
UPDATE: нашел баг при обучении, исправил, результаты стали существенно лучше, поэтому заменил картинки
Данная статья является вольным переводом моей статьи на Medium.
В детстве я любил играть на компьютере. Совсем маленьким я застал несколько игр на кассетном ZS Spectrum, однако настоящим открытием стали красочные DOS игры 90x годов. Тогда же и зародилось большинство существующих жанров. Немного поностальгировав, я решил вспомнить молодость и запустить одну из старых игр на эмуляторе Dosbox и был неприятно поражен гигантскими пикселями и низким разрешением. Хотя в крупнопиксельной старой графике может быть свое очарование, многих сейчас не устраивает такое качество.
Для повышения разрешения и избавления от угловатости в играх в настоящее время используются различные алгоритмы постпроцессинга и сглаживания (подробно можно почитать, например тут zen.yandex.ru/media/id/5c993c6021b68f00b3fe919c/kak-rabotaet-sglajivanie-v-kompiuternyh-igrah-5c9b3e76d82a083cc9a0f1a7 ), но алгоритмы сглаживания приводят ко всем ненавистной «мыльной» картинке, которая часто еще менее предпочтительна, чем угловатость больших пикселей.
При этом улучшение качества графики часто критично для геймеров. Перерисовка текстур для hd игре Heroes 3 заняла около полугода в 2014 году у компании Ubisoft и вызвало всплеск интереса к данной игре. Из недавних новостей — переиздание первой CNC в hd графике. Подробно можно увидеть рост интереса к переизданным в hd графике на google trends.
Не для каждой игры имеет смысл заморачиваться и переиздавать в высоком качестве — перерисовка текстур — занятие затратное. Но можно попробовать улучшить качество графики используя технологию суперразрешения (superresolution). Идея superresolution лежит в улучшении разрешения изображения путем дорисовки недостающих пикселей нейросетью на основании имеющихся данных. Сейчас достигнуты впечатляющие результаты, вызывающие ассоциацию с разобранной на мемы сценой улучшения изображения из фильма bladerunner
Технология superresolution улучшает визуальное восприятие картинки, например вот github.com/tg-bomze/Face-Depixelizer, однако привносит новую информацию в изображение. И может быть использована для улучшения качества фильмов:
Однако большинство алгоритмов ресурсоемки, а мне хотелось создать скрипт для улучшения игры в реальном времени.
Стоит отметить, что схожая идея улучшения графики используется в технологии DLSS от Nvidia.
Немного теории
Все нижесказанное будет относиться к сверточным нейросетям— подтипу нейросетей, использумому для работы с изображениями. Для начала рассмотрим, как работает нейросеть для решения задачи superresolution. Задача очень похожа на решение задачи автоэнкодера . На вход сети необходимо подать изображение, на выходе получить такое же изображение. Однако автоэнкодеры обычно используют для решения задачи эффективного сжатия данных, поэтом особенностью их архитектуры является Bottleneck — бутылочное горлышко, то есть слой сети с небольшим количеством нейронов. Наличие такого слоя заставляет оставшиеся части обучаться для эффективного кодирования и раскодирования информации. Для обучения сетей superresolution разрешение высококачественного изображения сначала намеренно уменьшается и подается на вход нейросети. На выходе ожидается исходное изображение в высоком качестве.
Задача superresolution определяет архитектуру используемых сетей:
обычно в них присутствует связь между входными и выходными данными (skip-connection), сильно ускоряющая обучение. Размер пикселя входных данных увеличивается и прибавляется к выходу сверточной сети. Таким образом, фактически не нужно обучать сеть превращать изображение в почти такое же. Нужно лишь обучить ее дорисовывать разницу между увеличенным при помощи увеличения размера пикселя и реальным изображением. Идея наличия skip connections различного уровня и через разное количество слоев чрезвычайно эффективна и привела к появлению класса сетей Residual Networks. Сейчас подобные связи используются почти во всех популярных архитектурах. Неплохой обзор state-of-art архитектур для решения задач superresolution можно посмотреть тут. Моей же задачей было создать нейросеть для решения задачи superresolution в реальном времени.
Сначала мной была выбрана архитектура edsr с 4 блоками (обычно используют более 16 слоев из блоков) ResNet c увеличением разрешения в 4 раза. Тут я частично воспользовался наработками из github.com/krasserm/super-resolution и генератором данных из этого же проекта.
Общая архитектура сети показана на схеме. Каждый блок – изображение X*Y*N, где ширина соответствует числу каналов. Переходы – соответствуют сверткам 3x3 (в случае res блоков с последующей активацией ReLU для нелинейности). Шаг Upscaling – увеличение размерности за счет уплощения каналов.
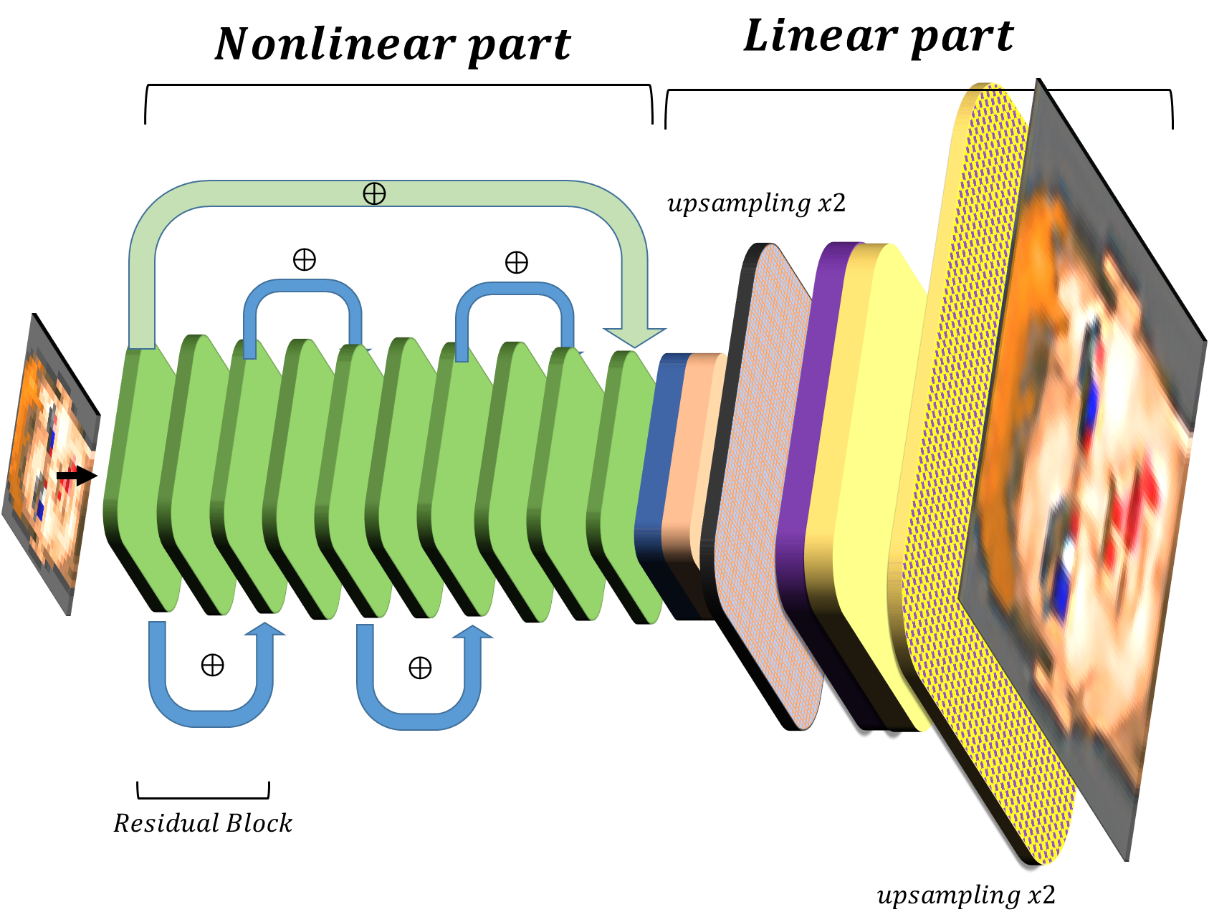
Если приглядеться к такой небольшой сети, то можно заметить, что последние блоки — линейные и наличие нескольких шагов upscaling неоправданно. Можно без потери качества заменить их на один слой с гораздо меньшим количеством фильтров без потери качества работы сети:
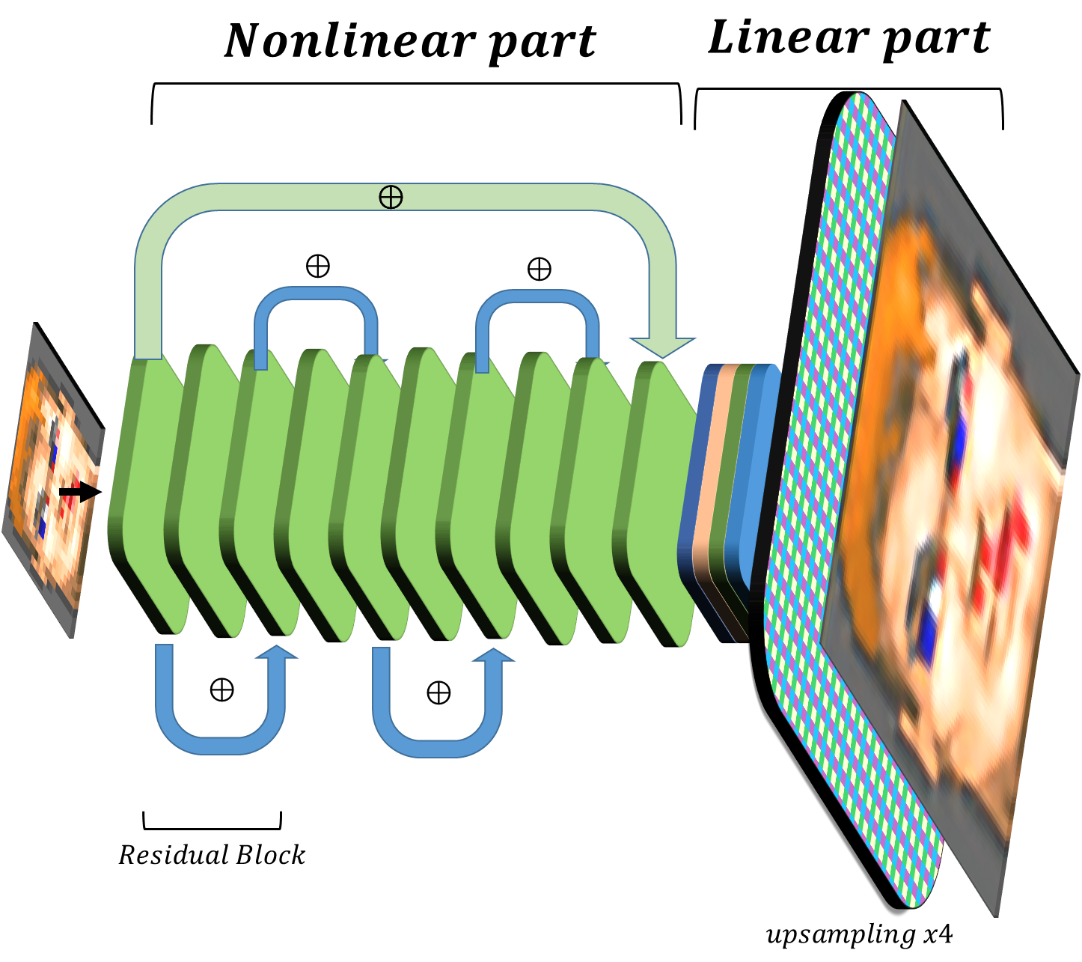
Оказалось, что такая сеть практически так же справляется с задачей superresolution, но гораздо быстрее и может быть запущена для обработки небольшого по разрешению видео в реальном времени.
Высококачественные фото были скачаны из data.vision.ee.ethz.ch/cvl/DIV2K. В принципе можно использовать любые фото для обучения.
import tensorflow as tf
import numpy as np
from utils import load_image, plot_sample
from data import DIV2K
from tensorflow.keras.optimizers.schedules import PiecewiseConstantDecay
import PIL
from PIL import Image
import os
import tqdm
# Model creation
rgb_mean = np.array([0.4488, 0.4371, 0.4040]) * 255
def normalize(x, rgb_mean=rgb_mean):
return (x - rgb_mean) / 127.5
def denormalize(x, rgb_mean=rgb_mean):
return x * 127.5 + rgb_mean
inp=tf.keras.layers.Input((None,None,3))
x=tf.keras.layers.Lambda(normalize)(inp)
x0=tf.keras.layers.Conv2D(64,3,padding='same')(x)
x=x0
for i in range(4):
y=tf.keras.layers.Conv2D(64,3,activation='relu',padding='same')(x)
y=tf.keras.layers.Conv2D(64,3,padding='same')(y)
x=tf.keras.layers.Add()([x,y])
x=tf.keras.layers.Conv2D(64,3,padding='same')(x)
x=tf.keras.layers.Add()([x0,x])
x=tf.keras.layers.Conv2D(48,3,padding='same')(x)
x=tf.keras.layers.Lambda (lambda z: tf.nn.depth_to_space(z, 4))(x)
out=tf.keras.layers.Lambda(denormalize)(x)
rtsrn=tf.keras.models.Model(inputs=inp, outputs=out)
train_loader = DIV2K(scale=4,
downgrade='unknown',
subset='train')
train_ds = train_loader.dataset(batch_size=16,
random_transform=True,
repeat_count=None)
valid_loader = DIV2K(scale=4,
downgrade='unknown',
subset='valid')
valid_ds = valid_loader.dataset(batch_size=16, # use batch size of 1 as DIV2K images have different size
random_transform=True, # use DIV2K images in original size
repeat_count=40) # 1 epoch
#OUR resize method
trainhrpath='.div2k/images/DIV2K_train_HR/'
validhrpath='.div2k/images/DIV2K_valid_HR/'
trainlrpath='.div2k/images/DIV2K_train_LR_unknown/X4/'
validlrpath='.div2k/images/DIV2K_valid_LR_unknown/X4/'
for imagename in tqdm.tqdm(os.listdir(trainhrpath)):
imgtest=Image.open(trainhrpath+imagename)
imgtest.resize((imgtest.size[0]//4,imgtest.size[1]//4), Image.NEAREST).save(trainlrpath+imagename[:-4]+'x4'+'.png')
for imagename in tqdm.tqdm(os.listdir(validhrpath)):
imgtest=Image.open(validhrpath+imagename)
imgtest.resize((imgtest.size[0]//4,imgtest.size[1]//4), Image.NEAREST).save(validlrpath+imagename[:-4]+'x4'+'.png')
После этого удалим данные кэша, в папке ./cahes, перезапустим генераторы данных и начнем обучение:
train_loader = DIV2K(scale=4,
downgrade='unknown',
subset='train')
train_ds = train_loader.dataset(batch_size=16,
random_transform=True,
repeat_count=None)
valid_loader = DIV2K(scale=4,
downgrade='unknown',
subset='valid')
valid_ds = valid_loader.dataset(batch_size=16, # use batch size of 1 as DIV2K images have different size
random_transform=True, # use DIV2K images in original size
repeat_count=40) # 1 epoch
cbcks=tf.keras.callbacks.ModelCheckpoint('myedsr_smaller_callback_x4{epoch:02d}-{loss:.2f}', monitor='loss', verbose=0, save_best_only=False)
learning_rate=PiecewiseConstantDecay(boundaries=[20000], values=[1e-4, 5e-5])
rtsrn.compile(loss='mae', optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate))
rtsrn.fit(train_ds,validation_data=valid_ds, steps_per_epoch=3000, epochs=100, validation_steps=10,callbacks=[cbcks])
rtsrn.save'RTSRN.h5')
На выходе получаем относительно небольшую (2.6 МБ) нейросеть с простой архитектурой. При этом проверка дает малозаметное отличие от предобученной 16 блочной сети:

Изображение слева — исходное, справа — улучшенное при помощи 16 слойной edsr, в середине — с помощью rtsr. Разница между 2 и 3 с моей точки зрения несущественна.
Инференс
github.com/Alexankharin/RTSR
Полученную сеть запустим на видеокарте (у меня GTX 1060) с поддержкой cudnn (https://developer.nvidia.com/cudnn) для высокой производительности.
Pipeline для инференса выглядит следующим образом:
- Захват изображения из области или из окна
- Улучшение изображения
- Отрисовка улучшенного изображения в новом окне
При тестировании я обнаружил, хотя при запуске большинства игр в эмуляторе dosbox разрешение составляет 640x480 пикселей, однако чаще всего это просто увеличенные в размере пиксели разрешения 320x240(и позже нашел подробности www.dosgamers.com/dos/dosbox-dos-emulator/screen-resolution ), что приводит ук необходимости в некоторых случаях делать downscale в 2 раза перед обработкой.
Захват скриншотов производится с использованием библиотеки mss (для OS ubuntu) или d3dshot (быстрее для windows).
Отображение — с использованием opencv-python. Для закрытия окна необходимо сделать его активным и нажать на клавишу «q». Управлением захватом улучшаемой области при помощи клавиш WSAD и IKJL.
Скрипт написан в файле superres_win.py
Результаты:
на ноутбуке с GTX 1060 (3Gb) и OS Windows10 скрипт выдает 14-15 FPS, что достаточно для квестов или стратегий, но немного маловато для платформеров. Кроме того, при запуске RTSR на стационарном ПК с OS Ubuntu и такой же видеокартой падал до 10-12 (почему — пока не разбирался). Судя по бенчмаркам ai-benchmark.com/ranking_deeplearning_detailed.html 1080 на схожих задачах должна дать FPS около 25, что близко к оригинальным значениям и достаточно для комфортной игры. Пример улучшения графики можно увидеть на видео:
Примеры улучшения:
MegaManX

Legend of Kyrandia

Wolf3d

Heroes of might and magic
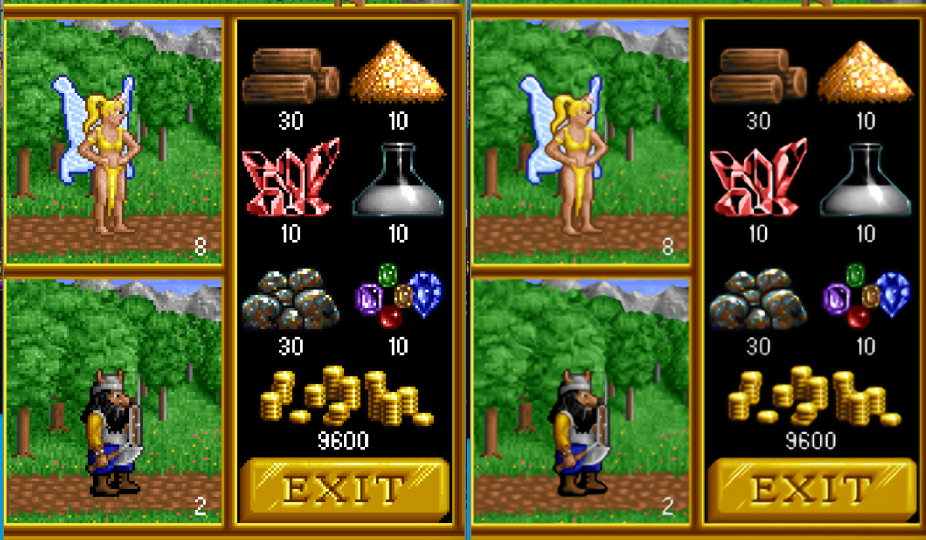
Больше примеров можете попробовать сами
Как запустить?
Для быстрой работы необходима видеокарта с поддержкой cuda и cudnn (https://developer.nvidia.com/cuda-gpus ) и установленными библиотеками cuda/cudnn. Нужен установленный python 3.7 и tensorflow (версия выше 2.0 с поддержкой gpu). Это может быть сложной задачей, и могут возникнуть проблемы совместимости.
Простейшим способом может быть установка дистрибутива Anaconda (https://www.anaconda.com/products/individual ), а затем в установка tensorflow-gpu При помощи conda:
conda install tensorflow-gpu
Если не получится из-за конфликтов, то можно попробовать
conda install cudnn
pip install tensorflow-gpu
должно сработать.
Остальные библиотеки можно установить при помощи pip:
pip install opencv-python
pip install pywin32
pip install mss
Далее необходимо запустить скрипт командой:
python superres.py
Управление окном захвата проводится при помощи клавиш wsad и ijkl (изменение размера). q- закрытие окна. 0 -включение и выключение режима superresolution. Цифры 1 и 2 — режим изображения (2 по умолчанию означает, что в игре используется увеличение за счет увеличения пикселя в 2 раза).
