Я работаю в JetBrains Research в группе, занимающейся применением методов машинного обучения в области программной инженерии. В данной статье я расскажу об одном из наших проектов — автоматической системе подсказок для онлайн-курсов по программированию.
Онлайн-курсы по программированию — популярный способ получения дополнительного образования. На таких курсах учащимся предлагается прочитать текст либо посмотреть видео с объяснением нового материала, а потом решить несколько практических задач. Автоматическая проверяющая система запускает каждое присланное решение на заранее подготовленном наборе тестов и сообщает учащемуся результаты тестирования. Такой вид обучения имеет ряд очевидных преимуществ перед традиционной системой образования: число учащихся неограниченно, они могут учиться в любое удобное время и в любом удобном месте. Однако имеются и недостатки. Например, слабая обратная связь. Преподаватели объясняют ученикам, в чем заключаются их ошибки и на что стоит обратить внимание, в то время как автоматическая проверяющая система может лишь проверить корректность решения. Разумеется, можно попросить помощи у создателей курса в комментариях, но зачастую ответ приходится ждать долго, особенно если таких просьб много. Эту проблему может решить автоматическая система выдачи подсказок.
К сожалению, классические подходы к поиску проблем в исходном коде (определение «запахов» кода, рекомендация рефакторингов, прогнозирование ошибок) здесь не эффективны, так как они разрабатывались для больших промышленных проектов, а решения практических задач обычно состоят всего из одного метода. Однако есть и специально спроектированные для нашей задачи решения. Обычно в них так или иначе анализируется разница между неправильным решением и правильным, а потом с помощью шаблонов генерируется подсказка вроде «в строке 26 замените int на long». Такие подсказки указывают, как нужно исправить решение, но не говорят, в чём состоит ошибка, и поэтому далеки от объяснений преподавателей. Таким образом, учащиеся лишаются мотивации к самостоятельному анализу ошибки. Преподаватели обычно говорят: «Обратите внимание на ограничение на размер входных данных, — или, — у вас переполнение int-а». В нашем исследовании мы ставили себе цель давать более высокоуровневые подсказки, которые помогают вам исправить решения, а не исправляют их за вас.
Для дальнейшего рассказа нам понадобится ввести несколько понятий.
Абстрактное синтаксическое дерево (AST) — это представление программного кода в виде дерева, содержащее полную информацию о семантике кода, но опускающее синтаксические подробности (форматирование, скобки, запятые). Каждая вершина в дереве имеет тип (number_literal, primitive_type, for_statement и т.п.) и метку («1», «566» и т.д. для number_literal; «int», «long», «double» и т.д. для primitive_type; пустая строка для for_statement).
Сценарий редактирования — это последовательность элементарных модификаций (добавление вершины, удаление вершины, перемещение вершины, изменение метки вершины), преобразующих одно абстрактное синтаксическое дерево в другое. Для построения AST и генерации сценариев редактирования мы использовали библиотеку GumTree.
Для примера рассмотрим два фрагмента кода:
Для первого AST будет выглядеть так:
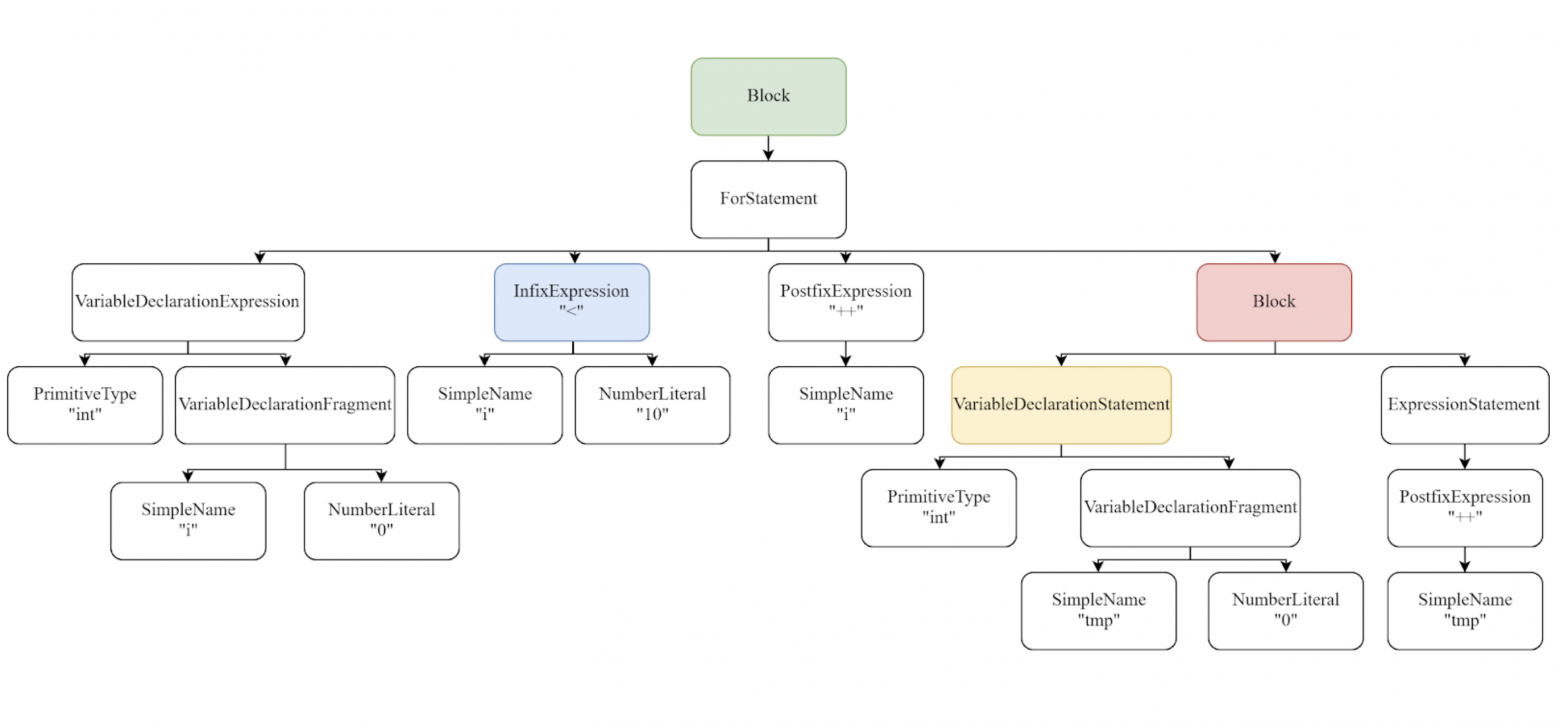
А для второго вот так:
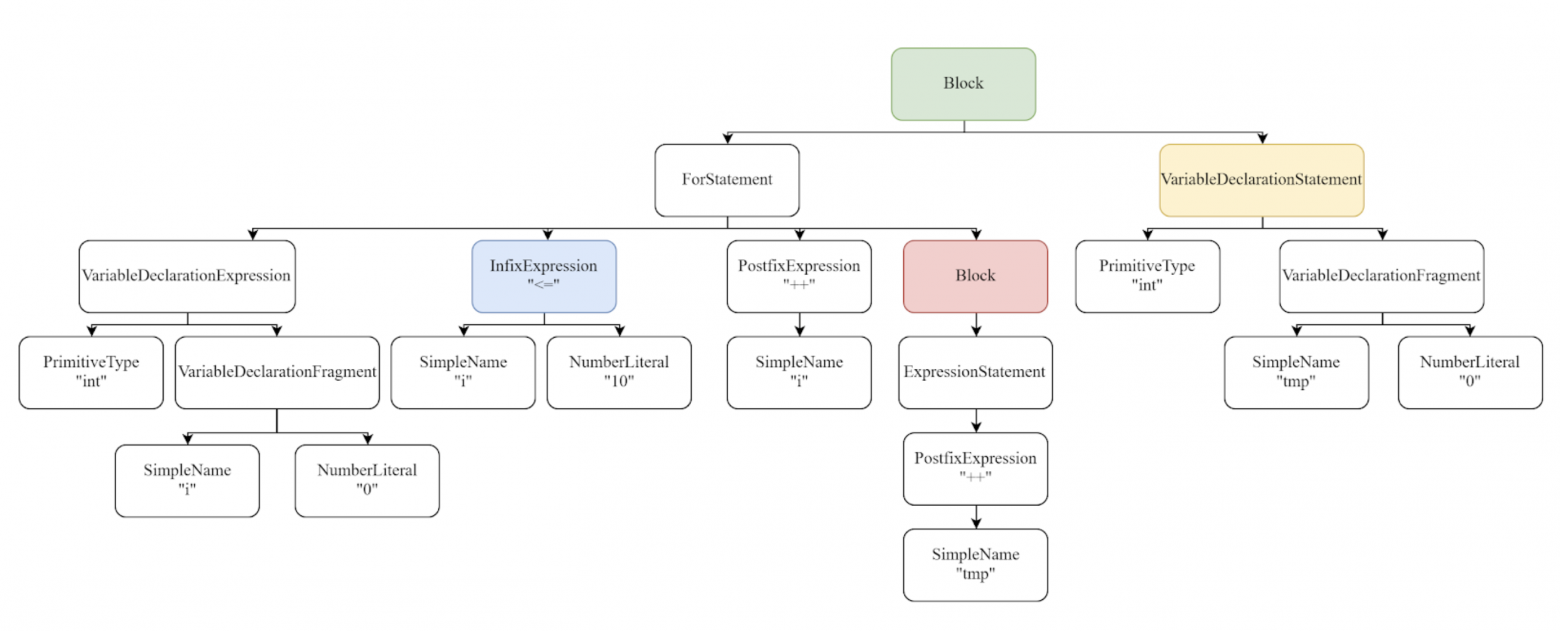
Для удобства некоторые вершины подсвечены цветами. Тогда сценарий редактирования, превращающий первое дерево во второе, будет выглядеть условно вот так:

Итак, сравнивая неправильное решение с правильным, мы можем получить его исправление в формате сценария редактирования. Вопрос в том, как этому исправлению сопоставить подсказку. Если бы для всех исправлений уже присланных решений кто-нибудь написал подсказки, то задача свелась бы к классической задаче классификации. Но к сожалению, данные обычно не размечены. Для решения этой проблемы мы выделяем частые ошибки и размечаем хотя бы их. В перспективе на стадии разметки эксперты должны писать подсказки — связный текст, который призван помочь учащимся исправить решения. Полученная размеченная выборка исправлений использовалась для обучения классификатора. Теперь поговорим о каждом этапе подробнее.
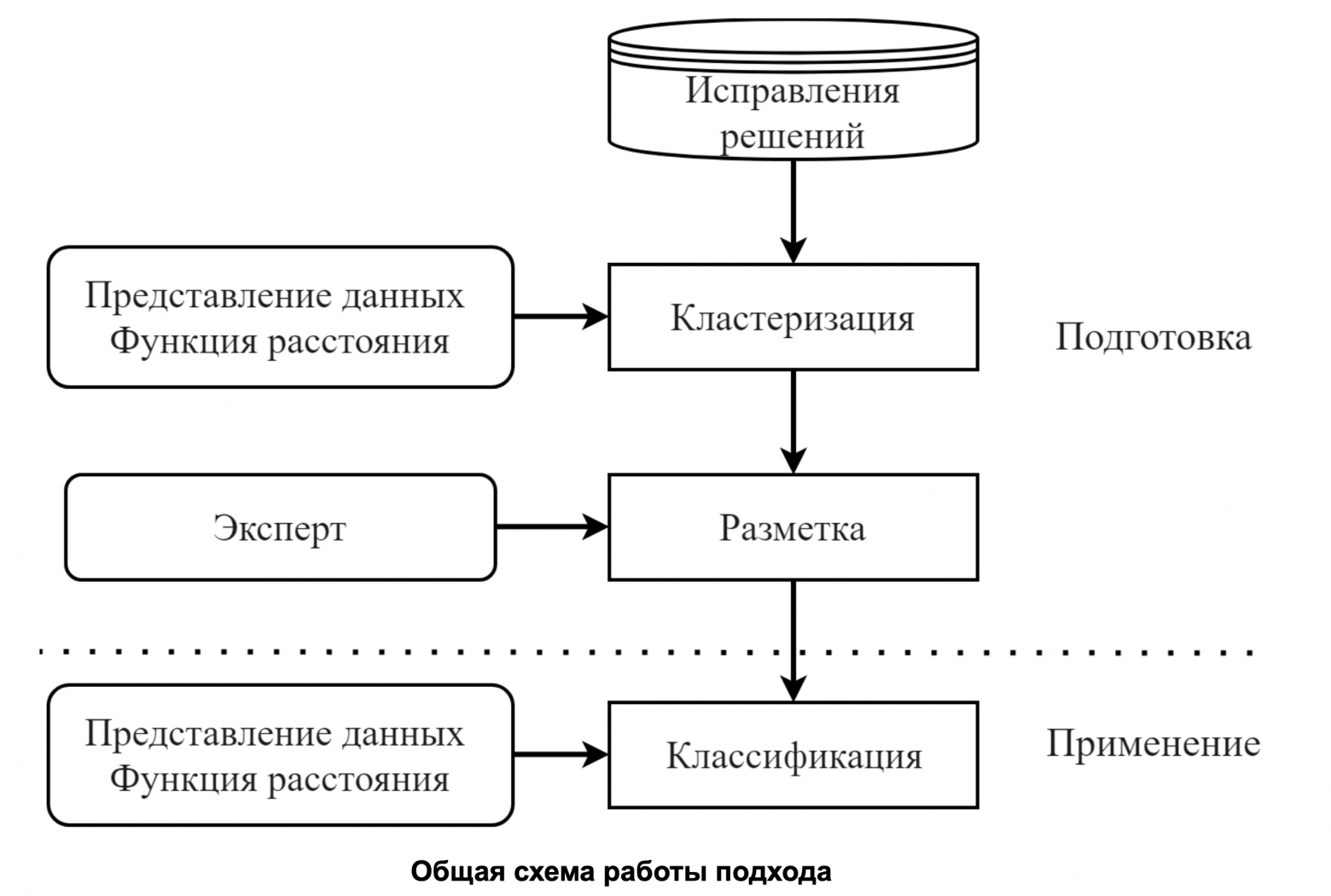
Шаг первый: подготовка данных. Для начала отсеивались неправильные решения, для которых было невозможно построить AST. Далее из решений удалялись комментарии, стандартизировались имена переменных, приводились к одному виду изоморфные конструкции (удалялись лишние скобки в математических выражениях, проставлялись необязательные скобки в if-ах и for-ах, упорядочивались в алфавитном порядке типы в конструкции объединения типов в try-catch).
Шаг второй: выделение исправлений. Изначально планировалось на стадии кластеризации использовать изменения между последним неправильным решением и первым правильным для каждой сессии. Однако оказалось, что одну и ту же ошибку можно исправлять множеством способов. Чтобы стандартизировать способ исправления ошибки, было решено искать разницу не с правильным решением из той же сессии, а со всеми известными правильными решениями и использовать самый короткий из получившихся сценариев редактирования. На стадии классификации для нового неправильного решения сценарий редактирования искался так же.
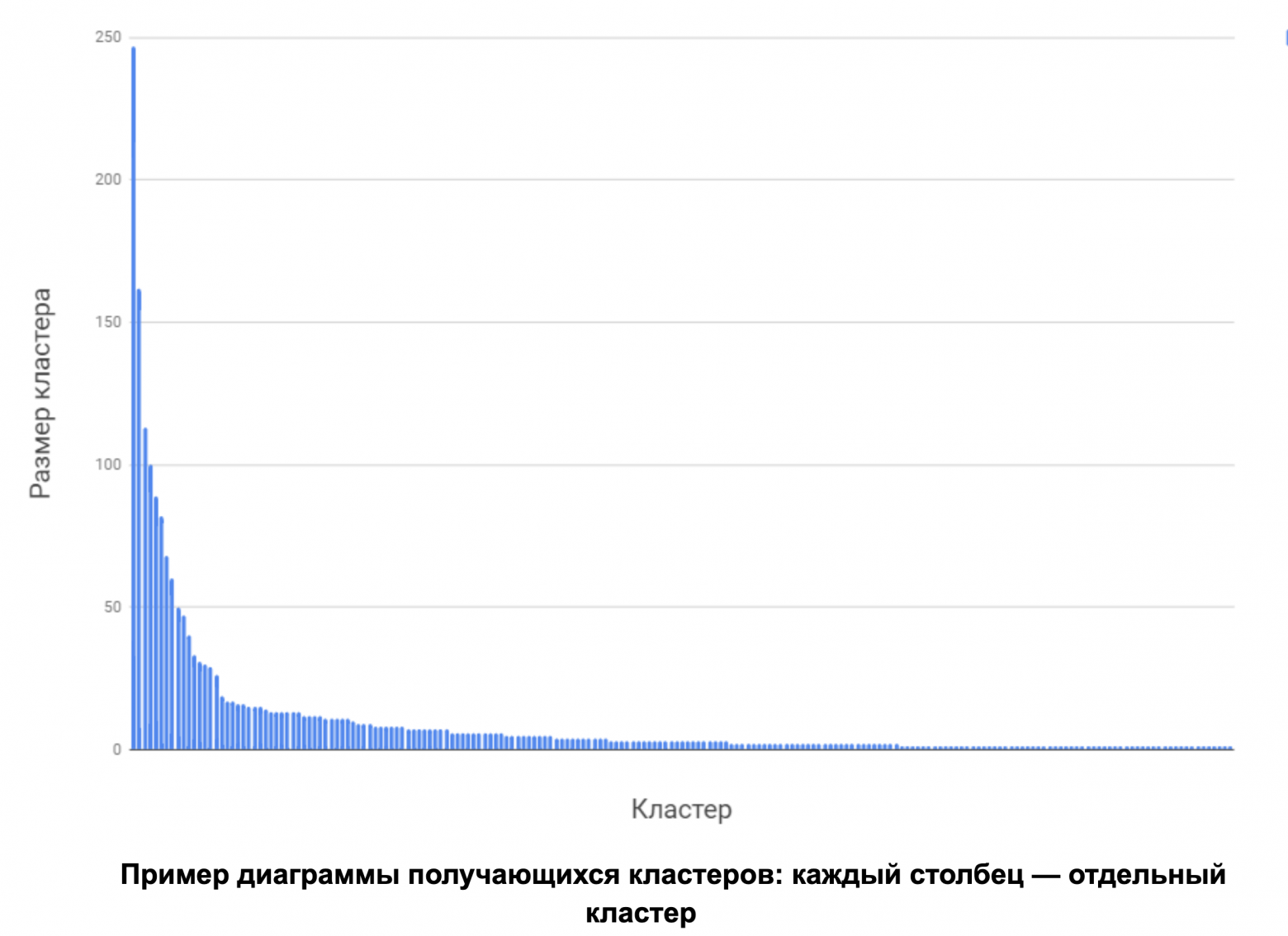
Шаг третий: выявление типичных ошибок. База исправлений решений одной задачи кластеризовалась с помощью алгоритма иерархической агломеративной кластеризации. Этот алгоритм работает следующим образом: сначала каждый элемент помещается в свой кластер, затем на каждом шаге находится пара ближайших кластеров и объединяется в один. Этот процесс завершается, если расстояние между ближайшими кластерами слишком большое либо если осталось слишком мало кластеров. Какое-то количество самых больших из получившихся кластеров размечалось вручную. Пример диаграммы получающихся кластеров показан ниже.
Шаг четвёртый: построение классификатора. В данной работе использовался алгоритм k ближайших соседей со взвешенным голосованием. Для классификации нового элемента находится k ближайших к нему элементов из обучающей выборки, которые голосуют за класс, которому они принадлежат, причём чем ближе элемент к новому, тем больше весит его голос. При классификации стоит помнить, что возможные ошибки не ограничиваются теми, которые мы нашли на третьем шаге, поэтому важен не только результат классификации, но и степень уверенности в нём. Если уверенность ниже порогового значения, то считается, что определить ошибку и, соответственно, выдать подсказку не удалось.
Можно заметить, что использовавшиеся алгоритмы классификации и кластеризации требовали для работы задания функции расстояния между сценариями редактирования. Была проведена обширная работа для сравнения различных подходов. Далее кратко описаны рассматривавшиеся подходы.
Классической функцией расстояния между двумя множествами является коэффициент Жаккара. Для пары мультимножеств A и B значение коэффициента Жаккара можно вычислить по формуле: . В зависимости от определения равенства элементарных модификаций, можно получить несколько итоговых функций расстояния.
. В зависимости от определения равенства элементарных модификаций, можно получить несколько итоговых функций расстояния.
Для работы со сценариями редактирования и элементарными модификациями удобно их векторизовать. Векторизация элементарных модификаций в данной работе была сделана с помощью автокодировщика — подхода, позволяющего сжимать разреженные данные в вектор с минимальной потерей информации. В качестве автокодировщика использовалась нейронная сеть с одним скрытым слоем, при этом размеры входного и выходного слоя совпадали, а скрытый слой имел значительно меньший размер. Условная архитектура автокодировщика показана ниже.
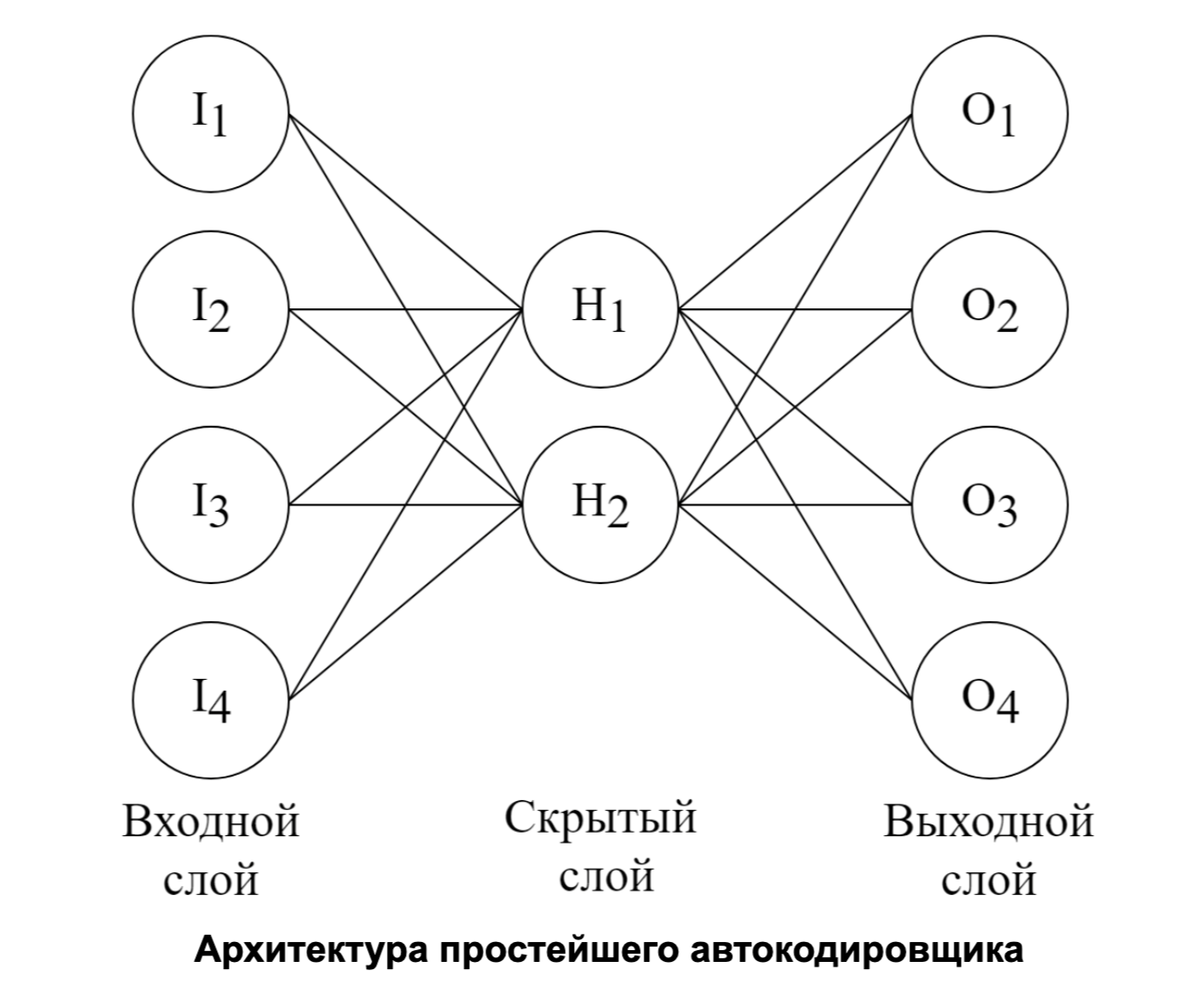
Если сложить векторы для элементарных модификаций, то можно получить вектор, характеризующий сценарий редактирования в целом. В качестве функции расстояния между векторами использовалось косинусное расстояние.
Также можно определить нечёткий коэффициент Жаккара, опирающийся не на равенство элементов, а на степень их схожести. Схожесть элементарных модификаций можно определить эвристической формулой или с помощью косинусного расстояния и векторизации из предыдущего пункта.
Последний использовавшийся подход — bag-of-words или мешок слов. В рамках данного подхода сначала элементарные модификации кодируются в строки несколькими способами с учётом разной информации о контексте, затем составляется словарь таких строк, каждому элементу присваивается уникальный числовой идентификатор, а потом для мультимножества элементов в качестве векторного представления используется вектор, i-ая компонента которого равна количеству элементов i-ого типа. Расстояние между векторами опять косинусное.
Теперь перейдём к практической части. В данной работе использовался анонимизированный датасет решений на языке Java, предоставленный платформой Stepik. Итак, мы получили некий возможный подход к решению, но ещё необходимо подобрать оптимальные параметры. Для этого были выбраны 4 задачи, отличающиеся тематикой и средним размером решения. Из каждой сессии решений по этим задачам была выбрана последняя неправильная попытка (при наличии) и первая правильная (при наличии). Получившаяся выборка была разделена на тестовую и обучающую. Тестовая выборка и часть обучающей были размечены вручную.
Сначала необходимо определить метрику качества решения. В нашей работе была выбрана метрика Area Under Precision-Recall Curve. Для её использования мы считаем значения Precision и Recall при разных значениях пороговой уверенности классификатора, а потом считаем площадь под получившейся кривой. Чем больше полученное значение, тем лучше классификация.
Получившиеся кривые Precision-Recall показаны ниже:
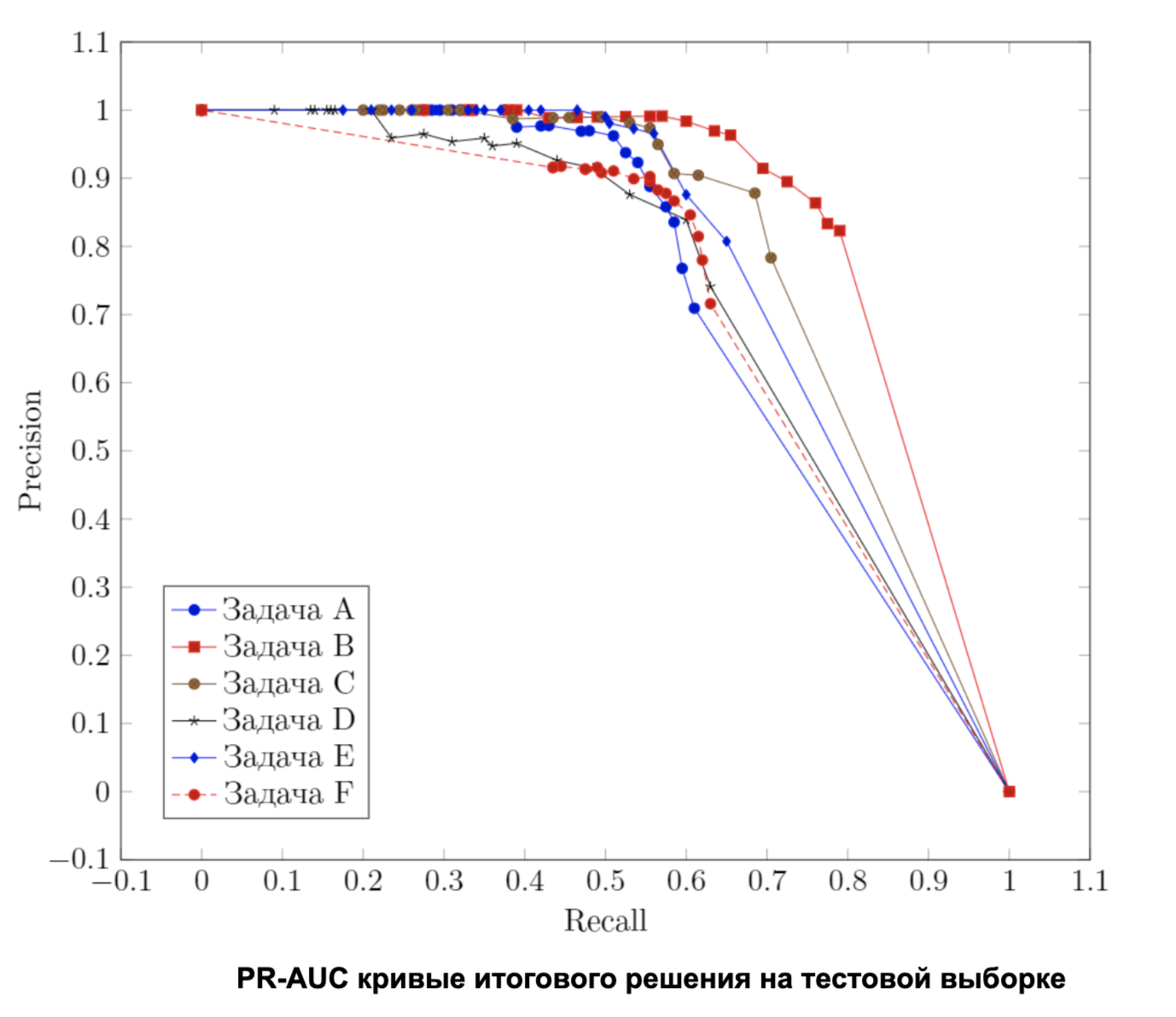
Для оценки качества комбинации параметров использовалась кросс-валидация. Размеченная часть обучающей выборки разбивалась на 10 частей, после чего 9 частей вместе с неразмеченной частью подвергались кластеризации. Полученные кластеры автоматически размечались на основе попавших в них размеченных элементов. Процесс повторялся 10 раз, результат тестирования усреднялся. Для получения независимой оценки лучшая конфигурация была протестирована на тестовых выборках 6 задач (в том числе двух, не участвовавших в подборе параметров).
Цифры — это очень увлекательно, но давайте посмотрим, какие ошибки мы таким образом научились отлавливать. Для примера рассмотрим задачу E. В этой задаче требуется найти минимум и максимум в потоке. Подробнее с условиями можно ознакомиться здесь. Рассмотрим несколько кластеров.
В этот кластер попали решения, в которых учащиеся забыли обработать случай пустого потока и, соответственно, пустой коллекции. Сами решения довольно разнообразны, но исправления похожи: добавляется if, который проверяет размер коллекции/массива и передаёт в метод accept либо их элементы, либо null.
Ожидается, что каждый экземпляр класса Stream будет использован только один раз. В этот кластер попали решения, в которых есть попытки повторного использования потока.
Эти решения можно исправить, сохранив сначала все значения потока в коллекцию, а потом использовав её для создания нескольких новых потоков.
Ещё одной частой проблемой является сортировка без использования переданного в качестве параметра компаратора.
Такие решения исправляются передачей компаратора в соответствующее место.
Если объект Optional ничего не хранил, то при попытке получить его содержимое возникнет исключение. Для исправления таких решений следует использовать метод getOrElse вместо get либо проверять наличие объекта перед извлечением.
В отличие от инструкции return, вызов метода accept не завершает выполнение метода. Такие решения исправляются добавлением инструкции return после вызова accept или переносом остального кода в блок else.
В списке из n элементов последний имеет индекс n-1.
Должен ли компаратор корректно обрабатывать null-значения — вопрос философский. Использовавшаяся реализация компаратора не ожидала получить значение null. В самом потоке нет null-ов, но если хранить где-то промежуточный результат, то начальным значением может быть null.
Платформа ожидала получить решение в виде одного метода, но многие пользователи присылали полноценную программу с объявлением внешнего класса и импортами.
Все функциональные методы класса Stream возвращают новый экземпляр класса, а не модифицируют старый.
В случае пустого потока ожидалось, что будут переданы значения null. В некоторых решениях в этом случае метод accept вообще не вызывался.
Некоторые решения пытаются явно проверять пустоту потоков, но делают это неправильно. В некоторых случаях проверки получаются бессмысленными (например, никакой объект не может быть equals значению null), а count — терминальная операция, поэтому её использование делает невозможным дальнейшее использование потока.
Также учащиеся часто путались в знаках сравнения.
Из полученных результатов можно сделать вывод, что выбранный подход может применяться для автоматической выдачи подсказок на обучающей онлайн-платформе. В данной работе использовался простейший алгоритм классификации. Сейчас мы исследуем применимость в данной задаче более сложных нейросетевых подходов. Их использование осложнено сравнительно небольшим количеством решений, но предварительные данные показывают, что такие подходы всё равно дают преимущество в качестве итоговой классификации. Исходный код проекта можно найти здесь. О других проектах нашей группы можно узнать тут.
Автор статьи: Артём Лобанов, исследователь лаборатории методов машинного обучения в программной инженерии в JetBrains Research.
Онлайн-курсы по программированию — популярный способ получения дополнительного образования. На таких курсах учащимся предлагается прочитать текст либо посмотреть видео с объяснением нового материала, а потом решить несколько практических задач. Автоматическая проверяющая система запускает каждое присланное решение на заранее подготовленном наборе тестов и сообщает учащемуся результаты тестирования. Такой вид обучения имеет ряд очевидных преимуществ перед традиционной системой образования: число учащихся неограниченно, они могут учиться в любое удобное время и в любом удобном месте. Однако имеются и недостатки. Например, слабая обратная связь. Преподаватели объясняют ученикам, в чем заключаются их ошибки и на что стоит обратить внимание, в то время как автоматическая проверяющая система может лишь проверить корректность решения. Разумеется, можно попросить помощи у создателей курса в комментариях, но зачастую ответ приходится ждать долго, особенно если таких просьб много. Эту проблему может решить автоматическая система выдачи подсказок.
К сожалению, классические подходы к поиску проблем в исходном коде (определение «запахов» кода, рекомендация рефакторингов, прогнозирование ошибок) здесь не эффективны, так как они разрабатывались для больших промышленных проектов, а решения практических задач обычно состоят всего из одного метода. Однако есть и специально спроектированные для нашей задачи решения. Обычно в них так или иначе анализируется разница между неправильным решением и правильным, а потом с помощью шаблонов генерируется подсказка вроде «в строке 26 замените int на long». Такие подсказки указывают, как нужно исправить решение, но не говорят, в чём состоит ошибка, и поэтому далеки от объяснений преподавателей. Таким образом, учащиеся лишаются мотивации к самостоятельному анализу ошибки. Преподаватели обычно говорят: «Обратите внимание на ограничение на размер входных данных, — или, — у вас переполнение int-а». В нашем исследовании мы ставили себе цель давать более высокоуровневые подсказки, которые помогают вам исправить решения, а не исправляют их за вас.
Для дальнейшего рассказа нам понадобится ввести несколько понятий.
Абстрактное синтаксическое дерево (AST) — это представление программного кода в виде дерева, содержащее полную информацию о семантике кода, но опускающее синтаксические подробности (форматирование, скобки, запятые). Каждая вершина в дереве имеет тип (number_literal, primitive_type, for_statement и т.п.) и метку («1», «566» и т.д. для number_literal; «int», «long», «double» и т.д. для primitive_type; пустая строка для for_statement).
Сценарий редактирования — это последовательность элементарных модификаций (добавление вершины, удаление вершины, перемещение вершины, изменение метки вершины), преобразующих одно абстрактное синтаксическое дерево в другое. Для построения AST и генерации сценариев редактирования мы использовали библиотеку GumTree.
Для примера рассмотрим два фрагмента кода:
for (int i = 0; i < 10; i++) {
int tmp = 0;
tmp++;
}int tmp = 0;
for (int i = 0; i <= 10; i++) {
tmp++;
}Для первого AST будет выглядеть так:

А для второго вот так:

Для удобства некоторые вершины подсвечены цветами. Тогда сценарий редактирования, превращающий первое дерево во второе, будет выглядеть условно вот так:

Итак, сравнивая неправильное решение с правильным, мы можем получить его исправление в формате сценария редактирования. Вопрос в том, как этому исправлению сопоставить подсказку. Если бы для всех исправлений уже присланных решений кто-нибудь написал подсказки, то задача свелась бы к классической задаче классификации. Но к сожалению, данные обычно не размечены. Для решения этой проблемы мы выделяем частые ошибки и размечаем хотя бы их. В перспективе на стадии разметки эксперты должны писать подсказки — связный текст, который призван помочь учащимся исправить решения. Полученная размеченная выборка исправлений использовалась для обучения классификатора. Теперь поговорим о каждом этапе подробнее.

Шаг первый: подготовка данных. Для начала отсеивались неправильные решения, для которых было невозможно построить AST. Далее из решений удалялись комментарии, стандартизировались имена переменных, приводились к одному виду изоморфные конструкции (удалялись лишние скобки в математических выражениях, проставлялись необязательные скобки в if-ах и for-ах, упорядочивались в алфавитном порядке типы в конструкции объединения типов в try-catch).
Шаг второй: выделение исправлений. Изначально планировалось на стадии кластеризации использовать изменения между последним неправильным решением и первым правильным для каждой сессии. Однако оказалось, что одну и ту же ошибку можно исправлять множеством способов. Чтобы стандартизировать способ исправления ошибки, было решено искать разницу не с правильным решением из той же сессии, а со всеми известными правильными решениями и использовать самый короткий из получившихся сценариев редактирования. На стадии классификации для нового неправильного решения сценарий редактирования искался так же.
Шаг третий: выявление типичных ошибок. База исправлений решений одной задачи кластеризовалась с помощью алгоритма иерархической агломеративной кластеризации. Этот алгоритм работает следующим образом: сначала каждый элемент помещается в свой кластер, затем на каждом шаге находится пара ближайших кластеров и объединяется в один. Этот процесс завершается, если расстояние между ближайшими кластерами слишком большое либо если осталось слишком мало кластеров. Какое-то количество самых больших из получившихся кластеров размечалось вручную. Пример диаграммы получающихся кластеров показан ниже.

Шаг четвёртый: построение классификатора. В данной работе использовался алгоритм k ближайших соседей со взвешенным голосованием. Для классификации нового элемента находится k ближайших к нему элементов из обучающей выборки, которые голосуют за класс, которому они принадлежат, причём чем ближе элемент к новому, тем больше весит его голос. При классификации стоит помнить, что возможные ошибки не ограничиваются теми, которые мы нашли на третьем шаге, поэтому важен не только результат классификации, но и степень уверенности в нём. Если уверенность ниже порогового значения, то считается, что определить ошибку и, соответственно, выдать подсказку не удалось.
Можно заметить, что использовавшиеся алгоритмы классификации и кластеризации требовали для работы задания функции расстояния между сценариями редактирования. Была проведена обширная работа для сравнения различных подходов. Далее кратко описаны рассматривавшиеся подходы.
Классической функцией расстояния между двумя множествами является коэффициент Жаккара. Для пары мультимножеств A и B значение коэффициента Жаккара можно вычислить по формуле:
. В зависимости от определения равенства элементарных модификаций, можно получить несколько итоговых функций расстояния. Для работы со сценариями редактирования и элементарными модификациями удобно их векторизовать. Векторизация элементарных модификаций в данной работе была сделана с помощью автокодировщика — подхода, позволяющего сжимать разреженные данные в вектор с минимальной потерей информации. В качестве автокодировщика использовалась нейронная сеть с одним скрытым слоем, при этом размеры входного и выходного слоя совпадали, а скрытый слой имел значительно меньший размер. Условная архитектура автокодировщика показана ниже.

Если сложить векторы для элементарных модификаций, то можно получить вектор, характеризующий сценарий редактирования в целом. В качестве функции расстояния между векторами использовалось косинусное расстояние.
Также можно определить нечёткий коэффициент Жаккара, опирающийся не на равенство элементов, а на степень их схожести. Схожесть элементарных модификаций можно определить эвристической формулой или с помощью косинусного расстояния и векторизации из предыдущего пункта.
Последний использовавшийся подход — bag-of-words или мешок слов. В рамках данного подхода сначала элементарные модификации кодируются в строки несколькими способами с учётом разной информации о контексте, затем составляется словарь таких строк, каждому элементу присваивается уникальный числовой идентификатор, а потом для мультимножества элементов в качестве векторного представления используется вектор, i-ая компонента которого равна количеству элементов i-ого типа. Расстояние между векторами опять косинусное.
Теперь перейдём к практической части. В данной работе использовался анонимизированный датасет решений на языке Java, предоставленный платформой Stepik. Итак, мы получили некий возможный подход к решению, но ещё необходимо подобрать оптимальные параметры. Для этого были выбраны 4 задачи, отличающиеся тематикой и средним размером решения. Из каждой сессии решений по этим задачам была выбрана последняя неправильная попытка (при наличии) и первая правильная (при наличии). Получившаяся выборка была разделена на тестовую и обучающую. Тестовая выборка и часть обучающей были размечены вручную.
Сначала необходимо определить метрику качества решения. В нашей работе была выбрана метрика Area Under Precision-Recall Curve. Для её использования мы считаем значения Precision и Recall при разных значениях пороговой уверенности классификатора, а потом считаем площадь под получившейся кривой. Чем больше полученное значение, тем лучше классификация.
Получившиеся кривые Precision-Recall показаны ниже:

Для оценки качества комбинации параметров использовалась кросс-валидация. Размеченная часть обучающей выборки разбивалась на 10 частей, после чего 9 частей вместе с неразмеченной частью подвергались кластеризации. Полученные кластеры автоматически размечались на основе попавших в них размеченных элементов. Процесс повторялся 10 раз, результат тестирования усреднялся. Для получения независимой оценки лучшая конфигурация была протестирована на тестовых выборках 6 задач (в том числе двух, не участвовавших в подборе параметров).
| Задача | Кросс-валидация | Тестовая выборка |
|---|---|---|
| A | 0.770 | 0.741 |
| B | 0.858 | 0.857 |
| C | 0.793 | 0.793 |
| D | 0.713 | 0.727 |
| E | - | 0.778 |
| F | - | 0.722 |
Цифры — это очень увлекательно, но давайте посмотрим, какие ошибки мы таким образом научились отлавливать. Для примера рассмотрим задачу E. В этой задаче требуется найти минимум и максимум в потоке. Подробнее с условиями можно ознакомиться здесь. Рассмотрим несколько кластеров.
Обращение к элементам пустых коллекций/массивов
В этот кластер попали решения, в которых учащиеся забыли обработать случай пустого потока и, соответственно, пустой коллекции. Сами решения довольно разнообразны, но исправления похожи: добавляется if, который проверяет размер коллекции/массива и передаёт в метод accept либо их элементы, либо null.
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
Object[] array = stream.sorted(order).toArray();
minMaxConsumer.accept((T) array[0], (T) array[array.length - 1]);
}Повторное использование Stream
Ожидается, что каждый экземпляр класса Stream будет использован только один раз. В этот кластер попали решения, в которых есть попытки повторного использования потока.
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
if (stream.count() == 0) {
minMaxConsumer.accept(null, null);
} else {
T min = stream.min(order).get();
T max = stream.max(order).get();
minMaxConsumer.accept(min, max);
}
}
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
T min = stream.min(order).orElse(null);
T max = stream.max(order).orElse(null);
minMaxConsumer.accept(min, max);
}Эти решения можно исправить, сохранив сначала все значения потока в коллекцию, а потом использовав её для создания нескольких новых потоков.
Сортировка без использования компаратора
Ещё одной частой проблемой является сортировка без использования переданного в качестве параметра компаратора.
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
List<T> list = stream.sorted()
.collect(Collectors.toList());
if (list.isEmpty()) {
minMaxConsumer.accept(null, null);
} else {
minMaxConsumer.accept(list.get(0),
list.get(list.size() - 1));
}
}
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
Object[] array = stream.sorted().toArray();
if (array.length > 0)
minMaxConsumer.accept((T) array[0],
(T) array[array.length - 1]);
else
minMaxConsumer.accept(null, null);
}Такие решения исправляются передачей компаратора в соответствующее место.
Неаккуратное использование Optional
Если объект Optional ничего не хранил, то при попытке получить его содержимое возникнет исключение. Для исправления таких решений следует использовать метод getOrElse вместо get либо проверять наличие объекта перед извлечением.
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
List<T> list = stream.collect(Collectors.toList());
minMaxConsumer.accept(list.stream().min(order).get(),
list.stream().max(order).get());
}
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
final List<Optional<T>> minMax= Arrays.asList(
Optional.empty(),
Optional.empty());
stream.peek(x -> {
if (minMax.get(0).isEmpty()) {
minMax.set(0, Optional.of(x));
minMax.set(1, Optional.of(x));
} else {
if (order.compare(x, minMax.get(0).get()) < 0) {
minMax.set(0, Optional.of(x));
}
if (order.compare(x, minMax.get(1).get()) > 0) {
minMax.set(1, Optional.of(x));
}
}
}).count();
minMaxConsumer.accept(minMax.get(0).get(), minMax.get(1).get());
}
Повторный вызов метода accept
В отличие от инструкции return, вызов метода accept не завершает выполнение метода. Такие решения исправляются добавлением инструкции return после вызова accept или переносом остального кода в блок else.
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
List<T> list = stream.sorted(order)
.collect(Collectors.toList());
if (list.isEmpty())
minMaxConsumer.accept(null, null);
minMaxConsumer.accept(list.get(0),
list.get(list.size() - 1));
}
Неправильный индекс последнего элемента
В списке из n элементов последний имеет индекс n-1.
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
List<T> list = stream.sorted(order)
.collect(Collectors.toList());
if (list.isEmpty()) {
minMaxConsumer.accept(null, null);
} else {
minMaxConsumer.accept(list.get(0), list.get(list.size()));
}
}Использование null-значений с компаратором
Должен ли компаратор корректно обрабатывать null-значения — вопрос философский. Использовавшаяся реализация компаратора не ожидала получить значение null. В самом потоке нет null-ов, но если хранить где-то промежуточный результат, то начальным значением может быть null.
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
Object[] minMaxHolder = new Object[]{null, null};
stream.forEach(val -> {
if (order.compare(val, (T) minMaxHolder[0]) < 0) {
m[0] = val;
}
if (order.compare(val, (T) minMaxHolder[1]) > 0) {
m[1] = val;
}
});
minMaxConsumer.accept((T) minMaxHolder[0], (T) minMaxHolder[1]);
}Обёртка решения в класс
Платформа ожидала получить решение в виде одного метода, но многие пользователи присылали полноценную программу с объявлением внешнего класса и импортами.
Неправильное использование метода sorted
Все функциональные методы класса Stream возвращают новый экземпляр класса, а не модифицируют старый.
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
stream.sorted(order);
T[] array = (T[]) stream.toArray();
if (t.length == 0) {
minMaxConsumer.accept(null, null);
} else {
minMaxConsumer.accept(array [0], array [array .length - 1]);
}
}Неправильная обработка пустого потока
В случае пустого потока ожидалось, что будут переданы значения null. В некоторых решениях в этом случае метод accept вообще не вызывался.
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
List<Object> list = Arrays.asList(
stream.sorted(order).toArray());
if(arrayList.size() > 0) {
minMaxConsumer.accept((T) list.get(0), (T) list.get(list.size()-1));
}
}
Неправильная проверка потока на пустоту
Некоторые решения пытаются явно проверять пустоту потоков, но делают это неправильно. В некоторых случаях проверки получаются бессмысленными (например, никакой объект не может быть equals значению null), а count — терминальная операция, поэтому её использование делает невозможным дальнейшее использование потока.
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
if (stream.equals(null)) {
minMaxConsumer.accept(null, null);
} else {
List<T> list = stream.sorted(order)
.collect(Collectors.toList());
minMaxConsumer.accept(list.get(0),
list.get(list.size() - 1));
}
}
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
if (stream.count() > 0) {
List<T> list = stream.sorted(order)
.collect(Collectors.toList());
minMaxConsumer.accept(list.get(0),
list.get(list.size() - 1));
}
minMaxConsumer.accept(null, null);
}Путаница в операторах сравнения
Также учащиеся часто путались в знаках сравнения.
public static <T> void findMinMax(
Stream<? extends T> stream,
Comparator<? super T> order,
BiConsumer<? super T, ? super T> minMaxConsumer) {
Object[] minMaxHolder = new Object[]{null, null};
stream.forEach(x -> {
if (minMaxHolder[0] == null) {
minMaxHolder[0] = x;
minMaxHolder[1] = x;
}
if (order.compare((T) minMaxHolder[0], x) < 0)
minMaxHolder[0] = x;
if (order.compare((T) minMaxHolder[1], x) > 0)
minMaxHolder[1] = x;
});
minMaxConsumer.accept((T) minMaxHolder[0], (T) minMaxHolder[1]);
}Из полученных результатов можно сделать вывод, что выбранный подход может применяться для автоматической выдачи подсказок на обучающей онлайн-платформе. В данной работе использовался простейший алгоритм классификации. Сейчас мы исследуем применимость в данной задаче более сложных нейросетевых подходов. Их использование осложнено сравнительно небольшим количеством решений, но предварительные данные показывают, что такие подходы всё равно дают преимущество в качестве итоговой классификации. Исходный код проекта можно найти здесь. О других проектах нашей группы можно узнать тут.
Автор статьи: Артём Лобанов, исследователь лаборатории методов машинного обучения в программной инженерии в JetBrains Research.
