В преддверии запуска нового потока по курсу «Data Engineer» подготовили перевод интересного материала.

Мы поговорим о достаточно популярном паттерне, с помощью которого приложения используют несколько хранилищ данных, где каждое хранилище используется под свои цели, например, для хранения канонической формы данных (MySQL и т.д.), обеспечения расширенных возможностей поиска (ElasticSearch и т.д.), кэширования (Memcached и т.д.) и других. Обычно при использовании нескольких хранилищ данных одно из них работает как основное хранилище, а другие как производные хранилища. Единственная проблема заключается в том, как синхронизировать эти хранилища данных.
Мы рассмотрели ряд различных паттернов, которые пытались решить проблему синхронизации нескольких хранилищ, таких как двойная запись, распределенные транзакции и т.д. Однако эти подходы имеют существенные ограничения в плане использования в реальной жизни, надежности и технического обслуживания. Помимо синхронизации данных, некоторым приложениям также необходимо обогащать данные, вызывая внешние сервисы.
Для решения этих проблем и была разработана Delta. Delta в конечном итоге представляет из себя согласованную, управляемую событиями платформу для синхронизации и обогащения данных.
Чтобы синхронизировать два хранилища данных, можно использовать двойную запись, которая выполняет запись в одно хранилище, а потом сразу после этого делает запись в другое. Первую запись можно повторить, а вторую – прервать, если первая завершится неудачей после исчерпания количества попыток. Однако два хранилища данных могут перестать синхронизироваться, если запись во второе хранилище завершится неудачей. Решается эта проблема обычно созданием процедуры восстановления, которая может периодически повторно переносить данные из первого хранилища во второе или делать это только в том случае, если в данных обнаруживаются различия.
Проблемы:
Выполнение процедуры восстановления – это специфичная работа, которую нельзя переиспользовать. Кроме того, данные между хранилищами остаются рассинхронизированными до тех пор, пока не пройдет процедура восстановления. Решение усложняется, если используется более двух хранилищ данных. И, наконец, процедура восстановления может добавить нагрузку на исходный источник данных.
Когда в наборе таблиц происходят изменения (например, вставка, обновление и удаление записи), записи изменений добавляются в таблицу логов, как часть той же транзакции. Другой поток или процесс постоянно запрашивает события из таблицы логов и записывает их в одно или несколько хранилищ данных, при появлении необходимости удаляя события из таблицы логов после подтверждения записи всеми хранилищами.
Проблемы:
Этот паттерн должен быть реализован как библиотека и в идеале без изменения кода приложения ее использующего. В среде-полиглоте реализация такой библиотеки должна существовать на любом необходимом языке, но обеспечить согласованность работы функций и поведения между языками очень непросто.
Другая проблема кроется в получении изменений схемы, в тех системах, которые не поддерживают транзакционные изменения схемы [1][2], как, например, MySQL. Поэтому шаблон выполнения изменения (например, изменения схемы) и транзакционной записи его в таблицу логов изменений не всегда будет работать.
Распределенные транзакции можно использовать для того, чтобы разделить транзакцию между несколькими разнородными хранилищами данных так, чтобы операция либо фиксировалась во всех используемых хранилищах, либо не фиксировалась ни в одном из них.
Проблемы:
Распределенные транзакции – очень большая проблема для разнородных хранилищ данных. По своей природе они могут полагаться только на наименьший общий знаменатель участвующих систем. Например, XA-транзакции блокируют выполнение, если в процессе приложения происходит сбой на этапе подготовки. Кроме того, XA не обеспечивает обнаружения дедлоков и не поддерживает оптимистические схемы управления параллелизмом. Помимо этого, некоторые системы по типу ElasticSearch не поддерживают XA или любую другую гетерогенную модель транзакций. Таким образом, обеспечение атомарности записи в различных технологиях хранения данных остается для приложений весьма сложной задачей [3].
Delta была разработана для устранения ограничений существующих решений по синхронизации данных, она также позволяет обогащать данные на лету. Наша цель состояла в том, чтобы абстрагировать все эти сложные моменты от разработчиков приложений, чтобы они могли полностью сосредоточиться на реализации бизнес-функционала. Далее мы будем описывать «Movie Search», фактический вариант использования Delta от Netflix.
В Netflix широко применяется микросервисная архитектура и каждый микросервис обычно обслуживает по одному типу данных. Основные сведения о фильме вынесены в микросервис, который называется Movie Service, а также связанные с ними данные, такие как информация о продюсерах, актерах, вендорах и так далее управляются несколькими другими микросервисами (а именно Deal Service, Talent Service и Vendor Service).
Бизнес-пользователи в Netflix Studios часто нуждаются в поиске по различным критериям фильмов, именно поэтому для них очень важно иметь возможность осуществлять поиск по всем данным, связанным с фильмами.
До появления Delta команде поиска фильмов нужно было получать данные из нескольких микросервисов, прежде чем индексировать данные фильмов. Помимо этого, команда должна была разработать систему, которая периодически обновляла бы поисковый индекс, запрашивая изменения у других микросервисов, даже если изменений не было вообще. Эта система очень быстро обросла сложностями и ее стало трудно поддерживать.
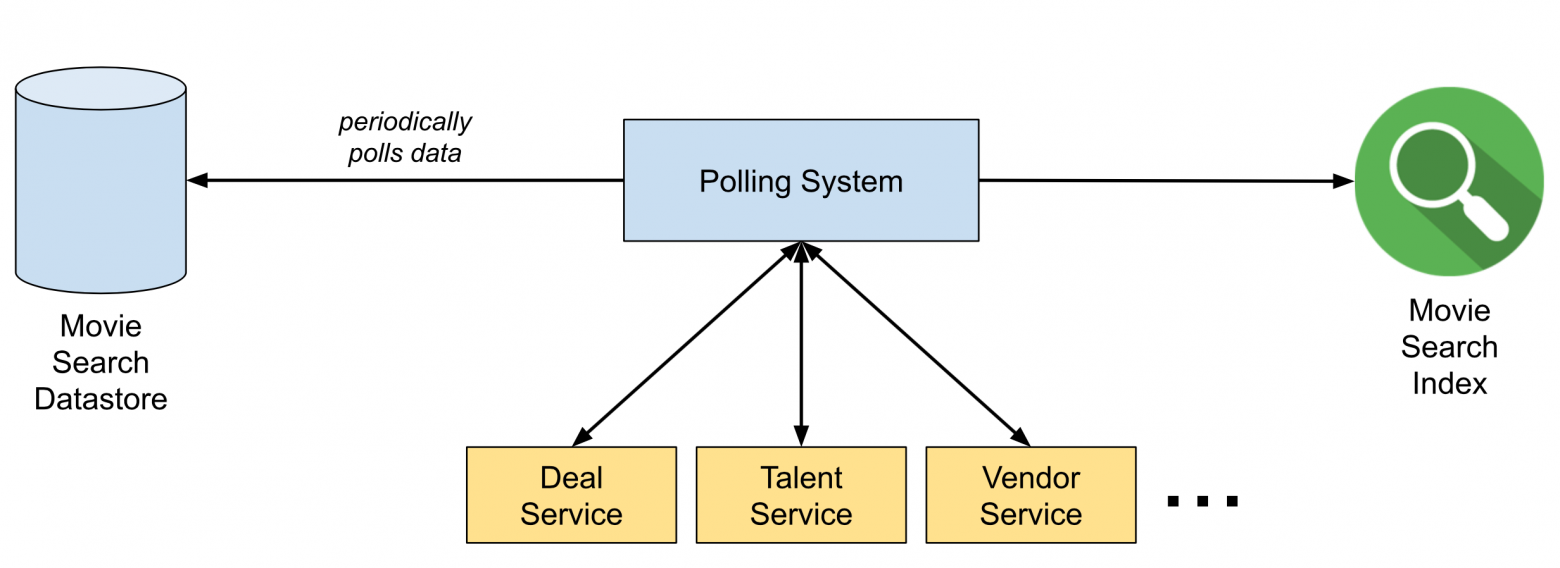
Рисунок 1. Система поллинга до Delta
После начала использования Delta, система была упрощена до системы, управляемой событиями, как показано на следующем рисунке. События CDC (Change-Data-Capture) отправляются в топики Keystone Kafka с помощью Delta-Connector. Приложение Delta, построенное с использованием Delta Stream Processing Framework (основанного на Flink), получает CDC-события из топика, обогащает их, вызывая другие микросервисы, и, наконец, передает обогащенные данные в поисковый индекс в Elasticsearch. Весь процесс проходит почти в реальном времени, то есть, как только изменения фиксируются в хранилище данных, поисковые индексы обновляются.

Рисунок 2. Пайплайн данных при использовании Delta
В следующих разделах мы опишем работу Delta-Connector, который подключается к хранилищу и публикует CDC-события на транспортном уровне, который представляет из себя инфраструктуру передачи данных в реальном времени, направляющую CDC-события в топики Kafka. А в самом конце мы поговорим о структуре обработки потоков Delta, которую разработчики приложений могут использовать для логики обработки и обогащения данных.
Мы разработали CDC-сервис под названием Delta-Connector, который может фиксировать закоммиченные изменения из хранилища данных в режиме реального времени и писать их в поток. Изменения в реальном времени берутся из журнала транзакций и дампов хранилища. Дампы используются поскольку журналы транзакций обычно не хранят всю историю изменений. Изменения обычно сериализуются как события Delta, так что получателю не нужно беспокоиться о том, откуда появляется изменение.
Delta-Connector поддерживает несколько дополнительных функций, таких как:
Сейчас мы поддерживаем MySQL и Postgres, в том числе при развертывании в AWS RDS и Aurora. Также мы поддерживаем Cassandra (multi-master). Больше подробностей о Delta-Connector вы можете узнать в этом блоге.
Транспортный уровень событий Delta построен на сервисе обмена сообщениями платформы Keystone.
Так исторически сложилось, что публикация сообщений в Netflix оптимизировалась с учетом повышения доступности, а не долговечности (см. предыдущую статью). Компромиссом оказалось потенциальное несоответствие данных брокера в различных пограничных сценариях. Например, unclean leader election отвечает за то, что получатель потенциально дублирует или теряет события.
С Delta нам хотелось получить более весомые гарантии долговечности, чтобы обеспечить доставку CDC-событий в производные хранилища. Для этого мы предложили специально спроектированный кластер Kafka в качестве объекта первого класса. Вы можете посмотреть на некоторые настройки брокера в таблице ниже:

В кластерах Keystone Kafka, unclean leader election обычно включен для обеспечения доступности издателя. Это может привести к потере сообщений в случае, если несинхронизированная реплика будет выбрана в качестве лидера. Для нового высоконадежного кластера Kafka параметр unclean leader election выключен, чтобы предотвратить потерю сообщений.
Также мы увеличили replication factor с 2 до 3 и minimum insync replicas с 1 до 2. Издатели, пишущие в этот кластер, требуют acks от всех других, гарантируя, что 2 из 3 реплик будут иметь самые актуальные сообщения, отправленные издателем.
Когда экземпляр брокера завершает работу, новый экземпляр заменяет старый. Однако новому брокеру нужно будет догнать несинхронизированные реплики, что может занять несколько часов. Чтобы сократить время восстановления работы этого сценария, мы начали использовать блочное хранилище данных (Amazon Elastic Block Store) вместо локальных дисков брокеров. Когда новый экземпляр заменяет завершившийся экземпляр брокера, он присоединяет EBS-том, который был у завершившегося экземпляра, и начинает догонять новые сообщения. Этот процесс сокращает время ликвидации отставания с нескольких часов до нескольких минут, так как новому экземпляру больше не нужно реплицировать из пустого состояния. В целом, отдельные жизненные циклы хранилища и брокера значительно снижают влияние эффекта от смены брокера.
Чтобы еще больше увеличить гарантию доставки данных, мы использовали систему отслеживания сообщений для обнаружения любой потери сообщений в экстремальных условиях (например, рассинхронизация часов в лидере раздела).
Уровень обработки в Delta построен на базе платформы Netflix SPaaS, которая обеспечивает интеграцию Apache Flink с экосистемой Netflix. Платформа предоставляет пользовательский интерфейс, который управляет развертыванием заданий Flink и оркестрацией кластеров Flink поверх нашей платформы управления контейнерами Titus. Интерфейс также управляет конфигурациями заданий и позволяет пользователями вносить изменения в конфигурацию динамически без необходимости перекомпилировать задания Flink.
Delta предоставляет фреймворк потоковой обработки (stream processing framework) данных на базе Flink и SPaaS, которая использует основанный на аннотациях DSL (Domain Specific Language), чтобы абстрагировать технические детали. Например, чтобы определить шаг, с которым будут обогащаться события, вызывая внешние сервисы, пользователям нужно написать следующий DSL, а фреймворк создаст на основе него модель, которая выполнится Flink.
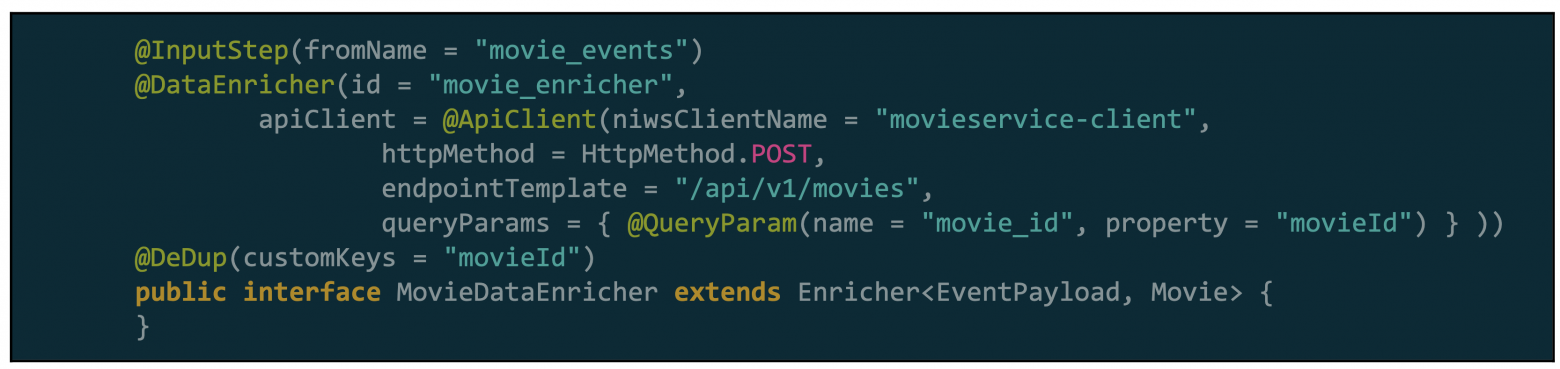
Рисунок 3. Пример обогащения на DSL в Delta
Фреймворк для обработки не только сокращает кривую обучения, но и обеспечивает общие функции обработки потока, такие как дедупликация, схематизация, а также гибкость и отказоустойчивость для решения общих проблем в работе.
Delta Stream Processing Framework состоит из двух ключевых модулей, модуля DSL & API и модуля Runtime. Модуль DSL & API предоставляет DSL и UDF (User-Defined-Function) API для того, чтобы пользователи могли написать собственную логику обработки (например, фильтрацию или преобразования). Модуль Runtime предоставляет реализацию парсера DSL, который строит внутреннее представление шагов обработки в моделях DAG. Компонент Execution интерпретирует DAG-модели, чтобы инициализировать фактические операторы Flink и в конечном итоге запустить приложение Flink. Архитектура фреймворка проиллюстрирована на следующем рисунке.
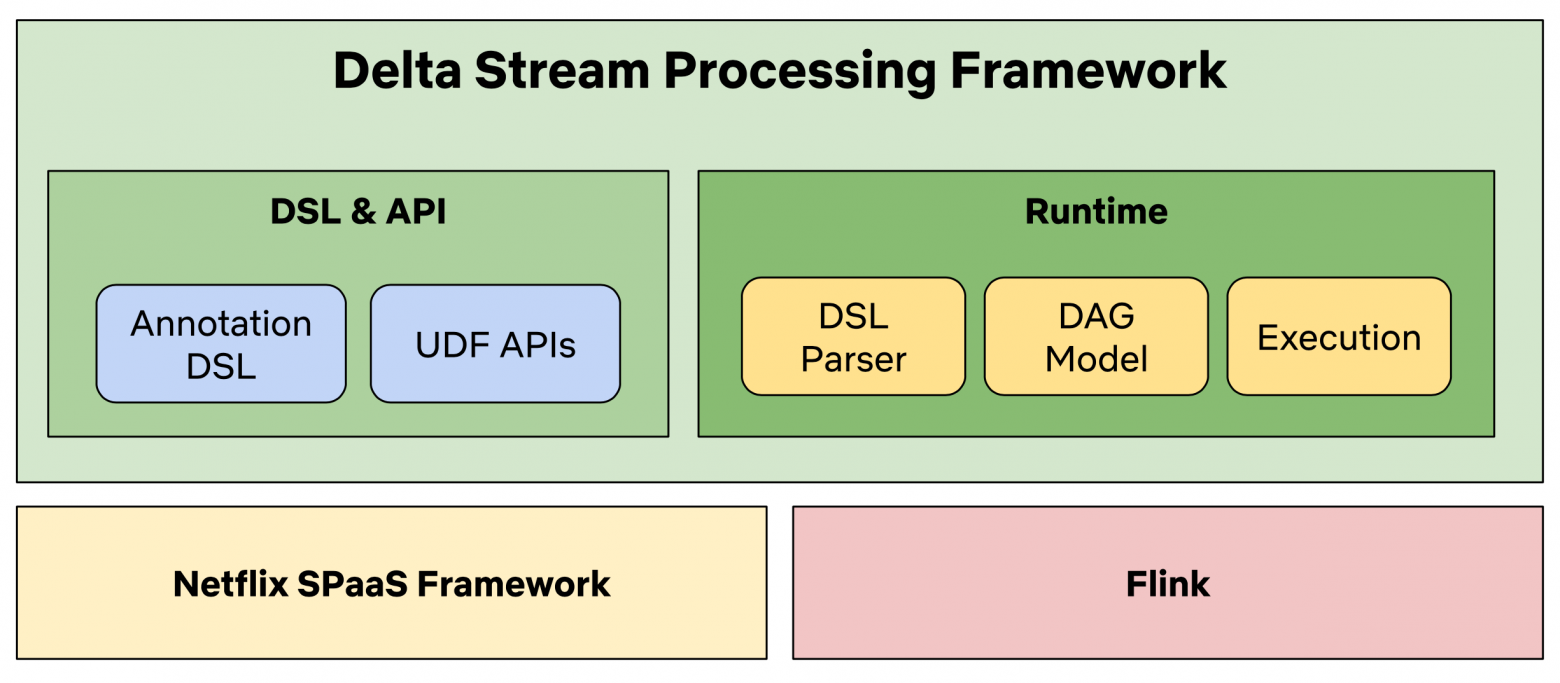
Рисунок 4. Архитектура Delta Stream Processing Framework
У такого подхода есть несколько преимуществ:
Delta работает на продакшене уже больше года и играет ключевую роль во многих приложениях Netflix Studio. Она помогла командам реализовать такие варианты использования, как индексация поиска, хранение данных и рабочие процессы, управляемые событиями. Ниже представлен обзор высокоуровневой архитектуры платформы Delta.

Рисунок 5. Высокоуровневая архитектура Delta.
Мы хотели бы поблагодарить следующих людей, которые участвовали в создании и развитии Delta в Netflix: Allen Wang, Charles Zhao, Jaebin Yoon, Josh Snyder, Kasturi Chatterjee, Mark Cho, Olof Johansson, Piyush Goyal, Prashanth Ramdas, Raghuram Onti Srinivasan, Sandeep Gupta, Steven Wu, Tharanga Gamaethige, Yun Wang и Zhenzhong Xu.
Записаться на бесплатный вебинар: «Data Build Tool для хранилища Amazon Redshift».

Обзор
Мы поговорим о достаточно популярном паттерне, с помощью которого приложения используют несколько хранилищ данных, где каждое хранилище используется под свои цели, например, для хранения канонической формы данных (MySQL и т.д.), обеспечения расширенных возможностей поиска (ElasticSearch и т.д.), кэширования (Memcached и т.д.) и других. Обычно при использовании нескольких хранилищ данных одно из них работает как основное хранилище, а другие как производные хранилища. Единственная проблема заключается в том, как синхронизировать эти хранилища данных.
Мы рассмотрели ряд различных паттернов, которые пытались решить проблему синхронизации нескольких хранилищ, таких как двойная запись, распределенные транзакции и т.д. Однако эти подходы имеют существенные ограничения в плане использования в реальной жизни, надежности и технического обслуживания. Помимо синхронизации данных, некоторым приложениям также необходимо обогащать данные, вызывая внешние сервисы.
Для решения этих проблем и была разработана Delta. Delta в конечном итоге представляет из себя согласованную, управляемую событиями платформу для синхронизации и обогащения данных.
Существующие решения
Двойная запись
Чтобы синхронизировать два хранилища данных, можно использовать двойную запись, которая выполняет запись в одно хранилище, а потом сразу после этого делает запись в другое. Первую запись можно повторить, а вторую – прервать, если первая завершится неудачей после исчерпания количества попыток. Однако два хранилища данных могут перестать синхронизироваться, если запись во второе хранилище завершится неудачей. Решается эта проблема обычно созданием процедуры восстановления, которая может периодически повторно переносить данные из первого хранилища во второе или делать это только в том случае, если в данных обнаруживаются различия.
Проблемы:
Выполнение процедуры восстановления – это специфичная работа, которую нельзя переиспользовать. Кроме того, данные между хранилищами остаются рассинхронизированными до тех пор, пока не пройдет процедура восстановления. Решение усложняется, если используется более двух хранилищ данных. И, наконец, процедура восстановления может добавить нагрузку на исходный источник данных.
Таблица логов изменений
Когда в наборе таблиц происходят изменения (например, вставка, обновление и удаление записи), записи изменений добавляются в таблицу логов, как часть той же транзакции. Другой поток или процесс постоянно запрашивает события из таблицы логов и записывает их в одно или несколько хранилищ данных, при появлении необходимости удаляя события из таблицы логов после подтверждения записи всеми хранилищами.
Проблемы:
Этот паттерн должен быть реализован как библиотека и в идеале без изменения кода приложения ее использующего. В среде-полиглоте реализация такой библиотеки должна существовать на любом необходимом языке, но обеспечить согласованность работы функций и поведения между языками очень непросто.
Другая проблема кроется в получении изменений схемы, в тех системах, которые не поддерживают транзакционные изменения схемы [1][2], как, например, MySQL. Поэтому шаблон выполнения изменения (например, изменения схемы) и транзакционной записи его в таблицу логов изменений не всегда будет работать.
Распределенные Транзакции
Распределенные транзакции можно использовать для того, чтобы разделить транзакцию между несколькими разнородными хранилищами данных так, чтобы операция либо фиксировалась во всех используемых хранилищах, либо не фиксировалась ни в одном из них.
Проблемы:
Распределенные транзакции – очень большая проблема для разнородных хранилищ данных. По своей природе они могут полагаться только на наименьший общий знаменатель участвующих систем. Например, XA-транзакции блокируют выполнение, если в процессе приложения происходит сбой на этапе подготовки. Кроме того, XA не обеспечивает обнаружения дедлоков и не поддерживает оптимистические схемы управления параллелизмом. Помимо этого, некоторые системы по типу ElasticSearch не поддерживают XA или любую другую гетерогенную модель транзакций. Таким образом, обеспечение атомарности записи в различных технологиях хранения данных остается для приложений весьма сложной задачей [3].
Delta
Delta была разработана для устранения ограничений существующих решений по синхронизации данных, она также позволяет обогащать данные на лету. Наша цель состояла в том, чтобы абстрагировать все эти сложные моменты от разработчиков приложений, чтобы они могли полностью сосредоточиться на реализации бизнес-функционала. Далее мы будем описывать «Movie Search», фактический вариант использования Delta от Netflix.
В Netflix широко применяется микросервисная архитектура и каждый микросервис обычно обслуживает по одному типу данных. Основные сведения о фильме вынесены в микросервис, который называется Movie Service, а также связанные с ними данные, такие как информация о продюсерах, актерах, вендорах и так далее управляются несколькими другими микросервисами (а именно Deal Service, Talent Service и Vendor Service).
Бизнес-пользователи в Netflix Studios часто нуждаются в поиске по различным критериям фильмов, именно поэтому для них очень важно иметь возможность осуществлять поиск по всем данным, связанным с фильмами.
До появления Delta команде поиска фильмов нужно было получать данные из нескольких микросервисов, прежде чем индексировать данные фильмов. Помимо этого, команда должна была разработать систему, которая периодически обновляла бы поисковый индекс, запрашивая изменения у других микросервисов, даже если изменений не было вообще. Эта система очень быстро обросла сложностями и ее стало трудно поддерживать.

Рисунок 1. Система поллинга до Delta
После начала использования Delta, система была упрощена до системы, управляемой событиями, как показано на следующем рисунке. События CDC (Change-Data-Capture) отправляются в топики Keystone Kafka с помощью Delta-Connector. Приложение Delta, построенное с использованием Delta Stream Processing Framework (основанного на Flink), получает CDC-события из топика, обогащает их, вызывая другие микросервисы, и, наконец, передает обогащенные данные в поисковый индекс в Elasticsearch. Весь процесс проходит почти в реальном времени, то есть, как только изменения фиксируются в хранилище данных, поисковые индексы обновляются.

Рисунок 2. Пайплайн данных при использовании Delta
В следующих разделах мы опишем работу Delta-Connector, который подключается к хранилищу и публикует CDC-события на транспортном уровне, который представляет из себя инфраструктуру передачи данных в реальном времени, направляющую CDC-события в топики Kafka. А в самом конце мы поговорим о структуре обработки потоков Delta, которую разработчики приложений могут использовать для логики обработки и обогащения данных.
CDC (Change-Data-Capture)
Мы разработали CDC-сервис под названием Delta-Connector, который может фиксировать закоммиченные изменения из хранилища данных в режиме реального времени и писать их в поток. Изменения в реальном времени берутся из журнала транзакций и дампов хранилища. Дампы используются поскольку журналы транзакций обычно не хранят всю историю изменений. Изменения обычно сериализуются как события Delta, так что получателю не нужно беспокоиться о том, откуда появляется изменение.
Delta-Connector поддерживает несколько дополнительных функций, таких как:
- Возможность писать в кастомные выходные данные мимо Kafka.
- Возможность активации ручных дампов в любое время для всех таблиц, какой-то определенной таблицы или для определенных первичных ключей.
- Дампы можно забирать чанками, поэтому нет необходимости начинать все с начала в случае сбоя.
- Нет необходимости ставить блокировки на таблицы, что очень важно для того, чтобы трафик записи в базу данных никогда не блокировался нашим сервисом.
- Высокая доступность из-за резервных экземпляров в AWS Availability Zones.
Сейчас мы поддерживаем MySQL и Postgres, в том числе при развертывании в AWS RDS и Aurora. Также мы поддерживаем Cassandra (multi-master). Больше подробностей о Delta-Connector вы можете узнать в этом блоге.
Kafka и транспортный уровень
Транспортный уровень событий Delta построен на сервисе обмена сообщениями платформы Keystone.
Так исторически сложилось, что публикация сообщений в Netflix оптимизировалась с учетом повышения доступности, а не долговечности (см. предыдущую статью). Компромиссом оказалось потенциальное несоответствие данных брокера в различных пограничных сценариях. Например, unclean leader election отвечает за то, что получатель потенциально дублирует или теряет события.
С Delta нам хотелось получить более весомые гарантии долговечности, чтобы обеспечить доставку CDC-событий в производные хранилища. Для этого мы предложили специально спроектированный кластер Kafka в качестве объекта первого класса. Вы можете посмотреть на некоторые настройки брокера в таблице ниже:

В кластерах Keystone Kafka, unclean leader election обычно включен для обеспечения доступности издателя. Это может привести к потере сообщений в случае, если несинхронизированная реплика будет выбрана в качестве лидера. Для нового высоконадежного кластера Kafka параметр unclean leader election выключен, чтобы предотвратить потерю сообщений.
Также мы увеличили replication factor с 2 до 3 и minimum insync replicas с 1 до 2. Издатели, пишущие в этот кластер, требуют acks от всех других, гарантируя, что 2 из 3 реплик будут иметь самые актуальные сообщения, отправленные издателем.
Когда экземпляр брокера завершает работу, новый экземпляр заменяет старый. Однако новому брокеру нужно будет догнать несинхронизированные реплики, что может занять несколько часов. Чтобы сократить время восстановления работы этого сценария, мы начали использовать блочное хранилище данных (Amazon Elastic Block Store) вместо локальных дисков брокеров. Когда новый экземпляр заменяет завершившийся экземпляр брокера, он присоединяет EBS-том, который был у завершившегося экземпляра, и начинает догонять новые сообщения. Этот процесс сокращает время ликвидации отставания с нескольких часов до нескольких минут, так как новому экземпляру больше не нужно реплицировать из пустого состояния. В целом, отдельные жизненные циклы хранилища и брокера значительно снижают влияние эффекта от смены брокера.
Чтобы еще больше увеличить гарантию доставки данных, мы использовали систему отслеживания сообщений для обнаружения любой потери сообщений в экстремальных условиях (например, рассинхронизация часов в лидере раздела).
Stream Processing Framework
Уровень обработки в Delta построен на базе платформы Netflix SPaaS, которая обеспечивает интеграцию Apache Flink с экосистемой Netflix. Платформа предоставляет пользовательский интерфейс, который управляет развертыванием заданий Flink и оркестрацией кластеров Flink поверх нашей платформы управления контейнерами Titus. Интерфейс также управляет конфигурациями заданий и позволяет пользователями вносить изменения в конфигурацию динамически без необходимости перекомпилировать задания Flink.
Delta предоставляет фреймворк потоковой обработки (stream processing framework) данных на базе Flink и SPaaS, которая использует основанный на аннотациях DSL (Domain Specific Language), чтобы абстрагировать технические детали. Например, чтобы определить шаг, с которым будут обогащаться события, вызывая внешние сервисы, пользователям нужно написать следующий DSL, а фреймворк создаст на основе него модель, которая выполнится Flink.

Рисунок 3. Пример обогащения на DSL в Delta
Фреймворк для обработки не только сокращает кривую обучения, но и обеспечивает общие функции обработки потока, такие как дедупликация, схематизация, а также гибкость и отказоустойчивость для решения общих проблем в работе.
Delta Stream Processing Framework состоит из двух ключевых модулей, модуля DSL & API и модуля Runtime. Модуль DSL & API предоставляет DSL и UDF (User-Defined-Function) API для того, чтобы пользователи могли написать собственную логику обработки (например, фильтрацию или преобразования). Модуль Runtime предоставляет реализацию парсера DSL, который строит внутреннее представление шагов обработки в моделях DAG. Компонент Execution интерпретирует DAG-модели, чтобы инициализировать фактические операторы Flink и в конечном итоге запустить приложение Flink. Архитектура фреймворка проиллюстрирована на следующем рисунке.

Рисунок 4. Архитектура Delta Stream Processing Framework
У такого подхода есть несколько преимуществ:
- Пользователи могут сфокусироваться на своей бизнес-логике без необходимости углубляться в специфику Flink или структуру SPaaS.
- Оптимизация может выполняться прозрачным для пользователей способом, а ошибки могут быть исправлены без необходимости внесения каких-либо изменений в код пользователя (UDF).
- Работа приложений Delta упрощена для пользователей, поскольку платформа обеспечивает гибкость и отказоустойчивость из коробки и собирает множество подробных метрик, которые можно использовать для оповещений.
Использование на продакшене
Delta работает на продакшене уже больше года и играет ключевую роль во многих приложениях Netflix Studio. Она помогла командам реализовать такие варианты использования, как индексация поиска, хранение данных и рабочие процессы, управляемые событиями. Ниже представлен обзор высокоуровневой архитектуры платформы Delta.

Рисунок 5. Высокоуровневая архитектура Delta.
Благодарности
Мы хотели бы поблагодарить следующих людей, которые участвовали в создании и развитии Delta в Netflix: Allen Wang, Charles Zhao, Jaebin Yoon, Josh Snyder, Kasturi Chatterjee, Mark Cho, Olof Johansson, Piyush Goyal, Prashanth Ramdas, Raghuram Onti Srinivasan, Sandeep Gupta, Steven Wu, Tharanga Gamaethige, Yun Wang и Zhenzhong Xu.
Источники
- dev.mysql.com/doc/refman/5.7/en/implicit-commit.html
- dev.mysql.com/doc/refman/5.7/en/cannot-roll-back.html
- Martin Kleppmann, Alastair R. Beresford, Boerge Svingen: Online event processing. Commun. ACM 62(5): 43–49 (2019). DOI: doi.org/10.1145/3312527
Записаться на бесплатный вебинар: «Data Build Tool для хранилища Amazon Redshift».
