Привет, Хабр! Сегодня делимся историей нашего коллеги из партнерской компании о том, как он занимался внедрением машинного обучения в свою команду. Передаю слово автору.
Я работаю тимлидом во внутренней техподдержке — мы поддерживаем внутренних пользователей, и соответственно внутренние системы.
Ежедневно через нашу первую линию проходит порядка 200 обращений. Пользователь может обратиться к нам двумя способами — через портал, либо через почту. В нашей команде 7 человек, двое на первой линии, пятеро на второй. Одна из обязанностей ребят на 1 линии — классификация и маршрутизация заявок на 2 линию (к которой помимо наших 5 ребят инженеров относятся множество команд и подразделений). При этом цифра в 200 обращений, о которой я говорил выше, такой была не всегда — около года назад обращений было значительно меньше, но уже тогда цифра заметно начала расти, вместе с новыми сервисами и усложнением существующих. И в тот момент перед нами вставал вопрос — текущим составом первой линии (2ч) классифицировать и маршрутизировать 200 обращений становится всё сложнее, на это уходит как минимум больше времени.
При этом ребята на 1 линии, помимо классификации и маршрутизации, занимаются множеством других верхнеуровневых вопросов — например, выдача прав во внутренние системы, мониторинг и реагирование на алерты внутренних систем, и прочие штуки, которые не требуют крайне глубокого погружения в предмет. Расширение штата первой линии — самый простой вариант, который можно использовать, но он, разумеется, требует инвестиций, как денежных, так и человеческих — новых ребят нанимать и обучать. Мы оставили этот вариант как план B, или даже C — быть уверенными, в том, что количество заявок стабилизируется мы не можем, а значит и видеть конца расширению штата тоже. И разумеется, в 2019 году мы не могли не рассмотреть такой вариант, как Machine Learning, и всё, что из него вытекает.

Мы поизучали рынок, посмотрели как работают другие команды и другие компании и выделили для себя три возможных варианта:
Помимо вариантов, сразу утвердили для себя ряд принципов, на которые будем опираться при внедрении нового решения:
Ну и наконец формулировка задачи, которую мы перед собой ставили: необходимо сократить время маршрутизации заявки на 50% или выше.
Вернемся к вариантам, на которых мы остановились.
В общем выбор был сделан, и мы приступили к работе. Забегая вперёд, от старта идеи до продакшена мне понадобилось шагов:
Любая история про Machine Learning начинается с данных, и мы были не исключением.
Все наши обращения от пользователей хранятся в БД, а значит их можно легко оттуда вытянуть. Мы разбили все заявки, которые уже были хоть как-то размечены, на 28 категорий. На каждую категорию постарались брать <= 1000 заявок и получили довольно большой датасет из 28000 пар «Class» и «IssueDescription».
Как только мы получили сырые данные, у меня уже чесались руки что-нибудь на них опробовать, поэтому закрыв Excel, я перешёл на портал Azure, открыл ML Studio, загрузил в неё готовый пример текстовой классификации данных, а на соседнем мониторе довольно простой гайд по использованию моделей. В моём примере была выбрана модель обучения Multiclass Logistic Regression. Как стало известно позже, это не лучший вариант для классификации текста, но тогда ещё я об этом не знал.
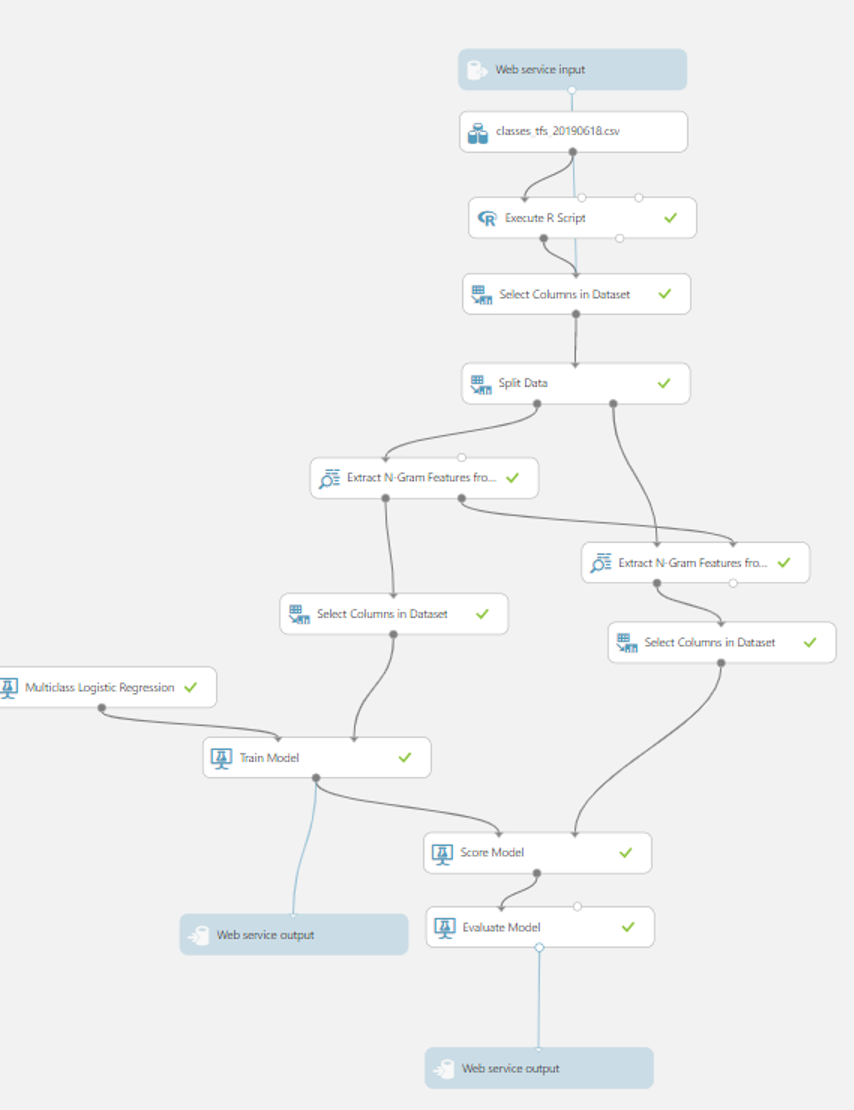
Модель представляет собой несколько модулей, которые соединены между собой коннекторами в виде линий, соединяются и разъединяются они drag & drop'ом, наподобие конструкторов для блок-схем. Если в двух словах пробежаться, что здесь происходит:
Я заменил исходный CSV из примера на свой, скорректировал названия столбцов на те, что были в примере и, неизвестно на что рассчитывая, нажал кнопку «Run». Внизу забегал прогресс бар, и я уже ждал появления ошибки — ведь я просто подсунул чужой датасет. Но ошибка не появилась, вместо этого на экране загорелось «Done». Мой скептицизм на этом не остановился, и я был уверен, что на выходе получится полная чепуха. Все результаты обучения находятся в модуле Evaluate Model — они представлены в виде удобной матрицы с процентами успешных предсказаний текущей модели для каждой категории.
К моему удивлению, из коробки, на чужой модели я получил 31% успешных предсказаний. Радости от увиденной магии не было предела — всё же получить хотя бы 31%, приступив к задаче около часа назад — не то, что ты ожидаешь от абсолютно нового для тебя стека технологий. Порадовав руководство, что лёд уже сдвинулся с места (не думаю, что мне поверили), я начал крутить настройки буквально вслепую, менять 0 на 1, крутить treshold, ratio и прочие параметры, в назначении которых в данном контексте я ничего не понимал. И радость от 31% улетучилась довольно быстро — общий процент успешных предсказаний чаще падал, нежели поднимался, а если и поднимался, то не больше чем на пару процентов. Знающие люди подсказали мне, что на сырых данных я ничего великого не добьюсь, поэтому надо приводить их в порядок.
Наши данные это абсолютный RAW, а значит это:
В общем нам нужно очистить датасет из 28000 объектов от разного рода мусора. Для этой задачи ML Studio предлагает нам два полезных модуля, которые можно подключить к нашему датасету, и пропустить его через них. Это Python и R Script модули. Лично мне Python не знаком от слова совсем, а вот R я немного, но знаю. В нашем случае датасет чуть больше чем полностью состоит из кириллического набора символов, версия языка R, предустановленная в ML Studio, по какой-то причине ломала кодировку текста популярной в языке функцией gsub(). Увы, Python изучать не было времени, поэтому я воспользовался запасным вариантом — мы написали крохотный сервис на .NET, который регулярными выражениями и простой автозаменой убирает из датасета всё, что нам не нужно. Для этого мы создали несколько txt-словарей, в которые поместили всевозможные имена собственные, предлоги и так далее. Вся очистка текста уложилась в код, с которым вполне справится junior, или в нашем случае инженер техподдержки:
—
Обращу внимание, что на красоту и эстетичность кода мы не претендуем.
Ок, данные мы почистили, и выглядят они уже куда более лаконично, плюс датасет заметно похудел. Но осталась ещё одна немаловажная задача, которую при подготовке датасета пропустить нельзя — лемматизация. Выражаясь простым языком весь наш текст нужно привести к условным леммам. Если ещё более простым — все слова в датасете нужно привести к их «простой» форме. Какого-то очевидного решения на .NET для этого я не нашёл, поэтому появилась возможность дать R модулю второй шанс: в R есть простая библиотека SnowballC, которая для разных языков, включая кириллицу, по простому алгоритму обрезает окончания у слов. Например, слово «погода» превратится в «погод», «прыгать» в «прыг», «бегают» в «бег». Выглядит в итоге текст не очень читаемо, но читать датасет будет не человек, а машина — поэтому этот вопрос нас не беспокоит. К датасету мы снова подключили модуль R, в котором прямо в ML Studio написали маленький скрипт:
—
Таким образом заявка
и заявка
для машины становятся одним и тем же, так как после лемматизации и очистки текста они примут вид:
Пожалуй, вот и всё, что мы кодили в контексте машинного обучения. В сумме это не так много строчек кода, на достаточно популярных языках.
На переподготовку данных у меня ушло около недели, и руки снова зачесались — пора опробовать наш подготовленный датасет в деле. Награда не заставила себя ждать: подключив новый датасет, подключив к нему R модуль, после переобучения я получил 71% успешных предсказаний. Неплохо, правда? Очень, и очень неплохо.

Матрица процентного соотношения успешных предсказаний категорий
Если резюмировать всё вышесказанное — мы взяли обращения пользователей, отчистили их от мусора, подключили в готовую модель — и практически из коробки получили очень неплохой помощник классификации заявок с 71% успешных предсказаний. При этом на некоторых категориях модель выдаёт >90%, и для них мы можем избавиться от ручной классификации в принципе.
Внизу статьи я приложу ссылку на нашу стартовую модель классификации в галерее Azure, если вы решите её опробовать. Всё, что нужно, это заменить первый модуль с CSV на ваш, и переименовать в вашем датасете колонки в class и description. Этот пример, конечно же, не является образцом, это ровно тот же экземпляр, который я использовал в первые дни реализации задачи. Но взглянув на него можно представить, как легко можно начать внедрять искусственный интеллект, а именно машинное обучение в свой проект, не имея специализированных знаний на старте.
Итого весь наш процесс классификации заявок можно описать в несколько этапов:
Для специалиста всё выглядит ещё проще — прилетает заявка от пользователя, он выбирает одну из трёх предсказанных категорий (как правило 1-ю по очереди, так как она имеет наивысший SCORE) — всё.
Таким образом мы практически полностью избавили ребят на первой линии от времени, которое они тратили на маршрутизацию заявки — больше им не нужно листать базы знаний, огромные списки с правилами классификации заявок. Раньше на это могло уходить до минуты, сейчас это буквально 5-7 секунд, чтобы по диагонали просмотреть текст заявки и выбрать исполнителя из трёхстрочного списка. Если говорить про сухие цифры – мы сэкономили 70 человеко-часов в месяц, или 40% рабочего времени каждого специалиста.
Впереди у нас повышение качества предсказаний и частичный уход от ручной классификации (полностью уйти мы не сможем, так как ребята на первой линии часто проводят первичную обработку заявки), и конечно же детальная настройка модели не в слепую, а имея бэкграунд в виде понимания за что отвечает каждый модуль. Сегодня, немного поизучав предмет, мы заменили Multiclass Logistic Regression на Two-Class Boosted Decision в паре с One vs All Multiclass, плюс поиграли с настройками N-грамм, и выиграли еще + 6%. Но это уже другая история.
Теперь разумный вопрос — во сколько нам это всё обходится? Azure берёт деньги за траффик, то есть как часто и насколько тяжёлыми данными вы обмениваетесь с ним. Учитывая наш объём в 200+ заявок ежедневно, ежемесячная плата за сервис нам обходится в ~600р, то есть около 20 рублей в день, за экономию 40% рабочего времени на одного человека — на мой взгляд это несоизмеримый профит до/после за такие деньги.
И напоследок, мораль этой истории. Если у вас небольшая команда, и вам требуется разгрузить специалистов от ручной, зачастую машинной работы, не бойтесь использовать облачные решения — сегодня это совсем не сложные с точки зрения пользователя механизмы, которые дают вам простое управление, а сложные алгоритмы работы отходят на второй план (впрочем ничего не мешает вам разобраться и в них, если есть желание и потребность в повышении качества предсказаний).
Ссылка на эксперимент в галерее Azure

Павел Денисов – тимлид команды поддержки внутренних продуктов в компании 2ГИС.
Я работаю тимлидом во внутренней техподдержке — мы поддерживаем внутренних пользователей, и соответственно внутренние системы.
Ежедневно через нашу первую линию проходит порядка 200 обращений. Пользователь может обратиться к нам двумя способами — через портал, либо через почту. В нашей команде 7 человек, двое на первой линии, пятеро на второй. Одна из обязанностей ребят на 1 линии — классификация и маршрутизация заявок на 2 линию (к которой помимо наших 5 ребят инженеров относятся множество команд и подразделений). При этом цифра в 200 обращений, о которой я говорил выше, такой была не всегда — около года назад обращений было значительно меньше, но уже тогда цифра заметно начала расти, вместе с новыми сервисами и усложнением существующих. И в тот момент перед нами вставал вопрос — текущим составом первой линии (2ч) классифицировать и маршрутизировать 200 обращений становится всё сложнее, на это уходит как минимум больше времени.
При этом ребята на 1 линии, помимо классификации и маршрутизации, занимаются множеством других верхнеуровневых вопросов — например, выдача прав во внутренние системы, мониторинг и реагирование на алерты внутренних систем, и прочие штуки, которые не требуют крайне глубокого погружения в предмет. Расширение штата первой линии — самый простой вариант, который можно использовать, но он, разумеется, требует инвестиций, как денежных, так и человеческих — новых ребят нанимать и обучать. Мы оставили этот вариант как план B, или даже C — быть уверенными, в том, что количество заявок стабилизируется мы не можем, а значит и видеть конца расширению штата тоже. И разумеется, в 2019 году мы не могли не рассмотреть такой вариант, как Machine Learning, и всё, что из него вытекает.

Мы поизучали рынок, посмотрели как работают другие команды и другие компании и выделили для себя три возможных варианта:
- Попросить разработчиков сделать нам сервис, который будет помогать нам классифицировать и маршрутизировать заявки.
- Сделать самим что-то вроде статьи или БД с ключевыми словами, и как-то связать входящий поток обращений с этим источником, и, опираясь на ключевые слова, говорить нам, к какой категории относится обращение
- Использовать облачное ML решение
Помимо вариантов, сразу утвердили для себя ряд принципов, на которые будем опираться при внедрении нового решения:
- Низкая стоимость. Решение в идеале должно быть бесплатным, либо обойтись нам минимальными деньгами и минимальными человеческими ресурсами
- Автономность. Все мы знаем, что такое влезать в чужие роадмапы с просьбой что-то покодить и вопросами типа «ну когда уже??». Иногда это надо делать, иногда и делаем, но тогда мы решили, что будем делать всё в «4-х стенах» нашей команды.
- Лёгкость конфигурации. Любой участник команды должен иметь возможность работать с решением, конфигурировать и масштабировать его, если потребуется.
Ну и наконец формулировка задачи, которую мы перед собой ставили: необходимо сократить время маршрутизации заявки на 50% или выше.
Вернемся к вариантам, на которых мы остановились.
- Вариант можно назвать как «Локальный сервис предсказаний категории заявок». То есть кто-то пишет нам скрипт, где-то его поднимает и обслуживает.Здесь мы никак не можем обойтись без помощи разработчиков, а значит придётся просить их этот самый сервис нам разработать, где-то поднять, мониторить его, реагировать на алерты и так далее. Мониторинг, конечно, можно перекинуть на нас, но всё остальное — как видим, противоречит принципу №2 — автономностью и замкнутостью процесса в команде и не пахнет.
- Так называемый условный категоризатор с источником в виде статьи или БД — если в тексте обращения есть ключевое слово, то относить его к той или иной категории. Опять же, сами вряд ли справимся, так или иначе математика, все дела, плюс вероятность верных предсказаний, основанных лишь на найденном словесном совпадении вряд ли будет хоть сколько-нибудь высокой.
- Облачное решение. Спойлер — мы практически сразу выбрали этот вариант. Возможно это очевидно, но расскажу, что в нём мы такого нашли:
- Во-первых, у нас уже используется ряд продуктов от MS, и мы можем используя наши доменные учетки пробовать их продукты в ограниченном виде бесплатно.
- Решение облачное — а значит за мониторинг и отказоустойчивость отвечают люди, которые могут гарантировать работу сервиса 24/7 (как правило в таких случаях отказоустойчивость стремится к 99.9%).
- Низкий порог вхождения — большую часть времени работы с инструментом я занимался drag&drop'ом, чуть ниже я расскажу об этом.
- Много документации. Очень много. Много буквальных гайдов, куча информации на docs.Microsoft, довольно много Q&A на StackOverflow. И что особенно меня радует — много готовых примеров по всему интернету.
- Весь процесс замкнут в облаке. Здесь поставлю небольшую звёздочку, так как на самом деле, пока (в нашем случае), не весь.
В общем выбор был сделан, и мы приступили к работе. Забегая вперёд, от старта идеи до продакшена мне понадобилось шагов:
- Выгрузка данных с заявками
- Подготовка данных
- Выбор модели обучения / для MVP выбор готовой модели
- Интеграция с сервисом маршрутизации заявок
Любая история про Machine Learning начинается с данных, и мы были не исключением.
Получаем датасет
Все наши обращения от пользователей хранятся в БД, а значит их можно легко оттуда вытянуть. Мы разбили все заявки, которые уже были хоть как-то размечены, на 28 категорий. На каждую категорию постарались брать <= 1000 заявок и получили довольно большой датасет из 28000 пар «Class» и «IssueDescription».
Как только мы получили сырые данные, у меня уже чесались руки что-нибудь на них опробовать, поэтому закрыв Excel, я перешёл на портал Azure, открыл ML Studio, загрузил в неё готовый пример текстовой классификации данных, а на соседнем мониторе довольно простой гайд по использованию моделей. В моём примере была выбрана модель обучения Multiclass Logistic Regression. Как стало известно позже, это не лучший вариант для классификации текста, но тогда ещё я об этом не знал.

Модель представляет собой несколько модулей, которые соединены между собой коннекторами в виде линий, соединяются и разъединяются они drag & drop'ом, наподобие конструкторов для блок-схем. Если в двух словах пробежаться, что здесь происходит:
- Подключаем в первом модуле датасет в CSV
- Выбираем колонки, которые нас интересуют
- Датасет делится на две части – 75% идёт на обучение, оставшиеся 25% на проверку обучения
- Данные разбиваются на N-граммы (описывать что это я не буду, проще прочитать здесь)
- Дальше проходит «магия» обучения
Я заменил исходный CSV из примера на свой, скорректировал названия столбцов на те, что были в примере и, неизвестно на что рассчитывая, нажал кнопку «Run». Внизу забегал прогресс бар, и я уже ждал появления ошибки — ведь я просто подсунул чужой датасет. Но ошибка не появилась, вместо этого на экране загорелось «Done». Мой скептицизм на этом не остановился, и я был уверен, что на выходе получится полная чепуха. Все результаты обучения находятся в модуле Evaluate Model — они представлены в виде удобной матрицы с процентами успешных предсказаний текущей модели для каждой категории.
К моему удивлению, из коробки, на чужой модели я получил 31% успешных предсказаний. Радости от увиденной магии не было предела — всё же получить хотя бы 31%, приступив к задаче около часа назад — не то, что ты ожидаешь от абсолютно нового для тебя стека технологий. Порадовав руководство, что лёд уже сдвинулся с места (не думаю, что мне поверили), я начал крутить настройки буквально вслепую, менять 0 на 1, крутить treshold, ratio и прочие параметры, в назначении которых в данном контексте я ничего не понимал. И радость от 31% улетучилась довольно быстро — общий процент успешных предсказаний чаще падал, нежели поднимался, а если и поднимался, то не больше чем на пару процентов. Знающие люди подсказали мне, что на сырых данных я ничего великого не добьюсь, поэтому надо приводить их в порядок.
Работа с данными
Наши данные это абсолютный RAW, а значит это:
- Приветствия пользователя
- Подвалы из подписей почты
- Теги от html-кодировки
- Словесные артефакты, много, много артефактов в виде предлогов, имен собственных, местоимений, дат, номеров телефонов и прочего, очень много прочего, что никак не должно влиять на решение машины
В общем нам нужно очистить датасет из 28000 объектов от разного рода мусора. Для этой задачи ML Studio предлагает нам два полезных модуля, которые можно подключить к нашему датасету, и пропустить его через них. Это Python и R Script модули. Лично мне Python не знаком от слова совсем, а вот R я немного, но знаю. В нашем случае датасет чуть больше чем полностью состоит из кириллического набора символов, версия языка R, предустановленная в ML Studio, по какой-то причине ломала кодировку текста популярной в языке функцией gsub(). Увы, Python изучать не было времени, поэтому я воспользовался запасным вариантом — мы написали крохотный сервис на .NET, который регулярными выражениями и простой автозаменой убирает из датасета всё, что нам не нужно. Для этого мы создали несколько txt-словарей, в которые поместили всевозможные имена собственные, предлоги и так далее. Вся очистка текста уложилась в код, с которым вполне справится junior, или в нашем случае инженер техподдержки:
—
public string CleanUp(string text, List<string> filters)
{
var result = "";
foreach (var item in filters)
{
text = Regex.Replace(text ?? "Нет данных", item, string.Empty);
}
text = text.ToLower();
//Разбиваем текст на массив слов
string[] words = text.Split(new[] { ' ', ',', '.', '!', '?', '\n', '\r', '-' }, StringSplitOptions.RemoveEmptyEntries);
var pathToRus = AppDomain.CurrentDomain.BaseDirectory + "LibDataWorkItems/RusStopWords.txt";
var pathToEng = AppDomain.CurrentDomain.BaseDirectory + "LibDataWorkItems/EngStopWords.txt";
russianStopWords = new HashSet<string>(File.ReadAllLines(pathToRus)
.Where(l => !l.StartsWith("#"))
.Select(l => l.Trim())
.ToArray());
englishStopWords = new HashSet<string>(File.ReadAllLines(pathToEng)
.Where(l => !l.StartsWith("#"))
.Select(l => l.Trim())
.ToArray());
var index = 0;
foreach (var word in words)
{
string _word = word;
if (_word == "1c" || _word == "1с")
{
_word = "odins";
}
_word = Regex.Replace(_word, @"[^а-яa-z]", string.Empty);
if (russianStopWords.Contains(_word.Trim()))
_word = string.Empty;
if (englishStopWords.Contains(_word.Trim()))
_word = string.Empty;
if (_word == "odins")
{
_word = "1c";
}
if (index != words.Length-1)
{
result += String.IsNullOrEmpty(_word) ? _word : _word + ' ';
}
else
{
result += String.IsNullOrEmpty(_word) ? _word : _word;
}
index++;
}
//Убираем лишние пробелы
result = Regex.Replace(result, @" +", " ");
return result;
}Обращу внимание, что на красоту и эстетичность кода мы не претендуем.
Ок, данные мы почистили, и выглядят они уже куда более лаконично, плюс датасет заметно похудел. Но осталась ещё одна немаловажная задача, которую при подготовке датасета пропустить нельзя — лемматизация. Выражаясь простым языком весь наш текст нужно привести к условным леммам. Если ещё более простым — все слова в датасете нужно привести к их «простой» форме. Какого-то очевидного решения на .NET для этого я не нашёл, поэтому появилась возможность дать R модулю второй шанс: в R есть простая библиотека SnowballC, которая для разных языков, включая кириллицу, по простому алгоритму обрезает окончания у слов. Например, слово «погода» превратится в «погод», «прыгать» в «прыг», «бегают» в «бег». Выглядит в итоге текст не очень читаемо, но читать датасет будет не человек, а машина — поэтому этот вопрос нас не беспокоит. К датасету мы снова подключили модуль R, в котором прямо в ML Studio написали маленький скрипт:
—
dataset1 <- maml.mapInputPort(1) # class: data.frame
Encoding(dataset1$description)<-'UTF-8'
library(SnowballC)
stem_text<- function(text, language = "russian", mc.cores = 1) {
# стеммим каждое слово в блоке текста
stem_string <- function(str, language) {
str <- strsplit(x = str, split = ' ')
str <- wordStem(unlist(str), language = language)
str <- paste(str, collapse = " ")
return(str)
}
# стеммим каждый блок по очереди
x <- lapply(X = text, FUN = stem_string, language)
# возвращаем преобразованные блоки текста
return(unlist(x))
}
###########
dataset1$description <- stem_text(dataset1$description)
maml.mapOutputPort("dataset1");Таким образом заявка
«У меня не работает клавиатура»
и заявка
«Моя клавиатура не работает нормально»
для машины становятся одним и тем же, так как после лемматизации и очистки текста они примут вид:
«работ клавиатур»
Пожалуй, вот и всё, что мы кодили в контексте машинного обучения. В сумме это не так много строчек кода, на достаточно популярных языках.
На переподготовку данных у меня ушло около недели, и руки снова зачесались — пора опробовать наш подготовленный датасет в деле. Награда не заставила себя ждать: подключив новый датасет, подключив к нему R модуль, после переобучения я получил 71% успешных предсказаний. Неплохо, правда? Очень, и очень неплохо.
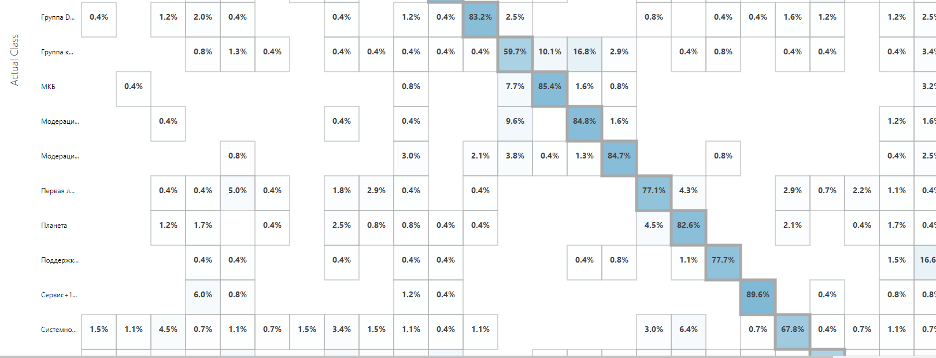
Матрица процентного соотношения успешных предсказаний категорий
Если резюмировать всё вышесказанное — мы взяли обращения пользователей, отчистили их от мусора, подключили в готовую модель — и практически из коробки получили очень неплохой помощник классификации заявок с 71% успешных предсказаний. При этом на некоторых категориях модель выдаёт >90%, и для них мы можем избавиться от ручной классификации в принципе.
Внизу статьи я приложу ссылку на нашу стартовую модель классификации в галерее Azure, если вы решите её опробовать. Всё, что нужно, это заменить первый модуль с CSV на ваш, и переименовать в вашем датасете колонки в class и description. Этот пример, конечно же, не является образцом, это ровно тот же экземпляр, который я использовал в первые дни реализации задачи. Но взглянув на него можно представить, как легко можно начать внедрять искусственный интеллект, а именно машинное обучение в свой проект, не имея специализированных знаний на старте.
Итого весь наш процесс классификации заявок можно описать в несколько этапов:
- Заявка попадает в наш сервис для классификации заявок
- Сервис очищает текст от мусора (.NET)
- Отправляет очищенный текст в облако (лемматизация в R и само предсказание)
- Облако возвращает JSON с предсказаниями
- Сериализуем JSON с предсказаниями в сервисе классификации заявок
- Сервис сопоставляет предсказанные категории с заранее подготовленными исполнителями
- Специалист видит 3 предсказания с максимальным SCORE
Для специалиста всё выглядит ещё проще — прилетает заявка от пользователя, он выбирает одну из трёх предсказанных категорий (как правило 1-ю по очереди, так как она имеет наивысший SCORE) — всё.
Таким образом мы практически полностью избавили ребят на первой линии от времени, которое они тратили на маршрутизацию заявки — больше им не нужно листать базы знаний, огромные списки с правилами классификации заявок. Раньше на это могло уходить до минуты, сейчас это буквально 5-7 секунд, чтобы по диагонали просмотреть текст заявки и выбрать исполнителя из трёхстрочного списка. Если говорить про сухие цифры – мы сэкономили 70 человеко-часов в месяц, или 40% рабочего времени каждого специалиста.
Впереди у нас повышение качества предсказаний и частичный уход от ручной классификации (полностью уйти мы не сможем, так как ребята на первой линии часто проводят первичную обработку заявки), и конечно же детальная настройка модели не в слепую, а имея бэкграунд в виде понимания за что отвечает каждый модуль. Сегодня, немного поизучав предмет, мы заменили Multiclass Logistic Regression на Two-Class Boosted Decision в паре с One vs All Multiclass, плюс поиграли с настройками N-грамм, и выиграли еще + 6%. Но это уже другая история.
Теперь разумный вопрос — во сколько нам это всё обходится? Azure берёт деньги за траффик, то есть как часто и насколько тяжёлыми данными вы обмениваетесь с ним. Учитывая наш объём в 200+ заявок ежедневно, ежемесячная плата за сервис нам обходится в ~600р, то есть около 20 рублей в день, за экономию 40% рабочего времени на одного человека — на мой взгляд это несоизмеримый профит до/после за такие деньги.
И напоследок, мораль этой истории. Если у вас небольшая команда, и вам требуется разгрузить специалистов от ручной, зачастую машинной работы, не бойтесь использовать облачные решения — сегодня это совсем не сложные с точки зрения пользователя механизмы, которые дают вам простое управление, а сложные алгоритмы работы отходят на второй план (впрочем ничего не мешает вам разобраться и в них, если есть желание и потребность в повышении качества предсказаний).
Ссылка на эксперимент в галерее Azure
Об авторе

Павел Денисов – тимлид команды поддержки внутренних продуктов в компании 2ГИС.
