Succinct data structures свежее веяние в алгоритмистике. В русскоязычной школе материала мало, нет даже устоявшегося перевода. Будем восполнять этот пробел. На правах первопроходцев терминологию будем вводить налету. Пусть, скажем, компактные структуры данных. На Хабре уже появилась хорошая ознакомительная статья.
Под катом развитие темы с описанием пары новых(такое вы не найдете у Кнута)трюков структур, примеры применения и реализация на языке Go.
Поиск в Яндекс подскажет вам вейвлет преобразование, как альтернативу преобразованию Фурье в цифровой обработке сигнала с разложением на высоко и низкочастотные составляющие, что позволяет отбросить высокочастотную и осуществить сжатие с предсказуемыми потерями. Сегодня не об этом. Вейвлет деревья были предложены Grossi, Gupta, Vitter в 2003 как компактное представление последовательности на конечном алфавите с гарантированно быстрыми методами доступа.

На картинке бинарное дерево последовательности S=“alabar a la alabarda” на алфавите Σ={‘ ’, a, b, d, l, r} Корень дерева хранит битовую карту всей последовательности, а ветви рекурсивно разбивают вхождения элементов последовательности в подразделы алфавита. Листья дерева ссылаются на символы алфавита. Так «b» последовательности кодируется «0» в корне потому что относится к левому подразделу алфавита и далее «1» в левой ветви потому что относится к правому подразделу левого раздела. На каждой ступени дерева кодируем символ «0» или «1» если он попадает в левый или правый раздел алфавита соответственно.
Формальное рекурсивное определение структуры:
Можно заметить, что дерево будет lg(σ) высоты и иметь σ-1 узлов. На каждом уровне дерева будет храниться n бит. То есть всего нужно хранить n*lg(σ) бит, а сложность методов будет иметь множитель lg(σ).
Вейвлет дерево предоставляет два основных метода доступа.

Access(S[i])
Проверяем v_root[i]
Если «0» то S[i] в левом разделе словаря и левой ветви дерева, иначе направо. Остается решить на какую позицию в бит-карте узла проецируется символ. Если мы оперируем, например, вторым «0» в бит-карте очевидно символ будет проецироваться на вторую позицию левой ветви. Третья единица на третью позицию правой ветви и так вниз рекурсивно. Количество «0» до позиции i в бит-карте B принято считать функцией rank0(B, i), единиц rank1(B, i).

Функции rank() и select() базовые функции над бит-картами для компактных(succinct) структур данных. (Толковое объяснение функций с картинками можно посмотреть в уже упомянутом посте.

Алгоритмы для этих функции хорошо проработаны и реализованы.
Обратная операция:
Track(symbol, count) позволяет найти symbol в последовательности S[i] использованный count раз. Для реализации этого метода понадобится вторая базовая функция select0(j) возвращающая индекс j-го «0» в бит-карте (или select1(j)). Двигаемся от словаря вверх до корня применяя эту функцию. Нам нужно просто обратить предыдущий алгоритм и вместо rank() применять select().
Следует отметить, что вейвлет дерево совсем не обязательно должно быть сбалансированным. Зная что некоторые символы встречаются в последовательности чаще других мы очень можем применить кодирование Хаффмана при построении дерева. Это лишь изменит топологию, а алгоритмы и функции будут работать как и прежде. И мы сможем добиться дополнительного сжатия данных и коротких треков для высокочастотных символов словаря.

Рассмотрим применение вейвлет дерева для построения индекса полнотекстового поиска. Обычно для этой цели строят обратный индекс — массив ассоциирующий символы словаря с позициями вхождения в последовательность. Преимуществами в-дерева в таком амплуа можно считать:
То есть вейвлет дерево это сразу два индекса прямой и обратный в компактном представлении. Такая компактность позволяет работать с большими последовательностями в памяти.
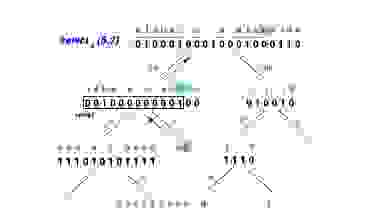
Для быстрого поиска по индексу кроме rank() и select() нужен еще быстрый поиск по словарю, особенно если этот словарь большой. Типично применять для этого ассоциативный массив. Однако associative array очень общая структура с избыточными характеристиками. В текстовых системах эффективней trie, префиксное дерево, ключами которого являются строки а значениями числа. Кроме большей скорости и компактности по сравнению с ассоциативным массивом на хеш-функциях префиксное дерево еще предлагает специфические для текстовых систем методы — PrefixMatch() и PrefixPredict(), необходимые например для автоподсказок. Однако хранить дерево ссылками может быть неэффективным по сравнению с последовательными структурами. И способы сериализации префиксного дерева появились. Сначала triple array trie, которое потом было модифицировано до double array trie. Почитать теорию вопроса можно здесь, хорошо объяснен классический алгоритм. Но структура получилась довольно сложная в реализации. И вот пожалуйста — вариант double array trie пришедший не из академического мира, а из блога коммерческой японской компании. Хоть и несколько ограниченный но подкупающий элегантностью, лаконичностью и простотой реализации в коде. Очень succinct. Собственно результат на картинке:

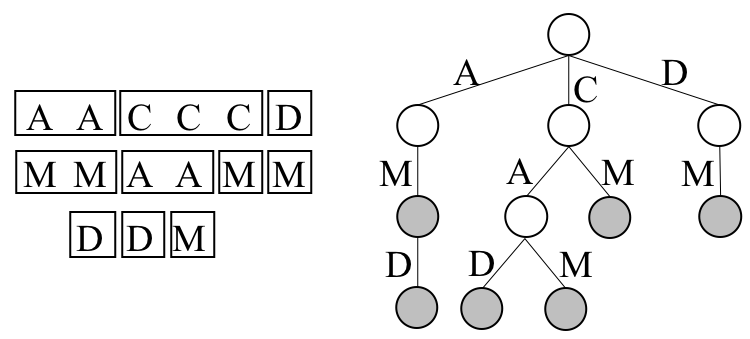
По шагам. На следующей иллюстрации последовательность термов и префиксное дерево к ней.

Наивная сериализация этого дерева в матрицу. Термы — столбцы матрицы.
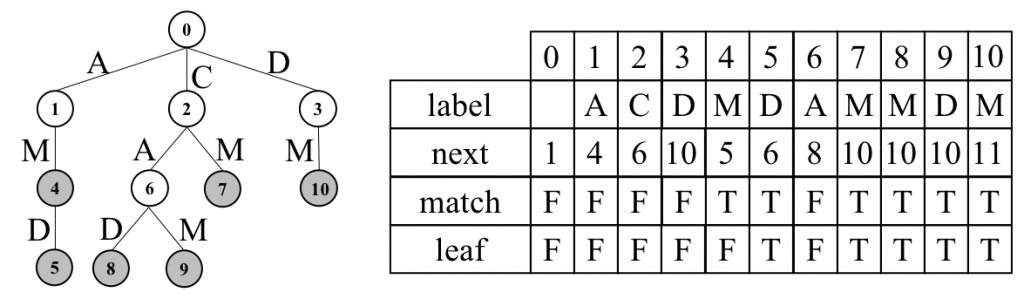
Нумеруем узлы. И вот изюминка, стратегия обхода дерева — "сперва брат". Не в глубину DFS, не в ширину BFS, а «по братски»(Sibling priority search). Рекурсивно: сперва всех братьев, потом вглубь. Такой способ обхода и позволяет сделать структуру компактной.

Double-array trie будет выглядеть так. В поле next индекс первого дочернего узла или, если дочернего нет и это лист, то индекс первого дочернего узла старшего брата (первого кузена). Тогда все дети узла T[i] между T[i].next… T[i].next.next На этом и строится поиск. Дополнительные чеки — является ли узел термом словаря, является ли листом дерева.
Формальный алгоритм построения в псевдокоде:
Пошаговая иллюстрация построения:

Формальный алгоритм доступа:
В текстовых системах большинство термов имеют уникальные окончания, а не рознятся в одной последней букве. Введя в таблицу еще один чек — tail сигнализирующий что далее следует окончание и ветвления больше не будет мы можем сократить количество проверок при поиске. Эта оптимизация не детализирована здесь, чтобы не загромождать повествование, но она сделана в коде.
Для начала очень обобщенно, а то Go ругают за отсутствие generic и object oriented. Вот generic вейвлет дерево, архитектура сверху.
Видно, что структура использует методы Child(), Parrent() характерные для дерева повторяя алгоритм буквально. Построить дерево на ссылках задача тривиальная. Сериализация сбалансированного дерева в массив тоже давно известна и не представляет труда:
В качестве рабочей лошадки для операций над бит-картами будем использовать math/bits из stdlib. Этого нам вполне хватит(в Go качественная stdlib и ее обычно хватает). В качестве собственно бит-карты применяем []uint64.
Доступ к биту на позиции pos в карте представленной таким образом прост:
Рутины Rank() Select() реализованы через библиотечную функцию bits.OnesCount64() (подсчет установленных в единицу бит), примерно так:
Такая реализация Rank() дает линейную сложность от длины бит-карты. Длина бит-карты логарифмически снижается к листьям дерева от длины последовательности. В теоретических работах приводятся методы реализации Rank() Select() константной сложности. Это может быть достигнуто хранением дополнительных таблиц переходов, что то вроде динамического программирования. Эти методы не рассматриваются здесь ввиду громоздкой реализации в коде, но интересующимся succinct полезно знать что это возможно — возможны реализации Rank() Select() константной ассимптотической сложности ценой дополнительных расходов памяти и громоздкого кода.
В репозитарии github.com/uvelichitel/wtree есть пример использования generic кода для сбалансированного дерева сериализованного в массив. Прописаны методы доступа для этого массива и прописанные методы для бит-карты. Вы можете так же реализовать методы интерфейса для своей модели дерева, а готовый тип бит-карты просто включить (embedd) в свой тип.
Примерно так:
Теперь необходимые методы для интерфейсов реализованы и вы можете использовать функции вейвлет дерева Track() Access() для своего типа.
С деревьями Хаффмана посложней. Сериализация такого дерева уже требует применения LOUDS (смотреть вводную статью) Классический LOUDS в нашем случае избыточен потому что дерево Хаффмана бинарно и несбалансировано правой косынкой (а не любое дерево вообще). Будем сериализовать так — массив узлов и массив LBS (LOUDS Bit String), но LBS будет существенно проще классического, а именно — «0» для листа или «1». Для построения дерева Хаффмана нам нужна процедура слияния двух деревьев в одно. В нашем случае алгоритм будет выглядеть следующим образом(вот здесь алгоритмистика авторская).
(алгоритм реализован функцией combine() в репозитарии)
Имея процедуру склейки мы легко можем написать алгоритм конструирования дерева Хаффмана из частотного словаря. Классический алгоритм использует «кучу». Но есть решение посвежее — если частотный словарь отсортирован, а частотные словари как правило предлагаются уже отсортированными, то можно обойтись «очередью».
Ассимптотическая сложность O(n). Ассимптотическая сложность алгоритма с "кучей" O(nLogn), зато работает на неотсортированных частотных словарях.
Довольно просто, но в процедурных языках C-семейства нет эффективного примитива очереди.
Обычно для реализации очереди в последовательной памяти (не перевязанной ссылками) применяют идею кольцевого буфера. Именно так, кстати, реализованы каналы channel в Go.
(В репозитарии есть функции Huffman() и Huffman1() для построения дерева Хаффмана из частотного словаря использующие "очередь" и "кучу" соответственно).
Структура репозитария:
Цитатник:
Под катом развитие темы с описанием пары новых(такое вы не найдете у Кнута)
Итак — вейвлет дерево
Поиск в Яндекс подскажет вам вейвлет преобразование, как альтернативу преобразованию Фурье в цифровой обработке сигнала с разложением на высоко и низкочастотные составляющие, что позволяет отбросить высокочастотную и осуществить сжатие с предсказуемыми потерями. Сегодня не об этом. Вейвлет деревья были предложены Grossi, Gupta, Vitter в 2003 как компактное представление последовательности на конечном алфавите с гарантированно быстрыми методами доступа.

На картинке бинарное дерево последовательности S=“alabar a la alabarda” на алфавите Σ={‘ ’, a, b, d, l, r} Корень дерева хранит битовую карту всей последовательности, а ветви рекурсивно разбивают вхождения элементов последовательности в подразделы алфавита. Листья дерева ссылаются на символы алфавита. Так «b» последовательности кодируется «0» в корне потому что относится к левому подразделу алфавита и далее «1» в левой ветви потому что относится к правому подразделу левого раздела. На каждой ступени дерева кодируем символ «0» или «1» если он попадает в левый или правый раздел алфавита соответственно.
Формальное рекурсивное определение структуры:
Вейвлет дерево последовательности S[1 ,n] на алфавите [a .. b] ⊆ [1 .. σ] это сбалансированное бинарное дерево b − a + 1 листьев такое что
если a = b просто лист "a" иначе дерево имеет корень представляющий всю последовательность в виде битовой карты v_root определенной следующим образом
если S[i] не больше (a + b)/2 то v_root[i] = 0, иначе v_root[i] = 1
Определим S0[1 , n0] как подраздел S[1 ,n] состоящую из символов c > (a + b)/2 Тогда левая ветвь v_root это вейвлет дерево S0[1 , n0] на алфавите [a..(a + b)/2] и правая ветвь это в-дерево для S1[1, n1] на алфавите [1+(a + b)/2..b]Можно заметить, что дерево будет lg(σ) высоты и иметь σ-1 узлов. На каждом уровне дерева будет храниться n бит. То есть всего нужно хранить n*lg(σ) бит, а сложность методов будет иметь множитель lg(σ).
Вейвлет дерево предоставляет два основных метода доступа.

Access(S[i])
Проверяем v_root[i]
Если «0» то S[i] в левом разделе словаря и левой ветви дерева, иначе направо. Остается решить на какую позицию в бит-карте узла проецируется символ. Если мы оперируем, например, вторым «0» в бит-карте очевидно символ будет проецироваться на вторую позицию левой ветви. Третья единица на третью позицию правой ветви и так вниз рекурсивно. Количество «0» до позиции i в бит-карте B принято считать функцией rank0(B, i), единиц rank1(B, i).

Функции rank() и select() базовые функции над бит-картами для компактных(succinct) структур данных. (Толковое объяснение функций с картинками можно посмотреть в уже упомянутом посте.

Алгоритмы для этих функции хорошо проработаны и реализованы.
Обратная операция:

Track(symbol, count) позволяет найти symbol в последовательности S[i] использованный count раз. Для реализации этого метода понадобится вторая базовая функция select0(j) возвращающая индекс j-го «0» в бит-карте (или select1(j)). Двигаемся от словаря вверх до корня применяя эту функцию. Нам нужно просто обратить предыдущий алгоритм и вместо rank() применять select().
Следует отметить, что вейвлет дерево совсем не обязательно должно быть сбалансированным. Зная что некоторые символы встречаются в последовательности чаще других мы очень можем применить кодирование Хаффмана при построении дерева. Это лишь изменит топологию, а алгоритмы и функции будут работать как и прежде. И мы сможем добиться дополнительного сжатия данных и коротких треков для высокочастотных символов словаря.

Рассмотрим применение вейвлет дерева для построения индекса полнотекстового поиска. Обычно для этой цели строят обратный индекс — массив ассоциирующий символы словаря с позициями вхождения в последовательность. Преимуществами в-дерева в таком амплуа можно считать:
- нет необходимости хранить саму исходную последовательность
- обратный индекс предоставляет только метод Track(symbol), а у в-дерева есть еще метод Access(i) предлагающий обратную операцию — поиск символа по прямому индексу за логарифмическое время.
То есть вейвлет дерево это сразу два индекса прямой и обратный в компактном представлении. Такая компактность позволяет работать с большими последовательностями в памяти.
Для быстрого поиска по индексу кроме rank() и select() нужен еще быстрый поиск по словарю, особенно если этот словарь большой. Типично применять для этого ассоциативный массив. Однако associative array очень общая структура с избыточными характеристиками. В текстовых системах эффективней trie, префиксное дерево, ключами которого являются строки а значениями числа. Кроме большей скорости и компактности по сравнению с ассоциативным массивом на хеш-функциях префиксное дерево еще предлагает специфические для текстовых систем методы — PrefixMatch() и PrefixPredict(), необходимые например для автоподсказок. Однако хранить дерево ссылками может быть неэффективным по сравнению с последовательными структурами. И способы сериализации префиксного дерева появились. Сначала triple array trie, которое потом было модифицировано до double array trie. Почитать теорию вопроса можно здесь, хорошо объяснен классический алгоритм. Но структура получилась довольно сложная в реализации. И вот пожалуйста — вариант double array trie пришедший не из академического мира, а из блога коммерческой японской компании. Хоть и несколько ограниченный но подкупающий элегантностью, лаконичностью и простотой реализации в коде. Очень succinct. Собственно результат на картинке:

По шагам. На следующей иллюстрации последовательность термов и префиксное дерево к ней.

Наивная сериализация этого дерева в матрицу. Термы — столбцы матрицы.

Нумеруем узлы. И вот изюминка, стратегия обхода дерева — "сперва брат". Не в глубину DFS, не в ширину BFS, а «по братски»(Sibling priority search). Рекурсивно: сперва всех братьев, потом вглубь. Такой способ обхода и позволяет сделать структуру компактной.

Double-array trie будет выглядеть так. В поле next индекс первого дочернего узла или, если дочернего нет и это лист, то индекс первого дочернего узла старшего брата (первого кузена). Тогда все дети узла T[i] между T[i].next… T[i].next.next На этом и строится поиск. Дополнительные чеки — является ли узел термом словаря, является ли листом дерева.

Формальный алгоритм построения в псевдокоде:
algorithm SFT(S: array of strings)
T = [] # empty array of nodes
T.append({ label: any symbol, next: 1, match: false, leaf: false })
construct(S, 1, |S|, 1, T, 1)
return T
algorithm construct(S, begin, end, depth, T, current)
if(d > |S[s]|)
T[current].match = true
if(++begin == end)
T[current].leaf = true
return
P = [] # empty array of integers
P.append(begin)
for(i = begin; i < end; )
T.append({ label: S[i][depth], next: NaN, match: false, leaf: false })
while(i < end && S[i][depth] == S[i+1][depth])
++i
P.append(i)
for(k = 1; k < |P| - 1; k = k + 1)
T[T[i].next + k].next = |T| + 1
construct(S, k, k + 1, depth + 1, T, T[current].next + k)
Пошаговая иллюстрация построения:

Формальный алгоритм доступа:
algorithm search(T, pattern)
u = 0
for(i = 1; i < |pattern|; i++)
if(T[u].leaf)
return false
u = T[u].next
v = T[u].next - 1
while(u < v)
m = (u + v) / 2
if(T[m].label < pattern[i])
u = m + 1
else
v = m
if(u > v || T[u].label != pattern[i])
return false
return T[u].matchВ текстовых системах большинство термов имеют уникальные окончания, а не рознятся в одной последней букве. Введя в таблицу еще один чек — tail сигнализирующий что далее следует окончание и ветвления больше не будет мы можем сократить количество проверок при поиске. Эта оптимизация не детализирована здесь, чтобы не загромождать повествование, но она сделана в коде.
Реализация на Go
Для начала очень обобщенно, а то Go ругают за отсутствие generic и object oriented. Вот generic вейвлет дерево, архитектура сверху.
type Bitmap interface {
Rank1(uint) uint
Rank0(uint) uint
Select1(uint) uint
Select0(uint) uint
Get(uint) int8
}
type WTree interface {
BitMap() Bitmap
RChild() WTree
LChild() WTree
Parrent() WTree
IsLeaf() bool
IsHead() bool
IsLChild() bool
}
func Access(wt WTree, pos uint) (WTree, uint) {
var bit int8
for !wt.IsLeaf() {
bit = wt.BitMap().Get(pos)
if bit == 0 {
pos = wt.BitMap().Rank0(pos) - 1
wt = wt.LChild()
} else {
pos = wt.BitMap().Rank1(pos) - 1
wt = wt.RChild()
}
}
return wt, pos
}
func Track(wt WTree, count uint, bit int8) (WTree, uint) {
lch := bit == 0
for {
if lch {
count = wt.BitMap().Select0(count)
} else {
count = wt.BitMap().Select1(count)
}
if wt.IsHead() {
break
}
lch = wt.IsLChild()
wt = wt.Parrent()
}
return wt, count
}Видно, что структура использует методы Child(), Parrent() характерные для дерева повторяя алгоритм буквально. Построить дерево на ссылках задача тривиальная. Сериализация сбалансированного дерева в массив тоже давно известна и не представляет труда:
leftChild=array[parrentIndex*2+1]
rightChild=array[parrentIndex*2+2]
parrent=array[(childIndex-1)/2]В качестве рабочей лошадки для операций над бит-картами будем использовать math/bits из stdlib. Этого нам вполне хватит(в Go качественная stdlib и ее обычно хватает). В качестве собственно бит-карты применяем []uint64.
Доступ к биту на позиции pos в карте представленной таким образом прост:
var bm []uint64
bit := bm[int(pos/64)] >> (pos % 64)) & 1Рутины Rank() Select() реализованы через библиотечную функцию bits.OnesCount64() (подсчет установленных в единицу бит), примерно так:
func (bm Bitmap64) Rank1(pos uint) (count uint) {
var n uint
for ; n < pos/64; n++ {
count += uint(bits.OnesCount64(bm[int(n)]))
}
count += uint(bits.OnesCount64(bm[int(n)] << (63 - pos%64)))
return
}Такая реализация Rank() дает линейную сложность от длины бит-карты. Длина бит-карты логарифмически снижается к листьям дерева от длины последовательности. В теоретических работах приводятся методы реализации Rank() Select() константной сложности. Это может быть достигнуто хранением дополнительных таблиц переходов, что то вроде динамического программирования. Эти методы не рассматриваются здесь ввиду громоздкой реализации в коде, но интересующимся succinct полезно знать что это возможно — возможны реализации Rank() Select() константной ассимптотической сложности ценой дополнительных расходов памяти и громоздкого кода.
В репозитарии github.com/uvelichitel/wtree есть пример использования generic кода для сбалансированного дерева сериализованного в массив. Прописаны методы доступа для этого массива и прописанные методы для бит-карты. Вы можете так же реализовать методы интерфейса для своей модели дерева, а готовый тип бит-карты просто включить (embedd) в свой тип.
Примерно так:
import "github.com/uvelichitel/wtree/bitmap64"
type Maps []bitmap64.Bitmap64
type WTArray struct {
*Maps
Mark int
}
...
func (wt WTArray) RChild() wtree.WTree {
wt.Mark = 2*wt.Mark + 2
return wt
}
...Теперь необходимые методы для интерфейсов реализованы и вы можете использовать функции вейвлет дерева Track() Access() для своего типа.
С деревьями Хаффмана посложней. Сериализация такого дерева уже требует применения LOUDS (смотреть вводную статью) Классический LOUDS в нашем случае избыточен потому что дерево Хаффмана бинарно и несбалансировано правой косынкой (а не любое дерево вообще). Будем сериализовать так — массив узлов и массив LBS (LOUDS Bit String), но LBS будет существенно проще классического, а именно — «0» для листа или «1». Для построения дерева Хаффмана нам нужна процедура слияния двух деревьев в одно. В нашем случае алгоритм будет выглядеть следующим образом(вот здесь алгоритмистика авторская).
Склеиваем дерево Huff{Nodes[], LBS[]} из деревьев Huff1{Nodes1[], LBS1[]) Huff2{Nodes2[], LBS2[]}
просматриваем оба дерева на каждом уровне "c" поочередно
пока с1>0 или c2>0
i1=c1 (узлы первого дерева на уровне с)
пока i1>0 (узлы на уровне с)
добавляем LBS1[i1] бит в итоговый LBS[]
если LBS1[i1] == 0, это лист, добавляем в Nodes[] узел из Nodes1[]
иначе c1=c1+2, это не лист и на следующем уровне этот узел добавит две ветви
i1--
i2=c2 (тоже для второго дерева на уровне с)
пока i2>0 (узлы на уровне с)
добавляем LBS1[i1] бит в итоговый LBS[]
если LBS2[i2] == 0, это лист, добавляем в Nodes[] узел из Nodes2[]
иначе c2=c2+2, это не лист и на следующем уровне этот узел добавит две ветви
i2--(алгоритм реализован функцией combine() в репозитарии)
Имея процедуру склейки мы легко можем написать алгоритм конструирования дерева Хаффмана из частотного словаря. Классический алгоритм использует «кучу». Но есть решение посвежее — если частотный словарь отсортирован, а частотные словари как правило предлагаются уже отсортированными, то можно обойтись «очередью».
1. Две пустых очереди
2. Построить узел из каждого элемента сортированного частотного словаря и запустить в первую очередь (в невозрастающем порядке).
3. Извлечь два поддерева
a) если вторая очередь пуста извлекать из первой
b) если первая очередь пуста извлекать из второй
с) иначе извлекать из той очереди где меньше вес
4. Слить два извлеченных дерева, присвоить вес равный сумме весов и запустить во вторую очередь
5. Повторять до опустошения обеих очередей.
Последнее извлеченное дерево будет результирующим деревом Хаффмана.Ассимптотическая сложность O(n). Ассимптотическая сложность алгоритма с "кучей" O(nLogn), зато работает на неотсортированных частотных словарях.
Довольно просто, но в процедурных языках C-семейства нет эффективного примитива очереди.
Обычно для реализации очереди в последовательной памяти (не перевязанной ссылками) применяют идею кольцевого буфера. Именно так, кстати, реализованы каналы channel в Go.
type Queue struct {
buf []Elem
head, tail, count int
}
//указатели head, tail обеспечивают механику кольца через buf[0]
//count чек свободного места в буфере
//примерно так
func (q *Queue) Push(elem Elem) {
if q.count == len(q.buf) {
q.resize() //если длины буфера не хватает делается аллокация
}
q.buf[q.tail] = elem
// bitwise modulus
q.tail = (q.tail + 1) & (len(q.buf) - 1)
q.count++
}(В репозитарии есть функции Huffman() и Huffman1() для построения дерева Хаффмана из частотного словаря использующие "очередь" и "кучу" соответственно).
Структура репозитария:
- wavelettree.go в корне — очень generic код демонстрирующий идею и подход
- bitmap64 — рабочая лошадка, содержит примитивы репрезентации bitmap массивом int64, можно включать в свои поделки succinct типов. Необходимо заметить что методы этого пакета возвращают только одно значение а не кортеж (value, error) как это заведено в Go. Так сделано сознательно, из соображений что эти методы будут крутиться в рабочих, нагруженных циклах. А проверки валидности предпологается выносить уровнем абстракции выше, в пользу производительности.
- dict — реализация словаря термов на double-array-trie вместо ассоциативного массива
- wtarray — представление сбалансированного вейвлет дерева последовательным массивом
- wutarray — представление небалансированного вейвлет дерева Хаффмана последовательным массивом
- hwtree — слабо структурированный код написанный для решения частной задачи (мониторинг больших логов в памяти) с которой справился, реализует вейвлет-дерево Хаффмана (два варианта кодирования)
- indexer — набор вспомогательных методов упрощающих построение исполняемого приложения: сериализация/десериализация на диск, реализация интерфейсов writer/reader, многопоточность.
Цитатник:
- habr.com/ru/company/mailru/blog/479822
- В комментариях исходников math/bits упоминается "Bit Twiddling Hacks By Sean Eron Anderson seander@cs.stanford.edu".Это хороший материал.
- linux.thai.net/~thep/datrie
- Journal of Discrete Algorithms Wavelet trees for all Gonzalo Navarro www.sciencedirect.com/science/article/pii/S1570866713000610
- engineering.linecorp.com/ja/blog/simple-tries
