Рассказываю, почему SQLite отлично подойдет вам в повседневной работе. И неважно, разработчик вы, аналитик, тестировщик, админ или продакт-менеджер.
Для затравки несколько известных фактов:
SQLite — самая распространенная СУБД в мире, включена во все популярные ОС.
Работает без сервера.
Для разработчиков — встраивается прямо в приложение.
Для всех остальных — удобная консоль (REPL) одним файлом (sqlite3.exe на Windows, sqlite3 в Linux / macOS).
Консоль, импорт и экспорт
Консоль — это киллер-фича SQLite: более мощный инструмент анализа данных, чем Excel, и сильно более простой, чем какой-нибудь pandas. Данные из CSV загружаются одной командой, таблица создается автоматически:
> .import --csv city.csv city
> select count(*) from city;
1117Поддерживаются базовые SQL-фичи, а результат консоль показывает в приятной табличке. Продвинутые SQL-фичи тоже есть, но о них чуть позже.
select
century || '-й век' as dates,
count(*) as city_count
from history
group by century
order by century desc;┌──────────┬────────────┐
│ dates │ city_count │
├──────────┼────────────┤
│ 21-й век │ 1 │
│ 20-й век │ 263 │
│ 19-й век │ 189 │
│ 18-й век │ 191 │
│ 17-й век │ 137 │
│ 16-й век │ 79 │
│ 15-й век │ 39 │
│ 14-й век │ 38 │
│ 13-й век │ 27 │
│ 12-й век │ 44 │
│ 11-й век │ 8 │
│ 10-й век │ 6 │
│ 9-й век │ 4 │
│ 5-й век │ 1 │
│ 3-й век │ 1 │
└──────────┴────────────┘Куча форматов выгрузки данных: sql, csv, json, даже markdown и html. Все делается парой команд:
.mode json
.output city.json
select city, foundation_year, timezone from city limit 10;
.shell cat city.json[{"city":"Адыгейск","foundation_year":1969,"timezone":"UTC+3"},
{"city":"Майкоп","foundation_year":1857,"timezone":"UTC+3"},
{"city":"Горно-Алтайск","foundation_year":1830,"timezone":"UTC+7"},
{"city":"Алейск","foundation_year":1913,"timezone":"UTC+7"},
{"city":"Барнаул","foundation_year":1730,"timezone":"UTC+7"},
{"city":"Белокуриха","foundation_year":1846,"timezone":"UTC+7"},
{"city":"Бийск","foundation_year":1709,"timezone":"UTC+7"},
{"city":"Горняк","foundation_year":1942,"timezone":"UTC+7"},
{"city":"Заринск","foundation_year":1748,"timezone":"UTC+7"},
{"city":"Змеиногорск","foundation_year":1736,"timezone":"UTC+7"}]Нативная работа с JSON
Нет ничего удобнее SQLite для анализа и преобразования JSON. Можно селектить данные напрямую из файла, как будто это обычная таблица. Или загрузить в таблицу и селектить оттуда — как вам удобнее.
select
json_extract(value, '$.code') as code,
json_extract(value, '$.name') as name,
json_extract(value, '$.rate') as rate,
json_extract(value, '$.default') as "default"
from
json_each(readfile('currency.sample.json'))
;┌──────┬───────────────────┬────────────┬─────────┐
│ code │ name │ rate │ default │
├──────┼───────────────────┼────────────┼─────────┤
│ AZN │ Манаты │ 0.023107 │ 0 │
│ BYR │ Белорусские рубли │ 0.034966 │ 0 │
│ EUR │ Евро │ 0.011138 │ 0 │
│ GEL │ Грузинский лари │ 0.0344 │ 0 │
│ KGS │ Киргизский сом │ 1.131738 │ 0 │
│ KZT │ Тенге │ 5.699857 │ 0 │
│ RUR │ Рубли │ 1.0 │ 1 │
│ UAH │ Гривны │ 0.380539 │ 0 │
│ USD │ Доллары │ 0.013601 │ 0 │
│ UZS │ Узбекский сум │ 142.441417 │ 0 │
└──────┴───────────────────┴────────────┴─────────┘Неважно, насколько развесистый JSON — можно выбрать атрибуты любой вложенности:
select
json_extract(value, '$.id') as id,
json_extract(value, '$.name') as name
from
json_tree(readfile('industry.sample.json'))
where
path like '$[%].industries'
;┌────────┬──────────────────────┐
│ id │ name │
├────────┼──────────────────────┤
│ 7.538 │ Интернет-провайдер │
│ 7.539 │ ИТ-консалтинг │
│ 7.540 │ Разработка ПО │
│ 9.399 │ Мобильная связь │
│ 9.400 │ Фиксированная связь │
│ 9.401 │ Оптоволоконная связь │
│ 43.641 │ Аудит │
│ 43.646 │ Страхование │
│ 43.647 │ Банк │
└────────┴──────────────────────┘CTE и операции над множествами
Разумеется, поддерживаются Common Table Expressions (конструкция WITH) и джойны, тут даже примеры приводить не буду. А если данные иерархичные (таблица ссылается сама на себя через столбец вроде parent_id) — поможет рекурсивный WITH. Иерархию любого уровня можно «размотать» одним запросом.
with recursive tmp(id, name, level) as (
select id, name, 1 as level
from area
where parent_id is null
union all
select
area.id,
tmp.name || ', ' || area.name as name,
tmp.level + 1 as level
from area
join tmp on area.parent_id = tmp.id
)
select * from tmp;┌──────┬─────────────────────────────────────┬───────┐
│ id │ name │ level │
├──────┼─────────────────────────────────────┼───────┤
│ 113 │ Россия │ 1 │
│ 1 │ Россия, Москва │ 2 │
│ 1586 │ Россия, Самарская область │ 2 │
│ 1588 │ Россия, Самарская область, Кинель │ 3 │
│ 78 │ Россия, Самарская область, Самара │ 3 │
│ 212 │ Россия, Самарская область, Тольятти │ 3 │
│ ... │ ... │ ... │
└──────┴─────────────────────────────────────┴───────┘Множества? Нет проблем: UNION, INTERSECT, EXCEPT к вашим услугам.
select employer_id
from employer_area
where area_id = 1
except
select employer_id
from employer_area
where area_id = 2;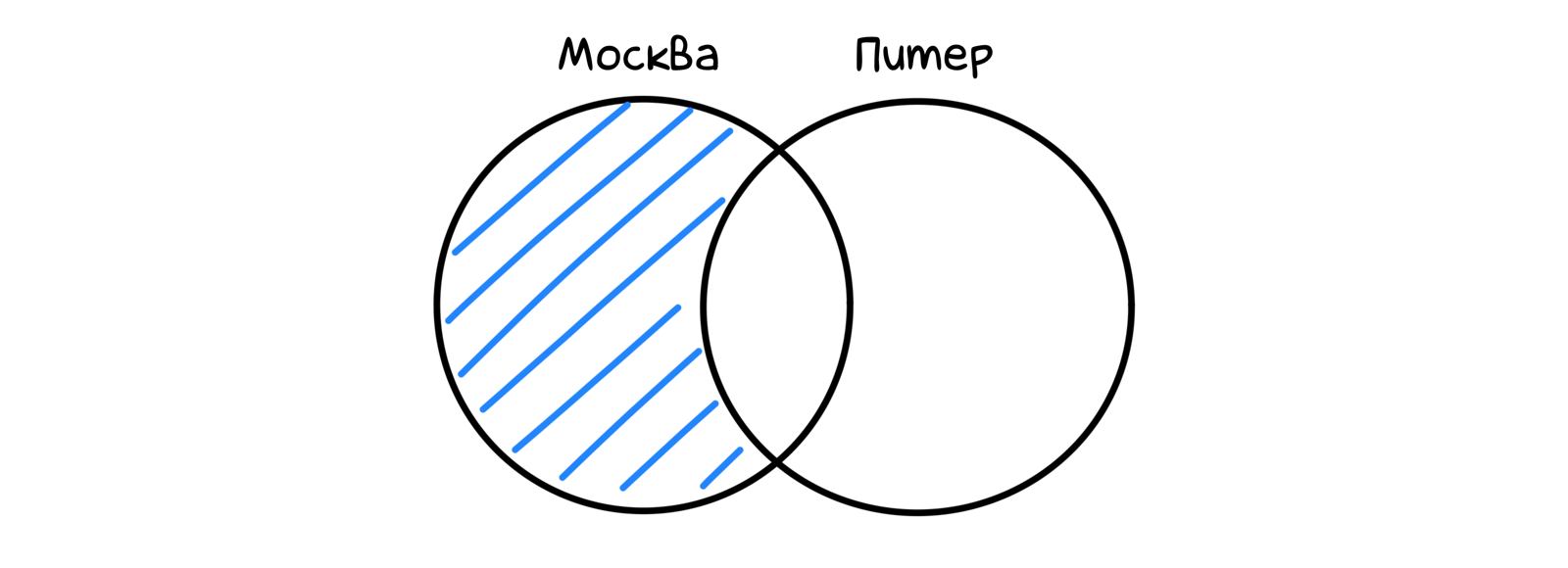
Хотите рассчитать один столбец на основании нескольких других? Пожалуйста — вычисляемые столбцы:
alter table vacancy
add column salary_net integer as (
case when salary_gross = true then
round(salary_from/1.13)
else
salary_from
end
);Вычисляемый столбец в селекте доступен точно так же, как обычный:
select
substr(name, 1, 40) as name,
salary_net
from vacancy
where
salary_currency = 'RUR'
and salary_net is not null
limit 10;┌──────────────────────────────────────────┬────────────┐
│ name │ salary_net │
├──────────────────────────────────────────┼────────────┤
│ Ведущий инженер-программист (Delphi) │ 40000 │
│ Ведущий программист Scala / Java ( Senio │ 60000 │
│ Java / Kotlin Developer │ 150000 │
│ Ведущий аналитик 1С │ 150000 │
│ Разработчик C# │ 53097 │
│ Программист 1С │ 80000 │
│ Java - разработчик (Middle, Senior) │ 100000 │
│ Программист C#/ .NET │ 70796 │
│ Тестировщик ПО/ QA engineer (ручное тест │ 45000 │
│ Курьер │ 17699 │
└──────────────────────────────────────────┴────────────┘Мат. статистика
Описательная статистика? Запросто: среднее, медиана, процентили, стандартное отклонение и вот это все. Правда, придется подключить библиотеку со стат. функциями, но это тоже одна команда (и один файл).
.load stats
select
count(*) as book_count,
cast(avg(num_pages) as integer) as mean,
cast(median(num_pages) as integer) as median,
mode(num_pages) as mode,
percentile_90(num_pages) as p90,
percentile_95(num_pages) as p95,
percentile_99(num_pages) as p99
from books;┌────────────┬──────┬────────┬──────┬─────┬─────┬──────┐
│ book_count │ mean │ median │ mode │ p90 │ p95 │ p99 │
├────────────┼──────┼────────┼──────┼─────┼─────┼──────┤
│ 1483 │ 349 │ 295 │ 256 │ 640 │ 817 │ 1199 │
└────────────┴──────┴────────┴──────┴─────┴─────┴──────┘Лирическое отступление. SQLite традиционно бедна функциями по сравнению с каким-нибудь постгресом. Но их легко добавить, чем многие и занимаются — каждый кто во что горазд. Получается легкий бардак.
Поэтому я решил сделать нормальный набор библиотек, с разделением по предметной области и автоматической сборкой для всех ОС:
А вот еще о статистике. Можно нарисовать распределение значений прямо в консоли. Смотрите, какая милота:
with slots as (
select
num_pages/100 as slot,
count(*) as book_count
from books
group by slot
),
max as (
select max(book_count) as value
from slots
)
select
slot,
book_count,
printf('%.' || (book_count * 30 / max.value) || 'c', '*') as bar
from slots, max
order by slot;┌──────┬────────────┬────────────────────────────────┐
│ slot │ book_count │ bar │
├──────┼────────────┼────────────────────────────────┤
│ 0 │ 116 │ ********* │
│ 1 │ 254 │ ******************** │
│ 2 │ 376 │ ****************************** │
│ 3 │ 285 │ ********************** │
│ 4 │ 184 │ ************** │
│ 5 │ 90 │ ******* │
│ 6 │ 54 │ **** │
│ 7 │ 41 │ *** │
│ 8 │ 31 │ ** │
│ 9 │ 15 │ * │
│ 10 │ 11 │ * │
│ 11 │ 12 │ * │
│ 12 │ 2 │ * │
│ 13 │ 5 │ * │
│ 14 │ 3 │ * │
│ 15 │ 1 │ * │
│ 17 │ 1 │ * │
│ 18 │ 2 │ * │
└──────┴────────────┴────────────────────────────────┘Быстродействие
SQLite спокойно работает с десятками миллионов записей (с сотнями тоже — я проверял). Обычные INSERT дают на моем ноуте около 240 тысяч записей в секунду. А если подключить исходный CSV как виртуальную таблицу (такая специальная фича) — еще в 2 раза быстрее.
.load vsv
create virtual table temp.blocks_csv using vsv(
filename="ipblocks.csv",
schema="create table x(network text, geoname_id integer, registered_country_geoname_id integer, represented_country_geoname_id integer, is_anonymous_proxy integer, is_satellite_provider integer, postal_code text, latitude real, longitude real, accuracy_radius integer)",
columns=10,
header=on,
nulls=on
);.timer on
insert into blocks
select * from blocks_csv;
Run Time: real 5.176 user 4.716420 sys 0.403866select count(*) from blocks;
3386629
Run Time: real 0.095 user 0.021972 sys 0.063716Среди разработчиков распространено мнение, что SQLite не подходит для веба, потому что поддерживает только одного клиента. Это миф. В режиме write-ahead log (стандартная фича современных СУБД) читателей может быть сколько угодно. Писатель — один, но часто больше и не надо.
SQLite отлично подходит для небольших сайтов и приложений. Например, sqlite.org использует SQLite в качестве базы, не заморачиваясь с оптимизацией (~200 запросов на страницу). При этом у него 700К визитов в месяц, а работает быстрее 95% сайтов.
Документы, графы и поиск
Поддерживаются частичные индексы и индексы по выражениям, как в «больших» СУБД. Можно даже строить индексы на виртуальных столбцах.
Так SQLite можно превратить хоть в документную БД: хранить сырой json и строить индексы по json_extract() на нужных столбцах:
create table currency(
body text,
code text as (json_extract(body, '$.code')),
name text as (json_extract(body, '$.name'))
);
create index currency_code_idx on currency(code);
insert into currency
select value
from json_each(readfile('currency.sample.json'));explain query plan
select name from currency where code = 'RUR';
QUERY PLAN
`--SEARCH TABLE currency USING INDEX currency_code_idx (code=?)Можно и как графовую базу использовать. Тут уже придется либо злые
WITH RECURSIVEиспользовать, либо добавить щепотку программирования:
Полнотекстовый поиск работает из коробки:
create virtual table books_fts
using fts5(title, author, publisher);
insert into books_fts
select title, author, publisher from books;
select
author,
substr(title, 1, 30) as title,
substr(publisher, 1, 10) as publisher
from books_fts
where books_fts match 'ann'
limit 5;┌─────────────────────┬────────────────────────────────┬────────────┐
│ author │ title │ publisher │
├─────────────────────┼────────────────────────────────┼────────────┤
│ Ruby Ann Boxcar │ Ruby Ann's Down Home Trailer P │ Citadel │
│ Ruby Ann Boxcar │ Ruby Ann's Down Home Trailer P │ Citadel │
│ Lynne Ann DeSpelder │ The Last Dance: Encountering D │ McGraw-Hil │
│ Daniel Defoe │ Robinson Crusoe │ Ann Arbor │
│ Ann Thwaite │ Waiting for the Party: The Lif │ David R. G │
└─────────────────────┴────────────────────────────────┴────────────┘А хотите in-memory базу для промежуточных вычислений? Одна строчка кода на питоне:
db = sqlite3.connect(":memory:")Можно даже обращаться к ней из нескольких соединений:
db = sqlite3.connect("file::memory:?cache=shared")И еще много всего
Есть навороченные оконные функции (в точности как в PostgreSQL). UPSERT, UPDATE FROM и generate_series(). R-Tree индексы. Регекспы, fuzzy-поиск и гео. По фичам SQLite посоперничает с любой «взрослой» СУБД.
Надеюсь, эта статья вдохновит вас применить SQLite в своих задачах. Спасибо, что прочитали!
Если интересно, как использовать SQLite на полную — подписывайтесь на канал @sqliter
