Перевод статьи подготовлен специально для студентов курса «Data Engineer».

За последние несколько недель мы с Nong Li добавили в Apache Arrow бинарный потоковый формат, дополнив уже существующий формат файлов random access/IPC. У нас есть реализации на Java и C++ и привязки Python. В этой статье я расскажу, как работает формат и покажу, как можно достичь очень высокой пропускной способности данных для DataFrame pandas.
Распространенный вопрос, который я получаю от пользователей Arrow, — это вопрос о высокой стоимости переноса больших наборов табличных данных из формата, ориентированного на строки или записи в колоночный формат. Для многогигабайтных датасетов транспонирование в памяти или на диске может оказаться непосильной задачей.
Для потоковой передачи данных, независимо от того, являются ли исходные данные строковыми или колоночными, одним из вариантов остается отправка небольших пакетов строк, каждый из которых внутри содержит компоновку по столбцам.
В Apache Arrow коллекция колоночных массивов в памяти, представляющая чанк таблицы, называется пакетом записей (record batch). Чтобы представить единую структуру данных логической таблицы можно собрать несколько пакетов записей.
В существующем формате файлов «random access» мы записываем метаданные, содержащие схему таблицы и расположение блоков в конце файла, что позволяет вам крайне дешево выбирать любой пакет записей или любой столбец из набора данных. В потоковом формате мы отправляем серию сообщений: схему, а потом один или несколько пакетов записей.
Различные форматы выглядят примерно так, как представлено на этом рисунке:

Чтобы показать вам как это работает, я создам пример датасета, представляющего один потоковый чанк:
Теперь, предположим, что мы хотим записать 1 Гб данных, состоящих из чанков размером 1 Мб каждый, итого 1024 чанка. Для начала давайте создадим первый фрейм данных размером 1 Мб с 16 столбцами:
Затем я конвертирую их в
Теперь я создам поток вывода, который будет писать в оперативную память и создам
Затем мы запишем 1024 чанка, которые в итоге составят 1Гб набора данных:
Поскольку мы писали в ОЗУ, то весь поток мы сможем получить в одном буфере:
Поскольку эти данные находятся в памяти, считывание пакетов записей Arrow получается zero-copy операцией. Я открываю StreamReader, считываю данные в
Все это, конечно, хорошо, но у вас могут возникнуть вопросы. Как быстро это происходит? Как размер чанка влияет на производительность получения DataFrame pandas?
По мере уменьшения размера чанка потоковой передачи стоимость реконструкции непрерывного столбчатого кадра DataFrame в pandas возрастает из-за неэффективных схем доступа к кэш-памяти. Существуют также некоторые накладные расходы от работы со структурами данных C++ и массивами и их буферами памяти.
Для 1 Мб, как указано выше, на моем ноутбуке (Quad-core Xeon E3-1505M) получается:
Получается, что эффективная пропускная способность — 7.75 Гб/с для восстановления DataFrame объемом 1Гб из 1024 чанков по 1Мб. Что происходит, если мы будем использовать чанки большего или меньшего размера? Вот такие результаты получатся:
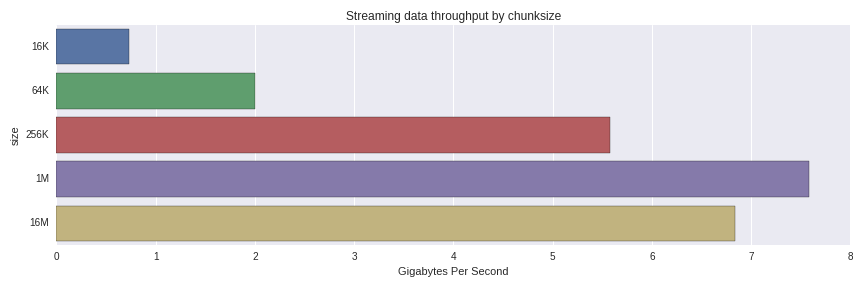
Производительность существенно снижается с 256K до 64K чанков. Меня удивило, что чанки размером 1 Мб обрабатывались быстрее, чем 16 Мб. Стоит провести более тщательное исследование и понять, является ли это нормальным распределением или тут влияет что-то еще.
В текущей реализации формата данные не сжимаются в принципе, поэтому размер в памяти и «в проводах» примерно одинаковый. В будущем сжатие может стать дополнительной опцией.
Потоковая передача колоночных данных может оказаться эффективным способом передачи больших наборов данных в колоночные аналитические инструменты, например в pandas, с помощью небольших чанков. Службы данных, использующие хранилище, ориентированное на строки, могут передавать и транспонировать небольшие чанки данных, которые более удобны для кэша L2 и L3 вашего процессора.
Полный код

За последние несколько недель мы с Nong Li добавили в Apache Arrow бинарный потоковый формат, дополнив уже существующий формат файлов random access/IPC. У нас есть реализации на Java и C++ и привязки Python. В этой статье я расскажу, как работает формат и покажу, как можно достичь очень высокой пропускной способности данных для DataFrame pandas.
Потоковая передача колоночных данных
Распространенный вопрос, который я получаю от пользователей Arrow, — это вопрос о высокой стоимости переноса больших наборов табличных данных из формата, ориентированного на строки или записи в колоночный формат. Для многогигабайтных датасетов транспонирование в памяти или на диске может оказаться непосильной задачей.
Для потоковой передачи данных, независимо от того, являются ли исходные данные строковыми или колоночными, одним из вариантов остается отправка небольших пакетов строк, каждый из которых внутри содержит компоновку по столбцам.
В Apache Arrow коллекция колоночных массивов в памяти, представляющая чанк таблицы, называется пакетом записей (record batch). Чтобы представить единую структуру данных логической таблицы можно собрать несколько пакетов записей.
В существующем формате файлов «random access» мы записываем метаданные, содержащие схему таблицы и расположение блоков в конце файла, что позволяет вам крайне дешево выбирать любой пакет записей или любой столбец из набора данных. В потоковом формате мы отправляем серию сообщений: схему, а потом один или несколько пакетов записей.
Различные форматы выглядят примерно так, как представлено на этом рисунке:

Потоковая передача данных в PyArrow: применение
Чтобы показать вам как это работает, я создам пример датасета, представляющего один потоковый чанк:
import time
import numpy as np
import pandas as pd
import pyarrow as pa
def generate_data(total_size, ncols):
nrows = int(total_size / ncols / np.dtype('float64').itemsize)
return pd.DataFrame({
'c' + str(i): np.random.randn(nrows)
for i in range(ncols)
}) Теперь, предположим, что мы хотим записать 1 Гб данных, состоящих из чанков размером 1 Мб каждый, итого 1024 чанка. Для начала давайте создадим первый фрейм данных размером 1 Мб с 16 столбцами:
KILOBYTE = 1 << 10
MEGABYTE = KILOBYTE * KILOBYTE
DATA_SIZE = 1024 * MEGABYTE
NCOLS = 16
df = generate_data(MEGABYTE, NCOLS)Затем я конвертирую их в
pyarrow.RecordBatch:batch = pa.RecordBatch.from_pandas(df)Теперь я создам поток вывода, который будет писать в оперативную память и создам
StreamWriter:sink = pa.InMemoryOutputStream()
stream_writer = pa.StreamWriter(sink, batch.schema)Затем мы запишем 1024 чанка, которые в итоге составят 1Гб набора данных:
for i in range(DATA_SIZE // MEGABYTE):
stream_writer.write_batch(batch)Поскольку мы писали в ОЗУ, то весь поток мы сможем получить в одном буфере:
In [13]: source = sink.get_result()
In [14]: source
Out[14]: <pyarrow.io.Buffer at 0x7f2df7118f80>
In [15]: source.size
Out[15]: 1074750744Поскольку эти данные находятся в памяти, считывание пакетов записей Arrow получается zero-copy операцией. Я открываю StreamReader, считываю данные в
pyarrow.Table, а затем конвертирую их в DataFrame pandas:In [16]: reader = pa.StreamReader(source)
In [17]: table = reader.read_all()
In [18]: table
Out[18]: <pyarrow.table.Table at 0x7fae8281f6f0>
In [19]: df = table.to_pandas()
In [20]: df.memory_usage().sum()
Out[20]: 1073741904Все это, конечно, хорошо, но у вас могут возникнуть вопросы. Как быстро это происходит? Как размер чанка влияет на производительность получения DataFrame pandas?
Производительность потоковой передачи данных
По мере уменьшения размера чанка потоковой передачи стоимость реконструкции непрерывного столбчатого кадра DataFrame в pandas возрастает из-за неэффективных схем доступа к кэш-памяти. Существуют также некоторые накладные расходы от работы со структурами данных C++ и массивами и их буферами памяти.
Для 1 Мб, как указано выше, на моем ноутбуке (Quad-core Xeon E3-1505M) получается:
In [20]: %timeit pa.StreamReader(source).read_all().to_pandas()
10 loops, best of 3: 129 ms per loopПолучается, что эффективная пропускная способность — 7.75 Гб/с для восстановления DataFrame объемом 1Гб из 1024 чанков по 1Мб. Что происходит, если мы будем использовать чанки большего или меньшего размера? Вот такие результаты получатся:

Производительность существенно снижается с 256K до 64K чанков. Меня удивило, что чанки размером 1 Мб обрабатывались быстрее, чем 16 Мб. Стоит провести более тщательное исследование и понять, является ли это нормальным распределением или тут влияет что-то еще.
В текущей реализации формата данные не сжимаются в принципе, поэтому размер в памяти и «в проводах» примерно одинаковый. В будущем сжатие может стать дополнительной опцией.
Итог
Потоковая передача колоночных данных может оказаться эффективным способом передачи больших наборов данных в колоночные аналитические инструменты, например в pandas, с помощью небольших чанков. Службы данных, использующие хранилище, ориентированное на строки, могут передавать и транспонировать небольшие чанки данных, которые более удобны для кэша L2 и L3 вашего процессора.
Полный код
import time
import numpy as np
import pandas as pd
import pyarrow as pa
def generate_data(total_size, ncols):
nrows = total_size / ncols / np.dtype('float64').itemsize
return pd.DataFrame({
'c' + str(i): np.random.randn(nrows)
for i in range(ncols)
})
KILOBYTE = 1 << 10
MEGABYTE = KILOBYTE * KILOBYTE
DATA_SIZE = 1024 * MEGABYTE
NCOLS = 16
def get_timing(f, niter):
start = time.clock_gettime(time.CLOCK_REALTIME)
for i in range(niter):
f()
return (time.clock_gettime(time.CLOCK_REALTIME) - start) / NITER
def read_as_dataframe(klass, source):
reader = klass(source)
table = reader.read_all()
return table.to_pandas()
NITER = 5
results = []
CHUNKSIZES = [16 * KILOBYTE, 64 * KILOBYTE, 256 * KILOBYTE, MEGABYTE, 16 * MEGABYTE]
for chunksize in CHUNKSIZES:
nchunks = DATA_SIZE // chunksize
batch = pa.RecordBatch.from_pandas(generate_data(chunksize, NCOLS))
sink = pa.InMemoryOutputStream()
stream_writer = pa.StreamWriter(sink, batch.schema)
for i in range(nchunks):
stream_writer.write_batch(batch)
source = sink.get_result()
elapsed = get_timing(lambda: read_as_dataframe(pa.StreamReader, source), NITER)
result = (chunksize, elapsed)
print(result)
results.append(result)