Все свое недлинное бытие в роли c# программиста я считал, что LINQ — это в первую очередь не про производительность кода, а про производительность программиста, как быстро он пишет код, а не как быстро сей код выполняет процессор. А проблемы с производительностью и кода и программиста, решаются после выявления «узких» мест. Посему, я часто пишу var groupedByDate = lst.GroupBy(item => item.IssueTime.Date).Select(…).ToList() и делаю так не из-за вредности или злого умысла, а просто так легче отлаживать код. Для списка достаточно поместить курсор мыши на текст переменной и сразу видно есть ли там что-то или нет.
Начало
После прочтения статьи «Неудачная статья про ускорение рефлексии» и утихания эмоций по поводу «в интернете кто-то не прав», я задался вопросом, а можно сделать «LINQ to Objects» код близким по производительности к «ручному». Почему именно «LINQ to Objects»? В своей работе я часто использую только поставщики «LINQ to Objects» и «LINQ to Entities». Производительность «LINQ to Entities», для меня не критична; критично насколько оптимальным для целевого сервера БД будет сгенерированный SQL-запрос и как быстро его выполнит сервер.
За основу я решил использовать проект автора статьи. В отличии от примеров из интернета, где в основном сравнивается код наподобие integerList.Where(item => item > 5).Sum() с «ручным» кодом, содержащим foreach, if и так далее, пример из статьи показался мне интересным и жизненным.
Первое что было мной сделано — это использование единой функции сравнения строк. В коде-первоисточнике, в методах выполняющих одну и ту же функцию, но находящихся в противоположных углах ринга, используются разные способы, в одном случае variable0.Equals(constant0, StringComparison.InvariantCultureIgnoreCase), а в другом variable0.ToUpperInvariant() ==constant0.ToUpperInvariant(). Особенно обидно за константу, которую переводят в верхний регистр каждый вызов метода. Я выбрал третий вариант с использованием в обеих случаях variable0.ToUpperInvariant() ==constant0InUpperCaseInvariant.
Далее был «выкинут» весь код, который напрямую не связан со сравнением производительности LINQ и «ручного» кода. Первым под горячую руку попался код, создающий и инициализирующий объект класса Mock<HabraDbContext>. Какой смысл создавать соединения с БД для каждого теста, один раз достаточно? Он был вынесен за рамки тестов производительности.
IStorage _db;
[GlobalSetup]
public void Setup()
{
_db = MockHelper.InstanceDb();
}
private IStorage DBInstance => _db;Для проформы запустился модифицированный тест… И — о, чудо! Метод с суффиксом Linq занимает первое место во всех «весовых» категориях!
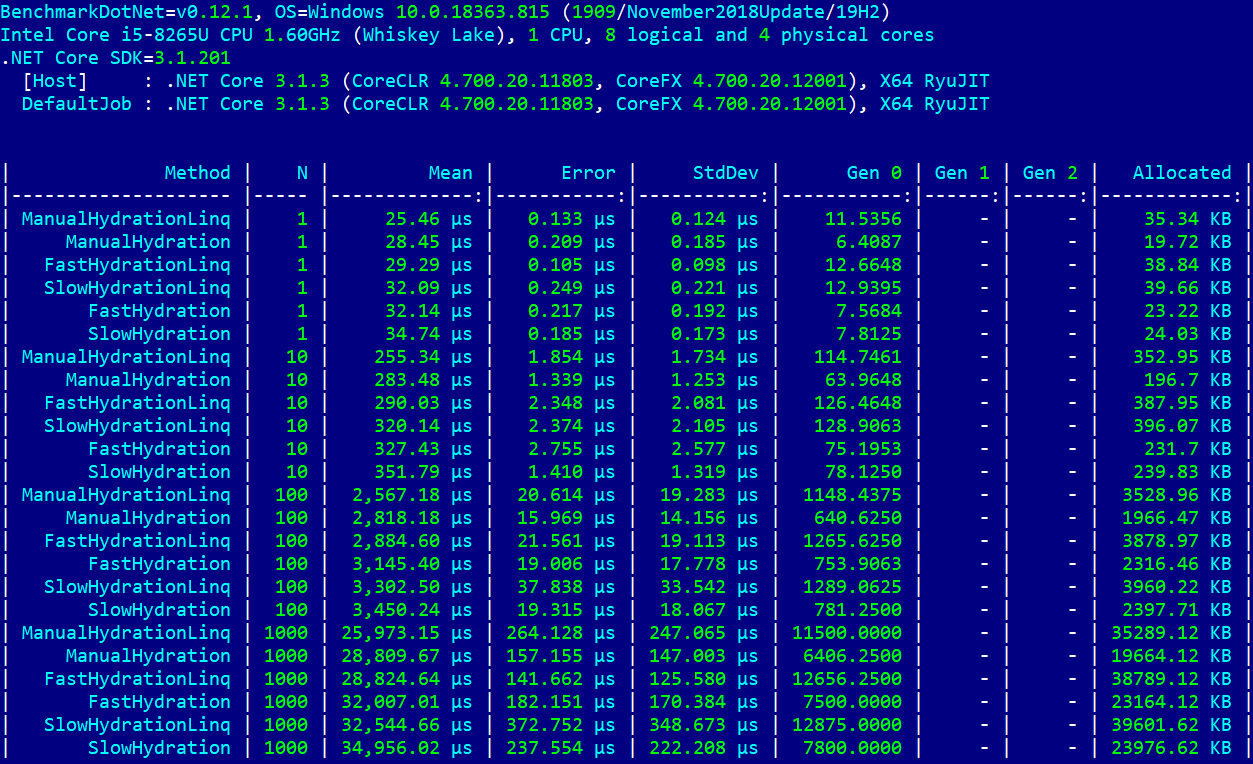
Малюсенький червячок сомнения «а может все таки в интернете кто-то не прав» отправился к праотцам. Реноме LINQ восстановлено. Новые тесты можно не писать, но рубикон перейден — продолжаем.
Цели меняются
Было решено написать свой тест производительности с нуля, перенеся туда только самое необходимое, непосредственно относящееся к противостоянию LINQ vs «ручной» код. Подробно описывать процесс написания теста не имеет смысла. Далее следуют наиболее интересные с моей точки зрения моменты. Ссылка на код будет приведена ниже.
Мне показалось, что для данного теста неудобно использовать среднеквадратическое отклонение для оценки разброса результатов, принимая во внимание, что средние величины отличаются на порядок для каждой категории ([Params(1, 10, 100, 1000)]). Захотелось увидеть колонку с коэффициентами вариации. С наскоку не удалось найти способ как добавить ее в отчет. Поиск в интернете так же не дал ответа. Был написан свой класс StatisticColumnRelStdDev.
Теперь перейдем непосредственно к задаче — переписать код класса FastHydrationLinq, так что бы его производительность приблизилась к ManualHydrationLinq — победителю исправленного теста из статьи. Как видно, цель статьи изменилась, вместо (Fast)(Manual)(Slow)HydrationLinq vs (Fast)(Manual)(Slow)Hydration, целью стала задача потягаться со скоростью исполнения ManualHydrationLinq. Тест FastHydrationLinq был выбран из-за его префикса в названии. Он просто обязан быть быстрым.
Оптимизация этого теста в основном свелась к избавлению от вызовов методов ToArray, ToDictionary и использованию универсальных шаблонов IEnumerable<T> в качестве типов возвращаемых значений различных методов. Незамысловатым путем копирования, был создан новый класс FastContactHydrator2. В нем был изменен тип хранилища списка пар ключ-объект класса Action<Contact, string> c ConcurrentDictionary<string, Action<Contact, string>> на IEnumerable<KeyValuePair<string, Action<Contact, string>>>. Был добавлен метод GetContact2, где вызов метода Sum, в завершении вызывает всю цепочку отложенных операций.
protected override Contact GetContact2(IEnumerable<PropertyToValueCorrelation> correlations)
{
var contact = new Contact();
int dummySum = _propertySettersArray.Join(correlations, propItem => propItem.Key, corrItem => corrItem.PropertyName, (prop, corr) => { prop.Value(contact, corr.Value); return 1; }).Sum();
return contact;
}Метод ParseWithLinq был переписан как
public static IEnumerable<KeyValuePair<string, string>> ParseWithLinq2(string rawData, string keyValueDelimiter = ":", string pairDelimiter = ";")
=> rawData.Split(pairDelimiter)
.Select(x => x.Split(keyValueDelimiter, StringSplitOptions.RemoveEmptyEntries))
.Select(x => x.Length == 2 ? new KeyValuePair<string, string>(x[0].Trim(), x[1].Trim())
: new KeyValuePair<string, string>(_unrecognizedKey, x[0].Trim()));Вот и вся оптимизация.
В время разработки кода класса FastContactHydrator2, в оригинальных тестах автора статьи, находились места, которые выглядели не логичными или не нужными в контексте цели моего теста и в общем, как например использование словаря как хранилища пар ключ-значение, но поиск происходит полным перебором (функции ParseWithLinq и ParseWithoutLinq). В этих местах словарь был заменен на список. В другом месте удален не нужный, в моем тесте, вызов метода ToArray. Так же было удалено магическое число 10 в коде var result = new List<PropertyToValueCorrelation>(10). Почему 10? Число 42 я бы понял, а вот 10 не могу. Так появилась серия тестов имеющих постфикс Fair в названии.
Еще пара слов об общих изменениях. Типы хранилищ исходных данных были приведены к массивам в обеих случаях. Данные возвращаемые методом GetFakeData расширены новыми ключевыми словами. Так сделано преднамеренно, что бы увеличить объем исходных данных.
Скомпилированный исполняемый файл был запущен несколько раз, и для анализа были взяты результаты тестов, которые имеют наименьший разброс значений в колонке «Коэффициент Вариации» (RelStdDev). Ими оказались тесты для N=1000.
Краткая аннотация к таблице ниже:
- Строки `ManualHydration`, `SlowHydration`, `FastHydration`, `ManualHydrationLinq`, `SlowHydrationLinq`, `FastHydrationLinq` - это тесты из первоначальной статьи, без изменений;- Строки
ManualHydrationFair,ManualHydrationFairLinq,FastHydrationFairLinq— это тесты из первоначальной статьи, из которых удалены нелогичности и ненужности; - Строка
FastHydrationLinq2— моя версия быстрого теста с использованием отложенного исполнения, которые, по-моему мнению, должны помочь компилятору произвести наиболее быстрый код для LINQ; - Колонка
Nимеет такое же назначение, что и в оригинальной статье; - Колонка
Ratioпоказывает отношение времени исполнения теста в строке к времени исполненияFastHydrationLinq2.
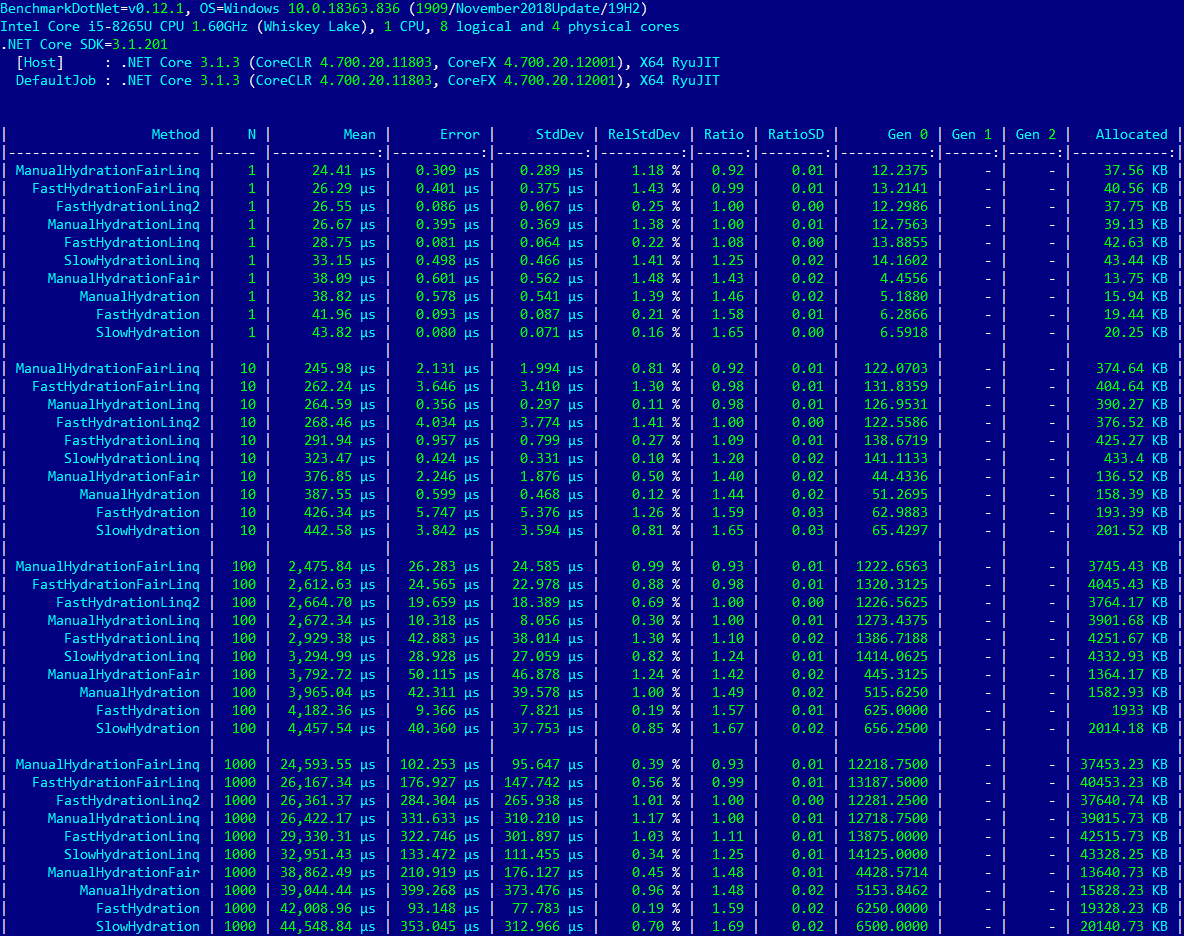
Linq-тесты в первых рядах
И что мы видим? Цель достигнута — тест FastHydrationLinq2 имеет паритет с ManualHydrationLinq в колонке Ratio. Абсолютное время исполнения 26,361.37 μs и 26,422.17 μs соответственно для N=1000. Оба теста делят третье/четверное место при всех значениях N. Абсолютным победителем стал тест ManualHydrationFairLinq, его производительность на 8% лучше, чем у теста ради которого и затеялась статья. Второе место занимает тест FastHydrationFairLinq, он выполняется примерно на 1% быстрее теста-протагониста.
Пару слов про производительность оптимизированных Fair-тестов. Как уже было указано выше, тест ManualHydrationFairLinq на 8% быстрее его не оптимизированного собрата. А FastHydrationFairLinq выигрывает у FastHydrationLinq 12%. Тесты без суффикса Linq занимают почетные три места в подвале таблицы.
Вот вроде бы и сказке конец, но постойте. Автор статьи упоминал о сборщике мусора и его отрицательное влияние на производительность. Оглядываясь назад видно, что я оптимизировал оригинальный тест путем переноса вызова метода MockHelper.InstanceDb() в метод Setup, а так же не перенес его в свой тест. Хотя этот вызов можно удалить и в оригинальном тесте — результат его исполнения нигде не используется, а данные для тестов генерируются методом GetFakeData, он все таки планомерно вызывается для каждого теста. Складывается впечатление, что единственная его цель — сгенерировать в памяти мусор. Что ж добавим MockHelper.InstanceDb() и в мой тест.
К колонке с заголовком N, добавилась колонка MakeGarbage. Для значений False мусор в памяти не генерируется, True — мусор должен присутствовать в изрядном количестве.
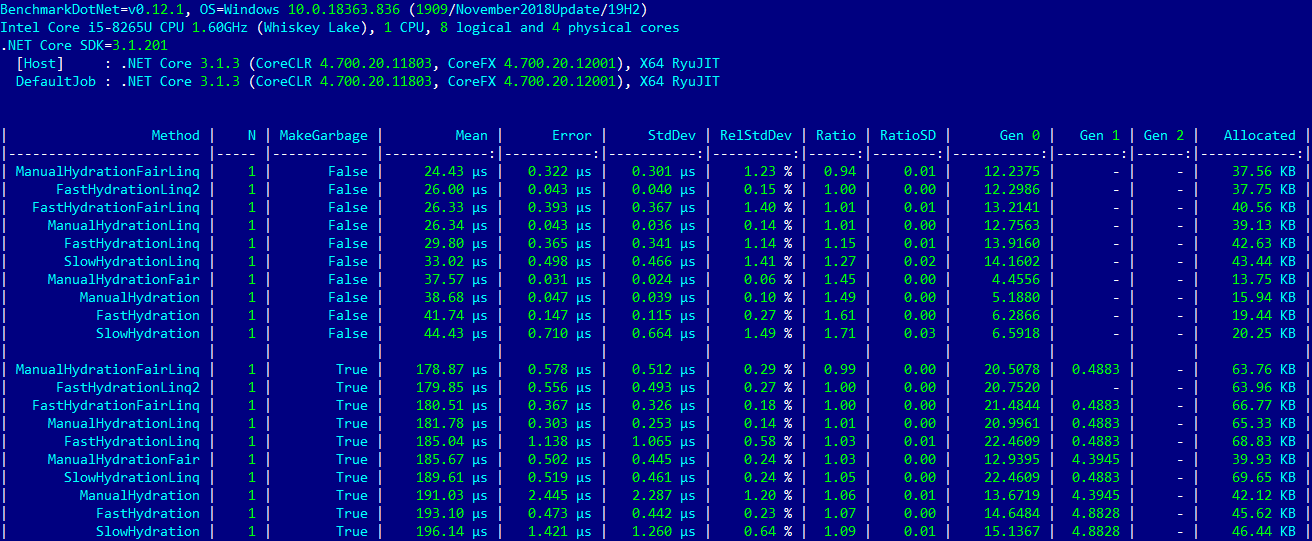
Сборщик мусора принялся за дело

Voilà, кроме размеров таблицы с результатами ничего удивительного, в тестах с мусором места разделились точно так же как и без него. Единственное значимое изменение — уменьшение разницы времени исполнения между самым быстрым и самым медленным тестами для N=1. Эта разница составляет 10% для тестов с мусором и 82% для тестов без него.
Выводы… Выводы будут немного позже.
В погоне за неуловимым Джо
После приведения моего исходного кода в опрятный вид, например были удалены тесты отдельных функций, или методы расположены в порядке «ручной» тест — Linq-тест, я запустил исполняемый файл и получил результаты похожие на результаты из оригинальной статьи:
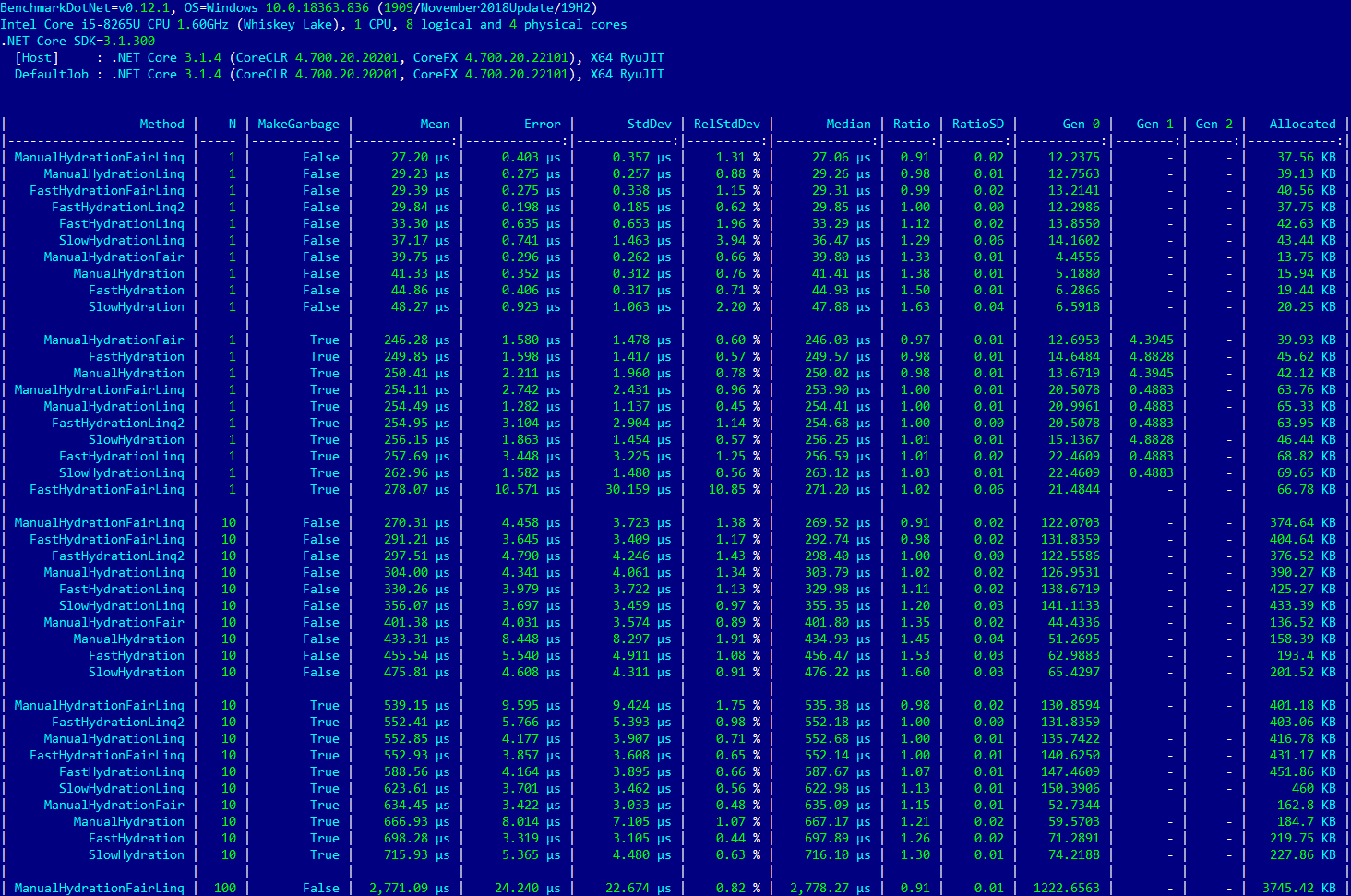
Для N=1 и MakeGarbage=True на первое место выходят «ручные» тесты
Я очень обрадовался, наконец то забрезжил лучик надежды, что удастся разобраться, с изменениями производительности LINQ при присутствии мусора в памяти.
Значения колонок «Gen X» и «Allocated» для N=1 и MakeGarbage=True в двух предыдущих таблицах примернo одинаковы, для теста FastHydrationLinq2 это
| | Gen 0 | Gen 1 | Gen 2 | Allocated |
|«Ручные» методы на первом месте | 20.5078 | 0.4883 | - | 63.95 KB |
|Linq-методы на первом месте | 20.7520 | - | - | 63.69 KB |Эти же значения для теста ManualHydrationFairLinq полностью одинаковые.
Количество выделенной памяти и количество вызовов сборщика мусора примерно одинаковы в обеих ситуациях. Не знаю верно ли это в действительности, но мое мнение, что в подобных случаях сборщик мусора должен влиять на производительность также — примерно одинаково.
Так что же так влияет на производительность одинакового кода, с одинаковыми объемами выделенной памяти и прочее? Под подозрение пал порядок вызова тестов. Для скорости выполнения, я исправляю аттрибут для N как [Params(1, 100)] и MakeGargabe=True. Начинаю пробовать различные комбинации «ручной» — Linq-код, все они давали результаты схожие с результатами на изображении выше. Опробовались различные вариации — сначала вызываются все ручные методы, второй вариант — сначала вызываются все Linq-методы, далее была комбинация Linq — Ручной — Ручной — Linq. Все без изменений — ручные тесты впереди. Значит источник проблемы не в порядке вызова.
На следующее утро, я запускаю тот же исполняемый файл для сокращенного теста, и вижу стандартную картину — Linq-тесты снова лидеры. На колу мочало, начинай сначала. Под подозрение падает запущенная программа работы с графическими изображениями paint.net, в которой я подготавливал изображения для статьи. Несколько запусков тестов с запущенным параллельно paint.net и без него — есть стойкая корреляция между тестом на первом месте и фактом нахождения paint.net в оперативной памяти. Запущен paint.net — «ручной» тест впереди, не запущен — Linq-тест впереди планеты всей.
Возвращаю тест в исходное состояние — значения N варьируются как 1, 10, 100, 1000 и переменной MakeGarbage возвращается атрибут [ParamsAllValues]. Запускаю paint.net, запускаю тест — «ручной» метод впереди. Запускаю тест еще три раза — теперь Linq-метод на первом месте. В дополнение к paint.net запускаю Visual Studio — «ручные» тесты снова на коне. Тут мне стало жалко своего времени, каждый прогон всех 80-и тестов занимает больше получаса. Пусть Джо остается неуловимым, тем более разница между самым быстрым ручным тестом и самым быстрым Linq-тестом около 2%.
Выводы
После написания тестов и анализа результатов, мое мнение о LINQ не изменилось — используя его моя производительность в написании кода выше, чем без него; с производительностью «LINQ to Objects» все в порядке. Использование отложенного исполнения LINQ-кода, как средства повышения производительности, не имеет особого смысла.
Если в каком-то проекте существуют проблемы с производительностью из-за сборщика мусора — родовой травмы .net, то вероятно выбор этой технологии был не лучшим решением.
Код моих тестов доступен здесь.
