Борьба за студентов, из которых вырастают хорошие IT-специалисты, заставляет потенциальных работодателей придумывать новые форматы поиска и привлечения талантов. Один из них выстрелил осенью 2019 года — это BigDataCamp — пятидневный интенсив по Data Science, который проходил в московском офисе МегаФона. Он объединил в себе практикум и хакатон по большим данным. Лучшие его участники могли получить приглашение на стажировку в МегаФон с возможным последующим трудоустройством. Как это выглядело для участников и организаторов — под катом.
От стажера до аналитика: как прокачаться в работе
Антон Сысоев
Участник BigDataCamp, который из стажера бэкенд-разработки переквалифицировался в дата-аналитика. Ему пришлось прокачать математику и вспомнить все, чему он научился в университете и на множестве курсов. Антон стал абсолютным победителем интенсива и получил приглашение на работу.
С выбором профессии у меня все решилось быстро и просто. Я еще в седьмом классе узнал, что центр дополнительного образования у нас в городе проводит конкурс-отбор на обучение программированию. Я прошел, меня затянуло, вжух — вот уже учусь на IT-специальности в универе.
Я поступил в МГТУ имени Баумана. Университет превосходно научил меня самостоятельности: во время первого семестра я понял, что актуальных знаний мне в вузе не получить, поэтому надо постигать все самому. Занимался самообразованием, учился в Технопарке Mail.ru Group в Бауманке.
Все, что я понял и что имеет отношение к современному миру, я изучил сам. Университетская программа далека от жизни. Хорошие дисциплины — иголки в стоге сена. Хорошо, если попадется одна за семестр.
А еще я сразу после школы начал искать работу, устроился на стажировку в известную IT-компанию. Да, при этом приходилось проворачивать хитрые трюки с расписанием, но мой приоритет — получение реальных «боевых» навыков на работе, а учеба — дополнение, которое я не собираюсь бросать.
Примерно полгода назад я понял, что аналитика данных — это интересная тема, начал сам изучать вопрос, проходил онлайн-курсы. Не открою Америку, если скажу, что математическая основа была сложной. Всю необходимую информацию опять нашел сам в интернете. А BigDataCamp стал моим первым оффлайн-курсом.
Ключи к победе
О BigDataCamp мы с друзьями узнали из рекламы во ВКонтакте. Решили подать заявку и все втроем поступили. Правда, потом на хакатоне нас раскидали по разным командам, новые знакомства приходилось заводить на ходу.
Формат мероприятия отличный — неделя интенсива с чередующимися теорией и практикой.
Система оценки была простой. Можно было сдавать задания после дедлайна или начинать делать их раньше срока. Первая проблема решалась ручной проверкой кода, а вот вторая мешала в последние дни занятий. Приходилось выбирать между честным слушанием лекционного материала и досрочным решением задач, чтобы просто не отстать от других участников, которые уже вовсю занимались практикой.
Перед началом хакатона нас поделили на команды, ориентируясь на заработанные баллы. Организаторы назначили меня формальным лидером группы. Я уже имел некоторый опыт руководства командой, поэтому быстро распределил задачи, чтобы люди сразу начинали что-то делать и получать результаты.
На хорошем хакатоне решают реальные бизнес-задачи. Потому что ломать голову над сферическим заданием в вакууме неинтересно.
Задача, которую нужно было решить на соревновании, связана с оттоком. На входе мы получили данные о потреблении абонентами услуг связи, которые мы первым делом внимательно исследовали. И только потом, когда все участники команды разобрались, что к чему, приступили к визуализации. Поставили на то, что основная цель хакатона — это демонстрация навыков работы с данными, а не построение самой успешной модели. Подход оказался правильным.
Будни дата-аналитика
Принимая участие в BigDataCamp, я особо не рассчитывал на получение места в компании. Поэтому, получив оффер, взял время на обдумывание. В принципе, у меня уже была неплохая работа, но перспектива попробовать себя в роли дата-аналитика все-таки перевесила.
Сразу на старте я включился в интересный проект. Это задача, связанная с нахождением оптимальных параметров начисления бонусов за пополнение баланса. Необходимо определить, кому из абонентов стоит делать предложение о бонусе за пополнение и на какую сумму.
В ближайшие месяцы я планирую поработать с разными типами задач, чтобы понять, как профессия соответствует моим ожиданиям. А пока — новая команда, работа по принципам AGILE, новый стек технологий и новые практики. Все это очень интересно.
Из математиков в айтишники: как попасть в профессию
Мария Чернова
Пополнила ряды айтишников после BigDataCamp. Сходила на интенсив и хакатон, показала отличный результат и получила оффер от МегаФона. Для нее самой это оказалось приятной неожиданностью — будучи математиком, никаких карьерных планов в IT Мария не строила. Она просто хотела поддержать друга, а в итоге заинтересовалась новой сферой и поменяла работу.
Никогда не мечтала стать айтишником. Эта профессия казалась чем-то непонятным и неинтересным. Мне нравится чистая математика, но вот найти такую работу не в институте или школе — проблема.
В бакалавриате я училась в НГУ на механико-математическом факультете и после выпуска не понимала, куда двигаться дальше. Решила продолжить учебу, поступила в Бауманку. На первом курсе магистратуры были учебные курсы, связанные с машинным обучением. Там я поняла, что мне действительно интересно это направление, и дальше начала самостоятельно изучать основы, прошла онлайн-курсы по ML на Coursera. А спустя четыре месяца попала на BigDataCamp.
Big Data — это настолько большие данные, что обычные операции над ними невозможны, стандартные алгоритмы не работают. Нужно придумывать что-то новое.
О мероприятии я узнала от друга из Новосибирска. Это была отличная возможность попасть на мероприятие в Москве: МегаФон оплачивал проезд, проживание и питание. В общем, за компанию подала заявку, прошла тестирование. По иронии судьбы я прошла отбор, а друг — нет.
Разделяй и властвуй
На интенсиве было интересно, там схожие с университетскими дисциплины. Но все было не так безоблачно, как хотелось: на второй день занятий я получила письмо, что в университете срочно требуют подготовить отчет по летней практике. В результате днем пришлось заниматься на интенсиве, а по вечерам писать этот отчет. Неделя тогда выдалась насыщенная.
На BigDataCamp использовалась балльно-рейтинговая система, баллы начислялись за выполнение практических задач в первые четыре дня интенсива. Я помогала некоторым участникам с решением, сама тоже просила помощи. С некоторыми ребятами мы подружились и общаемся до сих пор.
На пятый день был хакатон, где нас разделили по командам в соответствии с рейтингом. Меня назначили руководителем группы из четырех человек. Это был интересный опыт. Основная задача руководителя команды состоит в грамотном распределении обязанностей. Пришлось столкнуться и с волнением членов команды, и с нежеланием одного из них что-либо делать.
Стажировка: а задачи-то совсем другие
Честно говоря, на стажировку меня пригласили сразу после интенсива. Благодаря системе дополнительной оценки я набрала много баллов. У участников были наклейки, которые они могли дарить другим за помощь — я собрала много таких стикеров.
Когда предложили стажировку, я не стала раздумывать, сразу же уволилась с текущей работы и устроилась в МегаФон.
Когда предложили стажировку, я не стала раздумывать, сразу же уволилась с текущей работы и устроилась в МегаФон.
Сложно представить, что такая работа может быть интересной, но выглядит все именно так
Реальные задачи, с которыми приходится сталкиваться в офисе, отличаются от заданий хакатона степенью погружения: на хакатоне ты стремишься сделать задание быстро, пусть даже не очень качественно, на работе же ориентируешься в первую очередь на результат. Также на хакатоне не нужно было самим собирать данные и делать их предобработку. В реальности это занимает больше половины времени работы над задачей.
Меня окружают ребята, которые вели лекции на интенсиве или помогали с практикой, поэтому адаптация прошла легко и быстро. Приятно ощущать поддержку и заинтересованность в том, чтобы у тебя все получилось. От стажера до аналитика я доросла за три месяца. Хотя мне повезло, я делала модель для одного из самых топовых проектов МегаФона «Персональные предложения», которые можно «вытрясти» из смартфона. Моя модель определяет, одобрит ли абонент предложение со специально подобранной для него голосовой опцией.
Большие данные и код: как раскрыть потенциал на хакатоне
Артем Селезнев
Аналитик больших данных МегаФона. Артем был техническим руководителем BigDataCamp и преподавателем на интенсиве. А еще он создал для BigDataCamp онлайн-платформу для подсчета баллов и анализа кода участников.
Я в свое время прошел тернистый путь поиска профессии, побывал в роли специалиста по компьютерным сетям, преподавателя в колледже и программиста-хакатонщика. Что-то казалось слишком простым, что-то — однообразным. В феврале 2019 года я перешел в МегаФон аналитиком больших данных. Здесь проектов хватает на всех, а их сложность и разноплановость не дают заскучать. Хотя, конечно, есть в работе аналитика и свои минусы — мне бы хотелось больше кодить.
Так что создание онлайн-платформы подсчета баллов для BigDataCamp было моей собственной идеей. Немного повозился с кодом, и получилась несложная клиент-серверная система на Python, которая отсылала код решений примеров на сервер, проверяла его работоспособность тест-кейсами и высчитывала рейтинг участников.
Это позволило получать результаты проверки онлайн и следить за тем, на каком этапе выполнения практических занятий находятся участники. Также это была система защиты от жульничества участников, мы проверяли их на уникальность кода.
Получилось решение, совместившее в себе проверку заданий, таблицу рейтингов и мониторинг активности участников. По результатам мероприятия я немного доработал систему, и мы планируем ее использовать в других подходящих проектах.
BigDataCamp МегаФона: откуда он появился, как прошел и что в итоге получилось
Идея BigDataCamp появилась на одном из воркшопов с HR. Аналитики хотели попробовать себя в преподавании, а HR-отдел искал новый способ поиска стажеров и джунов. BigDataCamp закрывал обе потребности и в то же время отличался от стандартных курсов и хакатонов.
Хакатон прокачал сотрудников компании. Математическая основа больших данных сложна и разнообразна — это различные методы машинного обучения, задачи оптимизации, статистика, линейная алгебра. Сотрудники, привлеченные в качестве преподавателей, на каждый час выступления потратили порядка 30 часов на поиск материалов, подготовку презентаций и тестовых заданий. Освежили свои знания, попрактиковались в преподавании, работе с аудиторией, предварительно взяв несколько уроков у опытных тренеров.
Для студентов подобное мероприятие — это возможность не только получить новые знания и проверить их на хакатоне, но и реальное недельное погружение в жизнь телеком-компании. «Плюшки» получили все участники: бесплатное обучение, для ребят из других городов предусмотрена оплата дороги и проживания, наконец, afterparty после хакатона.
Вступительное техническое тестирование было подробным и сложным, включало в себя проверку знаний от Unix и Python до статистики, алгоритмов и структур данных. Из примерно 2000 заявок были отобраны 20 студентов. Помимо результатов тестов, при отборе учитывалось и содержание мотивационного письма: с какой целью человек идет на мероприятие, насколько он стремится стать частью команды МегаФона.
Вопросы тестирования были непростыми, вот несколько для примера:

Всех, кто прошел первый этап, ждал интенсив. Организаторам необходимо было выбрать формат, который позволил бы участникам погрузиться в обучение, сфокусироваться на нем, но при этом не занял бы слишком много времени. В итоге получилась конфигурация из четырех дней обучения, наполненных лекциями и практическими занятиями, с последующим однодневным хакатоном.
Темы для занятий были такие:
- Математика и Python для анализа данных. Основные средства разработки.
- Введение в машинное обучение. Предобработка данных. Алгоритмы kNN и наивный байес. Знакомство с sklearn.
- Линейные модели и метрики качества.
- Деревья решений. Boosting и Bagging.
После теоретического блока шла практика: участники решали задачи, писали код.
Примеры задач:
Метрики качества
В данном задании вам необходимо реализовать 4 основные метрики:
- M A E;
- M S E;
- R M S E;
- R².
Каждая из метрик принимает на вход 2 одномерных numpy массива:
- y_true — истинные значения;
- y_predict — предсказанные значения.
Каждая из функций должна возвращать одно число.
!!ВАЖНО!! не используйте в этих функциях циклы — тогда она будет вычислительно неэффективной.
!!ВАЖНО!! не используйте в этих функциях циклы — тогда она будет вычислительно неэффективной.
In=[12]:
def MAError(y_true, y_predict):
# YOUR CODE HERE
return error
def MSError(y_true, y_predict):
# YOUR CODE HERE
return error
def RMSEror(y_true, y_predict):
# YOUR CODE HERE
return error
def R_square(y_true, y_predict):
# YOUR CODE HERE
return error
def all_metric(y_true, y_predict):
d = {}
d['MAE'] = [MAError(y_true, y_predict)]
d['MSE'] = [MSError(y_true, y_predict)]
d['RMSE'] = [RMSError(y_true, y_predict)]
d['R_square'] = [R_square(y_true, y_predict)]
return d
# TESTS
assert round(MAError(y_true=Y_train, y_predict=Y_train_predict), 3) == 1.274, 'Неверно реализован расчет'
assert time_delta(MAError, Y_train, Y_train_predict) < 1.5, 'Функция работает слишком долго. Возможно, вы используете лишние циклы.'
assert round(MSError(y_true=Y_train, y_predict=Y_train_predict), 3) == 2.22, 'Неверно реализован расчет'
assert time_delta(MSError, Y_train, Y_train_predict) < 1.5, 'Функция работает слишком долго. Возможно, вы используете лишние циклы.'Немного теории
Мы разберем основные метрики качества и функционалы потерь задачи регрессии. Далее все будем называть метриками.
Метрики необходимы для:
- поиска оптимального решения;
- оценки качества работы модели;
- сравнения моделей;
- интерпретации результатов.
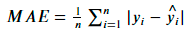
+ легко интерпретировать
+ единицы измерения таргета и метрики — эквивалентны
+ устойчивы к выбросам
- не ограничена сверху
- не дифференцируема в таком виде
+ единицы измерения таргета и метрики — эквивалентны
+ устойчивы к выбросам
- не ограничена сверху
- не дифференцируема в таком виде
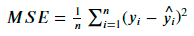
+ дифференцируема
+ чувствительна к выбросам
- не ограничена сверху
- сложно интегрировать
+ чувствительна к выбросам
- не ограничена сверху
- сложно интегрировать
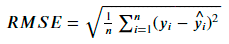
+ дифференцируема
- не ограничена сверху
- еще сложнее интерпретировать
- не ограничена сверху
- еще сложнее интерпретировать
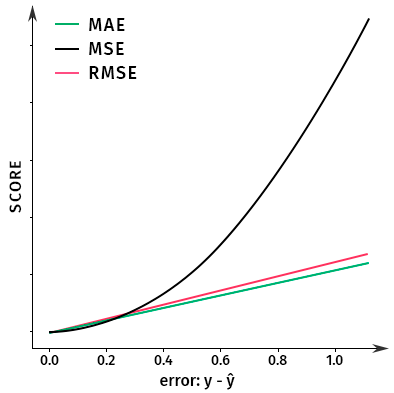
Основное различие R M S E и M A E заключается в том, что минимизация R M S E стремится к средней оценке, а M A E к медиане.
y — истинное значение, ŷ — предсказанное значение.
Две попытки объединить положительные свойства метрик:
Функция потерь Хьюбера:
- ведет себя как M S E на ошибках меньше σ и как M A E в противном случае. Что не дает «взрываться» метрике на больших значениях и «жестко» реагирует на маленькие остатки.
- Всё так же неудобно дифференцировать.
Log-Cosh Loss:
- принимает меньшие значения по сравнению с функцией Хьюбера на всем множестве.
- Дважды дифференцируема, что необходимо в некоторых методах численной оптимизации.
Хакатон BigDataCamp был не совсем обычным, особенно с точки зрения оценки. Для победы надо было не просто создать модель, показывающую лучший результат, но и продемонстрировать осмысленный подход к используемым метрикам, обосновать сделанный выбор и визуализировать его.
С BigDataCamp никто не ушел без приобретений. Кто-то из участников открыл для себя новое направление работы, кто-то устроился на стажировку, кто-то — на работу в крупную компанию, кто-то приобрел новых друзей, а кто-то просто провел время с пользой. По итогам BigDataCamp МегаФон закрыл несколько важных вакансий. А действующие сотрудники компании получили бесценный опыт организации сложного процесса обучения и тестирования.