Выпускница CS центра 2018 года, Дарья Родионова, рассказывает о транслитерации: что это такое, какие есть подходы к транслитерации, как создать свой транслитератор и как усовершенствовать модель.
Транслитерация — это графический перевод слова из одного алфавита в другой при условии, что у нас есть таблица соответствия знаков одной системы другой. Действительно, чем транслитерация не напоминает упрощённый переводчик? Здесь языки — это алфавиты и возможное количество правил перевода упрощается до четырёх важных:
До недавней поры весь рунет был написан на латинице. Тогда не на всех устройствах была доступна кириллическая раскладка, а во главе угла стоял ASCII — в то время кодировки ещё не умели обрабатывать кириллицу. В результате вместо послания на русском языке адресат получал абракадабру.
15 лет назад, когда на мобильных телефонах стала доступна кириллица, от операторов сотовой связи продолжали приходить SMSки на латинице. Не скрою, что с удовольствием расшифровывала эти послания :) И сейчас люди нередко переписываются латиницей на форумах или в чатах, потому что под рукой нет русской клавиатуры.
Обычно говорят о прямой транслитерации русских слов в латиницу. Когда нужно перевести географические названия или имена для иностранных документов, научных статей.
Обратная транслитерация — это конвертация слова на латинице в слово на кириллице. Она нужна во многих сферах, поэтому в каждой из них со временем появился свой стандарт. И поэтому теперь существуют сразу несколько стандартов, по которым слова транслитерируются неоднозначно.
Нам часто приходится слышать в новостях про нелепые переводы и транслитерации географических имён. Например, комбинация букв «sch» может быть последовательностью «СЧ» или буквой «Щ», как в слове Schyot. Даже на форумах встречаются разные взгляды на то, как написать латиницей букву «Щ». Там же можно встретить и неоднозначность комбинации «ch». Казалось бы, это всегда «Ч»! Нет, это ещё и «X» на конце слов: обычно перед ним идут буквы «И/Ы». А как вы будете переводить «YE» с латиницы? В «Е» или в «ЫЕ»? Подробнее — в статье «Транслит без правил».
Это finite-state transducer, состоящий из узлов, каждый из которых умеет обрабатывать входной символ и выдавать выходной. Если приводить формальное определение, то трансдьюсер состоит из 6 компонент (Q, Σ, Γ, I, F, δ), где:
Q — множество состояний
Σ — входной алфавит
Γ — выходной алфавит
I — подмножество начальных состояний из Q
F — подмножество конечных состояний из Q
δ — переход из Q ⨉ (Σ ⋃ {e}) в Q ⨉ (Γ ⋃ {e})
В общем случае множество Q представляет собой несколько состояний. Запишем некоторые в одно из-за числа букв в алфавите:
Помните, сколько правил перевода мы определяли в начале статьи? :) В качестве Σ выступает латинский алфавит и одинарная кавычка для обозначения мягкого знака, а множество Γ содержит целевой алфавит — кириллицу. Множества начальных и конечных состояний состоят из символов алфавита или из комбинаций символов алфавита, как это может встретиться при кодировке букв Ч, Ш, Щ, Ю, Я.
Трансдьюсер до поры до времени использовался в некоторых NLP-задачах, в том числе в морфологическом анализе слов:
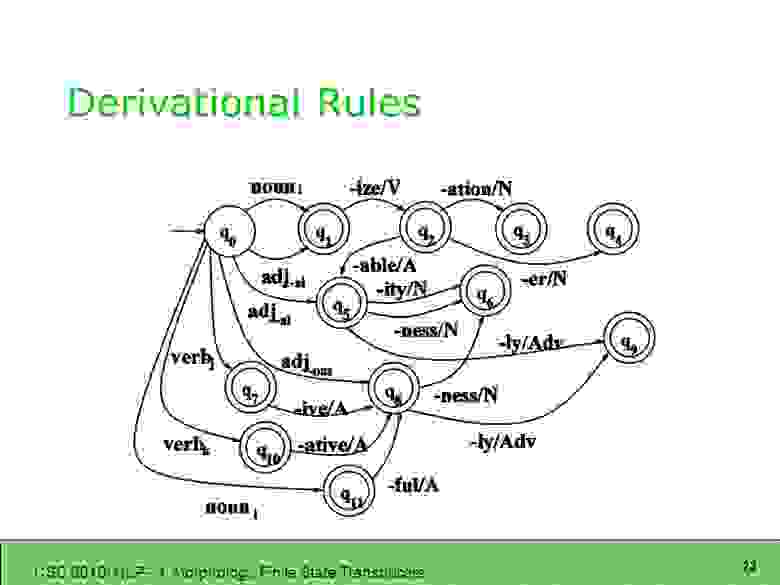
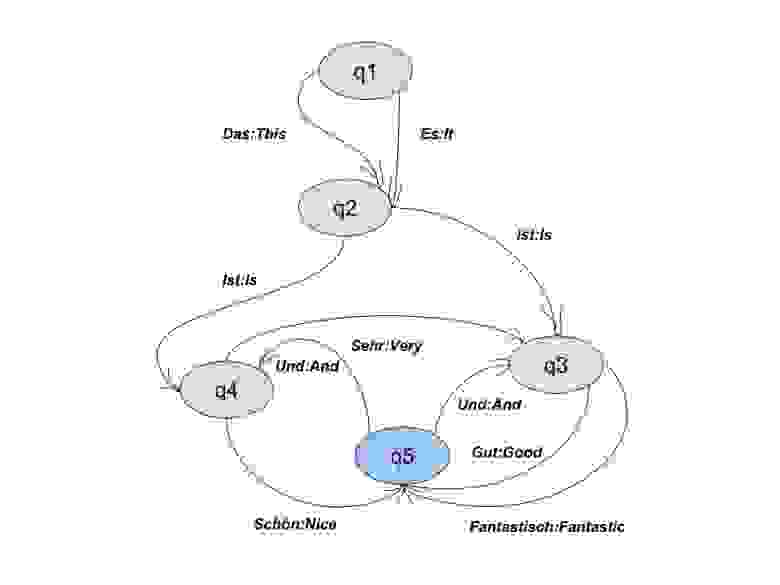
А вот ещё один пример простого трансдьюсера для переводчика. Последняя схема лучше всего подойдёт для проектирования транслитерации. Одно отличие: в каждом состоянии q мы обрабатываем не слово, а его символ.
Подробнее о трансдьюсерах
Ну а мы с вами попытаемся построить такой транслитератор, что умеет анализировать входные данные с разных ГОСТов и конвертировать разные варианты их написания в единый на кириллице. Другими словами, мы будем проектировать логику переходов трансдьюсера.
Существует несколько подходов к построению транслитератора, два из которых — ML и rule-based.
ML — любая вероятностная seq-to-seq модель (марковская как базовая). Она основана на принципе Витерби, когда мы одновременно сегментируем латинское слово и ищем наиболее вероятную последовательность скрытых состояний или кириллических комбинаций.
Состояния — это конечное число кириллических комбинаций. Наблюдения или входная последовательность — латинские комбинации, переходы — между латинскими комбинациями и кириллицей, эмиссии (вероятности наблюдения после перехода в новое состояние) — вероятность латинской комбинации в некоторой кириллической комбинации.
Также ML-модель транслитерации можно определить как задачу машинного перевода. Так, например, можно обучить модель транскрипции слов в языке. Сначала нужно составить таблицу соответствий звуков буквам, а затем обучить на примерах вероятности переводов букв в звуки.
Сейчас мы не будем рассматривать ML-модель, потому что под рукой нет репрезентативного датасета с вариантами транслитерации. Сбор данных — отдельная задача. Вернёмся к транслитерации и остановимся на rule-based подходе. Для этого нам понадобятся словарь (палочка-выручалочка для любого лингвиста), таблица сочетаемости букв и таблица для транслитерации фонем.
Простейший процесс транслитерации состоит из трёх шагов:
Подпоследовательность может иметь неоднозначную интерпретацию в русские символы. Здесь начинается ветвление на правила. Основные подводные камни третьего шага:
1. Перевод звука CH. В начале слова это могут быть Ч, Х и К. На конце слова тоже два варианта: Ч, Х. Простейшая эвристика, использованная в текущей реализации, — наличие фонемы И/Ы перед звуком CH. Вы спросите, почему мы уверены в том, что перед буквой О можно преобразовать CHR в ХР, а перед И — в КР? Всё дело в поиске слов, начинающихся с ЧР в актуальных словарях русского языка. На сегодняшний день никто не обнаружил русских слов с началом ЧРО/ЧРИ.
2. Учимся распознавать разделительный твёрдый знак. В данном случае собираем возможные приставки в регулярное выражение, проверяем следующий символ, который должен быть йотированным гласным в транслитерации (ЕЁЮЯ). Если всё хорошо, то ставим перед гласной твёрдый знак. Бывают и ошибочные разборы, как со словом «подЪяческая», которое на самом деле должно быть разобрано как «подЬяческая».
3. Где переводим йотированные звуки в Е/Ё/Ю/Я, а где — оставляем как пару гласных. Мы знаем, что йотированные гласные идут после приставок после разделительного твёрдого знака, в предыдущем шаге мы распознали последний. Значит, и наша текущая буква есть та самая гласная. Также мы получаем йотированную гласную в начале слова. Конечно, и здесь не обходится без ошибочных разборов: IONY → ЁНЫ вместо ИОНЫ. Но такие разборы можно сократить. Мы снова используем словарь, в котором видим, что в слове, которое начинается с ИО обычно следуют буквы ТАД. Добавим и это наблюдение в наши правила.
4. Где ИЙ, а где ЫЙ? Здесь тоже применена простая эвристика, где перед искомой последовательностью символов проверяется согласный звук. Если это ГДЖКЦЧШЩ, то мы получаем окончание ИЙ, иначе берём сочетание ЫЙ из таблицы переводов.
Детали транслитерации для самостоятельного изучения
Буду рада ответить на вопросы в комментариях и подумать над улучшениями транслитератора :)
Транслитерация — это графический перевод слова из одного алфавита в другой при условии, что у нас есть таблица соответствия знаков одной системы другой. Действительно, чем транслитерация не напоминает упрощённый переводчик? Здесь языки — это алфавиты и возможное количество правил перевода упрощается до четырёх важных:
- One-to-one: B → Б, R → Р, P → П
- One-to-many: Y → ЫЙ
- Many-to-one: SCH → Щ, CH → Ч, YU → Ю
- Many-to-many: зависит от контекста, например, IE → ИЕ
До недавней поры весь рунет был написан на латинице. Тогда не на всех устройствах была доступна кириллическая раскладка, а во главе угла стоял ASCII — в то время кодировки ещё не умели обрабатывать кириллицу. В результате вместо послания на русском языке адресат получал абракадабру.
15 лет назад, когда на мобильных телефонах стала доступна кириллица, от операторов сотовой связи продолжали приходить SMSки на латинице. Не скрою, что с удовольствием расшифровывала эти послания :) И сейчас люди нередко переписываются латиницей на форумах или в чатах, потому что под рукой нет русской клавиатуры.
Зачем нужна автоматическая транслитерация
Обычно говорят о прямой транслитерации русских слов в латиницу. Когда нужно перевести географические названия или имена для иностранных документов, научных статей.
Обратная транслитерация — это конвертация слова на латинице в слово на кириллице. Она нужна во многих сферах, поэтому в каждой из них со временем появился свой стандарт. И поэтому теперь существуют сразу несколько стандартов, по которым слова транслитерируются неоднозначно.
Нам часто приходится слышать в новостях про нелепые переводы и транслитерации географических имён. Например, комбинация букв «sch» может быть последовательностью «СЧ» или буквой «Щ», как в слове Schyot. Даже на форумах встречаются разные взгляды на то, как написать латиницей букву «Щ». Там же можно встретить и неоднозначность комбинации «ch». Казалось бы, это всегда «Ч»! Нет, это ещё и «X» на конце слов: обычно перед ним идут буквы «И/Ы». А как вы будете переводить «YE» с латиницы? В «Е» или в «ЫЕ»? Подробнее — в статье «Транслит без правил».
Теоретическое описание транслитератора
Это finite-state transducer, состоящий из узлов, каждый из которых умеет обрабатывать входной символ и выдавать выходной. Если приводить формальное определение, то трансдьюсер состоит из 6 компонент (Q, Σ, Γ, I, F, δ), где:
Q — множество состояний
Σ — входной алфавит
Γ — выходной алфавит
I — подмножество начальных состояний из Q
F — подмножество конечных состояний из Q
δ — переход из Q ⨉ (Σ ⋃ {e}) в Q ⨉ (Γ ⋃ {e})
В общем случае множество Q представляет собой несколько состояний. Запишем некоторые в одно из-за числа букв в алфавите:
- старт, состояние 1 или замена одного символа на другой,
- состояние 2 или замена нескольких символов на один,
- состояние 3 или замена одного символа на несколько,
- состояние 4 или замена группы символов другой группой символов, конец.
Помните, сколько правил перевода мы определяли в начале статьи? :) В качестве Σ выступает латинский алфавит и одинарная кавычка для обозначения мягкого знака, а множество Γ содержит целевой алфавит — кириллицу. Множества начальных и конечных состояний состоят из символов алфавита или из комбинаций символов алфавита, как это может встретиться при кодировке букв Ч, Ш, Щ, Ю, Я.
Трансдьюсер до поры до времени использовался в некоторых NLP-задачах, в том числе в морфологическом анализе слов:

А вот ещё один пример простого трансдьюсера для переводчика. Последняя схема лучше всего подойдёт для проектирования транслитерации. Одно отличие: в каждом состоянии q мы обрабатываем не слово, а его символ.

Подробнее о трансдьюсерах
Ну а мы с вами попытаемся построить такой транслитератор, что умеет анализировать входные данные с разных ГОСТов и конвертировать разные варианты их написания в единый на кириллице. Другими словами, мы будем проектировать логику переходов трансдьюсера.
Основные подходы к транслитерации
Существует несколько подходов к построению транслитератора, два из которых — ML и rule-based.
ML — любая вероятностная seq-to-seq модель (марковская как базовая). Она основана на принципе Витерби, когда мы одновременно сегментируем латинское слово и ищем наиболее вероятную последовательность скрытых состояний или кириллических комбинаций.
Состояния — это конечное число кириллических комбинаций. Наблюдения или входная последовательность — латинские комбинации, переходы — между латинскими комбинациями и кириллицей, эмиссии (вероятности наблюдения после перехода в новое состояние) — вероятность латинской комбинации в некоторой кириллической комбинации.
Также ML-модель транслитерации можно определить как задачу машинного перевода. Так, например, можно обучить модель транскрипции слов в языке. Сначала нужно составить таблицу соответствий звуков буквам, а затем обучить на примерах вероятности переводов букв в звуки.
Сейчас мы не будем рассматривать ML-модель, потому что под рукой нет репрезентативного датасета с вариантами транслитерации. Сбор данных — отдельная задача. Вернёмся к транслитерации и остановимся на rule-based подходе. Для этого нам понадобятся словарь (палочка-выручалочка для любого лингвиста), таблица сочетаемости букв и таблица для транслитерации фонем.
Как это работает?
Простейший процесс транслитерации состоит из трёх шагов:
- Идём по последовательности, которую надо перевести на русский язык.
- Ищем комбинацию звуков в таблице транслитерации фонем.
- Если фонемы найдены, то транслитерируем текущую комбинацию и корректируем несочетаемость букв с помощью регулярных выражений.
Подпоследовательность может иметь неоднозначную интерпретацию в русские символы. Здесь начинается ветвление на правила. Основные подводные камни третьего шага:
1. Перевод звука CH. В начале слова это могут быть Ч, Х и К. На конце слова тоже два варианта: Ч, Х. Простейшая эвристика, использованная в текущей реализации, — наличие фонемы И/Ы перед звуком CH. Вы спросите, почему мы уверены в том, что перед буквой О можно преобразовать CHR в ХР, а перед И — в КР? Всё дело в поиске слов, начинающихся с ЧР в актуальных словарях русского языка. На сегодняшний день никто не обнаружил русских слов с началом ЧРО/ЧРИ.
2. Учимся распознавать разделительный твёрдый знак. В данном случае собираем возможные приставки в регулярное выражение, проверяем следующий символ, который должен быть йотированным гласным в транслитерации (ЕЁЮЯ). Если всё хорошо, то ставим перед гласной твёрдый знак. Бывают и ошибочные разборы, как со словом «подЪяческая», которое на самом деле должно быть разобрано как «подЬяческая».
3. Где переводим йотированные звуки в Е/Ё/Ю/Я, а где — оставляем как пару гласных. Мы знаем, что йотированные гласные идут после приставок после разделительного твёрдого знака, в предыдущем шаге мы распознали последний. Значит, и наша текущая буква есть та самая гласная. Также мы получаем йотированную гласную в начале слова. Конечно, и здесь не обходится без ошибочных разборов: IONY → ЁНЫ вместо ИОНЫ. Но такие разборы можно сократить. Мы снова используем словарь, в котором видим, что в слове, которое начинается с ИО обычно следуют буквы ТАД. Добавим и это наблюдение в наши правила.
4. Где ИЙ, а где ЫЙ? Здесь тоже применена простая эвристика, где перед искомой последовательностью символов проверяется согласный звук. Если это ГДЖКЦЧШЩ, то мы получаем окончание ИЙ, иначе берём сочетание ЫЙ из таблицы переводов.
Как усовершенствовать эту модель
- Подумать над тем, как распознавать мягкий знак в словах.
- Подключить какой-нибудь актуальный орфографический электронный словарь, на котором основываются эвристики. Он помог бы отслеживать актуальность наших правил и, возможно, ввести такое понятие как «вес правила». Так мы потихоньку перешли бы к ML-модели.
- Использовать в контексте спеллчекер. Конечно, это уже не задача транслитерации, но спеллинг помог бы получить более осмысленный результат :)
Детали транслитерации для самостоятельного изучения
Буду рада ответить на вопросы в комментариях и подумать над улучшениями транслитератора :)
