Перевод статьи подготовлен специально для студентов курса «MS SQL Server Developer».

Вычисляемые столбцы могут стать причиной сложнодиагностируемых проблем с производительностью. В этой статье рассматривается ряд проблем и некоторые способы их решения.
Вычисляемые столбцы представляют собой удобный способ для встраивания вычислений в определения таблиц. Но они могут быть причиной проблем с производительностью, особенно когда выражения усложняются, приложения становятся более требовательными, а объемы данных непрерывно увеличиваются.
Вычисляемый столбец — это виртуальный столбец, значение которого вычисляется на основе значений в других столбцах таблицы. По умолчанию вычисленное значение физически не сохраняется, а вместо этого SQL Server вычисляет его при каждом запросе столбца. Это увеличивает нагрузку на процессор, но уменьшает объем данных, которые необходимо сохранять при изменении таблицы.
Часто несохраняемые (non-persistent) вычисляемые столбцы создают большую нагрузку на процессор, что приводит к замедлению запросов и зависанию приложений. К счастью, SQL Server предоставляет несколько способов улучшения производительности вычисляемых столбцов. Можно создавать сохраняемые (persisted) вычисляемые столбцы, индексировать их или делать и то и другое.
Для демонстрации я создал четыре похожие таблицы и заполнил их идентичными данными, полученными из демонстрационной базы данных WideWorldImporters. В каждой таблице есть одинаковый вычисляемый столбец, но в двух таблицах он сохраняемый, а в двух — с индексом. В результате получаются следующие варианты:
Вычисляемое выражение довольно простое, а набор данных очень мал. Тем не менее этого должно быть достаточно для демонстрации принципов сохраняемых и индексированных вычисляемых столбцов и того, как это помогает в решении проблем, связанных с производительностью.
Возможно, в вашей ситуации вам могут понадобиться несохраняемые вычисляемые столбцы, чтобы избежать хранения данных, создания индексов или для использования с недетерминированным столбцом. Например, SQL Server будет воспринимать скалярную пользовательскую функцию как недетерминированную, если в определении функции отсутствует WITH SCHEMABINDING. Если попытаться создать сохраняемый вычисляемый столбец с помощью такой функции, то будет ошибка, что сохраняемый столбец не может быть создан.
Однако следует отметить, что пользовательские функции могут создать свои проблемы с производительностью. Если таблица содержит вычисляемый столбец с функцией, то Query Engine не будет использовать параллелизм (только если вы не используете SQL Server 2019). Даже в ситуации, если вычисляемый столбец не указан в запросе. Для большого набора данных это может сильно влиять на производительность. Функции также могут замедлять выполнение UPDATE и влиять на то, как оптимизатор вычисляет стоимость запроса к вычисляемому столбцу. Это не значит, что вы никогда не должны использовать функции в вычисляемом столбце, но определенно к этому следует относиться с осторожностью.
Независимо от того, используете вы функции или нет, создание несохраняемого вычисляемого столбца довольно просто. Следующая инструкция
Чтобы определить вычисляемый столбец, укажите его имя с последующим ключевым словом AS и выражением. В нашем примере мы умножаем
Этот запрос должен вернуть 22 973 строки или все строки, которые есть у вас в базе данных WideWorldImporters. План выполнения этого запроса показан на рисунке 1.

Рисунок 1. План выполнения запроса к таблице Orders1
Первое, что следует отметить — это сканирование кластерного индекса (Clustered Index Scan), что не является эффективным способом получения данных. Но это не единственная проблема. Давайте посмотрим на количество логических чтений (Actual Logical Reads) в свойствах Clustered Index Scan (см. рисунок 2).

Рисунок 2. Логические чтения для запроса к таблице Orders1
Количество логических чтений (в данном случае 1108) — это количество страниц, которые прочитаны из кэша данных. Цель состоит в том, чтобы попытаться максимально уменьшить это число. Поэтому полезно его запомнить и сравнить с другими вариантами.
Количество логических чтений можно также получить, запустив инструкцию
Еще один момент, на который стоит обратить внимание — в плане выполнения присутствуют два оператора Compute Scalar. Первый (тот, что справа) — это вычисление значения вычисляемого столбца для каждой возвращаемой строки. Поскольку значения столбцов вычисляются на лету, вы не можете избежать этого шага с несохраняемыми вычисляемыми столбцами, если только не создадите индекс на этом столбце.
В некоторых случаях несохраняемый вычисляемый столбец обеспечивает необходимую производительность без его сохранения или использования индекса. Это не только экономит место для хранения, но также позволяет избежать накладных расходов, связанных с обновлением вычисляемых значений в таблице или в индексе. Однако чаще всего несохраняемый вычисляемый столбец приводит к проблемам с производительностью, и тогда вам стоит начать искать альтернативу.
Один из методов, часто используемых для решения проблем с производительностью, — это определение вычисляемого столбца как сохраняемого (persisted). При таком подходе выражение вычисляется заранее и результат сохраняется вместе с остальными данными таблицы.
Чтобы столбец можно было сделать сохраняемым, он должен быть детерминированным, то есть выражение должно всегда возвращать один и тот же результат при одинаковых входных данных. Например, вы не можете использовать функцию GETDATE в выражении столбца, потому что возвращаемое значение всегда изменяется.
Чтобы создать сохраняемый вычисляемый столбец, необходимо добавить к определению столбца ключевое слово
Таблица
На рисунке 3 показан результат выполнения этой хранимой процедуры. Объем данных в таблице

Рисунок 3. Сравнение размера таблиц Orders1 и Orders2
Хотя эти примеры основаны на довольно небольшом наборе данных, но вы можете видеть, как количество хранимых данных может быстро увеличиваться. Тем не менее это может быть компромиссом, если производительность улучшается.
Чтобы посмотреть разницу в производительности, выполните следующий SELECT.
Это тот же SELECT, который я использовал для таблицы Orders1 (за исключением изменения имени). На рисунке 4 показан план выполнения.

Рисунок 4. План выполнения запроса к таблице Orders2
Здесь также все начинается с Clustered Index Scan. Но на этот раз, есть только один оператор Compute Scalar, потому что вычисляемые столбцы больше не нужно вычислять во время выполнения. В общем случае чем меньше шагов, тем лучше. Хотя это и далеко не всегда так.
Второй запрос генерирует 1593 логических чтения, что на 485 больше по сравнению с 1108 чтений для первой таблицы. Несмотря на это, он выполняется быстрее, чем первый. Хотя и только примерно на 100 мс, а иногда и намного меньше. Процессорное время также уменьшилось, но тоже не на много. Скорее всего, разница была бы гораздо больше на больших объемах и более сложных вычислениях.
Другой метод, который обычно используется для улучшения производительности вычисляемого столбца, — это индексирование. Для возможности создания индекса столбец должен быть детерминированным и точным, что означает, что выражение не может использовать типы float и real (если столбец несохраняемый). Существуют также ограничения и для других типов данных, а также на параметры SET. Полный перечень ограничений см. в документации SQL Server Indexes on Computed Columns (Индексы на вычисляемых столбцов).
Проверить подходит ли несохраняемый вычисляемый столбец для индексирования можно через его свойства. Для просмотра свойств воспользуемся функцией
Оператор SELECT должен возвращать значение 1 для каждого свойства, чтобы вычисляемый столбец мог быть проиндексирован (см. рисунок 5).
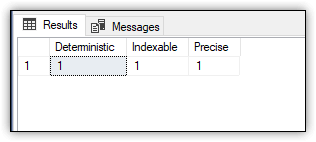
Рисунок 5. Проверка возможности создания индекса
После проверки вы можете создать некластерный индекс. Вместо изменения таблицы
Я создал некластерный покрывающий индекс, который включает оба столбца
На рисунке 6 показан план выполнения этого запроса, который теперь использует некластерный индекс ix_cost3 (Index Seek), а не выполняет сканирование кластерного индекса.
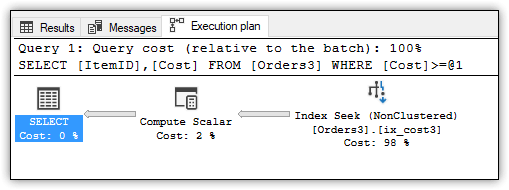
Рисунок 6. План выполнения запроса к таблице Orders3
Если вы посмотрите свойства оператора Index Seek, то обнаружите, что запрос теперь выполняет только 92 логических чтения, а в свойствах оператора SELECT увидите, что процессорное и общее время стало меньше. Разница несущественная, но, опять же, здесь небольшой набор данных.
Следует также отметить, что в плане выполнения присутствует только один оператор Compute Scalar, а не два, как было в первом запросе. Поскольку вычисляемый столбец проиндексирован, то значения уже вычислены. Это устраняет необходимость вычисления значений во время выполнения, даже если столбец не был определен как сохраняемый.
Вы также можете создать индекс для сохраняемого вычисляемого столбца. Хотя это приведет к хранению дополнительных данных и данных индекса, но в некоторых случаях может быть полезно. Например, вы можете создать индекс для сохраняемого вычисляемого столбца, даже если он использует типы данных float или real. Этот подход также может быть полезен при работе с функциями CLR, и когда нельзя проверить, являются ли функции детерминированными.
Следующая инструкция
После того как таблица и индекс созданы и заполнены, выполним SELECT.
На рисунке 7 показан план выполнения. Как и в предыдущем примере, запрос начинается с поиска по некластерному индексу (Index Seek).
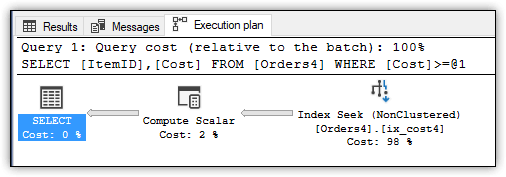
Рисунок 7. План выполнения запроса к таблице Orders4
Этот запрос также выполняет только 92 логических чтения, как и предыдущий, что приводит к примерно аналогичной производительности. Основное различие между этими двумя вычисляемыми столбцами, а также между индексированными и неиндексированными столбцами заключается в объеме используемого пространства. Проверим это, запустив хранимую процедуру
Результаты показаны на рисунке 8. Как и ожидалось, в сохраняемых вычисляемых столбцах больше объем данных, а в индексированных — больше объем индексов.
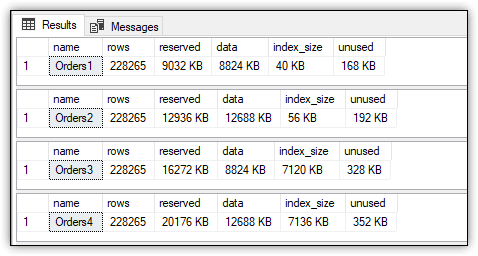
Рисунок 8. Сравнение использования пространства для всех четырех таблиц
Скорее всего, вам не нужно будет индексировать сохраняемые вычисляемые столбцы без веской на то причины. Как и в случаях с другими вопросами, связанными с базами данных, ваш выбор должен основываться на вашей конкретной ситуации: на ваших запросах и характере ваших данных.
Вычисляемый столбец не является обычным столбцом таблицы, и с ним следует обращаться с осторожностью, чтобы не ухудшить производительность. Большинство проблем с производительностью можно решить через сохранение или индексацию столбца, но в обоих подходах необходимо учитывать дополнительное дисковое пространство и то, как изменяются данные. При изменении данных значения вычисляемого столбца должны быть обновлены в таблице или индексе или в обоих местах, если вы проиндексировали сохраняемый вычисляемый столбец. Решить, какой из вариантов лучше подходит, можно только для вашего конкретного случая. И, скорее всего, вам придется использовать все варианты.


Вычисляемые столбцы могут стать причиной сложнодиагностируемых проблем с производительностью. В этой статье рассматривается ряд проблем и некоторые способы их решения.
Вычисляемые столбцы представляют собой удобный способ для встраивания вычислений в определения таблиц. Но они могут быть причиной проблем с производительностью, особенно когда выражения усложняются, приложения становятся более требовательными, а объемы данных непрерывно увеличиваются.
Вычисляемый столбец — это виртуальный столбец, значение которого вычисляется на основе значений в других столбцах таблицы. По умолчанию вычисленное значение физически не сохраняется, а вместо этого SQL Server вычисляет его при каждом запросе столбца. Это увеличивает нагрузку на процессор, но уменьшает объем данных, которые необходимо сохранять при изменении таблицы.
Часто несохраняемые (non-persistent) вычисляемые столбцы создают большую нагрузку на процессор, что приводит к замедлению запросов и зависанию приложений. К счастью, SQL Server предоставляет несколько способов улучшения производительности вычисляемых столбцов. Можно создавать сохраняемые (persisted) вычисляемые столбцы, индексировать их или делать и то и другое.
Для демонстрации я создал четыре похожие таблицы и заполнил их идентичными данными, полученными из демонстрационной базы данных WideWorldImporters. В каждой таблице есть одинаковый вычисляемый столбец, но в двух таблицах он сохраняемый, а в двух — с индексом. В результате получаются следующие варианты:
- Таблица
Orders1— несохраняемый вычисляемый столбец. - Таблица
Orders2— сохраняемый вычисляемый столбец. - Таблица
Orders3— несохраняемый вычисляемый столбец с индексом. - Таблица
Orders4— сохраняемый вычисляемый столбец с индексом.
Вычисляемое выражение довольно простое, а набор данных очень мал. Тем не менее этого должно быть достаточно для демонстрации принципов сохраняемых и индексированных вычисляемых столбцов и того, как это помогает в решении проблем, связанных с производительностью.
Несохраняемый вычисляемый столбец
Возможно, в вашей ситуации вам могут понадобиться несохраняемые вычисляемые столбцы, чтобы избежать хранения данных, создания индексов или для использования с недетерминированным столбцом. Например, SQL Server будет воспринимать скалярную пользовательскую функцию как недетерминированную, если в определении функции отсутствует WITH SCHEMABINDING. Если попытаться создать сохраняемый вычисляемый столбец с помощью такой функции, то будет ошибка, что сохраняемый столбец не может быть создан.
Однако следует отметить, что пользовательские функции могут создать свои проблемы с производительностью. Если таблица содержит вычисляемый столбец с функцией, то Query Engine не будет использовать параллелизм (только если вы не используете SQL Server 2019). Даже в ситуации, если вычисляемый столбец не указан в запросе. Для большого набора данных это может сильно влиять на производительность. Функции также могут замедлять выполнение UPDATE и влиять на то, как оптимизатор вычисляет стоимость запроса к вычисляемому столбцу. Это не значит, что вы никогда не должны использовать функции в вычисляемом столбце, но определенно к этому следует относиться с осторожностью.
Независимо от того, используете вы функции или нет, создание несохраняемого вычисляемого столбца довольно просто. Следующая инструкция
CREATE TABLE определяет таблицу Orders1, которая включает в себя вычисляемый столбец Cost.USE WideWorldImporters;
GO
DROP TABLE IF EXISTS Orders1;
GO
CREATE TABLE Orders1(
LineID int IDENTITY PRIMARY KEY,
ItemID int NOT NULL,
Quantity int NOT NULL,
Price decimal(18, 2) NOT NULL,
Profit decimal(18, 2) NOT NULL,
Cost AS (Quantity * Price - Profit));
INSERT INTO Orders1 (ItemID, Quantity, Price, Profit)
SELECT StockItemID, Quantity, UnitPrice, LineProfit
FROM Sales.InvoiceLines
WHERE UnitPrice IS NOT NULL
ORDER BY InvoiceLineID;Чтобы определить вычисляемый столбец, укажите его имя с последующим ключевым словом AS и выражением. В нашем примере мы умножаем
Quantity на Price и вычитаем Profit. После создания таблицы заполняем ее с помощью INSERT, используя данные из таблицы Sales.InvoiceLines базы данных WideWorldImporters. Далее выполняем SELECT.SELECT ItemID, Cost FROM Orders1 WHERE Cost >= 1000;Этот запрос должен вернуть 22 973 строки или все строки, которые есть у вас в базе данных WideWorldImporters. План выполнения этого запроса показан на рисунке 1.

Рисунок 1. План выполнения запроса к таблице Orders1
Первое, что следует отметить — это сканирование кластерного индекса (Clustered Index Scan), что не является эффективным способом получения данных. Но это не единственная проблема. Давайте посмотрим на количество логических чтений (Actual Logical Reads) в свойствах Clustered Index Scan (см. рисунок 2).

Рисунок 2. Логические чтения для запроса к таблице Orders1
Количество логических чтений (в данном случае 1108) — это количество страниц, которые прочитаны из кэша данных. Цель состоит в том, чтобы попытаться максимально уменьшить это число. Поэтому полезно его запомнить и сравнить с другими вариантами.
Количество логических чтений можно также получить, запустив инструкцию
SET STATISTICS IO ON перед выполнением SELECT. Для просмотра процессорного и общего времени — SET STATISTICS TIME ON или посмотреть свойства оператора SELECT в плане выполнения запроса.Еще один момент, на который стоит обратить внимание — в плане выполнения присутствуют два оператора Compute Scalar. Первый (тот, что справа) — это вычисление значения вычисляемого столбца для каждой возвращаемой строки. Поскольку значения столбцов вычисляются на лету, вы не можете избежать этого шага с несохраняемыми вычисляемыми столбцами, если только не создадите индекс на этом столбце.
В некоторых случаях несохраняемый вычисляемый столбец обеспечивает необходимую производительность без его сохранения или использования индекса. Это не только экономит место для хранения, но также позволяет избежать накладных расходов, связанных с обновлением вычисляемых значений в таблице или в индексе. Однако чаще всего несохраняемый вычисляемый столбец приводит к проблемам с производительностью, и тогда вам стоит начать искать альтернативу.
Сохраняемый вычисляемый столбец
Один из методов, часто используемых для решения проблем с производительностью, — это определение вычисляемого столбца как сохраняемого (persisted). При таком подходе выражение вычисляется заранее и результат сохраняется вместе с остальными данными таблицы.
Чтобы столбец можно было сделать сохраняемым, он должен быть детерминированным, то есть выражение должно всегда возвращать один и тот же результат при одинаковых входных данных. Например, вы не можете использовать функцию GETDATE в выражении столбца, потому что возвращаемое значение всегда изменяется.
Чтобы создать сохраняемый вычисляемый столбец, необходимо добавить к определению столбца ключевое слово
PERSISTED, как показано в следующем примере.DROP TABLE IF EXISTS Orders2;
GO
CREATE TABLE Orders2(
LineID int IDENTITY PRIMARY KEY,
ItemID int NOT NULL,
Quantity int NOT NULL,
Price decimal(18, 2) NOT NULL,
Profit decimal(18, 2) NOT NULL,
Cost AS (Quantity * Price - Profit) PERSISTED);
INSERT INTO Orders2 (ItemID, Quantity, Price, Profit)
SELECT StockItemID, Quantity, UnitPrice, LineProfit
FROM Sales.InvoiceLines
WHERE UnitPrice IS NOT NULL
ORDER BY InvoiceLineID;Таблица
Orders2 практически идентична таблице Orders1, за исключением того, что столбец Cost содержит ключевое слово PERSISTED. SQL Server автоматически заполняет этот столбец при добавлении и изменении строк. Конечно, это означает, что таблица Orders2 будет занимать больше места, чем таблица Orders1. Это можно проверить с помощью хранимой процедуры sp_spaceused.sp_spaceused 'Orders1';
GO
sp_spaceused 'Orders2';
GOНа рисунке 3 показан результат выполнения этой хранимой процедуры. Объем данных в таблице
Orders1 составляет 8 824 КБ, а в таблице Orders2 — 12 936 КБ. На 4 112 КБ больше, что необходимо для хранения вычисленных значений. 
Рисунок 3. Сравнение размера таблиц Orders1 и Orders2
Хотя эти примеры основаны на довольно небольшом наборе данных, но вы можете видеть, как количество хранимых данных может быстро увеличиваться. Тем не менее это может быть компромиссом, если производительность улучшается.
Чтобы посмотреть разницу в производительности, выполните следующий SELECT.
SELECT ItemID, Cost FROM Orders2 WHERE Cost >= 1000;Это тот же SELECT, который я использовал для таблицы Orders1 (за исключением изменения имени). На рисунке 4 показан план выполнения.

Рисунок 4. План выполнения запроса к таблице Orders2
Здесь также все начинается с Clustered Index Scan. Но на этот раз, есть только один оператор Compute Scalar, потому что вычисляемые столбцы больше не нужно вычислять во время выполнения. В общем случае чем меньше шагов, тем лучше. Хотя это и далеко не всегда так.
Второй запрос генерирует 1593 логических чтения, что на 485 больше по сравнению с 1108 чтений для первой таблицы. Несмотря на это, он выполняется быстрее, чем первый. Хотя и только примерно на 100 мс, а иногда и намного меньше. Процессорное время также уменьшилось, но тоже не на много. Скорее всего, разница была бы гораздо больше на больших объемах и более сложных вычислениях.
Индекс на несохраняемом вычисляемом столбце
Другой метод, который обычно используется для улучшения производительности вычисляемого столбца, — это индексирование. Для возможности создания индекса столбец должен быть детерминированным и точным, что означает, что выражение не может использовать типы float и real (если столбец несохраняемый). Существуют также ограничения и для других типов данных, а также на параметры SET. Полный перечень ограничений см. в документации SQL Server Indexes on Computed Columns (Индексы на вычисляемых столбцов).
Проверить подходит ли несохраняемый вычисляемый столбец для индексирования можно через его свойства. Для просмотра свойств воспользуемся функцией
COLUMNPROPERTY. Нам важны свойства IsDeterministic, IsIndexable и IsPrecise.DECLARE @id int = OBJECT_ID('dbo.Orders1')
SELECT
COLUMNPROPERTY(@id,'Cost','IsDeterministic') AS 'Deterministic',
COLUMNPROPERTY(@id,'Cost','IsIndexable') AS 'Indexable',
COLUMNPROPERTY(@id,'Cost','IsPrecise') AS 'Precise';Оператор SELECT должен возвращать значение 1 для каждого свойства, чтобы вычисляемый столбец мог быть проиндексирован (см. рисунок 5).

Рисунок 5. Проверка возможности создания индекса
После проверки вы можете создать некластерный индекс. Вместо изменения таблицы
Orders1 я создал третью таблицу (Orders3) и включил индекс в определение таблицы.DROP TABLE IF EXISTS Orders3;
GO
CREATE TABLE Orders3(
LineID int IDENTITY PRIMARY KEY,
ItemID int NOT NULL,
Quantity int NOT NULL,
Price decimal(18, 2) NOT NULL,
Profit decimal(18, 2) NOT NULL,
Cost AS (Quantity * Price - Profit),
INDEX ix_cost3 NONCLUSTERED (Cost, ItemID));
INSERT INTO Orders3 (ItemID, Quantity, Price, Profit)
SELECT StockItemID, Quantity, UnitPrice, LineProfit
FROM Sales.InvoiceLines
WHERE UnitPrice IS NOT NULL
ORDER BY InvoiceLineID;Я создал некластерный покрывающий индекс, который включает оба столбца
ItemID и Cost из запроса SELECT. После создания, заполнения таблицы и индекса можно выполнить следующую инструкцию SELECT, аналогичную предыдущим примерам.SELECT ItemID, Cost FROM Orders3 WHERE Cost >= 1000;На рисунке 6 показан план выполнения этого запроса, который теперь использует некластерный индекс ix_cost3 (Index Seek), а не выполняет сканирование кластерного индекса.

Рисунок 6. План выполнения запроса к таблице Orders3
Если вы посмотрите свойства оператора Index Seek, то обнаружите, что запрос теперь выполняет только 92 логических чтения, а в свойствах оператора SELECT увидите, что процессорное и общее время стало меньше. Разница несущественная, но, опять же, здесь небольшой набор данных.
Следует также отметить, что в плане выполнения присутствует только один оператор Compute Scalar, а не два, как было в первом запросе. Поскольку вычисляемый столбец проиндексирован, то значения уже вычислены. Это устраняет необходимость вычисления значений во время выполнения, даже если столбец не был определен как сохраняемый.
Индекс на сохраняемом столбце
Вы также можете создать индекс для сохраняемого вычисляемого столбца. Хотя это приведет к хранению дополнительных данных и данных индекса, но в некоторых случаях может быть полезно. Например, вы можете создать индекс для сохраняемого вычисляемого столбца, даже если он использует типы данных float или real. Этот подход также может быть полезен при работе с функциями CLR, и когда нельзя проверить, являются ли функции детерминированными.
Следующая инструкция
CREATE TABLE создает таблицу Orders4. Определение таблицы включает в себя как сохраняемый столбец Cost, так и некластерный покрывающий индекс ix_cost4.DROP TABLE IF EXISTS Orders4;
GO
CREATE TABLE Orders4(
LineID int IDENTITY PRIMARY KEY,
ItemID int NOT NULL,
Quantity int NOT NULL,
Price decimal(18, 2) NOT NULL,
Profit decimal(18, 2) NOT NULL,
Cost AS (Quantity * Price - Profit) PERSISTED,
INDEX ix_cost4 NONCLUSTERED (Cost, ItemID));
INSERT INTO Orders4 (ItemID, Quantity, Price, Profit)
SELECT StockItemID, Quantity, UnitPrice, LineProfit
FROM Sales.InvoiceLines
WHERE UnitPrice IS NOT NULL
ORDER BY InvoiceLineID;После того как таблица и индекс созданы и заполнены, выполним SELECT.
SELECT ItemID, Cost FROM Orders4 WHERE Cost >= 1000;На рисунке 7 показан план выполнения. Как и в предыдущем примере, запрос начинается с поиска по некластерному индексу (Index Seek).

Рисунок 7. План выполнения запроса к таблице Orders4
Этот запрос также выполняет только 92 логических чтения, как и предыдущий, что приводит к примерно аналогичной производительности. Основное различие между этими двумя вычисляемыми столбцами, а также между индексированными и неиндексированными столбцами заключается в объеме используемого пространства. Проверим это, запустив хранимую процедуру
sp_spaceused.sp_spaceused 'Orders1';
GO
sp_spaceused 'Orders2';
GO
sp_spaceused 'Orders3';
GO
sp_spaceused 'Orders4';
GOРезультаты показаны на рисунке 8. Как и ожидалось, в сохраняемых вычисляемых столбцах больше объем данных, а в индексированных — больше объем индексов.

Рисунок 8. Сравнение использования пространства для всех четырех таблиц
Скорее всего, вам не нужно будет индексировать сохраняемые вычисляемые столбцы без веской на то причины. Как и в случаях с другими вопросами, связанными с базами данных, ваш выбор должен основываться на вашей конкретной ситуации: на ваших запросах и характере ваших данных.
Работа с вычисляемыми столбцами в SQL Server
Вычисляемый столбец не является обычным столбцом таблицы, и с ним следует обращаться с осторожностью, чтобы не ухудшить производительность. Большинство проблем с производительностью можно решить через сохранение или индексацию столбца, но в обоих подходах необходимо учитывать дополнительное дисковое пространство и то, как изменяются данные. При изменении данных значения вычисляемого столбца должны быть обновлены в таблице или индексе или в обоих местах, если вы проиндексировали сохраняемый вычисляемый столбец. Решить, какой из вариантов лучше подходит, можно только для вашего конкретного случая. И, скорее всего, вам придется использовать все варианты.

Читать ещё
