Привет. У нас 15 260+ объектов и 38 000 сетевых устройств, которые нужно настраивать, обновлять и проверять их работоспособность. Обслуживать такой парк оборудования довольно сложно и требует много времени, сил и людей. Поэтому нам потребовалось автоматизировать работу с сетевым оборудованием и мы решили адаптировать концепцию Network as a Code для управления сетью в нашей компании. Под катом читайте нашу историю автоматизации, совершенные ошибки и дальнейший план построения систем.
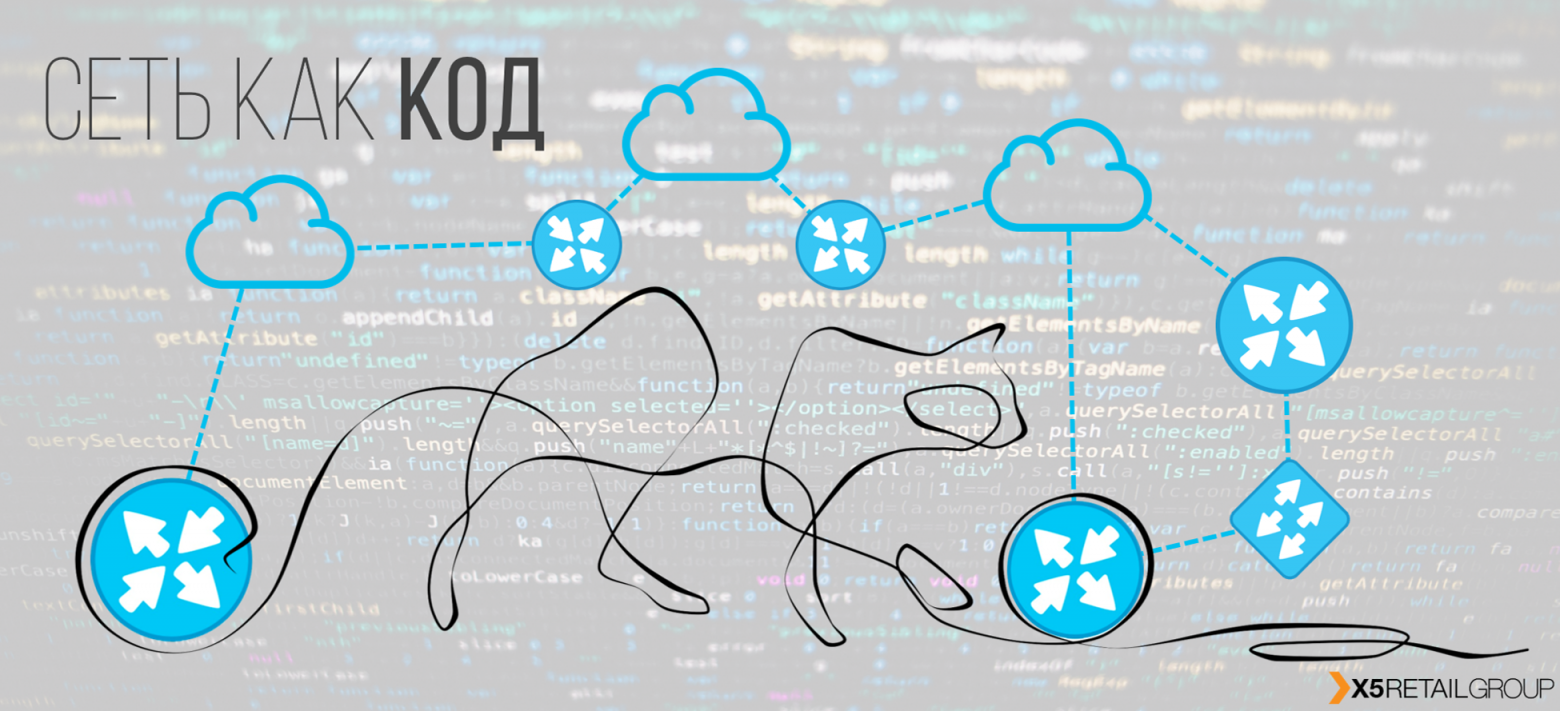
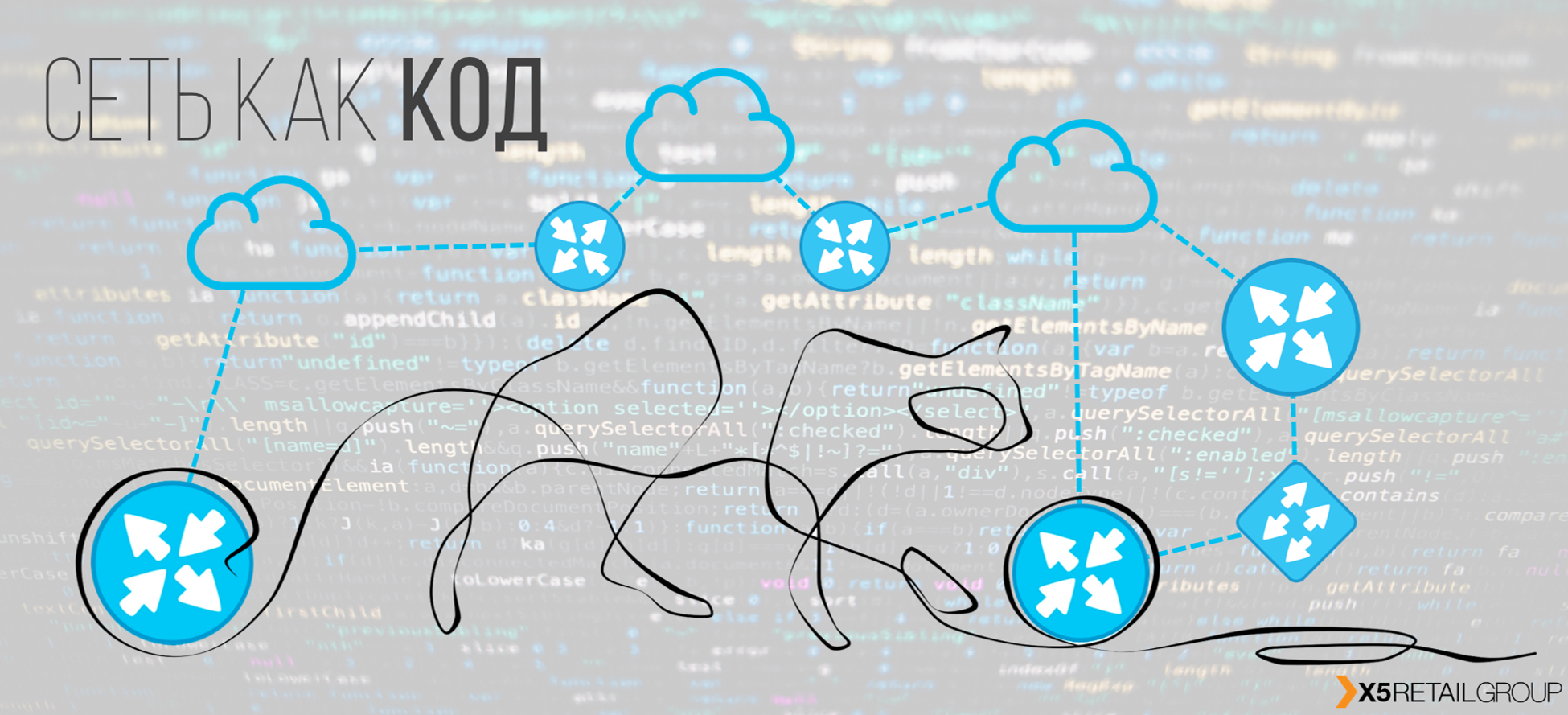
Привет! Меня зовут Александр Прохоров, и вместе с командой сетевых инженеров нашего отдела мы занимаемся сетью в #ITX5. Наш отдел развивает сетевую инфраструктуру, мониторинг, автоматизацию сети и модное направление Network as a Code.
Изначально, не очень верилось в какую-либо автоматизацию в нашей сети в принципе. Оставалась масса legacy и ошибок конфигурации — не везде была центральная авторизация, не все железо поддерживало SSH, не везде был настроен SNMP. Все это сильно подрывало веру в автоматизацию. Поэтому, первым делом, мы привели в порядок то, что необходимо для начала автоматизации, а именно: стандартизация подключения SSH, единая авторизация (AAA) и профили SNMP. Весь этот фундамент позволяет написать инструмент массовой доставки конфигураций на устройство, но встает вопрос можно ли получить больше? Так мы пришли к необходимости составления плана развития направления автоматизации и концепции Network as a Code, в частности.
Под концепцией Network as a Code, по версии Cisco, подразумеваются следующие принципы:

Первые два пункта позволяют применять в управлении сетевой инфраструктурой подход DevOps, или NetDevOps. С третим пунктом возникают сложности, например, что делать если API нет? Конечно, SSH и CLI, мы же сетевики!
Помимо попытки применения новых подходов к управлению сетью, мы хотели решить еще несколько острых проблем в сетевой инфраструктуре, таких как целостность данных, их актуализация и, конечно, автоматизация. Под автоматизацией мы понимаем не только массовую доставку конфигураций на оборудование, но и автоматическое составление конфигураций, автоматический сбор инвентарных данных сетевого оборудования, интеграцию с системами мониторинга. Но обо всем по порядку.
Функционал, на который мы нацелились, такой:
Краткий вывод из спойлера — лучше систематизировать и контролировать процесс массовой доставки конфигураций, чтобы не прийти к массовой доставке ошибок в конфигурациях.
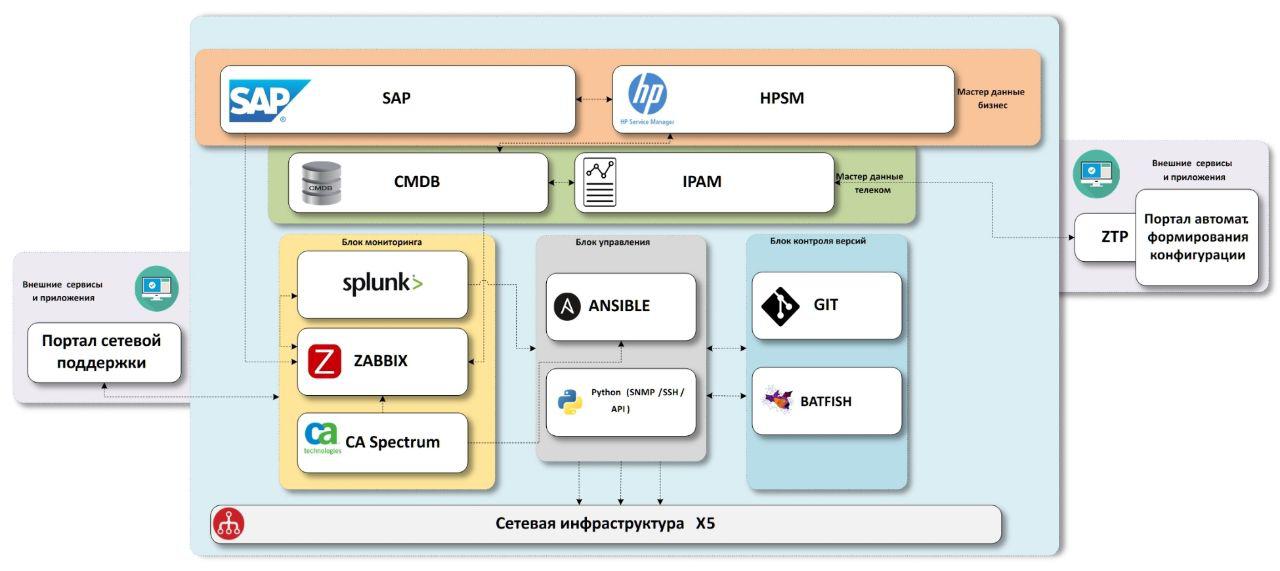
Схема, к которой мы пришли, состоит из блоков «бизнес» мастер-данных, «сетевых» мастер-данных, систем мониторинга сетевой инфраструктуры, системы доставки конфигураций, системы контроля версий с блоком тестирования.

Для начала нам нужно знать, какие объекты есть в компании.
SAP – ERP система компании. Данные почти по всем объектам есть там, а точнее по всем магазинам и распределительным центрам. Также, как есть данные по оборудованию, прошедшему через IT-склад с инвентарными номерами, что также пригодится нам в будущем. Не хватает только офисов, в системе их не заводят. Эту проблему мы пытаемся решить отдельным процессом, начиная с момента открытия, на каждом же объекте нужна связь, а настройки для связи выделяем мы, соответственно где-то в этот момент нужно формировать мастер-данные. Но недостаточность данных — тема отдельная, это описание лучше вынести в отдельную статью, если будет к этому интерес.
HPSM – система содержащая общую CMDB по IT, incident-менеджмент, change-менеджмент. Так как система общая для всего ИТ, в ней должно быть и все ИТ-оборудование, включая сетевое. Это то место, куда мы будем складывать все финальные данные по сети. С incident и change менеджментом мы планируем взаимодействовать из систем мониторинга в будущем.
Мы знаем какие объекты у нас есть, обогатим их данными по сети. Для этой цели у нас существуют две системы – IPAM от SolarWinds и собственная система CMDB.noc.
IPAM – хранилище IP подсетей, самые правильные и верные данные по принадлежности IP адресов в компании должны быть здесь.
CMDB.noc – база данных с WEB-интерфейсом, где хранятся статичные данные по сетевому оборудованию – роутеры, коммутаторы, точки доступа, а также провайдеры и их характеристики. Под статичными подразумевается, что их изменение проводится только с участием человека. Другими словами, автодискаверинг не вносит изменения в эту базу, она нужна нам, чтобы понимать, что «должно» быть установлено на объекте. Своя база нужна как буфер между продуктивными системами, с которыми работает вся компания, и внутренними инструментами сети. Ускоряется разработка, добавление нужных полей, новых связей, корректировка параметров и т.д. Плюс этого решения не только в скорости разработки, но и в наличии тех связей между данными, которые необходимы именно нам, без компромиссов. Как мини-пример, мы используем несколько exid в базе для связи данных между IPAM, SAP и HPSM.
В итоге, получили полные данные по всем объектам, с привязанным сетевым оборудованием и IP-адресами. Теперь нам нужны шаблоны конфигураций, или сетевых сервисов, которые мы предоставляем на этих объектах.

Здесь как раз мы дошли до применения первого принцип NaaC – хранения целевых конфигураций в репозитории. В нашем случае это Gitlab. Выбор для нас был несложным:
В Gitlab будет происходить основная интересная часть автоматизации – процесс изменения конфигурационного стандарта или, проще говоря, шаблона.
Теперь допустим, к нам приходит новый проект. Задачи для нового IT-проекта – сделать пилот на некотором объеме магазинов. По результатам пилота – в случае успеха, сделать тиражирование на все объекты данного типа; в ином случае свернуть пилот без выполнения тиражирования.
Этот процесс очень хорошо ложится в логику Git:

В первом приближении — даже без автоматизации, это очень удобный инструмент для совместной работы над сетевой конфигурацией. Особенно, если представить, что проектов одновременно пришло три и больше. Когда придет время выпуска проектов в prod, нужно будет решить все конфликты конфигураций в merge-request'ах и проверить, что изменения настроек не взаимоисключающие. И это очень удобно делать в git.
Плюс подобный подход добавляет нам возможности гибко использовать инструменты Gitlab CI/CD для тестирования конфигураций виртуально, автоматизировать доставку конфигураций на тестовый стенд или пилотную группу объектов. //И даже на prod, если хотите.
Изначально, основной целью была именно массовая доставка конфигураций, как инструмент, который очень явно позволяет сэкономить время работы инженеров и ускорить выполнение задач по конфигурации. Для этого, еще до старта большой активности «Network as a Code», мы писали python-решение по подключению к оборудованию либо для сбора конфигураций оборудования, либо для его настройки. Это netmiko, это pysnmp, это jinja2 и etc.
Но для нас пришло время разделить массовую настройку на несколько подвидов:
Одна из задач автоматизации — это, конечно, находить что из этой автоматизации выпало. Не все 38k настраиваются идеально с первого раза, бывает даже так, что кто-то настраивает оборудование руками. И необходимо отслеживать эти изменения и восстанавливатьсправедливость целевую конфигурацию.
Есть три подхода к проверке соответствия конфигураций стандарту:
В третьем случае появляется опция передать эту работу в инцидент-менеджмент (операционку), чтобы несоответствия устранялись малыми порциями в течении всего времени, чем один раз авралом.
Zabbix, о котором я писал ранее в статье «Как мы делали мониторинг 14000 объектов» — наша система мониторинга распределенных объектов, где мы можем делать любые триггеры и алерты, которые придумаем. С момента написания прошлой статьи мы обновились до Zabbix 4.0 LTS.
На основе Web Zabbix мы сделали update нашего портала сетевой поддержки, где теперь можно найти всю информацию по объекту из всех наших систем на одном экране, а также запустить скрипты для проверки часто возникающих проблем.

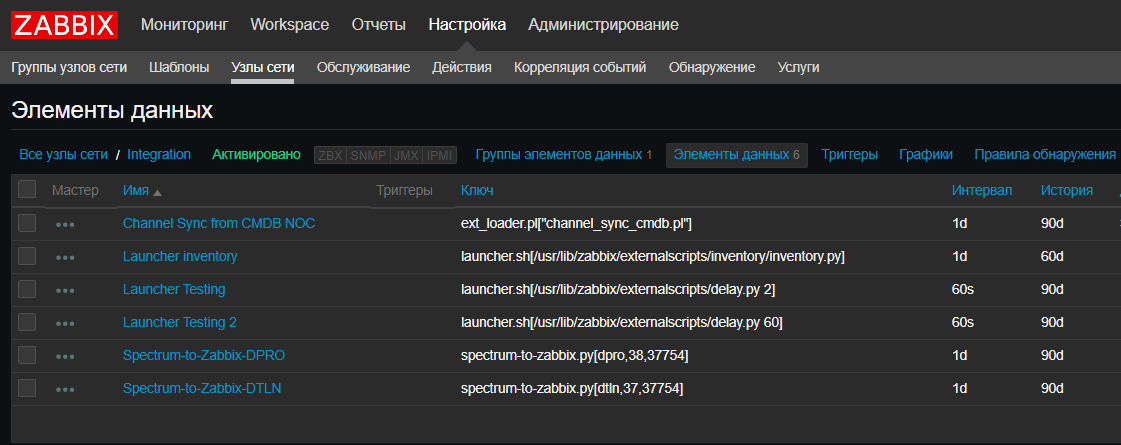
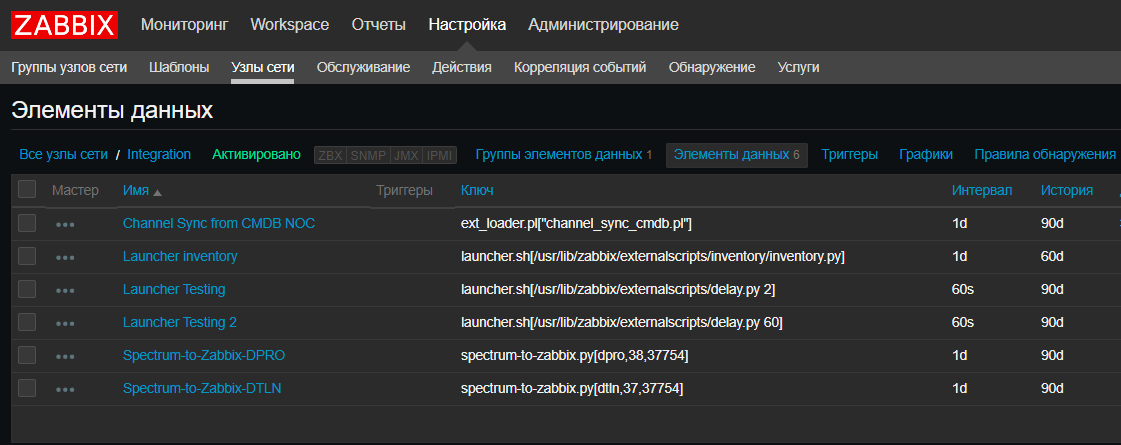
Также мы ввели новую фишечку — для нас Zabbix стал в некотором роде CRON'ом для запуска скриптов по расписанию, таких как скрипты интеграции систем, скрипты автодискаверинга. Это действительно удобно, когда нужно посмотреть текущие скрипты и когда и где они запускаются, не проверяя все сервера. Правда, для скриптов, выполняющихся больше 30 секунд, понадобится launcher, который их запускает, не дожидаясь окончания. К счастью, он несложный:
Splunk – решение которое позволяет собирать журналы событий с сетевого оборудования, и это можно использовать также для мониторинга автоматизации. Например, собирая бекап конфигурации, python-скрипт генерирует LOG-сообщение CFG-5-BACKUP, роутер или свитч отправляет сообщение в Splunk, в котором мы считаем количество сообщений данного типа от сетевого оборудования. Это позволяет нам отслеживать количество оборудования, которое обнаружил скрипт. И мы видим, сколько железок смогли сообщить об этом в Splunk и верифицировать, что сообщения от всех железок дошли.
Spectrum – комплексная система, используется у нас для мониторинга критичных объектов, довольно мощный инструмент, который нам очень помогает в решении критичных инцидентов по сети. В автоматизации мы его используем только дергая из него данные, это не open-source, поэтому возможности несколько ограничены.
 Используя системы с мастер-данными по оборудованию мы можем задуматься о создании ZTP, или Zero Touch Provisioning. Как кнопка «автонастройка», но только без кнопки.
Используя системы с мастер-данными по оборудованию мы можем задуматься о создании ZTP, или Zero Touch Provisioning. Как кнопка «автонастройка», но только без кнопки.
Все необходимые данные у нас есть из предыдущих блоков – мы знаем объект, его тип, какое там оборудование (вендор и модель), какие там адреса (IPAM), какой текущий стандарт конфигурации (Git). Собрав их все вместе, мы можем как минимум подготовить шаблон конфигурации для заливки на устройство, это будет скорее похоже на One Touch Provisioning, но иногда большего и не требуется.
Для True Zero Touch нужен способ автоматической доставки конфигурации на ненастроенное оборудование. Причем, желательно вне зависимости от вендора. Есть несколько рабочих вариантов – консольный сервер, если все оборудование проходит через центральный склад, мобильные консольные решения, если оборудование сразу приезжает на место. Эти решения мы пока только прорабатываем, но как только будет рабочий вариант, сможем им поделиться.
Итого, в нашей концепции Network as a Code получилось 5 основных вех:
Вместить все в одну статью не получилось, каждый пункт достоин отдельного обсуждения, о чем-то мы можем рассказать уже сейчас, о чем-то когда проверим решения на практике. Если есть заинтересованность в какой-то из тем — в конце будет опрос, где можно проголосовать за следующую статью. Если тема в список не вошла, но интересно про нее почитать — оставьте комментарий, как только сможем, обязательно поделимся нашим опытом.
Отдельное спасибо Вирилину Александру(xscrew) и Сибгатулину Марату(eucariot) за рефернс-визит осенью 2018 в yandex-облако и рассказ об автомейшне в сетевой инфраструктуре облака. После него у нас появилось вдохновение и множество идей о применении автоматизации и NetDevOps'а в инфраструктуре X5 Retail Group.
Long story short, we want to automate the network
Привет! Меня зовут Александр Прохоров, и вместе с командой сетевых инженеров нашего отдела мы занимаемся сетью в #ITX5. Наш отдел развивает сетевую инфраструктуру, мониторинг, автоматизацию сети и модное направление Network as a Code.
Изначально, не очень верилось в какую-либо автоматизацию в нашей сети в принципе. Оставалась масса legacy и ошибок конфигурации — не везде была центральная авторизация, не все железо поддерживало SSH, не везде был настроен SNMP. Все это сильно подрывало веру в автоматизацию. Поэтому, первым делом, мы привели в порядок то, что необходимо для начала автоматизации, а именно: стандартизация подключения SSH, единая авторизация (AAA) и профили SNMP. Весь этот фундамент позволяет написать инструмент массовой доставки конфигураций на устройство, но встает вопрос можно ли получить больше? Так мы пришли к необходимости составления плана развития направления автоматизации и концепции Network as a Code, в частности.
Под концепцией Network as a Code, по версии Cisco, подразумеваются следующие принципы:
- Хранение целевых конфигураций в репозитории, Source Control
- Изменения конфигураций проходят через репозиторий, Single Source of Truth
- Внедрение конфигураций через API

Первые два пункта позволяют применять в управлении сетевой инфраструктурой подход DevOps, или NetDevOps. С третим пунктом возникают сложности, например, что делать если API нет? Конечно, SSH и CLI, мы же сетевики!
И это все что нам нужно?
Одно только применение этих принципов не решает всех задач сетевой инфраструктуры, также как и для их применения нужен некий фундамент с данными о сети.
Вопросы, которые возникли у нас при мыслях об этом:
Исходя из всех вопросов выше стало понятно, что нам потребуется комплекс систем, которые решают различные задачи, работают в связке друг с другом и дают нам полную информацию о сетевой инфраструктуре.
Вопросы, которые возникли у нас при мыслях об этом:
- Окей, я храню конфигурацию как код, как я должен применять ее на конкретном объекте?
- Окей, у меня есть шаблон конфигурации в репозитории, но как на его основе автоматически сформировать конфигурацию под объект?
- Как узнать какая модель и какого вендора должна быть на этом объекте? Можно автоматически?
- Как мне проверить совпадают ли текущие настройки объекта с параметрами в репозитории?
- Как работать с изменениям в репозитории и тиражировать их на продуктивную сеть?
- Какой набор данных и систем мне нужен, чтобы задуматься о Zero Touch Provisioning?
- Как быть с различиями в вендорах, и даже моделях одного вендора?
- Как хранить подсети для автоматического формирования конфигураций?
Исходя из всех вопросов выше стало понятно, что нам потребуется комплекс систем, которые решают различные задачи, работают в связке друг с другом и дают нам полную информацию о сетевой инфраструктуре.

Помимо попытки применения новых подходов к управлению сетью, мы хотели решить еще несколько острых проблем в сетевой инфраструктуре, таких как целостность данных, их актуализация и, конечно, автоматизация. Под автоматизацией мы понимаем не только массовую доставку конфигураций на оборудование, но и автоматическое составление конфигураций, автоматический сбор инвентарных данных сетевого оборудования, интеграцию с системами мониторинга. Но обо всем по порядку.
Функционал, на который мы нацелились, такой:
- База сетевого оборудования (+ дискаверинг, + автообновление)
- База сетевых адресов (IPAM + проверки на достоверность)
- Интеграция систем мониторинга с инвентарными данными
- Хранение стандартов конфигураций в системе контроля версий
- Автоматическое формирование целевых конфигураций под объект
- Массовая доставка конфигураций на сетевое оборудование
- Внедрение процесса CI/CD для управления изменениями сетевых конфигураций
- Тестирование сетевых конфигураций в рамках CI/CD
- ZTP (Zero Touch Provisioning) – автоматическая настойка оборудования под объект
Long story, we tried automatization
Мы начали пробовать автоматизировать работу по настройке сети еще 2 года тому назад. Почему же сейчас этот вопрос встал снова и на него нужно обращать внимание?
Больше нескольких десятков устройств настраивать руками утомительно и скучно. Иногда рука инженера дергается, и он совершает ошибки. Для нескольких десятков обычно достаточно скрипта, написанного одним инженером, который раскатывает обновленные настройки на оборудование сети.
Почему же этим не ограничиться? На самом деле, многие сетевые инженеры уже умеют всякие питоны, а те, кто еще не умеет, уже совсем скоро будет уметь (Наталья Самойленко же выпустила отличный труд по Python, специально для сетевиков). Тот, кому поставлена задача настроить n+1 маршрутизаторов, способен написать скрипт и раскатать настройки очень быстро. Намного быстрее, чем потом способен вернуть все обратно. По опыту автоматизации «каждый сам за себя» случаются ошибки, когда восстановить связь можно только руками, и только большими страданиями всей команды.

 Однажды, один из инженеров решил выполнить важную задачу – навести порядок в конфигурациях роутеров. В результате ревизии на нескольких объектах был обнаружен устаревший prefix-list со специфичными подсетями, который больше нам не был нужен. Ранее он использовался для фильтрации адресов loopback'ов центральных площадок, чтобы они приходили только через один канал, и мы могли тестировать связь именно на этом канале. Но механизм оптимизировали, и такую схему тестирования каналов перестали использовать. Сотрудник решил удалить этот prefix-list, чтобы он не маячил в конфигурации и не вызывал путаницу в будущем. Все согласились с удалением неиспользуемого prefix-list'а, задача несложная, сразу забыли. Но удалять руками на десятках объектов одинаковый prefix-list довольно скучно и требует много времени. И инженер написал скрипт, который быстро пройдется по оборудованию, сделает «no prefix-list pl-cisco-primer» и торжественно сохранит конфигурацию.
Однажды, один из инженеров решил выполнить важную задачу – навести порядок в конфигурациях роутеров. В результате ревизии на нескольких объектах был обнаружен устаревший prefix-list со специфичными подсетями, который больше нам не был нужен. Ранее он использовался для фильтрации адресов loopback'ов центральных площадок, чтобы они приходили только через один канал, и мы могли тестировать связь именно на этом канале. Но механизм оптимизировали, и такую схему тестирования каналов перестали использовать. Сотрудник решил удалить этот prefix-list, чтобы он не маячил в конфигурации и не вызывал путаницу в будущем. Все согласились с удалением неиспользуемого prefix-list'а, задача несложная, сразу забыли. Но удалять руками на десятках объектов одинаковый prefix-list довольно скучно и требует много времени. И инженер написал скрипт, который быстро пройдется по оборудованию, сделает «no prefix-list pl-cisco-primer» и торжественно сохранит конфигурацию.
Через какое-то время после обсуждения, несколько часов, или через день, уже и не помню, упал один объект. Через пару минут еще один, похожий. Количество недоступных объектов продолжало расти, за полчаса до 10, и каждые 2-3 минуты добавлялся новый. Были подключены для диагностики все инженеры. Через 40-50 минут после начала аварии опросили всех об изменениях, и сотрудник остановил скрипт. На тот момент насчитывалось уже около 20 объектов со сломанными каналами. Полное восстановление заняло 7 инженеров на несколько часов.
Prefix-list использовался для фильтрации loopback'ов — на одном канале фильтровался один, на резервном второй. Использовалось это для проверки связи без переключения продуктивного трафика между каналами. Поэтому первое правило входящего route-map на BGP соседа было DENY с «match ip address prefix list». Остальные правила в route-map все были PERMIT.
Тут есть несколько нюансов, которые возможно стоит отметить:
Все вышеописанное верно для Cisco IOS. Пустой prefix-list может появится, когда вы объявляете route-map, делайте в нем «match ip address prefix-list pl-test-cisco». Данный prefix-list не будет объявлен в явном виде в конфигурации (помимо строчки с match), но его можно обнаружить в show ip prefix-list.
Возвращаясь к произошедшему, когда скриптом был удален prefix-list, он стал пустым, так как все еще находился в первом правиле DENY в route-map. Пустой prefix-list разрешает все подсети, соответственно все что передавал нам BGP пир попало в первое правило DENY.
Почему же инженер сразу не заметил, что сломал связь? Тут сыграли роль таймеры BGP в Cisco.
BGP сам по себе не обменивается маршрутами по расписанию, и если вы обновили маршрутную политику BGP, нужно сбросить BGP сессию для применения изменений, «clear ip bgp <peer-ip>» на Cisco.
Чтобы не сбрасывать сессию есть два механизма:
Soft-reconfiguration держит информацию, полученную в UPDATE от соседа, о маршрутах до применения политик в локальной таблице adj-RIB-in. При обновлении политик появляется возможность эмулировать UPDATE от соседа.
Route Refresh – это «умение» пиров отправлять UPDATE по запросу. О наличии этой возможности договариваются при установлении соседства. Плюсы – не нужно хранить копию UPDATE локально. Минусы – на практике после запроса UPDATE от соседа нужно подождать, пока он его отправит. Кстати, отключить функцию на Cisco можно скрытой командой:
Есть недокументированная особенность Cisco – 30-секундный таймер, триггером к которому является изменение политик BGP. После изменения политик, через 30 секунд запустится процесс обновления маршрутов по одной из вышеописанных технологий. Документированного описания этого таймера мне найти не удалось, однако есть его упоминание в BUG CSCvi91270. Узнать о его наличии можно на практике, проведя изменения в лабе и посмотрев в debug запросы на UPDATE к соседу или процесс soft-reconfiguration. (Если есть дополнительная информация на тему – можно оставить в комментариях)
проведя изменения в лабе и посмотрев в debug запросы на UPDATE к соседу или процесс soft-reconfiguration. (Если есть дополнительная информация на тему – можно оставить в комментариях)
Для Soft-Reconfiguration работа таймера выглядит так:
Для Route-Refresh со стороны соседа вот так:
Если Route-Refresh не поддерживается одним из пиров и soft-reconfiguration inbound не включен, то обновления маршрутов по новой политике автоматически не произойдет.
Итак, prefix-list был удален, связь оставалась, через 30 секунд пропала. Скрипт успевал поменять конфиг, проверить связь, и сохранить конфиг. Падения с работой скрипта связали не сразу, на фоне общего большого количества объектов.
Всего этого легко можно было избежать тестированием, частичным тиражированием настроек, Появилось понимание, что автоматизация должна быть централизованной и контролируемой.

Больше нескольких десятков устройств настраивать руками утомительно и скучно. Иногда рука инженера дергается, и он совершает ошибки. Для нескольких десятков обычно достаточно скрипта, написанного одним инженером, который раскатывает обновленные настройки на оборудование сети.
Почему же этим не ограничиться? На самом деле, многие сетевые инженеры уже умеют всякие питоны, а те, кто еще не умеет, уже совсем скоро будет уметь (Наталья Самойленко же выпустила отличный труд по Python, специально для сетевиков). Тот, кому поставлена задача настроить n+1 маршрутизаторов, способен написать скрипт и раскатать настройки очень быстро. Намного быстрее, чем потом способен вернуть все обратно. По опыту автоматизации «каждый сам за себя» случаются ошибки, когда восстановить связь можно только руками, и только большими страданиями всей команды.

Пример
 Однажды, один из инженеров решил выполнить важную задачу – навести порядок в конфигурациях роутеров. В результате ревизии на нескольких объектах был обнаружен устаревший prefix-list со специфичными подсетями, который больше нам не был нужен. Ранее он использовался для фильтрации адресов loopback'ов центральных площадок, чтобы они приходили только через один канал, и мы могли тестировать связь именно на этом канале. Но механизм оптимизировали, и такую схему тестирования каналов перестали использовать. Сотрудник решил удалить этот prefix-list, чтобы он не маячил в конфигурации и не вызывал путаницу в будущем. Все согласились с удалением неиспользуемого prefix-list'а, задача несложная, сразу забыли. Но удалять руками на десятках объектов одинаковый prefix-list довольно скучно и требует много времени. И инженер написал скрипт, который быстро пройдется по оборудованию, сделает «no prefix-list pl-cisco-primer» и торжественно сохранит конфигурацию.
Однажды, один из инженеров решил выполнить важную задачу – навести порядок в конфигурациях роутеров. В результате ревизии на нескольких объектах был обнаружен устаревший prefix-list со специфичными подсетями, который больше нам не был нужен. Ранее он использовался для фильтрации адресов loopback'ов центральных площадок, чтобы они приходили только через один канал, и мы могли тестировать связь именно на этом канале. Но механизм оптимизировали, и такую схему тестирования каналов перестали использовать. Сотрудник решил удалить этот prefix-list, чтобы он не маячил в конфигурации и не вызывал путаницу в будущем. Все согласились с удалением неиспользуемого prefix-list'а, задача несложная, сразу забыли. Но удалять руками на десятках объектов одинаковый prefix-list довольно скучно и требует много времени. И инженер написал скрипт, который быстро пройдется по оборудованию, сделает «no prefix-list pl-cisco-primer» и торжественно сохранит конфигурацию.Через какое-то время после обсуждения, несколько часов, или через день, уже и не помню, упал один объект. Через пару минут еще один, похожий. Количество недоступных объектов продолжало расти, за полчаса до 10, и каждые 2-3 минуты добавлялся новый. Были подключены для диагностики все инженеры. Через 40-50 минут после начала аварии опросили всех об изменениях, и сотрудник остановил скрипт. На тот момент насчитывалось уже около 20 объектов со сломанными каналами. Полное восстановление заняло 7 инженеров на несколько часов.
Техническая сторона
Prefix-list использовался для фильтрации loopback'ов — на одном канале фильтровался один, на резервном второй. Использовалось это для проверки связи без переключения продуктивного трафика между каналами. Поэтому первое правило входящего route-map на BGP соседа было DENY с «match ip address prefix list». Остальные правила в route-map все были PERMIT.
Тут есть несколько нюансов, которые возможно стоит отметить:
- Правило route-map, в котором нет match – пропускает все
- В конце prefix-list стоит implicit deny, но только если он не пустой
- Пустой prefix-list это implicit permit
Все вышеописанное верно для Cisco IOS. Пустой prefix-list может появится, когда вы объявляете route-map, делайте в нем «match ip address prefix-list pl-test-cisco». Данный prefix-list не будет объявлен в явном виде в конфигурации (помимо строчки с match), но его можно обнаружить в show ip prefix-list.
2901-NOC-4.2(config)#route-map rm-test-in
2901-NOC-4.2(config-route-map)#match ip address prefix-list pl-test-in
2901-NOC-4.2(config-route-map)#do sh run | i prefix
match ip address prefix-list pl-test-in
2901-NOC-4.2(config-route-map)#do sh ip prefix
ip prefix-list pl-test-in: 0 entries
2901-NOC-4.2(config-route-map)#
Возвращаясь к произошедшему, когда скриптом был удален prefix-list, он стал пустым, так как все еще находился в первом правиле DENY в route-map. Пустой prefix-list разрешает все подсети, соответственно все что передавал нам BGP пир попало в первое правило DENY.
Почему же инженер сразу не заметил, что сломал связь? Тут сыграли роль таймеры BGP в Cisco.
BGP сам по себе не обменивается маршрутами по расписанию, и если вы обновили маршрутную политику BGP, нужно сбросить BGP сессию для применения изменений, «clear ip bgp <peer-ip>» на Cisco.
Чтобы не сбрасывать сессию есть два механизма:
- Soft-Reconfiguration у Cisco
- Route Refresh в виде RFC2918
Soft-reconfiguration держит информацию, полученную в UPDATE от соседа, о маршрутах до применения политик в локальной таблице adj-RIB-in. При обновлении политик появляется возможность эмулировать UPDATE от соседа.
Route Refresh – это «умение» пиров отправлять UPDATE по запросу. О наличии этой возможности договариваются при установлении соседства. Плюсы – не нужно хранить копию UPDATE локально. Минусы – на практике после запроса UPDATE от соседа нужно подождать, пока он его отправит. Кстати, отключить функцию на Cisco можно скрытой командой:
neighbor <peer-ip> dont-capability-negotiate
Есть недокументированная особенность Cisco – 30-секундный таймер, триггером к которому является изменение политик BGP. После изменения политик, через 30 секунд запустится процесс обновления маршрутов по одной из вышеописанных технологий. Документированного описания этого таймера мне найти не удалось, однако есть его упоминание в BUG CSCvi91270. Узнать о его наличии можно на практике,
 проведя изменения в лабе и посмотрев в debug запросы на UPDATE к соседу или процесс soft-reconfiguration. (Если есть дополнительная информация на тему – можно оставить в комментариях)
проведя изменения в лабе и посмотрев в debug запросы на UPDATE к соседу или процесс soft-reconfiguration. (Если есть дополнительная информация на тему – можно оставить в комментариях)Для Soft-Reconfiguration работа таймера выглядит так:
2901-NOC-4.2(config)#no ip prefix-list pl-test seq 10 permit 10.5.5.0/26
2901-NOC-4.2(config)#do sh clock
16:53:31.117 Tue Sep 24 2019
Sep 24 16:53:59.396: BGP(0): start inbound soft reconfiguration for
Sep 24 16:53:59.396: BGP(0): process 10.5.5.0/26, next hop 10.0.0.1, metric 0 from 10.0.0.1
Sep 24 16:53:59.396: BGP(0): Prefix 10.5.5.0/26 rejected by inbound route-map.
Sep 24 16:53:59.396: BGP(0): update denied, previous used path deleted
Sep 24 16:53:59.396: BGP(0): no valid path for 10.5.5.0/26
Sep 24 16:53:59.396: BGP(0): complete inbound soft reconfiguration, ran for 0ms
Sep 24 16:53:59.396: BGP: topo global:IPv4 Unicast:base Remove_fwdroute for 10.5.5.0/26
2901-NOC-4.2(config)#
Для Route-Refresh со стороны соседа вот так:
2801-RTR (config-router)#
*Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 rcv REFRESH_REQ for afi/sfai: 1/1
*Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 start outbound soft reconfig for afi/safi: 1/1
Если Route-Refresh не поддерживается одним из пиров и soft-reconfiguration inbound не включен, то обновления маршрутов по новой политике автоматически не произойдет.
Итак, prefix-list был удален, связь оставалась, через 30 секунд пропала. Скрипт успевал поменять конфиг, проверить связь, и сохранить конфиг. Падения с работой скрипта связали не сразу, на фоне общего большого количества объектов.
Всего этого легко можно было избежать тестированием, частичным тиражированием настроек, Появилось понимание, что автоматизация должна быть централизованной и контролируемой.

Системы, которые нам нужны и их связи
Краткий вывод из спойлера — лучше систематизировать и контролировать процесс массовой доставки конфигураций, чтобы не прийти к массовой доставке ошибок в конфигурациях.
- DevOps: как деплоить за 50ms и не просыпаться в 4 утра от алертов
- Читайте в моей новой книге: "Никак, !@#$%"
Схема, к которой мы пришли, состоит из блоков «бизнес» мастер-данных, «сетевых» мастер-данных, систем мониторинга сетевой инфраструктуры, системы доставки конфигураций, системы контроля версий с блоком тестирования.
All we need is Data
Для начала нам нужно знать, какие объекты есть в компании.
SAP – ERP система компании. Данные почти по всем объектам есть там, а точнее по всем магазинам и распределительным центрам. Также, как есть данные по оборудованию, прошедшему через IT-склад с инвентарными номерами, что также пригодится нам в будущем. Не хватает только офисов, в системе их не заводят. Эту проблему мы пытаемся решить отдельным процессом, начиная с момента открытия, на каждом же объекте нужна связь, а настройки для связи выделяем мы, соответственно где-то в этот момент нужно формировать мастер-данные. Но недостаточность данных — тема отдельная, это описание лучше вынести в отдельную статью, если будет к этому интерес.
HPSM – система содержащая общую CMDB по IT, incident-менеджмент, change-менеджмент. Так как система общая для всего ИТ, в ней должно быть и все ИТ-оборудование, включая сетевое. Это то место, куда мы будем складывать все финальные данные по сети. С incident и change менеджментом мы планируем взаимодействовать из систем мониторинга в будущем.
Мы знаем какие объекты у нас есть, обогатим их данными по сети. Для этой цели у нас существуют две системы – IPAM от SolarWinds и собственная система CMDB.noc.
IPAM – хранилище IP подсетей, самые правильные и верные данные по принадлежности IP адресов в компании должны быть здесь.
CMDB.noc – база данных с WEB-интерфейсом, где хранятся статичные данные по сетевому оборудованию – роутеры, коммутаторы, точки доступа, а также провайдеры и их характеристики. Под статичными подразумевается, что их изменение проводится только с участием человека. Другими словами, автодискаверинг не вносит изменения в эту базу, она нужна нам, чтобы понимать, что «должно» быть установлено на объекте. Своя база нужна как буфер между продуктивными системами, с которыми работает вся компания, и внутренними инструментами сети. Ускоряется разработка, добавление нужных полей, новых связей, корректировка параметров и т.д. Плюс этого решения не только в скорости разработки, но и в наличии тех связей между данными, которые необходимы именно нам, без компромиссов. Как мини-пример, мы используем несколько exid в базе для связи данных между IPAM, SAP и HPSM.
В итоге, получили полные данные по всем объектам, с привязанным сетевым оборудованием и IP-адресами. Теперь нам нужны шаблоны конфигураций, или сетевых сервисов, которые мы предоставляем на этих объектах.

Single Source of Truth
Здесь как раз мы дошли до применения первого принцип NaaC – хранения целевых конфигураций в репозитории. В нашем случае это Gitlab. Выбор для нас был несложным:
- Во-первых, у нас в компании уже есть этот инструмент, нам не нужно было разворачивать его с нуля
- Во-вторых, он вполне подходит под все наши текущие и будущие задачи по сетевой инфраструктуре
В Gitlab будет происходить основная интересная часть автоматизации – процесс изменения конфигурационного стандарта или, проще говоря, шаблона.
Пример процесса изменения стандарта
Один из типов объектов, который у нас есть — это магазин «Пятерочка». Там типовая топология состоит из одного роутера и одного/двух коммутаторов. Шаблонный конфигурационный файл хранится в Gitlab, в этой части все просто. Но это еще не совсем NaaC.Теперь допустим, к нам приходит новый проект. Задачи для нового IT-проекта – сделать пилот на некотором объеме магазинов. По результатам пилота – в случае успеха, сделать тиражирование на все объекты данного типа; в ином случае свернуть пилот без выполнения тиражирования.
Этот процесс очень хорошо ложится в логику Git:
- Для нового проекта мы создаем Branch, где выполняем изменения в конфигурациях
- В Branch также храним список объектов, на которых этот проект пилотируется
- В случае успеха мы делаем merge-request в master-ветку, которую необходимо будет тиражировать на prod-сеть
- В случае неудачи, либо оставляем Branch для истории, либо просто удаляем

В первом приближении — даже без автоматизации, это очень удобный инструмент для совместной работы над сетевой конфигурацией. Особенно, если представить, что проектов одновременно пришло три и больше. Когда придет время выпуска проектов в prod, нужно будет решить все конфликты конфигураций в merge-request'ах и проверить, что изменения настроек не взаимоисключающие. И это очень удобно делать в git.
Плюс подобный подход добавляет нам возможности гибко использовать инструменты Gitlab CI/CD для тестирования конфигураций виртуально, автоматизировать доставку конфигураций на тестовый стенд или пилотную группу объектов. //И даже на prod, если хотите.
Deploying configuration to any environment
Изначально, основной целью была именно массовая доставка конфигураций, как инструмент, который очень явно позволяет сэкономить время работы инженеров и ускорить выполнение задач по конфигурации. Для этого, еще до старта большой активности «Network as a Code», мы писали python-решение по подключению к оборудованию либо для сбора конфигураций оборудования, либо для его настройки. Это netmiko, это pysnmp, это jinja2 и etc.
Но для нас пришло время разделить массовую настройку на несколько подвидов:
- Доставка конфигураций в тестовые и пилотные зоныЭтот пункт основывается на Gitlab CI, который позволяет включить в pipeline доставку конфигураций на пилотные и тестовые зоны.
- Тиражирование конфигураций в prod
- Отдельный пункт, чаще всего тиражирование на 38k устройств происходит в несколько волн — нарастающим объемом — для мониторинга ситуации в prod. Плюс, работы таких масштабов требуют согласования проведения работ, следовательно запускать этот процесс лучше руками. Для этого удобно использовать Ansible +-AWX и прикручивать к нему динамическое составление inventory из наших систем мастер-данных.
- Как дополнение – это удобное решение, когда нужно отдать второй линии запуск преднастроенных playbook’ов, выполняющих сложные и важные операции, такие как переключение трафика между площадками.
- Сбор данных
- Автообнаружение сетевых устройств
- Бекапирование конфигураций
- Проверка возможности подключения
Эту задачу мы выделили в отдельный блок, так как бывают случаи когда кто-то вдруг демонтировал свитч или установил новое устройство, а мы об этом заранее не знали. Соответственно, это устройство не будет находится в наших мастер-данных и выпадет из процесса доставки конфигураций, мониторинга, да и в целом операционной работы. Бывает, оборудование было установлено легитимно, но конфигурацию туда «влили» некорректно и, по какой-то причине, там не работает ssh, snmp, aaa или нестандартные пароли для доступа. Для этого у нас есть python, чтобы перепробовать все возможные legacy-способы подключения, которые могли быть у нас в компании, сделать брут-форс по всем старым паролям, и все ради того чтобы попасть на железку и подготовить ее к работе с ansible и мониторингу.
Есть простой способ — сделать для ansible нескольких inventory-файлов, где описать все возможные данные для подключений (все типы вендоров со всеми возможными парами логин/пароль) и запустить playbook для каждого варианта inventory. Мы надеялись на лучшее решение, но на конференции RedHat архитектор Ansible посоветовал такой же способ. В основном предполагается, что ты знаешь заранее к чему подключаешься.
Нам захотелось универсального решения — при снятии бэкапа поискать новое оборудование и, если нашел, – добавить его во все необходимые системы. Поэтому, выбираем решение на python -ведь что может быть прекраснее программы, которая сама может обнаружить сетевую железку подключиться к ней вне зависимости от того, что на ней настроено (в разумных пределах, конечно), настроить как нужно, снять конфигурацию и, заодно, добавить в нужные системы данные о ней по API.
Verification like Monitoring
Одна из задач автоматизации — это, конечно, находить что из этой автоматизации выпало. Не все 38k настраиваются идеально с первого раза, бывает даже так, что кто-то настраивает оборудование руками. И необходимо отслеживать эти изменения и восстанавливать
Есть три подхода к проверке соответствия конфигураций стандарту:
- Делать проверку один раз в период — выгружать текущее состояние, сверять с целевым и исправлять выявленные недостатки.
- Ничего не проверяя, один раз в период — раскатывать целевые конфигурации. Правда тут есть риск что-нибудь сломать — может, в целевой конфигурации было не все.
- Удобный подход — когда отличия от целевой конфигурации в Single Source of Truth считаются алертом и фиксируются системой мониторинга. К этому относятся: несовпадение с текущим стандартом конфигурации, отличие железа от указанного в мастер-данных, несовпадение с данными в IPAM.
В третьем случае появляется опция передать эту работу в инцидент-менеджмент (операционку), чтобы несоответствия устранялись малыми порциями в течении всего времени, чем один раз авралом.
Zabbix, о котором я писал ранее в статье «Как мы делали мониторинг 14000 объектов» — наша система мониторинга распределенных объектов, где мы можем делать любые триггеры и алерты, которые придумаем. С момента написания прошлой статьи мы обновились до Zabbix 4.0 LTS.
На основе Web Zabbix мы сделали update нашего портала сетевой поддержки, где теперь можно найти всю информацию по объекту из всех наших систем на одном экране, а также запустить скрипты для проверки часто возникающих проблем.
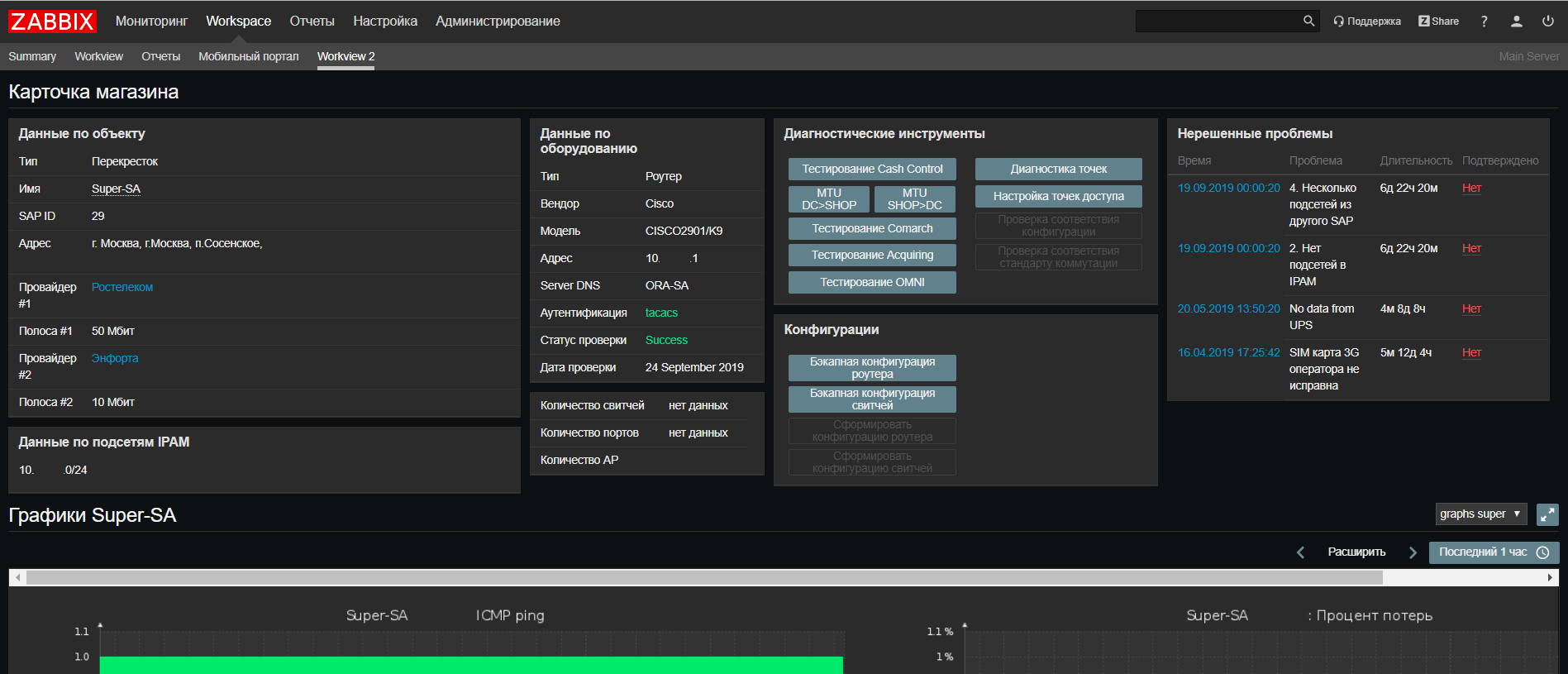
Также мы ввели новую фишечку — для нас Zabbix стал в некотором роде CRON'ом для запуска скриптов по расписанию, таких как скрипты интеграции систем, скрипты автодискаверинга. Это действительно удобно, когда нужно посмотреть текущие скрипты и когда и где они запускаются, не проверяя все сервера. Правда, для скриптов, выполняющихся больше 30 секунд, понадобится launcher, который их запускает, не дожидаясь окончания. К счастью, он несложный:
launcher.sh
#!/bin/bash
nohup $* > /dev/null 2>/dev/null &
echo $(date) Started job for $*
Splunk – решение которое позволяет собирать журналы событий с сетевого оборудования, и это можно использовать также для мониторинга автоматизации. Например, собирая бекап конфигурации, python-скрипт генерирует LOG-сообщение CFG-5-BACKUP, роутер или свитч отправляет сообщение в Splunk, в котором мы считаем количество сообщений данного типа от сетевого оборудования. Это позволяет нам отслеживать количество оборудования, которое обнаружил скрипт. И мы видим, сколько железок смогли сообщить об этом в Splunk и верифицировать, что сообщения от всех железок дошли.
Spectrum – комплексная система, используется у нас для мониторинга критичных объектов, довольно мощный инструмент, который нам очень помогает в решении критичных инцидентов по сети. В автоматизации мы его используем только дергая из него данные, это не open-source, поэтому возможности несколько ограничены.
The cherry on the cake
 Используя системы с мастер-данными по оборудованию мы можем задуматься о создании ZTP, или Zero Touch Provisioning. Как кнопка «автонастройка», но только без кнопки.
Используя системы с мастер-данными по оборудованию мы можем задуматься о создании ZTP, или Zero Touch Provisioning. Как кнопка «автонастройка», но только без кнопки.Все необходимые данные у нас есть из предыдущих блоков – мы знаем объект, его тип, какое там оборудование (вендор и модель), какие там адреса (IPAM), какой текущий стандарт конфигурации (Git). Собрав их все вместе, мы можем как минимум подготовить шаблон конфигурации для заливки на устройство, это будет скорее похоже на One Touch Provisioning, но иногда большего и не требуется.
Для True Zero Touch нужен способ автоматической доставки конфигурации на ненастроенное оборудование. Причем, желательно вне зависимости от вендора. Есть несколько рабочих вариантов – консольный сервер, если все оборудование проходит через центральный склад, мобильные консольные решения, если оборудование сразу приезжает на место. Эти решения мы пока только прорабатываем, но как только будет рабочий вариант, сможем им поделиться.
Заключение
Итого, в нашей концепции Network as a Code получилось 5 основных вех:
- Мастер-данные (связь систем и данных между собой, API систем, достаточность данных для поддержки и запуска)
- Мониторинг данных и конфигураций (автодискаверинг сетевых устройств, проверки на актуальность конфигурации на объекте)
- Контроль версий, тестирование и пилотирование конфигураций (Gitlab CI/CD в применении к сети, инструменты тестирования сетевых конфигураций)
- Доставка конфигураций (Ansible, AWX, python-скрипты для подключения)
- Zero Touch Provisioning (Какие данные нужны, как выстроить процесс, чтобы они были, как подключиться к ненастроенной железке)
Вместить все в одну статью не получилось, каждый пункт достоин отдельного обсуждения, о чем-то мы можем рассказать уже сейчас, о чем-то когда проверим решения на практике. Если есть заинтересованность в какой-то из тем — в конце будет опрос, где можно проголосовать за следующую статью. Если тема в список не вошла, но интересно про нее почитать — оставьте комментарий, как только сможем, обязательно поделимся нашим опытом.
Отдельное спасибо Вирилину Александру(xscrew) и Сибгатулину Марату(eucariot) за рефернс-визит осенью 2018 в yandex-облако и рассказ об автомейшне в сетевой инфраструктуре облака. После него у нас появилось вдохновение и множество идей о применении автоматизации и NetDevOps'а в инфраструктуре X5 Retail Group.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какая тема следующей статьи интереснее?
51.16% Мастер-данные сетевой инфраструктуры, как хранить и связать данные, что делать если их нет.22
76.74% Мониторинг данных и конфигураций. Автодискаверинг на Python и Zabbix.33
65.12% База сетевых адресов (IPAM + проверки на достоверность)28
0% Другие, лучше напишу в комментариях.0
0% Никакие, ничего не нравится.0
Проголосовали 43 пользователя. Воздержались 6 пользователей.
