Когда мы с МТС готовили опрос, нам хотелось узнать, насколько глубоко использование Big Data проникло в российские IT. В результате однозначного ответа нам получить не удалось: мнения сторонников и противников применения этой технологии поделились примерно поровну. Что ж, тем интереснее было анализировать ваши ответы. Под катом мы рассказываем, что в больших данных хорошо, а что можно сделать ещё лучше.
Опрос мы начали с прямого и главного вопроса об использовании больших данных в российских компаниях. Сделав погрешность на честность, можно сказать, что победила дружба: почти половина участвовавших в опросе используют Big Data в своей компании или планируют сделать это в скором времени.

По данным новостных источников, в России всё больше компаний внедряют технологии Big Data для улучшения своих сервисов, получения прибыли и сокращения расходов. В перспективе, по данным аналитиков, эта технология сможет дать дополнительный вклад в ВВП.
В то же время на пути внедрения возникает много вопросов о том, как именно должна работать технология, чтобы оправдать инвестиции. Первый из них: кто же всё-таки должен заниматься внедрением, поддержкой и развитием технологии больших данных в компании? В этом вопросе мнения разделились — большинство считает, что эту задачу способен решить отдел Data Science.

Однако комментарии показали, что одним Data Science отделаться не получится:
“
Data Science + DBA + Developers + Бизнес (потому что Big Data, построенная парой человек с питоном и fit/predict, не несёт ценности)
Разумеется, всё зависит от масштаба компании. Там, где в маленькой компании справится пара специалистов, в крупной к внедрению Big Data подходят основательно — это становится совместной работой отдела Data Science, DBA, разработчиков и бизнес-аналитиков, и это только starter pack необходимых специалистов. За рубежом над внедрением Big Data работает более 15 разноплановых специалистов, и это не предел.

На практике применение Data Science топ-менеджментом и владельцами бизнеса часто воспринимается как часть направления Big Data и в структуре компании оказывается там же. Чтобы не делить Data Science на большие данные и малые, и тем и другим зачастую занимается один и тот же отдел: в конце концов, «малые» данные — это то, что обычно остаётся после фильтрации «больших».
В итоге в компаниях встречаются все возможные конфигурации:
- Отдел Data Science — часть направления Big Data (чаще в компаниях из сферы телекома, ретейла, промышленности, финансов).
- Группа, отвечающая за данные и инфраструктуру, входит в отдел Data Science.
- Отделы Big Data и Data Science — отдельные, не вложенные друг в друга сущности.
К примеру, в МТС сейчас реализован первый вариант. Но, разумеется, дело не ограничивается только специалистами в Data Science. Прежде чем попасть к эксперту по Data Science, данные проходят этапы сбора, хранения и обработки. Над каждым этапом работают различные специалисты, поэтому в МТС Big Data, помимо Data Science, есть более десятка различных компетенций (разработка, DevOps, Data Engineering, ETL и др.). Есть отдельная команда Data Governance, которая следит за качеством данных. Используются данные тоже не только в Data Science отделе: непосредственный анализ данных часто проводится бизнес-аналитиками, а созданием общей системы потоковой обработки данных занимается команда разработки.

Основными сферами IT, в которых востребованы технологии Big Data, пользователи Хабра назвали маркетинг, банковскую сферу и аналитику контента.
Маркетинг и аналитика контента признаны самыми востребованными в первую очередь потому, что в этих сферах проще всего увидеть результат в виде прибыли. Обработка больших данных зачастую решает комплексную задачу по улучшению сервиса. При этом, по статистике, маркетинг отстаёт по скорости внедрения технологии Big Data от остальных сфер, однако в скором времени эта индустрия вполне может обогнать конкурентов по темпу использования больших данных.
Для того чтобы сделать внедрение Big Data проще, у МТС есть решения для маркетинговых кампаний, такие как «МТС Маркетолог», применяемый для создания умной таргетированной рекламы с самостоятельной обработкой больших данных без необходимости внедрения специального ПО.
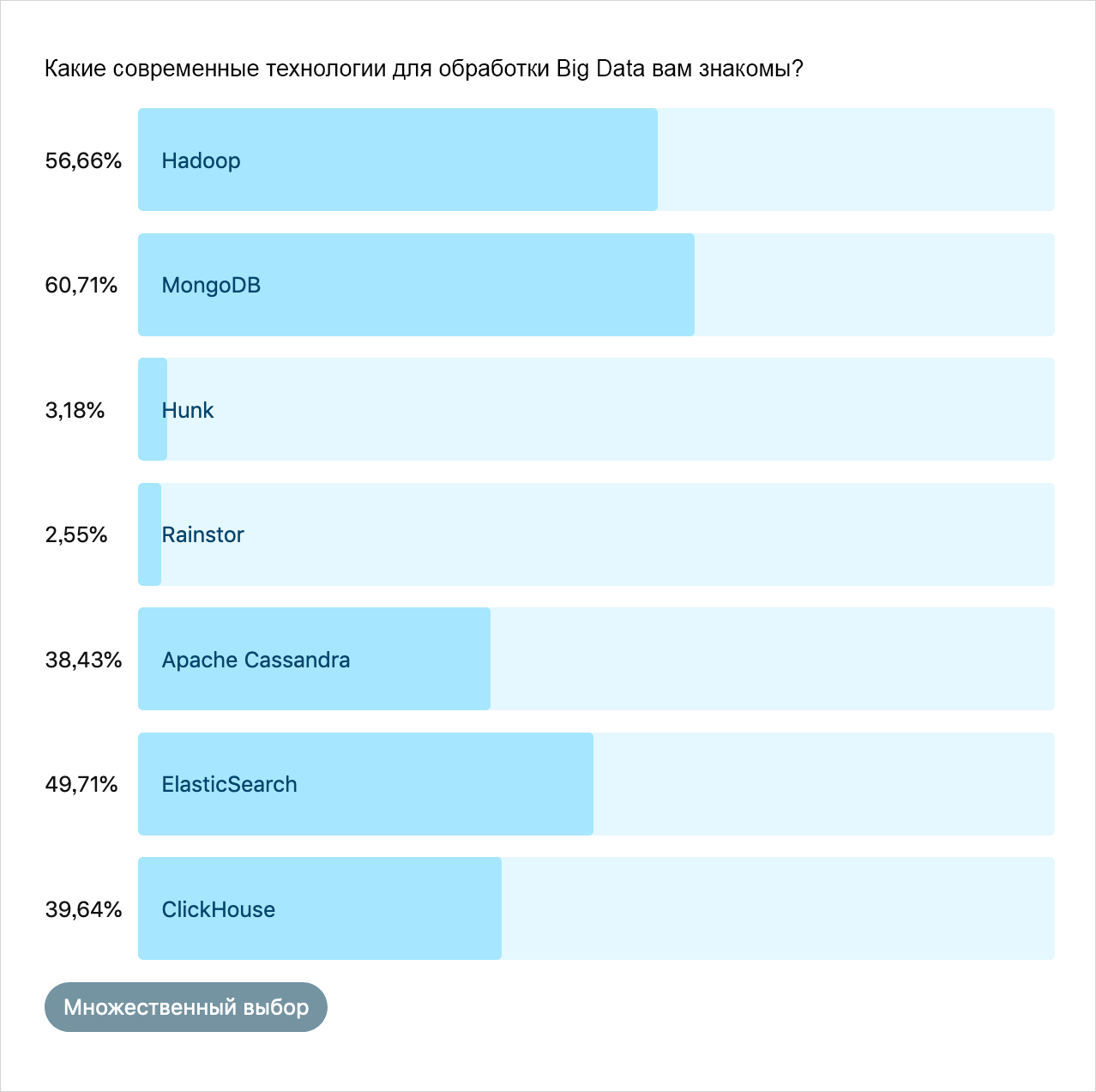
Кстати, о программном обеспечении, применяемом для обработки больших данных. Самым известным средством для работы с Big Data по результатам опроса признан старый добрый Hadoop, и с небольшим отставанием второе место занимает MongoDB.
Какие плюсы есть у перечисленных технологий? Большинство из них OpenSource, могут быть развёрнуты на своих серверах и имеют тысячи мануалов по использованию в интернете. Однако минусы их также очевидны: необходимы отдельные специалисты, которые будут поддерживать это ПО.
Если говорить о типичных проблемах, с которыми сталкиваются компании при построении архитектуры для Big Data, в первую очередь можно назвать взаимодействие разных технологий между собой. Зачастую с этим могут возникать сложности, хотя по отдельности технологии работают достаточно хорошо.
Еще одна типичная проблема — это распределение данных. В Big Data решениях широко используется распараллеливание обработки данных. При этом подразумевается, что данные независимы и одинаково разделимы. Но на практике часто бывает, что очень тяжело или даже невозможно поделить данные равномерно, и из-за этого происходит неоптимальная их обработка.
Основными технологиями, используемыми для обработки данных в МТС, выступают Hadoop, Apache Spark и Kafka. На этих технологиях создана общая платформа для кастомной real-time-обработки входящих потоков данных в зависимости от бизнес-требований, определяемых конкретными потребителями. Работа системы основана на технологии Spark Streaming, используемой для потоковых распределённых вычислений. Также она включает в себя собственное решение для запуска и конфигурирования Spark Job.
Следующим встаёт вопрос о том, какие данные собирать, чтобы они были максимально информативны и при этом их было легко обрабатывать.
Пользователи Хабра склоняются к тому, что наиболее доступным способом получения больших данных является сбор данных транзакций и данных поиска.

Разобрались со специалистами, ПО и данными, и тут возникает самый важный вопрос: в чём же использование больших данных может реально помочь компании?

В первую очередь пользователи Хабра назвали здесь увеличение прибыли и сокращение расходов. Однако более четверти опрошенных уверены, что Big Data ничем не поможет компании. Разумеется, всё зависит от того, как внедрять и использовать технологию, ведь это всего лишь инструмент, который важно применять с умом.
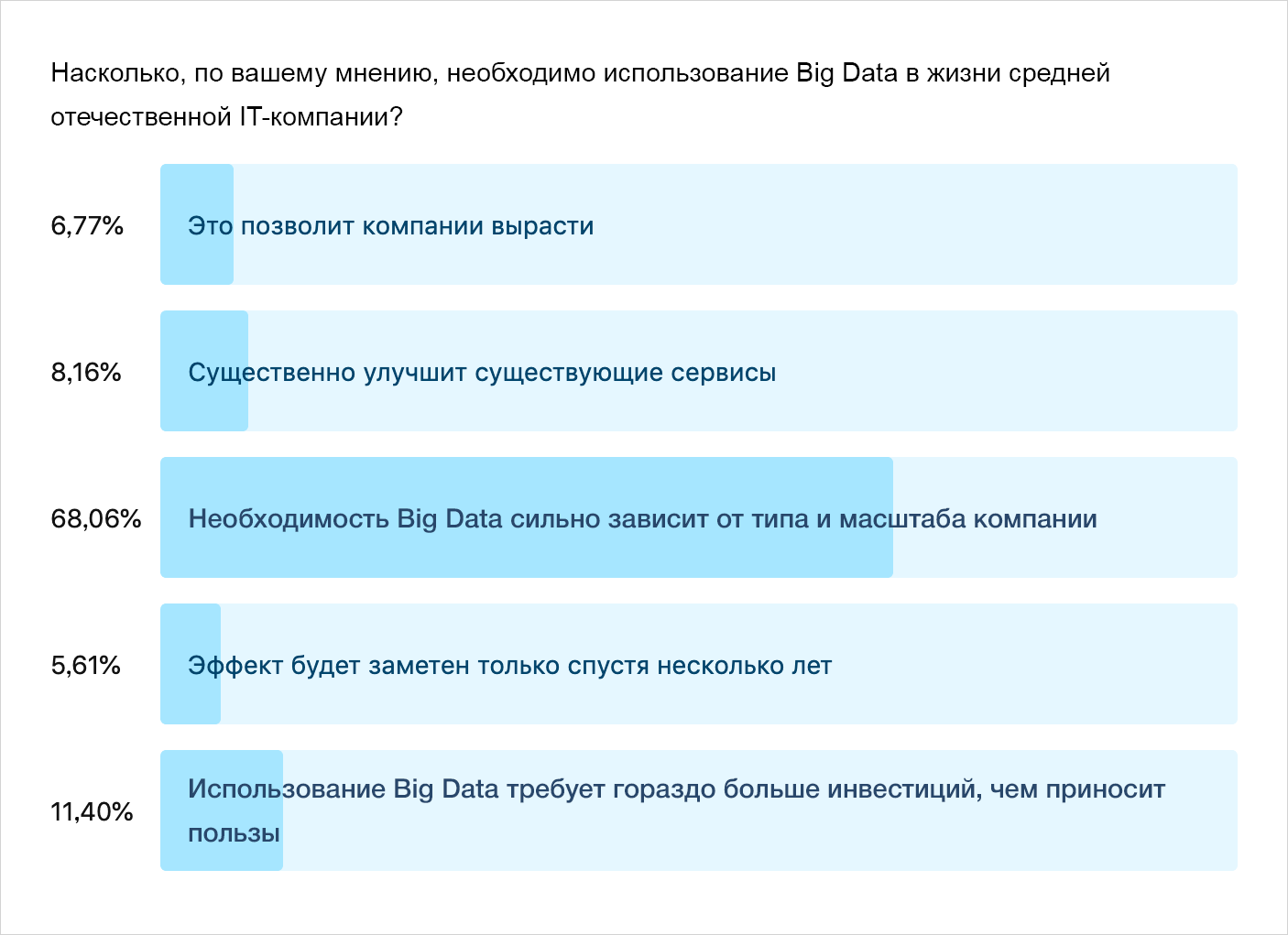
По поводу перспектив использования Big Data наша аудитория почти единогласно решила, что здесь всё зависит от типа и масштаба компании.
“
Технологиям и проектам сильно мешает низкая квалификация управленческого персонала в компаниях, большинство компаний никогда не сможет получить рабочие Big Data продукты в связи с недостатком финансирования и низким качеством ТЗ и исследований. И то, что в вебе сглаживалось Kubernetes, в Big Data только увеличивает проблемы.
Что касается подводных камней при внедрении технологии Big Data, здесь хабрапользователи выбрали сразу несколько вариантов.
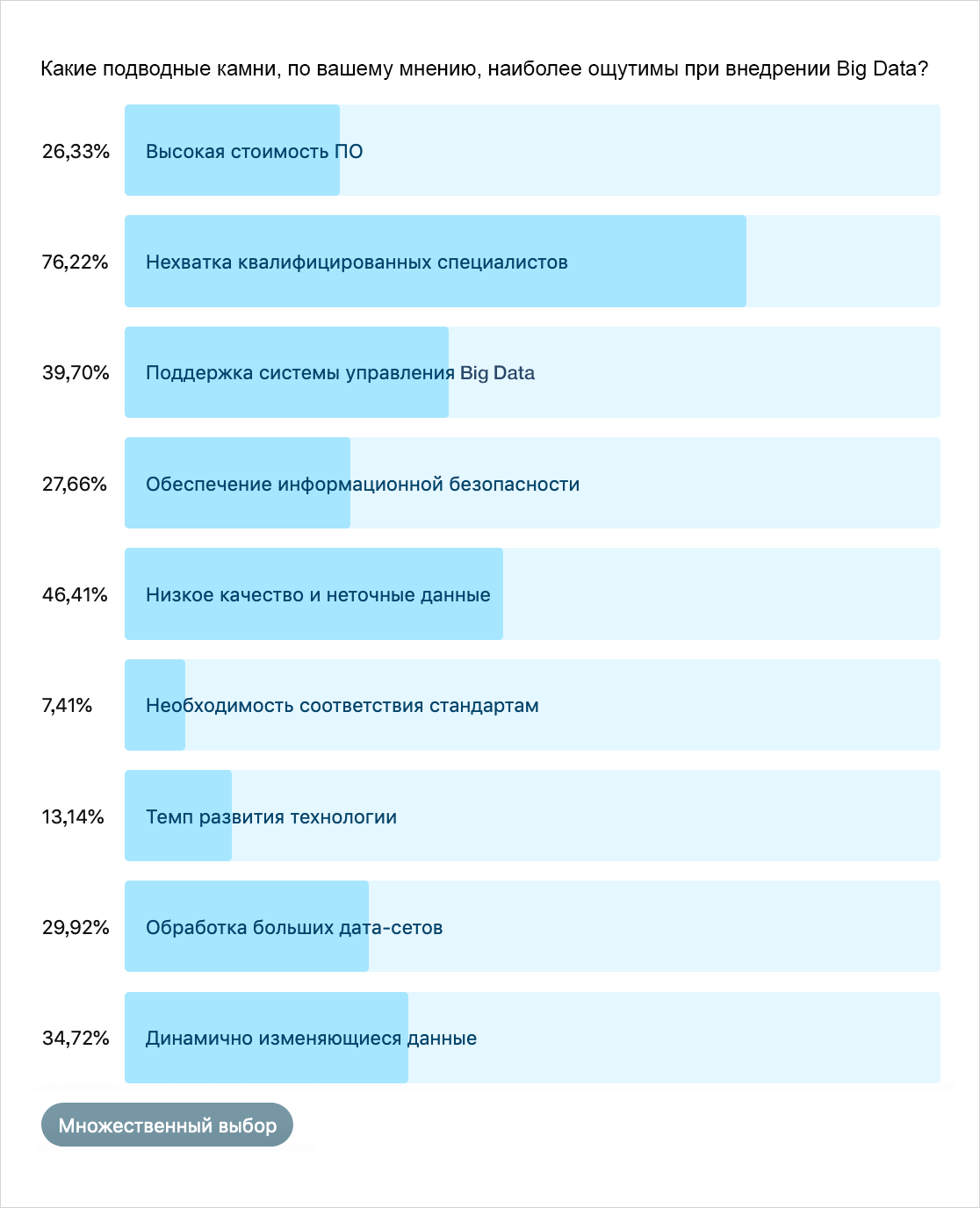
Как выяснилось, не пугает в больших данных только необходимость следования стандартам, все остальные варианты, по мнению опрошенных, так или иначе представляют опасность. Разумеется, нехватка квалифицированных специалистов является одной из приоритетных проблем как в России, так и за рубежом.
Big Data для МТС — стратегически важная часть бизнеса, поэтому поиску технических спецов уделяется особенное внимание. Большое значение имеет профильное образование и опыт кандидата, а решающим становится техническое интервью, потому что по своему содержанию оно максимально приближено к тому, чем человек будет заниматься в компании. Перечень востребованных специалистов по Big Data широк: это аналитики, разработчики, Data Scientist и не только — интересные вакансии можно посмотреть здесь.
Также стоит не забывать вкладываться в развитие уже работающей у команды: поездки на профильные конференции, кросс-функциональные курсы (например, разработке и Data Science часто есть чем поделиться друг с другом, чтобы работать вместе эффективнее), внешние узкоспециализированные курсы и воркшопы от экспертов в области.
Но помимо нехватки кадров пользователи Хабра видят и другие сложности.
“
Средний и малый бизнес зачастую не понимают важности сбора, обработки и использования проходящей через них информации. С развитием доступных сервисов, которые бы позволяли использовать хотя бы некоторые возможности Big Data, компании существенно ускорят развитие. Пока слишком дорого и сложно создавать собственный отдел, поэтому многим это не под силу. Объяснение необходимости использования больших данных не решит эти проблемы, нужно предоставить компаниям готовые решения за приемлемую стоимость.
Низкое качество и неточные данные — второй по популярности у хабрасообщества вариант ответа на вопрос о подводных камнях Big Data, и здесь тоже максимально точное попадание. К сожалению, пропуски и искажения в данных возникают всегда. Понять, достаточно ли данные качественные, часто можно только попытавшись построить на них модели. Но валидировать качество данных на уровне поиска пропусков и нестыковок в них всё равно нужно.
Последний вопрос по поводу будущего Big Data был богат ответами с комментариями.

При этом подавляющее большинство респондентов уверено, что Big Data не изменят IT-индустрию и всё останется на том же уровне.
“
Big Data не самая простая отрасль, и для среднестатистического бизнеса она совсем не приоритетна. Обычно есть более очевидные и срочные проблемы/идеи, требующие решения/реализации. Как только Big Data обзаведётся достаточно «простым» инструментарием для внедрения в проекты, люди начнут этим активнее интересоваться и внедрять в своих проектах. И, собственно, тогда часть проектов с использованием Big Data заметно увеличится
Однако есть и другое мнение:
“
Если не использовать Big Data, то разрыв с компаниями, использующими Big Data, будет нарастать и, соответственно, отставание неминуемо.
Но здесь есть два основных препятствия. Во-первых, для понимания, дает ли решение на основе данных прирост каких-то важных метрик бизнеса, нужно, чтобы данных хватало хотя бы для замера статистически значимого эффекта (т. е. аппарат статистики должен подтвердить, что эффект будет воспроизводиться в дальнейшем). В случае небольших компаний данных, как правило, не хватает. Во-вторых, на разных стадиях развития компании нужны свои инструменты. Big Data позволяет оптимизировать уже стабилизировавшиеся бизнес-процессы в большой компании, а в случае небольшой компании эффект от разумного перестроения процессов всё равно будет больше, чем от экономии на каком-то существующем процессе.
Что можно сказать в конце? Big Data — уже широко распространившийся инструмент, позволяющий большим компаниям оптимизировать существующие бизнес-процессы и запускать новые продукты. При этом ажиотаж вокруг больших данных создаёт некоторый «пузырь», и технология начинает использоваться в угоду модным трендам, а не оптимизации прибыли компании, а на этой ситуации «паразитирует» большое количество специалистов с невысокой квалификацией. Чтобы не попасть в эту ловушку, нужно заботиться об оценке проектов Big Data на всех стадиях и вкладываться в развитие специалистов внутри и вне компании.
Если же вы по каким-то причинам пропустили наш опрос или считаете, что ваше мнение не было услышано, смело высказывайтесь в комментариях.