QoS — тема большая. Прежде чем рассказывать про тонкости настроек и различные подходы в применении правил обработки трафика, имеет смысл напомнить, что такое вообще QoS.
Quality of Service (QoS) — технология предоставления различным классам трафика различных приоритетов в обслуживании.
Во-первых, легко понять, что любая приоритезация имеет смысл только в том случае, когда возникает очередь на обслуживание. Именно там, в очереди, можно «проскользнуть» первым, используя своё право.
Очередь же образуется там, где узко (обычно такие места называются «бутылочным горлышком», bottle-neck). Типичное «горлышко» — выход в Интернет офиса, где компьютеры, подключенные к сети как минимум на скорости 100 Мбит/сек, все используют канал к провайдеру, который редко превышает 100 МБит/сек, а часто составляет мизерные 1-2-10МБит/сек. На всех.
Во-вторых, QoS не панацея: если «горлышко» уж слишком узкое, то часто переполняется физический буфер интерфейса, куда помещаются все пакеты, собирающиеся выйти через этот интерфейс. И тогда новопришедшие пакеты будут уничтожены, даже если они сверхнужные. Поэтому, если очередь на интерфейсе в среднем превышает 20% от максимального своего размера (на маршрутизаторах cisco максимальный размер очереди составляет как правило 128-256 пакетов), есть повод крепко задуматься над дизайном своей сети, проложить дополнительные маршруты или расширить полосу до провайдера.
Разберемся с составными элементами технологии
(дальше под катом, много)
Маркировка. В полях заголовков различных сетевых протоколов (Ethernet, IP, ATM, MPLS и др.) присутствуют специальные поля, выделенные для маркирования трафика. Маркировать же трафик нужно для последующей более простой обработки в очередях.
Ethernet. Поле Class of Service (CoS) — 3 бита. Позволяет разделить трафик на 8 потоков с различной маркировкой
IP. Есть 2 стандарта: старый и новый. В старом было поле ToS (8 бит), из которого в свою очередь выделялись 3 бита под названием IP Precedence. Это поле копировалось в поле CoS Ethernet заголовка.
Позднее был определен новый стандарт. Поле ToS было переименовано в DiffServ, и дополнительно выделено 6 бит для поля Differencial Service Code Point (DSCP), в котором можно передавать требуемые для данного типа трафика параметры.
Маркировать данные лучше всего ближе к источнику этих данных. По этой причине большинство IP-телефонов самостоятельно добавляют в IP-заголовок голосовых пакетов поле DSCP = EF или CS5. Многие приложения также маркируют трафик самостоятельно в надежде, что их пакеты будут обработаны приоритетно. Например, этим «грешат» пиринговые сети.
Очереди.
Даже если мы не используем никаких технологий приоритезации, это не значит, что не возникает очередей. В узком месте очередь возникнет в любом случае и будет предоставлять стандартный механизм FIFO (First In First Out). Такая очередь, очевидно, позволит не уничтожать пакеты сразу, сохраняя их до отправки в буфере, но никаких преференций, скажем, голосовому трафику не предоставит.
Если хочется предоставить некоторому выделенному классу абсолютный приоритет (т.е. пакеты из этого класса всегда будут обрабатываться первыми), то такая технология называется Priority queuing. Все пакеты, находящиеся в физическом исходящем буфере интерфейса будут разделены на 2 логических очереди и пакеты из привилегированной очереди будут отсылаться, пока она не опустеет. Только после этого начнут передаваться пакеты из второй очереди. Эта технология простая, довольно грубая, её можно считать устаревшей, т.к. обработка неприоритетного трафика будет постоянно останавливаться. На маршрутизаторах cisco можно создать
4 очереди с разными приоритетами. В них соблюдается строгая иерархия: пакеты из менее привилегированных очередей не будут обслуживаться до тех пор, пока не опустеют все очереди с более высоким приоритетом.
Справедливая очередь (Fair Queuing). Технология, которая позволяет каждому классу трафика предоставить одинаковые права. Как правило не используется, т.к. мало даёт с точки зрения улучшения качества сервиса.
Взвешенная справедливая очередь (Weighted Fair Queuing, WFQ). Технология, которая предоставляет разным классам трафика разные права (можно сказать, что «вес» у разных очередей разный), но одновременно обслуживает все очереди. «На пальцах» это выглядит так: все пакеты делятся на логические очереди, используя в
качестве критерия поле IP Precedence. Это же поле задаёт и приоритет (чем больше, тем лучше). Дальше, маршрутизатор вычисляет, пакет из какой очереди «быстрее» передать и передаёт именно его.
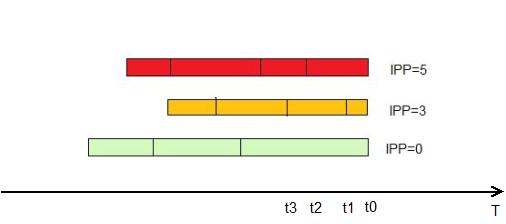
Считает он это по формуле:
dT=(t(i)-t(0))/(1+IPP)
IPP — значение поля IP Precedence
t(i) — Время, требуемое на реальную передачу пакета интерфейсом. Можно вычислить, как L/Speed, где L — длина пакета, а Speed — скорость передачи интерфейса
Такая очередь по умолчанию включена на всех интерфейсах маршрутизаторов cisco, кроме интерфейсов точка-точка (инкапсуляция HDLC или РРР).
WFQ имеет ряд минусов: такая очередизация использует уже отмаркированные ранее пакеты, и не позволяет самостоятельно определять классы трафика и выделяемую полосу. Мало того, как правило уже никто не маркирует полем IP Precedence, поэтому пакеты идут немаркированные, т.е. все попадают в одну очередь.
Развитием WFQ стала взвешенная справедливая очередь, основанная на классах (Class-Based Weighted Fair Queuing, CBWFQ). В этой очереди администратор сам задаёт классы трафика, следуя различным критериям, например, используя ACL, как шаблон или анализируя заголовки протоколов (см.NBAR). Далее, для этих классов
определяется «вес» и пакеты их очередей обслуживаются, соразмерно весу (больше вес — больше пакетов из этой очереди уйдёт в единицу времени)
Но такая очередь не обеспечивает строгого пропускания наиболее важных пакетов (как правило голосовых или пакетов других интерактивных приложений). Поэтому появился гибрид Priority и Class-Based Weighted Fair Queuing — PQ-CBWFQ, также известный как, Low Latency Queuing (LLQ). В этой технологии можно задать до 4х приоритетных очередей, остальные классы обслуживать по механизму CBWFQ
LLQ — наиболее удобный, гибкий и часто используемый механизм. Но он требует настройки классов, настройки политики и применения политики на интерфейсе.
Подробнее о настройках расскажу дальше.
Таким образом процесс предоставления качества обслуживания можно поделить на 2 этапа:
Маркировка. Поближе к источникам.
Обработка пакетов. Помещение их в физическую очередь на интерфейсе, подразделение на логические очереди и предоставление этим логическим очередям различных ресурсов.
Технология QoS — достаточно ресурсоёмкая и весьма существенно грузит процессор. И тем сильнее грузит, чем глубже в заголовки приходится залезать для классификации пакетов. Для сравнения: маршрутизатору гораздо проще заглянуть в заголовок IP пакета и проанализировать там 3 бита IPP, нежели раскручивать поток практически до уровня приложения, определяя, что за протокол идёт внутри (технология NBAR)
Для упрощения дальнейшей обработки трафика, а также для создания так называемой «области доверия» (trusted boundary), где мы верим всем заголовкам, относящимся к QoS, мы можем делать следующее:
1. На коммутаторах и маршрутизаторах уровня доступа (близко к клиентским машинам) ловить пакеты, раскидывать их по классам
2.В политике качестве действия перекрашивать заголовки по-своему или переносить значения QoS-заголовков более высокого уровня на нижние.
Например, на маршрутизаторе ловим все пакеты из гостевого WiFi домена (предполагаем, что там могут быть не управляемые нами компьютеры и софт, который может использовать нестандартные QoS-заголовки), меняем любые заголовки IP на дефолтные, сопоставляем заголовкам 3 уровня (DSCP) заголовки канального уровня (CoS),
чтобы дальше и коммутаторы могли эффективно приоритезировать трафик, используя только метку канального уровня.
Настройка LLQ
Настройка очередей заключается в настройке классов, затем для этих классов надо определить параметры полосы пропускания и применить всю созданную конструкцию на интерфейс.
Создание классов:
class-map NAME
match?
access-group Access group
any Any packets
class-map Class map
cos IEEE 802.1Q/ISL class of service/user priority values
destination-address Destination address
discard-class Discard behavior identifier
dscp Match DSCP in IP(v4) and IPv6 packets
flow Flow based QoS parameters
fr-de Match on Frame-relay DE bit
fr-dlci Match on fr-dlci
input-interface Select an input interface to match
ip IP specific values
mpls Multi Protocol Label Switching specific values
not Negate this match result
packet Layer 3 Packet length
precedence Match Precedence in IP(v4) and IPv6 packets
protocol Protocol
qos-group Qos-group
source-address Source address
vlan VLANs to match
Пакеты в классы можно рассортировывать по различным атрибутам, например, указывая ACL, как шаблон, либо по полю DSCP, либо выделяя конкретный протокол (включается технология NBAR)
Создание политики:
policy-map POLICY
class NAME1
?
bandwidth Bandwidth
compression Activate Compression
drop Drop all packets
log Log IPv4 and ARP packets
netflow-sampler NetFlow action
police Police
priority Strict Scheduling Priority for this Class
queue-limit Queue Max Threshold for Tail Drop
random-detect Enable Random Early Detection as drop policy
service-policy Configure Flow Next
set Set QoS values
shape Traffic Shaping
Для каждого класса в политике можно либо выделить приритетно кусок полосы:
policy-map POLICY
class NAME1
priority?
[8-2000000] Kilo Bits per second
percent % of total bandwidth
и тогда пакеты этого класса смогут всегда рассчитывать как минимум на этот кусок.
Либо описать, какой «вес» имеет данный класс в рамках CBWFQ
policy-map POLICY
class NAME1
bandwidth?
[8-2000000] Kilo Bits per second
percent % of total Bandwidth
remaining % of the remaining bandwidth
В обоих случаях можно указать как аболютное значение, так и процент от всей доступной полосы
Возникает резонный вопрос: а откуда маршрутизатор знает ВСЮ полосу? Ответ банален: из параметра bandwidth на интерфейсе. Даже если он не сконфигурирован явно, какое то его значение обязательно есть. Его можно посмотреть командой sh int.
Также обязательно помнить, что по умолчанию вы распоряжаетсь не всей полосой, а лишь 75%. Пакеты, явно не попавшие в другие классы, попадают в class-default. Эту настройку для дефолтного класса можно задать явно
policy-map POLICY
class class-default
bandwidth percent 10
max-reserved-bandwidth [percent]
Маршрутизаторы ревностно следят, чтобы админ не выдал случайно больше полосы, чем есть и ругаются на такие попытки.
Создаётся впечатление, что политика будет выдавать классам не больше, чем написано. Однако, такая ситуация будет лишь в том случае, если все очереди наполнены. Если же какая то пустует, то выделенную ей полосу наполненные очереди поделят пропорционально своему «весу».
Работать же вся эта конструкция будет так:
Если идут пакеты из класса с указанием priority, то маршрутизатор сосредотачивается на передаче этих пакетов. Причем, т.к. таких приоритетных очередей может быть несколько, то между ними полоса делится пропорционально указанным процентам.
Как только все приоритетные пакеты закончились, наступает очередь CBWFQ. За каждый отсчёт времени из каждой очереди «зачёрпывается» доля пакетов, указанная в настройке для данного класса. Если же часть очередей пустует, то их полоса делится пропорционально «весу» класса между загруженными очередями.
Применение на интерфейсе:
int s0/0
service-policy [input|output] POLICY
А что же делать, если надо строго рубить пакеты из класса, выходящие за дозволенную скорость? Ведь указание bandwidth лишь распределяет полосу между классами, когда очереди загружены.
Для решения этой задачи для класса трафика в политике есть технология
police [speed] [birst] conform-action [действие] exceed-action [действие]
она позволяет явно указать желаемую среднюю скорость (speed), максимальный «выброс», т.е. количество передаваемых данных за единицу времени. Чем больше «выброс», тем больше реальная скорость передачи может отклоняться от желаемой средней. Также указываются: действие для нормального трафика, не превышающего
указанную скорость и действие для трафика, превысившего среднюю скорость. Действия могут быть такими
police 100000 8000 conform-action?
drop drop packet
exceed-action action when rate is within conform and
conform + exceed burst
set-clp-transmit set atm clp and send it
set-discard-class-transmit set discard-class and send it
set-dscp-transmit set dscp and send it
set-frde-transmit set FR DE and send it
set-mpls-exp-imposition-transmit set exp at tag imposition and send it
set-mpls-exp-topmost-transmit set exp on topmost label and send it
set-prec-transmit rewrite packet precedence and send it
set-qos-transmit set qos-group and send it
transmit transmit packet
Часто возникает также и другая задача. Предположим, что надо ограничить поток, идущий в сторону соседа с медленным каналом.
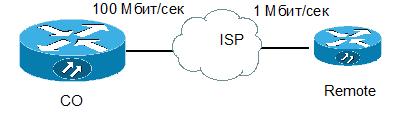
Дабы точно предсказать, какие пакеты дойдут до соседа, а какие будут уничтожены в силу загруженности канала на «медленной» стороне, надо на «быстрой» стороне создать политику, которая бы заранее обрабатывала очереди и уничтожала избыточные пакеты.
И тут мы сталкиваемся с одной очень важной вещью: для решения этой задачи надо сэмулировать «медленный» канал. Для этой эмуляции не достаточно только раскидать пакеты по очередям, надо ещё сэмулировать физический буфер «медленного» интерфейса. У каждого интерфейса есть скорость передачи пакетов. Т.е. в единицу времени каждый интерфейс может передать не более, чем N пакетов. Обычно физический буфер интерфейса рассчитывают так, чтобы обеспечить «автономную» работу интерфейсу на несколько единиц вермени. Поэтому физический буфер, скажем, GigabitEthernet будет в десятки раз больше какого-нибудь интерфейса Serial.
Что же плохого в том, чтобы запомнить много? Давайте рассмотрим подробно, что произойдёт, в случае если буфер на быстрой передающей стороне будет существенно больше буфера принимающей.
Пусть для простоты есть 1 очередь. На «быстрой» стороне сэмулируем малую скорость передачи. Это значит, что попадая под нашу политику пакеты начнут накапливаться в очереди. Т.к. физический буфер большой, то и логическая очередь получится внушительной. Часть приложений (работающих через ТСР) поздно получат уведомление о том, что часть пакетов не получена и долго будут держать большой размер окна, нагружая сторону-приемник. Это будет происходить в том идеальном случае, когда скорость передачи будет равна или меньше скорости приёма. Но интерфейс принимающей стороны может быть сам загружен и другими пакетами
и тогда маленькая очередь на принимающей стороне не сможет вместить всех пакетов, передаваемых ей из центра. Начнутся потери, которые повлекут за собой дополнительные передачи, но в передающем буфере ведь ещё останется солидный «хвост» ранее накопленных пакетов, которые будут передаваться «вхолостую», т.к. на принимающей стороне не дождались более раннего пакета, а значит более позние будут просто проигнорированы.
Поэтому для корректного решения задачи понижения скорости передачи к медленному соседу физический буфер тоже надо ограничить.
Делается это командой
shape average [speed]
Ну а теперь самое интересное: а как быть, если мне помимо эмуляции физического буфера надо внутри него создать логические очереди? Например, выделить приоритетно голос?
Для это создаётся так называемая вложенная политика, которая применяется внутри основной и делит на логические очереди то, что в неё попадает из родительской.
Пришло время разобрать какой-нибудь залихватский пример на основе приведенной картинки.
Пусть мы собираеися создать устойчиво работающие голосовые каналы через интернет между CO и Remote. Для простоты пусть сеть Remote (172.16.1.0/24) имеет только связь с СО (10.0.0.0/8). Скорость интерфейса на Remote — 1 Мбит/сек и выделяется 25% этой скорости на голосовой трафик.
Тогда для начала нам надо выделить приоритетный класс трафика с обеих сторон и создать политику для данного класса. На СО дополнительно создадим класс, описывающий трафик между офисами
На СО:
class-map RTP
match protocol rtp
policy-map RTP
class RTP
priority percent 25
ip access-list extended CO_REMOTE
permit ip 10.0.0.0 0.255.255.255 172.16.1.0 0.0.0.255
class-map CO_REMOTE
match access-list CO_REMOTE
На Remote поступим иначе: пусть в силу дохлости железа мы не можем использовать NBAR, тогда нам остаётся только явно описать порты для RTP
ip access-list extended RTP
permit udp 172.16.1.0 0.0.0.255 range 16384 32768 10.0.0.0 0.255.255.255 range 16384 32768
class-map RTP
match access-list RTP
policy-map QoS
class RTP
priority percent 25
Далее, на СО надо сэмулировать медленный интерфейс, применить вложенную политику для приоритезации голосовых пакетов
policy-map QoS
class CO_REMOTE
shape average 1000000
service-policy RTP
и применить политику на интерфейсе
int g0/0
service-policy output QoS
На Remote установим параметр bandwidth (в кбит/сек) в соответствие со скоростью интерфейса. Напомню, что именно от этого параметра будет считаться 25%. И применим политику.
int s0/0
bandwidth 1000
service-policy output QoS
Повествование было бы не полным, если не охватить возможности коммутаторов. Понятно, что чисто L2 коммутаторы не способны так глубоко заглядывать в пакеты и делить их на классы по тем же критериям.
На более умных L2/3 коммутаторах на маршрутизируемых интерфейсах (т.е. либо на interface vlan, либо если порт выведен со второго уровня командой no switchport) применяется та же конструкция, что работает и на маршрутизаторах, а если порт или весь коммутатор работает в режиме L2 (верно для моделей 2950/60), то там для класса трафика можно использовать только указание police, а priority или bandwidth не доступны.
С сугубо защитной точки зрения, знание основ QoS позволит оперативно предотвращать бутылочные горла, вызванные работой червей. Как известно, червь сам по себе довольно агрессивен на фазе распространения и создаёт много паразитного трафика, т.е. по сути атаку отказа в обслуживании (Denial of Service, DoS).
Причем часто червь распространяется по нужным для работы портам (ТСР/135,445,80 и др.) Просто закрыть на маршрутизаторе эти порты было бы опрометчиво, поэтому гуманнее поступать так:
1. Собираем статистику по сетевому трафику. Либо по NetFlow, либо NBARом, либо по SNMP.
2. Выявляем профиль нормального трафика, т.е. по статистике, в среднем, протокол HTTP занимает не больше 70%, ICMP — не больше 5% и т.д. Такой профиль можно либо создать вручную, либо применив накопленную NBARом статистику. Мало того, можно даже автоматически создать классы, политику и применить на интерфейсе
командой autoqos :)
3. Далее, можно ограничить для нетипичного сетевого трафика полосу. Если вдруг и подцепим заразу по нестандартному порту, большой беды для шлюза не будет: на загруженном интерфейсе зараза займет не более выделенной части.
4. Создав конструкцию (class-map — policy-map — service-policy) можно оперативно реагировать на появление нетипичного всплеска трафика, создавая вручную для него класс и сильно ограничивая полосу для этого класса.
Сергей Фёдоров
Quality of Service (QoS) — технология предоставления различным классам трафика различных приоритетов в обслуживании.
Во-первых, легко понять, что любая приоритезация имеет смысл только в том случае, когда возникает очередь на обслуживание. Именно там, в очереди, можно «проскользнуть» первым, используя своё право.
Очередь же образуется там, где узко (обычно такие места называются «бутылочным горлышком», bottle-neck). Типичное «горлышко» — выход в Интернет офиса, где компьютеры, подключенные к сети как минимум на скорости 100 Мбит/сек, все используют канал к провайдеру, который редко превышает 100 МБит/сек, а часто составляет мизерные 1-2-10МБит/сек. На всех.
Во-вторых, QoS не панацея: если «горлышко» уж слишком узкое, то часто переполняется физический буфер интерфейса, куда помещаются все пакеты, собирающиеся выйти через этот интерфейс. И тогда новопришедшие пакеты будут уничтожены, даже если они сверхнужные. Поэтому, если очередь на интерфейсе в среднем превышает 20% от максимального своего размера (на маршрутизаторах cisco максимальный размер очереди составляет как правило 128-256 пакетов), есть повод крепко задуматься над дизайном своей сети, проложить дополнительные маршруты или расширить полосу до провайдера.
Разберемся с составными элементами технологии
(дальше под катом, много)
Маркировка. В полях заголовков различных сетевых протоколов (Ethernet, IP, ATM, MPLS и др.) присутствуют специальные поля, выделенные для маркирования трафика. Маркировать же трафик нужно для последующей более простой обработки в очередях.
Ethernet. Поле Class of Service (CoS) — 3 бита. Позволяет разделить трафик на 8 потоков с различной маркировкой
IP. Есть 2 стандарта: старый и новый. В старом было поле ToS (8 бит), из которого в свою очередь выделялись 3 бита под названием IP Precedence. Это поле копировалось в поле CoS Ethernet заголовка.
Позднее был определен новый стандарт. Поле ToS было переименовано в DiffServ, и дополнительно выделено 6 бит для поля Differencial Service Code Point (DSCP), в котором можно передавать требуемые для данного типа трафика параметры.
Маркировать данные лучше всего ближе к источнику этих данных. По этой причине большинство IP-телефонов самостоятельно добавляют в IP-заголовок голосовых пакетов поле DSCP = EF или CS5. Многие приложения также маркируют трафик самостоятельно в надежде, что их пакеты будут обработаны приоритетно. Например, этим «грешат» пиринговые сети.
Очереди.
Даже если мы не используем никаких технологий приоритезации, это не значит, что не возникает очередей. В узком месте очередь возникнет в любом случае и будет предоставлять стандартный механизм FIFO (First In First Out). Такая очередь, очевидно, позволит не уничтожать пакеты сразу, сохраняя их до отправки в буфере, но никаких преференций, скажем, голосовому трафику не предоставит.
Если хочется предоставить некоторому выделенному классу абсолютный приоритет (т.е. пакеты из этого класса всегда будут обрабатываться первыми), то такая технология называется Priority queuing. Все пакеты, находящиеся в физическом исходящем буфере интерфейса будут разделены на 2 логических очереди и пакеты из привилегированной очереди будут отсылаться, пока она не опустеет. Только после этого начнут передаваться пакеты из второй очереди. Эта технология простая, довольно грубая, её можно считать устаревшей, т.к. обработка неприоритетного трафика будет постоянно останавливаться. На маршрутизаторах cisco можно создать
4 очереди с разными приоритетами. В них соблюдается строгая иерархия: пакеты из менее привилегированных очередей не будут обслуживаться до тех пор, пока не опустеют все очереди с более высоким приоритетом.
Справедливая очередь (Fair Queuing). Технология, которая позволяет каждому классу трафика предоставить одинаковые права. Как правило не используется, т.к. мало даёт с точки зрения улучшения качества сервиса.
Взвешенная справедливая очередь (Weighted Fair Queuing, WFQ). Технология, которая предоставляет разным классам трафика разные права (можно сказать, что «вес» у разных очередей разный), но одновременно обслуживает все очереди. «На пальцах» это выглядит так: все пакеты делятся на логические очереди, используя в
качестве критерия поле IP Precedence. Это же поле задаёт и приоритет (чем больше, тем лучше). Дальше, маршрутизатор вычисляет, пакет из какой очереди «быстрее» передать и передаёт именно его.
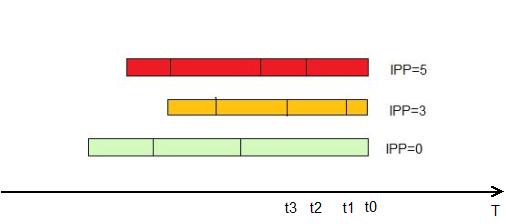
Считает он это по формуле:
dT=(t(i)-t(0))/(1+IPP)
IPP — значение поля IP Precedence
t(i) — Время, требуемое на реальную передачу пакета интерфейсом. Можно вычислить, как L/Speed, где L — длина пакета, а Speed — скорость передачи интерфейса
Такая очередь по умолчанию включена на всех интерфейсах маршрутизаторов cisco, кроме интерфейсов точка-точка (инкапсуляция HDLC или РРР).
WFQ имеет ряд минусов: такая очередизация использует уже отмаркированные ранее пакеты, и не позволяет самостоятельно определять классы трафика и выделяемую полосу. Мало того, как правило уже никто не маркирует полем IP Precedence, поэтому пакеты идут немаркированные, т.е. все попадают в одну очередь.
Развитием WFQ стала взвешенная справедливая очередь, основанная на классах (Class-Based Weighted Fair Queuing, CBWFQ). В этой очереди администратор сам задаёт классы трафика, следуя различным критериям, например, используя ACL, как шаблон или анализируя заголовки протоколов (см.NBAR). Далее, для этих классов
определяется «вес» и пакеты их очередей обслуживаются, соразмерно весу (больше вес — больше пакетов из этой очереди уйдёт в единицу времени)
Но такая очередь не обеспечивает строгого пропускания наиболее важных пакетов (как правило голосовых или пакетов других интерактивных приложений). Поэтому появился гибрид Priority и Class-Based Weighted Fair Queuing — PQ-CBWFQ, также известный как, Low Latency Queuing (LLQ). В этой технологии можно задать до 4х приоритетных очередей, остальные классы обслуживать по механизму CBWFQ
LLQ — наиболее удобный, гибкий и часто используемый механизм. Но он требует настройки классов, настройки политики и применения политики на интерфейсе.
Подробнее о настройках расскажу дальше.
Таким образом процесс предоставления качества обслуживания можно поделить на 2 этапа:
Маркировка. Поближе к источникам.
Обработка пакетов. Помещение их в физическую очередь на интерфейсе, подразделение на логические очереди и предоставление этим логическим очередям различных ресурсов.
Технология QoS — достаточно ресурсоёмкая и весьма существенно грузит процессор. И тем сильнее грузит, чем глубже в заголовки приходится залезать для классификации пакетов. Для сравнения: маршрутизатору гораздо проще заглянуть в заголовок IP пакета и проанализировать там 3 бита IPP, нежели раскручивать поток практически до уровня приложения, определяя, что за протокол идёт внутри (технология NBAR)
Для упрощения дальнейшей обработки трафика, а также для создания так называемой «области доверия» (trusted boundary), где мы верим всем заголовкам, относящимся к QoS, мы можем делать следующее:
1. На коммутаторах и маршрутизаторах уровня доступа (близко к клиентским машинам) ловить пакеты, раскидывать их по классам
2.В политике качестве действия перекрашивать заголовки по-своему или переносить значения QoS-заголовков более высокого уровня на нижние.
Например, на маршрутизаторе ловим все пакеты из гостевого WiFi домена (предполагаем, что там могут быть не управляемые нами компьютеры и софт, который может использовать нестандартные QoS-заголовки), меняем любые заголовки IP на дефолтные, сопоставляем заголовкам 3 уровня (DSCP) заголовки канального уровня (CoS),
чтобы дальше и коммутаторы могли эффективно приоритезировать трафик, используя только метку канального уровня.
Настройка LLQ
Настройка очередей заключается в настройке классов, затем для этих классов надо определить параметры полосы пропускания и применить всю созданную конструкцию на интерфейс.
Создание классов:
class-map NAME
match?
access-group Access group
any Any packets
class-map Class map
cos IEEE 802.1Q/ISL class of service/user priority values
destination-address Destination address
discard-class Discard behavior identifier
dscp Match DSCP in IP(v4) and IPv6 packets
flow Flow based QoS parameters
fr-de Match on Frame-relay DE bit
fr-dlci Match on fr-dlci
input-interface Select an input interface to match
ip IP specific values
mpls Multi Protocol Label Switching specific values
not Negate this match result
packet Layer 3 Packet length
precedence Match Precedence in IP(v4) and IPv6 packets
protocol Protocol
qos-group Qos-group
source-address Source address
vlan VLANs to match
Пакеты в классы можно рассортировывать по различным атрибутам, например, указывая ACL, как шаблон, либо по полю DSCP, либо выделяя конкретный протокол (включается технология NBAR)
Создание политики:
policy-map POLICY
class NAME1
?
bandwidth Bandwidth
compression Activate Compression
drop Drop all packets
log Log IPv4 and ARP packets
netflow-sampler NetFlow action
police Police
priority Strict Scheduling Priority for this Class
queue-limit Queue Max Threshold for Tail Drop
random-detect Enable Random Early Detection as drop policy
service-policy Configure Flow Next
set Set QoS values
shape Traffic Shaping
Для каждого класса в политике можно либо выделить приритетно кусок полосы:
policy-map POLICY
class NAME1
priority?
[8-2000000] Kilo Bits per second
percent % of total bandwidth
и тогда пакеты этого класса смогут всегда рассчитывать как минимум на этот кусок.
Либо описать, какой «вес» имеет данный класс в рамках CBWFQ
policy-map POLICY
class NAME1
bandwidth?
[8-2000000] Kilo Bits per second
percent % of total Bandwidth
remaining % of the remaining bandwidth
В обоих случаях можно указать как аболютное значение, так и процент от всей доступной полосы
Возникает резонный вопрос: а откуда маршрутизатор знает ВСЮ полосу? Ответ банален: из параметра bandwidth на интерфейсе. Даже если он не сконфигурирован явно, какое то его значение обязательно есть. Его можно посмотреть командой sh int.
Также обязательно помнить, что по умолчанию вы распоряжаетсь не всей полосой, а лишь 75%. Пакеты, явно не попавшие в другие классы, попадают в class-default. Эту настройку для дефолтного класса можно задать явно
policy-map POLICY
class class-default
bandwidth percent 10
(UPD, спасибо OlegD)
Изменить максимальную доступную полосу с дефолтных 75% можно командой на интерфейсеmax-reserved-bandwidth [percent]
Маршрутизаторы ревностно следят, чтобы админ не выдал случайно больше полосы, чем есть и ругаются на такие попытки.
Создаётся впечатление, что политика будет выдавать классам не больше, чем написано. Однако, такая ситуация будет лишь в том случае, если все очереди наполнены. Если же какая то пустует, то выделенную ей полосу наполненные очереди поделят пропорционально своему «весу».
Работать же вся эта конструкция будет так:
Если идут пакеты из класса с указанием priority, то маршрутизатор сосредотачивается на передаче этих пакетов. Причем, т.к. таких приоритетных очередей может быть несколько, то между ними полоса делится пропорционально указанным процентам.
Как только все приоритетные пакеты закончились, наступает очередь CBWFQ. За каждый отсчёт времени из каждой очереди «зачёрпывается» доля пакетов, указанная в настройке для данного класса. Если же часть очередей пустует, то их полоса делится пропорционально «весу» класса между загруженными очередями.
Применение на интерфейсе:
int s0/0
service-policy [input|output] POLICY
А что же делать, если надо строго рубить пакеты из класса, выходящие за дозволенную скорость? Ведь указание bandwidth лишь распределяет полосу между классами, когда очереди загружены.
Для решения этой задачи для класса трафика в политике есть технология
police [speed] [birst] conform-action [действие] exceed-action [действие]
она позволяет явно указать желаемую среднюю скорость (speed), максимальный «выброс», т.е. количество передаваемых данных за единицу времени. Чем больше «выброс», тем больше реальная скорость передачи может отклоняться от желаемой средней. Также указываются: действие для нормального трафика, не превышающего
указанную скорость и действие для трафика, превысившего среднюю скорость. Действия могут быть такими
police 100000 8000 conform-action?
drop drop packet
exceed-action action when rate is within conform and
conform + exceed burst
set-clp-transmit set atm clp and send it
set-discard-class-transmit set discard-class and send it
set-dscp-transmit set dscp and send it
set-frde-transmit set FR DE and send it
set-mpls-exp-imposition-transmit set exp at tag imposition and send it
set-mpls-exp-topmost-transmit set exp on topmost label and send it
set-prec-transmit rewrite packet precedence and send it
set-qos-transmit set qos-group and send it
transmit transmit packet
Часто возникает также и другая задача. Предположим, что надо ограничить поток, идущий в сторону соседа с медленным каналом.
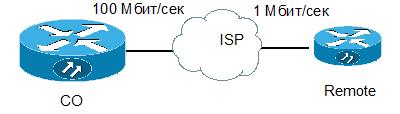
Дабы точно предсказать, какие пакеты дойдут до соседа, а какие будут уничтожены в силу загруженности канала на «медленной» стороне, надо на «быстрой» стороне создать политику, которая бы заранее обрабатывала очереди и уничтожала избыточные пакеты.
И тут мы сталкиваемся с одной очень важной вещью: для решения этой задачи надо сэмулировать «медленный» канал. Для этой эмуляции не достаточно только раскидать пакеты по очередям, надо ещё сэмулировать физический буфер «медленного» интерфейса. У каждого интерфейса есть скорость передачи пакетов. Т.е. в единицу времени каждый интерфейс может передать не более, чем N пакетов. Обычно физический буфер интерфейса рассчитывают так, чтобы обеспечить «автономную» работу интерфейсу на несколько единиц вермени. Поэтому физический буфер, скажем, GigabitEthernet будет в десятки раз больше какого-нибудь интерфейса Serial.
Что же плохого в том, чтобы запомнить много? Давайте рассмотрим подробно, что произойдёт, в случае если буфер на быстрой передающей стороне будет существенно больше буфера принимающей.
Пусть для простоты есть 1 очередь. На «быстрой» стороне сэмулируем малую скорость передачи. Это значит, что попадая под нашу политику пакеты начнут накапливаться в очереди. Т.к. физический буфер большой, то и логическая очередь получится внушительной. Часть приложений (работающих через ТСР) поздно получат уведомление о том, что часть пакетов не получена и долго будут держать большой размер окна, нагружая сторону-приемник. Это будет происходить в том идеальном случае, когда скорость передачи будет равна или меньше скорости приёма. Но интерфейс принимающей стороны может быть сам загружен и другими пакетами
и тогда маленькая очередь на принимающей стороне не сможет вместить всех пакетов, передаваемых ей из центра. Начнутся потери, которые повлекут за собой дополнительные передачи, но в передающем буфере ведь ещё останется солидный «хвост» ранее накопленных пакетов, которые будут передаваться «вхолостую», т.к. на принимающей стороне не дождались более раннего пакета, а значит более позние будут просто проигнорированы.
Поэтому для корректного решения задачи понижения скорости передачи к медленному соседу физический буфер тоже надо ограничить.
Делается это командой
shape average [speed]
Ну а теперь самое интересное: а как быть, если мне помимо эмуляции физического буфера надо внутри него создать логические очереди? Например, выделить приоритетно голос?
Для это создаётся так называемая вложенная политика, которая применяется внутри основной и делит на логические очереди то, что в неё попадает из родительской.
Пришло время разобрать какой-нибудь залихватский пример на основе приведенной картинки.
Пусть мы собираеися создать устойчиво работающие голосовые каналы через интернет между CO и Remote. Для простоты пусть сеть Remote (172.16.1.0/24) имеет только связь с СО (10.0.0.0/8). Скорость интерфейса на Remote — 1 Мбит/сек и выделяется 25% этой скорости на голосовой трафик.
Тогда для начала нам надо выделить приоритетный класс трафика с обеих сторон и создать политику для данного класса. На СО дополнительно создадим класс, описывающий трафик между офисами
На СО:
class-map RTP
match protocol rtp
policy-map RTP
class RTP
priority percent 25
ip access-list extended CO_REMOTE
permit ip 10.0.0.0 0.255.255.255 172.16.1.0 0.0.0.255
class-map CO_REMOTE
match access-list CO_REMOTE
На Remote поступим иначе: пусть в силу дохлости железа мы не можем использовать NBAR, тогда нам остаётся только явно описать порты для RTP
ip access-list extended RTP
permit udp 172.16.1.0 0.0.0.255 range 16384 32768 10.0.0.0 0.255.255.255 range 16384 32768
class-map RTP
match access-list RTP
policy-map QoS
class RTP
priority percent 25
Далее, на СО надо сэмулировать медленный интерфейс, применить вложенную политику для приоритезации голосовых пакетов
policy-map QoS
class CO_REMOTE
shape average 1000000
service-policy RTP
и применить политику на интерфейсе
int g0/0
service-policy output QoS
На Remote установим параметр bandwidth (в кбит/сек) в соответствие со скоростью интерфейса. Напомню, что именно от этого параметра будет считаться 25%. И применим политику.
int s0/0
bandwidth 1000
service-policy output QoS
Повествование было бы не полным, если не охватить возможности коммутаторов. Понятно, что чисто L2 коммутаторы не способны так глубоко заглядывать в пакеты и делить их на классы по тем же критериям.
На более умных L2/3 коммутаторах на маршрутизируемых интерфейсах (т.е. либо на interface vlan, либо если порт выведен со второго уровня командой no switchport) применяется та же конструкция, что работает и на маршрутизаторах, а если порт или весь коммутатор работает в режиме L2 (верно для моделей 2950/60), то там для класса трафика можно использовать только указание police, а priority или bandwidth не доступны.
С сугубо защитной точки зрения, знание основ QoS позволит оперативно предотвращать бутылочные горла, вызванные работой червей. Как известно, червь сам по себе довольно агрессивен на фазе распространения и создаёт много паразитного трафика, т.е. по сути атаку отказа в обслуживании (Denial of Service, DoS).
Причем часто червь распространяется по нужным для работы портам (ТСР/135,445,80 и др.) Просто закрыть на маршрутизаторе эти порты было бы опрометчиво, поэтому гуманнее поступать так:
1. Собираем статистику по сетевому трафику. Либо по NetFlow, либо NBARом, либо по SNMP.
2. Выявляем профиль нормального трафика, т.е. по статистике, в среднем, протокол HTTP занимает не больше 70%, ICMP — не больше 5% и т.д. Такой профиль можно либо создать вручную, либо применив накопленную NBARом статистику. Мало того, можно даже автоматически создать классы, политику и применить на интерфейсе
командой autoqos :)
3. Далее, можно ограничить для нетипичного сетевого трафика полосу. Если вдруг и подцепим заразу по нестандартному порту, большой беды для шлюза не будет: на загруженном интерфейсе зараза займет не более выделенной части.
4. Создав конструкцию (class-map — policy-map — service-policy) можно оперативно реагировать на появление нетипичного всплеска трафика, создавая вручную для него класс и сильно ограничивая полосу для этого класса.
Сергей Фёдоров
