
Всем привет. В предыдущих статьях мы говорили о базовых вещах оптимизации: раз и два. Сегодня я предлагаю с разбега окунуться в одну часть из тех задач, которыми занимается команда архитектуры фронтенда в hh.ru.
Я работаю в команде архитектуры. Мы не только перекладываем файлики из одной папки в другую, но и занимаемся кучей других вещей:
- Перфоманс приложения
- Инфраструктура: сборка, тесты, пайплайны, раскатка на продакшене, инструменты для разработчика (например бабель-плагины, кастомные eslint правила)
- Дизайн-система (UIKit)
- Переезд на новые технологии
Если покопаться, можно найти много интересного.
Поэтому, давайте поговорим о перфомансе. Команда фронтенд архитектуры ответственна как за клиентскую часть, так и серверную (SSR).
Я предлагаю посмотреть на метрики и разобраться, как мы реагируем на различные триггеры. Статья будет разбита на 2 составляющие. Серверную и клиентскую. Графики, код и кулстори прилагаются.

В этой статье мы поговорим о том, как трекаем, какие (интересные) результаты есть. Для теории и что-почем лучше обратиться к первой статье.
Клиент
Главная проблема клиентских метрик — устройства. Они разные, их очень много, как и систем, браузеров и качества соединения. На основе всех этих данных нужно строить какую-то информацию, которая будет поддаваться анализу.
Процесс построения правильных графиков был не единоразовым событием. Мы построили первую версию метрик. Осознали, что они не работают, провели работу над ошибками, перестроили. Повторили несколько раз для части метрик. В итоге сейчас мы трекаем:
FMP (first meaningful paint)

FMP трекается для двух частей сайта: меню и конец контента. Каждая линия — отдельная страница. На графики выводим TOP самых тяжелых страниц. Практически все наши графики отображают 95 перцентиль. Эти не стали исключением.
Тот же график, но с отображением только одной страницы:

Для нас FMP наиболее важный график и вот почему:
- Сайт hh.ru с точки зрения соискателя — текстовый. Открыть поиск, кликнуть на вакансию, прочитать, решить — ок или нет, откликнуться.
- С точки зрения работодателя — сайт частично текстовый. Открыть поиск или разобрать отклики — это работа с резюме кандидата.
Вопрос правильного измерения FMP — один из наиболее важных для нас. Что мы понимаем под FMP? Это количество и время загрузки критических для рендера ресурсов.
Кажется, что FMP может считаться как-то так:
requestAnimationFrame(function() {
// Перед первым рендером взяли время когда renderTree было сформировано
var renderTreeFormed = performance.now();
requestAnimationFrame(function() {
// Здесь данные отрендерены пользователю
var fmp = performance.now();
// Сохраняем для дальнейшей отправки на сервер
window.globalVars.performance.fmp.push({
renderTreeFormed: renderTreeFormed,
fmp: fmp
})
});
});Здесь есть несколько интересных моментов:
- Если вставить этот код после меню и перед закрытием body, то получаемые данные могут и будут отличаться (при условии, что у вас вся страница не умещается в 1 экран). Дело в том, что браузеры будут пытаться оптимизировать рендер.
- Это решение — не работает ¯(ツ)/¯
Дело в том, что браузер не будет вызывать raf и будет сильно замедлять вызовы setTimeout\interval когда вкладка не является активной. Поэтому мы получим некорректные данные.
Это означает, что в текущем решении нам нужно как-то обрабатывать этот случай. Здесь на помощь приходит PageVisibility API:
window.globalVars = window.globalVars || {};
window.globalVars.performance = window.globalVars.performance || {};
// Помечаем, была ли страница активна в момент загрузки
window.globalVars.performance.pageWasActive = document.visibilityState === "visible";
document.addEventListener("visibilitychange", function(e) {
// Если что-то изменилось — реагируем
if (document.visibilityState !== "visible") {
window.globalVars.performance.pageWasActive = false;
}
});Используем полученные знания в FMP:
requestAnimationFrame(function() {
// Перед первым рендером взяли время когда renderTree было сформировано
var renderTreeFormed = performance.now();
requestAnimationFrame(function() {
// Здесь данные отрендерены пользователю
var fmp = performance.now();
// Сохраняем для дальнейшей отправки на сервер,
// только в случае, если страница была все время активной
if (window.globalVars.performance.pageWasActive) {
window.globalVars.performance.fmp.push({
renderTreeFormed: renderTreeFormed,
fmp: fmp
});
}
});
});Окей, теперь мы не отправляем заведомо некорректные данные. Качество данных стало лучше.
Следующая проблема: один из популярнейших паттернов для наших пользователей — зайти на страницу поиска, нащелкать "открыть в новой вкладке" вакансий, а затем переключаться по вкладкам. Мы теряем очень много аналитики.
Нужна ли нам такая сложная структура, учитывая, что она теряет данные? На самом деле нет, нам важно определить, когда renderTree (почти) готова, чтобы понимать, загружены ли ресурсы и дошел ли браузер до конца меню, контента.
Поэтому мы решили задачу изящнее. В нужные места мы стали вставлять вот такие метки (и fmp_menu для меню):
<script>window.performance.mark('fmp_body')</script>На их основе мы и строим графики:

Такой способ удобен: мы всегда можем добавить новую контрольную точку и оптимизировать отображение вакансии, резюме и поисковой выдачи.
Несколько интересностей:
- На FMP у нас настроен триггер. Чтобы реагировать на массовые проблемы, он настроен на 3 минуты бесперебойных проблем. Поэтому "одиночные" выбросы просто игнорирует.
- Критический FMP: 10 секунд. В эти моменты мы смотрим на проблемные урлы и на выдаваемые нами данные.
- У нас было несколько интересных историй, когда FMP начинал зашкаливать. Часто эта метрика может коррелировать с массовыми проблемами с сетью у пользователей, а также с проблемами на наших бекендах. Метрика получилась очень чувствительной
- Если брать статистику, то мобильные телефоны получаются производительней настольных машин! Вот пример, на котором я взял время с большой нагрузкой в рабочий день и построил графики по одному url-у. Слева мобильники, справа десктопы, 95 перцентиль:
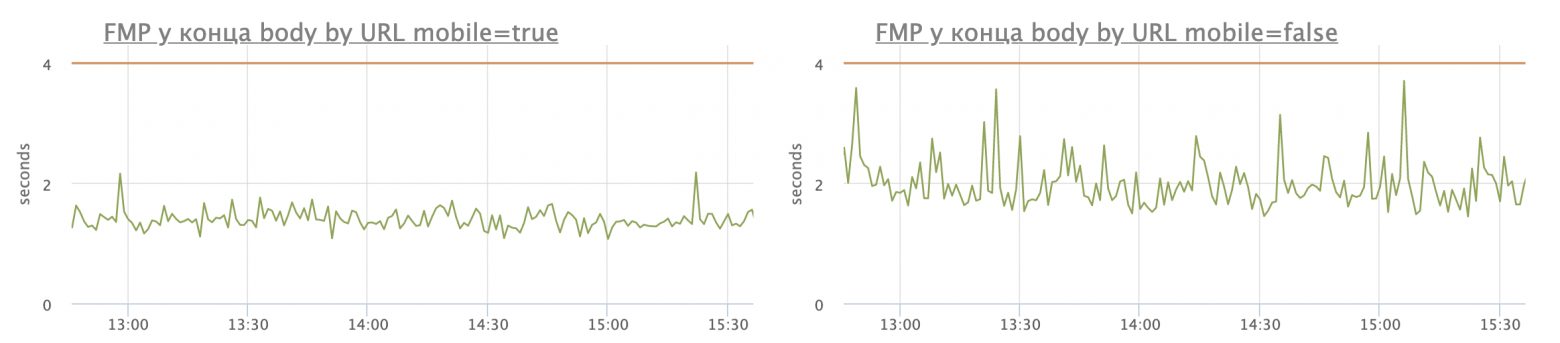

Разница незначительная, но она есть. Я лично склонен полагать, что телефоны люди обновляют чаще, чем компьютеры.
Вторая метрика TTI
В целом, для работы с TTI более чем достаточно взять готовый код у гугла
У нас для вычисления TTI свой велосипед. Он нам нужен, потому что мы завязываемся внутри на Page Visibility API, о котором я писал выше. К сожалению, TTI полностью завязан на longtask и у нас нет опции "посчитать его как-нибудь по-другому", поэтому мы вырезаем пласт метрик, когда пользователь уходит со страницы.
function timeToInteractive() {
// Ожидаемое время TTI
const LONG_TASK_TIME = 2000;
// Максимально ожидаемое время TTI, если не произошло лонгтасок
const MAX_LONG_TASK_TIME = 30000;
const metrics = {
report: 'TTI_WITH_VISIBILITY_API',
mobile: Supports.mobile(),
};
if ('PerformanceObserver' in window && 'PerformanceLongTaskTiming' in window) {
let timeoutIdCheckTTI;
const longTask = [];
const observer = new window.PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
longTask.push(Math.round(entry.startTime + entry.duration));
}
});
observer.observe({ entryTypes: ['longtask'] });
const checkTTI = () => {
if (longTask.length === 0 && performance.now() > MAX_LONG_TASK_TIME) {
clearTimeout(timeoutIdCheckTTI);
}
const eventTime = longTask[longTask.length - 1];
if (eventTime && performance.now() - eventTime >= LONG_TASK_TIME) {
if (window.globalVars?.performance?.pageWasActive) {
StatsSender.sendMetrics({ ...metrics, tti: eventTime });
}
} else {
timeoutIdCheckTTI = setTimeout(checkTTI, LONG_TASK_TIME);
}
};
checkTTI();
}
}
export default timeToInteractive;Выглядит TTI вот так (95", TOP тяжелых урлов):

Может появиться вопрос: почему TTI такой большой? Дело в:
- Рекламе, которая грузится по requestIdleCallback
- Аналитике
- 3d party скриптах
К сожалению, "обстоятельства сильнее нас". Поэтому для аналитики своего кода приходится выкручиваться и мы используем еще немного метрик:
Время инита приложения без гидрейта (рендера)
95" TOP тяжеленьких:

Зачем? Мы понимаем, как много JS кода мы грузим и сколько времени нужно, чтобы он проинитился.
По этому графику мы понимаем, какие страницы наиболее загружены js кодом, при больших выбросах во время релизов, можно сказать, где сломались чанки приложения.
Но самым показательным для нас на клиенте в плане JS рантайма является
Гидрейт
Замеряем время по окончанию инита без рендера, делаем hydrate, который принимает третьим аргументом колбек, в колбеке замеряем еще раз время и сохраняем разницу:

Если совместить график инита и гидрейта, можем сделать несколько выводов:
- Если самая тяжелая страница в гидрейте и ините одинаковая, то её тяжесть обоснована огромным количеством разных компонентов и логики, а не данных (большим списком резюме \ вакансий, чем-то еще)
- Если график гидрейта не коррелирует с графиком инита — проблема в количестве данных для рендера. Здесь выделяются графики поисковых страниц, они сильнее зависят от тяжести данных для рендера:


Чем помогают эти графики?
- Как только видим всплеск в FMP, идем в остальные графики клиента и смотрим, увеличилось ли время гидрейта или инита. Они дают понять, была ли проблема с клиентом или нужно смотреть на сеть, SSR и бэкенды.
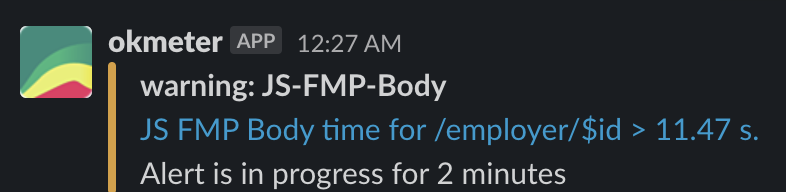
- Триггеры позволяют понимать, когда были проблемы во время релизов. На моей памяти это было лишь однажды. Статика крайне редко ломает релизы настолько сильно.

LongTasks
PerformanceObserver позволяет трекать тяжелые таски у пользователей:

История появления данного графика занятна:
Весна, поют птички, приходят разработчики в офис (да, это не 2020!). Прилетает сообщение от техподдержки: сайт не работает! Разработчики быстро просыпаются и пытаются воспроизвести проблему. Количество обращений растет.
Выясняется довольно занятная штука: поставщик рекламы добавил новый баннер с кормом для собак, где блокирующий js постоянно вызывал reflow, который надежно убивал event loop ровно на 30 секунд.
В общем, владельцы собак пострадали. К сожалению, в то время в команде архитектуры владельцев собак не было. Сейчас не проверяли, не довелось ;)
Из этой истории мы вынесли 2 урока:
- Решить, что сделать с рекламой
- Трекать Longtasks. Сказано — сделано.
Что еще?
Это не все графики, которые мы строим для клиента. У нас есть время инициализации не реакт-компонентов, на старых страницах, rate ошибок в сентри + триггер, чтобы быстро реагировать при проблемах, FID. Но они практически не использовались нами в аналитике.
С клиентом разобрались, переходим к серверу.
Сервер и кулстори
Здесь все намного проще. Сервер — это наше игровое поле. Мы его контролируем, мы знаем окружение и что на него может повлиять.
Что самое важное для серверов? Нагрузка, время ответа и понимание на что это время потратили.
У нас огромное количество графиков, которые трекают память, CPU, диски — массу всего. Остановимся на специфичном и наиболее часто используемом нашей командой для SSR. Вот так выглядят наши серверные графики:
График запросов и ошибок

График времени ответа http клиента

Каждая линия — отдельный урл, здесь TOP наиболее проблемных урлов. Все триггеры настроены на 95 перцентиль. На графике мы видим, что был некий всплеск в 12:10 и затем одному урлу стало не очень хорошо в 12:40. На этих графиках "криминала нет", но как только потолок в 400мс пробивается, в это время зажигается триггер и один человек из команды бодро марширует во внутренние сервисы с логами, кибану и разбирает "что это было". Также локализовать проблему помогают дополнительные графики:
Время рендера и парcинг

Здесь уже видно, что первая проблема коррелирует с увеличением parse time.
Копаем дальше и видим график утилизации CPU. Здесь дискотека:
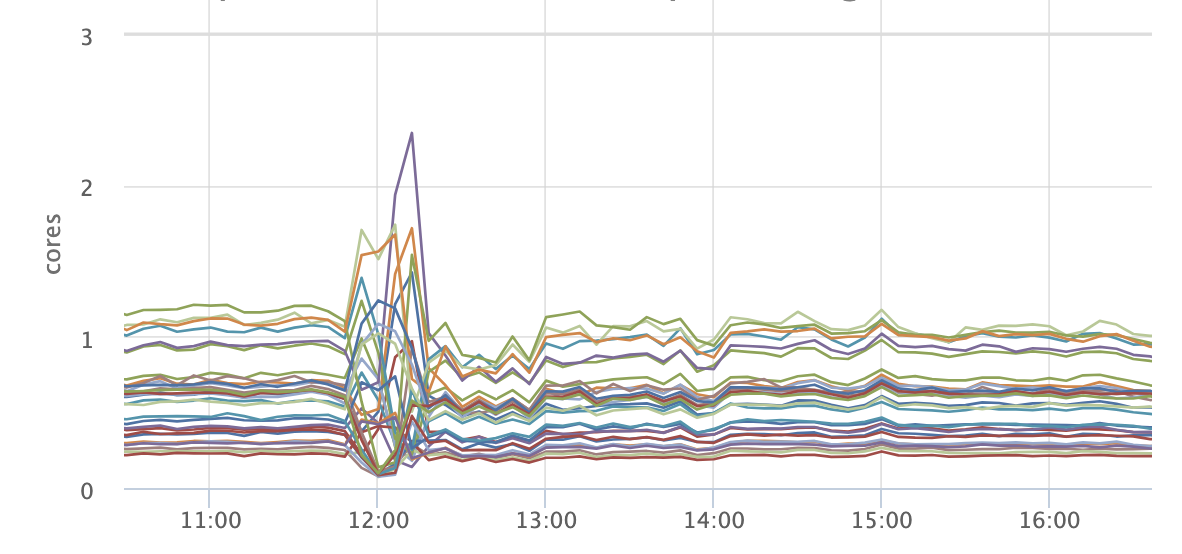
Это поведение характерно, когда происходит релиз сервиса. Каждый сервис у нас релизится как минимум 1 раз в день. Обычно чаще.
Причина первого скачка на графике становится довольно понятной: у нас был релиз. В 12 часов нагрузка на сервис достаточно высокая, поэтому на часть инстансов прилетело больше запросов. Но все равно это порядка 150мс, до 400мс еще далеко.
Бывает другая ситуация. Собственно тот случай и сподвиг меня написать эту статью. Пятница, утро, вместо кофе видишь в slack зажегшийся триггер:
Одному из урлов надоело жить.
В то же время render и parse time чувствуют себя отлично:
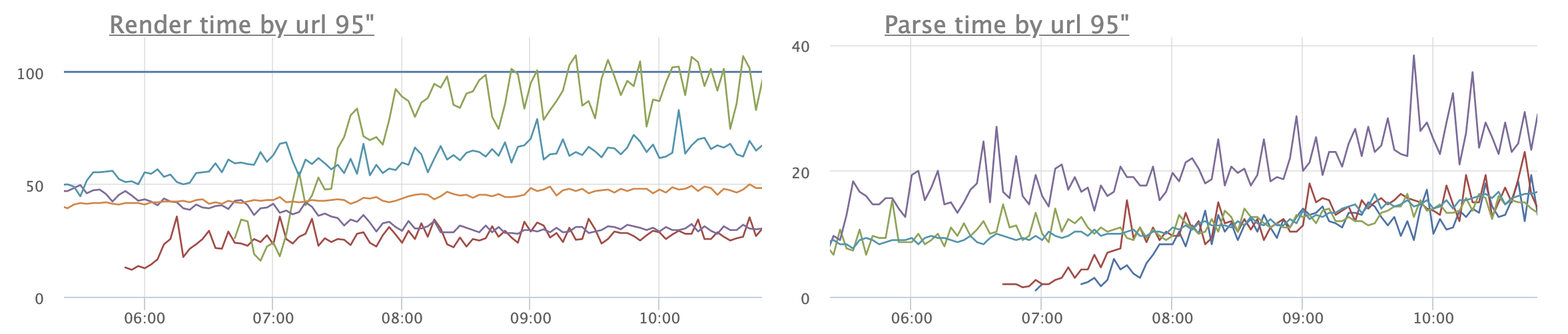
На графике видно, что количество ошибок увеличивается:
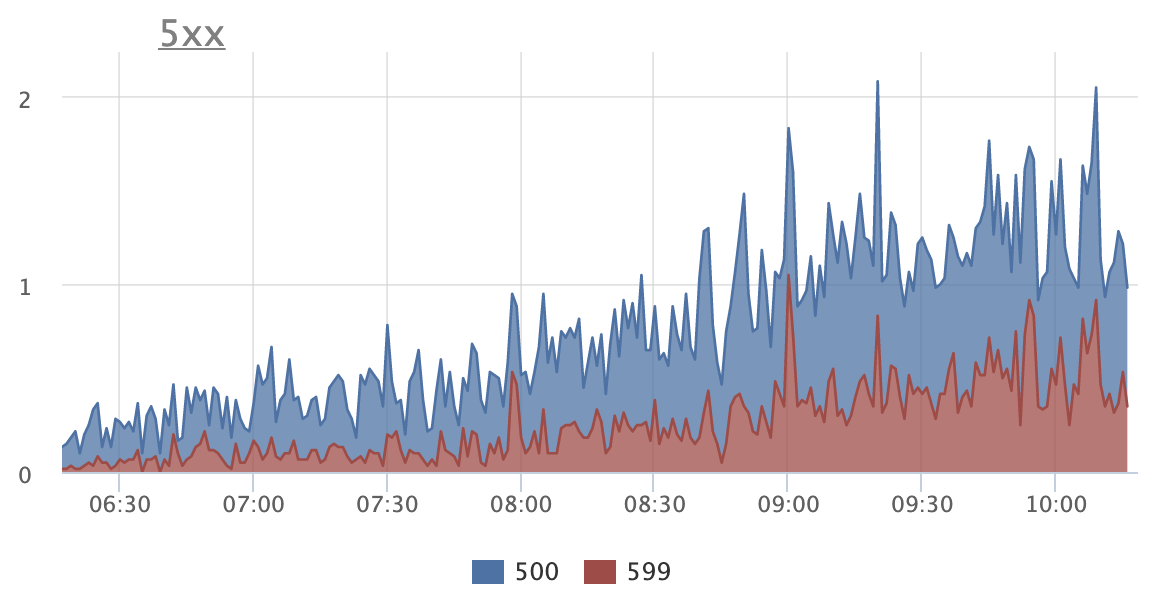
Грепаем логи, из них извлекаем ошибку
TypeError: Cannot read property 'map' of undefined
at Social (at path/to/module)Кажется, сервер стал асоциальным.
Проблема локализована, хотфикс выпущен, графики стабилизируются, кофе остыл:

И еще один пример, когда parse time имеет значение:
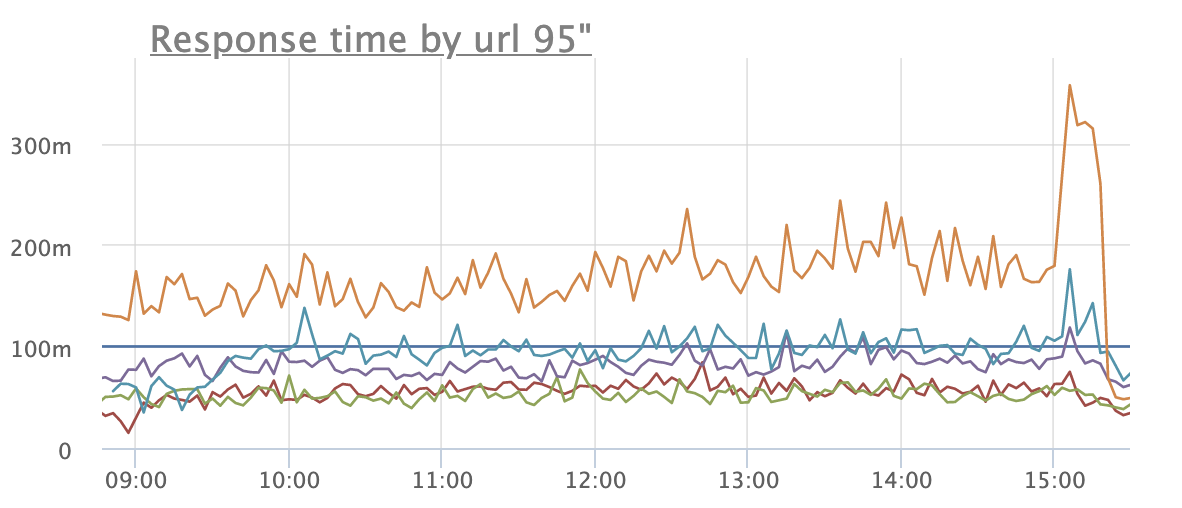
Видим постепенно растущий график времени ответа сервиса. Но время рендера совсем не растет. А время парсинга наоборот крайне подозрительно коррелирует с временем ответа:

У нас SSR работает as a service. То есть у нас BFF, которая ходит в наш node.js сервис, для рендера данных. Сама BFF написана на питоне.
Подобная корреляция между временем ответа, парсингом и полным отсутствием влияния на время рендера возможна, как мне кажется, только в одном случае: BFF посылает с каждым разом все больше и больше данных, которые никак не используются node.js. По простому — BFF дала течь. Сервис правится, ситуация разруливается.
Сама протечка получилась небольшой и на графиках используемой памяти в BFF это было практически незаметно. А вот на времени ответов \ парсинге это сказалось отрицательно.
Мораль
Сей басни такова:
На сервере достаточно легко вычислять корреляции и предпринимать правильные шаги. Это мы разобрали на примерах.
Чем больше информации вы трекаете, тем проще понимать что происходит.
С первого взгляда, на клиенте должно работать тоже самое. Но там все сильно сложнее. Чего стоит только пример с FMP. Кроме этого почти все клиенские графики, имеют выбросы, достаточно сложно поддаются аналитике, мы не знаем всех условий, в котором находится наш пользователь. Однако аналитика по-прежнему возможна. Мы можем локализовать проблему: загрузка, инит до гидрейта, рендер, реклама и\или аналитика, лонгтаски.
Все это позволяет нам обрести глаза и своевременно реагировать на проблемы.
