Как известно, компания SAP предлагает полный спектр программного обеспечения, как для ведения транзакционных данных, так и для обработки этих данных в системах анализа и отчетности. В частности платформа SAP Business Warehouse (SAP BW) представляет собой инструментарий для хранения и анализа данных, обладающий широкими техническими возможностями. При всех своих объективных преимуществах система SAP BW обладает одним значительным недостатком. Это высокая стоимость хранения и обработки данных, особенно заметная при использовании облачной SAP BW on Hana.
А что если в качестве хранилища начать использовать какой-нибудь non-SAP и желательно OpenSource продукт? Мы в Х5 Retail Group остановили свой выбор на GreenPlum. Это конечно решает вопрос стоимости, но при этом сразу появляются вопросы, которые при использовании SAP BW решались практически по умолчанию.

В частности, каким образом забирать данные из систем источников, которые в большинстве своем являются решениями SAP?
«HR-метрики» стал первым проектом, в котором необходимо было решить эту проблему. Нашей целью было создание хранилища HR-данных и построение аналитической отчетности по направлению работы с сотрудниками. При этом основным источником данных является транзакционная система SAP HCM, в которой ведутся все кадровые, организационные и зарплатные мероприятия.
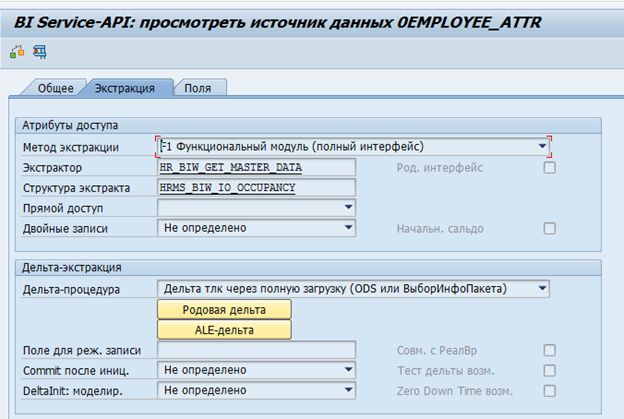
В SAP BW для SAP-систем существуют стандартные экстракторы данных. Эти экстракторы могут автоматически собирать необходимые данные, отслеживать их целостность, определять дельты изменений. Вот, например, стандартный источник данных по атрибутам сотрудника 0EMPLOYEE_ATTR:
Результат экстракции данных из него по одному сотруднику:

При необходимости такой экстрактор может быть модифицирован под собственные требования или может быть создан свой собственный экстрактор.
Первой возникла идея о возможности их переиспользования. К сожалению, это оказалось неосуществимой задачей. Большая часть логики реализована на стороне SAP BW, и безболезненно отделить экстрактор на источнике от SAP BW не получилось.
Стало очевидно, что потребуется разработка собственного механизма извлечения данных из SAP систем.
Для понимания требований к такому механизму, первоначально нужно определить какие именно данные нам потребуются.
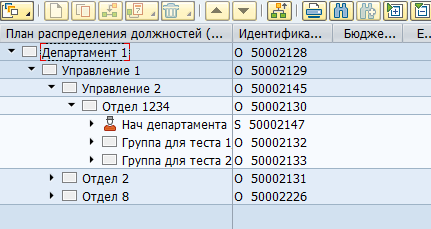
Большинство данных в SAP HCM хранится в плоских SQL таблицах. На основании этих данных приложения SAP визуализируют пользователю оргструктуры, сотрудников и прочую HR информацию. Например, вот так в SAP HCM выглядит оргструктура:
Физически такое дерево хранится в двух таблицах — в hrp1000 объекты и в hrp1001 связи между этими объектами.
Объекты «Департамент 1» и «Управление 1»:

Связь между объектами:

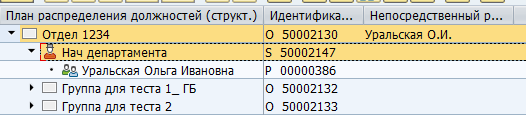
Как типов объектов, так и типов связи между ними может быть огромное количество. Существуют как стандартные связи между объектами, так и кастомизированные для собственных специфичных нужд. Например, стандартная связь B012 между оргединицей и штатной должностью указывает на руководителя подразделения.
Отображение руководителя в SAP:
Хранение в таблице БД:

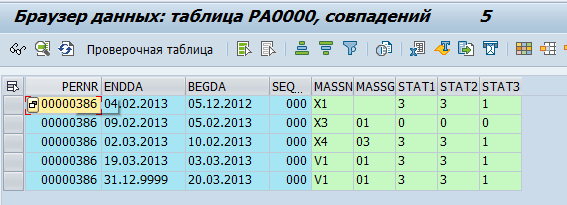
Данные по сотрудникам хранятся в таблицах pa*. Например, данные о кадровых мероприятиях по сотруднику хранятся в таблице pa0000
Мы приняли решение, что GreenPlum будет забирать «сырые» данные, т.е. просто копировать их из SAP таблиц. И уже непосредственно в GreenPlum они будут обрабатываться и преобразовываться в физические объекты (например, Отдел или Сотрудник) и метрики (например, среднесписочная численность).
Было определено порядка 70 таблиц, данные из которых необходимо передавать в GreenPlum. После чего мы приступили к проработке способа передачи этих данных.
SAP предлагает достаточно большое количество механизмов интеграции. Но самый простой способ – прямой доступ к базе данных запрещен из-за лицензионных ограничений. Таким образом, все интеграционные потоки должны быть реализованы на уровне сервера приложений.
Следующей проблемой было отсутствие данных об удаленных записях в БД SAP. При удалении строки в БД, она удаляется физически. Т.е. формирование дельты изменений по времени изменения не представлялось возможным.
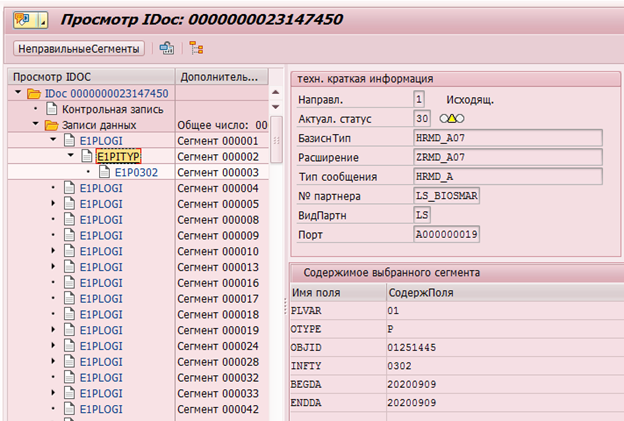
Конечно, в SAP HCM есть механизмы фиксация изменений данных. Например, для последующей передачи в системы получатели существуют указатели изменений(change pointer), которые фиксируют любые изменения и на основании которых формируются Idoc (объект для передачи во внешние системы).
Пример IDoc изменения инфотипа 0302 у сотрудника с табельным номером 1251445:
Или ведение логов изменений данных в таблице DBTABLOG.
Пример лога удаления записи с ключом QK53216375 из таблицы hrp1000:

Но эти механизмы доступны не для всех необходимых данных и их обработка на уровне сервера приложений может потреблять достаточно много ресурсов. Поэтому массовое включение логирования на все необходимые таблицы может привести к заметной деградации производительности системы.
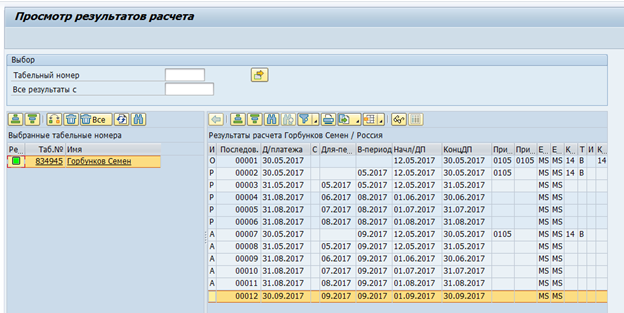
Следующей серьезной проблемой были кластерные таблицы. Данные оценки времени и расчета зарплаты в RDBMS версии SAP HCM хранятся в виде набора логических таблиц по каждому сотруднику за каждый расчет. Эти логические таблицы в виде двоичных данных хранятся в таблице pcl2.
Кластер расчета заработной платы:
Данные из кластерных таблиц невозможно считать SQL командой, а требуется использование макрокоманд SAP HCM или специальных функциональных модулей. Соответственно, скорость считывания таких таблиц будет достаточно низка. С другой стороны, в таких кластерах хранятся данные, которые необходимы только раз в месяц – итоговый расчет заработной платы и оценка времени. Так что скорость в этом случае не столь критична.
Оценивая варианты с формированием дельты изменения данных, решили так же рассмотреть вариант с полной выгрузкой. Вариант каждый день передавать гигабайты неизменных данных между системами не может выглядеть красиво. Однако он имеет и ряд преимуществ – нет необходимости как реализации дельты на стороне источника, так и реализация встраивания этой дельты на стороне приемника. Соответственно, уменьшается стоимость и сроки реализации, и повышается надежность интеграции. При этом было определено, что практически все изменения в SAP HR происходят в горизонте трех месяцев до текущей даты. Таким образом, было принято решение остановиться на ежедневной полной выгрузке данных из SAP HR за N месяцев до текущей даты и на ежемесячной полной выгрузке. Параметр N зависит от конкретной таблицы
и колеблется от 1 до 15.
Для экстракции данных была предложена следующая схема:

Внешняя система формирует запрос и отправляет его в SAP HCM, там этот запрос проверяется на полноту данных и полномочия на доступ к таблицам. В случае успешной проверки, в SAP HCM отрабатывает программа, собирающая необходимые данные и передающая их в интеграционное решение Fuse. Fuse определяет необходимый топик в Kafka и передает данные туда. Далее данные из Kafka передаются в Stage Area GP.
Нас в данной цепочке интересует вопрос извлечения данных из SAP HCM. Остановимся на нем подробнее.
Схема взаимодействия SAP HCM-FUSE.

Внешняя система определяет время последнего успешного запроса в SAP.
Процесс может быть запущен по таймеру или иному событию, в том числе может быть установлен таймаут ожидания ответа с данными от SAP и инициация повторного запроса. После чего формирует запрос дельты и отправляет его в SAP.
Данные запроса передаются в body в формате json.
Метод http: POST.
Пример запроса:

Сервис SAP выполняет контроль запроса на полноту, соответствие текущей структуре SAP, наличие разрешения доступа к запрошенной таблице.
В случае ошибок сервис возвращает ответ с соответствующим кодом и описанием. В случае успешного контроля он создает фоновый процесс для формирования выборки, генерирует и синхронно возвращает уникальный id сессии.
Внешняя система в случае ошибки регистрирует ее в журнале. В случае успешного ответа передает id сессии и имя таблицы по которой был сделан запрос.
Внешняя система регистрирует текущую сессию как открытую. Если есть другие сессии по данной таблице, они закрываются с регистрацией предупреждения в журнале.
Фоновое задание SAP формирует курсор по заданным параметрам и пакет данных заданного размера. Размер пакета – максимальное количество записей, которые процесс читает из БД. По умолчанию принимается равным 2000. Если в выборке БД больше записей, чем используемый размер пакета после передачи первого пакета формируется следующий блок с соответствующим offset и инкрементированным номером пакета. Номера инкрементируются на 1 и отправляются строго последовательно.
Далее SAP передает пакет на вход web-сервису внешней системы. А она система выполняет контроли входящего пакета. В системе должна быть зарегистрирована сессия с полученным id и она должна находиться в открытом статусе. Если номер пакета > 1 в системе должно быть зарегистрировано успешное получение предыдущего пакета (package_id-1).
В случае успешного контроля внешняя система парсит и сохраняет данные таблицы.
Дополнительно, если в пакете присутствует флаг final и сериализация прошла успешно, происходит уведомление модуля интеграции об успешном завершении обработки сессии и модуль обновляет статус сессии.
В случае ошибки контролей/разбора ошибка логируется и пакеты по данной сессии будут отклоняться внешней системой.
Так же и в обратном случае, когда внешняя система возвращает ошибку, она логируется и прекращается передача пакетов.
Для запроса данных на стороне SAP HСM был реализован интеграционный сервис. Сервис реализован на фреймворке ICF (SAP Internet Communication Framework — help.sap.com/viewer/6da7259a6c4b1014b7d5e759cc76fd22/7.01.22/en-US/488d6e0ea6ed72d5e10000000a42189c.html). Он позволяет производить запрос данных из системы SAP HCM по определенным таблицам. При формировании запроса данных есть возможность задавать перечень конкретных полей и параметры фильтрации с целью получения необходимых данных. При этом реализация сервиса не предполагает какой-либо бизнес-логики. Алгоритмы расчёта дельты, параметров запроса, контроля целостности, и пр. также реализуются на стороне внешней системы.
Данный механизм позволяет собирать и передавать все необходимые данные за несколько часов. Такая скорость находится на грани приемлемой, поэтому это решение рассматривается нами как временное, позволившее закрыть потребность в инструменте экстракции на проекте.
В целевой картине для решения задачи экстракции данных прорабатываются варианты использования CDC систем типа Oracle Golden Gate или ETL инструментов типа SAP DS.
А что если в качестве хранилища начать использовать какой-нибудь non-SAP и желательно OpenSource продукт? Мы в Х5 Retail Group остановили свой выбор на GreenPlum. Это конечно решает вопрос стоимости, но при этом сразу появляются вопросы, которые при использовании SAP BW решались практически по умолчанию.

В частности, каким образом забирать данные из систем источников, которые в большинстве своем являются решениями SAP?
«HR-метрики» стал первым проектом, в котором необходимо было решить эту проблему. Нашей целью было создание хранилища HR-данных и построение аналитической отчетности по направлению работы с сотрудниками. При этом основным источником данных является транзакционная система SAP HCM, в которой ведутся все кадровые, организационные и зарплатные мероприятия.
Экстракция данных
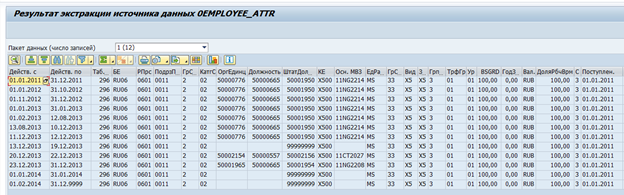
В SAP BW для SAP-систем существуют стандартные экстракторы данных. Эти экстракторы могут автоматически собирать необходимые данные, отслеживать их целостность, определять дельты изменений. Вот, например, стандартный источник данных по атрибутам сотрудника 0EMPLOYEE_ATTR:

Результат экстракции данных из него по одному сотруднику:
При необходимости такой экстрактор может быть модифицирован под собственные требования или может быть создан свой собственный экстрактор.
Первой возникла идея о возможности их переиспользования. К сожалению, это оказалось неосуществимой задачей. Большая часть логики реализована на стороне SAP BW, и безболезненно отделить экстрактор на источнике от SAP BW не получилось.
Стало очевидно, что потребуется разработка собственного механизма извлечения данных из SAP систем.
Структура хранения данных в SAP HCM
Для понимания требований к такому механизму, первоначально нужно определить какие именно данные нам потребуются.
Большинство данных в SAP HCM хранится в плоских SQL таблицах. На основании этих данных приложения SAP визуализируют пользователю оргструктуры, сотрудников и прочую HR информацию. Например, вот так в SAP HCM выглядит оргструктура:
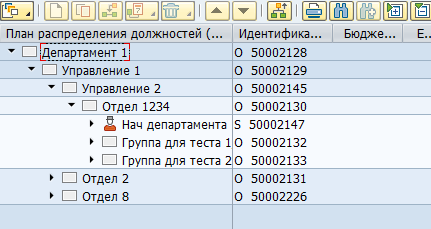
Физически такое дерево хранится в двух таблицах — в hrp1000 объекты и в hrp1001 связи между этими объектами.
Объекты «Департамент 1» и «Управление 1»:

Связь между объектами:

Как типов объектов, так и типов связи между ними может быть огромное количество. Существуют как стандартные связи между объектами, так и кастомизированные для собственных специфичных нужд. Например, стандартная связь B012 между оргединицей и штатной должностью указывает на руководителя подразделения.
Отображение руководителя в SAP:
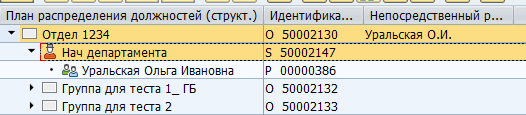
Хранение в таблице БД:

Данные по сотрудникам хранятся в таблицах pa*. Например, данные о кадровых мероприятиях по сотруднику хранятся в таблице pa0000
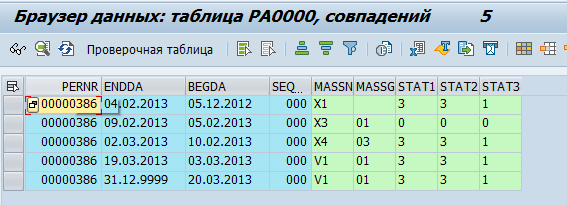
Мы приняли решение, что GreenPlum будет забирать «сырые» данные, т.е. просто копировать их из SAP таблиц. И уже непосредственно в GreenPlum они будут обрабатываться и преобразовываться в физические объекты (например, Отдел или Сотрудник) и метрики (например, среднесписочная численность).
Было определено порядка 70 таблиц, данные из которых необходимо передавать в GreenPlum. После чего мы приступили к проработке способа передачи этих данных.
SAP предлагает достаточно большое количество механизмов интеграции. Но самый простой способ – прямой доступ к базе данных запрещен из-за лицензионных ограничений. Таким образом, все интеграционные потоки должны быть реализованы на уровне сервера приложений.
Следующей проблемой было отсутствие данных об удаленных записях в БД SAP. При удалении строки в БД, она удаляется физически. Т.е. формирование дельты изменений по времени изменения не представлялось возможным.
Конечно, в SAP HCM есть механизмы фиксация изменений данных. Например, для последующей передачи в системы получатели существуют указатели изменений(change pointer), которые фиксируют любые изменения и на основании которых формируются Idoc (объект для передачи во внешние системы).
Пример IDoc изменения инфотипа 0302 у сотрудника с табельным номером 1251445:
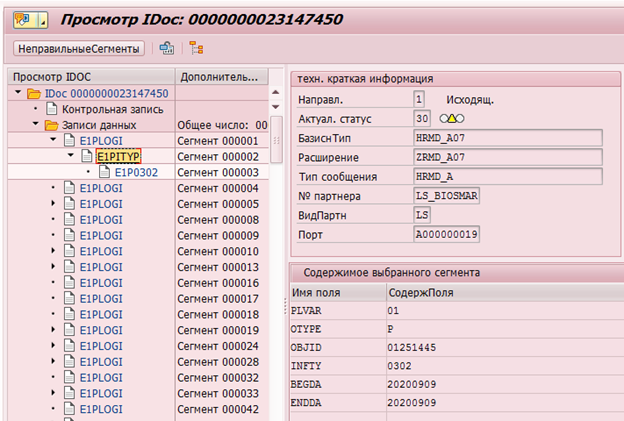
Или ведение логов изменений данных в таблице DBTABLOG.
Пример лога удаления записи с ключом QK53216375 из таблицы hrp1000:

Но эти механизмы доступны не для всех необходимых данных и их обработка на уровне сервера приложений может потреблять достаточно много ресурсов. Поэтому массовое включение логирования на все необходимые таблицы может привести к заметной деградации производительности системы.
Следующей серьезной проблемой были кластерные таблицы. Данные оценки времени и расчета зарплаты в RDBMS версии SAP HCM хранятся в виде набора логических таблиц по каждому сотруднику за каждый расчет. Эти логические таблицы в виде двоичных данных хранятся в таблице pcl2.
Кластер расчета заработной платы:
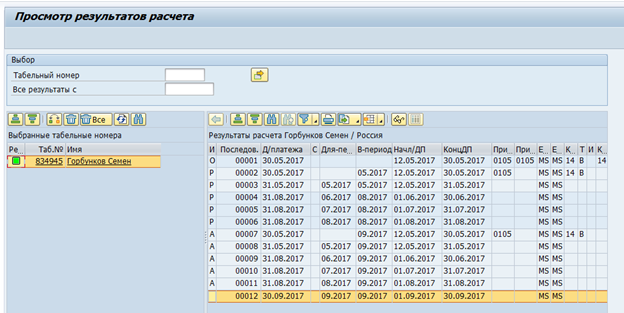
Данные из кластерных таблиц невозможно считать SQL командой, а требуется использование макрокоманд SAP HCM или специальных функциональных модулей. Соответственно, скорость считывания таких таблиц будет достаточно низка. С другой стороны, в таких кластерах хранятся данные, которые необходимы только раз в месяц – итоговый расчет заработной платы и оценка времени. Так что скорость в этом случае не столь критична.
Оценивая варианты с формированием дельты изменения данных, решили так же рассмотреть вариант с полной выгрузкой. Вариант каждый день передавать гигабайты неизменных данных между системами не может выглядеть красиво. Однако он имеет и ряд преимуществ – нет необходимости как реализации дельты на стороне источника, так и реализация встраивания этой дельты на стороне приемника. Соответственно, уменьшается стоимость и сроки реализации, и повышается надежность интеграции. При этом было определено, что практически все изменения в SAP HR происходят в горизонте трех месяцев до текущей даты. Таким образом, было принято решение остановиться на ежедневной полной выгрузке данных из SAP HR за N месяцев до текущей даты и на ежемесячной полной выгрузке. Параметр N зависит от конкретной таблицы
и колеблется от 1 до 15.
Для экстракции данных была предложена следующая схема:

Внешняя система формирует запрос и отправляет его в SAP HCM, там этот запрос проверяется на полноту данных и полномочия на доступ к таблицам. В случае успешной проверки, в SAP HCM отрабатывает программа, собирающая необходимые данные и передающая их в интеграционное решение Fuse. Fuse определяет необходимый топик в Kafka и передает данные туда. Далее данные из Kafka передаются в Stage Area GP.
Нас в данной цепочке интересует вопрос извлечения данных из SAP HCM. Остановимся на нем подробнее.
Схема взаимодействия SAP HCM-FUSE.
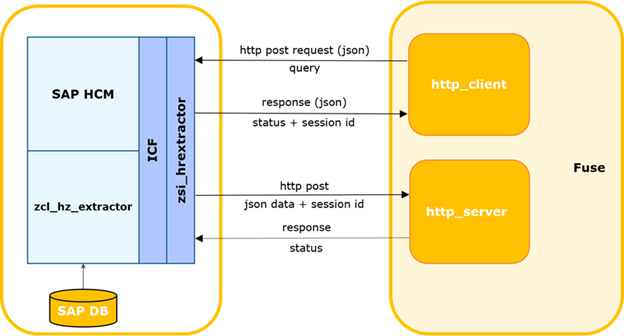
Внешняя система определяет время последнего успешного запроса в SAP.
Процесс может быть запущен по таймеру или иному событию, в том числе может быть установлен таймаут ожидания ответа с данными от SAP и инициация повторного запроса. После чего формирует запрос дельты и отправляет его в SAP.
Данные запроса передаются в body в формате json.
Метод http: POST.
Пример запроса:

Сервис SAP выполняет контроль запроса на полноту, соответствие текущей структуре SAP, наличие разрешения доступа к запрошенной таблице.
В случае ошибок сервис возвращает ответ с соответствующим кодом и описанием. В случае успешного контроля он создает фоновый процесс для формирования выборки, генерирует и синхронно возвращает уникальный id сессии.
Внешняя система в случае ошибки регистрирует ее в журнале. В случае успешного ответа передает id сессии и имя таблицы по которой был сделан запрос.
Внешняя система регистрирует текущую сессию как открытую. Если есть другие сессии по данной таблице, они закрываются с регистрацией предупреждения в журнале.
Фоновое задание SAP формирует курсор по заданным параметрам и пакет данных заданного размера. Размер пакета – максимальное количество записей, которые процесс читает из БД. По умолчанию принимается равным 2000. Если в выборке БД больше записей, чем используемый размер пакета после передачи первого пакета формируется следующий блок с соответствующим offset и инкрементированным номером пакета. Номера инкрементируются на 1 и отправляются строго последовательно.
Далее SAP передает пакет на вход web-сервису внешней системы. А она система выполняет контроли входящего пакета. В системе должна быть зарегистрирована сессия с полученным id и она должна находиться в открытом статусе. Если номер пакета > 1 в системе должно быть зарегистрировано успешное получение предыдущего пакета (package_id-1).
В случае успешного контроля внешняя система парсит и сохраняет данные таблицы.
Дополнительно, если в пакете присутствует флаг final и сериализация прошла успешно, происходит уведомление модуля интеграции об успешном завершении обработки сессии и модуль обновляет статус сессии.
В случае ошибки контролей/разбора ошибка логируется и пакеты по данной сессии будут отклоняться внешней системой.
Так же и в обратном случае, когда внешняя система возвращает ошибку, она логируется и прекращается передача пакетов.
Для запроса данных на стороне SAP HСM был реализован интеграционный сервис. Сервис реализован на фреймворке ICF (SAP Internet Communication Framework — help.sap.com/viewer/6da7259a6c4b1014b7d5e759cc76fd22/7.01.22/en-US/488d6e0ea6ed72d5e10000000a42189c.html). Он позволяет производить запрос данных из системы SAP HCM по определенным таблицам. При формировании запроса данных есть возможность задавать перечень конкретных полей и параметры фильтрации с целью получения необходимых данных. При этом реализация сервиса не предполагает какой-либо бизнес-логики. Алгоритмы расчёта дельты, параметров запроса, контроля целостности, и пр. также реализуются на стороне внешней системы.
Данный механизм позволяет собирать и передавать все необходимые данные за несколько часов. Такая скорость находится на грани приемлемой, поэтому это решение рассматривается нами как временное, позволившее закрыть потребность в инструменте экстракции на проекте.
В целевой картине для решения задачи экстракции данных прорабатываются варианты использования CDC систем типа Oracle Golden Gate или ETL инструментов типа SAP DS.
