Через такое прошли многие стартапы: каждый день регистрируются толпы новых пользователей, а команда разработчиков изо всех сил пытается поддержать работу сервиса.
Это приятная проблема, но в Сети мало чёткой информации, как аккуратно масштабировать веб-приложение с нуля до сотен тысяч пользователей. Обычно встречаются или пожарные решения, или устранение узких мест (а часто и то, и другое). Поэтому люди используют довольно шаблонные приёмы по масштабированию своего любительского проекта в нечто действительно серьёзное.
Попытаемся отфильтровать информацию и записать основную формулу. Мы собираемся пошагово масштабировать наш новый сайт для обмена фотографиями Graminsta с 1 до 100 000 пользователей.
Запишем, какие конкретные действия необходимо сделать при увеличении аудитории до 10, 100, 1000, 10 000 и 100 000 человек.
Почти у каждого приложения, будь то веб-сайт или мобильное приложение, есть три ключевых компонента:
База данных хранит постоянные данные. API обслуживает запросы к этим данным и вокруг них. Клиент передаёт данные пользователю.
Я пришёл к выводу, что гораздо проще рассуждать о масштабировании приложения, если с точки зрения архитектуры полностью разделить сущности клиента и API.
Когда мы впервые начинаем создавать приложение, все три компонента можно запускать на одном сервере. В некотором смысле это напоминает нашу среду разработки: один инженер запускает базу данных, API и клиент на одном компьютере.
Теоретически, мы могли бы развернуть его в облаке на одном экземпляре DigitalOcean Droplet или AWS EC2, как показано ниже:

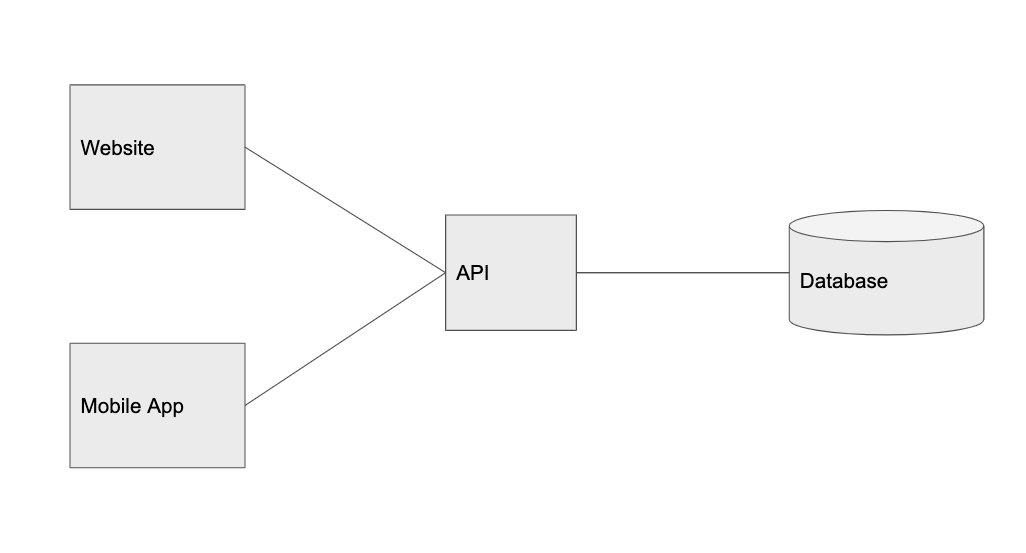
С учётом сказанного, если на сайте будет больше одного пользователя, почти всегда имеет смысл выделить уровень базы данных.
Разделение базы данных на управляемые службы, такие как Amazon RDS или Digital Ocean Managed Database, хорошо послужит нам в течение длительного времени. Это немного дороже, чем самостоятельный хостинг на одной машине или экземпляре EC2, но с этими службами вы из коробки получаете множество полезных расширений, которые пригодятся в будущем: резервирование по нескольким регионам, реплики чтения, автоматическое резервное копирование и многое другое.
Вот как теперь выглядит система:

К счастью, наше приложение очень понравилось первым пользователи. Трафик становится более стабильным, так что пришло время вынести клиента в отдельный уровень. Следует отметить, что разделение сущностей является ключевым аспектом построения масштабируемого приложения. Поскольку одна часть системы получает больше трафика, мы можем разделить её так, чтобы управлять масштабированием сервиса на основе специфических шаблонов трафика.
Вот почему мне нравится представлять клиента отдельно от API. Это позволяет очень легко рассуждать о разработке под нескольких платформ: веб, мобильный веб, iOS, Android, десктопные приложения, сторонние сервисы и т. д. Все они — просто клиенты, использующие один и тот же API.
Например, сейчас наши пользователи чаще всего просят выпустить мобильное приложение. Если разделить сущности клиента и API, то это становится проще.
Вот как выглядит такая система:
Дела идут на лад. Пользователи Graminsta загружают всё больше фотографии. Количество регистраций тоже растёт. Наш одинокий API-сервер с трудом справляется со всем трафиком. Нужно больше железа!
Балансировщик нагрузки — очень мощная концепция. Ключевая идея в том, что мы ставим балансировщик перед API, а он распределяет трафик по отдельным экземплярам службы. Так осуществляется горизонтальное масштабирование, то есть мы добавляем больше серверов с одним и тем же кодом, увеличивая количество запросов, которые можем обрабатывать.
Мы собираемся разместить отдельные балансировщики нагрузки перед веб-клиентом и перед API. Это означает, что можно запустить несколько инстансов, выполняющих код API и код веб-клиента. Балансировщик нагрузки будет направлять запросы к тому серверу, который меньше нагружен.
Здесь мы получаем ещё одно важное преимущество — избыточность. Когда один экземпляр выходит из строя (возможно, перегружается или падает), то у нас остаются другие, которые по-прежнему отвечают на входящие запросы. Если бы работал единственный экземпляр, то в случае сбоя упала бы вся система.
Балансировщик нагрузки также обеспечивает автоматическое масштабирование. Мы можем его настроить, чтобы увеличить количество инстансов перед пиковой нагрузкой, и уменьшить, когда все пользователи спят.
С балансировщиком нагрузки уровень API можно масштабировать практически до бесконечности, просто добавляем новые экземпляры по мере увеличения количества запросов.
Возможно, следовало сделать это с самого начала. Обработка запросов и приём новых фотографий начинают слишком нагружать наши серверы.
На данном этапе нужно использовать облачный сервис хранения статического контента — изображений, видео и многого другого (AWS S3 или Digital Ocean Spaces). В общем, наш API должен избегать обработки таких вещей, как выдача изображений и закачка изображений на сервер.
Ещё одно преимущество облачного хостинга — это CDN (в AWS это дополнение называется Cloudfront, но многие облачные хранилища предлагают его из коробки). CDN автоматически кэширует наши изображения в различных дата-центрах по всему миру.
Хотя наш основной дата-центр может быть размещён в Огайо, но если кто-то запросит изображение из Японии, то облачный провайдер сделает копию и сохранит её в своём японском дата-центре. Следующий, кто запросит это изображение в Японии, получит его гораздо быстрее. Это важно, когда мы работаем с файлами больших размеров, как фотографии или видео, которые долго загружать и передавать через всю планету.
CDN очень помог: трафик растёт полным ходом. Знаменитый видеоблогер Мэвид Мобрик только что зарегистрировался у нас и запостил свою «стори», как они говорят. Благодаря балансировщику нагрузки уровень использования CPU и памяти на серверах API держится на низком уровне (запущено десять инстансов API), но мы начинаем получать много таймаутов на запросы… откуда взялись эти задержки?
Немного покопавшись в метриках, мы видим, что CPU на сервере базы данных загружен на 80-90%. Мы на пределе.
Масштабирование слоя данных, вероятно, самая сложная часть уравнения. Серверы API обслуживают запросы без сохранения состояния (stateless), поэтому мы просто добавляем больше инстансов API. Но с большинством баз данных так сделать не получится. Мы оговорим о популярных реляционных системах управления базами данных (PostgreSQL, MySQL и др.).
Один из самых простых способов увеличить производительность нашей базы данных — ввести новый компонент: уровень кэша. Наиболее распространённый способ кэширования — хранилище записей «ключ-значение» в оперативной памяти, например, Redis или Memcached. В большинстве облаков есть управляемая версия таких сервисов: Elasticache на AWS и Memorystore на Google Cloud.
Кэш полезен, когда служба делает много повторных вызовов к БД для получения одной и той же информации. По сути, мы обращаемся к базе только один раз, сохраняем информацию в кэше — и больше её не трогаем.
Например, в в нашем сервисе Graminsta каждый раз, когда кто-то переходит на страницу профиля звезды Мобрика, сервер API запрашивает в БД информацию из его профиля. Это происходит снова и снова. Поскольку информация профиля Мобрика не меняется при каждом запросе, то отлично подходит для кэширования.
Будем кэшировать результаты из БД в Redis по ключу
Другое преимущество большинства сервисов кэширования в том, что их проще масштабировать, чем серверы БД. У Redis есть встроенный режим кластера Redis Cluster. Подобно балансировщику нагрузки1, он позволяет распределять кэш Redis по нескольким машинам (по тысячам серверов, если нужно).
Почти все крупномасштабные приложения используют кэширование, это абсолютно неотъемлемая часть быстрого API. Ускорение обработки запросов и более производительный код — всё это важно, но без кэша практически невозможно масштабировать сервис до миллионов пользователей.
Когда количество запросов к БД сильно возросло, мы можем сделать ещё одну вещь — добавить реплики чтения в системе управления базами данных. С помощью описанных выше управляемых служб это можно сделать в один клик. Реплика чтения будет оставаться актуальной в основной БД и доступна для операторов SELECT.
Вот наша система сейчас:

Поскольку приложение продолжает масштабироваться, мы продолжим разделять службы, чтобы масштабировать их независимо друг от друга. Например, если мы начинаем использовать Websockets, то имеет смысл вытащить код обработки Websockets в отдельную службу. Мы можем разместить её на новых инстансах за собственным балансировщиком нагрузки, который может масштабироваться вверх и вниз в зависимости от открытых соединений Websockets и независимо от количества HTTP-запросов.
Также продолжим бороться с ограничениями на уровне БД. Именно на данном этапе пришло время изучить партиционирование и шардирование базы данных. Оба подхода требуют дополнительных накладных расходов, зато позволяют масштабировать БД практически до бесконечности.
Мы также хотим установить сервис мониторинга и аналитики вроде New Relic или Datadog. Это позволит выявить медленные запросы и понять, где требуется улучшение. По мере масштабирования мы хотим сосредоточиться на поиске узких мест и их устранении — часто используя некоторые идеи из предыдущих разделов.
Этот пост вдохновлён одним из моих любимых постов о высокой масштабируемости. Я хотел немного конкретизировать статью для начальных стадий проектов и отвязать её от одного вендора. Обязательно прочитайте, если интересуетесь этой темой.

Это приятная проблема, но в Сети мало чёткой информации, как аккуратно масштабировать веб-приложение с нуля до сотен тысяч пользователей. Обычно встречаются или пожарные решения, или устранение узких мест (а часто и то, и другое). Поэтому люди используют довольно шаблонные приёмы по масштабированию своего любительского проекта в нечто действительно серьёзное.
Попытаемся отфильтровать информацию и записать основную формулу. Мы собираемся пошагово масштабировать наш новый сайт для обмена фотографиями Graminsta с 1 до 100 000 пользователей.
Запишем, какие конкретные действия необходимо сделать при увеличении аудитории до 10, 100, 1000, 10 000 и 100 000 человек.
1 пользователь: 1 машина
Почти у каждого приложения, будь то веб-сайт или мобильное приложение, есть три ключевых компонента:
- API
- база данных
- клиент (само мобильное приложение или веб-сайт)
База данных хранит постоянные данные. API обслуживает запросы к этим данным и вокруг них. Клиент передаёт данные пользователю.
Я пришёл к выводу, что гораздо проще рассуждать о масштабировании приложения, если с точки зрения архитектуры полностью разделить сущности клиента и API.
Когда мы впервые начинаем создавать приложение, все три компонента можно запускать на одном сервере. В некотором смысле это напоминает нашу среду разработки: один инженер запускает базу данных, API и клиент на одном компьютере.
Теоретически, мы могли бы развернуть его в облаке на одном экземпляре DigitalOcean Droplet или AWS EC2, как показано ниже:

С учётом сказанного, если на сайте будет больше одного пользователя, почти всегда имеет смысл выделить уровень базы данных.
10 пользователей: вынос БД в отдельный уровень
Разделение базы данных на управляемые службы, такие как Amazon RDS или Digital Ocean Managed Database, хорошо послужит нам в течение длительного времени. Это немного дороже, чем самостоятельный хостинг на одной машине или экземпляре EC2, но с этими службами вы из коробки получаете множество полезных расширений, которые пригодятся в будущем: резервирование по нескольким регионам, реплики чтения, автоматическое резервное копирование и многое другое.
Вот как теперь выглядит система:

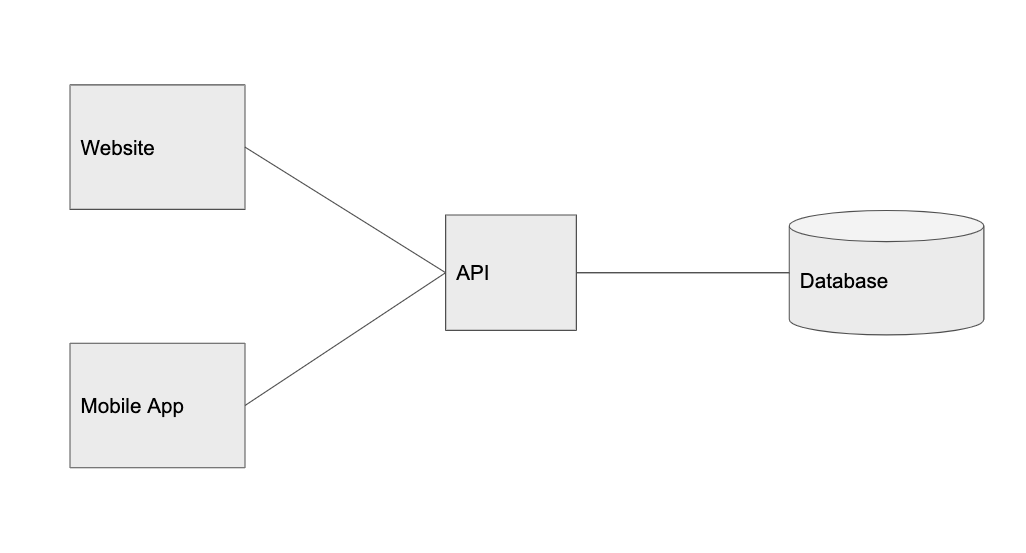
100 пользователей: вынос клиента в отдельный уровень
К счастью, наше приложение очень понравилось первым пользователи. Трафик становится более стабильным, так что пришло время вынести клиента в отдельный уровень. Следует отметить, что разделение сущностей является ключевым аспектом построения масштабируемого приложения. Поскольку одна часть системы получает больше трафика, мы можем разделить её так, чтобы управлять масштабированием сервиса на основе специфических шаблонов трафика.
Вот почему мне нравится представлять клиента отдельно от API. Это позволяет очень легко рассуждать о разработке под нескольких платформ: веб, мобильный веб, iOS, Android, десктопные приложения, сторонние сервисы и т. д. Все они — просто клиенты, использующие один и тот же API.
Например, сейчас наши пользователи чаще всего просят выпустить мобильное приложение. Если разделить сущности клиента и API, то это становится проще.
Вот как выглядит такая система:
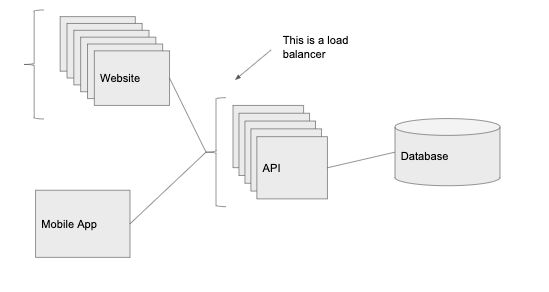
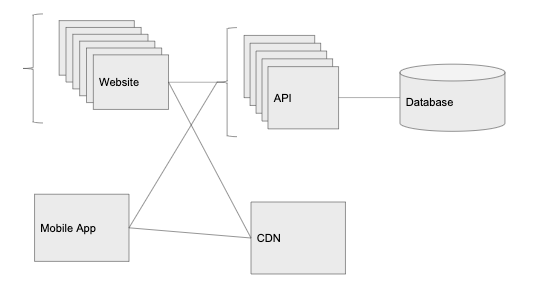
1000 пользователей: добавить балансировщик нагрузки
Дела идут на лад. Пользователи Graminsta загружают всё больше фотографии. Количество регистраций тоже растёт. Наш одинокий API-сервер с трудом справляется со всем трафиком. Нужно больше железа!
Балансировщик нагрузки — очень мощная концепция. Ключевая идея в том, что мы ставим балансировщик перед API, а он распределяет трафик по отдельным экземплярам службы. Так осуществляется горизонтальное масштабирование, то есть мы добавляем больше серверов с одним и тем же кодом, увеличивая количество запросов, которые можем обрабатывать.
Мы собираемся разместить отдельные балансировщики нагрузки перед веб-клиентом и перед API. Это означает, что можно запустить несколько инстансов, выполняющих код API и код веб-клиента. Балансировщик нагрузки будет направлять запросы к тому серверу, который меньше нагружен.
Здесь мы получаем ещё одно важное преимущество — избыточность. Когда один экземпляр выходит из строя (возможно, перегружается или падает), то у нас остаются другие, которые по-прежнему отвечают на входящие запросы. Если бы работал единственный экземпляр, то в случае сбоя упала бы вся система.
Балансировщик нагрузки также обеспечивает автоматическое масштабирование. Мы можем его настроить, чтобы увеличить количество инстансов перед пиковой нагрузкой, и уменьшить, когда все пользователи спят.
С балансировщиком нагрузки уровень API можно масштабировать практически до бесконечности, просто добавляем новые экземпляры по мере увеличения количества запросов.

Примечание. В данный момент наша система очень похожа на то, что из коробки предлагают компании PaaS, такие как Heroku или сервис Elastic Beanstalk в AWS (поэтому они так популярны). Heroku помещает БД на отдельный хост, управляет балансировщиком нагрузки с автоматическим масштабированием и позволяет разместить веб-клиент отдельно от API. Это отличная причина, чтобы использовать Heroku для проектов или стартапов на ранней стадии — все базовые сервисы вы получаете из коробки.
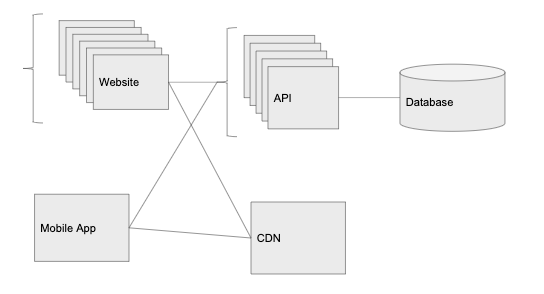
10 000 пользователей: CDN
Возможно, следовало сделать это с самого начала. Обработка запросов и приём новых фотографий начинают слишком нагружать наши серверы.
На данном этапе нужно использовать облачный сервис хранения статического контента — изображений, видео и многого другого (AWS S3 или Digital Ocean Spaces). В общем, наш API должен избегать обработки таких вещей, как выдача изображений и закачка изображений на сервер.
Ещё одно преимущество облачного хостинга — это CDN (в AWS это дополнение называется Cloudfront, но многие облачные хранилища предлагают его из коробки). CDN автоматически кэширует наши изображения в различных дата-центрах по всему миру.
Хотя наш основной дата-центр может быть размещён в Огайо, но если кто-то запросит изображение из Японии, то облачный провайдер сделает копию и сохранит её в своём японском дата-центре. Следующий, кто запросит это изображение в Японии, получит его гораздо быстрее. Это важно, когда мы работаем с файлами больших размеров, как фотографии или видео, которые долго загружать и передавать через всю планету.
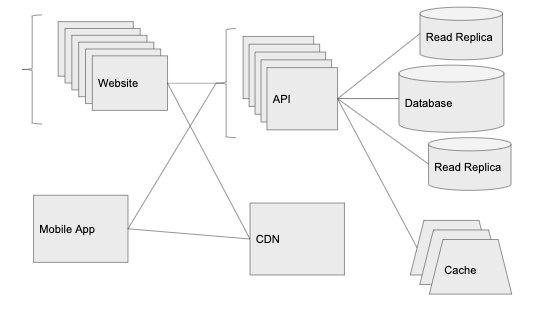
100 000 пользователей: масштабирование уровня данных
CDN очень помог: трафик растёт полным ходом. Знаменитый видеоблогер Мэвид Мобрик только что зарегистрировался у нас и запостил свою «стори», как они говорят. Благодаря балансировщику нагрузки уровень использования CPU и памяти на серверах API держится на низком уровне (запущено десять инстансов API), но мы начинаем получать много таймаутов на запросы… откуда взялись эти задержки?
Немного покопавшись в метриках, мы видим, что CPU на сервере базы данных загружен на 80-90%. Мы на пределе.
Масштабирование слоя данных, вероятно, самая сложная часть уравнения. Серверы API обслуживают запросы без сохранения состояния (stateless), поэтому мы просто добавляем больше инстансов API. Но с большинством баз данных так сделать не получится. Мы оговорим о популярных реляционных системах управления базами данных (PostgreSQL, MySQL и др.).
Кэширование
Один из самых простых способов увеличить производительность нашей базы данных — ввести новый компонент: уровень кэша. Наиболее распространённый способ кэширования — хранилище записей «ключ-значение» в оперативной памяти, например, Redis или Memcached. В большинстве облаков есть управляемая версия таких сервисов: Elasticache на AWS и Memorystore на Google Cloud.
Кэш полезен, когда служба делает много повторных вызовов к БД для получения одной и той же информации. По сути, мы обращаемся к базе только один раз, сохраняем информацию в кэше — и больше её не трогаем.
Например, в в нашем сервисе Graminsta каждый раз, когда кто-то переходит на страницу профиля звезды Мобрика, сервер API запрашивает в БД информацию из его профиля. Это происходит снова и снова. Поскольку информация профиля Мобрика не меняется при каждом запросе, то отлично подходит для кэширования.
Будем кэшировать результаты из БД в Redis по ключу
user:id со сроком действия 30 секунд. Теперь, когда кто-то заходит в профиль Мобрика, мы сначала проверяем Redis, и если данные там есть, просто передаём их прямо из Redis. Теперь запросы к самому популярному профилю на сайте практически не нагружают нашу базу данных.Другое преимущество большинства сервисов кэширования в том, что их проще масштабировать, чем серверы БД. У Redis есть встроенный режим кластера Redis Cluster. Подобно балансировщику нагрузки1, он позволяет распределять кэш Redis по нескольким машинам (по тысячам серверов, если нужно).
Почти все крупномасштабные приложения используют кэширование, это абсолютно неотъемлемая часть быстрого API. Ускорение обработки запросов и более производительный код — всё это важно, но без кэша практически невозможно масштабировать сервис до миллионов пользователей.
Реплики чтения
Когда количество запросов к БД сильно возросло, мы можем сделать ещё одну вещь — добавить реплики чтения в системе управления базами данных. С помощью описанных выше управляемых служб это можно сделать в один клик. Реплика чтения будет оставаться актуальной в основной БД и доступна для операторов SELECT.
Вот наша система сейчас:
Дальнейшие действия
Поскольку приложение продолжает масштабироваться, мы продолжим разделять службы, чтобы масштабировать их независимо друг от друга. Например, если мы начинаем использовать Websockets, то имеет смысл вытащить код обработки Websockets в отдельную службу. Мы можем разместить её на новых инстансах за собственным балансировщиком нагрузки, который может масштабироваться вверх и вниз в зависимости от открытых соединений Websockets и независимо от количества HTTP-запросов.
Также продолжим бороться с ограничениями на уровне БД. Именно на данном этапе пришло время изучить партиционирование и шардирование базы данных. Оба подхода требуют дополнительных накладных расходов, зато позволяют масштабировать БД практически до бесконечности.
Мы также хотим установить сервис мониторинга и аналитики вроде New Relic или Datadog. Это позволит выявить медленные запросы и понять, где требуется улучшение. По мере масштабирования мы хотим сосредоточиться на поиске узких мест и их устранении — часто используя некоторые идеи из предыдущих разделов.
Источники
Этот пост вдохновлён одним из моих любимых постов о высокой масштабируемости. Я хотел немного конкретизировать статью для начальных стадий проектов и отвязать её от одного вендора. Обязательно прочитайте, если интересуетесь этой темой.
Сноски
- Несмотря на схожесть с точки зрения распределения нагрузки между несколькими инстансами, базовая реализация кластера Redis сильно отличается от балансировщика нагрузки. [вернуться]

