Всем привет!
Я руковожу сектором тестирования в отделе системного анализа и тестирования департамента корпоративных систем ЛАНИТ. В этой сфере я уже 14 лет. В 2009 году я впервые столкнулась с тестированием государственной информационной системы. И для ЛАНИТ, и для заказчика — это был огромный и значимый проект. Он более девяти лет находится в промышленной эксплуатации.
 Источник
Источник
Этот текст познакомит вас с подходом к тестированию ГИС, который используют у нас в компании. В частности, вы узнаете (ссылка проводит вас к фрагменту статьи, о котором говорится в конкретном пункте):
До ЛАНИТ я работала в группе тестирования из пяти человек, где все задачи распределяла руководитель группы. Когда я пришла в ЛАНИТ, мне поручили управлять территориально распределенной командой тестирования из четырех тестировщиков, которых на старте проекта привлекли для тестирования государственной информационной системы. По мере развития проекта, количество тестировщиков в группе увеличивалось пропорционально увеличению функционала.
Когда мы начали работать с ГИС, в первую очередь пришлось столкнуться с большими объемами функциональности (несколько десятков подсистем, в каждой до сотни функций), которые необходимо было протестировать в короткие сроки. Перед командой стояли задачи не запутаться в объеме функций и минимизировать риски пропущенных дефектов.
Нормативная документация, на базе которой разрабатывались технические спецификации, постоянно менялась, и всей команде приходилось адаптироваться к нововведениям: мы пересматривали технические спецификации на разработку и приоритеты на проекте (как следствие, менялся план тестирования).
Аналитикам было сложно подстроиться к частой смене нормативной документации, что привело к непониманию того, как поддерживать технические спецификации в актуальном состоянии, как всегда иметь набор актуальных спецификаций для каждой версии системы, как и где отображать степень влияния изменения в одной спецификации на множество других связанных документов.
Поскольку результатом работы аналитиков пользовались разработчики и тестировщики, то вопросы в актуальности технических спецификаций, понятности ведения истории спецификаций, соответствие набора технических спецификаций готовящейся версии релиза, стояли остро для всех участников проектной команды. Последствия от путаницы с документацией, версионностью технических спецификаций сказывались на стоимости реализации проекта.
Порой ситуация поворачивалась на 180 градусов. Согласитесь, когда поезд мчится на высокой скорости, резко изменить направления движения без последствий невозможно.
Я регулярно присутствовала на совещаниях и понимала причину перемен в проекте. Самое сложное — объяснить удаленным тестировщикам, почему мы месяц тестировали новый реестр, а сейчас нам надо все забыть и готовиться к тесту полностью переработанного функционала этого реестра. Люди начинали чувствовать себя винтиками в гигантской машине, а свой труд считали совершенно бесполезным.
Сначала такие перемены раздражали коллектив и сильно демотивировали. Но команда приняла факт, что повлиять на изменение технических спецификаций нельзя, но можно научиться работать с этим. В тот сложный для проекта период у команды тестировщиков появилась новая задача, которая обычно отсутствовала на менее крупных проектах, — тестирование требований.
В итоге минусы от изменений требований превратились для тестировщиков в плюсы в виде новой задачи для тестирования и возможности повлиять на итоговый результат проекта.
Помимо взаимодействия с аналитиками команда тестирования оказалась зависимой от коммуникаций с внешними системами, с которыми должны выполнять интеграцию. Далеко не все из них готовы были предоставлять свой тестовый контур и информировать сторонние системы о своих сроках релиза и обмениваться информацией об изменениях в сервисах. Такая рассинхронизация в коммуникациях или безалаберное отношение к уведомлению о составе изменений веб-сервисов со стороны внешних систем приводила к ошибкам в продуктиве и сложностям в проведении интеграционного тестирования. Тестировщикам пришлось налаживать коммуникации с внешними системами, нарабатывать навык тестирования интеграции и привлекать разработчиков для реализации заглушек.
Вся группа тестирования, участвовавшая в проекте, столкнулась с необходимостью погружения в производственный процесс команды разработки. На старте проекта, команда разработки начала искать новые подходы к организации работы, внедрили модели ветвления Feature Branch Workflow и модель Gitflow. Разработка небольших проектов ранее обходились без кучи веток, всем было комфортно. Но столкнувшись с проблемой невозможности стабилизировать версию на протяжении пары месяцев для очередной демонстрации промежуточной стадии проекта заказчику, проанализировав причины, руководитель разработки и архитектор пришли к выводу, что процесс создания софта надо менять. Тогда и стали активно применять Feature Branch Workflow и Gitflow на проекте. Появилась еще одна новая задача у тестирования — изучить принципы работы моделей разработки, чтобы адаптироваться к процессу создания софта.
ГИС подразумевает деление проекта на функциональные блоки, каждый из которых включает набор компонентов, тесно связанных между собой по бизнесу и/или выполняющих самостоятельную техническую функцию. Если на старте проекта все тестировщики проверяли вновь поступающие функциональные блоки, и все в команде были взаимозаменяемы, обладали равной степенью знаний всех блоков, то по мере наращивания объемов проекта количество тестировщиков также пришлось увеличивать и разделять на группы. Рост команды привел к процессу разделения по группам тестирования, выделению проектных ролей в рамках каждой группы.
По мере развития проекта стали проявляться особенности государственных информационных систем.
Прежде всего к крупным ГИС предъявляются повышенные требования к надежности и нагрузке, работа системы — в режиме 24/7, сбои в работе системы не должны приводить к потерям данных, время восстановления системы — не более 1 часа, время отклика — не более 2 секунд и многое другое.
Поскольку это был веб-портал, тестировщикам пришлось погрузиться в процесс тестирования многопользовательских веб-порталов и выстраивать подход к проектированию тестов и процессу теста с учетом особенностей веб-интерфейса.
Веб-приложение одновременно может использоваться большим количеством пользователей. Потребовалось предусматривать нагрузочное тестирование открытой части ГИС, используемой всеми пользователями, предугадать модель нагрузки и провести нагрузочное тестирование.
Пользователь может иметь свои уровни доступа. Потребовалось тестировать матрицу ролей пользователей в подсистеме прикладного администрирования с применением техник тест-дизайна.
Пользователи могут обращаться к одним сущностям, что приводит к конкурентному доступу. Чтобы вводимые данные одного пользователя не затирали данные другого, пришлось провести тестовый анализ ситуаций, в которых возможно одновременное изменение данных в личных кабинетах пользователей, включить в тесты проверки правильной отработки контроля с диагностическими сообщениями.
Одной из особенностей системы было использование поискового движка SphinxSearch, с которым команда тестирования не умела работать. Чтобы разобраться в тонкостях тестирования Sphinx пришлось консультироваться с разработчиками и понять, как происходит индексирование данных.
Тестировщики осваивали особенности тестирования поиска по словоформам, фрагментам слова, синонимам, по поиску внутри приложенных документов, стали разбираться, почему только что созданные поисковые данные не попали в результат поиска, и является ли это ошибкой.
В проекте была подсистема прикладного администрирования, которая включала в себя не только регистрацию пользователей, но и усложнялась наличием матрицы ролей пользователей. Она настраивалась в личных кабинетах администраторов организаций. Количество комбинаций проверок матрицы ролей было огромным и количество типов организаций также было не маленьким, то есть число комбинаций проверок росло в геометрической прогрессии. Потребовалось менять привычный подход к проектированию тестов, применяемый ранее на небольших проектах.
Поскольку система предполагала наличие веб-интерфейса, понадобилось предусмотреть кроссбраузерное тестирование, которое изначально не было запланировано. Когда проект только начинался, Internet Explorer 7.0 был единственным браузером, поддерживающим отечественную криптографию, и основное число пользователей пользовались именно этим браузером. Поэтому на старте проекта, для тестирования логики и функционала работы личных кабинетов использовался только IE этой версии, а вот для открытой части портала, требовалась поддержка всех существующих на тот момент браузеров. Однако в тот момент про кроссбраузерное тестирование не подумали.
Когда у меня спросили: «Как система ведет себя во всех известных версиях браузеров?» — я была, мягко говоря, в панике, так как объем тестовой модели был огромен (около 4000 тест-кейсов), регрессионный тестовый набор составлял порядка 1500 тест-кейсов, а команда тестирования всей толпой проверяла исключительно на одном выбранном по дефолту браузере. Данный кейс пришлось очень быстро решать и применять смекалку, чтоб успеть в сроки первого релиза и покрыть тестами основные версии браузеров.
На просторах интернета тогда было мало статей, посвященных тестированию, разработке тестовых моделей. Для нашей команды непонятной на тот момент задачей было, как создавать, где хранить и как поддерживать в актуальном состоянии большую тестовую модель. Не ясно было, как уйти от исследовательского тестирования, которое могло стать бесконечным, а на бесконечный тест не было ресурсов: ни человеческих, ни временных.
После запуска ГИС в опытную эксплуатацию, а затем в промышленную, появилась новая задача — обработка инцидентов пользователей.
До того, как была создана полноценная служба сопровождения пользователей ГИС, первый удар пользовательских обращений встретила команда тестирования, как наиболее погруженная в детали работы системы, пытаясь совместить основные задачи по тестированию новых доработок, а также своевременно обрабатывать поступающие инциденты, на которые был наложен SLA.
С такой задачей группа тестирования ранее не сталкивалась. Поток инцидентов нужно было обрабатывать, систематизировать, локализовывать, править, проверять и включать изменения в новый релизный цикл.
Уровень понимания и зрелости процесса эксплуатации рос и совершенствовался по мере роста самой системы.
Я перечислила лишь часть особенностей, с которыми команда тестирования столкнулась при работе с ГИС.
В процессе работы команды тестирования над несколькими крупными ГИС мы придумали рекомендации для тест-менеджеров. В дальнейшем они трансформировались в методологию процесса тестирования таких систем в нашем департаменте и продолжают совершенствоваться при решении новых задач в проектах аналогичного масштаба.
Не паниковать и разбить функционал на блоки/модули/функции, подключить аналитика к аудиту результата, убедиться в правильности видения функциональных блоков.
Рекомендуем составить:
Функционала меньше не становится. Теперь его все так же много, но он в новом представлении (в виде матрицы). Необходимо определить, какие функции являются наиболее важными с точки зрения бизнеса и что нельзя предоставить пользователям в «сыром» виде. Так начинается приоритезация функционала. Идеально, если тестировщику в этом будет помогать аналитик. Как минимум, он оценит корректность расставленных тестированием приоритетов.
Наиболее важные функции/блоки/модули будут относиться к высокому приоритету для теста, менее важные — покрываться тестами вторым приоритетом, остальные — третьим или в случае, когда «сроки горят», можно отложить их тест на более спокойное время.
Таким образом, у нас появилась возможность проверять функциональность, действительно важную для заказчика. Мы навели порядок в огромном количестве функций, понимаем, что покрыто тестами, а что еще предстоит покрыть, знаем, что внутри необходимо усилить со стороны тестирования, на случай болезней/увольнений ответственных тестировщиков, понимаем, кому из тестировщиков команды передавать в тест доработки (в соответствие с матрицей знаний), какие новые интересные функции/модули/подсистемы я могу предложить условным Васе, Пете, Лизе, когда они устали тестировать одно и то же. То есть у меня появился наглядный инструмент мотивации тестировщиков, желающих узнавать что-то новое на проекте.
Рекомендуем внедрить процесс тестирования требований на проекте. Чем раньше обнаружен дефект, тем меньше его стоимость.
Тестировщики, распределенные по матрице знаний, по факту готовности технических спецификаций на разработку, сразу приступают к их изучению и проверке. Для того, чтобы всем было понятно, какие ошибки в требованиях, был разработан набор правил для аналитиков «Рецепт качественных требований», по которым они старались писать требования, также созданы шаблоны технических спецификаций, чтобы они описывались в едином стиле. Правила к формату технических спецификаций и рекомендации к описанию требований, были выданы и тестировщикам для понимания, какие ошибки искать в требованиях.
Конечно, основная задача тестировщика была найти логические нестыковки или неучтенные моменты влияния на смежные функции/подсистемы/модули, которые мог пропустить аналитик. После обнаружения дефектов они фиксировались в багтрекере, назначались на автора требования, аналитик останавливал разработку и/или в чате с тестировщиком и разработчиком сообщал, что в условие будет внесено изменение в соответствии с дефектом (чтобы не тормозить разработку), вносил правки и публиковал исправленную версию требований. Тестировщик проверял и закрывал работу над дефектом к требованиям. Эта процедура давала команде уверенность, что через пару недель разработки, обнаруженная проблема точно не всплывет в тесте.
Помимо раннего обнаружения дефектов мы получили мощный инструмент сбора метрик по качеству работы аналитиков. Имея статистику по количеству ошибок в требованиях, ведущий аналитик проекта мог предпринимать меры, чтобы улучшить качество работы в своей группе.
Необходимо изучить требования к нагрузке, придумать её модель, разработать тест-кейсы, согласовать тестовую модель нагрузки с аналитиком и разработать нагрузочные скрипты с привлечением компетентных специалистов по нагрузочному тестированию.
Конечно, с тестовой моделью нагрузки можно не угадать, но для более точного попадания помимо аналитика можно привлечь архитектора или DevOps-специалиста, которые проанализировав информацию, статистику, метрики, смогут подсказать, какие еще кейсы необходимы в предложенной модели нагрузки.
Также стоит внедрить процесс запуска нагрузочных тестов, снятия результатов нагрузки и передачи его разработчикам для устранения узких мест.
Процесс нагрузки проводить регулярно перед выпуском каждого релиза, периодически менять модель нагрузки, чтобы выявить новые узкие места.
Есть базовые пути: например, можно пойти на курсы повышения квалификации по теме тестирования Rest API, почитать статьи в интернете, получить обмен опыта с коллегами через Skype, с демонстрацией процесса, нанять в группу тестирования специалиста, хорошо разбирающегося в тестировании Rest API.
Способов погрузиться в этот вид тестирования много. В моей команде был нанят опытный специалист, который в будущем обучил меня и всю команду тестирования, разработал методички: на что обращать внимание при тестировании Rest API, как составлять тест-дизайн для проверки интеграции, проводил вебинары с демонстрацией процесса тестирования на всю команду.
Мы придумали тестовые задания, на которых каждый имел возможность потренироваться и погрузиться в этот процесс. Сейчас уже наработанный с годами материал только совершенствуется, и процесс обучения и погружения в тестирование Rest API занимает 1-2 недели, тогда как ранее на погружение уходил месяц и более, в зависимости от сложности проекта и объемов тестовой модели.
 Источник
Источник
Пока ГИС на начальном этапе разработки, есть всего две ветки кода: мастер и релизная. Вторую отделяют на этапе стабилизации для проведения завершающих регрессионных тестов и исправления точечных дефектов регресса.
Когда релизную ветку отправили в production и началась следующая итерация разработки, в какой-то момент решили сделать параллельной разработку новых задач, чтобы более крупную задачу, запланированную через релиз, успеть сделать в сроки. В какой-то момент таких веток стало 3-4 и даже больше. Появилось более трёх тестовых стендов, развернутых с целью, как можно скорее приступать к тестированию доработок будущих релизов.
Тестировщики уверены, что специалист со стороны инфраструктуры установил, например, доработку №10001 на один из тестовых стендов, выполнил все корректно, и они могут приступить к тесту. Специалист инфраструктуры выполнил deploy из ветки кода, отчитался, что стенд развернут, код установлен, можно тестировать.
Мы начинаем тест и понимаем, что:
Провели анализ и выяснили, что разработчики не передали специалисту инфраструктуры инструкцию, из какой ветки собирать deploy, сотрудник собрал из ветки develop, при этом разработчик успел слить в ветку develop только часть кода из feature-ветки.
Тестировщик, совершенно не понимающий в ведении веток разработчиками, получив задачу и ссылку на стенд, побежал тестировать, потратил время, завел много дефектов, большая часть оказались неактуальны из-за всей этой путаницы.
Что мы сделали, чтобы избежать в будущем подобных ситуаций:

Рекомендуем составлять стратегию тестирования заранее, но раз уж этот момент упустили, вероятно, вам пригодится мой опыт.
Во-первых, надо понять, какие браузеры указаны в требованиях. Если с этим определились, а времени совсем нет, смотрим статистику наиболее часто используемых браузеров, например, тут. Потом пытаемся охватить три или пять максимально популярных браузеров.
Поскольку проект большой и команда тестирования большая была физическая возможность выделить по одному популярному по статистике браузеру каждому тестировщику. Он проводит свои регрессионные кейсы на выделенной версии браузера, особое внимание необходимо обращать на верстку, кликабельность кнопок и ссылок. Выглядит этот процесс так: например, есть 100 сценариев на регрессионный тест, в команде есть 5 тестировщиков, каждый может взять в работу по 20 сценариев, за каждым закреплено по браузеру. За один прогон регресса каждый тестировщик проверял свои кейсы в одном из браузеров. Покрытие в итоге не полное, но поскольку многие сценарии все равно повторяются в той или иной степени, то процент покрытия увеличивался за счет прохождения части регрессионный сценариев разными браузерами.
Конечно, это не дало 100% покрытия тестами всего функционала, но позволило существенно снизить риски попадания на production кроссбраузерных дефектов по основным бизнес-сценариям в системе.
Далее мы не только на регрессе, но и на тесте доработок и валидации дефектов выполняли проверки на разных браузерах, расширяя покрытие кроссбраузерности.
В будущем подход с распределением тестировщиков по браузерам стали применять и на тесте доработок, не дожидаясь этапа регрессионного тестирования, тем самым еще больше увеличив процент покрытия тестами разных версий браузеров.
Что мы получили:
Довольно быстро у нас встал вопрос о ведении тестов в едином хранилище, поддержке их в актуальном состоянии и о возможности выполнять тестовые прогоны с отметками о результате выполнения.
В команде были сотрудники, имеющие опыт работы с системой ведения тестов TestLink. Это единственная система управления тест-кейсами с открытым исходными кодами, благодаря чему она и была выбрана для работы. У этой системы очень простой графический интерфейс и дизайн без лишних изысков. Мы оперативно наполнили программу тестами, встал вопрос, как это поддерживать. Первое время тратилось очень много ресурсов на актуализацию кейсов под каждую доработку, этот вариант оказался нерабочим.
Посоветовавшись с аналитиком и командой тестирования, решили, что нет необходимости держать всегда в актуальном состоянии такую большую тестовую модель из-за затрат на ее поддержку.
Все кейсы были поделены в соответствии с матрицей функциональных требований на папки, каждый функциональный модуль/подсистема хранил набор кейсов в отдельной папке. Это позволило визуально структурировать тест-кейсы. Были созданы ключевые слова в TestLink, с помощью которых определялась принадлежность кейса к той или иной группе, например:
В итоге для новых доработок всегда проектируется тест-дизайн, в результате которого появляется документ чек-лист. В нем происходит ранжирование проверок по приоритетам, и только часть проверок попадает под «Приоритет 1» или smoke и на них уже создаются регрессионные тест-кейсы в системе TestLink.
Перед стартом регрессионного теста все подготовительные работы, включая актуализацию или добавление новых кейсов в регресс, выполнены. А это значит, что если запустить прогон тест-кейсов, актуальных для нового релиза, то они могут повлечь за собой дефекты при проверке HotFix по таким тест-кейсам.
Исправления HotFix сделаны на старой ветке кода (прошлый релиз) и в код внесены изменения по фиксам дефектов, тогда как в текущие тест-кейсы могли быть внесены изменения из доработок будущего релиза. То есть прогон тест-кейсов, актуальных для будущего релиза, может привести к регистрации ложных дефектов и сорвать сроки выпуска HotFix.
Чтобы избежать регистрации ложных дефектов и срыва сроков тестирования HotFix, решили использовать механизм, чем-то схожий с ведением веток кода. Только слияние и актуализация кейсов между ветками (читай «папками») TestLink осуществлялся вручную тестировщиками по определенному алгоритму, тогда как в модели Gitflow это делается автоматически средствами Git.
Вот так выглядит набор тест-кейсов в TestLink:

Был придуман процесс актуализации кейсов в TestLink
В случае необходимости актуализации кейсов:
Таким образом, мы всегда имеем актуальный тестовый набор кейсов, соответствующий прошлой релизной версии системы и его используем при тесте HotFix, а также ведем работу по актуализации нового тестового набора, готовимся к регрессионному тестированию и процессу стабилизации нового планового релиза. В какой-то момент одновременно может получиться сразу 3-4 тестовых ветки (читай «папки») TestLink, соответствующих разным версиям системы, что особенно актуально при тестировании доработок в фича-ветках.
После каждого релиза можем оценить на сколько у нас изменилась регрессионная модель, основываясь на метках «добавлен»/«изменен».
В случае, если регрессионная модель очень сильно увеличивается, при этом объем доработок в релизе существенно не изменился по сравнению с предыдущим релизом, то это повод задуматься о корректности выставления приоритетов в чек-листе проверок по доработке. Возможно, тестировщик сделал некорректный выбор кейсов для регресса и необходимо предпринять меры: например, объяснить тестировщику принцип выставления приоритетов, привлечь аналитика к согласованию приоритетов, изменить полученную регрессионную модель, убрав избыточные тест-кейсы.
Мы начали работать с регрессионной тестовой моделью, оптимизировали процесс разработки тест-кейсов регресса путем выделения приоритетов и включения в регресс только кейсов «Приоритета 1». Столкнулись с тем, что тестовая модель, спустя время, стала большой, затраты на прогон её кейсов выросли, и мы перестали укладываться во временной интервал, приемлемый для проведения регрессионного теста на проекте.
Пришло время внедрять автоматизацию тестирования, целью которой было:
Был разработан framework для автоматизации тестов GUI на Java (в качестве системы контроля версий исходного кода использовался GIT).
На разработку автотестов была привлечена отдельная команда автоматизированного тестирования, которая успешно справилась с поставленной задачей. Для новых проектов аналогичного масштаба в будущем планируется применять существующие наработки и запускать автоматизированное тестирование на старте проекта, чтобы как можно раньше получать пользу от его применения. Подробнее про автоматизацию тестирования крупной ГИС можно прочитать в статье моих коллег, принимавших непосредственное участие в организации и проведении автоматизированного тестирования.
Со стороны функционального ручного тестирования также была проведена оптимизация регрессионной модели.
На примере двух крупных ГИС мы с командой придумали и внедрили сессии тестирования или тест-туры, суть которых была в следующем: необходимо было проанализировать бизнес-процесс в каждой подсистеме и продумать сессию (тур) проверок, проходящих через этот бизнес-процесс, имитируя наиболее часто выполняемые действия пользователя по процессу.
На одном ГИС-проекте это называли «сессии тестирования», на другом назвали «тест-туром». Но суть оставалась единой — мы продумывали сквозной (через всю доработку) ключевой бизнес-сценарий, который полностью покрывает бизнес-идею реализуемой доработки (может быть несколько таких сценариев).
Сценарий тест-тура согласовывался с аналитиком, разрабатывались детальные регрессионные тест-кейсы и в случаях, когда не успевали провести регрессионный тест по всей тестовой модели, могли ограничиться проведением «регресс-сессии» или «регрессионного тест-тура», который, как правило, занимал меньше времени и позволял однозначно понять, есть ли проблемы по ключевым бизнес-процессам в системе.
В будущем, тест-туры покрывались авто-тестами, а освободившиеся от рутинных проверок тестировщики переключались на тестирование доработок следующих плановых релизов.
Пример тестового-тура: «создание, редактирование, публикация и аннулирование сущности».
Тест-тур можно усложнить, например:
Рекомендую не относиться к процессу локализации инцидентов от пользователей, как к низкоуровневой задаче. Стоит воспринимать это как часть процесса тестирования. Кроме того, это гораздо более творческий процесс, чем, к примеру, проверять по тест-кейсам. Необходимо применить логику, опыт техник тест-дизайна, чтоб докопаться до сути ошибки, отловить ее и передать в разработку.
Конечно, желательно организовывать процесс эксплуатации ГИС с тремя уровнями поддержки (идеально) и как итог на команду тестирования будут проваливаться уже отфильтрованные на первых двух линиях, самые неочевидные инциденты, локализовать которые способны часто только тестировщики.
Для соблюдения SLA рекомендуем внести процесс локализации инцидентов в обязанность в команде тестирования с наивысшим приоритетом и стараться внедрить методы оптимизации работ, чтобы скорость воспроизведения инцидента была максимально высокой.
Для оптимизации временных затрат тестировщиков можно:
Про «матрицу знаний» было написано выше. Что касается «матрицы ответственности» — это таблица, в которой по аналогии с «матрицей знаний» выписаны функциональные блоки/модули/подсистемы и указано, кто из группы тестирования отвечает за тестирование функционала, как правило, — это тимлид группы или старший/ведущий тестировщик в группе.
Это больная тема, с которой мы сталкивались на нескольких крупных ГИС-проектах. Команда сделала «матрицу знаний», тестировщики провели самооценку степени погруженности в функционал и закрепились за своим кусочком функционала. Но в какой-то момент опытные тестировщики, участвовавшие со старта проекта, выбыли из группы, а новые специалисты еще не были погружены во все бизнес-процессы и не видели полной картины. Это привело к тому, что при тестировании кейсов в одном модуле результаты этого кейса должны были использоваться в следующем модуле и в итоге, если на вход второго модуля подавались некорректные результаты (предусловия были не идеальные для выполнения кейсов из предыдущего модуля), то требовалось анализировать ситуацию и регистрировать ошибки.
Но тестировщики не задумывались, почему им на вход пришли такие цифры и просто отрабатывали свои кейсы. Формально тест проведен, все хорошо, дефектов не обнаружено, а при приемке функционала аналитиком или при подготовке к приемо-сдаточным испытаниям, выясняются существенные проблемы в работе бизнес-логики, которые пропустили на тесте. Причина оказалась в непонимании сквозного бизнес-процесса, выполняемого системой.
В сложившейся ситуации было предпринято следующее:
Фух! Постаралась собрать основные проблемы и рекомендации по их устранению, однако это далеко не вся полезная информация, которой хочется поделиться.
Прежде чем внедрить на проекте сбор метрик, мы задались вопросом: «Зачем нам это делать?» Главными целями стали отслеживание качества работы команды тестирования, качества выпускаемого в production релиза, отслеживание показателей эффективности работы участников группы тестирования, чтобы понимать, как развивать команду.
Был проведен анализ, какие метрики необходимы для достижения поставленных целей. Далее распределили их по группам. Затем обдумали, что можно измерять без дополнительных изменений в процессе, а где потребуется помощь со стороны других участников проектной команды.
Когда все подготовительные этапы были пройдены, началась регулярная сборка метрик: раз в месяц/релиз/спринт/квартал — в зависимости от проекта и особенностей производственного процесса.
Собрав первые метрики, потребовалось определить целевые показатели, к которым мы хотим стремиться на данном этапе развития проекта. Далее оставалось регулярно снимать метрики и анализировать причины отклонения их от целевых показателей, принимать меры, направленные на улучшение показателей, то есть оптимизировать не только процесс тестирования, но и весь производственный процесс на проекте.
Конечно, в улучшении качества задействованы не только тестировщики, к оптимизации процесса привлекались и аналитики и разработка и релиз-менеджер, DevOps-инженеры — все ключевые участники процесса, так как все желали повышать качество релиза и совершенствоваться в работе.
Пример, как выглядит сбор метрик и целевые показатели на одном из завершенных проектов:
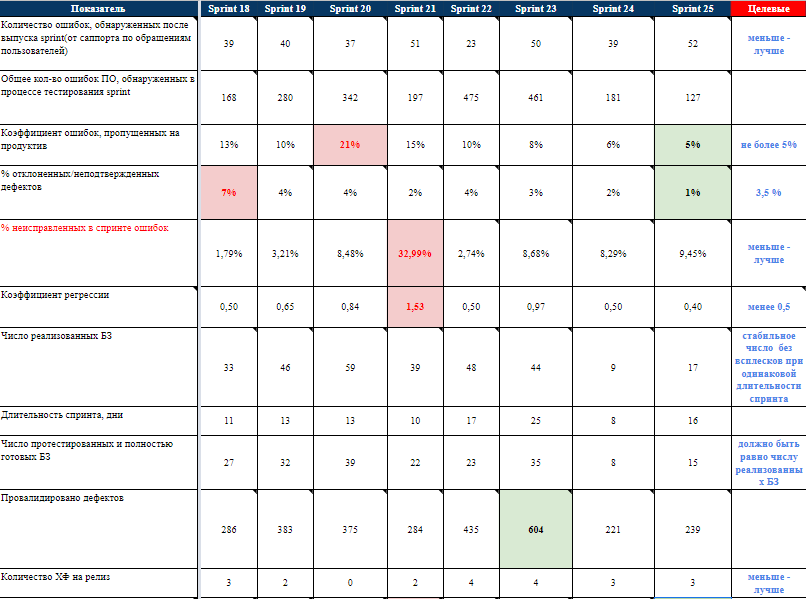
Для того, чтобы сообщать руководителю проекта более точные сроки по завершению работ тестирования, основываясь на сборе метрик с однотипных проектов, была разработана методика для оценки трудозатрат тестирования, позволяющая максимально точно сообщать сроки завершения тестирования и оповещать о рисках тестирования.
Эта методика применяется на всех проектах по реализации ГИС, отличия могут быть только в некоторых значениях метрик, но принцип расчета одинаковый.
Временные метрики получены путем многократных замеров фактических затрат тестировщиков разного уровня компетенции на разных проектах, взято среднее арифметическое.
Время на регистрацию ошибки — 10 минут (время на регистрацию 1 ошибки в багртекере).
Время на валидацию ошибки/уточнения — 15 минут (время на проверку корректности исправления 1 ошибки/уточнения).
Время на написание 1 ТК (тест-кейса) — 20 минут (время на разработку тест-кейса в системе TestLink).
Время на выполнение 1 ТК — 15 минут (время на выполнение проверок по тест-кейсу в системе TestLink).
Время на тест. Суммарное время, полученное путем сложения затрат в Чек-листе по столбцу «Время выполнения, мин».
Время на отчет по тестированию — 20 минут (время на написание отчета по шаблону).
Время на ошибки. Плановое время на регистрацию всех ошибок/уточнений, (время на регистрацию 1 ошибки/уточнения * возможное количество ошибок/уточнений (10 ошибок на доработку — предполагаемое количество ошибок на одну доработку)).
Общее время на DV (defect validation). Плановое время на валидацию всех найденных и исправленных ошибок/уточнений (время на валидацию 1 ошибки/уточнения * предполагаемое количество ошибок/уточнений).
Подготовка тестовых данных. Время на подготовку тестовых данных рассчитывается субъективно на основании опыта тестирования аналогичных задач на текущем проекте в зависимости от разных параметров (объем задачи с точки зрения Тест аналитика, компетенции команды разработки кода (новая неизвестная команда или проверенная команды, по которой есть статистика по качеству работы), интеграции между разными модулями и т.д.).
Путем замеров фактических затрат на одном из проектов было вычислено следующее:
В особенных случаях, плановые затраты на подготовку тестовых данных могли меняться по согласованию с тест-менеджером.
Время на написание ТК. Время на написание ТК, которое оценивается после готовности чек-листа проверок и установки проверкам приоритетов для тестирования. На регрессионный тест составлялись ТК, помеченные Приоритетом 0 (количество проверок Приоритета 0 * 20 минут (время на написание 1 ТК)).
Время на регресс по ТК. Время на выполнение одной итерации регрессионного тестирования по ТК в системе TestLink (количество ТК * среднее время выполнения 1 ТК (15 минут)).
Риски. Закладывается 15% от времени на тест (под рисками понимаются все ручные операции, падения стендов, блокирующие проблемы и т. д.).
Общее время на тестирование. Общие затраты на выполнение тестирования по одному ЧЛ (подготовка тестовых данных + выполнение теста + время на регистрацию ошибок/уточнений + валидация ошибок/уточнений + время на регресс по ТК Приоритета 0 + риски) в ч/ч.
Общее время на задачу. Суммарные затраты на всю задачу тестирования, цифра в ч/ч (Общее время на тестирование + время на отчет + время на написание ТК).
Все эти метрики используются на проекте для решения разных задач, связанных с планированием, оценками работ, как временных так и финансовых. Как показала практика, подобная оценка дает минимальную погрешность (не более 10%), что является достаточно высоким показателем достоверности оценки.
Конечно, вы можете не применять какие-то метрики или именно ваши метрики по статистике могут сильно отличаться, но принцип оценки затрат на работы по тестированию можно применить к любому проекту и подобрать наиболее оптимальную формулу расчета, применительно к вашему проекту и команде.
Важно показать тест-менеджерам и тестировщикам, что столкнувшись с трудностями и новыми задачами, можно находить пути решения, оптимизировать процесс тестирования и стараться применить накопившийся опыт для будущих проектов.
Всем читателям я приготовила сюрпризы — рецепт успешного процесса тестирования ГИС и шаблоны документов, которые вы сможете скачать и использовать на ваших проектах.
Итак, рецепт, как сделать процесс тестирования крупной информационной системы успешным, и что мы рекомендуем обязательно включить в этот процесс, постараюсь изложить кратко и ёмко.
Со стороны процесса аналитики:
Со стороны процесса тестирования:
Сейчас я как раз готовлюсь к тестированию новой ГИС. Вот так выглядит моя рабочая Wiki, в которой уже учтены многие моменты, которые мы рекомендовали сделать:

Если вы дочитали статью до конца, вы заслужили подарок. Хочу поделиться с вами полезными шаблонами, которые можно использовать в работе:
Надеюсь, наши рекомендации, примеры, идеи, ссылки и мои шаблоны помогут многим командам грамотно выстроить процесс тестирования, оптимизировать свои затраты и успешно справиться с поставленными задачами на ответственном и сложном проекте.
Желающим присоединиться к команде тестирования ЛАНИТ и поучаствовать в тестировании ГИС, советую посмотреть вакансии нашей компании.
Желаю всем интересных проектов и удачи!
P.S. Очень уж напрашивается провести небольшой опрос.
Я руковожу сектором тестирования в отделе системного анализа и тестирования департамента корпоративных систем ЛАНИТ. В этой сфере я уже 14 лет. В 2009 году я впервые столкнулась с тестированием государственной информационной системы. И для ЛАНИТ, и для заказчика — это был огромный и значимый проект. Он более девяти лет находится в промышленной эксплуатации.

Этот текст познакомит вас с подходом к тестированию ГИС, который используют у нас в компании. В частности, вы узнаете (ссылка проводит вас к фрагменту статьи, о котором говорится в конкретном пункте):
- с какими трудностями мы столкнулись при тестировании первой крупной ГИС;
- об особенностях ГИС, о которых мы узнали на старте проекта;
- с какими проблемами столкнулись и как смогли их решить;
- методики, которые мы применяли для оценки трудозатрат (они актуальны для любого крупного проекта);
- рецепт организации успешного тестирования;
- какие шаблоны документов могут пригодиться в работе тест-менеджерам.
До ЛАНИТ я работала в группе тестирования из пяти человек, где все задачи распределяла руководитель группы. Когда я пришла в ЛАНИТ, мне поручили управлять территориально распределенной командой тестирования из четырех тестировщиков, которых на старте проекта привлекли для тестирования государственной информационной системы. По мере развития проекта, количество тестировщиков в группе увеличивалось пропорционально увеличению функционала.
Глава 1. Старт первого проекта тестирования ГИС
Когда мы начали работать с ГИС, в первую очередь пришлось столкнуться с большими объемами функциональности (несколько десятков подсистем, в каждой до сотни функций), которые необходимо было протестировать в короткие сроки. Перед командой стояли задачи не запутаться в объеме функций и минимизировать риски пропущенных дефектов.
Нормативная документация, на базе которой разрабатывались технические спецификации, постоянно менялась, и всей команде приходилось адаптироваться к нововведениям: мы пересматривали технические спецификации на разработку и приоритеты на проекте (как следствие, менялся план тестирования).
Аналитикам было сложно подстроиться к частой смене нормативной документации, что привело к непониманию того, как поддерживать технические спецификации в актуальном состоянии, как всегда иметь набор актуальных спецификаций для каждой версии системы, как и где отображать степень влияния изменения в одной спецификации на множество других связанных документов.
Поскольку результатом работы аналитиков пользовались разработчики и тестировщики, то вопросы в актуальности технических спецификаций, понятности ведения истории спецификаций, соответствие набора технических спецификаций готовящейся версии релиза, стояли остро для всех участников проектной команды. Последствия от путаницы с документацией, версионностью технических спецификаций сказывались на стоимости реализации проекта.
Порой ситуация поворачивалась на 180 градусов. Согласитесь, когда поезд мчится на высокой скорости, резко изменить направления движения без последствий невозможно.
Я регулярно присутствовала на совещаниях и понимала причину перемен в проекте. Самое сложное — объяснить удаленным тестировщикам, почему мы месяц тестировали новый реестр, а сейчас нам надо все забыть и готовиться к тесту полностью переработанного функционала этого реестра. Люди начинали чувствовать себя винтиками в гигантской машине, а свой труд считали совершенно бесполезным.
Сначала такие перемены раздражали коллектив и сильно демотивировали. Но команда приняла факт, что повлиять на изменение технических спецификаций нельзя, но можно научиться работать с этим. В тот сложный для проекта период у команды тестировщиков появилась новая задача, которая обычно отсутствовала на менее крупных проектах, — тестирование требований.
В итоге минусы от изменений требований превратились для тестировщиков в плюсы в виде новой задачи для тестирования и возможности повлиять на итоговый результат проекта.
Помимо взаимодействия с аналитиками команда тестирования оказалась зависимой от коммуникаций с внешними системами, с которыми должны выполнять интеграцию. Далеко не все из них готовы были предоставлять свой тестовый контур и информировать сторонние системы о своих сроках релиза и обмениваться информацией об изменениях в сервисах. Такая рассинхронизация в коммуникациях или безалаберное отношение к уведомлению о составе изменений веб-сервисов со стороны внешних систем приводила к ошибкам в продуктиве и сложностям в проведении интеграционного тестирования. Тестировщикам пришлось налаживать коммуникации с внешними системами, нарабатывать навык тестирования интеграции и привлекать разработчиков для реализации заглушек.
Вся группа тестирования, участвовавшая в проекте, столкнулась с необходимостью погружения в производственный процесс команды разработки. На старте проекта, команда разработки начала искать новые подходы к организации работы, внедрили модели ветвления Feature Branch Workflow и модель Gitflow. Разработка небольших проектов ранее обходились без кучи веток, всем было комфортно. Но столкнувшись с проблемой невозможности стабилизировать версию на протяжении пары месяцев для очередной демонстрации промежуточной стадии проекта заказчику, проанализировав причины, руководитель разработки и архитектор пришли к выводу, что процесс создания софта надо менять. Тогда и стали активно применять Feature Branch Workflow и Gitflow на проекте. Появилась еще одна новая задача у тестирования — изучить принципы работы моделей разработки, чтобы адаптироваться к процессу создания софта.
ГИС подразумевает деление проекта на функциональные блоки, каждый из которых включает набор компонентов, тесно связанных между собой по бизнесу и/или выполняющих самостоятельную техническую функцию. Если на старте проекта все тестировщики проверяли вновь поступающие функциональные блоки, и все в команде были взаимозаменяемы, обладали равной степенью знаний всех блоков, то по мере наращивания объемов проекта количество тестировщиков также пришлось увеличивать и разделять на группы. Рост команды привел к процессу разделения по группам тестирования, выделению проектных ролей в рамках каждой группы.
По мере развития проекта стали проявляться особенности государственных информационных систем.
Глава 2. Особенности ГИС. Как с ними жить и работать тестировщикам
Прежде всего к крупным ГИС предъявляются повышенные требования к надежности и нагрузке, работа системы — в режиме 24/7, сбои в работе системы не должны приводить к потерям данных, время восстановления системы — не более 1 часа, время отклика — не более 2 секунд и многое другое.
Поскольку это был веб-портал, тестировщикам пришлось погрузиться в процесс тестирования многопользовательских веб-порталов и выстраивать подход к проектированию тестов и процессу теста с учетом особенностей веб-интерфейса.
Веб-приложение одновременно может использоваться большим количеством пользователей. Потребовалось предусматривать нагрузочное тестирование открытой части ГИС, используемой всеми пользователями, предугадать модель нагрузки и провести нагрузочное тестирование.
Пользователь может иметь свои уровни доступа. Потребовалось тестировать матрицу ролей пользователей в подсистеме прикладного администрирования с применением техник тест-дизайна.
Пользователи могут обращаться к одним сущностям, что приводит к конкурентному доступу. Чтобы вводимые данные одного пользователя не затирали данные другого, пришлось провести тестовый анализ ситуаций, в которых возможно одновременное изменение данных в личных кабинетах пользователей, включить в тесты проверки правильной отработки контроля с диагностическими сообщениями.
Одной из особенностей системы было использование поискового движка SphinxSearch, с которым команда тестирования не умела работать. Чтобы разобраться в тонкостях тестирования Sphinx пришлось консультироваться с разработчиками и понять, как происходит индексирование данных.
Тестировщики осваивали особенности тестирования поиска по словоформам, фрагментам слова, синонимам, по поиску внутри приложенных документов, стали разбираться, почему только что созданные поисковые данные не попали в результат поиска, и является ли это ошибкой.
В проекте была подсистема прикладного администрирования, которая включала в себя не только регистрацию пользователей, но и усложнялась наличием матрицы ролей пользователей. Она настраивалась в личных кабинетах администраторов организаций. Количество комбинаций проверок матрицы ролей было огромным и количество типов организаций также было не маленьким, то есть число комбинаций проверок росло в геометрической прогрессии. Потребовалось менять привычный подход к проектированию тестов, применяемый ранее на небольших проектах.
Поскольку система предполагала наличие веб-интерфейса, понадобилось предусмотреть кроссбраузерное тестирование, которое изначально не было запланировано. Когда проект только начинался, Internet Explorer 7.0 был единственным браузером, поддерживающим отечественную криптографию, и основное число пользователей пользовались именно этим браузером. Поэтому на старте проекта, для тестирования логики и функционала работы личных кабинетов использовался только IE этой версии, а вот для открытой части портала, требовалась поддержка всех существующих на тот момент браузеров. Однако в тот момент про кроссбраузерное тестирование не подумали.
Когда у меня спросили: «Как система ведет себя во всех известных версиях браузеров?» — я была, мягко говоря, в панике, так как объем тестовой модели был огромен (около 4000 тест-кейсов), регрессионный тестовый набор составлял порядка 1500 тест-кейсов, а команда тестирования всей толпой проверяла исключительно на одном выбранном по дефолту браузере. Данный кейс пришлось очень быстро решать и применять смекалку, чтоб успеть в сроки первого релиза и покрыть тестами основные версии браузеров.
На просторах интернета тогда было мало статей, посвященных тестированию, разработке тестовых моделей. Для нашей команды непонятной на тот момент задачей было, как создавать, где хранить и как поддерживать в актуальном состоянии большую тестовую модель. Не ясно было, как уйти от исследовательского тестирования, которое могло стать бесконечным, а на бесконечный тест не было ресурсов: ни человеческих, ни временных.
После запуска ГИС в опытную эксплуатацию, а затем в промышленную, появилась новая задача — обработка инцидентов пользователей.
До того, как была создана полноценная служба сопровождения пользователей ГИС, первый удар пользовательских обращений встретила команда тестирования, как наиболее погруженная в детали работы системы, пытаясь совместить основные задачи по тестированию новых доработок, а также своевременно обрабатывать поступающие инциденты, на которые был наложен SLA.
С такой задачей группа тестирования ранее не сталкивалась. Поток инцидентов нужно было обрабатывать, систематизировать, локализовывать, править, проверять и включать изменения в новый релизный цикл.
Уровень понимания и зрелости процесса эксплуатации рос и совершенствовался по мере роста самой системы.
Я перечислила лишь часть особенностей, с которыми команда тестирования столкнулась при работе с ГИС.
Глава 3. Проблемы тестирования ГИС и способы их решения. Рекомендации тест-менеджерам команд.
В процессе работы команды тестирования над несколькими крупными ГИС мы придумали рекомендации для тест-менеджеров. В дальнейшем они трансформировались в методологию процесса тестирования таких систем в нашем департаменте и продолжают совершенствоваться при решении новых задач в проектах аналогичного масштаба.
Что делать, когда очень много функционала?
Не паниковать и разбить функционал на блоки/модули/функции, подключить аналитика к аудиту результата, убедиться в правильности видения функциональных блоков.
Рекомендуем составить:
- Матрицу покрытия функциональных требований тестами.
Она отражает, что осталось не протестированным, какой прогресс тестирования, каким из оставшихся непроверенных требований уделить большее внимание, снизив возможные риски пропуска дефектов в production. Эта матрица дает прозрачность процесса тестирования и понимание, куда двигаться. - Матрицу знаний команды тестирования функциональных блоков/модулей/функций.
Суть матрицы в том, что по вертикали выписываются все функциональные требования, а по горизонтали — ФИО тестировщиков, на пересечении столбца и строки сотрудник самостоятельно отмечает по пятибалльной шкале степень своей погруженности в требование/функцию/модуль/подсистему. При наличии большой и, что особенно важно, распределенной команды тестирования, такая матрица помогает тест-менеджеру понять, где узкие места в команде, где люди не взаимозаменяемы, какой функционал необходимо усилить тестировщиками в случае болезней/увольнений или на какие модули/подсистемы/функции ротировать специалистов, в случае, если у них «замылился глаз» или они устали от функционала, в их зоне ответственности.
Что делать с матрицами знаний и покрытия функциональных требований?
Функционала меньше не становится. Теперь его все так же много, но он в новом представлении (в виде матрицы). Необходимо определить, какие функции являются наиболее важными с точки зрения бизнеса и что нельзя предоставить пользователям в «сыром» виде. Так начинается приоритезация функционала. Идеально, если тестировщику в этом будет помогать аналитик. Как минимум, он оценит корректность расставленных тестированием приоритетов.
Наиболее важные функции/блоки/модули будут относиться к высокому приоритету для теста, менее важные — покрываться тестами вторым приоритетом, остальные — третьим или в случае, когда «сроки горят», можно отложить их тест на более спокойное время.
Таким образом, у нас появилась возможность проверять функциональность, действительно важную для заказчика. Мы навели порядок в огромном количестве функций, понимаем, что покрыто тестами, а что еще предстоит покрыть, знаем, что внутри необходимо усилить со стороны тестирования, на случай болезней/увольнений ответственных тестировщиков, понимаем, кому из тестировщиков команды передавать в тест доработки (в соответствие с матрицей знаний), какие новые интересные функции/модули/подсистемы я могу предложить условным Васе, Пете, Лизе, когда они устали тестировать одно и то же. То есть у меня появился наглядный инструмент мотивации тестировщиков, желающих узнавать что-то новое на проекте.
Что делать, когда требования не поддерживают историчности, запутаны, дублируются, как с этим работать тестировщикам?
Рекомендуем внедрить процесс тестирования требований на проекте. Чем раньше обнаружен дефект, тем меньше его стоимость.
Тестировщики, распределенные по матрице знаний, по факту готовности технических спецификаций на разработку, сразу приступают к их изучению и проверке. Для того, чтобы всем было понятно, какие ошибки в требованиях, был разработан набор правил для аналитиков «Рецепт качественных требований», по которым они старались писать требования, также созданы шаблоны технических спецификаций, чтобы они описывались в едином стиле. Правила к формату технических спецификаций и рекомендации к описанию требований, были выданы и тестировщикам для понимания, какие ошибки искать в требованиях.
Конечно, основная задача тестировщика была найти логические нестыковки или неучтенные моменты влияния на смежные функции/подсистемы/модули, которые мог пропустить аналитик. После обнаружения дефектов они фиксировались в багтрекере, назначались на автора требования, аналитик останавливал разработку и/или в чате с тестировщиком и разработчиком сообщал, что в условие будет внесено изменение в соответствии с дефектом (чтобы не тормозить разработку), вносил правки и публиковал исправленную версию требований. Тестировщик проверял и закрывал работу над дефектом к требованиям. Эта процедура давала команде уверенность, что через пару недель разработки, обнаруженная проблема точно не всплывет в тесте.
Помимо раннего обнаружения дефектов мы получили мощный инструмент сбора метрик по качеству работы аналитиков. Имея статистику по количеству ошибок в требованиях, ведущий аналитик проекта мог предпринимать меры, чтобы улучшить качество работы в своей группе.
Что делать, когда необходимо провести нагрузочное тестирование?
Необходимо изучить требования к нагрузке, придумать её модель, разработать тест-кейсы, согласовать тестовую модель нагрузки с аналитиком и разработать нагрузочные скрипты с привлечением компетентных специалистов по нагрузочному тестированию.
Конечно, с тестовой моделью нагрузки можно не угадать, но для более точного попадания помимо аналитика можно привлечь архитектора или DevOps-специалиста, которые проанализировав информацию, статистику, метрики, смогут подсказать, какие еще кейсы необходимы в предложенной модели нагрузки.
Также стоит внедрить процесс запуска нагрузочных тестов, снятия результатов нагрузки и передачи его разработчикам для устранения узких мест.
Процесс нагрузки проводить регулярно перед выпуском каждого релиза, периодически менять модель нагрузки, чтобы выявить новые узкие места.
Что делать, когда необходимо провести интеграционное тестирование, опыта в котором нет?
Есть базовые пути: например, можно пойти на курсы повышения квалификации по теме тестирования Rest API, почитать статьи в интернете, получить обмен опыта с коллегами через Skype, с демонстрацией процесса, нанять в группу тестирования специалиста, хорошо разбирающегося в тестировании Rest API.
Способов погрузиться в этот вид тестирования много. В моей команде был нанят опытный специалист, который в будущем обучил меня и всю команду тестирования, разработал методички: на что обращать внимание при тестировании Rest API, как составлять тест-дизайн для проверки интеграции, проводил вебинары с демонстрацией процесса тестирования на всю команду.
Мы придумали тестовые задания, на которых каждый имел возможность потренироваться и погрузиться в этот процесс. Сейчас уже наработанный с годами материал только совершенствуется, и процесс обучения и погружения в тестирование Rest API занимает 1-2 недели, тогда как ранее на погружение уходил месяц и более, в зависимости от сложности проекта и объемов тестовой модели.

Как не запутаться в ветках кода, стендах, деплоях и тестировать нужный код?
Пока ГИС на начальном этапе разработки, есть всего две ветки кода: мастер и релизная. Вторую отделяют на этапе стабилизации для проведения завершающих регрессионных тестов и исправления точечных дефектов регресса.
Когда релизную ветку отправили в production и началась следующая итерация разработки, в какой-то момент решили сделать параллельной разработку новых задач, чтобы более крупную задачу, запланированную через релиз, успеть сделать в сроки. В какой-то момент таких веток стало 3-4 и даже больше. Появилось более трёх тестовых стендов, развернутых с целью, как можно скорее приступать к тестированию доработок будущих релизов.
Тестировщики уверены, что специалист со стороны инфраструктуры установил, например, доработку №10001 на один из тестовых стендов, выполнил все корректно, и они могут приступить к тесту. Специалист инфраструктуры выполнил deploy из ветки кода, отчитался, что стенд развернут, код установлен, можно тестировать.
Мы начинаем тест и понимаем, что:
- встречаются ошибки, которые ранее уже были исправлены;
- функционал, из существующего блока существенно отличается от аналогичного функционала, который стоит на другом тестовом стенде и готовится к ближайшему плановому релизу, при этом доработок по нему не должно быть в рамках переданной ветки кода;
- начинаем регистрировать дефекты, разработчики их возвращают, начинается холивар в проектных чатах и выяснение, что собственно нам установили и почему не то, что мы ожидали.
Провели анализ и выяснили, что разработчики не передали специалисту инфраструктуры инструкцию, из какой ветки собирать deploy, сотрудник собрал из ветки develop, при этом разработчик успел слить в ветку develop только часть кода из feature-ветки.
Тестировщик, совершенно не понимающий в ведении веток разработчиками, получив задачу и ссылку на стенд, побежал тестировать, потратил время, завел много дефектов, большая часть оказались неактуальны из-за всей этой путаницы.
Что мы сделали, чтобы избежать в будущем подобных ситуаций:
- разработчик готовит инструкцию специалисту инфраструктуры с указанием откуда собирать deploy, инструкция передается через задачу в jira;
- специалист инфраструктуры не путается и делает то, что ему передали;
- специалист по внутренней инфраструктуре департамента реализовал интеграцию багтрекера и GIT, при каждом коммите, в задаче jira отображалось в какие ветки кода был выполнен коммит;
- в jira выглядело это примерно так:
- тестирование изучило принципы работы модели Gitflow на уровне, достаточном для понимания, почему нужно обращать внимание куда закоммитили код разработчики и не забыли ли они исправления ветки hotfixes включить в develop, к примеру.


Что делать, когда времени до релиза мало, но необходимо провести кроссбраузерное тестирование на основных браузерах и нескольких версиях браузеров?
Рекомендуем составлять стратегию тестирования заранее, но раз уж этот момент упустили, вероятно, вам пригодится мой опыт.
Во-первых, надо понять, какие браузеры указаны в требованиях. Если с этим определились, а времени совсем нет, смотрим статистику наиболее часто используемых браузеров, например, тут. Потом пытаемся охватить три или пять максимально популярных браузеров.
Поскольку проект большой и команда тестирования большая была физическая возможность выделить по одному популярному по статистике браузеру каждому тестировщику. Он проводит свои регрессионные кейсы на выделенной версии браузера, особое внимание необходимо обращать на верстку, кликабельность кнопок и ссылок. Выглядит этот процесс так: например, есть 100 сценариев на регрессионный тест, в команде есть 5 тестировщиков, каждый может взять в работу по 20 сценариев, за каждым закреплено по браузеру. За один прогон регресса каждый тестировщик проверял свои кейсы в одном из браузеров. Покрытие в итоге не полное, но поскольку многие сценарии все равно повторяются в той или иной степени, то процент покрытия увеличивался за счет прохождения части регрессионный сценариев разными браузерами.
Конечно, это не дало 100% покрытия тестами всего функционала, но позволило существенно снизить риски попадания на production кроссбраузерных дефектов по основным бизнес-сценариям в системе.
Далее мы не только на регрессе, но и на тесте доработок и валидации дефектов выполняли проверки на разных браузерах, расширяя покрытие кроссбраузерности.
В будущем подход с распределением тестировщиков по браузерам стали применять и на тесте доработок, не дожидаясь этапа регрессионного тестирования, тем самым еще больше увеличив процент покрытия тестами разных версий браузеров.
Что мы получили:
- оптимизировали затраты тестирования, как финансовые, так и временные, за один интервал времени проверили и регрессионный тест и кроссбраузерный;
- все дефекты кроссбраузерности помечали метками в багртекере, для возможности их оперативно отфильтровать и совместно с аналитиком отметить их Severity;
- на будущее применяли такой подход при проведении теста новых доработок, тем самым не дожидаясь регрессионного теста, покрывали разные браузеры проверками.
Что делать с огромной тестовой моделью и как поддерживать ее в актуальном состоянии?
Довольно быстро у нас встал вопрос о ведении тестов в едином хранилище, поддержке их в актуальном состоянии и о возможности выполнять тестовые прогоны с отметками о результате выполнения.
В команде были сотрудники, имеющие опыт работы с системой ведения тестов TestLink. Это единственная система управления тест-кейсами с открытым исходными кодами, благодаря чему она и была выбрана для работы. У этой системы очень простой графический интерфейс и дизайн без лишних изысков. Мы оперативно наполнили программу тестами, встал вопрос, как это поддерживать. Первое время тратилось очень много ресурсов на актуализацию кейсов под каждую доработку, этот вариант оказался нерабочим.
Посоветовавшись с аналитиком и командой тестирования, решили, что нет необходимости держать всегда в актуальном состоянии такую большую тестовую модель из-за затрат на ее поддержку.
Все кейсы были поделены в соответствии с матрицей функциональных требований на папки, каждый функциональный модуль/подсистема хранил набор кейсов в отдельной папке. Это позволило визуально структурировать тест-кейсы. Были созданы ключевые слова в TestLink, с помощью которых определялась принадлежность кейса к той или иной группе, например:
- smoke – используется для тест-кейсов, входящих в smoke test (выполнение минимального набора тестов для выявления явных дефектов критичной функциональности);
- авто-тест – используется для тест-кейсов по которым разрабатываются автотесты;
- «Приоритет 1» — используется для тест-кейсов, относящихся к бизнес функциям, помеченным «Приоритет 1».
В итоге для новых доработок всегда проектируется тест-дизайн, в результате которого появляется документ чек-лист. В нем происходит ранжирование проверок по приоритетам, и только часть проверок попадает под «Приоритет 1» или smoke и на них уже создаются регрессионные тест-кейсы в системе TestLink.
Как всегда иметь актуальную регрессионную модель кейсов для планового релиза и внезапного HotFix на production?
Перед стартом регрессионного теста все подготовительные работы, включая актуализацию или добавление новых кейсов в регресс, выполнены. А это значит, что если запустить прогон тест-кейсов, актуальных для нового релиза, то они могут повлечь за собой дефекты при проверке HotFix по таким тест-кейсам.
Исправления HotFix сделаны на старой ветке кода (прошлый релиз) и в код внесены изменения по фиксам дефектов, тогда как в текущие тест-кейсы могли быть внесены изменения из доработок будущего релиза. То есть прогон тест-кейсов, актуальных для будущего релиза, может привести к регистрации ложных дефектов и сорвать сроки выпуска HotFix.
Чтобы избежать регистрации ложных дефектов и срыва сроков тестирования HotFix, решили использовать механизм, чем-то схожий с ведением веток кода. Только слияние и актуализация кейсов между ветками (читай «папками») TestLink осуществлялся вручную тестировщиками по определенному алгоритму, тогда как в модели Gitflow это делается автоматически средствами Git.
Вот так выглядит набор тест-кейсов в TestLink:

Был придуман процесс актуализации кейсов в TestLink
- Тест-менеджер копирует папку с кейсами «Тестовый проект 1.0.0» и создает новый тестовый набор, который именует номером следующего планового релиза. Получается папка с кейсами «Тестовый проект 2.0.0».
- После изучения доработок по будущему релизу анализируются тест-кейсы из папки «Тестовый проект 2.0.0» на предмет необходимости их актуализации под новые доработки.
В случае необходимости актуализации кейсов:
- ответственный тестировщик по доработке вносит изменения в тест-кейс в наборе «Тестовый проект 2.0.0»;
- если необходимо удалить тест-кейс, то сперва его нужно переместить в папку «Удалить», сделано это с целью возможности восстановить какой-то случайно удаленный тест-кейс или в случае, если требования вернули назад и тест-кейс снова востребован (удаляются тест-кейсы только из папки, соответствующей тестовому набору будущего планового релиза, в которой данный тест-кейс будет не актуален);
- если добавляем тест-кейс, то это необходимо сделать только в папке, соответствующей тестовому набору будущего планового релиза;
- тест-кейсы, которые меняются, помечаем ключевым словом «Изменен» (необходимо для оценки метрики степени влияния доработок на регрессионный функционал);
- кейсы, которые добавляются, помечаем ключевым словом «Добавлен» (необходимо для оценки метрики по влиянию доработок на регрессионный функционал).
Таким образом, мы всегда имеем актуальный тестовый набор кейсов, соответствующий прошлой релизной версии системы и его используем при тесте HotFix, а также ведем работу по актуализации нового тестового набора, готовимся к регрессионному тестированию и процессу стабилизации нового планового релиза. В какой-то момент одновременно может получиться сразу 3-4 тестовых ветки (читай «папки») TestLink, соответствующих разным версиям системы, что особенно актуально при тестировании доработок в фича-ветках.
После каждого релиза можем оценить на сколько у нас изменилась регрессионная модель, основываясь на метках «добавлен»/«изменен».
В случае, если регрессионная модель очень сильно увеличивается, при этом объем доработок в релизе существенно не изменился по сравнению с предыдущим релизом, то это повод задуматься о корректности выставления приоритетов в чек-листе проверок по доработке. Возможно, тестировщик сделал некорректный выбор кейсов для регресса и необходимо предпринять меры: например, объяснить тестировщику принцип выставления приоритетов, привлечь аналитика к согласованию приоритетов, изменить полученную регрессионную модель, убрав избыточные тест-кейсы.
Как можно оптимизировать регрессионную тестовую модель?
Мы начали работать с регрессионной тестовой моделью, оптимизировали процесс разработки тест-кейсов регресса путем выделения приоритетов и включения в регресс только кейсов «Приоритета 1». Столкнулись с тем, что тестовая модель, спустя время, стала большой, затраты на прогон её кейсов выросли, и мы перестали укладываться во временной интервал, приемлемый для проведения регрессионного теста на проекте.
Пришло время внедрять автоматизацию тестирования, целью которой было:
- сократить время на выполнение регрессионных тест-кейсов;
- использовать авто-тесты для создания предусловий для выполнения последующих проверок, тем самым оптимизировав временные и человеческие затраты на создание тестовых данных;
- повысить качество регрессионного тестирования за счет устранения влияния человеческого фактора на результаты ручного теста;
- сократить время обнаружения проблем, вызванных изменениями кода.
Был разработан framework для автоматизации тестов GUI на Java (в качестве системы контроля версий исходного кода использовался GIT).
На разработку автотестов была привлечена отдельная команда автоматизированного тестирования, которая успешно справилась с поставленной задачей. Для новых проектов аналогичного масштаба в будущем планируется применять существующие наработки и запускать автоматизированное тестирование на старте проекта, чтобы как можно раньше получать пользу от его применения. Подробнее про автоматизацию тестирования крупной ГИС можно прочитать в статье моих коллег, принимавших непосредственное участие в организации и проведении автоматизированного тестирования.
Со стороны функционального ручного тестирования также была проведена оптимизация регрессионной модели.
На примере двух крупных ГИС мы с командой придумали и внедрили сессии тестирования или тест-туры, суть которых была в следующем: необходимо было проанализировать бизнес-процесс в каждой подсистеме и продумать сессию (тур) проверок, проходящих через этот бизнес-процесс, имитируя наиболее часто выполняемые действия пользователя по процессу.
На одном ГИС-проекте это называли «сессии тестирования», на другом назвали «тест-туром». Но суть оставалась единой — мы продумывали сквозной (через всю доработку) ключевой бизнес-сценарий, который полностью покрывает бизнес-идею реализуемой доработки (может быть несколько таких сценариев).
Сценарий тест-тура согласовывался с аналитиком, разрабатывались детальные регрессионные тест-кейсы и в случаях, когда не успевали провести регрессионный тест по всей тестовой модели, могли ограничиться проведением «регресс-сессии» или «регрессионного тест-тура», который, как правило, занимал меньше времени и позволял однозначно понять, есть ли проблемы по ключевым бизнес-процессам в системе.
В будущем, тест-туры покрывались авто-тестами, а освободившиеся от рутинных проверок тестировщики переключались на тестирование доработок следующих плановых релизов.
Пример тестового-тура: «создание, редактирование, публикация и аннулирование сущности».
Тест-тур можно усложнить, например:
- выдать права на создание, редактирование и аннулирование,
- создать сущность в «Личном кабинете» пользователя с ролью «Специалист»,
- внести изменение в сущность,
- опубликовать сущность,
- проверить поиск опубликованной сущности в открытой части портала,
- аннулировать сущность в «Личном кабинете» пользователя с ролью «Специалист»,
- проверить, что аннулированная сущность не отобразится в открытой части портала.
Что делать с необходимостью обрабатывать инциденты от пользователей и соблюдать SLA?
Рекомендую не относиться к процессу локализации инцидентов от пользователей, как к низкоуровневой задаче. Стоит воспринимать это как часть процесса тестирования. Кроме того, это гораздо более творческий процесс, чем, к примеру, проверять по тест-кейсам. Необходимо применить логику, опыт техник тест-дизайна, чтоб докопаться до сути ошибки, отловить ее и передать в разработку.
Конечно, желательно организовывать процесс эксплуатации ГИС с тремя уровнями поддержки (идеально) и как итог на команду тестирования будут проваливаться уже отфильтрованные на первых двух линиях, самые неочевидные инциденты, локализовать которые способны часто только тестировщики.
Для соблюдения SLA рекомендуем внести процесс локализации инцидентов в обязанность в команде тестирования с наивысшим приоритетом и стараться внедрить методы оптимизации работ, чтобы скорость воспроизведения инцидента была максимально высокой.
Для оптимизации временных затрат тестировщиков можно:
- вести проектную базу знаний с типовыми или часто встречающимися SQL-запросами;
- организовать процесс ранжирования поступающих задач в багтрекере так, чтобы на панели индикаторов тестировщик сразу видел упавший инцидент и брал его в работу в первом приоритете;
- добавить счетчики времени с обратным отсчетом в JIRA на задачи, по которым есть SLA;
- настроить систему оповещений о поступивших инцидентах;
- поднимать тестовый стенд с деперсонализированной полной копией базы с production стенда (в идеальной картине мира — с точки зрения полноты базы), чтобы иметь возможность воспроизводить инциденты на данных, максимально приближенных к реальным, но, если такой возможности нет, то обходиться тестовыми средами с версией ПО, соответствующей production;
- инциденты должны распределяться на тестировщиков в соответствии с «матрицей ответственности» и «матрицей знаний проекта». Это будет способствовать максимальной эффективности в обработке инцидента.
Про «матрицу знаний» было написано выше. Что касается «матрицы ответственности» — это таблица, в которой по аналогии с «матрицей знаний» выписаны функциональные блоки/модули/подсистемы и указано, кто из группы тестирования отвечает за тестирование функционала, как правило, — это тимлид группы или старший/ведущий тестировщик в группе.
Что делать, если тестировщик одного функционального блока/модуля/подсистемы не понимает всей картины бизнес-процесса на проекте?
Это больная тема, с которой мы сталкивались на нескольких крупных ГИС-проектах. Команда сделала «матрицу знаний», тестировщики провели самооценку степени погруженности в функционал и закрепились за своим кусочком функционала. Но в какой-то момент опытные тестировщики, участвовавшие со старта проекта, выбыли из группы, а новые специалисты еще не были погружены во все бизнес-процессы и не видели полной картины. Это привело к тому, что при тестировании кейсов в одном модуле результаты этого кейса должны были использоваться в следующем модуле и в итоге, если на вход второго модуля подавались некорректные результаты (предусловия были не идеальные для выполнения кейсов из предыдущего модуля), то требовалось анализировать ситуацию и регистрировать ошибки.
Но тестировщики не задумывались, почему им на вход пришли такие цифры и просто отрабатывали свои кейсы. Формально тест проведен, все хорошо, дефектов не обнаружено, а при приемке функционала аналитиком или при подготовке к приемо-сдаточным испытаниям, выясняются существенные проблемы в работе бизнес-логики, которые пропустили на тесте. Причина оказалась в непонимании сквозного бизнес-процесса, выполняемого системой.
В сложившейся ситуации было предпринято следующее:
- проводилось погружение в функционал с привлечением аналитика;
- проводилось обучение в группе тестирования, обмен опытом, рассказы на митингах о своей подсистеме и что в ней происходит, обсуждение новых доработок, которые запланированы по подсистеме в ближайший плановый релиз;
- привлечение аналитиков и внедрение в шаблоны спецификаций информирования о степени влияния доработки на сторонние модули/подсистемы;
- внедрение процесса тестирования тестовых сессий (туров), которые составляют тестировщики и согласовывают их с аналитиками (помогает снизить риски непонимания бизнес процесса командой и количество бизнес-ошибок в системе).
Фух! Постаралась собрать основные проблемы и рекомендации по их устранению, однако это далеко не вся полезная информация, которой хочется поделиться.
Глава 4. Метрики для определения качества проекта и методика оценки трудозатрат на тестирование
Прежде чем внедрить на проекте сбор метрик, мы задались вопросом: «Зачем нам это делать?» Главными целями стали отслеживание качества работы команды тестирования, качества выпускаемого в production релиза, отслеживание показателей эффективности работы участников группы тестирования, чтобы понимать, как развивать команду.
Был проведен анализ, какие метрики необходимы для достижения поставленных целей. Далее распределили их по группам. Затем обдумали, что можно измерять без дополнительных изменений в процессе, а где потребуется помощь со стороны других участников проектной команды.
Когда все подготовительные этапы были пройдены, началась регулярная сборка метрик: раз в месяц/релиз/спринт/квартал — в зависимости от проекта и особенностей производственного процесса.
Собрав первые метрики, потребовалось определить целевые показатели, к которым мы хотим стремиться на данном этапе развития проекта. Далее оставалось регулярно снимать метрики и анализировать причины отклонения их от целевых показателей, принимать меры, направленные на улучшение показателей, то есть оптимизировать не только процесс тестирования, но и весь производственный процесс на проекте.
Конечно, в улучшении качества задействованы не только тестировщики, к оптимизации процесса привлекались и аналитики и разработка и релиз-менеджер, DevOps-инженеры — все ключевые участники процесса, так как все желали повышать качество релиза и совершенствоваться в работе.
Пример, как выглядит сбор метрик и целевые показатели на одном из завершенных проектов:
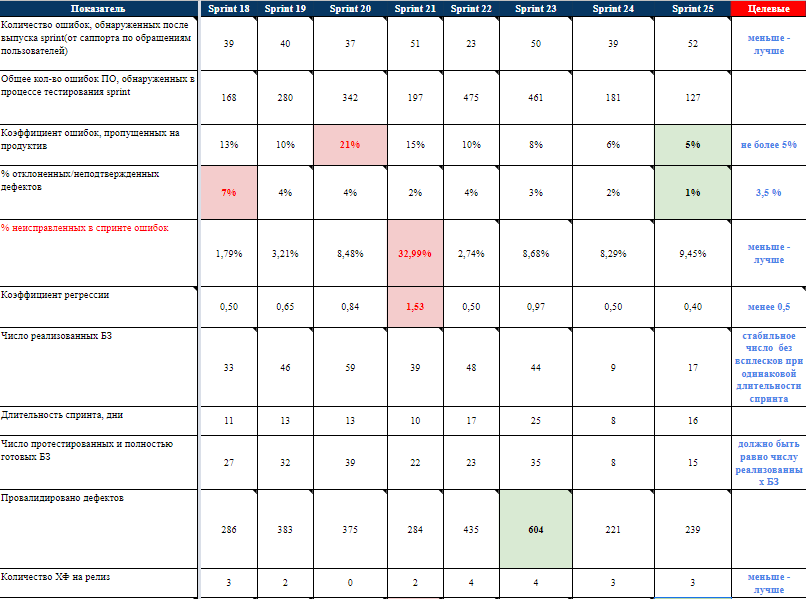
Методика оценки трудозатрат на тестирование
Для того, чтобы сообщать руководителю проекта более точные сроки по завершению работ тестирования, основываясь на сборе метрик с однотипных проектов, была разработана методика для оценки трудозатрат тестирования, позволяющая максимально точно сообщать сроки завершения тестирования и оповещать о рисках тестирования.
Эта методика применяется на всех проектах по реализации ГИС, отличия могут быть только в некоторых значениях метрик, но принцип расчета одинаковый.
Метрики, используемые для выполнения детальной оценки затрат на тестирование
Временные метрики получены путем многократных замеров фактических затрат тестировщиков разного уровня компетенции на разных проектах, взято среднее арифметическое.
Время на регистрацию ошибки — 10 минут (время на регистрацию 1 ошибки в багртекере).
Время на валидацию ошибки/уточнения — 15 минут (время на проверку корректности исправления 1 ошибки/уточнения).
Время на написание 1 ТК (тест-кейса) — 20 минут (время на разработку тест-кейса в системе TestLink).
Время на выполнение 1 ТК — 15 минут (время на выполнение проверок по тест-кейсу в системе TestLink).
Время на тест. Суммарное время, полученное путем сложения затрат в Чек-листе по столбцу «Время выполнения, мин».
Время на отчет по тестированию — 20 минут (время на написание отчета по шаблону).
Время на ошибки. Плановое время на регистрацию всех ошибок/уточнений, (время на регистрацию 1 ошибки/уточнения * возможное количество ошибок/уточнений (10 ошибок на доработку — предполагаемое количество ошибок на одну доработку)).
Общее время на DV (defect validation). Плановое время на валидацию всех найденных и исправленных ошибок/уточнений (время на валидацию 1 ошибки/уточнения * предполагаемое количество ошибок/уточнений).
Подготовка тестовых данных. Время на подготовку тестовых данных рассчитывается субъективно на основании опыта тестирования аналогичных задач на текущем проекте в зависимости от разных параметров (объем задачи с точки зрения Тест аналитика, компетенции команды разработки кода (новая неизвестная команда или проверенная команды, по которой есть статистика по качеству работы), интеграции между разными модулями и т.д.).
Путем замеров фактических затрат на одном из проектов было вычислено следующее:
- не более 1 часа на задачу до 60 часов разработки,
- не более 3 ч на задачу до 150 ч разработки,
- не более 4 ч на задачу до 300 ч разработки.
В особенных случаях, плановые затраты на подготовку тестовых данных могли меняться по согласованию с тест-менеджером.
Время на написание ТК. Время на написание ТК, которое оценивается после готовности чек-листа проверок и установки проверкам приоритетов для тестирования. На регрессионный тест составлялись ТК, помеченные Приоритетом 0 (количество проверок Приоритета 0 * 20 минут (время на написание 1 ТК)).
Время на регресс по ТК. Время на выполнение одной итерации регрессионного тестирования по ТК в системе TestLink (количество ТК * среднее время выполнения 1 ТК (15 минут)).
Риски. Закладывается 15% от времени на тест (под рисками понимаются все ручные операции, падения стендов, блокирующие проблемы и т. д.).
Общее время на тестирование. Общие затраты на выполнение тестирования по одному ЧЛ (подготовка тестовых данных + выполнение теста + время на регистрацию ошибок/уточнений + валидация ошибок/уточнений + время на регресс по ТК Приоритета 0 + риски) в ч/ч.
Общее время на задачу. Суммарные затраты на всю задачу тестирования, цифра в ч/ч (Общее время на тестирование + время на отчет + время на написание ТК).
Все эти метрики используются на проекте для решения разных задач, связанных с планированием, оценками работ, как временных так и финансовых. Как показала практика, подобная оценка дает минимальную погрешность (не более 10%), что является достаточно высоким показателем достоверности оценки.
Конечно, вы можете не применять какие-то метрики или именно ваши метрики по статистике могут сильно отличаться, но принцип оценки затрат на работы по тестированию можно применить к любому проекту и подобрать наиболее оптимальную формулу расчета, применительно к вашему проекту и команде.
Глава 5. Рецепт успешного процесса тестирования ГИС
Важно показать тест-менеджерам и тестировщикам, что столкнувшись с трудностями и новыми задачами, можно находить пути решения, оптимизировать процесс тестирования и стараться применить накопившийся опыт для будущих проектов.
Всем читателям я приготовила сюрпризы — рецепт успешного процесса тестирования ГИС и шаблоны документов, которые вы сможете скачать и использовать на ваших проектах.
Итак, рецепт, как сделать процесс тестирования крупной информационной системы успешным, и что мы рекомендуем обязательно включить в этот процесс, постараюсь изложить кратко и ёмко.
Со стороны процесса аналитики:
- внедрить шаблоны технических требований;
- внедрить правила разработки технических требований в группе аналитиков;
- разработать регламент оповещения о готовности технических требований проектной команды.
Со стороны процесса тестирования:
- как можно раньше подключать тест-менеджера к погружению в проект и изучению документации;
- заранее начать собирать команду тестирования в проект;
- внедрить процесс тестирования требований;
- разработать шаблоны тестовых документов и правила их заполнения:
○ шаблоны чек-листа проверок или матрицы покрытия тестами;
○ шаблон тест-кейсов;
○ шаблоны отчетов; - участвовать в разработке жизненного цикла задач в багтрекере, продумать на будущее, какие метрики потребуется снимать и учитывать все нюансы работы с багтрекером на старте, так как в процессе работы над проектом, изменения в багтрекере бывают болезненными и могут привести к потере данных или же сбоям при миграции данных, а также отвлекать от работы всю проектную команду;
- составлять стратегию тестирования заранее, чтобы не забыть важные проверки, учитывать требования технического задания и обязательно задуматься о неявных требованиях, которые могут быть не прописаны в техническом задании, но их также необходимо запланировать;
- определиться с метриками измерения качества;
- определить критерии старта и завершения тестов;
- подумать об инструментах тестирования и тестовых средах;
- составить план тестирования в любом удобном или принятом в компании формате;
- подготовить минимально необходимую базу знаний для погружения в проект новых людей (инструкции, методички, дорожная карта погружения в проект и т.д.);
- проводить анализ снимаемых метрик для оценки качества работы команды тестирования, качества выпускаемого продукта, проводить ретроспективу на регулярной основе и совершенствовать процесс;
- пользоваться рекомендациями более опытных коллег, наработками с других проектов, готовыми чит-листами, проводить мозговые штурмы с командой и искать новые методы оптимизации и совершенствования процесса.
Сейчас я как раз готовлюсь к тестированию новой ГИС. Вот так выглядит моя рабочая Wiki, в которой уже учтены многие моменты, которые мы рекомендовали сделать:

Сюрприз для терпеливых читателей.
Если вы дочитали статью до конца, вы заслужили подарок. Хочу поделиться с вами полезными шаблонами, которые можно использовать в работе:
- шаблон Чек-листа проверок, включающий минимальный набор рекомендаций по тестированию элементов интерфейса экранных форм (конечно, есть более широкие варианты проверок, это всего-лишь пример), включает формулы подсчета затрат на тестирование с пояснениями методики расчета;
- шаблон отчета по тестированию;
- шаблон матриц: знаний/ распределения по браузерам/платформам/график отпусков проектной команды;
- cписок ключевых метрик по проекту с пояснениями.
Надеюсь, наши рекомендации, примеры, идеи, ссылки и мои шаблоны помогут многим командам грамотно выстроить процесс тестирования, оптимизировать свои затраты и успешно справиться с поставленными задачами на ответственном и сложном проекте.
Желающим присоединиться к команде тестирования ЛАНИТ и поучаствовать в тестировании ГИС, советую посмотреть вакансии нашей компании.
Приходите в наши Школы тестирования!
У нас открыты Школы тестирования в Москве, Ижевске, Уфе и в Челябинске.
Желаю всем интересных проектов и удачи!
P.S. Очень уж напрашивается провести небольшой опрос.
Only registered users can participate in poll. Log in, please.
Как у вас проходит тестирование крупных информационных систем?
0% У нас нет UI, и все автоматизировано.0
37.5% У нас есть UI, все автоматизировано, руками не тестируем — прошлый век.3
62.5% У нас есть UI, что-то автоматизировано (подробности напишу в комментарии).5
8 users voted. 17 users abstained.
