
Эффект раздувания таблиц и индексов (bloat) широко известен и присутствует не только в Postgres. Есть способы борьбы с ним “из коробки” вроде VACUUM FULL или CLUSTER, но они блокируют таблицы во время работы и поэтому не всегда могут быть использованы.
В статье будет немного теории о том, как возникает bloat, как с ним можно бороться, о deferred constraints и о проблемах, которые они привносят в использование расширения pg_repack.
Эта статья написана на основе моего выступления на PgConf.Russia 2020.
Почему возникает bloat
В основе Postgres лежит многоверсионная модель (MVCC). Её суть в том, что каждая строка в таблице может иметь несколько версий, при этом транзакции видят не более одной из этих версий, но необязательно одну и ту же. Это позволяет работать нескольким транзакциям одновременно и практически не оказывать влияния друг на друга.
Очевидно, что все эти версии необходимо хранить. Postgres работает с памятью постранично и страница – это минимальный объём данных, который можно считать с диска либо записать. Давайте рассмотрим небольшой пример, чтобы понять как это происходит.
Допустим, у нас есть таблица, в которую мы добавили несколько записей. В первой странице файла, где хранится таблица, появились новые данные. Это живые версии строк, которые доступны другим транзакциям после коммита (для простоты будем полагать, что уровень изоляции Read Committed).
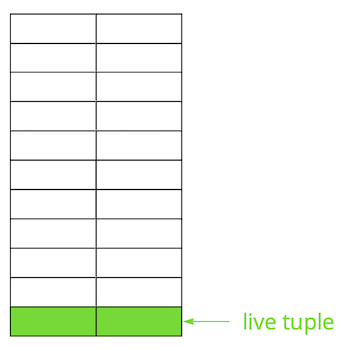
Затем мы обновили одну из записей и тем самым пометили старую версию как неактуальную.
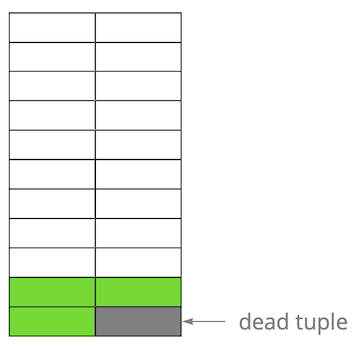
Шаг за шагом, обновляя и удаляя версии строк, мы получили страницу, в которой примерно половина данных – это “мусор”. Эти данные не видны ни одной транзакции.
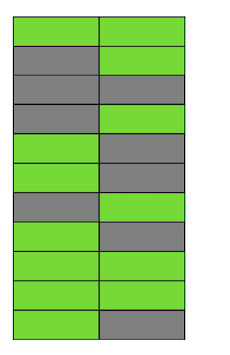
В Postgres существует механизм VACUUM, который вычищает неактуальные версии и освобождает место для новых данных. Но если он настроен не достаточно агрессивно или занят работой в других таблицах, то “мусорные данные” остаются, и нам приходится использовать дополнительные страницы для новых данных.
Так в нашем примере в какой-то момент времени таблица будет состоять из четырёх страниц, но живых данных в ней будет только половина. В результате, при обращении к таблице мы будем вычитывать гораздо больше данных, чем необходимо.
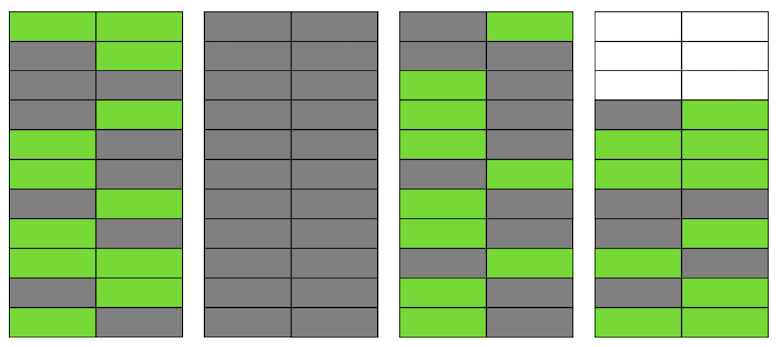
Даже если сейчас VACUUM удалит все неактуальные версии строк, ситуация не улучшится кардинально. У нас появится свободное место в страницах или даже целые страницы для новых строк, но мы по-прежнему будем вычитывать больше данных, чем нужно.
Кстати, если бы полностью пустая страница (вторая в нашем примере) оказалась в конце файла, то VACUUM смог бы её обрезать. Но сейчас она находится посередине, поэтому сделать с ней ничего не получится.
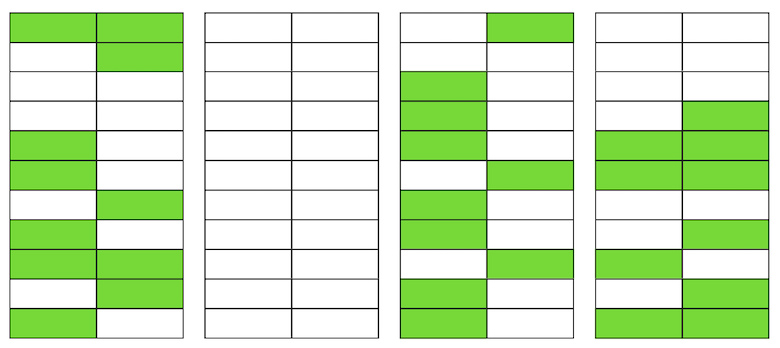
Когда количество таких пустых или сильно разряженных страниц становится большим, что и называется bloat, это начинает сказываться на производительности.
Всё описанное выше — механика возникновения bloat в таблицах. В индексах это происходит примерно так же.
А есть ли у меня bloat?
Есть несколько способов, чтобы определить, есть ли у вас bloat. Идея первого — использование внутренней статистики Postgres, в которой содержится приблизительная информация о количестве строк в таблицах, количестве “живых” строк и пр. В интернете можно найти множество вариаций уже готовых скриптов. Мы за основу взяли скрипт от PostgreSQL Experts, который может оценить bloat таблиц вместе с toast и bloat btree-индексов. По нашему опыту его погрешность составляет 10-20%.
Ещё мы использовали инструмент postgres-checkup, который помимо приблизительной оценки уровня bloat (логика оценки схожая) выдаёт много другой ценной информации о состоянии БД.
Другой способ — использовать расширение pgstattuple, которое позволять заглянуть внутрь страниц и получить как оценочное, так и точное значение bloat. Но во втором случае придется просканировать всю таблицу.
Небольшое значение bloat, до 20%, мы считаем приемлемым. Его можно считать как аналог fillfactor для таблиц и индексов. При 50% и выше могут начаться проблемы с производительностью.
Способы борьбы с bloat
В Postgres есть несколько способов борьбы с bloat “из коробки”, однако они далеко не всегда и не всем могут подойти.
Настроить AUTOVACUUM, чтобы bloat не возникал. А если точнее, чтобы он держался на приемлемом для вас уровне. Кажется, что это “капитанский” совет, но в реальности этого не всегда легко достигнуть. Например, у вас идёт активная разработка с регулярным изменением схемы данных или происходит какая-то миграция данных. Как следствие, ваш профиль нагрузки может часто меняться и, как правило, он бывает разным для разных таблиц. Значит, вам нужно постоянно работать немного на опережение и подстраивать AUTOVACUUM под меняющийся профиль каждой таблицы. Но очевидно, что сделать это непросто.
Другой распространённой причиной того, что AUTOVACUUM не успевает обрабатывать таблицы, является наличие длительных транзакций, которые не позволяют ему вычищать данные из-за того, что они доступны этим транзакциям. Рекомендация здесь также очевидна – избавиться от “висящих” транзакций и минимизировать время активных транзакций. Но если нагрузка на ваше приложение – это гибрид OLAP и OLTP, то у вас одновременно может быть как множество частых обновлений и коротких запросов, так и длительные операции – например, построение какого-либо отчета. В такой ситуации стоит задуматься о разнесении нагрузки на разные базы, что позволит провести более тонкую настройку каждой из них.
Еще один пример – даже если профиль однородный, но БД находится под очень высокой нагрузкой, то даже максимально агрессивный AUTOVACUUM может не справляться, и bloat будет возникать. Масштабирование (вертикальное либо горизонтальное) – единственное решение.
Как же быть в ситуации, когда AUTOVACUUM вы настроили, но bloat продолжает расти.
Команда VACUUM FULL перестраивает содержимое таблиц и индексов и оставляет в них только актуальные данные. Для устранения bloat она работает идеально, но во время её выполнения захватывается эксклюзивная блокировка на таблицу (AccessExclusiveLock), которая не позволят выполнять запросы к этой таблице, даже select-ы. Если вы можете позволить себе остановку вашего сервиса или его части на какое-то время (от десятков минут до нескольких часов в зависимости от размера БД и вашего железа), то этот вариант – лучший. Мы, к сожалению, не успеваем прогнать VACUUM FULL за время запланированного maintenance, поэтому такой способ нам не подходит.
Команда CLUSTER так же перестраивает содержимое таблиц, как и VACUUM FULL, при этом позволяет указать индекс, согласно которому данные будут физически упорядочены на диске (но в будущем для новых строк порядок не гарантируется). В определённых ситуациях это неплохая оптимизация для ряда запросов – с чтением нескольких записей по индексу. Недостаток у команды тот же, что у VACUUM FULL – она блокирует таблицу во время работы.
Команда REINDEX похожа на две предыдущие, но выполняет перестроение конкретного индекса или всех индексов таблицы. Блокировки чуть слабее: ShareLock на таблицу (мешает модификациям, но позволяет выполнять select) и AccessExclusiveLock на перестраиваемый индекс (блокирует запросы с использованием этого индекса). Однако в 12-й версии Postgres появился параметр CONCURRENTLY, который позволяет перестраивать индекс, не блокируя параллельное добавление, изменение или удаление записей.
В более ранних версиях Postgres можно добиться результата, схожего с REINDEX CONCURRENTLY, с помощью CREATE INDEX CONCURRENTLY. Он позволяет создать индекс без строгой блокировки (ShareUpdateExclusiveLock, который не мешает параллельным запросам), затем подменить старый индекс на новый и удалить старый индекс. Это позволяет устранить bloat индексов, не мешая работе вашего приложения. Важно учесть, что при перестроении индексов будет дополнительная нагрузка на дисковую подсистему.
Таким образом, если для индексов есть способы для устранения bloat “на горячую”, то для таблиц их нет. Тут в дело вступают различные внешние расширения: pg_repack (ранее pg_reorg), pgcompact, pgcompacttable и другие. В рамках этой статьи я не буду их сравнивать и расскажу только про pg_repack, которое после некоторой доработки мы используем у себя.
Как работает pg_repack

Допустим, у нас есть вполне себе обычная таблица – с индексами, ограничениями и, к сожалению, с bloat. Первым шагом pg_repack создаёт лог-таблицу, чтобы хранить данные обо всех изменениях во время работы. Триггер будет реплицировать эти изменения на каждый insert, update и delete. Затем создаётся таблица, аналогичная исходной по структуре, но без индексов и ограничений, чтобы не замедлять процесс вставки данных.
Далее pg_repack переносит в новую таблицу данные из старой, автоматически фильтруя все неактуальные строки, а затем создаёт индексы для новой таблицы. За время выполнения всех этих операций в лог-таблице накапливаются изменения.
Следующий шаг — перенести изменения в новую таблицу. Перенос выполняется в несколько итераций, и когда в лог-таблице остаётся менее 20 записей, pg_repack захватывает строгую блокировку, переносит последние данные и подменяет старую таблицу на новую в системных таблицах Postgres. Это единственный и очень короткий момент времени, когда вы не сможете работать с таблицей. После этого старая таблица и таблица с логами удаляются и в файловой системе освобождается место. Процесс завершён.
В теории всё выглядит отлично, что же на практике? Мы протестировали pg_repack без нагрузки и под нагрузкой, проверили его работу в случае преждевременной остановки (проще говоря, по Ctrl+C). Все тесты были положительными.
Мы отправились на прод — и тут всё пошло не так, как мы ожидали.
Первый блин на проде
На первом же кластере мы получили ошибку о нарушении уникального ограничения:
$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Это ограничение имело автосгенерированное наименование index_16508 – его создал pg_repack. По атрибутам, входящим в его состав, мы определили “наше” ограничение, которое ему соответствует. Проблема оказалось в том, что это не совсем обычное ограничение, а отложенное (deferred constraint), т.е. его проверка выполняется позже, чем sql-команда, что приводит к неожиданным последствиям.
Deferred constraints: зачем нужны и как работают
Немного теории о deferred-ограничениях.
Рассмотрим простой пример: у нас есть таблица-справочник автомобилей с двумя атрибутами – наименованием и порядком автомобиля в справочнике.
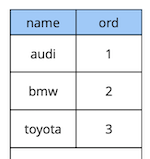
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
Допустим, нам понадобилось поменять первый и второй автомобили местами. Решение “в лоб” – обновить первое значение на второе, а второе на первое:
begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
Но при выполнении этого кода мы ожидаемо получим нарушение ограничения, потому что порядок значений в таблице уникален:
[23305] ERROR: duplicate key value violates unique constraint “uk_cars”
Detail: Key (ord)=(2) already exists.
Как сделать по-другому? Вариант первый: добавить дополнительную замену значения на порядок, которого гарантированно не существует в таблице, например “-1”. В программировании это называется “обменом значений двух переменных через третью”. Единственный недостаток этого метода – дополнительный update.
Вариант второй: перепроектировать таблицу, чтобы использовать для значения порядка тип данных с плавающей точкой вместо целых чисел. Тогда при обновлении значения с 1, например, на 2.5 первая запись автоматически “встанет” между второй и третьей. Это решение работающее, но есть два ограничения. Во-первых, оно не подойдет вам, если значение используется где-то в интерфейсе. Во-вторых, в зависимости от точности типа данных вы будете иметь ограниченное количество возможных вставок до проведения перерасчёта значений всех записей.
Вариант третий: сделать ограничение отложенным, чтобы оно проверялось только на момент коммита:
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);Поскольку логика нашего первоначального запроса гарантирует, что к моменту коммита все значения уникальны, то он выполнится успешно.
Рассмотренный выше пример, конечно, очень синтетический, но идею раскрывает. В нашем приложении мы используем отложенные ограничения для реализации логики, которая отвечает за разрешения конфликтов при одновременной работе пользователей с общими объектами-виджетами на доске. Использование таких ограничений позволяет нам сделать прикладной код немного проще.
В целом, в зависимости от типа ограничения в Postgres существует три уровня гранулярности их проверки: уровень строки, транзакции и выражения.
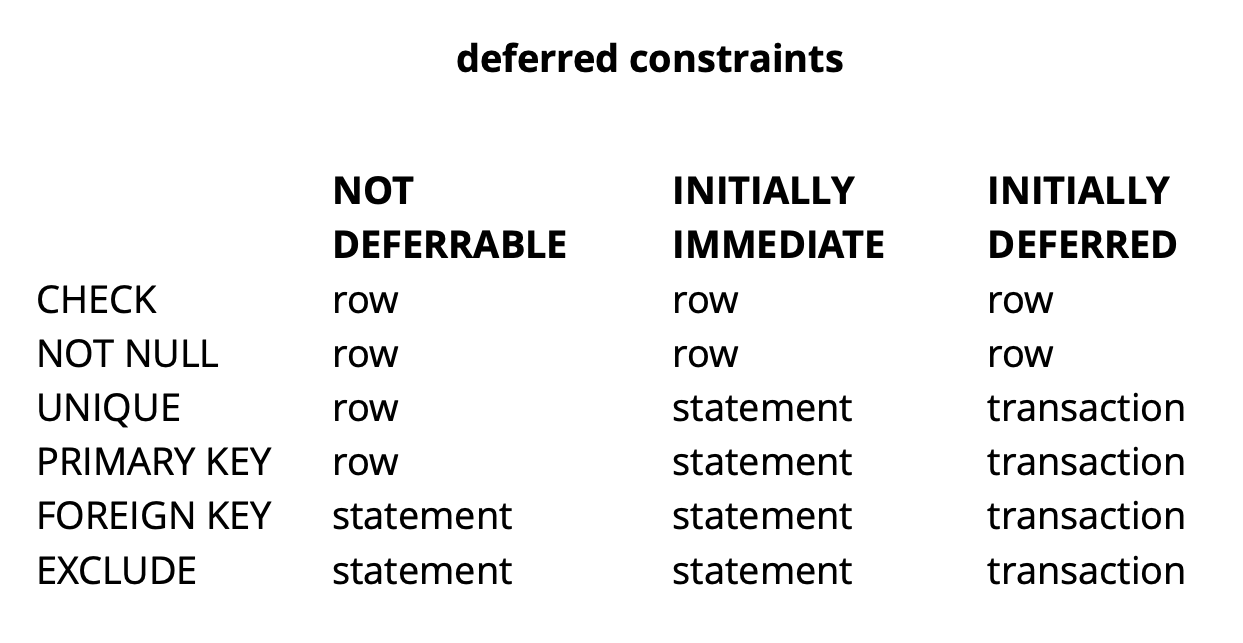
Источник: begriffs
CHECK и NOT NULL всегда проверяются на уровне строки, для остальных ограничений, как видно из таблицы, есть разные варианты. Подробнее можно почитать здесь.
Если кратко подытожить, то отложенные ограничения в ряде ситуаций дают более понятный для чтения код и меньшее количество команд. Однако за это приходится платить усложнением процесса дебага, поскольку момент возникновения ошибки и момент, когда вы о ней узнаёте, разнесены во времени. Ещё одна возможная проблема связана с тем, что планировщик не всегда может построить оптимальный план, если в запросе участвует отложенное ограничение.
Доработка pg_repack
Мы разобрались с тем, что такое отложенные ограничения, но как они связаны с нашей проблемой? Вспомним ошибку, которую мы ранее получили:
$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.Она возникает в момент копирования данных из лог-таблицы в новую таблицу. Это выглядит странно, т.к. данные в лог-таблице коммитятся вместе с данными исходной таблицы. Если они удовлетворяют ограничениям исходной таблицы, то как они могут нарушать те же самые ограничения в новой?
Как оказалось, корень проблемы таится в предыдущем шаге работы pg_repack, на котором создаются только индексы, но не ограничения: в старой таблице было уникальное ограничение, а в новой вместо него создался уникальный индекс.

Тут важно отметить, что если ограничение обычное, а не отложенное, то созданный вместо него уникальный индекс равносилен этому ограничению, т.к. уникальные ограничения в Postgres реализуются с помощью создания уникального индекса. Но в случае с отложенным ограничением поведение не одинаково, потому что индекс не может быть отложенным и всегда проверяется в момент выполнения sql-команды.
Таким образом, суть проблемы заключается в “отложенности” проверки: в исходной таблице она происходит в момент коммита, а в новой – в момент выполнения sql-команды. Значит нам нужно сделать так, чтобы проверки выполнялись одинаково в обоих случаях: либо всегда отложенно, либо всегда сразу же.
Итак, какие идеи у нас были.
Создать индекс, аналогичный deferred
Первая идея – выполнять обе проверки в режиме immediate. Это может породить несколько false positive срабатываний ограничения, но если их будет немного, то это не должно отразиться на работе пользователей, поскольку для них такие конфликты – нормальная ситуация. Они происходят, например, когда два пользователя начинают одновременно редактировать один и тот же виджет, и клиент второго пользователя не успевает получить информацию о том, что виджет уже заблокирован на редактирование первым пользователем. В такой ситуации сервер отвечает второму пользователю отказом, а его клиент откатывает изменения и блокирует виджет. Чуть позже, когда первый пользователь завершит редактирование, второй получит информацию, что виджет больше не заблокирован, и сможет повторить своё действие.

Чтобы проверки были всегда в неотложенном режиме, мы создали новый индекс, аналогичный оригинальному отложенному ограничению:
CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
-- run pg_repack
DROP INDEX CONCURRENTLY uk_tablename__immediate;На тестовом окружении мы получили всего несколько ожидаемых ошибок. Успех! Снова запустили pg_repack на проде и получили 5 ошибок на первом кластере за час работы. Это приемлемый результат. Однако уже на втором кластере количество ошибок увеличилось в разы и нам пришлось остановить pg_repack.
Почему так произошло? Вероятность возникновения ошибки зависит от того, как много пользователей работают одновременно с одними и теми же виджетами. Судя по всему, в тот момент с данными, хранящихся на первом кластере, было гораздо меньше конкурентных изменений, чем на остальных, т.е. нам просто “повезло”.
Идея не сработала. В тот момент мы видели два других варианта решения: переписать наш прикладной код, чтобы отказаться от отложенных ограничений, или “научить” pg_repack работать с ними. Мы выбрали второй.
Заменить индексы в новой таблице на отложенные ограничения из исходной таблицы
Цель доработки была очевидна – если исходная таблица имеет отложенное ограничение, то для новой нужно создавать такое ограничение, а не индекс.
Чтобы проверять наши изменения, мы написали простой тест:
- таблица с отложенным ограничением и одной записью;
- вставляем в цикле данные, которые конфликтуют с имеющейся записью;
- делаем update – данные уже не конфликтуют;
- коммитим изменения.
create table test_table
(
id serial,
val int,
constraint uk_test_table__val unique (val) deferrable initially deferred
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;Исходная версия pg_repack всегда падала на первом insert, доработанная версия работала без ошибок. Отлично.
Идём на прод и снова получаем ошибку на той же фазе копирования данных из лог-таблицы в новую:
$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.Классическая ситуация: на тестовых окружениях всё работает, а на проде — нет?!
APPLY_COUNT и стык двух батчей
Мы начали анализировать код буквально построчно и обнаружили важный момент: переливка данных из лог-таблицы в новую происходит батчами, константа APPLY_COUNT указывала на размер батча:
for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue; /* there might be still some tuples, repeat. */
...
}Проблема в том, что данные исходной транзакции, в которой несколько операций могут потенциально нарушить ограничение, при переносе могут попасть на стык двух батчей – половина команд будет закоммитчина в первом батче, а другая половина — во втором. И здесь как повезёт: если команды в первом батче ничего не нарушают, то всё хорошо, а если нарушают — происходит ошибка.
APPLY_COUNT равен 1000 записей, что объясняет, почему наши тесты проходили успешно – они не покрывали случая “стыка батчей”. Мы использовали две команды – insert и update, поэтому ровно 500 транзакций по две команды всегда помещались в батч и мы не испытывали проблем. После добавления второго update наша правка перестала работать:
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id; -- one more update
COMMIT;
END;
END LOOP;Итак, следующая задача – сделать так, чтобы данные из исходной таблицы, которые изменялись в одной транзакции, попадали в новую таблицу также внутри одной транзакции.
Отказ от батчинга
И у нас снова было два варианта решения. Первый: давайте вообще откажемся от разбиения на батчи и будем делать перенос данных одной транзакцией. В пользу этого решения была его простота – требуемые изменения кода минимальны (кстати, в более старых версиях тогда еще pg_reorg работал именно так). Но есть проблема — мы создаём длительную транзакцию, а это, как было ранее сказано, – угроза для возникновения нового bloat.
Второе решение — более сложное, но, наверное, более правильное: создать в лог-таблице столбец с идентификатором той транзакции, которая добавила данные в таблицу. Тогда при копировании данных мы сможем группировать их по этому атрибуту и гарантировать, что связанные изменения будут переноситься совместно. Батч будет формироваться из нескольких транзакций (или одной большой) и его размер будет варьироваться в зависимости от того, как много данных изменили в этих транзакциях. Важно отметить, что поскольку данные разных транзакций попадают в лог-таблицу в случайном порядке, то уже не получится читать ее последовательно, как это было раньше. seqscan при каждом запросе с фильтрацией по tx_id – это слишком дорого, нужен индекс, но и он замедлит работу метода из-за накладных расходов на его обновление. В общем, как всегда нужно чем-то жертвовать.
Итак, мы решили начать с первого варианта, как более простого. Для начала необходимо было понять будет ли длительная транзакция реальной проблемой. Поскольку основной перенос данных из старой таблицы в новую происходит также в одной длительной транзакции, то вопрос трансформировался в “насколько мы увеличим эту транзакцию?” Продолжительность первой транзакции зависит в основном от размера таблицы. Продолжительность новой – от того как много изменений накопится в таблице за время переливки данных, т.е. от интенсивности нагрузки. Прогон pg_repack происходил во время минимальной нагрузки на сервис, и объем изменений был несопоставимо мал по сравнению с исходным объемом таблицы. Мы решили, что можем пренебречь временем новой транзакции (для сравнения усредненно это 1ч и 2-3 минуты).
Эксперименты были положительны. Запуск на проде тоже. Для наглядности – картинка с размером одной из баз после прогона:
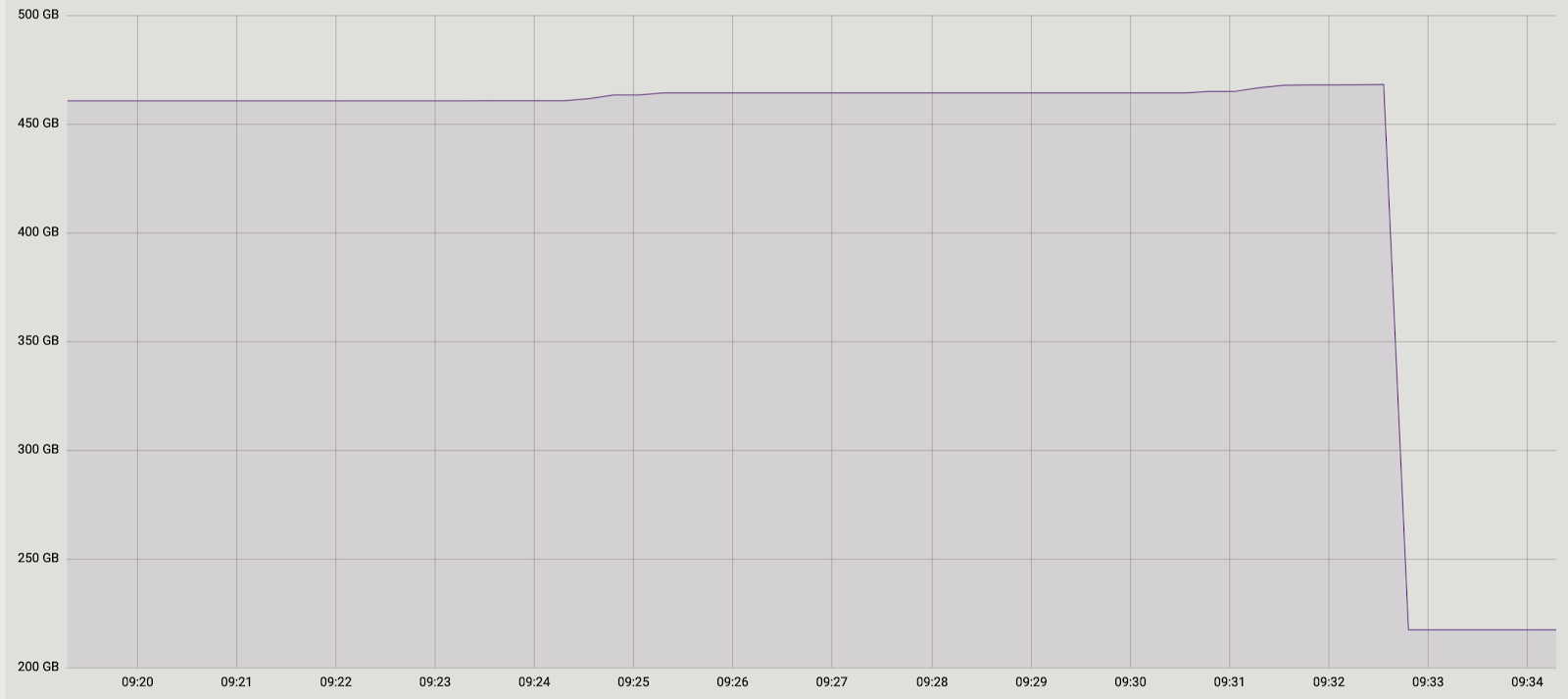
Поскольку это решение нас полностью устроило, то пробовать реализовать второе мы не стали, но рассматриваем возможность его обсуждения с разработчиками расширения. Наши текущая доработка, к сожалению, пока еще не готова к публикации, поскольку мы решили проблему только с уникальными отложенными ограничениями, а для полноценного патча необходимо сделать поддержку и других типов. Надеемся, что удастся сделать это в будущем.
Возможно, у вас возник вопрос, зачем мы вообще ввязались в эту историю с доработкой pg_repack, а не стали, например, использовать его аналоги? В какой-то момент мы тоже думали об этом, но положительный опыт его использования ранее, на таблицах без отложенных ограничений, мотивировал на то, чтобы попробовать разобраться в сути проблемы и исправить её. К тому же для использования других решений так же требуется время на проведение тестов, поэтому мы решили, что сперва попробуем исправить проблему в нем, и если поймем, что не сможем сделать это за разумное время, то тогда начнем рассматривать аналоги.
Выводы
Что мы можем рекомендовать на основе собственного опыта:
- Мониторьте ваш bloat. На основе данных мониторинга вы сможете понять, насколько хорошо настроен autovacuum.
- Настраивайте AUTOVACUUM, чтобы держать bloat на допустимом уровне.
- Если всё же bloat растет и вы не можете его побороть с помощью средств “из коробки”, не бойтесь использовать внешние расширения. Главное – все хорошо тестировать.
- Не бойтесь дорабатывать внешние решения под свои нужды – иногда этом может быть эффективнее и даже проще, чем изменение вашего собственного кода.
PS: Большое спасибо ребятам из postgres.ai за помощь в обнаружении проблемы с bloat и в поиске возможных путей решения.
