
Всем привет! Меня зовут Александр Афенов, я работаю в Lamoda. Эта статья по мотивам моего доклада с HighLoad 2019, запись которого лежит тут.
Раньше я был тимлидом, и в моем ведении была пара критикал-сервисов. И если в них что-то шло не так, это останавливало реальные бизнес-процессы. Например, заказы переставали уходить в сборку на складе.
Недавно я стал дирекшн-лидом и теперь отвечаю за три команды вместо одной. У каждой из них в ведении есть IT-система. Мне хочется понимать, что происходит в каждой системе и что может сломаться.
В этой статье я поговорю о том,

В Lamoda много систем. Все они релизятся, в них что-то меняется, что-то случается с техникой. И хочется иметь хотя бы иллюзию того, что мы легко локализуем поломку. Меня постоянно бомбит оповещениями, в которых я пытаюсь разобраться. Дабы уйти от абстракций и перейти к конкретике, расскажу первый пример.
Одним теплым летним утром без объявления войны, как это обычно бывает, у нас сработал мониторинг. В качестве алертинга мы используем Icinga. Алерт сказал, что у нас осталось 50 ГБ жесткого диска на сервере СУБД. Скорее всего, 50 гигабайт – это капля в море, и она закончится очень быстро. Мы решили посмотреть, сколько именно свободного места осталось. Надо понимать, что это не виртуалки, а железные сервера, и база под большой нагрузкой. Там стоит 1.5-терабайтная SSD. Скоро эта память скоро подойдет к концу: её хватит на 20-30 дней. Это очень мало, нужно оперативно решать проблему.
Потом мы дополнительно проверили, сколько на самом деле израсходовалось памяти за 1-2 дня. Оказывается, что 50 гигабайт хватит примерно на 5-7 дней. После чего сервис, который работает с этой базой, предсказуемо закончится. Мы начинаем думать о последствиях: что срочно заархивируем, какие данные удалим. У департамента Data analytics есть все бекапы, поэтому можно спокойно дропнуть всё старше 2015 года.
Пробуем удалить и вспоминаем, что MySQL так с полпинка не сработает. Удаленные данные – это замечательно, но размер файла, выделенного под таблицу и на DB, не меняется. MySQL потом использует это место. То есть проблема не решилась, места не стало больше.
Пробуем другой подход: миграцию табличек с быстрых заканчивающихся SSD на более медленные. Для этого выделяем таблички, которые много весят, но под маленькой нагрузкой, и используем мониторинг Percona. Перевезли таблицы и уже думаем о том, чтобы переехать самими серверами. После второго переезда сервера занимают не 1.5, а 4 терабайта SSD.
Мы потушили этот пожар: организовали переезд и, конечно, пофиксили мониторинг. Теперь warning будет срабатывать не на 50 гигабайтах, а на половине терабайта, а критическое значение мониторинга – на 50 гигабайтах. Но в действительности это лишь затыкание тылов одеялом. На какое-то время его хватит. Но если мы допустим повторения ситуации, не раздробив базу на части и не задумавшись о шардинге, всё кончится плохо.
Предположим, что дальше мы сменили сервера. На каком-то этапе потребовалось рестартануть мастер. Наверное, в этом случае появятся ошибки. В нашем случае даун-тайм был порядка 30 секунд. Но запросы идут, писать некуда, посыпались ошибки, сработал мониторинг. Мы используем систему мониторинга Prometheus – и видим в нём, что подскочила метрика 500-х ошибок или количество ошибок при создании заказа. Но мы не знаем деталей: какой именно заказ не создался, и тому подобные вещи.
Дальше расскажу, как мы работаем с мониторингами, чтобы не попадать в такие ситуации.
У нас есть несколько направлений и показателей, за которыми мы наблюдаем. В офисе везде висят телевизоры, на которых есть множество разных технических и бизнесовых меток, за которыми, кроме разработчиков, следит служба поддержки.
В этой статье я говорю о том, как у нас есть, и добавляю то, к чему мы хотим прийти. Это относится и к ревью мониторингов. Если бы мы регулярно проводили инвентаризацию нашего «имущества», то могли обновить всё устаревшее и зафиксить, не допуская повторения факапа. Для этого нужен внятный список.
У нас в репозитории есть конфиг-айсинги с алертами, где сейчас 4678 строк. Из этого списка сложно понять, о чем говорит каждый конкретный мониторинг. Допустим, наша метрика называется db_disc_space_left. Служба поддержки не сразу поймет, о чём тут речь. Что-то про свободное место, здорово.
Хотим копнуть глубже. Смотрим на конфиг этого мониторинга и понимаем, откуда он берется.
У этой метрики есть название, собственные ограничения, когда включать warning-мониторинг, алерт, чтобы сообщить о критической ситуации. Мы используем соглашение о наименовании метрик. В начале каждой метрики есть название системы. Благодаря этому, становится понятной зона ответственности. Если метрику заводит тот, кто отвечает за систему, сразу понятно, к кому идти.
Алерты сыпятся в телеграмм или слак. Служба поддержки реагирует на них первой в режиме 24/7. Ребята смотрят, что конкретно взорвалось, нормальная ли это ситуация. У них есть инструкции:
Также у нас есть сменные дежурства в командах, отвечающих за ключевые системы. В каждой команде есть тот, кто постоянно доступен. Если что-то случилось, его поднимают.
Когда сработал алерт, службе поддержки нужно быстро узнать всю ключевую информацию. Было бы классно, чтобы к сообщению об ошибке прикладывалась ссылка на описание мониторинга. Например, чтобы там была такая информация:
Также было бы удобно сразу посмотреть динамику трафика в интерфейсе Прометея.
Такие описания хотелось бы сделать по каждому мониторингу. Они помогут выстраивать ревью и вносить корректировки. Мы внедряем эту практику: в конфиге айсинга уже есть ссылочка на confluence с этой информацией. Я занимался одной системой почти 4 года, по ней в основном нет таких описаний. Поэтому сейчас я собираю знания воедино. Описания также решают проблему неосведомленности команды.
У нас есть инструкции по большинству алертов, где написано, что ведет к определенному бизнес-импакту. Вот почему мы должны оперативно разобраться в ситуации. Критичность возможных инцидентов определяют служба поддержки совместно с бизнесом.
Приведу пример: если сработал мониторинг расхода оперативной памяти на сервере RabbitMQ сервиса обработки заказов – это означает, что сервис очередей может упасть через несколько часов или даже минут. А это, в свою очередь, остановит множество бизнес-процессов. В результате, клиенты безуспешно будут ждать оформления заказов, SMS/push-оповещений, смены статусов и много другого.
Обсуждение мониторингов с бизнесом часто происходит после серьезных инцидентов. Если что-то сломалось, мы собираем комиссию с представителями направления, которого зацепило нашим релизом или инцидентом. На встрече разбираем причины инцидента, как сделать так, чтобы он никогда не повторился, какой ущерб мы понесли, сколько денег потеряли и на чем.
Бывает так, что нужно подключить бизнес для решения проблем, созданных для клиентов. Там обсуждаем проактивные действия: какой мониторинг завести, чтобы этого не повторялось.
Служба поддержки наблюдает за значениями метрик при помощи telegram-бота. Когда появляется новый мониторинг, сотруднику поддержки нужен простой инструмент, который позволит узнать, где сломалось и что с этим делать. Ссылка на описание в алерте решает эту задачу.
Недостаточно просто узнать об ошибке, хочется видеть подробности. Наш стандартный use case таков: выкатили релиз и получили алерты от K8S-стека. Благодаря мониторингу мы смотрим на состояние подов: какие версии приложения выкатились, чем закончился деплой, все ли хорошо.
Дальше мы заглядываем в РММ, что у нас с базой и с нагрузкой на нее. По Grafana и бордам мы смотрим на количество коннектов к Rabbit. Он клевый, но умеет протекать, когда заканчивается память. Мы мониторим эти штуки, а потом проверяем Sentry. Он позволяет наблюдать в онлайне, как образом разворачивается очередное фиаско со всеми деталями. В этом случае мониторинг после релиза сообщает, что сломалось и как именно.
В РНР-проектах мы используем raven-клиент, дополнительно обогащаем данными. Sentry это всё красиво агрегирует. И мы видим динамику по каждому факапу, как часто он происходит. А еще смотрим на примерах, какие запросы не удались, какие эксепшены вылезли.
Приблизительно так это выглядит. Я вижу, что на очередном релизе ошибок стало резко больше, чем обычно. Мы проверим, что конкретно сломалось. А потом, если нужно, по контексту достанем неудавшиеся заказы и их починим.
У нас есть классная штука – привязка к Jira. Это тикет-трекер: нажал кнопочку, и в Jira создался таск об ошибке со ссылкой на Sentry и стек-трейсом этой ошибки. Задача помечается определенными лейблами.
Один из разработчиков принес толковую инициативу – «Чистый проект, чистый Sentry». На планировании мы каждый раз закидываем в спринт хотя бы 1-2 задачи, созданных из Sentry. Если в системе всё время что-то сломано, то Sentry завалена миллионами мелких глупых ошибок. Мы регулярно чистим их, чтобы нечаянно не пропустить по-настоящему серьёзные.
Если что-то постоянно мигает и выглядит сломанным, это дает ощущение ложной нормы. Служба поддержки может заблуждаться, думая, что ситуация адекватная. И когда сломается что-то серьезное, это проигнорируют. Как в басне про мальчика, кричавшего: «Волки, волки!».
Классический кейс – наш проект, который отвечает за ордер-процессинг. Он работает с системой автоматизации склада и передает туда данные. Эта система релизится обычно в 7 утра, после чего у нас вспыхивают мониторинги. Все привыкли к этому и забивают, что не очень хорошо. Было бы разумно потюнить эти мониторинги. Например, связать релиз конкретной системы и некоторых алертов через Прометей, просто не врубать лишнюю сигнализацию.
Система обработки заказов передает данные на склад. Мы добавили мониторинги в эту систему. Ни один из них не стрелял, и кажется, что все нормально. Счётчик показывает, что данные уходят. В этом кейсе используется soap. В действительности счетчик может выглядеть так: зелененькая часть – это входящие обмены, желтые – исходящие.
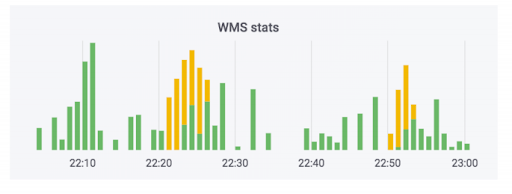
У нас был кейс, когда данные действительно угодили, но кривые. Заказы не были оплачены, но их пометили как оплаченные. То есть покупатель сможет забрать их бесплатно. Кажется, что это страшно. Но веселее наоборот: человек приходит забрать оплаченный заказ, а его просят заплатить ещё раз из-за ошибки в системе.
Чтобы избежать этой ситуации, мы наблюдаем не только за техникой, но и за метриками бизнеса. У нас есть конкретный мониторинг, который следит за количеством заказов, требующих оплаты при получении. Любые серьезные скачки в этой метрике покажут, если что-то пошло не так.
Мониторинг бизнес-показателей – это очевидная вещь, но про неё частенько забывают при выпуске новых сервисов, в том числе и мы. Все обмазывают новые сервисы сугубо техническими метриками, связанными с дисками, процом, чем угодно. У нас как интернет-магазина есть критически важная штука – это количество созданных заказов. Мы знаем, сколько люди обычно покупают с поправкой на маркетинговые акции. Поэтому при релизах мы следим за этим показателем.
Еще важная штука: когда клиент многократно заказывает доставку на один и тот же адрес, мы не мучаем его общением с колл-центром, а автоматически подтверждаем заказ. Сбой в системе сильно влияет на клиентский опыт. За этой метрикой мы тоже следим, поскольку релизы разных систем могут сильно на нее влиять.
Чтобы бизнес следил за разными показателями, мы запилили небольшую систему Real Time Dashboard. Изначально она делалась с другой целью. У бизнеса есть план, сколько заказов мы хотим продать в конкретный день грядущего месяца. Эта система показывает соответствие планов и сделанного по факту. Для графика она берет данные из продакшн-базы, читает оттуда на лету.
Однажды у нас развалилась реплика. Там не было мониторинга, поэтому мы не успели об этом узнать. Но бизнес увидел, что мы не выполняем план на 10 условных единиц заказов, и прибежал с комментариями. Мы начали разбираться в причинах. Оказалось, что из сломанной реплики читаются неактуальные данные. Это кейс, в котором бизнес наблюдает за интересными показателями, и мы помогаем друг другу при возникновении проблем.
Расскажу про ещё один мониторинг реального мира, который давно на разработке и постоянно тюнится каждой командой. У нас есть Jira Viewer – она позволяет наблюдать за процессом разработки. Система предельно простая: РНР фреймворк Symfony, который ходит в Jira Api и забирает оттуда данные о задачах, спринтах и так далее, в зависимости от того, что было дано на вход. Jira Viewer регулярно пишет метрики, связанные с командами и их проектами, в Prometeus. Там они мониторятся, алертятся и оттуда выводятся в Grafana. Благодаря этой системе мы следим за Work in progress.
На скриншоте видно, как Jira Viewer выдает данные. Это страница, где есть суммарная информация о статусах задачек из спринта, сколько весит каждая, и тому подобное. Такие штуки тоже собираются и летят в Прометей.
Чтобы собрать это все воедино, я предлагаю мониторить совместно и технику, и метрики, имеющие отношение к процессам, разработке и бизнесу. Одних технических метрик недостаточно.
Раньше я был тимлидом, и в моем ведении была пара критикал-сервисов. И если в них что-то шло не так, это останавливало реальные бизнес-процессы. Например, заказы переставали уходить в сборку на складе.
Недавно я стал дирекшн-лидом и теперь отвечаю за три команды вместо одной. У каждой из них в ведении есть IT-система. Мне хочется понимать, что происходит в каждой системе и что может сломаться.
В этой статье я поговорю о том,
- что мы мониторим,
- как мы мониторим,
- и самое главное: что мы делаем с результатами этих наблюдений.

В Lamoda много систем. Все они релизятся, в них что-то меняется, что-то случается с техникой. И хочется иметь хотя бы иллюзию того, что мы легко локализуем поломку. Меня постоянно бомбит оповещениями, в которых я пытаюсь разобраться. Дабы уйти от абстракций и перейти к конкретике, расскажу первый пример.
Время от времени что-то взрывается: хроники одного пожара
Одним теплым летним утром без объявления войны, как это обычно бывает, у нас сработал мониторинг. В качестве алертинга мы используем Icinga. Алерт сказал, что у нас осталось 50 ГБ жесткого диска на сервере СУБД. Скорее всего, 50 гигабайт – это капля в море, и она закончится очень быстро. Мы решили посмотреть, сколько именно свободного места осталось. Надо понимать, что это не виртуалки, а железные сервера, и база под большой нагрузкой. Там стоит 1.5-терабайтная SSD. Скоро эта память скоро подойдет к концу: её хватит на 20-30 дней. Это очень мало, нужно оперативно решать проблему.
Потом мы дополнительно проверили, сколько на самом деле израсходовалось памяти за 1-2 дня. Оказывается, что 50 гигабайт хватит примерно на 5-7 дней. После чего сервис, который работает с этой базой, предсказуемо закончится. Мы начинаем думать о последствиях: что срочно заархивируем, какие данные удалим. У департамента Data analytics есть все бекапы, поэтому можно спокойно дропнуть всё старше 2015 года.
Пробуем удалить и вспоминаем, что MySQL так с полпинка не сработает. Удаленные данные – это замечательно, но размер файла, выделенного под таблицу и на DB, не меняется. MySQL потом использует это место. То есть проблема не решилась, места не стало больше.
Пробуем другой подход: миграцию табличек с быстрых заканчивающихся SSD на более медленные. Для этого выделяем таблички, которые много весят, но под маленькой нагрузкой, и используем мониторинг Percona. Перевезли таблицы и уже думаем о том, чтобы переехать самими серверами. После второго переезда сервера занимают не 1.5, а 4 терабайта SSD.
Мы потушили этот пожар: организовали переезд и, конечно, пофиксили мониторинг. Теперь warning будет срабатывать не на 50 гигабайтах, а на половине терабайта, а критическое значение мониторинга – на 50 гигабайтах. Но в действительности это лишь затыкание тылов одеялом. На какое-то время его хватит. Но если мы допустим повторения ситуации, не раздробив базу на части и не задумавшись о шардинге, всё кончится плохо.
Предположим, что дальше мы сменили сервера. На каком-то этапе потребовалось рестартануть мастер. Наверное, в этом случае появятся ошибки. В нашем случае даун-тайм был порядка 30 секунд. Но запросы идут, писать некуда, посыпались ошибки, сработал мониторинг. Мы используем систему мониторинга Prometheus – и видим в нём, что подскочила метрика 500-х ошибок или количество ошибок при создании заказа. Но мы не знаем деталей: какой именно заказ не создался, и тому подобные вещи.
Дальше расскажу, как мы работаем с мониторингами, чтобы не попадать в такие ситуации.
Ревью мониторингов и внятное описание для службы поддержки
У нас есть несколько направлений и показателей, за которыми мы наблюдаем. В офисе везде висят телевизоры, на которых есть множество разных технических и бизнесовых меток, за которыми, кроме разработчиков, следит служба поддержки.
В этой статье я говорю о том, как у нас есть, и добавляю то, к чему мы хотим прийти. Это относится и к ревью мониторингов. Если бы мы регулярно проводили инвентаризацию нашего «имущества», то могли обновить всё устаревшее и зафиксить, не допуская повторения факапа. Для этого нужен внятный список.
У нас в репозитории есть конфиг-айсинги с алертами, где сейчас 4678 строк. Из этого списка сложно понять, о чем говорит каждый конкретный мониторинг. Допустим, наша метрика называется db_disc_space_left. Служба поддержки не сразу поймет, о чём тут речь. Что-то про свободное место, здорово.
Хотим копнуть глубже. Смотрим на конфиг этого мониторинга и понимаем, откуда он берется.
pm_host: "{{ prometheus_server }}"
pm_query: ”mysql_ssd_space_left"
pm_warning: 50
pm_critical: 10 pm_nanok: 1
У этой метрики есть название, собственные ограничения, когда включать warning-мониторинг, алерт, чтобы сообщить о критической ситуации. Мы используем соглашение о наименовании метрик. В начале каждой метрики есть название системы. Благодаря этому, становится понятной зона ответственности. Если метрику заводит тот, кто отвечает за систему, сразу понятно, к кому идти.
Алерты сыпятся в телеграмм или слак. Служба поддержки реагирует на них первой в режиме 24/7. Ребята смотрят, что конкретно взорвалось, нормальная ли это ситуация. У них есть инструкции:
- те, которые даются на смену,
- и инструкции, которые зафиксированы в confluence на постоянной основе. По названию взорвавшегося мониторинга можно найти, что он значит. Для самых критичных описано, что сломалось, каковы последствия, кого необходимо поднять.
Также у нас есть сменные дежурства в командах, отвечающих за ключевые системы. В каждой команде есть тот, кто постоянно доступен. Если что-то случилось, его поднимают.
Когда сработал алерт, службе поддержки нужно быстро узнать всю ключевую информацию. Было бы классно, чтобы к сообщению об ошибке прикладывалась ссылка на описание мониторинга. Например, чтобы там была такая информация:
- описание этого мониторинга в понятных, сравнительно простых терминах;
- адрес, где он расположен;
- объяснение, что это за метрика;
- последствия: чем всё закончится, если мы не исправим ошибку;
- У нас временами полыхают мониторинги, на которые можно забить, и ничего не произойдет. Возможно, это мониторинги, сделанные зря. Здесь нужен понятный экшн-пойнт, что делать.
Также было бы удобно сразу посмотреть динамику трафика в интерфейсе Прометея.
Такие описания хотелось бы сделать по каждому мониторингу. Они помогут выстраивать ревью и вносить корректировки. Мы внедряем эту практику: в конфиге айсинга уже есть ссылочка на confluence с этой информацией. Я занимался одной системой почти 4 года, по ней в основном нет таких описаний. Поэтому сейчас я собираю знания воедино. Описания также решают проблему неосведомленности команды.
У нас есть инструкции по большинству алертов, где написано, что ведет к определенному бизнес-импакту. Вот почему мы должны оперативно разобраться в ситуации. Критичность возможных инцидентов определяют служба поддержки совместно с бизнесом.
Приведу пример: если сработал мониторинг расхода оперативной памяти на сервере RabbitMQ сервиса обработки заказов – это означает, что сервис очередей может упасть через несколько часов или даже минут. А это, в свою очередь, остановит множество бизнес-процессов. В результате, клиенты безуспешно будут ждать оформления заказов, SMS/push-оповещений, смены статусов и много другого.
Обсуждение мониторингов с бизнесом часто происходит после серьезных инцидентов. Если что-то сломалось, мы собираем комиссию с представителями направления, которого зацепило нашим релизом или инцидентом. На встрече разбираем причины инцидента, как сделать так, чтобы он никогда не повторился, какой ущерб мы понесли, сколько денег потеряли и на чем.
Бывает так, что нужно подключить бизнес для решения проблем, созданных для клиентов. Там обсуждаем проактивные действия: какой мониторинг завести, чтобы этого не повторялось.
Служба поддержки наблюдает за значениями метрик при помощи telegram-бота. Когда появляется новый мониторинг, сотруднику поддержки нужен простой инструмент, который позволит узнать, где сломалось и что с этим делать. Ссылка на описание в алерте решает эту задачу.
Вижу факап как наяву: используем Sentry для разбора полётов
Недостаточно просто узнать об ошибке, хочется видеть подробности. Наш стандартный use case таков: выкатили релиз и получили алерты от K8S-стека. Благодаря мониторингу мы смотрим на состояние подов: какие версии приложения выкатились, чем закончился деплой, все ли хорошо.
Дальше мы заглядываем в РММ, что у нас с базой и с нагрузкой на нее. По Grafana и бордам мы смотрим на количество коннектов к Rabbit. Он клевый, но умеет протекать, когда заканчивается память. Мы мониторим эти штуки, а потом проверяем Sentry. Он позволяет наблюдать в онлайне, как образом разворачивается очередное фиаско со всеми деталями. В этом случае мониторинг после релиза сообщает, что сломалось и как именно.
В РНР-проектах мы используем raven-клиент, дополнительно обогащаем данными. Sentry это всё красиво агрегирует. И мы видим динамику по каждому факапу, как часто он происходит. А еще смотрим на примерах, какие запросы не удались, какие эксепшены вылезли.
Приблизительно так это выглядит. Я вижу, что на очередном релизе ошибок стало резко больше, чем обычно. Мы проверим, что конкретно сломалось. А потом, если нужно, по контексту достанем неудавшиеся заказы и их починим.
У нас есть классная штука – привязка к Jira. Это тикет-трекер: нажал кнопочку, и в Jira создался таск об ошибке со ссылкой на Sentry и стек-трейсом этой ошибки. Задача помечается определенными лейблами.
Один из разработчиков принес толковую инициативу – «Чистый проект, чистый Sentry». На планировании мы каждый раз закидываем в спринт хотя бы 1-2 задачи, созданных из Sentry. Если в системе всё время что-то сломано, то Sentry завалена миллионами мелких глупых ошибок. Мы регулярно чистим их, чтобы нечаянно не пропустить по-настоящему серьёзные.
Полыхает по любому поводу: избавляемся от мониторингов, на которые все забивают
- Привыкание к ошибкам
Если что-то постоянно мигает и выглядит сломанным, это дает ощущение ложной нормы. Служба поддержки может заблуждаться, думая, что ситуация адекватная. И когда сломается что-то серьезное, это проигнорируют. Как в басне про мальчика, кричавшего: «Волки, волки!».
Классический кейс – наш проект, который отвечает за ордер-процессинг. Он работает с системой автоматизации склада и передает туда данные. Эта система релизится обычно в 7 утра, после чего у нас вспыхивают мониторинги. Все привыкли к этому и забивают, что не очень хорошо. Было бы разумно потюнить эти мониторинги. Например, связать релиз конкретной системы и некоторых алертов через Прометей, просто не врубать лишнюю сигнализацию.
- Мониторинг не учитывает бизнес-показатели
Система обработки заказов передает данные на склад. Мы добавили мониторинги в эту систему. Ни один из них не стрелял, и кажется, что все нормально. Счётчик показывает, что данные уходят. В этом кейсе используется soap. В действительности счетчик может выглядеть так: зелененькая часть – это входящие обмены, желтые – исходящие.
У нас был кейс, когда данные действительно угодили, но кривые. Заказы не были оплачены, но их пометили как оплаченные. То есть покупатель сможет забрать их бесплатно. Кажется, что это страшно. Но веселее наоборот: человек приходит забрать оплаченный заказ, а его просят заплатить ещё раз из-за ошибки в системе.
Чтобы избежать этой ситуации, мы наблюдаем не только за техникой, но и за метриками бизнеса. У нас есть конкретный мониторинг, который следит за количеством заказов, требующих оплаты при получении. Любые серьезные скачки в этой метрике покажут, если что-то пошло не так.
Мониторинг бизнес-показателей – это очевидная вещь, но про неё частенько забывают при выпуске новых сервисов, в том числе и мы. Все обмазывают новые сервисы сугубо техническими метриками, связанными с дисками, процом, чем угодно. У нас как интернет-магазина есть критически важная штука – это количество созданных заказов. Мы знаем, сколько люди обычно покупают с поправкой на маркетинговые акции. Поэтому при релизах мы следим за этим показателем.
Еще важная штука: когда клиент многократно заказывает доставку на один и тот же адрес, мы не мучаем его общением с колл-центром, а автоматически подтверждаем заказ. Сбой в системе сильно влияет на клиентский опыт. За этой метрикой мы тоже следим, поскольку релизы разных систем могут сильно на нее влиять.
Наблюдаем за реальным миром: заботимся о здоровом спринте и нашей работоспособности
Чтобы бизнес следил за разными показателями, мы запилили небольшую систему Real Time Dashboard. Изначально она делалась с другой целью. У бизнеса есть план, сколько заказов мы хотим продать в конкретный день грядущего месяца. Эта система показывает соответствие планов и сделанного по факту. Для графика она берет данные из продакшн-базы, читает оттуда на лету.
Однажды у нас развалилась реплика. Там не было мониторинга, поэтому мы не успели об этом узнать. Но бизнес увидел, что мы не выполняем план на 10 условных единиц заказов, и прибежал с комментариями. Мы начали разбираться в причинах. Оказалось, что из сломанной реплики читаются неактуальные данные. Это кейс, в котором бизнес наблюдает за интересными показателями, и мы помогаем друг другу при возникновении проблем.
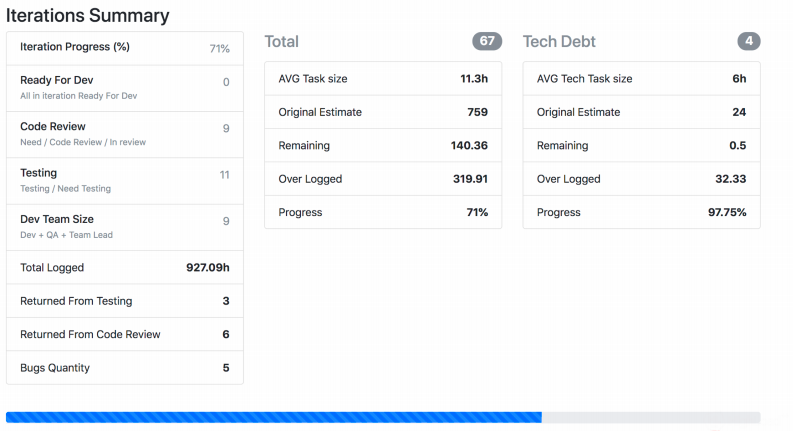
Расскажу про ещё один мониторинг реального мира, который давно на разработке и постоянно тюнится каждой командой. У нас есть Jira Viewer – она позволяет наблюдать за процессом разработки. Система предельно простая: РНР фреймворк Symfony, который ходит в Jira Api и забирает оттуда данные о задачах, спринтах и так далее, в зависимости от того, что было дано на вход. Jira Viewer регулярно пишет метрики, связанные с командами и их проектами, в Prometeus. Там они мониторятся, алертятся и оттуда выводятся в Grafana. Благодаря этой системе мы следим за Work in progress.
- Мы мониторим, как долго задача находится в работе с момента in progress и до выкатывания в прод. Если число слишком большое, теоретически это говорит о проблеме с процессами, командой, описанием задач и так далее. Срок жизни задачи – важная метрика, но самой по себе ее недостаточно.
- Ещё можно смотреть на здоровье спринта. Допустим, он кончается, а невыполненных задач осталось слишком много. Либо есть проблемы с логированием времени, если у вас принято его логировать.
- Нехватка релизов – слишком много задач в статусе ready for release, но никуда не уехали. Этот кейс у нас бывает из-за код-фриза перед большой акцией, такой как «Черная Пятница».
- Мониторим просадку в тестировании: когда куча задач висит на тестинг, за этим никто предметно не наблюдает. Эта метрика снимает ручную работу с менеджера или тимлида.
- Состояние беклогов тоже поддаётся мониторингу. Недавно мы взяли технический беклог одного проекта и сократили с 400 задач до 150. Мы просто поняли, что многое не будет сделано, и отменили их.
- Я мониторил в своей команде количество пулл-реквестов от разработчиков во внерабочее время. В частности, после 8 вечера. И когда метрика выстреливает, это тревожный знак: человек либо что-то не успевает, либо вкладывает слишком много сил и рано или поздно просто перегорит.
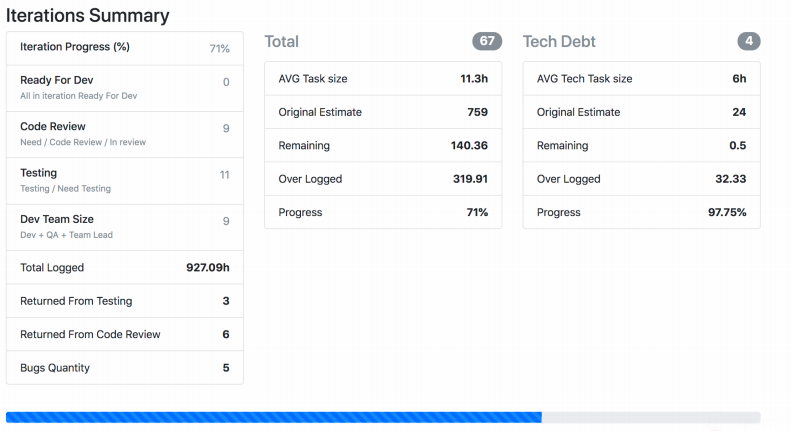
На скриншоте видно, как Jira Viewer выдает данные. Это страница, где есть суммарная информация о статусах задачек из спринта, сколько весит каждая, и тому подобное. Такие штуки тоже собираются и летят в Прометей.
Не только технические метрики: что мы уже мониторим, что можем мониторить и зачем это всё нужно
Чтобы собрать это все воедино, я предлагаю мониторить совместно и технику, и метрики, имеющие отношение к процессам, разработке и бизнесу. Одних технических метрик недостаточно.
- Мы взяли за правило, что когда выкатываем новую систему или новый бизнес-процесс, заранее формируем новый Grafana-борд. На эту доску выводятся все критичные метрики этой системы. Также заводятся наперед алерты, оповещения и так далее, чтобы мы предвосхищали проблемы на старте.
- Мы отслеживаем тренды: делаем мониторинги, которые наблюдают ситуацию в долгосрочной перспективе. Однажды мы увидели, как постепенно растет количество коннектов к нашей базе, благодаря чему выяснили проблему с crontab и переехали на supervisor. Так практика смотреть на долгосрочные изменения чиселок в Прометее привела к спасению системы. Правда, при этом мы породили еще один серьезный инцидент, но это бывает.
- Ревью мониторингов – штука, которая позволяет подчищать подобного рода истории и устранить древнее зло, которое заводилось непонятно зачем.
- Я предлагаю исключать ложные срабатывания: чтобы не было ситуаций, когда что-то полыхает, хотя на самом деле не должно. Очень важно, чтобы у людей не замыливался взгляд.
- В целом стоит делать так, чтобы алерты действительно отражали состояние данных по системе. Моя проблема в последний год – в Sentry скопилось несколько страниц ошибок. Какие-то из них случаются миллионами раз, и это хочется убрать. Я хочу видеть по-настоящему важные вещи, требующие устранения. А ещё чтобы в Sentry не попадало то, что является нормальным поведением, и чтобы там не было старых ошибок.
- Документировать метрики и объяснять их важность. Очень плохо, когда никто кроме автора метрики не понимает, почему она важна и что нужно чинить.
- Решать проблемы, а не затыкать тылы одеялом. Важно не просто тюнить мониторинги, поднимая пороговые значения из-за того, что в системе что-то постепенно разваливается. Я предлагаю действительно устранять первопричину алертов и не допускать повторения уже случившихся факапов.
