Переместить большой объем данных не останавливая работу серверов — задача посложнее, чем построить с нуля новую архитектуру. Надо понимать, что, как, когда и куда, а еще организовать переезд так, чтобы не тормозить уже существующие бизнес-процессы. Мы смогли найти программный продукт для решения всех этих задач и ниже расскажем, как переехать из одного ЦОД в другой за два месяца, решив несколько сопутствующих задач, и сделать это в условиях ограниченных ресурсов. При этом вся команда работала буквально не выходя из дома (благо технология позволяет), что можно считать еще одной победой. Но обо всем по порядку.
Как мы собирались переезжать, а заодно обновляться
Наша компания владеет крупной сетью автозаправок. Большая часть IT-инфраструктуры организована в облаках по принципу IaaS, с распределенной сетью точек продаж и несколькими площадками в разных ЦОД.
И вот у нас появилась задача слить несколько площадок в одну. Хорошо, что нам не надо было перевозить физические сервера — мы бы с ума сошли с инвентаризацией, резервными копиями, демонтажом и тестированием на новом месте.
В нашем случае речь шла только про переезд IaaS и объединение основных серверов на одной площадке. То есть провайдер предоставляет, а компания использует (не забывая вовремя платить). Например, можно перевезти только образы виртуальных машин и развернуть их на новом месте. Можно пойти еще дальше и перевезти только данные: дампы баз данных, содержимое файл-сервера и так далее. При этом оборудование на старом месте можно не отключать, сервисы не останавливать и в случае, если что-то пошло не так, временно вернуться к тому, что было ранее.
Звучит, как сказка? Да, потому что в реальности всегда найдутся подводные камни, и у нас это оказался «тонкий» канал между старыми площадками (далее для удобства мы будем обобщенно называть их ЦОД 1) и новой площадкой (ЦОД 2). 100 Мбит для переноса нашего объема данных было недостаточно, тянуть данные пришлось бы месяцами. Расширять канал мы не могли из-за технических ограничений ЦОД и интернет-провайдера. А поскольку на переносимых площадках располагались основные бизнес-сервисы, downtime должен был быть минимальным.
Кроме того, на прежних площадках использовалось старое ПО. Поэтому решили объять необъятное за один переезд, обновить версии ПО и перевести сервисы на другую площадку.
Переезд: с чем мы к нему приступили
Требования руководства к переезду были следующими:
- время простоя сервисов не более 30 минут;
- миграция и переключение на новый ЦОД без потери данных;
- реализовать проект удаленно, без командировок (ЦОД в другом городе и весьма далеко);
- конвертировать устаревшие физические сервера в виртуальные без остановки;
- реализовать проект, не увеличивая пропускной способности канала связи;
- перенести самописный софт с одного сервера на другой без переустановки (часть ПО была рукописной, авторы давно уволились, и последнее время мы жили по принципу «работает — не трогай!»);
- осуществить миграцию без участия инженеров сервис-провайдера в ЦОД;
- на все про все — два месяца (ни в чем себе не отказывайте).
Предстояло перенести из сервисов:
- различные СУБД: Oracle, MS SQL;
- ферму терминальных серверов на базе платформы Citrix;
- почту MS Exchange;
- файловые ресурсы;
- сервер приложений с рукописным ПО;
- кучу всякой мелочевки вроде документооборота и других полезных вещей.
Переезжало практически все ядро бизнеса, так как без любой из этих составляющих компания работать толком не сможет.
В итоге мы в отделе сформировали для себя такие требования:
- Данные с трех физических серверов с MS Windows Server 2008R2 из ЦОД 1 необходимо перенести на три физических сервера с MS Windows Server 2012R2 в ЦОД 2.
- Данные с девяти физических серверов с MS Windows Server из ЦОД 1 необходимо перенести на девять виртуальных серверов с MS Windows Server в ЦОД 2. Платформа виртуализации — VMWare ESX.
- Данные с пяти физических серверов с Linux из ЦОД 1 необходимо перенести на пять виртуальных серверов с Linux в ЦОД 2. Платформа виртуализации — VMware ESX.
Какие человеческие ресурсы оказались в нашем распоряжении:
- Мы, то есть IT-подразделение компании (сеть распределенная, и люди находятся в разных городах. Есть, кого послать патчкорд переключить. Но один-два человека на площадке еле справлялись с кучей задач и поручений).
- Возможно привлечение стороннего консультанта, но не от сервис-провайдера (руководство не собиралось распахнуть кошелек для привлечения системного интегратора, аутсорсера и так далее, поэтому слово «консультация» нужно понимать как «краткая консультация»).
Напомню, что переезд осуществлялся внутри одной страны, но в разные города, и у ЦОД были разные собственники.
Примечание.
Разные собственники — это, кстати, еще та засада. Старые договоренности уже не действуют, а новые могут оказаться совсем другими, например, при просьбе организовать какую-нибудь мелочь на новой площадке, вроде проброски дополнительного кабеля между стойками, изменения правил в ACL и так далее, можно запросто упереться в административный барьер: «А мы так не делаем, у нас по внутренним правилам такое не положено!». Вот и приходится либо идти к руководству нового ЦОД (чаще всего с дополнительными деньгами), либо искать какие-то пути обхода. Поэтому чем выше уровень абстракции, на котором работает IT-система, тем лучше.
Разные собственники — это, кстати, еще та засада. Старые договоренности уже не действуют, а новые могут оказаться совсем другими, например, при просьбе организовать какую-нибудь мелочь на новой площадке, вроде проброски дополнительного кабеля между стойками, изменения правил в ACL и так далее, можно запросто упереться в административный барьер: «А мы так не делаем, у нас по внутренним правилам такое не положено!». Вот и приходится либо идти к руководству нового ЦОД (чаще всего с дополнительными деньгами), либо искать какие-то пути обхода. Поэтому чем выше уровень абстракции, на котором работает IT-система, тем лучше.
Как мы осуществили систему миграции
В процессе подготовки мы перерыли различные тематические форумы и раскопали информацию про Carbonite.
Но это был не единственный вариант. Например, мы также рассмотрели передачу данных через бэкап по принципу «скопировал — развернул», распределенную файловую систему типа DFS и многое другое. Но ни один из способов не справлялся с нашим набором условий одновременно.
Скажем честно, мы воспользовались специальной поддержкой от вендора — производителя системы Carbonite — через их представителя в России First National Consulting Group. Это позволило быстро получить ответы на необходимые вопросы и составить точный план мероприятий с учетом всех возможностей продукта.
Общее описание процесса миграции
Основная идея заключается в следующем. На серверы, подлежащие миграции, устанавливается специальный программный агент, который, собственно, и отвечает за перенос данных. Репликация работает в асинхронном режиме, что позволяет системе работать без видимых задержек, не дожидаясь подтверждения успешной записи от удаленной системы.
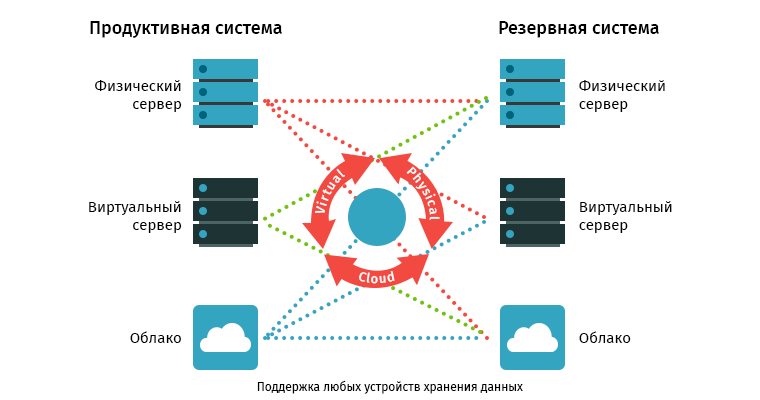
Весь процесс миграции условно можно разделить на три этапа: подготовительный, основной и контрольный.
Что мы сделали, чтобы процесс миграции прошел гладко:
- Развернули систему Carbonite Availability and Migrate, которая позволила серверам из ЦОД 1 реплицировать 100% данных в ЦОД 2 без влияния на работу критически важных бизнес-приложений.
- По окончании первичной репликации провели тестовое включение серверов в ЦОД 2 в изолированной среде, зафиксировали результат документально и сообщили руководству, что система для миграции готова.
- Только после успешного завершения испытаний запустили миграцию всех необходимых производственных серверов из ЦОД 1 в ЦОД 2.
Требования к процессу миграции:
- В процессе репликации данных сервера и сервисы в основном ЦОД 1 должны были работать в штатном режиме.
- Провести 100% миграцию всех установленных приложений, системных настроек и данных, которыми оперируют серверы.
- По окончании миграции при осуществлении процесса переключения серверов из ЦОД 1 в ЦОД 2 должно быть обеспечено минимальное время простоя критически важных бизнес-приложений 15 минут, максимальное — 30 минут.
Чтобы было понятно, как все происходило, наверное, стоит рассказать о том, как работает Carbonite Migrate.
Драйвер Carbonite работает на уровне операционной системы, вне зависимости от типа и способов подключения используемых СХД, видов гипервизоров и операционных систем, являясь полностью аппаратно независимым решением. Не совсем родственный пример — работа антивирусного монитора, который, прежде чем записать данные на диск, выполняет проверку и по результатам отправляет файл либо в указанный каталог, либо в карантин. А Carbonite вместо карантина, перехватывая операции ввода-вывода, отправляет записанные данные с локальных дисков байт за байтом на удаленную площадку.
Процесс происходит прозрачно для системы, нагрузка практически не увеличивается, быстродействие при этом почти не страдает, так как реплицируются только подтвержденные системой операции записи на диск, а операции чтения игнорируются. У Carbonite для работы с тонкими каналами есть свои секреты, поэтому каких-либо сбоев и отказов мы не наблюдали.
Об архитектуре созданной системы репликации
Особенности архитектуры Carbonite в том, что это децентрализованная система. Чтобы приступить к работе, достаточно установить агент на серверы в разных локациях, и после небольшой настройки система готова к старту процесса репликации. При этом управлять заданиями рабочих нагрузок можно как с самих серверов, так и с любой другой машины, установив клиент консоли Carbonite. Не нужно ставить серверную часть, не нужно поднимать сервер базы данных. Это как нельзя лучше подходило для нашего случая, так как времени на глубокое погружение в сложную архитектуру у нас просто не было.
Очень пригодились те самые патентованные методики работы с узким каналом. Процесс подготовки выглядит интересно: вначале производится тестирование канала и наблюдение за характером передаваемого трафика. Далее составляется алгоритм работы передачи. Выделяются «окна», когда можно безболезненно реплицировать на предельной для этого канала скорости, а также «часы пик», когда системе репликации нужно снизить нагрузку на канал, чтобы не мешать работе production среды.
Важный момент — при обрыве соединения данные, подготовленные для передачи, накапливаются в очередях RAM и HDD. Агент Carbonite ожидает, когда связь восстановится, и выполняет отсроченные действия, отправляя дельту изменений.
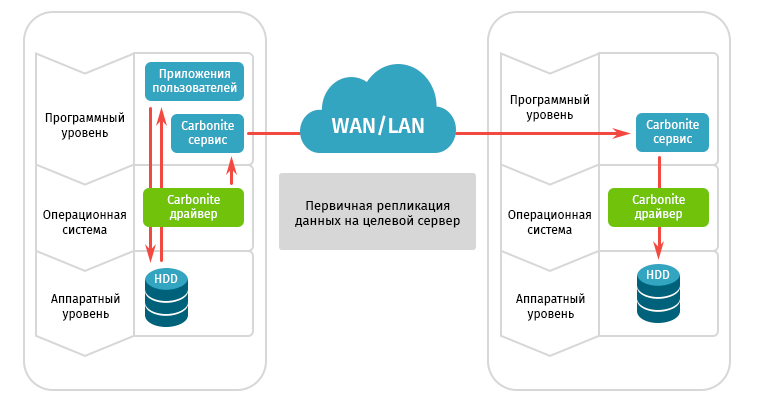
Краткая пошаговая инструкция выглядит так:
- Шаг 1 — установить агенты на серверы.
- Шаг 2 — настроить цель для репликации данных.
- Шаг 3 — включить и настроить систему оптимизации. При непохожих, но хорошо сжимаемых данных можно использовать 2- или даже 4-кратную компрессию. Для обеспечения базового уровня безопасности есть функции алгоритмов шифрования (AES 256).
- Шаг 4 — настроить систему контроля и мониторинга с оповещением об ошибках и сбоях при репликации данных.
Как мы мигрировали: шаг за шагом
Этап 1. Описание
Это проведение бесед с владельцами сервисов, консультации, полная инвентаризация ПО. Важно учесть все требования к безопасности (изменения в политике безопасности для конфигурирования репликации серверов), особенности приложений, особенности кластеров, сетевую топологию, зависимости серверов и другие технические факторы — все это было детально описано в документации.
Итог данного этапа — составление плана проекта, выработка критериев тестирования, уточнение спецификации оборудования, описание примерной конфигурации для Carbonite.
“
Особое внимание мы уделили слабой пропускной способности канала. Для дополнительного анализа данных рекомендуется, чтобы на производственных серверах был запущен Carbonite Statistics, чтобы определить пропускную способность канала для поддержания репликации критических данных.
В нашем случае выполнялась миграция большого объема данных, которые, к тому же, изменяются в процессе работы бизнес-приложений. Поэтому было важно сразу определить скорость изменения этих данных, чтобы уточнить время синхронизации серверов и последующего тестирования результатов.
По предварительной оценке, передача 1 ТБ данных занимала примерно 24 часа. Не зная объем изменяемых данных на серверах, невозможно хотя бы приблизительно предугадать, сколько времени может занять первичная репликация всего объема, учитывая тот факт, что одновременно с переносом исходных данных необходимо реплицировать все изменяемые данные в режиме реального времени.
Планирование рабочих нагрузок и разнесение по временной шкале активных сессий позволило оптимизировать весь процесс миграции.
Этап 2. Конфигурации
В данном случае имеется в виду конфигурация установленных агентов продукта Carbonite Migrate на определенных серверах в соответствии со спецификацией, определенной на первом этапе. Здесь производится задание конкретных сценариев и установок репликации для переноса данных, а также настраивается ежедневный мониторинг состояния синхронизации, состояния очереди данных и ежедневный анализ результатов. Важно поддерживать синхронизированный статус по крайней мере 48 часов от окончания процесса репликации до стадии тестирования.
Этап 3. Перенос данных и тестирование
На этом этапе выполняется и завершается процесс репликации, серверы переходят в состояние idle, и на исходных серверах постепенно приостанавливается репликация. При этом создается принудительная очередь на исходных серверах. При нулевой очереди передачи данных на всех серверах делается снимок состояния целевых серверов. Целевая площадка изолируется и выполняется миграция.
После успешного запуска серверов производится тестирование с тестовыми клиентами (базы данных, ферма Сitrix, почта, OWA и другие приложения, определенные на стадии описания). После этого составляется отчет о времени, затраченном на тесты (Failover), и результатах тестовой миграции. Далее в течение 24-часового периода производится откат целевых серверов на прошлый снимок состояния и переподключение репликации с серверов из ЦОД 1 на целевые сервера в ЦОД 2. Исходные сервера из ЦОД 1 продолжают репликацию до полного очищения очередей. При нулевом размере очередей объявляется готовность к отключению производственных исходных серверов. После этого остается согласовать время, чтобы провести итоговое переключение серверов из ЦОД 1 в ЦОД 2.
Этап 4. Завершение миграции
На данном этапе производится корректное отключение соответствующих бизнес-единиц. Самое главное — обеспечить план возврата в ЦОД 1 в случае сбоя при переключении на серверы в ЦОД 2. Все-таки поиск и устранение проблем после сдачи в production дело неблагодарное.
Далее можно запустить площадку в изолированной среде тестирования, а затем включить доступ для пользователей.
Для перехода на другой ресурс понадобилось окно в четыре часа, при этом потребовалась дополнительная ручная настройка (маршрутизация IP подсетей и так далее). Дополнительно добавились два часа для проверки всех критически важных бизнес-приложений в изолированной среде. После успешного тестирования все пользователи и другие площадки смогли подключиться к перенесенным сервисам на ЦОД 2.
Примечание.
Кроме всего вышеописанного, был еще план Б на случай, если потребуется возврат в ЦОД 1.
Мы были готовы к тому, что если проверка серверов в ЦОД 2 выдала результат о каких-либо ошибках, то происходит откат в ЦОД 1 согласно плану. Если тесты прошли удачно, то производится настройка сетевых маршрутов в ЦОД 2.
На практике некоторые сервисы пришлось вернуть в состояние работы из ЦОД 1. Благодаря гибкости Carbonite и таким вещам, как test failover, процесс тестирования настройки был нетрудным.
Кроме всего вышеописанного, был еще план Б на случай, если потребуется возврат в ЦОД 1.
Мы были готовы к тому, что если проверка серверов в ЦОД 2 выдала результат о каких-либо ошибках, то происходит откат в ЦОД 1 согласно плану. Если тесты прошли удачно, то производится настройка сетевых маршрутов в ЦОД 2.
На практике некоторые сервисы пришлось вернуть в состояние работы из ЦОД 1. Благодаря гибкости Carbonite и таким вещам, как test failover, процесс тестирования настройки был нетрудным.
От миграции архива к Disaster Recovery
Локации, которые слили между собой, — это не единственные ЦОДы, находящиеся в распоряжении компании.
Как известно, любой успех окрыляет. И созрела мысль: «Раз мы такие молодцы и так замечательно мигрировали данные из ЦОД1 в ЦОД2, может быть, сделаем что-то подобное для Disaster Recovery?»
Да, действительно, получившаяся схема уже во многом напоминает систему Disaster Recovery примерно третьего уровня. Того самого, где „Electronic vaulting. Data is electronically transmitted to a hot site“. Когда бюджета на полное и порой избыточное дублирование систем пока нет, но для быстрого восстановления работоспособности (как и для того, чтобы было куда перемещать резервную копию при off-site) уже нужно иметь площадку в резервном ЦОД.
Каждый из оставшихся ЦОД может представлять собой резервную площадку для того или иного сервиса.
Остается докупить необходимое оборудование (пусть даже не в полном, а очень усеченном объеме), установить агенты Carbonite на критически важные серверы — и вот оно, счастье. Разумеется, не слишком быстрый канал накладывает свой отпечаток. Поэтому нужно было предусмотреть возможность обойти данное ограничение. Например, использовать терминальный доступ для критически важных сервисов, пока сотрудники IT-отдела ликвидируют аварию в своем мини-ЦОД.
И снова про архитектуру решения
Как уже было сказано выше, Carbonite работает на уровне операционной системы. Главное, чтобы были установлены агенты, имелось достаточно дискового пространства и система исправно работала.
В случае с централизованной системой управления пришлось бы устанавливать еще и сервер управления и его потом обслуживать. Проще говоря, пришлось бы отвечать на вопрос: «Как бэкапить бэкап-сервер?»
В децентрализованной системе, такой как Carbonite, этот вопрос снимается.
Carbonite не имеет такой ахиллесовой пяты, что для нашей задачи выглядит привлекательно.
Carbonite не имеет такой ахиллесовой пяты, что для нашей задачи выглядит привлекательно.
Архитектура Carbonite предусматривает несколько вариантов топологии. В нашем случае использовался простейший вариант: «точка-точка» или Active-Standby. Но можно настроить и вариант «один ко многим» и «многие к одному», и «многие к многим». Если появится несколько локаций, то будет возможность изменить топологию на более сложную, отвечающую новым требованиям.
Полезная фишка при создании схемы Disaster Recovery — все тот же Test Failover, позволяющий поднять стороннюю машину и перенести на ней данные, не трогая основную production-среду. Возможность регулярно проводить учения по восстановлению — это действительно важный момент для обеспечения отказоустойчивости.
Disaster Recovery: вот что получилось
В описанном варианте используются две локации, данные постоянно реплицируются из одной в другую и наоборот.
Допустим, в первой локации происходит авария. Однако остается доступна вторая локация со всем информационным содержимым, отреплицированным ранее. То есть в любом случае будет доступ к критичным сервисам, например, через подключение к терминальному серверу.

Что это дает помимо временного доступа для критичных задач? Во-первых, это снимает лишнее напряжение с IT-департамента. Когда быстро притушили часть проблем, есть возможность более спокойно заняться восстановлением IT-инфраструктуры.
Во-вторых, после восстановления есть откуда забирать данные. На вновь поднятую площадку данные восстанавливаются из предыдущей локации.
Что в итоге
Нам удалось реализовать проект консолидации IT-ресурсов на одной площадке без остановки бизнеса и в сжатые сроки.
В процессе миграции произвели обновление IT-инфраструктуры с поэтапным тестированием благодаря функции Carbonite Test Failover. Такой подход позволил значительно снизить риски и сократить время общего downtime.
Какие из этого можно сделать выводы?
Во-первых, мы попали не только на переезд, но и на обновление. С одной стороны, вроде за раз и обновили, и переехали, с другой стороны, это сильно усложнило задачу. Если бы репликация через тот же Carbonite работала по-другому (на более низком уровне), не умела передавать данные as-is и так далее, то подобный переход был бы вряд ли возможен.
Во-вторых, мы потратили дополнительное время на тестирование системы, используя несколько раз после передачи данных старую площадку как «запасной парашют», чтобы все идеально настроить на основной. Излишний перфекционизм? Может быть. Но иначе можно было запросто оказаться с набором неизвестных проблем, которые пришлось бы дожигать через ввод дополнительных downtime.
В-третьих, как выяснилось, узкий канал — это не приговор, а руководство к действию. Трафик удалось оптимизировать, данные сжать, репликацию данных перенести на менее загруженные часы.
Анализатор пропускной способности канала позволил нам найти оптимальное время и скорость передачи данных, чтобы не оказывать пагубное воздействие на обмен данными с продакшн-системами и в то же время не переплачивать за избыточные каналы.
Вот так выбор правильной системы миграции позволяет решить и многие сопутствующие проблемы, если с умом подходить к использованию всех возможностей.