул и для больших объемов текста плохого качества.
Если вы все же решились на создание эталона, отправляйтесь в меню Сервис -> Опции на вкладку Распознать. Здесь в группе Обучение нужно установить флажок в положение Распознать с обучением и нажать кнопку Эталоны, которая вызывает диалог создания нового эталона. Введите название для нового эталона, закройте все открытые диалоги и начинайте процесс распознавания. Как только встретится незнакомый символ, откроется диалог Ручное обучение эталона с изображением этого символа.
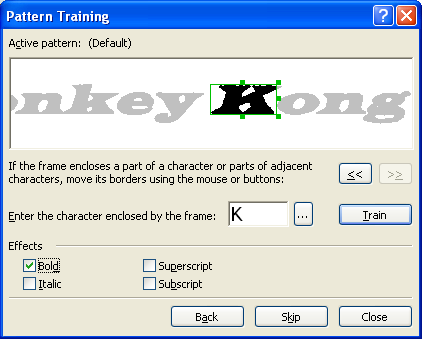
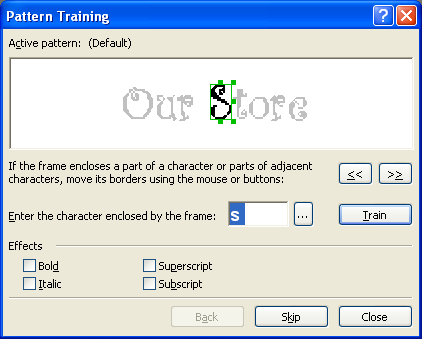
В результате распознавания вы получите именно те значения незнакомых символов, которым научили FineReader сами. Вот таким нехитрым способом происходит обучение FineReader. Кстати, созданные эталоны можно сохранять – тогда вы сможете их использовать их несколько раз, а также редактировать при необходимости.
Сегодня мы рассказали вам о двух возможностях FineReader, о которых вы, возможно, еще не знали и которые, быть может, окажутся вам полезными. Эти и другие интересные функции FineReader описаны в справке, поэтому рекомендуем вам иногда туда заглядывать.
Алиса Рахманова,
Департамент продуктов для распознавания текстов
