Двоичным деревьям поиска посвящено множество глав учебников и статей (например, раз, два, три), но они все концентрируются на общих идеях и поддержании баланса для сохранения эффективности. Методы неточного поиска, без которых двоичное дерево вообще не имеет преимущества перед реализациями без упорядочения ключей (как хэш-таблица), обычно не расписываются даже в учебниках. А в них есть интересные моменты...
Сравним стили реализации такого поиска:
- GCC STL, Clang STL
- Sestoft C5
- OpenJDK Java TreeMap
- Mozman bintrees
В названиях полный разнобой:
| Java | C++ STL | C5 | bintrees |
|---|---|---|---|
| ceilingEntry | lower_bound | weak successor(*2) | ceiling_item |
| higherEntry | upper_bound — 1(*3) | successor | succ_item(*1) |
| floorEntry | - | weak predecessor | floor_item |
| lowerEntry | - | predecessor | prev_item(*1) |
| firstEntry | begin | min | min_item |
| lastEntry | end — 1(*3) | max | max_item |
(*1) Здесь при отсутствии в дереве элемента с ключом, равным искомому, генерируется исключение. Непонятно, зачем так сделано — можно легко убрать это ограничение без потери функциональности.
(*2) Методы называются в стиле TryWeakSuccessor, FindMin.
(*3)Присутствуют только те методы, которые подходят и для других видов контейнеров STL. Но так как итераторы позволяют дёшево переходить к соседнему элементу, отсутствие части методов может быть компенсировано не выходя за пределы O(N log N).
Посмотрим на реализации на примере lower_bound и upper_bound (они же ceilingEntry и higherEntry, они же Гоша и Магоша... В сравнении опустим вопросы стиля, такие, как возврат null или возбуждение исключения, как возвращается значение (по ссылке или напрямую) и т.п.
Для примеров прохождения по дереву в поиске конкретного значения будем пользоваться простым примером (его сбалансированность не помогает и не мешает):
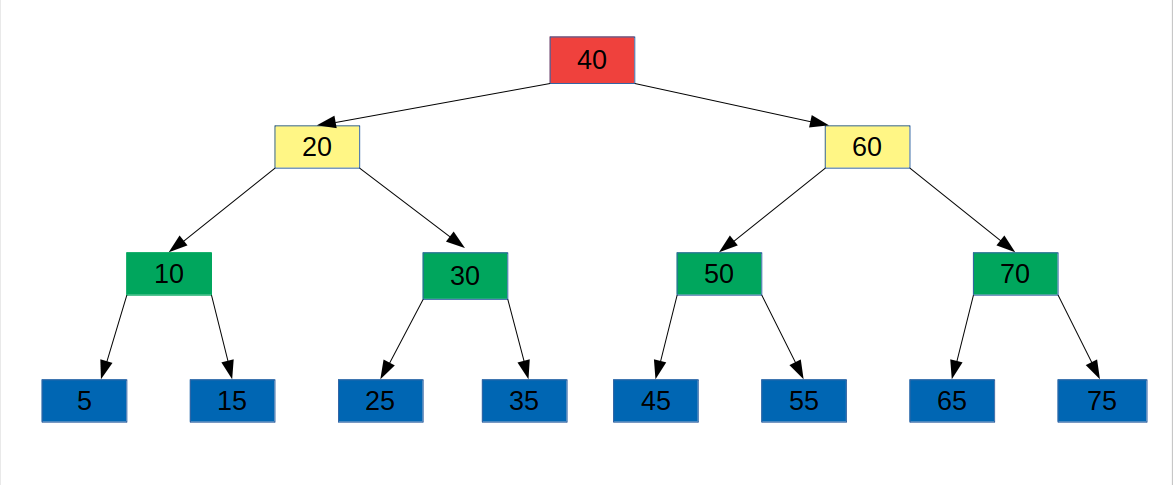
1. C5
Реализация в C5. Удобно начать с неё, как с самой интуитивно понятной вследствие стиля, в котором обычно учат теме алгоритмов.
Файл C5/Trees/TreeBag.cs, метод TreeBag<T>.TryWeakSuccessor().
public bool TryWeakSuccessor(T item, out T res)
{
[... неважное нам ...]
Node? cursor = root, bestsofar = null;
while (cursor != null)
{
int comp = comparer!.Compare(cursor.item, item);
if (comp < 0)
{
bestsofar = cursor;
cursor = Right(cursor);
}
else if (comp == 0)
{
res = cursor.item;
return true;
}
else
{
cursor = Left(cursor);
}
}
if (bestsofar == null)
{
res = default;
return false;
}
else
{
res = bestsofar.item;
return true;
}
}
Начиная с корня, проверяем значение ключа в текущем рассматриваемом узле.
- Если текущий меньше искомого, нас не интересует ни он сам, ни вся левая подветка (ключи в которой строго меньше искомого) — уходим на правую подветку.
- Если он равен искомому — результат найден, можно дальше не искать.
- Если текущий больше искомого — мы получили возможного кандидата, но надо проверить, не будет ли кандидат получше (включая точное совпадение) в левой подветке — поэтому переходим на неё.
Промежуточные кандидаты, естественно, запоминаются. Чуть менее очевидно (подумать пару секунд;)) — что не надо проверять, что следующий найденный кандидат будет лучше предыдущего (ключ будет строго меньше предыдущего).
Пример: ищем по ключу 21.
- Cursor.item == 40, идём на левую подветку, запомнили bestsofar.item == 40.
- Cursor.item == 20, идём на правую подветку.
- Cursor.item == 30, идём на левую подветку, запомнили bestsofar.item == 30.
- Cursor.item == 25, идём на левую подветку (null), запомнили bestsofar.item == 25.
Ответ: 25.
Существенно: компаратор выдаёт три варианта (меньше, равно, больше). Обычно это экономнее компаратора с выдачей только «меньше» или «не меньше»: если мы вообще добрались до сравнения элементов, почему не сделать это полностью?
Поиск для строго большего значения — тот же файл:
public bool TrySuccessor(T item, out T res)
{
Node? cursor = root, bestsofar = null;
while (cursor != null)
{
int comp = comparer!.Compare(cursor.item, item);
if (comp > 0)
{
bestsofar = cursor;
cursor = Left(cursor);
}
else if (comp == 0)
{
cursor = Right(cursor);
while (cursor != null)
{
bestsofar = cursor;
cursor = Left(cursor);
}
}
else
{
cursor = Right(cursor);
}
}
if (bestsofar == null)
{
res = default;
return false;
}
else
{
res = bestsofar.item;
return true;
}
}
Что происходит, если мы нашли точное совпадение ключа? Включается спецобработка: мы от узла с точным совпадением ищем правую подветку, а в ней — самый маленький ключ (для этого достаточно идти вниз по левым подветкам, пока есть куда). Так как в результате такого поиска оказывается cursor == null, это становится последней итерацией поиска (не нужно делать отдельный return).
Пример: ищем по ключу 20.
- Cursor.item == 40, идём на левую подветку, запомнили bestsofar.item == 40.
- Cursor.item == 20, включается спецметод.
Выходим вправо на 30, затем по левым подветкам (у нас только один шаг) — получили 25.
Ответ: 25.
Можно ли было обойтись без отдельной обработки такого случая? Да, можно было, увидев совпадение ключа, просто пойти на правую подветку. Основной цикл точно так же выполнялся бы, получая comp > 0 на каждой итерации, пока cursor != null. То есть, если заменить проверку «comp > 0» на «comp >= 0» и выкинуть весь код с «comp == 0», принципиальная работоспособность сохранилась бы.
Как искалось бы в случае того же 20?
- Cursor.item == 40, идём на левую подветку, запомнили bestsofar.item == 40.
- Cursor.item == 20, идём на правую подветку.
- Cursor.item == 30, идём на левую подветку, запомнили bestsofar.item == 30.
- Cursor.item == 25, идём на левую подветку (null), запомнили bestsofar.item == 25.
- Null — останавливаемся. Ответ: 25.
2. Mozman bintrees
Код метода CPYTHON_ABCTree.ceiling_item():
def ceiling_item(self, key):
[... неважное нам ...]
node = self._root
succ_node = None
while node is not None:
if key == node.key:
return node.key, node.value
elif key > node.key:
node = node.right
else:
if (succ_node is None) or (node.key < succ_node.key): ##N1
succ_node = node
node = node.left
if succ_node:
return succ_node.key, succ_node.value
raise KeyError(str(key))
Продвигаясь по дереву от корня (как обычно, это вверх или вниз?):
- Если ключ совпадает — выходим с результатом.
- Если у текущей вершины ключ меньше — идём направо, нас эта вершина и левая подветка не интересуют.
- Если у текущей вершины ключ больше — запоминаем её как потенциального кандидата и идём на левую подветку.
Замечания:
- Условие в if для обновления succ_node (помечено ##N1) всегда будет True. В C5 его просто не вводили. Но на производительность это заметно не влияет.
- Также мы проверяем на все три варианта (меньше, равно, больше) при прохождении одного узла. Но готового cmp() у нас нет (кстати, в Python 3 его убрали вообще… можно сымитировать, но так ли надо?) Был ли смысл в этом убирании — вопрос отдельного обсуждения.
Похожий код для поиска строго большего ключа:
def succ_item(self, key):
[...]
node = self._root
succ_node = None
while node is not None:
if key == node.key:
break
elif key < node.key:
if (succ_node is None) or (node.key < succ_node.key): ##N1
succ_node = node
node = node.left
else:
node = node.right
if node is None: # stay at dead end
raise KeyError(str(key))
# found node of key
if node.right is not None:
# find smallest node of right subtree
node = node.right
while node.left is not None:
node = node.left
if succ_node is None:
succ_node = node
elif node.key < succ_node.key:
succ_node = node
elif succ_node is None: # given key is biggest in tree
raise KeyError(str(key))
return succ_node.key, succ_node.value
Здесь логика чуть посложнее. Те же методы в случае, если ключ текущей вершины отличается от искомого; но что происходит, если мы попали на точное совпадение? Мы выходим из первого цикла, а дальше начинается тот же фокус, что в C5 — мы уходим на правую подветку и находим в ней минимальный узел.
Ещё можно заметить, что если ключа с искомым значением нет в дереве, то будет сгенерировано исключение. Например, в дереве минимальный ключ 5, а мы ищем начиная от 4… будет исключение на первом «stay at dead end». Аналогично для промежуточных значений ключей. Смысл этого ограничения непонятен; никакая из других рассмотренных реализаций не делает такого. Можно было бы без потери функциональности удалить весь второй цикл, подправив сравнение в первом цикле и возвращая параметры succ_node, если она есть.
Вдогонку отметим, что данная реализация bintrees как перенос подхода компилируемых языков оказалась неожиданно медленной по сравнению с SortedDict в Sorted Containers со всего двухуровневым хранилищем на плоских списках и дополнительным поддеревом для поиска на верхнем уровне. Но это уже специфика затрат рантайма на структуры данных Python и не портит идею двоичных деревьев per se.
3. GCC STL
исходник stl_tree.h:
...неважное сейчас определение шаблона...
_M_lower_bound(_Link_type __x, _Base_ptr __y,
const _Key& __k)
{
while (__x != 0)
if (!_M_impl._M_key_compare(_S_key(__x), __k))
__y = __x, __x = _S_left(__x);
else
__x = _S_right(__x);
return iterator(__y);
}
Метод вызывается при x указывающем на корень дерева. В отличие от предыдущих, отдельно условие равенство ключей не отрабатывается. При точном совпадении (compare даёт false) запоминаем полученное в y (в C5 оно названо лучше — bestsofar, да и succ_node из bintrees тоже даёт больше конкретики), но равно идём на продолжение (на подветку left), где гарантированно ничего не найдём, потому что там все ключи строго меньше...
Пример: ищем по ключу 30.
— key(x) == 40: идём на левую подветку, запомнили 40.
— key(x) == 30: идём на левую подветку, запомнили 30.
— key(x) == 25: идём на левую подветку (nullptr).
— x == nullptr: остановились.
Поиск строго большего значения отличается ненамного, и интересно сравнить, как это выглядит в его реализации:
_M_upper_bound(_Link_type __x, _Base_ptr __y,
const _Key& __k)
{
while (__x != 0)
if (_M_impl._M_key_compare(__k, _S_key(__x)))
__y = __x, __x = _S_left(__x);
else
__x = _S_right(__x);
return iterator(__y);
}
Отличие только в условиях сравнения — всё остальное 1:1. Если для _M_lower_bound переход на левую подветку с запоминанием узла как кандидата — выполнялся при key(x) >= k, то для _M_upper_bound — при key(x) > k. Характер сравнения замутнён тем, что _M_key_compare(a,b) выдаёт true при a<b, false в остальных случаях (см. std::less); авторы предпочли инвертировать условие в if, но сохранить идентичным код веток.
Пример: ищем по ключу 20.
- key(x) == 40: идём на левую подветку, запомнили 40.
- key(x) == 30: идём на левую подветку, запомнили 30.
- key(x) == 20: идём на правую подветку.
- key(x) == 25: идём на левую подветку (nullptr), запомнили 25.
- x == nullptr: остановились.
Если бы над этим кодом работал детектив, он бы предположил, что сначала был написан _M_upper_bound, для которого подобная реализация предельно естественна и не несёт заметных лишних затрат, а затем _M_lower_bound был для однообразности «подточен» под максимальное совпадение по строчкам кода. Мы заметим, что это не обязательно так, но оно вполне напрашивается;)) Главный вопрос — стоит ли оптимизация «если нашли точный ключ, не ищем дальше по дереву» затрат на два сравнения на каждый пройденный узел вместо одного?
Clang STL — код 1:1 с GCCʼшным, с точностью до стиля (но порядок тел после if совпадает с GCCʼшным;)) Похоже, на идею реализации влияет принципиальный дизайн STL, что компараторы (в отличие от принятого в Java, C#) проверяют только на «меньше», но не выдают три варианта (меньше/равно/больше)? Всё равно O(n log n) выполняется, так чего ж?
4. OpenJDK Java TreeMap
Реализация в TreeMap использует странный вариант (один и тот же в версиях 6..13):
final Entry<K,V> getCeilingEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
if (cmp < 0) {
if (p.left != null)
p = p.left;
else
return p;
} else if (cmp > 0) {
if (p.right != null) {
p = p.right;
} else {
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.right) {
ch = parent;
parent = parent.parent;
}
return parent;
}
} else
return p;
}
return null;
}
Здесь появляется очень странная реакция на граничный случай «хотел пойти вправо вниз, но некуда». Посмотрим, что происходит в нашем дереве при поиске по значению 39.
- На входе: key == 39, p.key == 40.
- p.key == 40: идём налево.
- p.key == 20: идём направо.
- p.key == 30: идём направо.
- p.key == 35: пошли бы направо, но детектируем, что правой подветки нет. Включается особая логика:
- Безусловно поднялись к родителю: parent.key == 30.
- Идём вверх, пока есть куда и мы были в правой подветке: один шаг, поднялись до 20.
- Финальный безусловный бросок к родителю: получили 40.
Похожий приём применён в higherEntry:
final Entry<K,V> getHigherEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
if (cmp < 0) {
if (p.left != null)
p = p.left;
else
return p;
} else {
if (p.right != null) {
p = p.right;
} else {
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.right) {
ch = parent;
parent = parent.parent;
}
return parent;
}
}
}
return null;
}
Разница: аварийный раскрут обратно к корню включается и нахождении узла с равным ключом без правой подветки. Прошлый пример с поиском по 39 остаётся в силе, но чтобы увидеть поведение при совпадении, можно заменить искомое на 35.
Изумление по сравнению с прошлыми вариантами вызывает сама необходимость такого раскрута обратно вверх по дереву (остановимся, как обычно тут, что дерево у нас инопланетное и растёт вниз). Пока мы шли по нему от корня к листьям, мы же получали все необходимые узлы — так зачем возвращаться? Сэкономили одну переменную?
В самих файлах авторы не указаны. Прежде чем задавать странные вопросы на StackExchange и тому подобных местах, хочется поговорить без возможных авторов, на взгляде со стороны и в более новых условиях :)
В заключение
Разумеется, все рассмотренные методы работают, несмотря на разнообразие подходов и видимых целей оптимизаций (странно было бы предполагать иное для столь популярных средств). Алгоритмическую корректность проверить легко — каждый может это сделать сам. Но я хотел поделиться тем, как даже в столь вроде бы простой задаче есть место пусть странному, но творчеству.
Хочется думать, что ответом на вопрос «почему???» было бы «мы сравнили производительность 100500 вариантов на тестовых данных». Тогда насколько этот результат актуален через 10-15 лет развития процессоров, рантаймов, ОС и компиляторов? (Не обещаю, но долгими зимними вечерами можно и измерить самому...)
