
Ваша компания хочет собирать и анализировать данные для изучения тенденций, но при этом не жертвуя конфиденциальностью? Или, возможно, вы уже пользуетесь различными инструментами для её сохранения и хотите углубить ваши знания или поделиться опытом? В любом случае, этот материал для вас.
Что нас побудило начать эту серию статей? В прошлом году NIST (Национальный институт стандартов и технологий США, прим. пер.) запустил Privacy Engineering Collaboration Space — площадку для сотрудничества, на которой собраны open source-инструменты, а также решения и описания процессов, необходимых для проектирования конфиденциальности систем и риск-менеджмента. Как модераторы этого пространства, мы помогаем NIST собирать имеющиеся инструменты дифференциальной приватности в области анонимизации. NIST также опубликовал работу «Privacy Framework: A Tool for Improving Privacy through Enterprise Risk Management» и план действий, описывающий ряд проблемных вопросов, связанных с приватностью данных, в том числе и анонимизацией. Сейчас мы хотим помочь Collaboration Space достичь поставленных в плане целей по анонимизации (де-идентификации). А в конечном счете — помочь NIST развить эту серию публикаций в более глубокое руководство по дифференциальной приватности.
Каждая статья будет начинаться с базовых концепций и примеров применения, чтобы помочь специалистам, — таким как владельцы бизнес-процессов или сотрудники, отвечающие за конфиденциальность данных, — узнать достаточно, чтобы начать представлять опасность (шутка). После рассмотрения основ мы разберём доступные инструменты и применяемые в них подходы, что будет полезно уже тем, кто работает над конкретными реализациями.
Мы начнем нашу первую статью с того, что опишем ключевые концепции и понятия дифференциальной приватности, которыми и будем пользоваться в последующих статьях.
Постановка задачи
Как можно изучить данные о населении, не затронув при этом её конкретных представителей? Давайте попробуем ответить на два вопроса:
- Как много людей живет в Вермонте (Vermont)?
- Как много людей с именем Джо Нир (Joe Near) живёт в Вермонте?
Первый вопрос касается свойства всего населения, а второй раскрывает информацию о конкретном человеке. Мы должны иметь возможность выяснить тенденции для всего населения, при этом не позволяя получить информацию о конкретном индивидууме.
Но как мы можем ответить на вопрос «сколько людей живет в Вермонте?» — который мы в дальнейшем будем называть «запрос» — при этом не ответив на второй вопрос «Как много людей с именем Джо Нир живёт в Вермонте?». Самое распространенное решение — деидентификация (или анонимизация), которое заключается в удалении всей идентифицирующей информации из набора данных (здесь и далее мы считаем, что в нашем датасете собрана информация по конкретным людям). Другой подход — разрешать только агрегирующие запросы, например, с вычислением среднего. К сожалению, сейчас мы уже знаем, что ни один из подходов не даёт необходимой защиты приватности. Анонимизированные данные являются целями атак, в ходе которых устанавливаются связи с другими базами данных. Агрегирование защищает приватность лишь тогда, когда размер группы, по которой выполняется выборка, достаточно велик. Но даже в таких случаях возможны успешные атаки [1, 2, 3, 4].
Дифференциальная приватность
Дифференциальная приватность [5, 6] — это математическое определение понятия «наличия приватности». Это не какой-то конкретный процесс, а, скорее, свойство, которым может обладать процесс. Например, можно рассчитать (доказать), что данный конкретный процесс удовлетворяет принципам дифференциальной приватности.
Попросту говоря, для каждого человека, чьи данные входят в анализируемый набор, дифференциальная приватность гарантирует, что результат анализа на дифференциальную приватность будет практически неотличим вне зависимости от того, есть ли ваши данные в наборе или нет. Анализ дифференциальной приватности часто называют механизмом, и мы обозначим его как
 .
.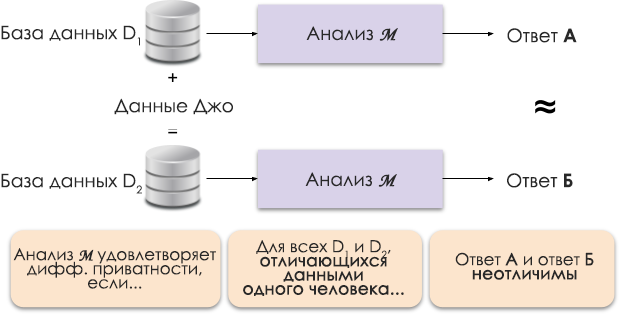
Рисунок 1: Схематичное представление дифференциальной приватности.
Принцип дифференциальной приватности показан на рисунке 1. Ответ А вычисляется без данных Джо, а ответ Б — с его данными. И утверждается, что оба ответа будут неразличимы. То есть кто бы ни посмотрел на результаты, он не сможет сказать, в каком случае использовались данные Джо, а в каком не использовались.
Мы контролируем требуемый уровень приватности через изменение параметра приватности ε, который также называют потерей приватности (privacy loss) или бюджетом приватности (privacy budget). Чем меньше значение ε, тем менее различимы результаты и тем больше защищены данные отдельных людей.
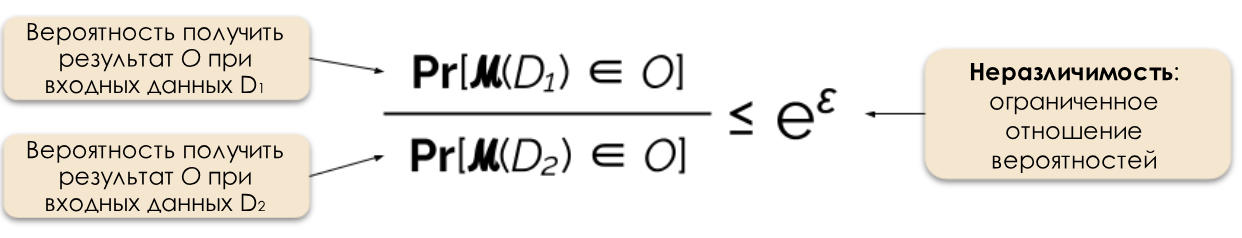
Рисунок 2: Формальное определение дифференциальной приватности.
Часто мы можем ответить на запрос с соблюдением дифференциальной приватности, добавляя случайный шум к ответу. Трудность заключается в определении, куда именно и сколько шума нужно добавлять. Один из самых популярных механизмов зашумления — механизм Лапласа [5, 7].
Запросы с повышенной конфиденциальностью требуют больше шума, чтобы удовлетворить конкретному значению «эпсилон» дифференциальной приватности. А этот дополнительный шум может снизить полезность полученных результатов. В будущих статьях мы подробнее расскажем о конфиденциальности и компромиссе между приватностью и полезностью.
Выгодные стороны дифференциальной приватности
Дифференциальная приватность имеет ряд важный преимуществ по сравнению с ранее использовавшимися техниками.
- Она предполагает, что абсолютно любая информация является идентифицирующей, избавляя нас от выполнения сложной (а иногда нерешаемой) задачи по определению всех идентифицирующих атрибутов в наборе данных.
- Она устойчива к атакам с использованием вспомогательной информации, то есть позволяет не допустить атаки с установлением взаимосвязей применительно к анонимизированным данным.
- Она композиционная: мы можем определить общую потерю приватности при выполнении двух дифференциально приватных операций анализа на одних и тех же данных, просто суммируя отдельные потери по каждой из них. Композиционность означает, что мы можем давать разумные гарантии касательно приватности даже при многократном анализе одних и тех же данных. Методики вроде анонимизации не являются композиционными, а многократные операции анализа могут приводить к катастрофической потере приватности.
Благодаря этим достоинствам применение методов дифференциальной приватности на практике предпочтительнее некоторых других методик. А обратной стороной медали является то, что эта методика довольно новая, и за пределами академического исследовательского сообщества не так просто найти проверенные инструменты, стандарты и отработанные подходы. Однако мы считаем, что в ближайшем будущем ситуация улучшится в связи растущим спросом на надёжные и простые решения по сохранению приватности данных.
Что дальше?
Подпишитесь на наш блог, и уже совсем скоро мы выложим перевод следующей статьи, рассказывающей про модели угроз, которые необходимо учитывать при построении систем для дифференциальной приватности, а также расскажем о различиях между центральной и локальной моделями дифференциальной приватности.
Источники
[1] Garfinkel, Simson, John M. Abowd, and Christian Martindale. «Understanding database reconstruction attacks on public data.» Communications of the ACM 62.3 (2019): 46-53.
[2] Gadotti, Andrea, et al. «When the signal is in the noise: exploiting diffix's sticky noise.» 28th USENIX Security Symposium (USENIX Security 19). 2019.
[3] Dinur, Irit, and Kobbi Nissim. «Revealing information while preserving privacy.» Proceedings of the twenty-second ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems. 2003.
[4] Sweeney, Latanya. «Simple demographics often identify people uniquely.» Health (San Francisco) 671 (2000): 1-34.
[5] Dwork, Cynthia, et al. «Calibrating noise to sensitivity in private data analysis.» Theory of cryptography conference. Springer, Berlin, Heidelberg, 2006.
[6] Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O'Brien, Thomas Steinke, and Salil Vadhan. «Differential privacy: A primer for a non-technical audience.» Vand. J. Ent. & Tech. L. 21 (2018): 209.
[7] Dwork, Cynthia, and Aaron Roth. «The algorithmic foundations of differential privacy.» Foundations and Trends in Theoretical Computer Science 9, no. 3-4 (2014): 211-407.
