Сегодня высокопроизводительные вычисления (HPC), искусственный интеллект (AI) и анализ данных (DA) пересекаются всё чаще и чаще. Дело в том, что для решения сложных проблем требуется комбинация различных методик. Сочетание AI, HPC и DA в традиционных технологических процессах может ускорить научные открытия и инновации.
Учёные и исследователи в области обработки данных разрабатывают новые процессы решения проблемы в массовом масштабе, требующие вычислительных ресурсов, таких как HPC-системы. Рабочие нагрузки, связанные с AI и анализом данных, выигрывают от использования HPC-инфраструктуры, которая способна масштабироваться для улучшения производительности. О тенденциях этого рынка и подходах к созданию архитектуры для DA, AI и HPC сегодня и поговорим под катом.

Тенденция к конвергенции современных рабочих нагрузок требует использования более унифицированной архитектуры. Для традиционных рабочих нагрузок HPC (скажем, моделирования) нужно больших вычислительных мощностей, а также быстрых сетевых соединений и высокопроизводительных файловых систем. Например, создание модели пласта месторождения полезных ископаемых может занимать от нескольких часов до нескольких дней.
Рабочие нагрузки, связанные с искусственным интеллектом и анализом данных, весьма ресурсоёмкие: они требуют наличия инструментов для сбора данных и специализированных рабочих мест для операторов, занимающихся их обработкой. Искусственный интеллект и аналитика данных — это процессы, требующие интерактивного взаимодействия и повторяющихся действий.
Разница в рабочих нагрузках HPC, AI и DA может создавать впечатление, что для них потребуются три отдельные инфраструктуры, однако это не так. Унифицированная архитектура подойдет как аналитикам данных, так и учёным, работающим с искусственным интеллектом, без переучивания и приспособления к новой операционной модели.
Однако интеграция всех трёх рабочих нагрузок на единой архитектуре действительно создает проблемы, которые необходимо учитывать:
Готовые решения Dell Technologies для искусственного интеллекта и анализа данных – это единая среда, соответствующая требованиям всех трёх нагрузок. Они строятся с учётом четырёх основных принципов:
Пользователи нуждаются в быстром доступе к своим данным независимо от рабочей нагрузки. Перемещение данных должно быть ограничено между разрозненными средами хранения. Наборы данных для HPC, AI и для DA должны быть объединены в единую среду для повышения операционной эффективности, особенно если рабочий процесс совмещает несколько техник.
Например, продвинутые системы помощи водителю используют модели экстремальных погодных условий для предотвращения аварийных ситуаций в условиях реального движения машины в плохую погоду. Затем новые данные используются для обучения глубокой нейронной сети: выход становится входом для обучения модели. Далее результаты загружаются в Spark, который используется для подключения к текущему набору данных заказчика и для отбора лучших данных для последующих тренировок модели. Для лучшей производительности данные, получаемые от рабочего процесса, должны быть как можно ближе к уже имеющимся данным.

Потребители высокопроизводительных вычислений зависят от традиционных планировщиков заданий, таких как SLURM. Для пакетного планирования SLURM распределяет аппаратные ресурсы на основе временных интервалов и предоставляет фреймворк для инициации, запуска и контроля выполняемых заданий. SLURM также обеспечивает управление очередью для поданных заявок во избежание разногласий между задачами в кластере.
При анализе данных используются такие планировщики заданий, как Spark Standalone и Mesos. Готовая архитектура для высокопроизводительных вычислений и искусственного интеллекта использует Kubernetes для оркестровки Spark и управления ресурсами для выполняемых задач. Так как ни один планировщик заданий не обращается к обеим средам, то архитектура должна поддерживать и то, и другое. Dell Technologies разработала архитектуру, которая удовлетворяет обоим требованиям.
Готовая архитектура Dell EMC для высокопроизводительных вычислений, анализа данных и искусственного интеллекта создает единый пул ресурсов. Ресурсы могут быть динамически назначены любой HPC-задаче, которая управляется с помощью менеджера ресурсов HPC или для контейнеризированных рабочих нагрузок искусственного интеллекта или анализа данных, которые, в свою очередь, управляются из контейнерной системы Kubernetes.
Архитектура должна быть способна масштабироваться для одного типа рабочей нагрузки без ущерба для другой. Важное значение в понимании требований нагрузок имеют языки программирования, потребности в масштабировании, управление программным стеком и файловыми системами. В таблице ниже приведены примеры используемых технологий при построении масштабируемой архитектуры:

Последним компонентом дизайна является интеграция Kubernetes и Docker в архитектуру Kubernetes — это система контейнеризации с открытым исходным кодом, используемая для автоматизации внедрения, масштабирования и управления. Kubernetes помогает организовать кластер серверов и составить расписание работы контейнеров с учётом имеющихся ресурсов и потребностей каждого контейнера в ресурсах. Контейнеры собраны в группы, базовую операционную единицу Kubernetes, которые масштабируются до желаемого размера.
Kubernetes помогает управлять сервисом обнаружения, включающим балансировку нагрузки, отслеживание распределения ресурсов, утилизацию и проверку состояния отдельных ресурсов. Это позволяет приложениям самовосстанавливаться путём автоматического перезапуска или копирования контейнеров.
Docker — это программная платформа, позволяющая быстро создавать, тестировать и внедрять программные продукты. Она упаковывает программы в стандартные модули, называемые контейнерами, которые имеют все необходимое для запуска программы, включая библиотеки, системные инструменты, код и условия для его исполнения. С помощью Docker можно быстро развернуть и масштабировать приложения в любой среде и быть уверенным, что код будет запущен.
Dell EMC PowerEdge DSS 8440 — это двухпроцессорный сервер (4U), оптимизированный для высокопроизводительных вычислений. В один DSS 8440 может быть установлено 4, 8 или 10 графических ускорителей NVIDIA V100 для распознавания изображений или NVIDIA T4 для обработки естественного языка (NLP). Десять NVMe накопителей обеспечивают быстрый доступ к обучающим данным. Этот сервер обладает как производительностью, так и гибкостью, чтобы быть идеальным решением для машинного обучения, а также других ресурсоёмких рабочих нагрузок. Например, моделирования и прогностического анализа в инженерной и научной среде.

Dell EMC PowerEdge C4140 обеспечивает потребности в масштабируемых серверных решениях, необходимых для обучения нейронных сетей. Глубокое обучение — процесс, требующий серьёзных вычислительных ресурсов, в том числе быстрых графических процессоров, особенно на этапе обучения. Каждый сервер C4140 поддерживает до четырёх графических процессоров NVIDIA Tesla V100 (Volta). Подключенные через фабрику NVIDIA NVLINK 20 восемь и более C4140 могут быть кластеризованы для более масштабных моделей, обеспечивая производительность до 500 Пфлопс.

Dell EMC PowerEdge R740xd – это классический двухпроцессорный сервер, который подходит для большинства проектов по машинному обучению. Этот 2U-сервер общего назначения обладает перспективой для дальнейшего его использования для задач глубокого обучения, так как поддерживает установку графических ускорителей и большого количества накопителей.

Dell EMC PowerSwitch S5232F-ON: высокопроизводительный Ethernet Dell EMC S5235F-ON S5235F-ON имеет 32 порта QSFP28 каждый из который поддерживает 100 GbE или 10/25/40/50 GbE с помощью кабелей-разветвителей. Шина коммутатора имеет пропускную способностью 64 Тбит/с, обеспечивая высокую производительность при низких задержках.
Mellanox SB7800 — подходящее решение для для множества одновременных нагрузок. Производительная, неблокируемая шина на 72 Тбит/c с задержкой между двумя любыми точками коммутации в 90 нс обеспечивает высокую производительность решения.
Выбор аппаратных компонентов зависит от решаемой задачи и используемого программного обеспечения. Достаточно условно подсистемы хранения данных можно разделить на три типа:
Можно выделить комбинированные подходы, когда в качестве оперативного уровня хранения используются либо встроенные сервисы хранения, либо специализированные системы, а облачные системы выступают в качестве архивного долговременного хранилища. Использование того или иного сервиса хранения зависит от решаемой задачи и регулирующих требований (защита от катастроф, интеграция с провайдерами авторизации и аудита, удобства использования).
С одной стороны, встроенные сервисы по хранению, если они доступны в ПО, достаточно быстро разворачиваются и, разумеется, максимально интегрированы с другими сервисами приложения. С другой стороны, они не всегда отвечают всем необходимым требованиям. Например отсутствует полноценная репликация или нет интеграции с системами резервного копирования. Более того, мы создаём ещё один выделенный «сегмент/остров данных» исключительно для одного дистрибутива либо набора приложений.

К сервису хранения данных можно предъявить следующие требования:
Производительность системы хранения данных критически важна для высокопроизводительных вычислений, машинного обучения и проектов с искусственным интеллектом. Поэтому Dell Technologies предлагает широкий ассортимент систем хранения данных, построенных полностью на флэш-памяти и гибридных систем, способных удовлетворить самым жестким требованиям, предъявляемым заказчиками.
Ассортимент систем хранения Dell EMC включает высокопроизводительные СХД PowerScale (HDFS, NFS/SMB) и ECS (S3, Opensatck Swift, HDFS), а также распределенные СХД, работающие по протоколам NFS и Lustre.
В качестве примера специализированной системы, которая позволяет эффективно работать в проектах, связанных c большими данными, можно привести Dell EMC PowerScale. Она позволяет построить корпоративное «озеро данных». СХД не содержит контроллеров и дисковых полок, а представляет собой набор равнозначных узлов, объединённых с помощью выделенной дублированной сети. Каждый узел содержит диски, процессоры, память и сетевые интерфейсы для клиентского доступа. Вся дисковая ёмкость кластера формирует единый пул хранения и единую файловую систему, доступ к которой возможен через любой из узлов.
Dell EMC PowerScale — это система хранения с параллельным доступом по различным файловым протоколам. Все узлы формируют единый пул ресурсов и единую файловую систему. Все узлы равноправны, любой из узлов может обработать любой запрос без дополнительных накладных расходов. Система расширяется до 252 узлов. В рамках одного кластера мы можем использовать пулы узлов с разной производительностью. Для оперативной обработки применять производительные узлы с SSD/NVMe и производительным сетевым доступом 40 либо 25 GbE, а для архивных данных узлы с ёмкими SATA дисками на 8-12 терабайт. Дополнительно появляется возможность перемещения наименее используемых данных в облако: как частное, так и публичное.

Использование системы Dell EMC PowerScale позволило реализовать ряд интересных проектов, связанных с технологиями больших данных. Например, систему идентификации подозрительных действий для Mastercard. Также с её помощью успешно решаются задачи, связанные с автоматическим управлением автомобиля (ADAS) компании Zenuity. Одним из важных моментов является возможность выделения сервиса хранения данных в отдельный уровень с возможностью его отдельного масштабирования.
Таким образом, к единой платформе хранения с одним набором данных можно подключать различные аналитические платформы. Например, основной аналитический кластер с определённым дистрибутивом Hadoop, который работает напрямую на серверах, и виртуализированный контур разработки/тестирования. При этом под задачи аналитики можно выделить не весь кластер, а только его определённую часть.
Вторым важным моментом является то, что PowerScale предоставляет доступ именно к файловой системе. То есть, по сравнению с традиционными решениями здесь нет жёсткого ограничения на объём анализируемой информации. Кластерная архитектура обеспечивает отличную производительность для задач машинного обучения даже при использовании ёмких SATA-дисков. Отличной иллюстрацией являются задачи по ML / DL где точность полученной модели может зависит от объёма и качества данных.
В качестве базовой системы хранения можно использовать — Dell EMC PowerVault ME4084 (DAS). Она расширяется до объёма в 3 петабайта и способна обеспечить пропускную способность 5500 Мб/с и 320 000 IOPS.
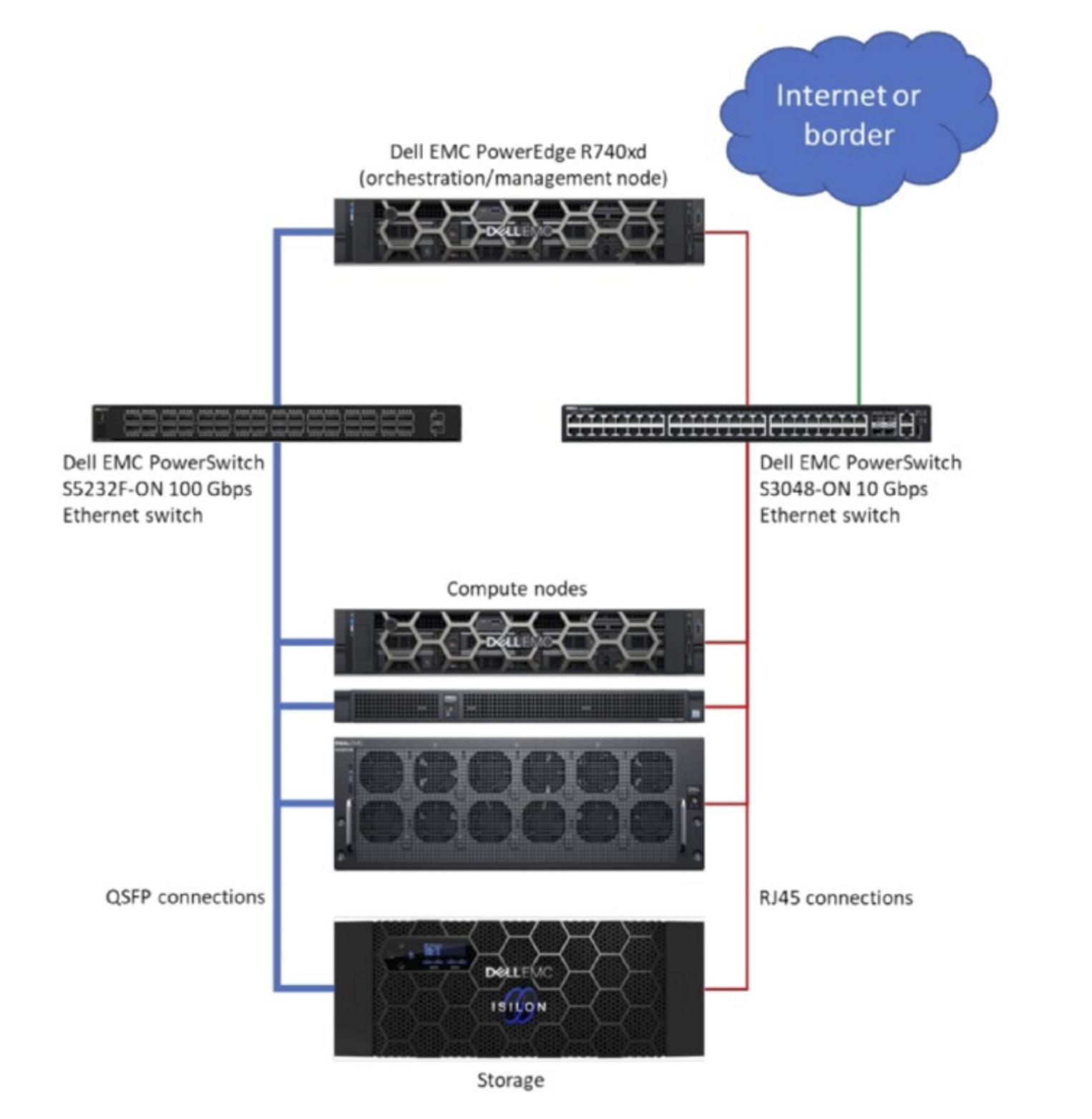
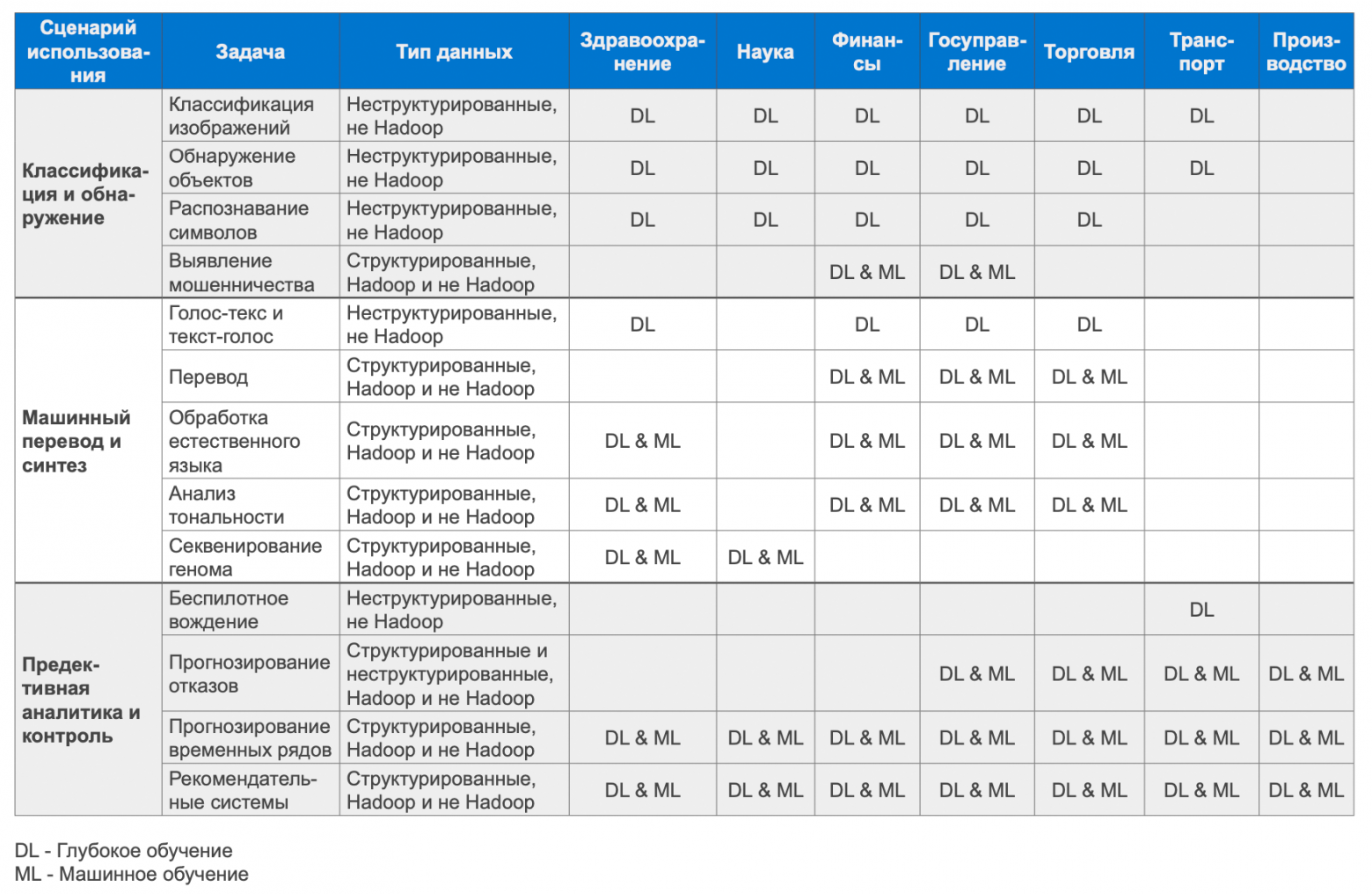
Готовые решения Dell Technologies для высокопроизводительных вычислений, искусственного интеллекта и анализа данных – это унифицированная архитектура, поддерживающая различные виды нагрузок. Архитектура основывается на четырёх ключевых компонентах: доступность данных, простое планирование заданий и управление ресурсами, оптимизация рабочих нагрузок плюс интегрированные оркестрация и контейнеризация. Архитектура поддерживает различные варианты серверов, сетей и хранилищ данных для наилучшего удовлетворения потребностей в области высокопроизводительных вычислений.
Использовать их можно для решения очень разных задач, и мы всегда готовы помочь заказчикам с выбором, развёртыванием, настройкой и обслуживанием оборудования.
Автор материала – Александр Коряковский, инженер-консультант департамента вычислительных и сетевых решений Dell Technologies в России
Учёные и исследователи в области обработки данных разрабатывают новые процессы решения проблемы в массовом масштабе, требующие вычислительных ресурсов, таких как HPC-системы. Рабочие нагрузки, связанные с AI и анализом данных, выигрывают от использования HPC-инфраструктуры, которая способна масштабироваться для улучшения производительности. О тенденциях этого рынка и подходах к созданию архитектуры для DA, AI и HPC сегодня и поговорим под катом.

Тенденция к конвергенции современных рабочих нагрузок требует использования более унифицированной архитектуры. Для традиционных рабочих нагрузок HPC (скажем, моделирования) нужно больших вычислительных мощностей, а также быстрых сетевых соединений и высокопроизводительных файловых систем. Например, создание модели пласта месторождения полезных ископаемых может занимать от нескольких часов до нескольких дней.
Рабочие нагрузки, связанные с искусственным интеллектом и анализом данных, весьма ресурсоёмкие: они требуют наличия инструментов для сбора данных и специализированных рабочих мест для операторов, занимающихся их обработкой. Искусственный интеллект и аналитика данных — это процессы, требующие интерактивного взаимодействия и повторяющихся действий.
Разница в рабочих нагрузках HPC, AI и DA может создавать впечатление, что для них потребуются три отдельные инфраструктуры, однако это не так. Унифицированная архитектура подойдет как аналитикам данных, так и учёным, работающим с искусственным интеллектом, без переучивания и приспособления к новой операционной модели.
Однако интеграция всех трёх рабочих нагрузок на единой архитектуре действительно создает проблемы, которые необходимо учитывать:
- Навыки пользователей HPC, AI или DA различаются.
- Системы управления ресурсами и планировщики нагрузок не являются взаимозаменяемыми.
- Не всё программное обеспечение и не все фреймворки интегрированы в единую платформу.
- Экосистемы требуют различных инструментов и функций.
- Нагрузки и их требования к производительности отличаются.
Основа готовых решений Dell Technologies
Готовые решения Dell Technologies для искусственного интеллекта и анализа данных – это единая среда, соответствующая требованиям всех трёх нагрузок. Они строятся с учётом четырёх основных принципов:
- Доступность данных.
- Простое планирование заданий и управление ресурсами.
- Оптимизация рабочих нагрузок.
- Интегрированные оркестрация и контейнеризация.
Доступность данных
Пользователи нуждаются в быстром доступе к своим данным независимо от рабочей нагрузки. Перемещение данных должно быть ограничено между разрозненными средами хранения. Наборы данных для HPC, AI и для DA должны быть объединены в единую среду для повышения операционной эффективности, особенно если рабочий процесс совмещает несколько техник.
Например, продвинутые системы помощи водителю используют модели экстремальных погодных условий для предотвращения аварийных ситуаций в условиях реального движения машины в плохую погоду. Затем новые данные используются для обучения глубокой нейронной сети: выход становится входом для обучения модели. Далее результаты загружаются в Spark, который используется для подключения к текущему набору данных заказчика и для отбора лучших данных для последующих тренировок модели. Для лучшей производительности данные, получаемые от рабочего процесса, должны быть как можно ближе к уже имеющимся данным.

Планирование заданий и управление ресурсами
Потребители высокопроизводительных вычислений зависят от традиционных планировщиков заданий, таких как SLURM. Для пакетного планирования SLURM распределяет аппаратные ресурсы на основе временных интервалов и предоставляет фреймворк для инициации, запуска и контроля выполняемых заданий. SLURM также обеспечивает управление очередью для поданных заявок во избежание разногласий между задачами в кластере.
При анализе данных используются такие планировщики заданий, как Spark Standalone и Mesos. Готовая архитектура для высокопроизводительных вычислений и искусственного интеллекта использует Kubernetes для оркестровки Spark и управления ресурсами для выполняемых задач. Так как ни один планировщик заданий не обращается к обеим средам, то архитектура должна поддерживать и то, и другое. Dell Technologies разработала архитектуру, которая удовлетворяет обоим требованиям.
Готовая архитектура Dell EMC для высокопроизводительных вычислений, анализа данных и искусственного интеллекта создает единый пул ресурсов. Ресурсы могут быть динамически назначены любой HPC-задаче, которая управляется с помощью менеджера ресурсов HPC или для контейнеризированных рабочих нагрузок искусственного интеллекта или анализа данных, которые, в свою очередь, управляются из контейнерной системы Kubernetes.
Оптимизация рабочих нагрузок
Архитектура должна быть способна масштабироваться для одного типа рабочей нагрузки без ущерба для другой. Важное значение в понимании требований нагрузок имеют языки программирования, потребности в масштабировании, управление программным стеком и файловыми системами. В таблице ниже приведены примеры используемых технологий при построении масштабируемой архитектуры:

Оркестрация и контейнеризация
Последним компонентом дизайна является интеграция Kubernetes и Docker в архитектуру Kubernetes — это система контейнеризации с открытым исходным кодом, используемая для автоматизации внедрения, масштабирования и управления. Kubernetes помогает организовать кластер серверов и составить расписание работы контейнеров с учётом имеющихся ресурсов и потребностей каждого контейнера в ресурсах. Контейнеры собраны в группы, базовую операционную единицу Kubernetes, которые масштабируются до желаемого размера.
Kubernetes помогает управлять сервисом обнаружения, включающим балансировку нагрузки, отслеживание распределения ресурсов, утилизацию и проверку состояния отдельных ресурсов. Это позволяет приложениям самовосстанавливаться путём автоматического перезапуска или копирования контейнеров.
Docker — это программная платформа, позволяющая быстро создавать, тестировать и внедрять программные продукты. Она упаковывает программы в стандартные модули, называемые контейнерами, которые имеют все необходимое для запуска программы, включая библиотеки, системные инструменты, код и условия для его исполнения. С помощью Docker можно быстро развернуть и масштабировать приложения в любой среде и быть уверенным, что код будет запущен.
Аппаратные блоки архитектуры
Выбор правильного сервера
Dell EMC PowerEdge DSS 8440 — это двухпроцессорный сервер (4U), оптимизированный для высокопроизводительных вычислений. В один DSS 8440 может быть установлено 4, 8 или 10 графических ускорителей NVIDIA V100 для распознавания изображений или NVIDIA T4 для обработки естественного языка (NLP). Десять NVMe накопителей обеспечивают быстрый доступ к обучающим данным. Этот сервер обладает как производительностью, так и гибкостью, чтобы быть идеальным решением для машинного обучения, а также других ресурсоёмких рабочих нагрузок. Например, моделирования и прогностического анализа в инженерной и научной среде.

Dell EMC PowerEdge C4140 обеспечивает потребности в масштабируемых серверных решениях, необходимых для обучения нейронных сетей. Глубокое обучение — процесс, требующий серьёзных вычислительных ресурсов, в том числе быстрых графических процессоров, особенно на этапе обучения. Каждый сервер C4140 поддерживает до четырёх графических процессоров NVIDIA Tesla V100 (Volta). Подключенные через фабрику NVIDIA NVLINK 20 восемь и более C4140 могут быть кластеризованы для более масштабных моделей, обеспечивая производительность до 500 Пфлопс.

Dell EMC PowerEdge R740xd – это классический двухпроцессорный сервер, который подходит для большинства проектов по машинному обучению. Этот 2U-сервер общего назначения обладает перспективой для дальнейшего его использования для задач глубокого обучения, так как поддерживает установку графических ускорителей и большого количества накопителей.

Выбор правильной сети
Dell EMC PowerSwitch S5232F-ON: высокопроизводительный Ethernet Dell EMC S5235F-ON S5235F-ON имеет 32 порта QSFP28 каждый из который поддерживает 100 GbE или 10/25/40/50 GbE с помощью кабелей-разветвителей. Шина коммутатора имеет пропускную способностью 64 Тбит/с, обеспечивая высокую производительность при низких задержках.
Mellanox SB7800 — подходящее решение для для множества одновременных нагрузок. Производительная, неблокируемая шина на 72 Тбит/c с задержкой между двумя любыми точками коммутации в 90 нс обеспечивает высокую производительность решения.
Сервисы и системы хранения данных
Выбор правильного сервиса хранения данных
Выбор аппаратных компонентов зависит от решаемой задачи и используемого программного обеспечения. Достаточно условно подсистемы хранения данных можно разделить на три типа:
- Сервис хранения встроен в программное обеспечение и является его составной частью. В качестве примера можно привести Apache Hadoop с файловой системой HDFS, либо No SQL БД Apache Cassandra.
- Сервис хранения предоставляется либо специализированными решениями (например, Dell EMC PowerScale), либо корпоративными системами хранения данных.
- Доступ к облачным ресурсам: как к частным Dell EMC ECS, Cloudian, Ceph, так и публичным – Amazon, Google, MS Azure. Доступ к данным, как правило, осуществляется на базе REST протоколов – Amazon S3, Openstack Swift и т.д. Это один из наиболее активно развивающихся сегментов рынка хранения для Big Data.
Можно выделить комбинированные подходы, когда в качестве оперативного уровня хранения используются либо встроенные сервисы хранения, либо специализированные системы, а облачные системы выступают в качестве архивного долговременного хранилища. Использование того или иного сервиса хранения зависит от решаемой задачи и регулирующих требований (защита от катастроф, интеграция с провайдерами авторизации и аудита, удобства использования).
С одной стороны, встроенные сервисы по хранению, если они доступны в ПО, достаточно быстро разворачиваются и, разумеется, максимально интегрированы с другими сервисами приложения. С другой стороны, они не всегда отвечают всем необходимым требованиям. Например отсутствует полноценная репликация или нет интеграции с системами резервного копирования. Более того, мы создаём ещё один выделенный «сегмент/остров данных» исключительно для одного дистрибутива либо набора приложений.

Требования к функциональности
К сервису хранения данных можно предъявить следующие требования:
- Линейная масштабируемость как по ёмкости, так и производительности.
- Возможность эффективно работать в многопоточной среде.
- Толерантность к массированным сбоям компонентов системы.
- Простота модернизации и расширения системы.
- Возможности по созданию оперативных и архивных уровней хранения.
- Расширенный функционал по работе с данными (аудит, средства DR, защита от несанкционированных изменений, дедупликация, поиск по метаданным и т.д.).
Производительность системы хранения данных критически важна для высокопроизводительных вычислений, машинного обучения и проектов с искусственным интеллектом. Поэтому Dell Technologies предлагает широкий ассортимент систем хранения данных, построенных полностью на флэш-памяти и гибридных систем, способных удовлетворить самым жестким требованиям, предъявляемым заказчиками.
Ассортимент систем хранения Dell EMC включает высокопроизводительные СХД PowerScale (HDFS, NFS/SMB) и ECS (S3, Opensatck Swift, HDFS), а также распределенные СХД, работающие по протоколам NFS и Lustre.
Пример специализированной системы
В качестве примера специализированной системы, которая позволяет эффективно работать в проектах, связанных c большими данными, можно привести Dell EMC PowerScale. Она позволяет построить корпоративное «озеро данных». СХД не содержит контроллеров и дисковых полок, а представляет собой набор равнозначных узлов, объединённых с помощью выделенной дублированной сети. Каждый узел содержит диски, процессоры, память и сетевые интерфейсы для клиентского доступа. Вся дисковая ёмкость кластера формирует единый пул хранения и единую файловую систему, доступ к которой возможен через любой из узлов.
Dell EMC PowerScale — это система хранения с параллельным доступом по различным файловым протоколам. Все узлы формируют единый пул ресурсов и единую файловую систему. Все узлы равноправны, любой из узлов может обработать любой запрос без дополнительных накладных расходов. Система расширяется до 252 узлов. В рамках одного кластера мы можем использовать пулы узлов с разной производительностью. Для оперативной обработки применять производительные узлы с SSD/NVMe и производительным сетевым доступом 40 либо 25 GbE, а для архивных данных узлы с ёмкими SATA дисками на 8-12 терабайт. Дополнительно появляется возможность перемещения наименее используемых данных в облако: как частное, так и публичное.

Проекты и сферы применения
Использование системы Dell EMC PowerScale позволило реализовать ряд интересных проектов, связанных с технологиями больших данных. Например, систему идентификации подозрительных действий для Mastercard. Также с её помощью успешно решаются задачи, связанные с автоматическим управлением автомобиля (ADAS) компании Zenuity. Одним из важных моментов является возможность выделения сервиса хранения данных в отдельный уровень с возможностью его отдельного масштабирования.
Таким образом, к единой платформе хранения с одним набором данных можно подключать различные аналитические платформы. Например, основной аналитический кластер с определённым дистрибутивом Hadoop, который работает напрямую на серверах, и виртуализированный контур разработки/тестирования. При этом под задачи аналитики можно выделить не весь кластер, а только его определённую часть.
Вторым важным моментом является то, что PowerScale предоставляет доступ именно к файловой системе. То есть, по сравнению с традиционными решениями здесь нет жёсткого ограничения на объём анализируемой информации. Кластерная архитектура обеспечивает отличную производительность для задач машинного обучения даже при использовании ёмких SATA-дисков. Отличной иллюстрацией являются задачи по ML / DL где точность полученной модели может зависит от объёма и качества данных.
Традиционные системы
В качестве базовой системы хранения можно использовать — Dell EMC PowerVault ME4084 (DAS). Она расширяется до объёма в 3 петабайта и способна обеспечить пропускную способность 5500 Мб/с и 320 000 IOPS.
Типовая схема готового решения для HPC, AI и анализа данных

Типовые сценарии применения ИИ по отраслям

Резюме
Готовые решения Dell Technologies для высокопроизводительных вычислений, искусственного интеллекта и анализа данных – это унифицированная архитектура, поддерживающая различные виды нагрузок. Архитектура основывается на четырёх ключевых компонентах: доступность данных, простое планирование заданий и управление ресурсами, оптимизация рабочих нагрузок плюс интегрированные оркестрация и контейнеризация. Архитектура поддерживает различные варианты серверов, сетей и хранилищ данных для наилучшего удовлетворения потребностей в области высокопроизводительных вычислений.
Использовать их можно для решения очень разных задач, и мы всегда готовы помочь заказчикам с выбором, развёртыванием, настройкой и обслуживанием оборудования.
Автор материала – Александр Коряковский, инженер-консультант департамента вычислительных и сетевых решений Dell Technologies в России
