Привет хабр! Сегодня мы бы хотели рассказать вам об очень интересной задаче, которой мы занимаемся с самого старта наших исследований распознавания документов в видеопотоке – задаче поиска оптимального момента остановки.

Рис. 1. Изображения текстовых полей ID-документов на кадрах видеопоследовательности.
Как многим известно, основным продуктом компании Smart Engines является система распознавания документов, удостоверяющих личность, Smart IDReader, применимая как на серверах и десктопах, так и на мобильных устройствах. В большом количестве кейсов распознавание документов на мобильнике должно происходить в автономном режиме, зачастую мы не можем контролировать условия и качество съемки, а стоимость ошибки распознавания, в особенности при распознавании удостоверяющих документов, весьма высока. При этом у нас есть важное преимущество – мы можем использовать не одно изображение, а последовательность захватываемых кадров (см. Рис. 1), для повышения точности распознавания.
При использовании множества изображений текстовых полей возникают два важных вопроса. Первый вопрос – каким образом комбинировать наблюдения? Стоит ли комбинировать исходные кадры для получения одного изображения, более высокого “качества”, или выбирать один лучший кадр (тогда откуда гарантия что будет кадр, на котором все хорошо)? Или, может быть, сначала распознать поле на каждом кадре, а потом выбрать наиболее “уверенный” результат (по какому критерию?), или комбинировать покадровые результаты распознавания, и т.п. Мы придерживаемся последнего подхода (покадровое распознавание с межкадровым комбинированием результатов), но оптимальный подход может отличаться как в зависимости от используемого движка распознавания так и от других параметров задачи.
Второй вопрос, возникающий независимо от первого, – когда останавливать процесс наблюдений? Другими словами, по какому критерию принимать решение о том, что процесс захвата кадров можно прекратить и накопленный к текущему моменту результат признать за окончательный? Как сравнивать такие критерии между собой и существует ли оптимальный?
Именно о задаче поиска момента остановки процесса наблюдений пойдет речь в этой статье.
Распознавание текстовой строки в видеопоследовательности, при котором после захвата очередного наблюдения результат тем или иным образом улучшается, можно рассматривать как Anytime-алгоритм – алгоритм с последовательно улучшающимся результатом, вычисления в рамках которого можно остановить в любой момент. Удобным инструментом для визуализации качества таких алгоритмов являются “профили ожидаемой эффективности” (Expected performance profiles) — графики завимости качества результата, измеряемого в том или ином виде, от времени вычислений.
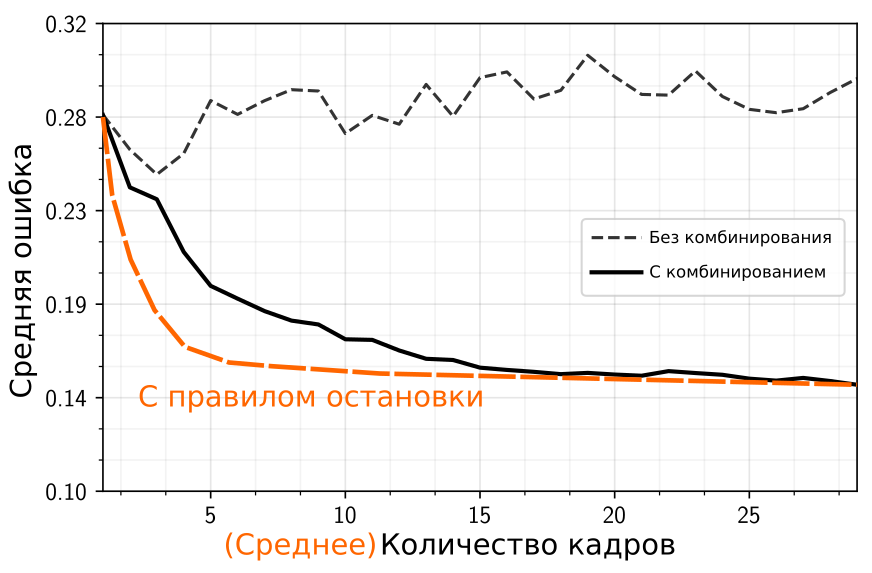
Рис. 2. Профили эффективности распознавания текстовой строки в видеопоследовательности (ниже – лучше). Черная пунктирная линия – покадровое качество, черная сплошная линия — результат межкадрового комбинированния. Оранжевая линия – то, что мы хотим от “хорошего” правила остановки.
На Рис. 2 показаны профили эффективности для распознавания текстовой строки – зависимости средней ошибки (в терминах расстояния Левенштейна до правильного ответа) от количества обработанных кадров. Графики черного цвета получены при помощи Tesseract v4.0.0 на текстовых полях датасета MIDV-500. Видно, что использование межкадрового комбинирования результатов распознавания позволяет достигнуть гораздо более низкого значения ошибки (что, в общем, не удивительно).
Что же мы хотим от “хорошего” правила остановки? Поскольку мы ожидаем, вполне обоснованно, что чем дольше мы будем продолжать процесс тем в среднем лучше у нас будет результат, было бы здорово, если бы правило остановки на некоторых видеопоследовательностях считало “подольше”, если есть шанс минимизировать ошибку, а на некоторых – останавливалось бы раньше, если результат уже и так хороший, или шанса его улучшить нет. За счет этого при одном и том же среднем качестве комбинированного результата может быть достигнуто в среднем меньшее количество обрабатываемых кадров, и наоборот, при том же среднем количестве кадров — лучше в среднем результат. Другими словами, важно понимать – правило остановки это не только про минимизацию времени, это еще и про максимизацию качества, за то же (в среднем) время.
Пусть мы ищем правило остановки в следующем виде: после обработки очередного кадра и получения комбинированного результата распознавания мы считаем какую-то характеристику, и производим ее пороговое отсечение – если, скажем, она ниже порога – то мы останавливаемся, в противном случае – продолжаем. Тогда при фиксированном правиле остановки, но варьируя порог, мы тоже получим профиль эффективности, за тем лишь исключением, что по горизонтальной оси будет находится не точное количество обработанных кадров, а среднее (см. оранжевый график на Рис. 2). Чем ниже расположен этот график, тем более эффективным мы можем считать правило остановки. Исходный профиль “комбинированного результата” мы можем считать профилем эффективности тривиального правила остановки – при котором мы производим пороговое отсечение просто количества обработанных кадров.
В математической статистике задачи поиска оптимального момента остановки хорошо известны и давно исследуются. Пожалуй, самыми известными задачами из этого класса являются задача о разборчивой невесте, (ей много занимался, например, Борис Абрамович Березовский), задача о продаже дома и другие. Не вдаваясь глубоко в теорию, давайте кратко поставим задачу о распознавании в видеопоследовательности как задачу оптимальной остановки.
Обозначим ошибку комбинированного результата на -м шаге процесса как
-м шаге процесса как  . Будем считать, что если мы остановимся на -м шаге, то мы понесем убыток следующего вида:
. Будем считать, что если мы остановимся на -м шаге, то мы понесем убыток следующего вида:  , где
, где  – некоторая заранее заданная относительная стоимость каждого наблюдения. Задачу поиска оптимального момента остановки можно сформулировать как поиск случайной величины
– некоторая заранее заданная относительная стоимость каждого наблюдения. Задачу поиска оптимального момента остановки можно сформулировать как поиск случайной величины  – времени остановки, распределение которой зависит от входных наблюдений (в некоторой литературе величину называют марковским моментом), и при которой минимизируется ожидаемый убыток
– времени остановки, распределение которой зависит от входных наблюдений (в некоторой литературе величину называют марковским моментом), и при которой минимизируется ожидаемый убыток  .
.
При определенных условиях в подобных задачах можно явно выразить оптимальное правило остановки. Примером являются так называемые монотонные задачи. Критерий монотонности задачи такой: если на каком-то шаге убыток  не превосходит ожидаемого убытка на следующем шаге, то это же будет выполняться на всех последующих шагах. Другими словами, из того, что случилось событие
не превосходит ожидаемого убытка на следующем шаге, то это же будет выполняться на всех последующих шагах. Другими словами, из того, что случилось событие  следует, что случится событие
следует, что случится событие  . Для монотонных задач оптимальным является так называемое “близорукое” правило остановки: остановись на первом же шаге, на котором выполнено условие .
. Для монотонных задач оптимальным является так называемое “близорукое” правило остановки: остановись на первом же шаге, на котором выполнено условие .
Предположим, что наша задача монотонная. Записав близорукое правило в терминах нашей функции получаем, что остановиться нужно тогда, когда выполнено следующее условие:

Это, конечно, здорово, но для реализации такого правила нам нужно уметь в рантайме оценивать не только “правильность” текущего результата, но и ожидаемую правильность следующего, что не так-то просто (не говоря уже о том, что мы властно потребовали от задачи монотонности). Можем ли мы как-нибудь применить это правило не оценивая напрямую “правильность” результата?.. Можно попробовать оценить левую часть неравенства сверху.
Давайте будем считать, что функция – это расстояние  от комбинированного результата распознавания
от комбинированного результата распознавания  до “правильного ответа”
до “правильного ответа”  , и как у любого уважающего себя расстояния у него выполняется неравенство треугольника. Упомянутое выше расстояние Левенштейна удовлетворяет неравенству треугольника, также как и простая функция в виде “правильно/неправильно” (если считать, что для правильного ответа равно нулю и для неправильного – константе). Согласно неравенству треугольника левая часть нашего критерия остановки не превосходит
, и как у любого уважающего себя расстояния у него выполняется неравенство треугольника. Упомянутое выше расстояние Левенштейна удовлетворяет неравенству треугольника, также как и простая функция в виде “правильно/неправильно” (если считать, что для правильного ответа равно нулю и для неправильного – константе). Согласно неравенству треугольника левая часть нашего критерия остановки не превосходит  – ожидаемого расстояния от текущего комбинированного результата до следующего.
– ожидаемого расстояния от текущего комбинированного результата до следующего.
Давайте также потребуем от нашего алгоритма межкадрового комбинирования результатов распознавания, чтобы в среднем расстояние между соседними комбинированными результатами не возрастали со временем (т.е. будем рассматривать последовательность комбинированных результатов как некоторый “сходящийся” процесс, хотя и не обязательно к правильному ответу). Тогда если ожидаемое расстояние от текущего результата до следующего становится меньше порога c, выполняются сразу две вещи. Во-первых, выполняется близорукий критерий остановки (поскольку его левая часть ограничена сверху этим самым расстоянием). А во-вторых, задача становится монотонной: на следующем шаге ожидаемое расстояние до следующего ответа не вырастет, а значит и снова продолжит быть меньше порога c, и близорукий критерий снова выполнится.
Это значит, что если мы ожидаем, что расстояния между соседними комбинированными результатами в среднем не возрастают, то останавливаться нужно пороговым отсечением ожидаемого расстояния от текущего результата до следующего, таким образом аппроксимируя оптимальное правило. Нужно понимать, что такое правило уже не оптимально (поскольку “настоящее” оптимальное правило могло остановиться раньше), но по крайней мере мы не остановимся раньше нужного.
Оценивать ожидаемое расстояние от текущего комбинированного результата до следующего можно разными способами. К примеру, если в качестве метрики над результатами используется расстояние Левенштейна, то даже просто расстояние между двумя последними результатами распонавания является неплохим приближением. Другой возможный подход – моделирование возможного следующего наблюдения (например, на основе уже полученных), проведение “холостых” комбинирований и вычисление среднего расстояния до полученных предсказаний.

Рис. 3. Сравнение профилей эффективности для нескольких правил остановки.
На Рис. 3 показаны профили эффективности для нескольких правил остановки. – то самое, упомянутое ранее, “тривиальное” правило – с пороговым отсечением количества обработанных наблюдений.
– то самое, упомянутое ранее, “тривиальное” правило – с пороговым отсечением количества обработанных наблюдений.  и
и  – пороговые отсечения размера максимального кластера одинаковых покадровых () и комбинированных () результатов. – правило, описанное в этой работе, с оценкой ожидаемого расстояния до следующего результата с помощью моделирования и “холостых” комбинирований.
– пороговые отсечения размера максимального кластера одинаковых покадровых () и комбинированных () результатов. – правило, описанное в этой работе, с оценкой ожидаемого расстояния до следующего результата с помощью моделирования и “холостых” комбинирований.
Целью статьи было показать, что в системах распознавания документов на кадрах видеопоследовательностей есть много интересных задач, не только непосредственно компьютерного зрения, но и из других интересных областей. Хотя мы показали задачу поиска оптимального момента остановки только в ее простейшем виде, самое интересное начинается, когда мы, к примеру, хотим учесть в модели не только количество кадров, но и реальное время исполнения. Надеемся, что вам было интересно, и спасибо за внимание!
–
Публикация подготовлена на основе статьи On optimal stopping strategies for text recognition in a video stream, K. Bulatov, N. Razumnyi, V. V. Arlazarov, IJDAR 22, 303-314 (2019) 10.1007/s10032-019-00333-0.
Если читателю интересна теория оптимального момента остановки, в частности — доказательство оптимальности близорукого правила для монотонных задач, крайне рекомендуем опубликованный курс Optimal Stopping and Applications (Thomas Ferguson, UCLA).
Еще несколько интересных источников по этой теме:
Chow Y.S., Siegmund D. Great expectations: The theory of optimal stopping, Houghton Mifflin, 1971, 139 p.
Березовский Б. А., Гнедин А.В. Задача наилучшего выбора, Наука, 1984, 200 с.
Ferguson T.S., Hardwick T.S. Stopping rules for proofreading, Journal of Applied Probability., V. 26, N. 2, 1989, p. 303-313.
Ferguson T.S. Mathematical statistics: a decision theoretic approach. Academic press, 1967, 396 p.

Рис. 1. Изображения текстовых полей ID-документов на кадрах видеопоследовательности.
Как многим известно, основным продуктом компании Smart Engines является система распознавания документов, удостоверяющих личность, Smart IDReader, применимая как на серверах и десктопах, так и на мобильных устройствах. В большом количестве кейсов распознавание документов на мобильнике должно происходить в автономном режиме, зачастую мы не можем контролировать условия и качество съемки, а стоимость ошибки распознавания, в особенности при распознавании удостоверяющих документов, весьма высока. При этом у нас есть важное преимущество – мы можем использовать не одно изображение, а последовательность захватываемых кадров (см. Рис. 1), для повышения точности распознавания.
При использовании множества изображений текстовых полей возникают два важных вопроса. Первый вопрос – каким образом комбинировать наблюдения? Стоит ли комбинировать исходные кадры для получения одного изображения, более высокого “качества”, или выбирать один лучший кадр (тогда откуда гарантия что будет кадр, на котором все хорошо)? Или, может быть, сначала распознать поле на каждом кадре, а потом выбрать наиболее “уверенный” результат (по какому критерию?), или комбинировать покадровые результаты распознавания, и т.п. Мы придерживаемся последнего подхода (покадровое распознавание с межкадровым комбинированием результатов), но оптимальный подход может отличаться как в зависимости от используемого движка распознавания так и от других параметров задачи.
Второй вопрос, возникающий независимо от первого, – когда останавливать процесс наблюдений? Другими словами, по какому критерию принимать решение о том, что процесс захвата кадров можно прекратить и накопленный к текущему моменту результат признать за окончательный? Как сравнивать такие критерии между собой и существует ли оптимальный?
Именно о задаче поиска момента остановки процесса наблюдений пойдет речь в этой статье.
Чего мы хотим достичь
Распознавание текстовой строки в видеопоследовательности, при котором после захвата очередного наблюдения результат тем или иным образом улучшается, можно рассматривать как Anytime-алгоритм – алгоритм с последовательно улучшающимся результатом, вычисления в рамках которого можно остановить в любой момент. Удобным инструментом для визуализации качества таких алгоритмов являются “профили ожидаемой эффективности” (Expected performance profiles) — графики завимости качества результата, измеряемого в том или ином виде, от времени вычислений.

Рис. 2. Профили эффективности распознавания текстовой строки в видеопоследовательности (ниже – лучше). Черная пунктирная линия – покадровое качество, черная сплошная линия — результат межкадрового комбинированния. Оранжевая линия – то, что мы хотим от “хорошего” правила остановки.
На Рис. 2 показаны профили эффективности для распознавания текстовой строки – зависимости средней ошибки (в терминах расстояния Левенштейна до правильного ответа) от количества обработанных кадров. Графики черного цвета получены при помощи Tesseract v4.0.0 на текстовых полях датасета MIDV-500. Видно, что использование межкадрового комбинирования результатов распознавания позволяет достигнуть гораздо более низкого значения ошибки (что, в общем, не удивительно).
Что же мы хотим от “хорошего” правила остановки? Поскольку мы ожидаем, вполне обоснованно, что чем дольше мы будем продолжать процесс тем в среднем лучше у нас будет результат, было бы здорово, если бы правило остановки на некоторых видеопоследовательностях считало “подольше”, если есть шанс минимизировать ошибку, а на некоторых – останавливалось бы раньше, если результат уже и так хороший, или шанса его улучшить нет. За счет этого при одном и том же среднем качестве комбинированного результата может быть достигнуто в среднем меньшее количество обрабатываемых кадров, и наоборот, при том же среднем количестве кадров — лучше в среднем результат. Другими словами, важно понимать – правило остановки это не только про минимизацию времени, это еще и про максимизацию качества, за то же (в среднем) время.
Пусть мы ищем правило остановки в следующем виде: после обработки очередного кадра и получения комбинированного результата распознавания мы считаем какую-то характеристику, и производим ее пороговое отсечение – если, скажем, она ниже порога – то мы останавливаемся, в противном случае – продолжаем. Тогда при фиксированном правиле остановки, но варьируя порог, мы тоже получим профиль эффективности, за тем лишь исключением, что по горизонтальной оси будет находится не точное количество обработанных кадров, а среднее (см. оранжевый график на Рис. 2). Чем ниже расположен этот график, тем более эффективным мы можем считать правило остановки. Исходный профиль “комбинированного результата” мы можем считать профилем эффективности тривиального правила остановки – при котором мы производим пороговое отсечение просто количества обработанных кадров.
Что говорит теория
В математической статистике задачи поиска оптимального момента остановки хорошо известны и давно исследуются. Пожалуй, самыми известными задачами из этого класса являются задача о разборчивой невесте, (ей много занимался, например, Борис Абрамович Березовский), задача о продаже дома и другие. Не вдаваясь глубоко в теорию, давайте кратко поставим задачу о распознавании в видеопоследовательности как задачу оптимальной остановки.
Обозначим ошибку комбинированного результата на
-м шаге процесса как . Будем считать, что если мы остановимся на -м шаге, то мы понесем убыток следующего вида: , где – некоторая заранее заданная относительная стоимость каждого наблюдения. Задачу поиска оптимального момента остановки можно сформулировать как поиск случайной величины – времени остановки, распределение которой зависит от входных наблюдений (в некоторой литературе величину называют марковским моментом), и при которой минимизируется ожидаемый убыток .Монотонные задачи
При определенных условиях в подобных задачах можно явно выразить оптимальное правило остановки. Примером являются так называемые монотонные задачи. Критерий монотонности задачи такой: если на каком-то шаге
убыток не превосходит ожидаемого убытка на следующем шаге, то это же будет выполняться на всех последующих шагах. Другими словами, из того, что случилось событие следует, что случится событие . Для монотонных задач оптимальным является так называемое “близорукое” правило остановки: остановись на первом же шаге, на котором выполнено условие .Предположим, что наша задача монотонная. Записав близорукое правило в терминах нашей функции
получаем, что остановиться нужно тогда, когда выполнено следующее условие:Это, конечно, здорово, но для реализации такого правила нам нужно уметь в рантайме оценивать не только “правильность” текущего результата, но и ожидаемую правильность следующего, что не так-то просто (не говоря уже о том, что мы властно потребовали от задачи монотонности). Можем ли мы как-нибудь применить это правило не оценивая напрямую “правильность” результата?.. Можно попробовать оценить левую часть неравенства сверху.
Как можно использовать близорукое правило
Давайте будем считать, что функция
– это расстояние от комбинированного результата распознавания до “правильного ответа” , и как у любого уважающего себя расстояния у него выполняется неравенство треугольника. Упомянутое выше расстояние Левенштейна удовлетворяет неравенству треугольника, также как и простая функция в виде “правильно/неправильно” (если считать, что для правильного ответа равно нулю и для неправильного – константе). Согласно неравенству треугольника левая часть нашего критерия остановки не превосходит – ожидаемого расстояния от текущего комбинированного результата до следующего.Давайте также потребуем от нашего алгоритма межкадрового комбинирования результатов распознавания, чтобы в среднем расстояние между соседними комбинированными результатами не возрастали со временем (т.е. будем рассматривать последовательность комбинированных результатов как некоторый “сходящийся” процесс, хотя и не обязательно к правильному ответу). Тогда если ожидаемое расстояние от текущего результата до следующего становится меньше порога c, выполняются сразу две вещи. Во-первых, выполняется близорукий критерий остановки (поскольку его левая часть ограничена сверху этим самым расстоянием). А во-вторых, задача становится монотонной: на следующем шаге ожидаемое расстояние до следующего ответа не вырастет, а значит и снова продолжит быть меньше порога c, и близорукий критерий снова выполнится.
Это значит, что если мы ожидаем, что расстояния между соседними комбинированными результатами в среднем не возрастают, то останавливаться нужно пороговым отсечением ожидаемого расстояния от текущего результата до следующего, таким образом аппроксимируя оптимальное правило. Нужно понимать, что такое правило уже не оптимально (поскольку “настоящее” оптимальное правило могло остановиться раньше), но по крайней мере мы не остановимся раньше нужного.
Оценивать ожидаемое расстояние от текущего комбинированного результата до следующего можно разными способами. К примеру, если в качестве метрики над результатами используется расстояние Левенштейна, то даже просто расстояние между двумя последними результатами распонавания является неплохим приближением. Другой возможный подход – моделирование возможного следующего наблюдения (например, на основе уже полученных), проведение “холостых” комбинирований и вычисление среднего расстояния до полученных предсказаний.

Рис. 3. Сравнение профилей эффективности для нескольких правил остановки.
На Рис. 3 показаны профили эффективности для нескольких правил остановки.
– то самое, упомянутое ранее, “тривиальное” правило – с пороговым отсечением количества обработанных наблюдений. и – пороговые отсечения размера максимального кластера одинаковых покадровых () и комбинированных () результатов. – правило, описанное в этой работе, с оценкой ожидаемого расстояния до следующего результата с помощью моделирования и “холостых” комбинирований.Вместо заключения
Целью статьи было показать, что в системах распознавания документов на кадрах видеопоследовательностей есть много интересных задач, не только непосредственно компьютерного зрения, но и из других интересных областей. Хотя мы показали задачу поиска оптимального момента остановки только в ее простейшем виде, самое интересное начинается, когда мы, к примеру, хотим учесть в модели не только количество кадров, но и реальное время исполнения. Надеемся, что вам было интересно, и спасибо за внимание!
–
Публикация подготовлена на основе статьи On optimal stopping strategies for text recognition in a video stream, K. Bulatov, N. Razumnyi, V. V. Arlazarov, IJDAR 22, 303-314 (2019) 10.1007/s10032-019-00333-0.
Если читателю интересна теория оптимального момента остановки, в частности — доказательство оптимальности близорукого правила для монотонных задач, крайне рекомендуем опубликованный курс Optimal Stopping and Applications (Thomas Ferguson, UCLA).
Еще несколько интересных источников по этой теме:
Chow Y.S., Siegmund D. Great expectations: The theory of optimal stopping, Houghton Mifflin, 1971, 139 p.
Березовский Б. А., Гнедин А.В. Задача наилучшего выбора, Наука, 1984, 200 с.
Ferguson T.S., Hardwick T.S. Stopping rules for proofreading, Journal of Applied Probability., V. 26, N. 2, 1989, p. 303-313.
Ferguson T.S. Mathematical statistics: a decision theoretic approach. Academic press, 1967, 396 p.
