Сколько бы ни говорили, что логи способны полностью заменить отладку, увы и ах — это не совсем так, а иногда — совсем не так. Действительно, иногда и в голову не придет, что надо было писать в лог именно эту переменную — в то же время, в режиме отладки можно часто просмотреть сразу несколько структур данных; можно, в конце концов, наткнутся на проблемный участок абсолютно случайно. Поэтому иногда отладка неизбежна, и часто она способна сэкономить очень немало времени.
Отлаживать однопоточное Java приложение просто. Отлаживать многопоточное Java приложение — чуть сложнее, но все равно просто. Отлаживать мультипроцессное Java приложение? С процессами, запущенными на разных машинах? Это определенно сложнее. Именно поэтому все руководства по Hadoop рекомендуют обращаться к отладке только и исключительно тогда, когда другие опции (читай: логгинг) исчерпаны и не помогли. Ситуация зачастую усложняется тем, что на больших кластерах у вас может и не быть доступа к конкретным map/reduce узлам (именно с этим вариантом я и столкнулся). Но давайте решать проблему по частям. Итак…
Самый простой вариант из всех возможных. Локальная инсталляция Hadoop — все выполняется на одной машине, и более того — в одном процессе, но в разных потоках. Отладка эквивалентна отладке обычного мультипоточного Java приложения — что может быть тривиальнее?
Как же этого добиться? Мы идем в директорию, где у нас развернут наш локальных Hadoop (я полагаю, что вы умеете это делать или умеете прочитать соответствующую инструкцию и уже теперь с этим справитесь).
Наша задача — добавить еще одну опцию JVM, где-то в районе 282-283 строки (в зависимости от версии, номер может и измениться), сразу после того, как скрипт закончил формировать
Что мы сказали этим заклинанием? Мы сказали, что мы хотим запускать Java машину с поддержкой удаленного отладчика, который должен будет соединиться на порт 1044, а пока он не подсоединится, выполнение программы будет приостановлено (сразу после старта). Все просто, правда? Осталось пойти в Eclipse (или любую другую Java IDE) и добавить там сессию удаленной отладки. Ну, например, вот так:
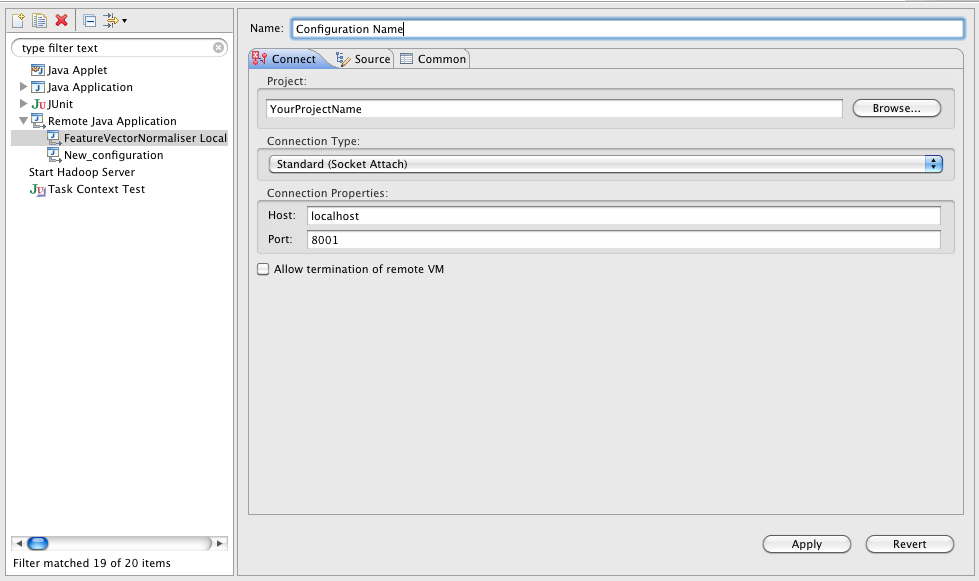
Если вы запускаете отладку не на локальной машине, а на каком-то сервере (что вполне нормально и обычно я так и делаю — оно мне надо, свой лаптоп грузить такими вещами, когда есть специальные дев-сервера с диким количеством памяти и многими процессорами?), то просто меняете
Хадуп стартует и ничего не делает, JVM сообщает что ждет подключения:
Все, теперь подключайтесь Eclipse'ом к сессии отладки — и ждите, пока «всплывет» ваш breakpoint. Отладка map/reduce классов ничем (в рамках данного сценария) не отличается от отладки gateway кода.
В pseudo-distributed режиме Hadoop ближе к тому состоянию, в котором он будет работать в production (а мы, соответственно, ближе к той головной боли, которую будем иметь когда что-то все-таки сломается). Отличие заключается в том, что map/reduce задачи выполняются в отдельных процессах, HDFS уже «настоящая» (а не имитирована локальной файловой системой — хотя и расположена всего на одном узле), и отлаживать это все труднее. То есть можно, конечно же, применить подход, описанный выше к старту новых процессов, но я это сделать не пытался и есть подозрение, что без модификации кода самого Hadoop это попросту не сработает.
Есть два основных подхода к решению задачи отладки в таком режиме — один из них использование локального таск-трекера, а другой —
Итак, IsolationRunner это вспомогательный класс, который позволяет максимально точно имитировать процесс выполнения конкретной задачи (Task), по сути, повторяя его исполнение. Для того, чтобы воспользоваться им, нужно сделать несколько телодвижений:
Как я уже заметил выше, этот способ будет гарантированно работать в pseudo-distributed mode, но также он отлично сработает если у вас есть доступ к узлам map/reduce (это практически идеальная ситуация). Но есть еще и третий сценарий, самый сложный…
Вы на настоящем, «боевом» кластере, в котором за тыщу машин, и никто вам не даст права залогиниться на одну из них, кроме специально предназначенных для этого шлюзов — gateway machines (отсюда и название gateway code, потому что на них он и выполняется). Все по-взрослому, хотя вы все еще работаете на тестовом «маленьком» наборе данных в пол-терабайта, но головная боль с отладкой уже встает в полный рост. Здесь, пожалуй, будет уместно повторить совет про логгинг — если вы его еще не делаете, то сделайте. Как минимум это позволит вам частично локализовать пролему, и, возможно, вы сумеете использовать один из двух вышеперечисленных способов чтобы ее идентифицировать и решить. Здесь нет простого способа отладки, который даст предсказуемые результаты. Строго говоря, все, что вы можете сделать, это заставить вашу задачу выполняться локально, на шлюзе — в этом случае вы будете работать с настоящей production HDFS, но точно воспроизвести поведение на конкретных узлах, скорее всего, не сможете.
Все, что вам нужно сделать для локального выполнения задачи, это установить
Итак, вот вам немного информации к размышлению на тему, каким непростым делом может быть отладка map/reduce приложений. Нисколько не отрицая всего вышеперечисленного, я бы рекомендовал следующую стратегию:
Удачной отладки!
P.S. написано по мотивам моего старинного поста и недельной отладки hadoop-приложения, Java-библиотеки и JNI, ее поддерживающей. Кроме того, привет Умпутуну и Бобуку, которые своим 179 выпуском РТ и рассказом про map/reduce напомнили мне, что есть вещи (хоть их и немного) в которых я разбираюсь и могу о них рассказать ;-)
Отлаживать однопоточное Java приложение просто. Отлаживать многопоточное Java приложение — чуть сложнее, но все равно просто. Отлаживать мультипроцессное Java приложение? С процессами, запущенными на разных машинах? Это определенно сложнее. Именно поэтому все руководства по Hadoop рекомендуют обращаться к отладке только и исключительно тогда, когда другие опции (читай: логгинг) исчерпаны и не помогли. Ситуация зачастую усложняется тем, что на больших кластерах у вас может и не быть доступа к конкретным map/reduce узлам (именно с этим вариантом я и столкнулся). Но давайте решать проблему по частям. Итак…
Сценарий первый: локальный Hadoop
Самый простой вариант из всех возможных. Локальная инсталляция Hadoop — все выполняется на одной машине, и более того — в одном процессе, но в разных потоках. Отладка эквивалентна отладке обычного мультипоточного Java приложения — что может быть тривиальнее?
Как же этого добиться? Мы идем в директорию, где у нас развернут наш локальных Hadoop (я полагаю, что вы умеете это делать или умеете прочитать соответствующую инструкцию и уже теперь с этим справитесь).
$ cd ~/dev/hadoop
$ cp bin/hadoop bin/hdebug
$ vim bin/hdebug Наша задача — добавить еще одну опцию JVM, где-то в районе 282-283 строки (в зависимости от версии, номер может и измениться), сразу после того, как скрипт закончил формировать
$HADOOP_OPTS:
HADOOP_OPTS="$HADOOP_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,address=1044,server=y,suspend=y"Что мы сказали этим заклинанием? Мы сказали, что мы хотим запускать Java машину с поддержкой удаленного отладчика, который должен будет соединиться на порт 1044, а пока он не подсоединится, выполнение программы будет приостановлено (сразу после старта). Все просто, правда? Осталось пойти в Eclipse (или любую другую Java IDE) и добавить там сессию удаленной отладки. Ну, например, вот так:
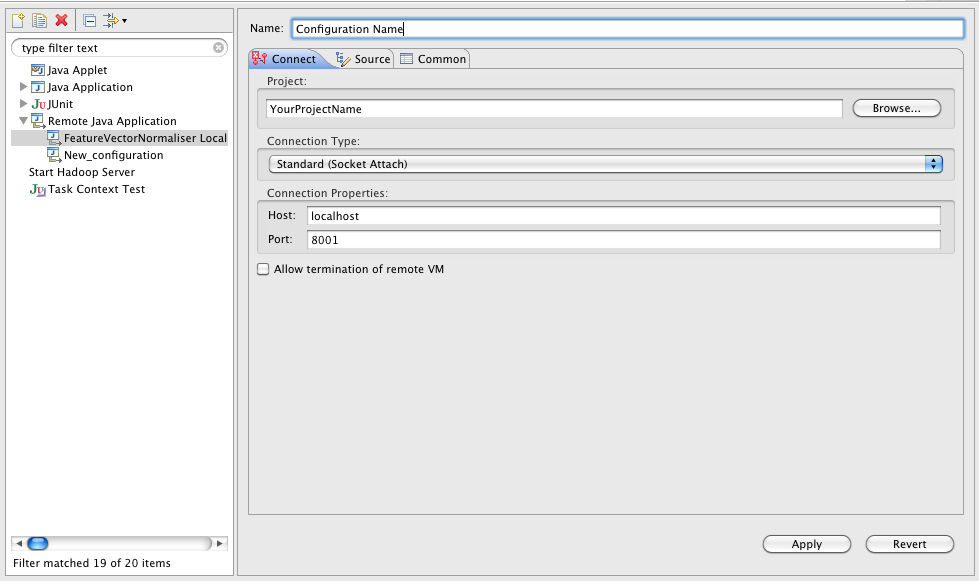
Если вы запускаете отладку не на локальной машине, а на каком-то сервере (что вполне нормально и обычно я так и делаю — оно мне надо, свой лаптоп грузить такими вещами, когда есть специальные дев-сервера с диким количеством памяти и многими процессорами?), то просто меняете
localhost на требуемый хост. Дальше ставите breakpoint в коде программы (для начала — в основном теле, так называемый gateway code), и стартуете Hadoop:
bin/hadoop jar myApplication.jar com.company.project.Application param1 param2 param3
Хадуп стартует и ничего не делает, JVM сообщает что ждет подключения:
Listening for transport dt_socket at address: 1044
Все, теперь подключайтесь Eclipse'ом к сессии отладки — и ждите, пока «всплывет» ваш breakpoint. Отладка map/reduce классов ничем (в рамках данного сценария) не отличается от отладки gateway кода.
Сценарий второй: pseudo-distributed mode
В pseudo-distributed режиме Hadoop ближе к тому состоянию, в котором он будет работать в production (а мы, соответственно, ближе к той головной боли, которую будем иметь когда что-то все-таки сломается). Отличие заключается в том, что map/reduce задачи выполняются в отдельных процессах, HDFS уже «настоящая» (а не имитирована локальной файловой системой — хотя и расположена всего на одном узле), и отлаживать это все труднее. То есть можно, конечно же, применить подход, описанный выше к старту новых процессов, но я это сделать не пытался и есть подозрение, что без модификации кода самого Hadoop это попросту не сработает.
Есть два основных подхода к решению задачи отладки в таком режиме — один из них использование локального таск-трекера, а другой —
IsolationRunner'а. Сразу скажем, что первый вариант может дать лишь очень приблизительные результаты, поскольку ноды будут другие и весь код будет выполняться в одном процессе (как в предыдущем варианте). Второй же вариант дает очень точное приближение реальной работы, но — увы и ах, невозможен в том случае, если у вас нет доступа на конкретные Task Nodes (что в случае больших production cluster'ов весьма и весьма вероятно). Итак, IsolationRunner это вспомогательный класс, который позволяет максимально точно имитировать процесс выполнения конкретной задачи (Task), по сути, повторяя его исполнение. Для того, чтобы воспользоваться им, нужно сделать несколько телодвижений:
- Установить значение
keep.failed.tasks.filesвtrueв конфигурации задачи (job configuration). В зависимости от того, как именно вы формируете свою задачу, это может быть сделано либо редактированием XML файла, либо в тексте программы, но, в любой случае, это несложно. Этим вы даете инструкцию task tracker'у, что если задача была завершена с ошибкой, не надо удалять ее конфигурацию и данные. - Дальше официальное руководство рекомендует отправиться на тот узел, на котором задача была завершена с ошибкой. В нашем случае — это все еще наш локальный (или не очень локальный, но все равно один-единственный) хост; директория, где находится taskTracker, зависит от конфигурации, но в режиме «по умолчанию» это скорее всего будет
hadoop/bin. Нагло скопируем пример из руководства:
$ cd <local path>/taskTracker/${taskid}/work $ bin/hadoop org.apache.hadoop.mapred.IsolationRunner ../job.xml
В нашем случае мы можем и должны заменитьbin/hadoopнаbin/hdebug, который мы создали выше (ну и понятно, что путь относительный будет каким-то другим ;-) ). Как результат — мы отлаживаем упавший таск, работая с именно теми данными, которые привели к его падению. Просто, красиво, удобно. - Подключаемся отладчиком, действуем, находим ошибку, радуемся
Как я уже заметил выше, этот способ будет гарантированно работать в pseudo-distributed mode, но также он отлично сработает если у вас есть доступ к узлам map/reduce (это практически идеальная ситуация). Но есть еще и третий сценарий, самый сложный…
Сценарий третий: production cluster
Вы на настоящем, «боевом» кластере, в котором за тыщу машин, и никто вам не даст права залогиниться на одну из них, кроме специально предназначенных для этого шлюзов — gateway machines (отсюда и название gateway code, потому что на них он и выполняется). Все по-взрослому, хотя вы все еще работаете на тестовом «маленьком» наборе данных в пол-терабайта, но головная боль с отладкой уже встает в полный рост. Здесь, пожалуй, будет уместно повторить совет про логгинг — если вы его еще не делаете, то сделайте. Как минимум это позволит вам частично локализовать пролему, и, возможно, вы сумеете использовать один из двух вышеперечисленных способов чтобы ее идентифицировать и решить. Здесь нет простого способа отладки, который даст предсказуемые результаты. Строго говоря, все, что вы можете сделать, это заставить вашу задачу выполняться локально, на шлюзе — в этом случае вы будете работать с настоящей production HDFS, но точно воспроизвести поведение на конкретных узлах, скорее всего, не сможете.
Все, что вам нужно сделать для локального выполнения задачи, это установить
mapred.job.tracker в значение local (в конфигурации задачи). Теперь вы, при некотором везении, сможете подключиться отладчиком (впрочем, скорее всего не вашим любимым Eclipse'ом, а чем-то консольным, запущенным в той же сети — или прокинув SSH туннель, если это доступно) и выполнять ваш код на шлюзе. Из плюсов — вы работаете с настоящими данными на настоящем HDFS. Из минусов — если ошибка плавающая и воспроизводится, не дай Б-г, только на одном-двух узлах кластера, черта с два вы ее найдете. В сухом остатке — это лучшее, чего вы можете добиться без общения с командой поддержки кластера и запросом временного доступа на конкретный узел. Заключение
Итак, вот вам немного информации к размышлению на тему, каким непростым делом может быть отладка map/reduce приложений. Нисколько не отрицая всего вышеперечисленного, я бы рекомендовал следующую стратегию:
- Расставьте отладочные сообщения по всему коду задачи — сперва редко (примерно), потом более часто, когда станет понятно, что падает таск, скажем, между 100 и 350 строкой
- Попытайтесь воспроизвести проблему на локальном Хадупе — очень часто это получится успешно, и вы сможете разобраться в чем дело
- Проверьте, есть ли у вас доступ на конкретные map/reduce узлы. Узнайте, реально ли его получить (хотя бы временно и не на все)
- Применяйте отладку методом пристального взгляда! Серьезно, это работает — только лучше, если взгляд не ваш: часто сторонний человек может увидеть баг за три секунды, когда ты уже к нему «присмотрелся» и не замечаешь в упор
- Если ничего не помогает — используйте разные комбинации описанных выше приемов. Хотя бы один из них сработает обязательно.
Удачной отладки!
P.S. написано по мотивам моего старинного поста и недельной отладки hadoop-приложения, Java-библиотеки и JNI, ее поддерживающей. Кроме того, привет Умпутуну и Бобуку, которые своим 179 выпуском РТ и рассказом про map/reduce напомнили мне, что есть вещи (хоть их и немного) в которых я разбираюсь и могу о них рассказать ;-)
