Об авторе статьи
Александра Малышева — выпускница бакалавриата по направлению «Прикладная математика и информатика» Санкт-Петербургского Академического университета и выпускница магистратуры питерской Вышки по направлению «Программирование и анализ данных». Кроме того, исследовательница в лаборатории «Агентные системы и обучение с подкреплением» JetBrains Research, а также ассистентка преподавателя по обучению с подкреплением в бакалавриате Вышки.
Мотивация проекта
Довольно часто современные технологии используются для создания более интересных игр или красивых виртуальных миров. Однако прогресс в технических науках можно использовать в медицине. Например, сейчас разработка протезов является очень дорогой, поскольку требуется перебор большого количества различных конструкций. При этом для тестирования созданого протеза необходимо привлекать реальных людей, потому что на данный момент взаимодействие человека с протезами недостаточно исследовано.
В 2017 году в Стэнфордском университете ученые реализовали компьютерные симуляции опорно-двигательного аппарата человека, чтобы предсказывать, как человек адаптируется к конкретной конструкции протеза, и иметь возможность тестировать каждую конкретную конструкцию виртуально за считаные секунды. Когда в Стэнфорде команда физиков и биологов разработала точную модель опорно-двигательного аппарата человека с точки зрения физики и биомеханики, осталось написать алгоритм, который мог бы контролировать эту систему способом, похожим на управление человеком.
NeurIPS 2018: Artificial Intelligence for Prosthetics challenge
 Одним из способов получения подобного алгоритма является применение методов обучения с подкреплением, поскольку такие алгоритмы способны решать сложные задачи, адаптируясь к конкретному окружению.
Одним из способов получения подобного алгоритма является применение методов обучения с подкреплением, поскольку такие алгоритмы способны решать сложные задачи, адаптируясь к конкретному окружению. Для того чтобы мотивировать людей на создание такого алгоритма, на одной из крупнейших конференций по машинному обучению NeurIPS решили провести соревнование, в котором нужно было научить трехмерный скелет бегать со строго заданной скоростью. Для этого лаборатория Стэнфордского университета адаптировала свое окружение для соревнования Learn to Run 2017.
В одной из предыдущих статей мы рассказывали, что уже принимали участие в соревновании Learn to Walk в 2016 году. И в 2018 наша лаборатория решила участвовать в соревновании AI for Prosthetics, чтобы проверить имеющиеся идеи.
Симулятор OpenSim
Хочется подробнее рассказать об окружении, в котором проходило соревнование. В 2016 году Лаборатория нервно-мышечной биомеханики Стенфорда предоставила участникам симулятор опорно-двигательного аппарата человека OpenSim, адаптированный для обучения с подкреплением. Также они зафиксировали метрику, которая позволяет оценивать качество модели.
Задача, которую предлагается решить участникам соревнования — разработать контроллер для симуляции движений человека с протезом ноги, управляя моделью при помощи изменения напряжения мышц, и заставить модель идти или бежать с заданной скоростью, которая может изменяться со временем.
Взаимодействие со средой OpenSim разделено на эпизоды. Каждый эпизод состоит из шагов среды, в случае OpenSim каждый эпизод ограничен 1000 шагами среды, что соответствует десяти секундам реального времени. Эпизод завершается досрочно, если модель человека упала, т.е. таз оказался ниже 60 сантиметров над уровнем земли. В качестве наблюдаемого состояния среда возвращает абсолютные координаты, скорости, ускорения, углы поворота, угловые скорости и угловые ускорения частей тела, а так же напряжение мышц и скорость, с которой должен двигаться агент.
Функция награды выглядит следующим образом:
 ,
, где
 — скорость, с которой должен двигаться агент в новом состоянии,
— скорость, с которой должен двигаться агент в новом состоянии,  — скорость, с которой двигается агент,
— скорость, с которой двигается агент,  — напряжение мышц в новом состоянии. При этом целевая скорость меняется приблизительно каждые 300 шагов среды.
— напряжение мышц в новом состоянии. При этом целевая скорость меняется приблизительно каждые 300 шагов среды.Базовая реализация
Как и в предыдущем соревновании, о котором вы можете прочитать тут, мы использовали алгоритм DDPG, потому что в статье было отмечено, что он показывает наилучшее результаты по сравнению с аналогами, такими как TRPO и PPO.
Сперва мы реализовали базовые модификации, которые помогли нам начать: например, используя относительные координаты, углы и скорости вместо абсолютных, в наблюдаемом состоянии мы сильно увеличиваем скорость обучения.
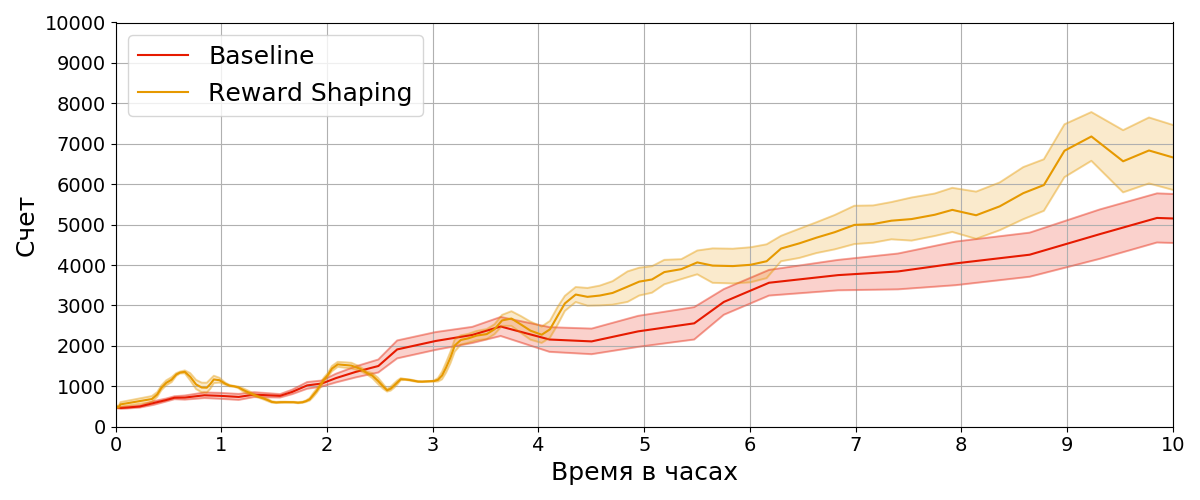
Первой протестированной модификацией является изменение наблюдаемой агентом награды на упрощенную. Мы решили убрать вычисление напряжений связок агента, так как это занимало много времени, и нормировать разницу в скоростях.


На рисунке можно увидеть, что новый агент, обученный с модифицированной наградой (Reward Shaping), статистически значимо превосходит агента, наблюдающего оригинальную награду (Baseline). Это означает, что мы смогли сэкономить вычислительные ресурсы, не просев по показателям оригинальной награды.
Feature engineering и потенциальные функции
Следующей протестированной модификацией является добавление новых признаков, таких как ускорение частей тела и скорость угловых поворотов.

Почти вся предыдущая статья посвящена потенциальным функциям. Также о них можно почитать в статье, поэтому не будем на них долго останавливаться.
Хочется лишь отметить, что в этот раз мы не смогли найти достаточно видеозаписей бегающих людей с одним протезом, поэтому нам пришлось записывать их самостоятельно. Кроме того, в этом году требовалось бежать с заданной скоростью (в отличие от прошлого года, когда надо было развить наибольшую скорость), поэтому мы использовали разные видео для разных заданных скоростей.

На графике видно, что агент, имеющий дополнительные признаки (Feature Engineering), значительно превосходит базовую реализацию агента.
Многопроцессное распределенное обучение

Среда OSim — точный физический симулятор опорно-двигательной системы человека. Для достижения высокой точности симуляции среде требуется совершать значительное количество вычислений после каждого совершенного контроллером действия. Это приводит к низкой производительности и медленной работе среды. Более того, симулятор не использует параллельные вычисления, что не позволяет ему применить все доступные вычислительные ресурсы.
Одним из возможных способов решения этой проблемы является запуск нескольких сред одновременно. Поскольку каждая среда OSim работает независимо от других и не использует параллельные вычисления, такое решение не отразится на производительности каждой запущенной среды. Но все запущенные среды в процессе обучения должны взаимодействовать с обучаемым агентом. Для выполнения этих требований был спроектирован фреймворк для распределенного многопоточного обучения. Фреймворк разделен на две части: клиент и сервер. Части взаимодействуют по сети интернет при помощи протокола HTTP.
Сервер отвечает за выполнение запросов клиента в реальных средах: перезапуск среды и совершение действия агентом. После каждого запроса сервер возвращает клиенту текущее состояние среды в качестве ответа.

Клиент, в свою очередь, также разделен на несколько частей: процессы обучения, процессы семплирования данных и взаимодействие с сервером. Для каждой реальной среды, запущенной на сервере, создается виртуальная среда, предоставляющая интерфейс реальной среды. Это позволяет клиенту взаимодействовать с удаленными средами так же, как с реальными. Поскольку для получения опыта из среды агенту требуется совершать в ней действия, в схему были добавлены процессы, отвечающие за совершение действий агентом (Model Worker). Они получают состояния из запущенных на данный момент сред и возвращают действие, которое желает совершить агент в полученном состоянии.
Для сохранения и переиспользования во время обучения опыта, полученного из OSim, используются процессы Sampling. Каждый из них хранит буфер переходов, которые наблюдал агент, и случайным образом собирает батчи данных. Собранные батчи передаются в процессы обучения, которые обновляют нейронную сеть в соответствии с выбранным алгоритмом.
Такой подход позволяет значительно повысить скорость обучения агента в низкопроизводительной среде за счет увеличения количества получаемого из среды опыта.
Результаты
Ниже приведена таблица с результатами в конце эпизодов и частотой падений обученных агентов. DDPG соответствует базовой реализации, Feature Engineering — добавлению новых признаков, Reward Shaping — наличию модификации награды, Ensembles — составлению ансамбля нескольких версий одного агента.

Данные техники помогли нам занять шестое место в общем соревновании.
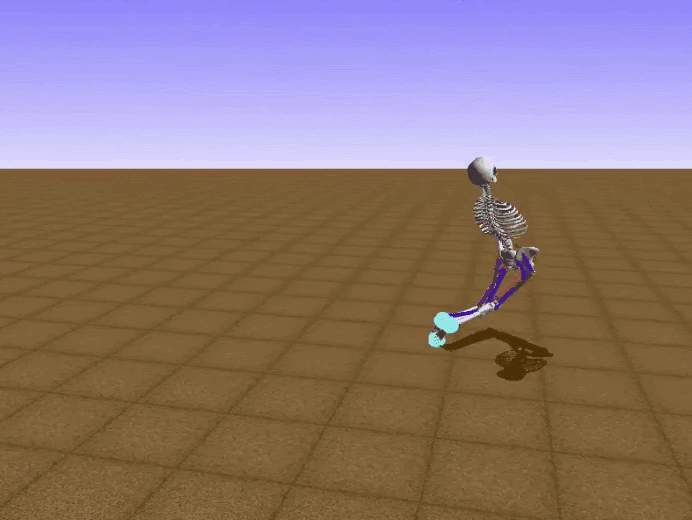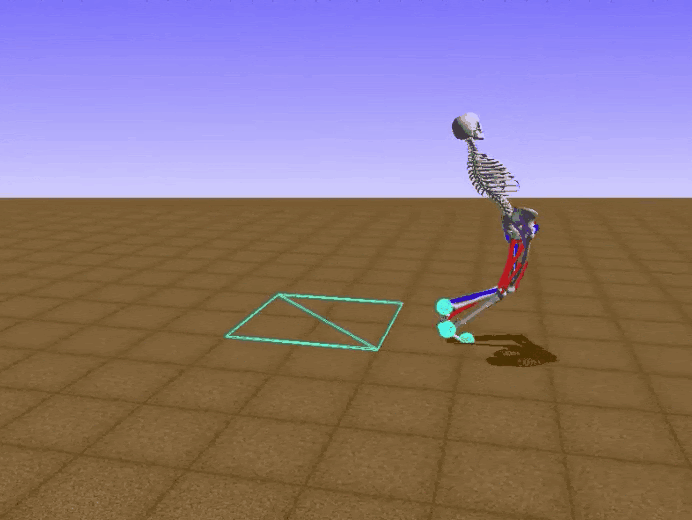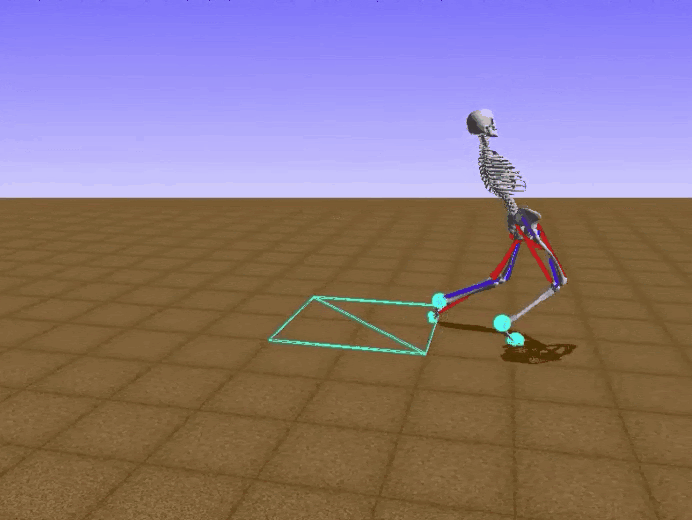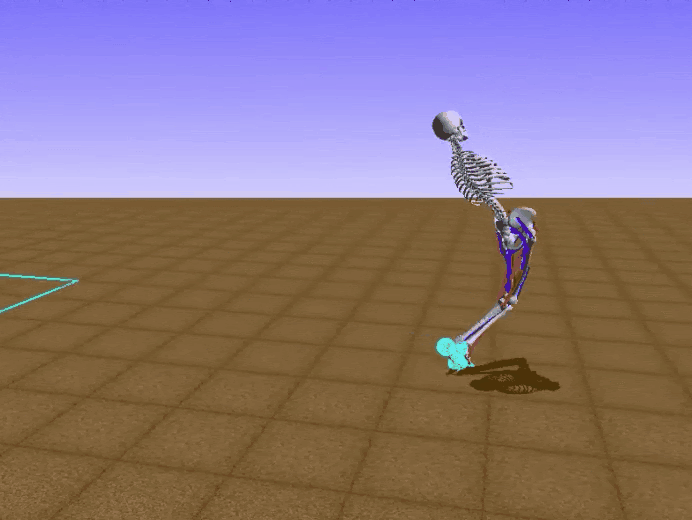
Отдельно хочется отметить, что, возможно, из-за использования потенциальных функций наш агент научился ходить «по-человечески». Для примера, ниже показаны результаты проектов, занявших два первых места, и наш :)
Результаты соперников:

Наш результат:

P.S.
Надеюсь, этот пост замотивирует вас попробовать поучаствовать в соревнованиях по обучению с подкреплением! Удачи! :)
