
В 80 годы прошлого века правительство Японии совершило попытку создать распределенную вычислительную систему следующего поколения с элементами ИИ. Проект закончился достаточно закономерным провалом. Причина провала достаточно проста, почему то посчитали, что простого наличия технологии производства больших интегральных схем хватит для качественного "скачка" в вычислительных технологиях (своеобразный переход количества в качество). Да, история повторилась, после изобретения компьютера, тоже присутствовала необоснованная уверенность в скором появлении ИИ и тоже провалилась.
Сейчас ИИ в основном рассматривается как совокупность нейронов, объединенных в сеть. В свою очередь я попытался посмотреть на человеческий мозг, как на вычислительную систему. При этом не акцентируя внимание на элементах какого типа он базируется.
<meta http-equiv="CONTENT-TYPE" content="text/html; charset=utf-8">
<title></title>
<meta name="GENERATOR" content="OpenOffice 4.1.6 (Win32)">
<style type="text/css">
<!--
@page { size: 21cm 29.7cm; margin: 2cm }
P { margin-bottom: 0.21cm }
-->
</style>
Современное состояние вычислительной техники
Современное состояние вычислительной техники можно охарактеризовать как стагнацию, основные идеи были сформулированы в 1940-1970 годы прошлого века и до настоящего времени не претерпели значимых изменений. Основной прогресс получался за счет совершенствования микроэлектронной технологии, до тех пор пока в начале двухтысячных весь процессор не был окончательно реализован в пределах одного кремниевого кристалла. С этого момента рост производительности резко замедлился и начали проявляться проблемы заложенные в вычислительную парадигму фон-неймана, как в части аппаратуры, так и в части создания программного обеспечения. Основными проблемами парадигмы фон-неймана является принципиальная последовательность исполнения команд и отсутствие (в пределах вычислительной парадигмы) второй и более вычислительной машины, а так же средств взаимодействия с ней. Еще можно отметить несоответствие современных задач, задачам под которые создавалась вычислительная машина фон-неймана. Современный компьютер создавался как средство для автоматизации расчетных работ, в настоящее время в основном используется как средство «оживления» различных моделей, физически существующих или полностью виртуальных (непосредственно расчетное использование минимально). Создание программного обеспечения базируется на математических принципах, что чрезвычайно неэффективно за пределами чисто математических задач.
В целом можно сказать, что для достижения значимого прогресса необходим революционный слом существующей парадигмы и всех навязанных искусственных ограничений (адресное пространство, последовательность исполнения команд, разрядность данных и многое другое).
Внимание:
Все идеи и алгоритмы, описываемые в данной статье, являются результатом моей независимой и полностью самостоятельной интеллектуальной деятельности. Как автор, разрешаю свободно использовать, изменять, дополнять все идеи и алгоритмы любому человеку или организации в любых типах проектов при обязательном указании моего авторства (Балыбердин Андрей Леонидович Rutel@Mail.ru).
В самом начале необходимо определить основной тип задач, на решение которых будет нацелена новая вычислительная парадигма. Архитектура фон-неймана решает задачи вычисления математических выражений, а все остальное идет «бесплатным» дополнением. В настоящее время акцент сместился в сторону моделирования поведения различных объектов или их «сообществ», именно эту задачу необходимо рассматривать как основную. Еще учитываю «своекорыстный» интерес, использование будущей вычислительной системы для моделирования человеческого мозга и как инструмент для моделирования (проектирования) биологических структур (нейро-интерфейс) внедряемых в мозг человека (проект переноса личности человека в вычислительную систему).
Примерное описание идеи в статье : Цифровое бессмертие — Инженерный подход.
Определим основные «термины»
Объект
Определение понятия объекта (правильнее сказать виртуальный объект), поведение которого и будет моделировать новая вычислительная система.
Виртуальный объект это отражение свойств и законов, которым подчиняется некоторый внешний по отношению к вычислительной системе объект, в данные хранимые и обрабатываемые вычислительной системой. Иными словами виртуальный объект это «связанный» набор данных (можно даже применить термин запутанность из квантовой физики), который изменяет свое состояние при взаимодействии с другими виртуальными объектами сообразно с законами функционирования и не может принимать значения противоречащие данным законам даже на короткий промежуток времени. Из это следует, что все данные характеризующие текущее состояние объекта, при взаимодействии с другими объектами изменяют свое состояние за бесконечно малый промежуток времени (мгновенно). Законы функционирования определяют набор действий, которые должна выполнить вычислительная система для «вычисления» нового состояния (аналог программы из парадигмы фон-неймана). Программирование в новой парадигме сводится к постулированию законов поведения объекта, базовых констант, и границ их применения (создание иерархического описания свойств объекта), на основании которых «компилятор» создает все остальные компоненты необходимые в конкретной вычислительной системе для моделирования. Профессия программист в данной парадигме отсутствует по причине практической невозможности в ручного переписывания исполняемой последовательности команд после каждого изменения законов поведения объекта (описание свойств должно производиться практически на естественном языке). Для формулирования свойств объекта необходимы знания специалиста, в интересах которого создается ПО (технология создания ПО будет рассматриваться в следующей статье).
Данные
Данные это иерархическая информационная конструкция, состоящая из совокупности символов. Данная структура, описывает «физические» параметры объекта в настоящем времени и изменяется согласно законам функционирования при взаимодействии с другими объектами.
Символ
Символ представляет собой неделимую информационную конструкцию обладающую свойствами тип и значение, информационная емкость (разрядность, да и вообще дискретность) не оговаривается. Именно через тип символа и происходит связывание виртуального объекта с физическим миром (отражением в физическом мире). В физике есть «Международная система единиц измерения», в том числе и через ее отображение в пространство символов происходит отображение «физической» реальности в виртуальную. Можно сказать, что каждый тип символа это отдельное «измерение» и каждый виртуальный объект может быть описан через координаты в пространстве «измерений».
Взаимодействие объектов
Взаимодействие объектов происходит через «перенос» части состояния одного объекта (части данных), в состояние взаимодействующего с ним другого объекта. Перенос данных взаимодействия происходит не мгновенно (дань конечности времени взаимодействия), время взаимодействия неизвестно и не постоянно во времени. Гарантируется только то, что порядок переноса данных взаимодействия будет совпадать с порядком их появления. Данные взаимодействия переносятся во взаимодействующий объект целиком и без искажений.
Время
Моделируемые объекты изменяют свое состояние во времени. Время в физическом мире не имеет носителя и является просто отношением скорости течения различных процессов. Единственно, что можно сказать о времени определенно, оно направлено из прошлого, через настоящее, в будущее и нереверсивно. Текущее состояние данных объекта это и есть его настоящее. Время, для вычислительной системы, логичнее определить через количество взаимодействий между объектами. Нет взаимодействий, нет времени. Если произошло взаимодействие (приняты данные взаимодействия), то оно мгновенно изменяет объект (его состояние). Если требуется привязать объект к реальному (модельному или физическому времени), то достаточно путем взаимодействия с объектом «таймер» добавить в его данные (состояние) значение времени.
Вычисление
Новая вычислительная парадигма в значительной степени (с вычислительной точки зрения) базируется на идеях DataFlow (вычисления возможны только после готовности всех исходных данных). В момент когда происходит взаимодействие (получены данные взаимодействия от другого объекта), выполняются все возможные «преобразования» для данного объекта, для которых присутствуют необходимые данные. В отличии от канонического DataFlow, где проверяется только готовность исходных данных, необходимо проверить еще наличие возможности «записать» результат преобразования. Такие проверки позволяют осуществлять координацию работы нескольких объектов, притормаживая объекты имеющие возможность создать много данных сразу (не считаясь с возможностью другого объекта их обработать). В результате получается сбалансированная система, где невозможно начать вычисления раньше готовности данных и производить вычисление слишком быстро по причине отсутствия места для сохранения данных. Можно добавить, что существенным отличием от вычислительной парадигмы фон-неймана, является возможность получить больше одного легитимного результата. Поскольку исходными данными для создания ПО являются «законы», а не отдельные команды (фон-нейман). Применение «законов» отделяет множество «легитимных» решений из множества возможных, их может быть больше одного, а может и не быть вообще. В парадигме фон-неймана происходит простое вычисление математического выражения, с одним результатом в итоге.
Физическая реализация «вычислителя» может любой (программа для обычного фон-неймановского процессора, FPGA, обычная логика, нейронные технологии и тд). Каналы переноса данных взаимодействия, по своим свойствам являются обычными каналами связи (точка-точка) с произвольно распределенным по их протяженности FIFO (канал имеет некую информационную емкость). Регулируя скорость передачи символов в отдельных каналах, можно регулировать скорость работы различного ПО, иначе говоря это более эффективный аналог системы приоритетов из парадигмы фон-неймана.
Итог
Отдельные объекты могут располагаться (исполняться) на различных кристаллах, которые соединяются каналами связи (для переноса данных взаимодействия). Нет границ между различными компонентами суммарной вычислительной системы. Состояние объекта в будущем зависит только от данных взаимодействия, плюс данные текущего состояния объекта, значит может быть вычислено полностью параллельно. Кроме того можно представить вычисление виде направленного ациклического графа, что позволит организовать вычислительный процесс по готовности данных с одновременным использованием большого числа вычислительных «ядер». Такой подход дополнительно распараллеливает вычислительный процесс. Получается максимально параллельная и распределенная вычислительная система.
Программирование в новой парадигме превращается из составления списка исполняемых команд (фон-нейман) в описании иерархии законов (свойств), которым должен подчиняться виртуальный объект (или их совокупность). Такой подход открывает очень большие перспективы, например избавляет от неэффективного «посредника» (программиста) при взаимодействии с вычислительной системой. Разрушает барьер максимальной сложности создаваемой программы. Человек может одновременно оперировать не более чем 5-7 информационными сущностями, что приводит к ошибкам логической связности больших объектов. Программирование в новой парадигме становится «инкрементальным», можно постепенно добавлять (редактировать) законы (свойства), до тех пор пока весь объект не станет соответствовать потребностям пользователя. В парадигме фон-неймана такой подход невозможен из-за того что программирование представляет собой создание (редактирование) последовательности действий, которая может полностью измениться при внесении даже небольших изменений в законы функционирования математической модели объекта. Замечу, что нигде не говорится о необходимости изначально понимать «устройство» создаваемого объекта, можно просто формировать список требований (законов). Произойдет постепенное формирование множества объектов подходящих для решения поставленной задачи. Объекты будут немного отличаться друг от друга, но только в части не значимой для решаемой задачи. Если «замкнуть» обратную связь с объектом существующим в физической реальности, то можно создать «автоматическую» исследовательскую систему, которая будет без участия оператора строить виртуальные модели физических объектов. Самое главное, такой подход позволит решить проблему написания адаптивно изменяющегося ПО, предназначенного для работы в не контролируемой среде (в изменяющемся реальном мире).
Можно будет строить отображение реального мира в виртуальный, как это делает мозг человека и на его основе предсказывать результат тех или иных действий (такое предсказание и является интеллектом). Для парадигмы фон-неймана написание корректно работающего ПО возможно только при полном знании среды в которой будет работать ПО и любое «непредвиденное» обстоятельство может нарушить логику работы.
Создание «программы» по заданным законам функционирования, можно делать многими способами. Самый простой пример : Использовать технологию обучения нейронных сетей, заменив библиотеку примеров на проверку соответствия получаемого объекта заданным законам (свойствам). Более полно технология «программирования» будет рассматриваться в следующей статье.
Физическая реализация вычислительной системы
Повторюсь, до начала 2000х наблюдался экспоненциальный рост производительности процессоров (закон Мура) и определялся он в основном успехами микроэлектронного производства. В момент когда удалось полностью разместить на одном кристалле процессор и все необходимое для его работы (кэш память и другое), наступил перелом. Рост производительности прекратился и повлияли на это множество факторов, частично из-за «электрических» ограничений, таких как невозможность рассеивать все потребляемую мощность (появилось понятие «темный кремний»), ограничение по частоте (размер кристалла, частотные свойства транзистора и суммарное потребление). Но самый главный «тормоз» в повышении производительности это невозможность эффективного распараллеливания, заложенный в самой вычислительной парадигме. Невозможно получить рост производительности путем простого увеличения числа ядер на одном кристалле.
Сетевая парадигма
Следующим сдерживающим фактором является отсутствие эффективной сетевой парадигмы, что не позволяет распределить вычислительный процесс в пространстве (объеме) и заставляет стягивать все компоненты вычислительной системы в пределы одного кристалла.

<meta http-equiv="CONTENT-TYPE" content="text/html; charset=utf-8">
<title></title>
<meta name="GENERATOR" content="OpenOffice 4.1.6 (Win32)">
<style type="text/css">
<!--
@page { size: 21cm 29.7cm; margin: 2cm }
P { margin-bottom: 0.21cm }
-->
</style>
В новой вычислительной системе за счет революционного увеличения эффективности сетевой подсистемы данная проблема должна быть решена. Необходимо получить скорости до 10Е14 бит в секунду для каждого отдельного кристалла, при стабильных задержках задержках передачи, на 90% определяемых скоростью распространения электромагнитной волны в среде передачи. (Подробное описание устройства коммуникационной парадигмы в статье: «Синхронный интернет: Синхронная символьная иерархия»). Получить такую производительность при использовании медных линий связи практически невозможно, соответственно необходимо полностью изменить подход к проектированию меж-соединений. В настоящее время все компоненты устанавливаются на печатную плату и соединяются медными проводниками. В качестве альтернативы такому подходу, предлагаю в текстолите прокладывать оптические волокна и выводить их с торцов ПП или вырезов в ней для устанавливаемых микросхем. Если сейчас микросхемы распаиваются, то в новом подходе кристаллы могут устанавливаться в прорези в печатной плате. Оптические интерфейсы микросхем должны располагаться с торцов и сопрягаться с оптическими интерфейсами ПП, различные ПП соединять разъемами устанавливаемыми на внешние края плат. Такой подход позволит максимально плотно (значит с минимальными задержками) и надежно строить систему оптических соединений.
Теплоотвод
Следующим ограничивающим фактором является энергопотребление и эффективность отвода тепла. Повышение энерго-эффективности будет рассмотрено в главе посвященной проектированию процессорного ядра. Сейчас можно отметить удвоение эффективности теплоотвода за счет возможности установить радиатор с двух сторон кристалла, в настоящее время только одна сторона микросхемы используется для отвода тепла, а вторая предназначена для размещения электрического интерфейса. Если линии связи выводятся с торцов микросхемы, то можно превратить поверхности микросхемы в единые контакты для подвода питания (одна сторона плюс питания, другая минус) и к каждой из них присоединить радиатор для отвода тепла. Радиатор может быть единым для всех микросхем установленных на ПП (подобные сборки использовались на мейнфреймах) и использовать жидкостное охлаждение, что для больших систем оно гораздо проще и эффективнее чем воздушное.
Структура вычислительной системы
В парадигме фон-неймана все ориентировано на понятие «адрес», как для доступа к памяти, доступа различным устройствам, так и для взаимодействия с другими вычислительными системами, хотя такое взаимодействие и не предусмотрено в базовой парадигме (думаю поэтому оно такое «кривое»).
В новой парадигме базового понятия адреса нет, коммуникационной основой вычислительной парадигмы является возможность создания одно-направленного последовательного канала (точка-точка) между любыми двумя объектами. На следующих уровнях иерархии работа такого канала может быть заблокирована, примерно как блокируется доступ к определенным частям адресного пространства в парадигме фон-неймана.
Структурно, новая вычислительная парадигма представляет собой большое число физически реализованных объектов (память, различные аппаратные ускорители, процессорные ядра и др), соединяемых между собой большим числом каналов передачи данных. Физически реализованные объекты в той или иной степени могут быть «запрограммированы», те могут сохранять конфигурационные данные, которые изменяют их поведение. С точки зрения программирования, каждый физический объект это реализованные в кремнии (не изменяемые) законы функционирования. При «программировании» вычислительной системы, есть возможность добавлять к этим законам свои локальные законы, по существу делать из более универсального объекта специализированный (решающие локальную задачу). Никаких ограничений по числу каналов и топологии системы связи нет, да и номера канала тоже нет. В обеих парадигмах нет указаний на наличие еще одной вычислительной системы, но в отличии от фон-неймана, новая парадигма допускает, что часть системы еще не создана или с ней нет соединения (которое может появиться или исчезнуть в любой момент).
При описании коммуникационной парадигмы, использован относительный способ адресации, на входе коммутатора для продолжения построения маршрута от адресных данных забирается некоторое число бит (сколько забрать и как интерпретировать, «личное» дело коммутатора). Получается что физический объект состоит из двух частей: «коммутатора» и «вычислителя». Все что является адресом будет воспринято коммутатором, а то что является данными взаимодействия будет обработано вычислителем. Принципиальной разницы в парадигме функционирования между «Вычислителем» и «Коммутатором» нет, это просто различно специализированные объекты (формально одинаково обрабатывают данные взаимодействия).
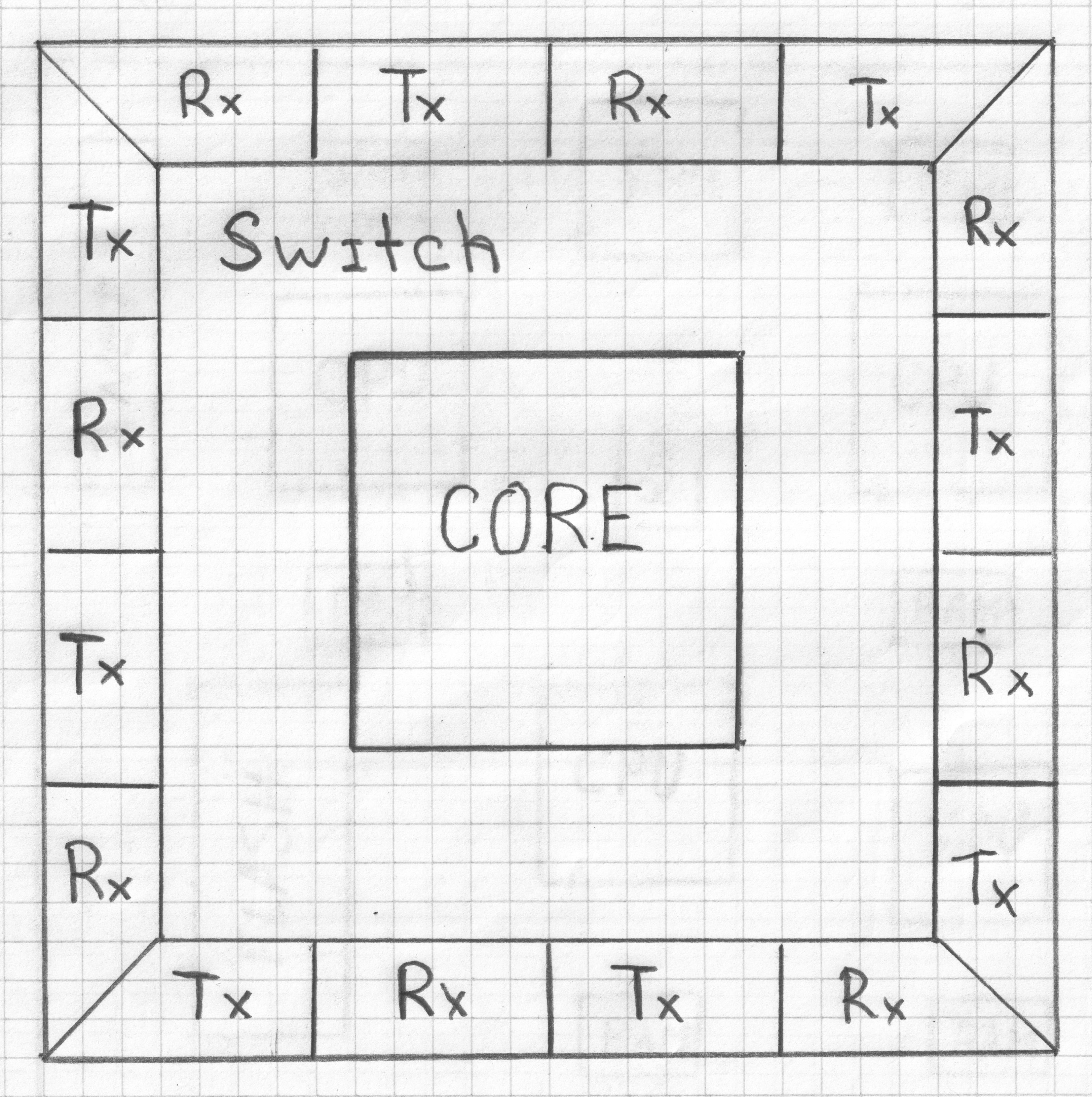
<meta http-equiv="CONTENT-TYPE" content="text/html; charset=utf-8">
<title></title>
<meta name="GENERATOR" content="OpenOffice 4.1.6 (Win32)">
<style type="text/css">
<!--
@page { size: 21cm 29.7cm; margin: 2cm }
P { margin-bottom: 0.21cm }
-->
</style>
Вопросы безопасности
Считаю, что любой код (пароль, шифр) рано или поздно может быть взломан и единственный способ помешать этому — не дать возможности создать канал доступа, через который это получится сделать. Способом полностью «взломать» новую систему должно быть, только физическое проникновение в место расположения вычислительной системы и применение методов «крипто-анализа» к администратору. Если такой администратор «параноик» и перед физическим проникновением уничтожил ключ, то сохранность данных будет определяться, только параметрами защиты отдельных компонентов, составляющей вычислительную систему.
В новой парадигме любой объект может получить непосредственный доступ (связаться), только с соседним объектом (соседним физической сети связи). Дальнейший путь проходит через коммутаторы встроенные в транзитные объекты, которые тоже являются управляемыми (программируемыми) объектами, со своими проверками и ограничениями доступа (задаваемыми администратором). Изменить программу управляющую коммутатором можно только получив доступ к системе программирования, понятно что доступ к ней с «внешних» портов будет невозможен. Коммутатор может применять правила доступа, не позволяющие строить прямые соединения к объектам находящимся внутри защищаемых зон. Пример - для определенных каналов можно создать соединения только с определенными объектами (присутствующими в списке) или запрет создания прямых соединений между определенными физическими портами.
Возникает вопрос: а если «злоумышленник» маскируется под легитимного абонента из внешней среды? Канал в новой коммуникационной парадигме является однонаправленным и для обеспечения обратной связи должен содержать маршрут по которому ответ будет доставлен назад «злоумышленнику». Обратный маршрут должен быть «действующим», иначе данные не будут доставлены. Анализируя этот адрес, коммутатор (или непосредственно объект) может идентифицировать вызывающего абонента, проверить маршрут по которому будут переданы данные ответа и выяснить не выходит ли этот маршрут за пределы «доверенной» зоны. Соответственно, подменить адрес или прослушать содержимое трафика можно только путем физического присоединения к коммуникационной аппаратуре, находящейся в «доверенной» зоне и уровень «доверия» к такому сеансу связи будет равен минимальному уровню «доверия» к промежуточному участку маршрута (про шифрование трафика пока не говорю). Присоединение к вычислителю на территории пользователя вызовет изменение топологии сетевых соединений, что сразу будет зафиксировано составляющими ее коммутаторами и присоединяемое устройство будет изолировано. Применение объекта с «закладками», потребует создание соединения с объектом за пределами зоны в которой находится «закладка», максимум что может случиться это хищение данных полученных этим объектом в процессе работы вычислительной системы с дальнейшей передачей собственным каналом связи (внешним по отношению к системе). Для «хищения» данных, потребуется внедрить закладки или выявить уязвимости, в целой цепочке объектов (от источника данных, до завершения доверенной зоны) Для особо важных частей вычислительной системы, может быть определена полная невозможность соединений не входящих в заранее указанный список и многократное дублирование. Кроме того можно в момент компиляции ПО можно добавить «законы» маркирующие данные индикатором степени секретности и тогда в коммутаторе можно проверять весь трафик на соответствие степени доверия конкретного канала, степени «секретности» передаваемой информации (это уже для совсем параноиков).
Границы вычислительной системы
Следующий вопрос: Если вычислительная система распределенная и в ней нет явных границ, то где конкретный пользователь имеет право монопольно распоряжаться «аппаратурой»(где граница частных владений)? Наиболее оптимальным будет создание физически существующего объекта «ключ», который подключается к специальным «административным» каналам, только с использованием этих каналов, можно «инициализировать» управляющее ПО коммутаторов. Все что удастся «инициализировать» с использованием такого ключа и есть границы личного пространства (собственная вычислительная система), все остальное это пространство с делегированными полномочиями (разрешением ограниченного использования, выданного владельцем другой вычислительной системы). Такая «инициализация» может быть коллективной, различные пользователи получают различные типы (правила) доступа. Различать пользователя опять же по ключу, при этом если «вынуть» ключ, то настройки сохраняются и запущенное ПО продолжает работать.
Ограничивать доступ можно не только по пользователю, но и по степени «доверенности» исполняемого ПО.
Энерго-эффективность
Тут все просто, если нет взаимодействий, то нет передаваемых данных, нет работы вычислительных блоков, нет изменения потенциалов на транзисторах и нет потребления энергии (ну почти нет). Кроме того легко определить «простаивающие» блоки и мгновенно отключить их от электропитания (верно и обратное).
«Вычислитель»
Все объекты (как физические так и виртуальные) в вычислительной системы контактируют друг с другом посредством каналов связи. Поскольку время вычисления нового состояния объекта равно нулю (при ненулевом времени передачи данных взаимодействия), то можно считать что все взаимодействия происходят последовательно. Запуск вычисления происходит в момент прихода данных взаимодействия. Данные взаимодействия являются копией частей данных состояния взаимодействующих объектов и не могут быть разделены или доставлены частично (иначе нарушится «запутанность» состояния объекта). Гарантированной доставкой данных занимается коммуникационная часть вычислительной системы. Если время доставки данных взаимодействия устанавливается равным нулю, то это означает превращение двух взаимодействующих объектов в один.
Далее будет описываться построение вычислителя, с принципами функционирования родственными DataFlow системам, но вычисления объекта возможны и другими вариантами (процессор на принципах фон-неймана, ПЛИС, нейронные сети и др.).
Программа для такого вычислителя представляет собой ациклический направленный граф. Ребра графа, это каналы передачи данных Узлами (вершинами) графа являются операции, которые могут выполнить АЛУ вычислительного «ядра».
Данные в новой вычислительной парадигме представлены в виде символов, неделимой конструкции: тип-значение. Для конкретных аппаратных блоков, будет излишним полное «понимание» всей системы типов и правил построения символьных конструкций. Например, для коммуникационной системы все что нужно «знать» это три группы символов (пользовательские символы, служебные символы коммутатора и символ отсутствия данных). Для каждой конкретной системы можно использовать только специфические ей типы символов (пока данные обрабатываются данной системой), а все остальные инкапсулировать в пределах поля «значение». После обработки (в момент пересечения границы системы) произвести обратную операцию извлечения (и сразу преобразования в другой тип символов — используемых другой системой). Поскольку в пределах конкретной системы используется только определенный тип символа (ну или несколько), то можно не хранить тип символа (экономия ресурсов). Аналогом такого преобразования в коммуникационной парадигме служит преобразование размера «символа» (кванта) передаваемых данных для различных физических каналов передачи данных. В современных процессорах в памяти хранятся байты, но при загрузке в математических сопроцессор могут преобразовываться в неделимую конструкцию «число с плавающей запятой».
Вычислитель оперирует (обрабатывает) символы типа «данные процессора ХХХ», как их интерпретировать «личное дело» этого вычислителя (никак не влияет на результат).
Пример структуры данных :
[EXE][READY][KEY][DATA]
EXE – данные принадлежат к активному (вычисляемому) пути графа
READY – данные вычислены и готовы к дальнейшему использованию (0 — нет данных)
KEY – уникальный ключ для поиска данных в ассоциативном ЗУ
DATA – данные для обработки
Вершина графа «вычисляется», только если все входящие ребра имеют значение отличное от «нет данных». Если вершины такого графа «рассортировать» по слоям, таким образом что бы все входящие ребра принадлежали вершинам предыдущих слоев (были вычислены) или были данными состояния объекта. Результатом будет некоторое число групп вершин (слоев), вычислять значения вершин внутри такой группы можно в любом порядке. Но и тут можно немного оптимизировать вычислительный процесс, большинство преобразований (так эффективней для реального АЛУ) имеет один либо два операнда и выдает один результат, все остальные приводят нескольким таким преобразованиям. Максимальная эффективность вычислительного процесса получается когда результат предыдущего преобразования используется как один из операндов в следующем, приходится читать только один операнд и результат не всегда сохранять (он «расходуется» в следующем преобразовании). Если сделать вторую, уже вертикальную сортировку по этому критерию, то получим набор коротких последовательностей преобразований («нитей»). Такие нити могут начинаться и заканчиваться на любом слое.
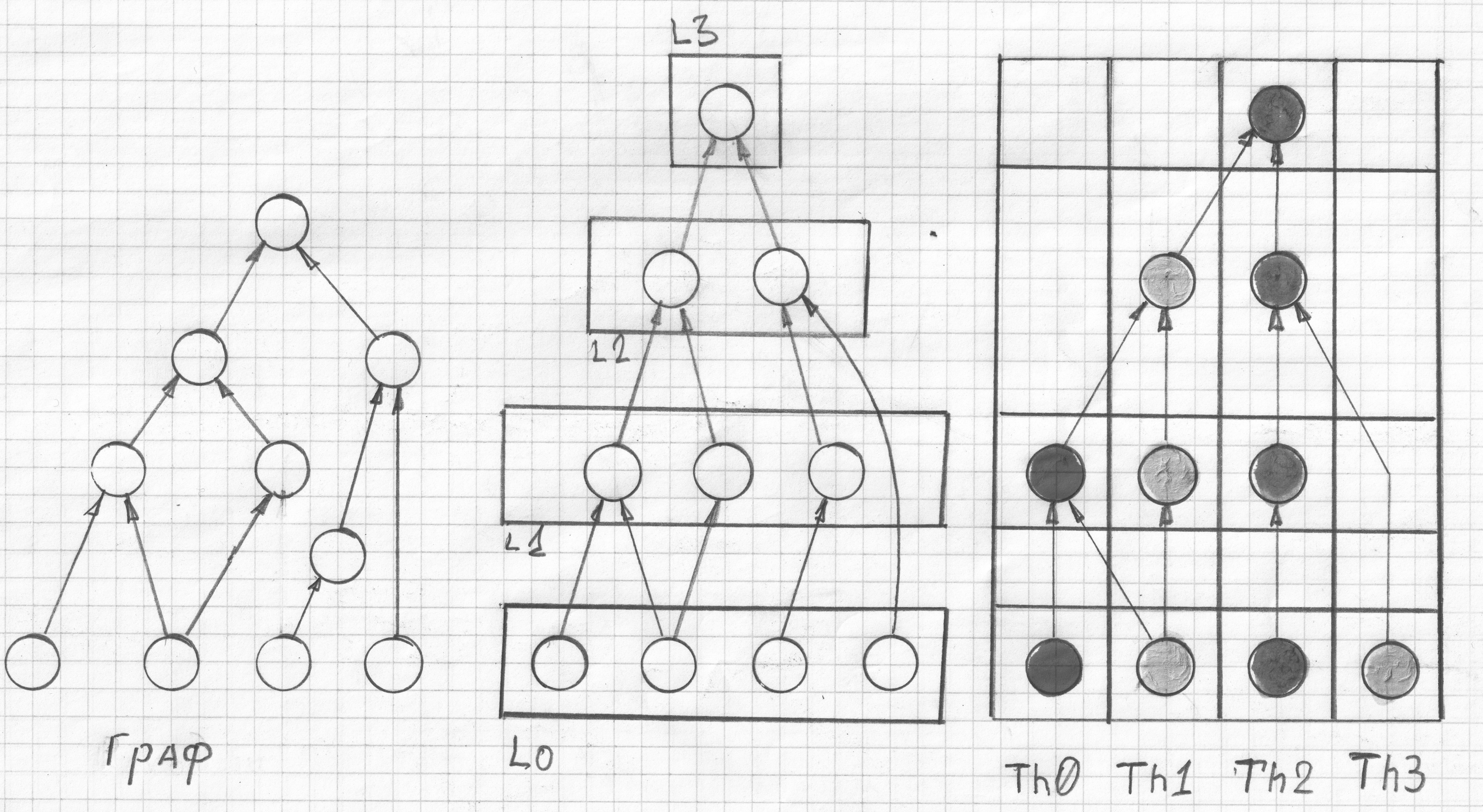
<meta http-equiv="CONTENT-TYPE" content="text/html; charset=utf-8">
<title></title>
<meta name="GENERATOR" content="OpenOffice 4.1.6 (Win32)">
<style type="text/css">
<!--
@page { size: 21cm 29.7cm; margin: 2cm }
P { margin-bottom: 0.21cm }
-->
</style>
Определим механизм чтения второго операнда.
Сохранять операнды в оперативной памяти, как это делается в современных процессорах невыгодно по времени доступа к памяти и затратам энергии. После вычисления «взаимодействия» эти данные будут полностью израсходованы, но в исходном графе таких ребер, временно хранимых операндов, может быть очень много. При выделении отдельной ячейки памяти для хранения каждого из операндов они все могут не поместиться в быструю память (расширенный аналог регистровой памяти). Если смотреть на результат сортировки узлов, то можно заметить, что данные появляются (и расходуются) не одномоментно. Можно определить сколько данных будет использовано в процессе вычисления каждого слоя (или нескольких слоев) и сколько перейдет следующим. Кроме памяти для второго операнда, требуется еще и память для хранения списка узлов, из которых состоит «нить» (или несколько нитей).
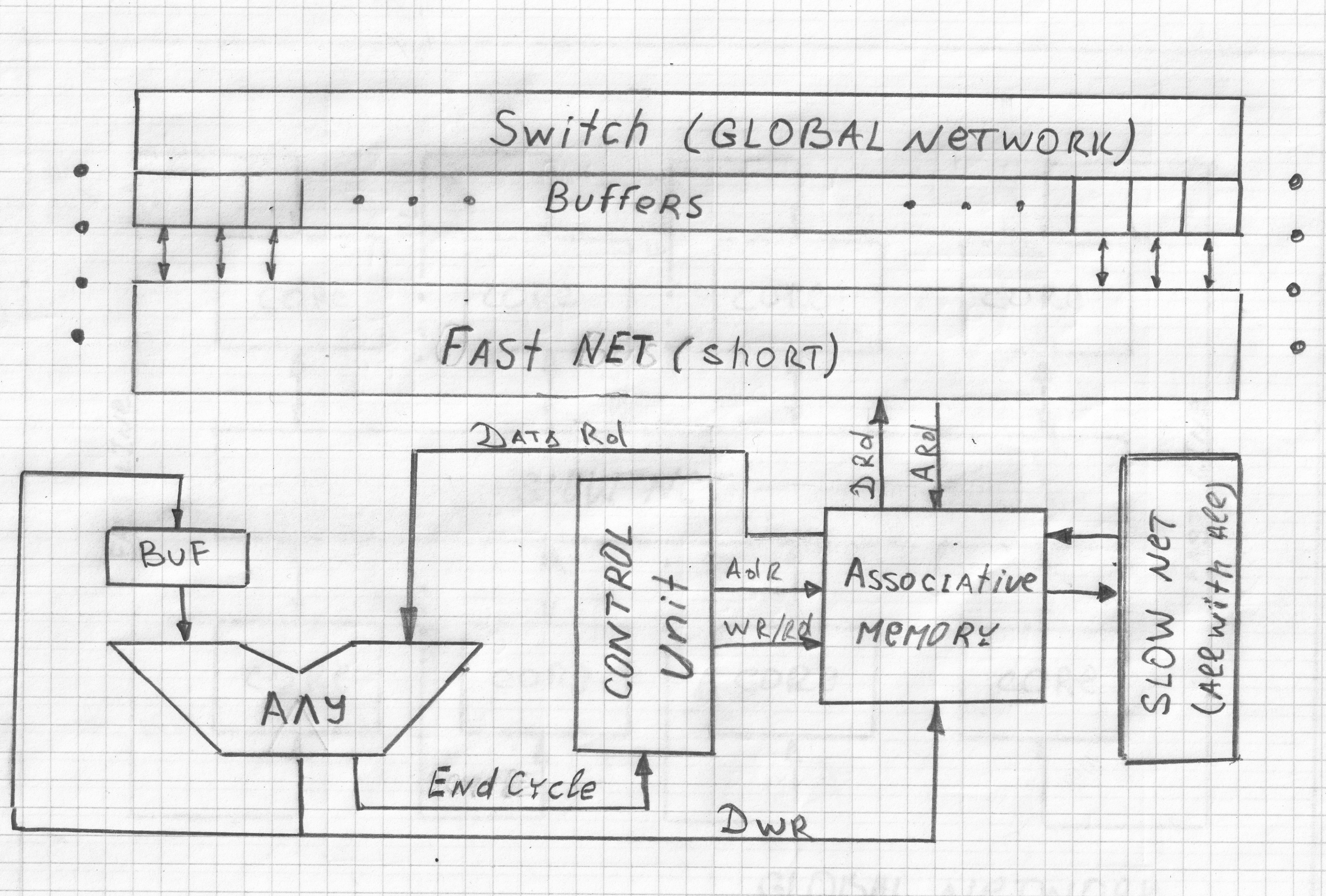
<meta http-equiv="CONTENT-TYPE" content="text/html; charset=utf-8">
<title></title>
<meta name="GENERATOR" content="OpenOffice 4.1.6 (Win32)">
<style type="text/css">
<!--
@page { size: 21cm 29.7cm; margin: 2cm }
P { margin-bottom: 0.21cm }
-->
</style>
Появляется задача распределения отсортированного графа по отдельным вычислительным «ядрам», имеющим некоторый объем памяти, интерфейс связи с соседними «ячейками» и возможность доступа к каналам связи. Назначим каждому ребру графа уникальный идентификатор, возможно уникальный даже в пределах нескольких объектов. С большой вероятностью число уникальных идентификаторов будет много больше суммарной памяти всех вычислительных ячеек и максимального числа одновременно передаваемых между слоями данных. Поэтому использовать обычную память (данные выбираются по адресу) невыгодно, в новой парадигме в вычислительных «ядрах» должна использоваться ассоциативная память (замена регистровой и КЭШ памяти в парадигме фон-неймана). АЗУ будет хранить данные до момента их использования и предоставлять их, как «своему» АЛУ, так некоторому числу соседних, но не всем одинаково быстро (ближайшим соседям быстро — за один такт) и это нужно учитывать при размещении «нитей» по различным «ядрам». Получается, что каждое «ядро» имеет многоканальное АЗУ, число каналов чтения равно числу соседей, которым предоставлен быстрый доступ к данным (остальные медленнее и другим механизмом). Для «вычисления» объекта необходимо распределить граф по отдельным вычислительным «ядрам» так, что бы хранимых на каждой ступени (несколько слоев) вычисления данных было не больше числа ячеек АЗУ и список вычисляемых вершин (команд) мог поместиться в память генератора команд (control unit). По вертикали (между слоями) «ядра» соединяются через основную коммуникационную среду вычислительной системы (обычные каналы передачи данных). Данные из АЗУ, а в ней кроме промежуточных данных хранятся еще и данные состояния объекта, также могут быть «коллективно» выгружены в оперативную память. Такой механизм можно сравнить с виртуальной памятью в современных процессорах, только здесь это будет механизм виртуального вычислительного пространства. Физически реализованных вычислительных ячеек может быть многократно меньше, чем использовано для исполнения конкретного набора ПО.

<meta http-equiv="CONTENT-TYPE" content="text/html; charset=utf-8">
<title></title>
<meta name="GENERATOR" content="OpenOffice 4.1.6 (Win32)">
<style type="text/css">
<!--
@page { size: 21cm 29.7cm; margin: 2cm }
P { margin-bottom: 0.21cm }
-->
</style>
Сколько физически существующих «ядер» необходимо для вычисления конкретного объекта?
Теоретически минимальное время вычисления объекта равно числу горизонтальных слоев (все вершины в слое могут быть вычислены одновременно). Для одновременного вычисления всех вершин в одном слое число вычислительных «ядер» должно быть всегда равным (или больше), числу вершин вычисляемых в каждом слое. Располагать весь граф в памяти вычислителя особого смысла нет, выгоднее выбрать размер памяти «ядер» такими, что бы время вычисления части графа было больше времени чтения данных для инициализации следующего «ядра» из оперативной памяти. Получим конвейер — половина ячеек вычисляет, вторая половина загружается из памяти, а может и вообще началось вычисление следующего взаимодействия. Если требуется получить максимальную производительность или реализовать конвейерную обработку большого числа данных, то можно максимально разложить граф по физически существующим ячейкам. При раскладке необходимо учитывать частоту исполнения тех или иных частей дерева, места расположения модулей памяти или математических сопроцессоров. Кроме того необходимо учитывать расположений линий связи и скорости передачи данных в создаваемых виртуальных каналах. Если все это учесть оптимальным образом, то можно получить крайне быструю согласованную работу миллионов составляющих вычислительной системы в рамках решаемой задачи, получить действительно «супер-компьютер», а не «грид-пародию» на него.
Исходный граф имеет множество путей исполнения (аналог условных переходов в парадигме фон-неймана) и если в пределах ячейки нет смысла исключать исполнение не активных путей (все данные не активных веток заменяются на символ «не вычислимо»), то при загрузке данных следующего «ядра», можно «заменить» универсальный граф вычисления объекта на «оптимизированный».
Вычислительный процесс состоит из множества нитей, необходимо синхронизировать (выравнивать) скорость исполнения во всех нитях. В парадигме фон-неймана, без дополнительных и весьма неэффективных ухищрений, это невозможно по причине отсутствия понятия «нет данных». В новой парадигме в вычислениях участвуют не просто битовые последовательности, а символы которые кроме непосредственно значения имеют еще и тип. АЗУ при отсутствии требуемого «ключа», будет при чтении выдавать символ: «нет данных». Вычислительный процесс в каждом «ядре» идет независимо друг от друга, но в момент когда в ответ на запрос чтения приходит значение «нет данных», вычисления останавливается до момента пока не вернется другой тип символа. Таким образом скорость в конкретном «ядре» притормаживается, относительно всех остальных. Результат вычисления должен быть записан (если это необходимо) в локальное АЗУ, писать можно только в свою локальную часть АЗУ (иначе может случиться «клинч»). Размер АЗУ конечен и в какой то момент наступит переполнение, после которого необходимо ждать освобождения памяти соседними «ядрами» (они используют эти данные для вычисления своих вершин). Увеличение размера локального АЗУ позволяет выполнить большее число команд, подготовить больше данных для соседних «ядер». Возможность заранее вычислять еще не востребованные данные, является аналогом внеочередного исполнения, в разных «ядрах» вычислительный процесс может находиться на разных «слоях». Если результат вычисления вершины графа используется в нескольких вычислениях, то выгоднее к данным добавить счетчик и уменьшать его при каждом чтении и когда он станет равным нулю освободить ячейку АЗУ, а не занимать отдельные ячейки памяти.
Для сложных команд (различные математические функции, различные виды памяти, различные виды ускорителей) можно связываться с таким вычислителем через коммуникационную сеть, выгоднее использовать «коллективный» буфер (в один поток суммируются запросы от многих «ядер») и выполнять коллективный доступ. При обращении, именно обращении к результату, а не при отправке исходных данных, вычислительный процесс приостановится (в конкретном «ядре») до получения результата.
Если Вам кажется, что ациклический ориентированный граф, это какая то редкая конструкция и не для всех задач его можно построить.
Проведите мысленный эксперимент:
Возьмем любую функцию (Изначально созданную на языке высокого уровня).
Выполним ее и запишем последовательность исполненных ассемблерных команд.
Для простоты понимания выделим из этих команд только те, которые производят изменения данных, их будет примерно 20% от общего количества.
Построим граф где вершиной будет команда, ребра будут результатами исполнения или данными имеющимися на момент начала вычисления
Получаем ориентированный ациклический граф, вычисляющий значение функции для данного конкретного набора данных. Эксперимент показывает, что есть возможность превращать обычную программу в программу (ациклический граф) для новой вычислительной парадигмы.
Да, реальный компилятор будет сложнее, но принципиальная возможность есть.
В новой парадигме нет понятие цикла (есть понятие спираль).
Вопрос: Как примирить сегодняшнее представление о программировании, где практически постоянно встречаются различные циклы?
Необходимо рассматривать цикл не как исполняемую конструкцию, а как способ записать многократно повторяющуюся последовательность команд (особый тип макроса).
Считаем, что цикл имеет бесконечное число повторений. Для того что бы в результате «компиляции» не получить бесконечного размера граф (программу), необходимо записывать ее в «сжатом» виде (добавить служебные символы указывающие на бесконечное число повторений) и в момент исполнения «распаковывать» (control unit) уже в вычислительном «ядре». В момент завершения цикла, необходимо отправить сообщение (записать данные в регистр управления) модулю генерирующему последовательность команд сигнал завершающий генерацию повторов тела цикла. В процессе компиляции никто не запрещает выполнить несколько «логических» итераций цикла за одну «физическую», что позволит дополнительно ускорить вычисление. Примерно по той же схеме можно организовывать вызовы функций (процедур), подмену частей графа на оптимизированные варианты (где исключены не использованные «пути»).
Память в новой парадигме.
Понятие адресного пространства отсутствует и обращение к данным идет по уникальному идентификатору. Никаких ограничений на размер и структуру уникального идентификатора нет, в него можно «вложить» путь до конкретного запоминающего устройства, тип памяти, параметры доступа и многое другое. Все уникальные идентификаторы могут выглядеть как адрес в сети и при построении маршрута он будет постепенно использоваться промежуточными объектами для маршрутизации, настроек доступа (пароли и др), адреса в физической памяти, размера в битах и многое другое. По существу в процессе доступа к данным уникальный идентификатор является данными взаимодействия. Кроме того большинство обращений к памяти являются коллективными (чтение массивов данных), все отдельные переменные (данные состояния или промежуточные данные) хранятся в АЗУ вычислительного «ядра» и загружаются (сохраняются) коллективно в момент инициализации вычислительного процесса.
Подробно процесс создания ПО, описание операционной системы и алгоритма решения произвольной задачи, будет описан в следующей статье.
