На прошлой неделе мы выпустили очередную версию OCR SDK – продукта для встраивания технологий распознавания текста в различные приложения. Уже в течение многих лет выпуск пользовательского коробочного FineReader’a мы дополняем тиражом кружек и маек выпуском соответствующих технологий в виде SDK – FineReader Engine (для краткости его зовем FRE).
Под катом я расскажу об улучшениях нового FRE по сравнению с предыдущими версиями.
Разрабатывая новую версию, мы ставим перед собой почти олимпийские цели – точнее, быстрее, функциональнее. Над точностью и функциональностью мы активно работали в девятой версии FineReader Engine и в этом отношении достигли заметных улучшений.
В десятой версии на первый план вышла скорость. К выпуску нам удалось ускорить Fast Mode (специальный скоростной режим распознавания) в 1,5–2 раза для большинства европейских языков. При этом рост скорости произошел не в ущерб качеству, точность распознавания в Fast Mode осталась в среднем на прежнем уровне. Для русского языка скорость возросла в среднем на 44%. Эти цифры получены в результате внутреннего тестирования на пакетах, содержащих основные типы офисных документов.
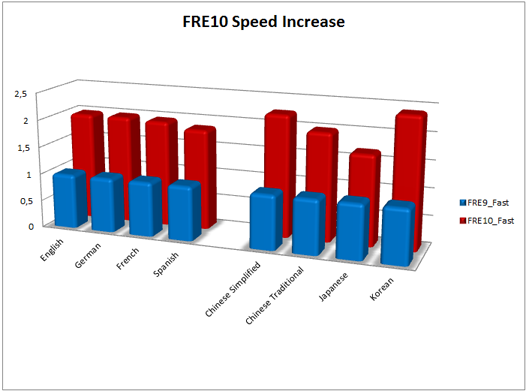
Относительный рост скорости для каждого языка по сравнению с результатами FRE 9.0 (выпуск 21 октября 2008 г.)
Для основных азиатских языков – китайского, японского и корейского – главной целью по-прежнему была точность. Число ошибок при распознавании документов на этих языках сократилось в среднем на 30-40%. Кроме этого на графике видно существенное повышение скорости.
Было сделано и много менее очевидных улучшений.
Новая бинаризация – преобразование цветных и полутоновых изображений в черно-белые. Это необходимый этап подготовки документов к распознаванию, от него зависит, удастся ли на скане мятого листа со следами от пальцев распознать бледный текст. Бинаризация стала значительно лучше, это одна из причин, почему при увеличении скорости не пострадало качество.
Camera OCRTM – набор специальных преобразований для улучшения качества распознавания текста на сфотографированных документах. Среди них:
– исправление трапециевидных искажений, которые появляются при съемке под углом,
– устранение смаза на фотографиях – характерного дефекта при съемке без штатива,
– сглаживание ISO-шума – множества разноцветных точек на фотографии, появляющихся при высокой чувствительности фотоаппарата в условиях недостаточной освещенности.
Появились новые возможности ADRTTM – восстановление структуры документа (document map) и оглавления (table of contents – TOC) по заголовкам, автоматическое создание стилей, распознавание подписей к картинкам, задание специального стиля для подписи и объединение картинки и подписи в единый объект.
Очень важное улучшение – повышение понятности, доступности продукта и облегчение работы с ним. OCR SDK – это многофункциональный инструмент с огромным API, позволяющим настраивать большое число параметров.
Пользователи решают самые разные задачи. Кто-то разрабатывает системы для сканирования книг из библиотеки в PDF с возможностью контекстного поиска, кто-то реализует автоматическую регистрацию документов в СЭД на основе распознавания штрих-кодов, а кто-то развивает на нем собственные технологии для извлечения данных, используя функцию распознавания и верификации текста.
Очевидно, что для разных задач – разные требования к функционалу SDK и качеству технологий. В одном случае на первом месте качество и размер получаемых PDF файлов, в другом – точность распознавания текста илиштрих-кодов . Следовательно, требуются разные настройки для решения разных задач.
Чтобы упростить настройку продукта, мы создали ряд профилей, содержащих оптимальные значения параметров для решения конкретных задач. Эта идея отражена на главном «вижуале» продукта:

Достаточно просто выбрать подходящий профиль – и можно работать.
Кроме этого была существенно доработана справка по продукту, она стала более структурированной и полной.
Мы надеемся, что все это поможет быстрее и легче интегрировать FineReader Engine в приложения и получать еще более качественные результаты распознавания.
Версию FRE10 для Linux мы планируем выпустить примерно через год.
Семён Сергунин
Департамент технологических продуктов
Под катом я расскажу об улучшениях нового FRE по сравнению с предыдущими версиями.
Разрабатывая новую версию, мы ставим перед собой почти олимпийские цели – точнее, быстрее, функциональнее. Над точностью и функциональностью мы активно работали в девятой версии FineReader Engine и в этом отношении достигли заметных улучшений.
В десятой версии на первый план вышла скорость. К выпуску нам удалось ускорить Fast Mode (специальный скоростной режим распознавания) в 1,5–2 раза для большинства европейских языков. При этом рост скорости произошел не в ущерб качеству, точность распознавания в Fast Mode осталась в среднем на прежнем уровне. Для русского языка скорость возросла в среднем на 44%. Эти цифры получены в результате внутреннего тестирования на пакетах, содержащих основные типы офисных документов.
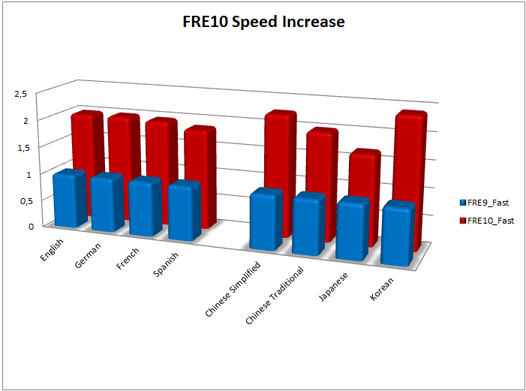
Относительный рост скорости для каждого языка по сравнению с результатами FRE 9.0 (выпуск 21 октября 2008 г.)
Для основных азиатских языков – китайского, японского и корейского – главной целью по-прежнему была точность. Число ошибок при распознавании документов на этих языках сократилось в среднем на 30-40%. Кроме этого на графике видно существенное повышение скорости.
Было сделано и много менее очевидных улучшений.
Новая бинаризация – преобразование цветных и полутоновых изображений в черно-белые. Это необходимый этап подготовки документов к распознаванию, от него зависит, удастся ли на скане мятого листа со следами от пальцев распознать бледный текст. Бинаризация стала значительно лучше, это одна из причин, почему при увеличении скорости не пострадало качество.
Camera OCRTM – набор специальных преобразований для улучшения качества распознавания текста на сфотографированных документах. Среди них:
– исправление трапециевидных искажений, которые появляются при съемке под углом,
– устранение смаза на фотографиях – характерного дефекта при съемке без штатива,
– сглаживание ISO-шума – множества разноцветных точек на фотографии, появляющихся при высокой чувствительности фотоаппарата в условиях недостаточной освещенности.
Появились новые возможности ADRTTM – восстановление структуры документа (document map) и оглавления (table of contents – TOC) по заголовкам, автоматическое создание стилей, распознавание подписей к картинкам, задание специального стиля для подписи и объединение картинки и подписи в единый объект.
Очень важное улучшение – повышение понятности, доступности продукта и облегчение работы с ним. OCR SDK – это многофункциональный инструмент с огромным API, позволяющим настраивать большое число параметров.
Пользователи решают самые разные задачи. Кто-то разрабатывает системы для сканирования книг из библиотеки в PDF с возможностью контекстного поиска, кто-то реализует автоматическую регистрацию документов в СЭД на основе распознавания штрих-кодов, а кто-то развивает на нем собственные технологии для извлечения данных, используя функцию распознавания и верификации текста.
Очевидно, что для разных задач – разные требования к функционалу SDK и качеству технологий. В одном случае на первом месте качество и размер получаемых PDF файлов, в другом – точность распознавания текста или
Чтобы упростить настройку продукта, мы создали ряд профилей, содержащих оптимальные значения параметров для решения конкретных задач. Эта идея отражена на главном «вижуале» продукта:

Достаточно просто выбрать подходящий профиль – и можно работать.
Кроме этого была существенно доработана справка по продукту, она стала более структурированной и полной.
Мы надеемся, что все это поможет быстрее и легче интегрировать FineReader Engine в приложения и получать еще более качественные результаты распознавания.
Версию FRE10 для Linux мы планируем выпустить примерно через год.
Семён Сергунин
Департамент технологических продуктов
