Привет, на связи Алексей Филатов (aka afilatov123). В 2017 году меня пригласили в команду «СёрчИнформ» для запуска нового программного решения. Точнее так – для наращивания возможностей флагманского продукта – DLP-системы. Рынку мало того, что софт уже умеет (предотвращать утечки информации и корпоративное мошенничество). Заказчики хотят, чтобы программа умела предсказывать пользовательское поведение: «вот этот сотрудник готовится к увольнению, а значит может...» или «человек испытывает стресс и вероятно совершит ошибку». И предсказания эти должны быть сделаны с высокой точностью и в автоматизированном формате.
Для решения этой задачи вендоры как правило идут по пути UEBA (или UBA). Но мы пошли своим и начали создавать автоматизированный профайлинг.

Под катом – история того, какой путь мы проделали, чтобы продукт состоялся.
Сразу уточню, что автоматизированный профайлинг с большими оговорками тоже можно называть анализом пользовательского поведения. Но разница в методах существенная, путаницу в терминах мы хотели бы разобрать в каком-то из ближайших постов (а то и без того объемный рассказ превратится в нескончаемую летопись).
Итак, профайлинг – давно существующая методика, но только в офлайн формате. В этом офлайн-мире существуют специалисты-профайлеры, которые на основе анализа речи, интонаций, мимики делают выводы об эмоциональном состоянии, личностных качествах человека, его криминальных наклонностях и т.д. Держать профайлера (а лучше десяток) в штате даже богатой компании – утопия. Отсюда и идея, чтобы появилась программа, которая заменит светлые головы.
Мы начали работать над ProfileCenter с выбора, что станет «сырьем» для анализа. Вариантов не так много:
Спойлер – мы взяли в разработку тексты, но сначала коротко объясню, почему отсеяли остальные варианты.
Устная речь – это доступный источник информации, потому вендоры хотят с ним работать. Да и есть хорошие научные разработки по оценке речи. В частности, самые заметные – работы Тима Полжехла (Tim Polzehl), например, Personality in Speech. А также Свати Джохар (Swati Johar), Котесвара Рао Анн (Koteswara Rao Anne), К. Сриниваса Рао (K. Sreenivasa Rao), Юте Йекош (Ute Jekosch). Но пока методика считается сырой: голосовые анализаторы умеют хорошо выявлять уровень стресса, но их способность достоверно определять личностные характеристики пока многими экспертами ставится под вопрос.
Другой вариант работы с устной речью – перевод ее в письменную с тем, чтобы в дальнейшем анализировать ее как текст. И инструменты перевода речи в буквы мы, конечно, тоже тестировали. Но до сих пор большинство офлайн-инструментов по качеству распознания нас не устроили.
Паттерны поведения – статистические показатели пользования компьютером. Например, время, которое человек проводит в том или ином приложении, программе, сколько отправляет писем и прочее. Известные UEBA (UBA)-проекты в основном работают как раз с этой информацией, выявляя, что, например, человек вдруг начал отправлять не 10, а 100 писем в день (а значит, нужно к нему присмотреться). Но эта технология до сих пор не принесла объективно хороших результатов в плане прогнозирования поведения пользователя и – опять же – оценки его личностных характеристик.
Относительно интересным параметром здесь является анализ трафика и поисковых запросов, однако он скорее говорит об актуальных интересах пользователя, а не его характере и личности.
Мимический анализ – это один из самых хорошо разработанных методов. Но в научной среде все чаще стали сомневаться в правильности этого подхода, т.к. появилось много сведений, что мимика не всегда отражает эмоциональное состояние человека и сильно «зашумлена».

С этим я как человек, непосредственно знакомый с FACS (Facial Action Coding System), тоже согласен. Оценка эмоций в основном может быть полезна с учетом контекста и точной взаимосвязи стимула и реакции. В наших условиях, это к сожалению, невозможно отследить. К тому же, если развивать идею дальше, придется столкнуться с физиогномическим анализом, а это уже чревато исследованиями в поле ненаучных знаний.
Клавиатурный почерк пока не встречает большого скепсиса в научном сообществе, есть десятки работ, которые изучали вопрос определения черт личности по тому, как человек «стучит по клавишам», но в практические модели эти работы пока не реализованы.
Сейчас эта технология узко специализирована на анализе того, как человек набирает логин и пароль и может применяться для идентификации личности. Анализ произвольных текстов же не разработан. Но даже учитывая эти ограничения, клавиатурный почерк из всех выше перечисленных источников информации для нас является самым интересным, что называется «на вырост».
И, наконец, анализ текстов. Наиболее изучен и доказан, так как письменная речь – непосредственный продукт мышления. Она отражает паттерны мышления, внутреннюю структуру личности, предпочтения, ценности и другие характеристики. Связь мышления и речи изучают две науки: в большей степени – психолингвистика, в меньшей – психосемантика. Не мы одни взяли в разработку именно письменную речь, ее как источник информации для своих продуктов используют ABBYY и Google – да много кто еще.
Есть еще один чисто технический плюс выбора письменной речи как основы для анализа – ее много, ее успешно собирает DLP-система, с которой интегрируется ProfileCenter. Так что, выбор был предопределен.
Итак, зафиксировали, что письменная речь стала для нас основным источником информации для программы. Дальнейший этап работы – создание алгоритма для очистки речи от «шума», нормализации текста. Очистить от «шума» – значит убрать из текста элементы, которые не несут смысловой нагрузки и не имеют ценности для анализа. Начать было просто: отвлеченные цифры, слова на латинице, опечатки, некоторые картинки – все отнесли к шуму.

Со знаками препинания все оказалось уже сложнее. Точку в конце предложения в бытовой переписке ставят далеко не все и нужно было для начала научиться определять, где она должна стоять. Наличие и количество запятых также является важным параметром. В то же время в Skype-переписке или социальных сетях знаки препинания практически все игнорируют.
Еще одна сложность заключалась в том, чтобы вычленить из переписки неформальное общение и анализировать тексты, в которых сотрудник выходит за рамки профессиональных и должностных обязанностей. Первый источник, который мы подключили к модулю, — почта. Из этого текста исключали вводные стандартные фразы (здравствуйте, с уважением, подпись и т.д.) и брали в аналитику только содержательную часть переписки. Однако люди пишут в email в основном сухие деловые письма и, если подключить другие источники информации (корпоративные мессенджеры, соцсети и проч.) мы получим более точный результат.
Следующим шагом для анализа подключили еще и переписку из корпоративных мессенджеров, Skype, Viber, WhatsApp, Lync, Telegram и социальных сетей.
Получили чистый текст. Дальнейший этап, он же самый сложный, – выстраивание психотипов пользователей на основе этого текста. В нашем понятийном аппарате «психотип» – это система поведенческих стереотипов, индивидуальных и ценностных установок, мотивационных, эмоциональных и коммуникативных особенностей личности, необходимых для описания разницы между людьми.
Психотипологий в трудах ученых существует множество, но в главном они дублируют друг друга. Мы больше опирались на труды Личко, Леонгарда, Собчик, Глухова, Косински, Салигмана, Белянина и модель структурно-динамичного профайлинга Psychea.
В результате синтеза этих типологий, мы сейчас опираемся на восемь психотипов с условными названиями: истероидный, эпилептоидный, паранояльный, эмотивный, тревожный, гипертимный, шизоидный и критикующий.
Первая гипотеза была такая: под каждый психотип нужно сформировать лексический словарь, находить совпадения в лексиконе человека и относить его к одному из восьми типов. Например, известно, что люди шизоидного типа больше употребляют низкочастотные слова («мюзле» вместо «проволка» или «октоторп» вместо #) и длинные, а эпилептоидного типа больше других любят глаголы.
Но это выводы на уровне эмпирических наблюдений. Если пытаться переводить их в алгоритмы, идея становится нереализуемой: словари оказываются слишком большие, каждому слову нужно присваивать вес (его значимость в общей формуле типажа). Кто может присвоить этот вес? Эксперт-профайлер. Предположим, что даже найдется такой абстрактный «Алексей Филатов», который возьмется за труд перелопатить все слова русского языка на предмет того, насколько каждое отвечает лексикону шизоида или эпилептоида. Но даже в таком утопичном варианте это будет субъективной оценкой конкретного эксперта.
А вот словари частотности того, какие слова употребляет человек в зависимости от выраженности отдельных личностных качеств, – совсем другое дело. Они у исследователей-психолингвистов есть. Но и то по значимости для анализа эта переменная в формуле не на первом месте. Потому что гораздо более важным является не то что говорит человек, а как: какие части речи использует, как составляет фразы, какую применяет морфологию и т.д. Многие из этих параметров описаны в корпусе русского языка, а это уже отправная точка для составления формул.
Еще важный момент. Для того, чтобы сказать про выраженность тех или иных личностных качеств у человека, нужна отправная точка. Человек не может быть просто мотивированным на деньги или просто конфликтным, он мотивирован или конфликтен только в сравнении с кем-то другим. Поэтому условной «нормой» для программы служит медианное значение личностных качеств по коллективу. Минимальная его численность для корректности вычисления медианного значения должна быть 20 человек.
В итоге алгоритм вычислений – от момента сбора текста пользователя до финального причисления его к тому или иному психотипу – был выбран такой:
Было решено, что в интерфейсе программы пользователь в лице специалиста службы безопасности или HR видит не итог вычислений в виде психотипа, а промежуточный этап вычислений. То есть раскладку по личностным качествам. Это более информативно. А сам психотип мы отображаем в так называемом расширенном отчете.
С алгоритмом вычислений определились. Как проверить формулу и как корректировать, на ком проверять? Испытуемыми для этих целей стали сами сотрудники «СёрчИнформ» – отобрали 102 человека. Их я с помощью коллег-профайлеров профилировал вручную. Испытуемые прошли три стандартизированных опросника: опросник 5PFQ (т.н. «большая пятерка»), опросник Шварца, опросники Л.Н.Собчик СМИЛ и ИТО. Затем мы сравнивали результаты с теми данными, что выдавала программа.
По шкалам результаты были разные – от 57% до 94%. Великолепно определялись шкалы экстраверсии/интроверсии, тревожность, конфликтность, активность и др. Хуже результаты оказались, например, по показателю «амбициозность».
По полученной статистике формулу корректировали, в результате мы «зашили» в нее больше 70 переменных (например, индекс страдательного залога, индекс длины слова, предложения, имен собственных и др.) и вес каждого.
Долго пришлось поработать над определением минимально достаточного количества письменного материала для анализа. Сейчас остановились на 20 тысячах лемм (лемма – неизменная форма слова). Но начинали анализ с 50 тысяч, сокращая этот объем с шагом в 5 тысяч.
Один из самых частых вопросов – почему мы до сих пор не реализовали возможность оценки стороннего текста пользователя, взятого из открытых источников? Мол, зачем ждать накопления 20 тысяч лемм, если можно в сети взять текст конкретного пользователя и проанализировать его по тем же критериям? Технически это возможно, но тогда в программу нужно загружать информацию не по одному человеку, а по коллективу сотрудников или людей схожих профессий (выше описывал, почему).
Когда была готова рабочая модель – примерно два года назад – начали тестировать (MVP) программу не только на собственных сотрудниках, но и на сотрудниках нескольких десятков клиентов, которые дали согласие на участие в эксперименте. К октябрю-ноябрю 2018 года получили хорошо работающий продукт. Мы были уверены, что он выдает качественные данные по т.н. первичным личностным качествам (которые мы можем перепроверить с помощью опросника).
Точность результатов готового модуля эксперты-профайлеры и клиенты оценивали в 75–80%. Для задачи, решения которой никто раньше не предлагал, это хорошие показатели. Главное, что этого достаточно, чтобы решать задачи бизнеса.

Остались линии, за которые мы пока не можем выйти. Чтобы создать психологический портрет максимально качественно, нужно две-четыре модальности: текст, интонации, трафик и др. Когда мы добавим в модуль анализ голоса, социальных сетей, клавиатурного почерка, качество реализации будет еще лучше. Но эти задачи решаются довольно сложно (рассказывал выше). Каждый следующий процент точности расчета нашего модуля дается со все большим трудом.
Примерно с теми же ограничениями сталкиваемся, пытаясь выстроить профили по тем людям, которые пишут мало и чей словарный запас, скажем прямо, беден. Речь про тех пользователей, общение которых сводится к «привет», «ок» и «давай». Выстроить корректный профиль только на основе письменной речи по ним сложно.
Продукт всех изысканий, описанных выше, – это краткий профиль личности. Как я говорил, это первичная информация, «сырье», чтобы на нем делать более развернутые выводы как об одном человеке, так и коллективе.
В кратком профиле нам нужно было создать такой портрет пользователя, в котором отражались бы принципиально важные характеристики с точки зрения специалиста службы безопасности и службы ИБ: сильные/слабые стороны, принципиальные отличия сотрудника от других пользователей, общий типаж, криминальные тенденции, ценности и рекомендации.
В итоге в кратком профиле выделяем три самых сильных и три самых слабых черты личности.
Это выглядит, например, так:

(Это, кстати, скриншот профиля одного сильного руководителя).
Дальше составляем индекс личностных качеств. Зачем он нам нужен? Не все личностные качества одинаково… стабильны. Проявление некоторых сильно зависит от контекста, и без какой-то исходной точки сделать вывод о выраженности качества невозможно.
Например, когда можно сказать про человека, что он конфликтный? Когда он начинает ругаться матом? Бить других? Стрелять? А вот если делать вывод о конфликтности в сравнении с противоположным качеством (в дихотомии), сможем понять, насколько выражены оба. То есть человек более отзывчивый, вежливый, чем конфликтный.

Еще в кратком профиле определяем криминальные тенденции (не забываем, что наш ProfileCenter – продукт в первую очередь для служб безопасности).
Для того, чтобы определить риски по каждому профилю, снова обращались к психологии, выделяли на языке экономической и информационной безопасности риски, которые заложены в личностных качествах. Например, конфликтность, болтливость, темная триада личности (манипулятивность), лидерские качества, эмоциональность. Есть исследования, которые позволили эти данные сопоставить и вывести рекомендации. Здесь мы ориентировались на большое количество работ не только в области криминологии, криминальной психологии и криминального профайлинга, но и по кадровой безопасности и управлению кадровыми рисками.
Для вычисления амбициозности мы составили собственные лингвистические формулы. Для выбора переменных формул расчета базовых ценностей взяли научные разработки Белянина и Шварца.
Вот так все это выглядит полностью. Отчет по краткому профилю:

Что дальше? Имея информацию о личностных качествах, мы взялись за создание рейтингов, так как это полезная функция для нашей целевой аудитории – специалистов служб безопасности и ИБ-спецов в частности. Они говорили нам: у нас 5000 пользователей, за всеми не уследишь. Если бы вы смогли сузить нам фокус внимания (выявить группы риска), мы бы знали, за кем наблюдать пристальнее.
Сложность на этом этапе была не технологическая, а методологическая. Так как недостаточно просто взять и рейтинговать всех пользователей по каждому качеству. Для служб безопасности информативны «синтетические» свойства личности, то есть не конфликтность, а скандальность, не стремление к взаимодействию, а лидерство. Скандальность и лидерство имеют в своем составе несколько показателей из краткого профиля. Чтобы составить формулу для каждого рейтинга, определить в ней вес каждого качества, мы снова обращались к психосемантике и психолингвистике. Переработали не меньше 35 работ на русском и английском. В итоге сейчас программа дает 12 рейтингов, на базе которых можно создавать свои собственные.
 Рейтинги могут определять группы риска тех сотрудников, которые готовятся к увольнению, демотивированных, агрессивных, скандальных и пр. И наоборот, с помощью рейтингов можно создавать группы кадрового резерва. Мы, кстати, очень хорошо умеем прогнозировать увольнение сотрудника, его выгорание, высокий лидерский потенциал.
Рейтинги могут определять группы риска тех сотрудников, которые готовятся к увольнению, демотивированных, агрессивных, скандальных и пр. И наоборот, с помощью рейтингов можно создавать группы кадрового резерва. Мы, кстати, очень хорошо умеем прогнозировать увольнение сотрудника, его выгорание, высокий лидерский потенциал.
В принципе те же технические и методические задачи из психолингвистики стояли и при создании расширенного профиля и динамики профиля – выбор переменных для формул и определение веса значения каждого.
В расширенном профиле сделали дополнительные отчеты, которые сильно расширяют область применения программы, т.к. по сути они дают информацию о ключевых компетенциях пользователя. Их обычно оценивают кадровики и управленцы по компетенциям SHL (потребность во власти и контроле, в согласии, экстраверсия, общий интеллект, открытость новому, обязательность, эмоциональная стабильность, мотивация достижений).
Динамика изменения профиля – по отчету можно получать предупреждения, если что-то с человеком происходит, если он вырывается в лидеры значимых для ИБ-специалистов рейтингов.

Тому, что мы смогли создать отчет по динамике, я придаю большое значение. Почему это было важно сделать? Если в течении 2-3-4 месяцев профиль и рейтинги пользователя после нескольких перерасчетов сохраняются в целом стабильными, то это показатель того, что найдено так называемое типовое поведение пользователя.
А значит – решена ключевая задача поведенческого анализа в ИБ.
Но как ни странно, повозиться пришлось не только с техническими, методическими проблемами. Вопрос о графическом представлении результатов вызывал не меньшие дискуссии. В моей голове интерфейс выглядел совсем иначе, чем сейчас. Но важно было думать о том, как с продуктом удобнее будет работать клиентам.

Дизайнер работал в авральном режиме, пересмотрели десятки вариантов. Критике подвергался каждый элемент: визуализация индекса личностных качеств, известная в команде проекта как «батарейка», пиктограммы для обозначения базовых ценностей и уровня амбиций, блок с рекомендациями.

Интерфейс «КИБ Сёрчинформ ProfileCenter», который вышел в релиз в 2018 году
Еще один момент — терминология. Как выбрать такие правильные с точки зрения науки, но информативные для наших пользователей названия личностных качеств, рейтингов? Например, в первой версии мы ввели параметр «азартность». В психологии это означает вовлеченность в процесс, а для большинства людей, — «приверженность к азартным играм».
Из-за разночтений в терминологии альфа-версия вызвала неоднозначную оценку, так что в финальном варианте отчета появились определения и краткие пояснения терминов.
Дискуссии продолжаются и сейчас, каждый раз, когда вводим новый рейтинг и нужно определиться с емким, но понятным непсихологам названием. Надо отметить, что тот же путь мы проходим и в иностранной лексике – в прошлом году релиз состоялся на английском языке.
Что еще дорабатываем? Пока идет работа над усовершенствованием отчетов. Сейчас модуль может формировать около 78 000 вариантов расширенных профилей сотрудников, умеет определять риск-рейтинг пользователя. ProfileCenter интегрируется с DLP-системой «СёрчИнформ КИБ», и нужно чтобы он научился находить корреляции с инцидентами и поведением человека.
Мы работаем над интеграцией модуля детекции клавиатурного почерка в состав ProfileCenter, составлением расширенного отчета и дополнительных рисков в области кадровой и информационной безопасности – в общем, вариантов, как нарастить возможности ПО, еще много.
В целом рынок активно развивается в этом направлении и уже появляются последователи, которые пробуют автоматизированно оценивать риски сотрудников в области ИБ. Но подчеркну, что такая работа может быть перспективной на стыке нескольких «модальностей» – когда одновременно в анализе учитывается как минимум не только «техническая», но и психолингвистическая информация: а лучше – даже больше.
Если мой длинный рассказ о профайлинге вас не отпугнул, а больше заинтересовал темой, приглашаю с понедельника на курс «Профайлинг для службы ИБ» – 5 занятий, которые мы в «СёрчИнформ» проводим очно и платно будут доступны онлайн и бесплатно (все из-за карантина, чего же еще).
Список тем:
Зарегистрироваться можно по ссылке.
Для решения этой задачи вендоры как правило идут по пути UEBA (или UBA). Но мы пошли своим и начали создавать автоматизированный профайлинг.

Под катом – история того, какой путь мы проделали, чтобы продукт состоялся.
Сразу уточню, что автоматизированный профайлинг с большими оговорками тоже можно называть анализом пользовательского поведения. Но разница в методах существенная, путаницу в терминах мы хотели бы разобрать в каком-то из ближайших постов (а то и без того объемный рассказ превратится в нескончаемую летопись).
Итак, профайлинг – давно существующая методика, но только в офлайн формате. В этом офлайн-мире существуют специалисты-профайлеры, которые на основе анализа речи, интонаций, мимики делают выводы об эмоциональном состоянии, личностных качествах человека, его криминальных наклонностях и т.д. Держать профайлера (а лучше десяток) в штате даже богатой компании – утопия. Отсюда и идея, чтобы появилась программа, которая заменит светлые головы.
Мы начали работать над ProfileCenter с выбора, что станет «сырьем» для анализа. Вариантов не так много:
- устная речь – для оценки лингвистики и характеристик голоса;
- клавиатурный почерк;
- интернет-трафик и другие паттерны взаимодействия пользователя с компьютером;
- мимика;
- тексты пользователей.
Спойлер – мы взяли в разработку тексты, но сначала коротко объясню, почему отсеяли остальные варианты.
Устная речь – это доступный источник информации, потому вендоры хотят с ним работать. Да и есть хорошие научные разработки по оценке речи. В частности, самые заметные – работы Тима Полжехла (Tim Polzehl), например, Personality in Speech. А также Свати Джохар (Swati Johar), Котесвара Рао Анн (Koteswara Rao Anne), К. Сриниваса Рао (K. Sreenivasa Rao), Юте Йекош (Ute Jekosch). Но пока методика считается сырой: голосовые анализаторы умеют хорошо выявлять уровень стресса, но их способность достоверно определять личностные характеристики пока многими экспертами ставится под вопрос.
Другой вариант работы с устной речью – перевод ее в письменную с тем, чтобы в дальнейшем анализировать ее как текст. И инструменты перевода речи в буквы мы, конечно, тоже тестировали. Но до сих пор большинство офлайн-инструментов по качеству распознания нас не устроили.
Паттерны поведения – статистические показатели пользования компьютером. Например, время, которое человек проводит в том или ином приложении, программе, сколько отправляет писем и прочее. Известные UEBA (UBA)-проекты в основном работают как раз с этой информацией, выявляя, что, например, человек вдруг начал отправлять не 10, а 100 писем в день (а значит, нужно к нему присмотреться). Но эта технология до сих пор не принесла объективно хороших результатов в плане прогнозирования поведения пользователя и – опять же – оценки его личностных характеристик.
Относительно интересным параметром здесь является анализ трафика и поисковых запросов, однако он скорее говорит об актуальных интересах пользователя, а не его характере и личности.
Мимический анализ – это один из самых хорошо разработанных методов. Но в научной среде все чаще стали сомневаться в правильности этого подхода, т.к. появилось много сведений, что мимика не всегда отражает эмоциональное состояние человека и сильно «зашумлена».

С этим я как человек, непосредственно знакомый с FACS (Facial Action Coding System), тоже согласен. Оценка эмоций в основном может быть полезна с учетом контекста и точной взаимосвязи стимула и реакции. В наших условиях, это к сожалению, невозможно отследить. К тому же, если развивать идею дальше, придется столкнуться с физиогномическим анализом, а это уже чревато исследованиями в поле ненаучных знаний.
Клавиатурный почерк пока не встречает большого скепсиса в научном сообществе, есть десятки работ, которые изучали вопрос определения черт личности по тому, как человек «стучит по клавишам», но в практические модели эти работы пока не реализованы.
Сейчас эта технология узко специализирована на анализе того, как человек набирает логин и пароль и может применяться для идентификации личности. Анализ произвольных текстов же не разработан. Но даже учитывая эти ограничения, клавиатурный почерк из всех выше перечисленных источников информации для нас является самым интересным, что называется «на вырост».
И, наконец, анализ текстов. Наиболее изучен и доказан, так как письменная речь – непосредственный продукт мышления. Она отражает паттерны мышления, внутреннюю структуру личности, предпочтения, ценности и другие характеристики. Связь мышления и речи изучают две науки: в большей степени – психолингвистика, в меньшей – психосемантика. Не мы одни взяли в разработку именно письменную речь, ее как источник информации для своих продуктов используют ABBYY и Google – да много кто еще.
Есть еще один чисто технический плюс выбора письменной речи как основы для анализа – ее много, ее успешно собирает DLP-система, с которой интегрируется ProfileCenter. Так что, выбор был предопределен.
Что считать шумом и как чистить текст
Итак, зафиксировали, что письменная речь стала для нас основным источником информации для программы. Дальнейший этап работы – создание алгоритма для очистки речи от «шума», нормализации текста. Очистить от «шума» – значит убрать из текста элементы, которые не несут смысловой нагрузки и не имеют ценности для анализа. Начать было просто: отвлеченные цифры, слова на латинице, опечатки, некоторые картинки – все отнесли к шуму.

Со знаками препинания все оказалось уже сложнее. Точку в конце предложения в бытовой переписке ставят далеко не все и нужно было для начала научиться определять, где она должна стоять. Наличие и количество запятых также является важным параметром. В то же время в Skype-переписке или социальных сетях знаки препинания практически все игнорируют.
Еще одна сложность заключалась в том, чтобы вычленить из переписки неформальное общение и анализировать тексты, в которых сотрудник выходит за рамки профессиональных и должностных обязанностей. Первый источник, который мы подключили к модулю, — почта. Из этого текста исключали вводные стандартные фразы (здравствуйте, с уважением, подпись и т.д.) и брали в аналитику только содержательную часть переписки. Однако люди пишут в email в основном сухие деловые письма и, если подключить другие источники информации (корпоративные мессенджеры, соцсети и проч.) мы получим более точный результат.
Следующим шагом для анализа подключили еще и переписку из корпоративных мессенджеров, Skype, Viber, WhatsApp, Lync, Telegram и социальных сетей.
Работа с очищенным текстом
Получили чистый текст. Дальнейший этап, он же самый сложный, – выстраивание психотипов пользователей на основе этого текста. В нашем понятийном аппарате «психотип» – это система поведенческих стереотипов, индивидуальных и ценностных установок, мотивационных, эмоциональных и коммуникативных особенностей личности, необходимых для описания разницы между людьми.
Психотипологий в трудах ученых существует множество, но в главном они дублируют друг друга. Мы больше опирались на труды Личко, Леонгарда, Собчик, Глухова, Косински, Салигмана, Белянина и модель структурно-динамичного профайлинга Psychea.
В результате синтеза этих типологий, мы сейчас опираемся на восемь психотипов с условными названиями: истероидный, эпилептоидный, паранояльный, эмотивный, тревожный, гипертимный, шизоидный и критикующий.
Но как проанализировать в автоматизированном формате текст так, чтобы отнести его автора к одному из восьми типов?
Первая гипотеза была такая: под каждый психотип нужно сформировать лексический словарь, находить совпадения в лексиконе человека и относить его к одному из восьми типов. Например, известно, что люди шизоидного типа больше употребляют низкочастотные слова («мюзле» вместо «проволка» или «октоторп» вместо #) и длинные, а эпилептоидного типа больше других любят глаголы.
Но это выводы на уровне эмпирических наблюдений. Если пытаться переводить их в алгоритмы, идея становится нереализуемой: словари оказываются слишком большие, каждому слову нужно присваивать вес (его значимость в общей формуле типажа). Кто может присвоить этот вес? Эксперт-профайлер. Предположим, что даже найдется такой абстрактный «Алексей Филатов», который возьмется за труд перелопатить все слова русского языка на предмет того, насколько каждое отвечает лексикону шизоида или эпилептоида. Но даже в таком утопичном варианте это будет субъективной оценкой конкретного эксперта.
А вот словари частотности того, какие слова употребляет человек в зависимости от выраженности отдельных личностных качеств, – совсем другое дело. Они у исследователей-психолингвистов есть. Но и то по значимости для анализа эта переменная в формуле не на первом месте. Потому что гораздо более важным является не то что говорит человек, а как: какие части речи использует, как составляет фразы, какую применяет морфологию и т.д. Многие из этих параметров описаны в корпусе русского языка, а это уже отправная точка для составления формул.
Еще важный момент. Для того, чтобы сказать про выраженность тех или иных личностных качеств у человека, нужна отправная точка. Человек не может быть просто мотивированным на деньги или просто конфликтным, он мотивирован или конфликтен только в сравнении с кем-то другим. Поэтому условной «нормой» для программы служит медианное значение личностных качеств по коллективу. Минимальная его численность для корректности вычисления медианного значения должна быть 20 человек.
В итоге алгоритм вычислений – от момента сбора текста пользователя до финального причисления его к тому или иному психотипу – был выбран такой:
- извлекаем неструктурированный текст пользователей из сообщений;
- определяем слова в неструктурированном тексте, совпадающие со словарями личностных качеств;
- определяем значение веса слов на основе частотности слов в неструктурированном тексте;
- определяем характеристики личностных качеств;
- определяем показатели количественной выраженности личностных качеств пользователя, сравнивая его характеристики с медианными показателями по всем пользователям коллектива;
- определяем психотип пользователя.
Было решено, что в интерфейсе программы пользователь в лице специалиста службы безопасности или HR видит не итог вычислений в виде психотипа, а промежуточный этап вычислений. То есть раскладку по личностным качествам. Это более информативно. А сам психотип мы отображаем в так называемом расширенном отчете.
Проверка гипотез и уточнение формул
С алгоритмом вычислений определились. Как проверить формулу и как корректировать, на ком проверять? Испытуемыми для этих целей стали сами сотрудники «СёрчИнформ» – отобрали 102 человека. Их я с помощью коллег-профайлеров профилировал вручную. Испытуемые прошли три стандартизированных опросника: опросник 5PFQ (т.н. «большая пятерка»), опросник Шварца, опросники Л.Н.Собчик СМИЛ и ИТО. Затем мы сравнивали результаты с теми данными, что выдавала программа.
По шкалам результаты были разные – от 57% до 94%. Великолепно определялись шкалы экстраверсии/интроверсии, тревожность, конфликтность, активность и др. Хуже результаты оказались, например, по показателю «амбициозность».
По полученной статистике формулу корректировали, в результате мы «зашили» в нее больше 70 переменных (например, индекс страдательного залога, индекс длины слова, предложения, имен собственных и др.) и вес каждого.
Долго пришлось поработать над определением минимально достаточного количества письменного материала для анализа. Сейчас остановились на 20 тысячах лемм (лемма – неизменная форма слова). Но начинали анализ с 50 тысяч, сокращая этот объем с шагом в 5 тысяч.
Один из самых частых вопросов – почему мы до сих пор не реализовали возможность оценки стороннего текста пользователя, взятого из открытых источников? Мол, зачем ждать накопления 20 тысяч лемм, если можно в сети взять текст конкретного пользователя и проанализировать его по тем же критериям? Технически это возможно, но тогда в программу нужно загружать информацию не по одному человеку, а по коллективу сотрудников или людей схожих профессий (выше описывал, почему).
Проверка боем и предел возможностей
Когда была готова рабочая модель – примерно два года назад – начали тестировать (MVP) программу не только на собственных сотрудниках, но и на сотрудниках нескольких десятков клиентов, которые дали согласие на участие в эксперименте. К октябрю-ноябрю 2018 года получили хорошо работающий продукт. Мы были уверены, что он выдает качественные данные по т.н. первичным личностным качествам (которые мы можем перепроверить с помощью опросника).
Точность результатов готового модуля эксперты-профайлеры и клиенты оценивали в 75–80%. Для задачи, решения которой никто раньше не предлагал, это хорошие показатели. Главное, что этого достаточно, чтобы решать задачи бизнеса.

Остались линии, за которые мы пока не можем выйти. Чтобы создать психологический портрет максимально качественно, нужно две-четыре модальности: текст, интонации, трафик и др. Когда мы добавим в модуль анализ голоса, социальных сетей, клавиатурного почерка, качество реализации будет еще лучше. Но эти задачи решаются довольно сложно (рассказывал выше). Каждый следующий процент точности расчета нашего модуля дается со все большим трудом.
Примерно с теми же ограничениями сталкиваемся, пытаясь выстроить профили по тем людям, которые пишут мало и чей словарный запас, скажем прямо, беден. Речь про тех пользователей, общение которых сводится к «привет», «ок» и «давай». Выстроить корректный профиль только на основе письменной речи по ним сложно.
И что же получилось? Краткий профиль – что в нем
Продукт всех изысканий, описанных выше, – это краткий профиль личности. Как я говорил, это первичная информация, «сырье», чтобы на нем делать более развернутые выводы как об одном человеке, так и коллективе.
В кратком профиле нам нужно было создать такой портрет пользователя, в котором отражались бы принципиально важные характеристики с точки зрения специалиста службы безопасности и службы ИБ: сильные/слабые стороны, принципиальные отличия сотрудника от других пользователей, общий типаж, криминальные тенденции, ценности и рекомендации.
В итоге в кратком профиле выделяем три самых сильных и три самых слабых черты личности.
Это выглядит, например, так:
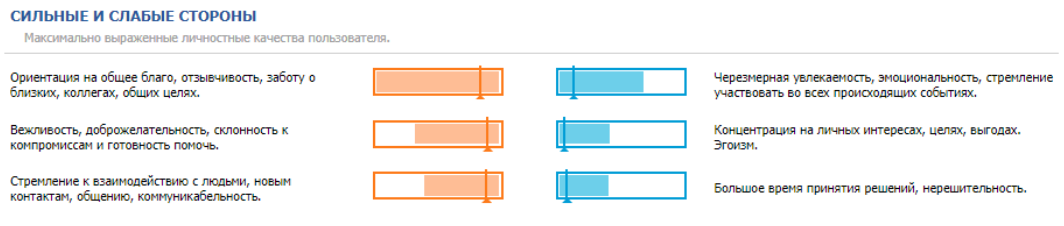
(Это, кстати, скриншот профиля одного сильного руководителя).
Дальше составляем индекс личностных качеств. Зачем он нам нужен? Не все личностные качества одинаково… стабильны. Проявление некоторых сильно зависит от контекста, и без какой-то исходной точки сделать вывод о выраженности качества невозможно.
Например, когда можно сказать про человека, что он конфликтный? Когда он начинает ругаться матом? Бить других? Стрелять? А вот если делать вывод о конфликтности в сравнении с противоположным качеством (в дихотомии), сможем понять, насколько выражены оба. То есть человек более отзывчивый, вежливый, чем конфликтный.
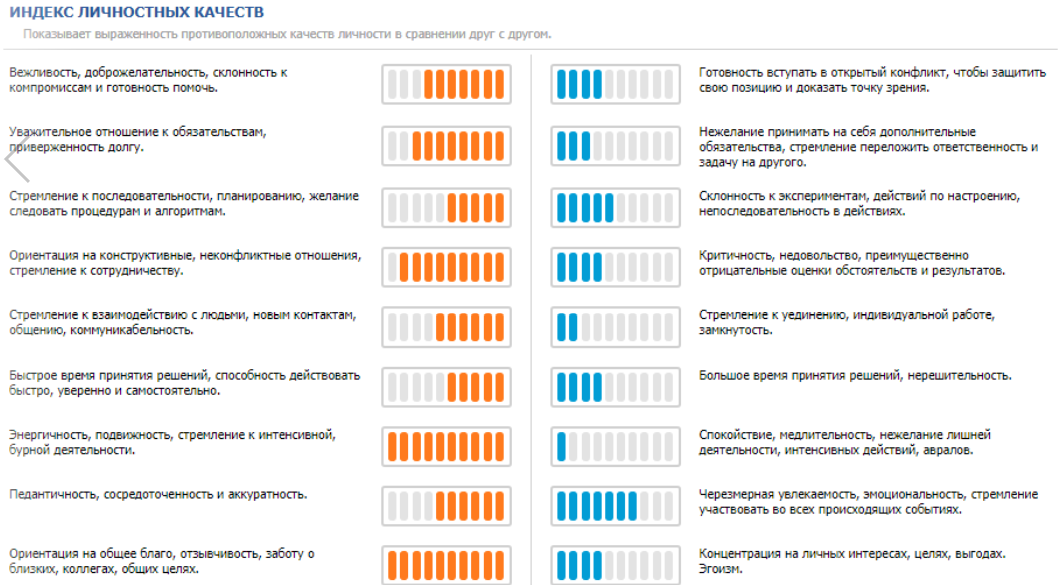
Еще в кратком профиле определяем криминальные тенденции (не забываем, что наш ProfileCenter – продукт в первую очередь для служб безопасности).
Для того, чтобы определить риски по каждому профилю, снова обращались к психологии, выделяли на языке экономической и информационной безопасности риски, которые заложены в личностных качествах. Например, конфликтность, болтливость, темная триада личности (манипулятивность), лидерские качества, эмоциональность. Есть исследования, которые позволили эти данные сопоставить и вывести рекомендации. Здесь мы ориентировались на большое количество работ не только в области криминологии, криминальной психологии и криминального профайлинга, но и по кадровой безопасности и управлению кадровыми рисками.
Для вычисления амбициозности мы составили собственные лингвистические формулы. Для выбора переменных формул расчета базовых ценностей взяли научные разработки Белянина и Шварца.
Вот так все это выглядит полностью. Отчет по краткому профилю:

Рейтинги, расширенные отчеты и динамика профилей
Что дальше? Имея информацию о личностных качествах, мы взялись за создание рейтингов, так как это полезная функция для нашей целевой аудитории – специалистов служб безопасности и ИБ-спецов в частности. Они говорили нам: у нас 5000 пользователей, за всеми не уследишь. Если бы вы смогли сузить нам фокус внимания (выявить группы риска), мы бы знали, за кем наблюдать пристальнее.
Сложность на этом этапе была не технологическая, а методологическая. Так как недостаточно просто взять и рейтинговать всех пользователей по каждому качеству. Для служб безопасности информативны «синтетические» свойства личности, то есть не конфликтность, а скандальность, не стремление к взаимодействию, а лидерство. Скандальность и лидерство имеют в своем составе несколько показателей из краткого профиля. Чтобы составить формулу для каждого рейтинга, определить в ней вес каждого качества, мы снова обращались к психосемантике и психолингвистике. Переработали не меньше 35 работ на русском и английском. В итоге сейчас программа дает 12 рейтингов, на базе которых можно создавать свои собственные.
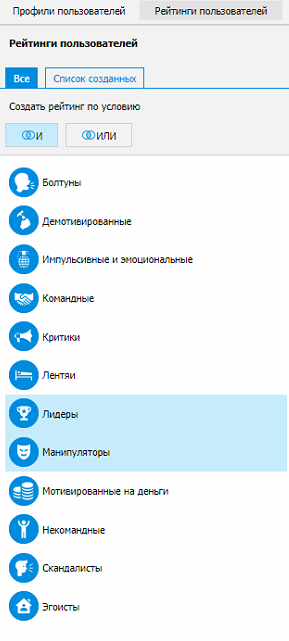 Рейтинги могут определять группы риска тех сотрудников, которые готовятся к увольнению, демотивированных, агрессивных, скандальных и пр. И наоборот, с помощью рейтингов можно создавать группы кадрового резерва. Мы, кстати, очень хорошо умеем прогнозировать увольнение сотрудника, его выгорание, высокий лидерский потенциал.
Рейтинги могут определять группы риска тех сотрудников, которые готовятся к увольнению, демотивированных, агрессивных, скандальных и пр. И наоборот, с помощью рейтингов можно создавать группы кадрового резерва. Мы, кстати, очень хорошо умеем прогнозировать увольнение сотрудника, его выгорание, высокий лидерский потенциал.В принципе те же технические и методические задачи из психолингвистики стояли и при создании расширенного профиля и динамики профиля – выбор переменных для формул и определение веса значения каждого.
В расширенном профиле сделали дополнительные отчеты, которые сильно расширяют область применения программы, т.к. по сути они дают информацию о ключевых компетенциях пользователя. Их обычно оценивают кадровики и управленцы по компетенциям SHL (потребность во власти и контроле, в согласии, экстраверсия, общий интеллект, открытость новому, обязательность, эмоциональная стабильность, мотивация достижений).
Динамика изменения профиля – по отчету можно получать предупреждения, если что-то с человеком происходит, если он вырывается в лидеры значимых для ИБ-специалистов рейтингов.
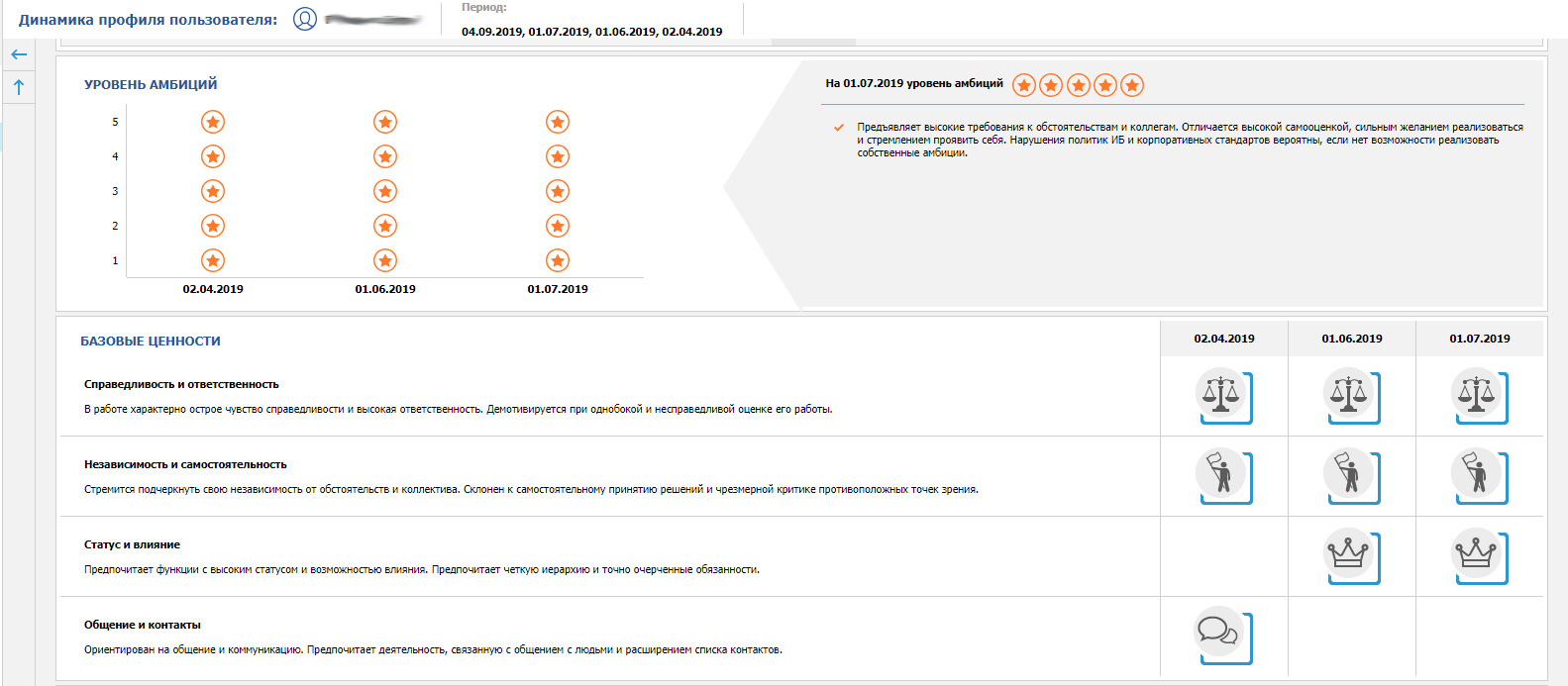
Тому, что мы смогли создать отчет по динамике, я придаю большое значение. Почему это было важно сделать? Если в течении 2-3-4 месяцев профиль и рейтинги пользователя после нескольких перерасчетов сохраняются в целом стабильными, то это показатель того, что найдено так называемое типовое поведение пользователя.
А значит – решена ключевая задача поведенческого анализа в ИБ.
Интерфейс
Но как ни странно, повозиться пришлось не только с техническими, методическими проблемами. Вопрос о графическом представлении результатов вызывал не меньшие дискуссии. В моей голове интерфейс выглядел совсем иначе, чем сейчас. Но важно было думать о том, как с продуктом удобнее будет работать клиентам.

Дизайнер работал в авральном режиме, пересмотрели десятки вариантов. Критике подвергался каждый элемент: визуализация индекса личностных качеств, известная в команде проекта как «батарейка», пиктограммы для обозначения базовых ценностей и уровня амбиций, блок с рекомендациями.

Интерфейс «КИБ Сёрчинформ ProfileCenter», который вышел в релиз в 2018 году
«Трудности перевода»
Еще один момент — терминология. Как выбрать такие правильные с точки зрения науки, но информативные для наших пользователей названия личностных качеств, рейтингов? Например, в первой версии мы ввели параметр «азартность». В психологии это означает вовлеченность в процесс, а для большинства людей, — «приверженность к азартным играм».
Из-за разночтений в терминологии альфа-версия вызвала неоднозначную оценку, так что в финальном варианте отчета появились определения и краткие пояснения терминов.
Дискуссии продолжаются и сейчас, каждый раз, когда вводим новый рейтинг и нужно определиться с емким, но понятным непсихологам названием. Надо отметить, что тот же путь мы проходим и в иностранной лексике – в прошлом году релиз состоялся на английском языке.
Что еще дорабатываем? Пока идет работа над усовершенствованием отчетов. Сейчас модуль может формировать около 78 000 вариантов расширенных профилей сотрудников, умеет определять риск-рейтинг пользователя. ProfileCenter интегрируется с DLP-системой «СёрчИнформ КИБ», и нужно чтобы он научился находить корреляции с инцидентами и поведением человека.
Мы работаем над интеграцией модуля детекции клавиатурного почерка в состав ProfileCenter, составлением расширенного отчета и дополнительных рисков в области кадровой и информационной безопасности – в общем, вариантов, как нарастить возможности ПО, еще много.
В целом рынок активно развивается в этом направлении и уже появляются последователи, которые пробуют автоматизированно оценивать риски сотрудников в области ИБ. Но подчеркну, что такая работа может быть перспективной на стыке нескольких «модальностей» – когда одновременно в анализе учитывается как минимум не только «техническая», но и психолингвистическая информация: а лучше – даже больше.
Постскриптум
Если мой длинный рассказ о профайлинге вас не отпугнул, а больше заинтересовал темой, приглашаю с понедельника на курс «Профайлинг для службы ИБ» – 5 занятий, которые мы в «СёрчИнформ» проводим очно и платно будут доступны онлайн и бесплатно (все из-за карантина, чего же еще).
Список тем:
- 20 апреля, 11.00 Современный профайлинг: основные понятия и показатели. Инструменты профайлинга и психотипологии. Профайлинг, основанный на доказательствах.
- 21 апреля, 11.00 Профайлинг в области безопасности и управления кадровыми рисками.
«СёрчИнформ ProfileCenter» в повседневной работе службы ИБ. - 22 апреля 11.00 Когнитивные искажения.
Основные ошибки при принятии решений. Как мозг заставляет нас ошибаться при оценке человека и ситуации? Разбор кейсов. - 23 апреля, 11.00 Верификация лжи Основы безынструментальной детекции лжи. Признаки лжи в поведении человека. Работа с инсайдом.
- 24 апреля, 11.00 Стратегии выявления лжи.
Опросные беседы. Как склонить к сотрудничеству подозреваемого? Основные модели получения признаний.
Зарегистрироваться можно по ссылке.
