Это райтап об одном из заданий, которое мы приготовили для отборочного этапа CTFZone, прошедшего в конце ноября. О процессе подготовки к квалификации можно прочитать здесь.
Вы начинаете с двумя файлами: decrypt_flag.py и ntfs_volume.raw. Давайте взглянем на скрипт. Он открывает файл c именем key.bin, а затем при помощи цикла пробует взять из каждого смещения внутри файла бинарную строку размером 34 байта, которая затем используется в качестве входных данных для функции PBKDF2. Каждый возвращенный ключ используется в качестве XOR-ключа для расшифровывания вшитой в код зашифрованной строки. Если в расшифрованной форме ее хеш MD5 совпадает с заранее определенным значением, скрипт использует полученные данные, чтобы сформировать и напечатать флаг.
Итак, вам нужно найти файл key.bin. Просто перебрать все смещения внутри файла образа (ntfs_volume.raw) нельзя, так как процесс поиска ключа будет слишком медленным. Правилами это не запрещено, но до конца CTF вы точно не успеете.
Файл образа содержит таблицу разделов MBR с одним разделом. Его смещение — 2048 512-байтовых секторов, а содержит он файловую систему NTFS, но файла key.bin там нет:
NTFS хранит имена файлов в кодировке UTF-16LE. Давайте попробуем поискать в ней!
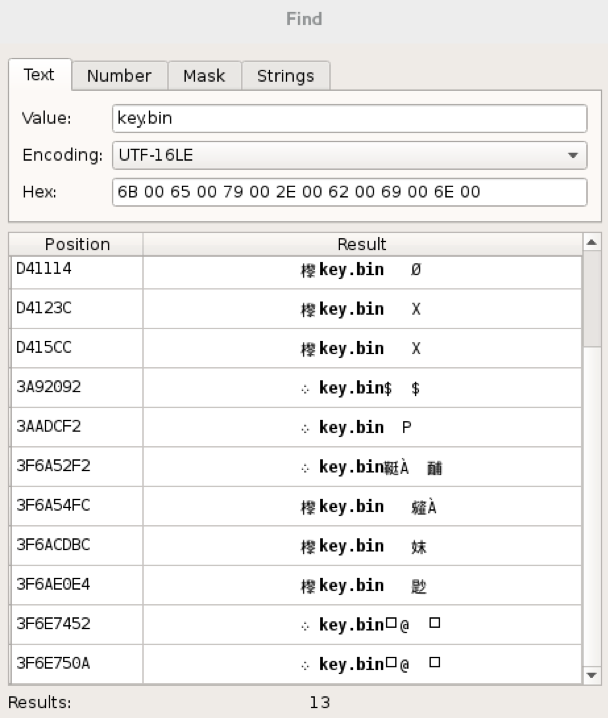
Результаты поиска записей о файле
Изучив результаты поиска, сфокусируемся на файловых записях, которые начинаются с сигнатуры FILE [1]. Вот единственная такая запись:

Найденная запись
Цель уже близка! Запись о файле у нас есть, но нам нужны данные. В NTFS они хранятся в атрибуте $DATA, который может быть резидентным или нерезидентным [2]. У записи, которую мы нашли, этот атрибут начинается по смещению 0×3AADD00 и указывает на нерезидентные данные (это означает, что информация хранится вне записи о файле).
Так где же именно находятся данные нужного файла? Чтобы ответить на этот вопрос, придется декодировать так называемые mapping pairs, или data runs (пары «длина блока — смещение блока») [3]. Data runs искомого файла следующие (обратите внимание на смещение 0×3AADD40): 22 53 01 A0 4E 21 05 31 C1 11 38 30 00. Или, если мы их перегруппируем:
Файл состоит из трех фрагментов, размер первого из которых составляет 339 кластеров, а начинается он с кластера #20128. Для нашего кода, использующего PBKDF2, этот фрагмент крупноват. Как указано в заголовке файловой системы, размер одного кластера — 4096 байт:
Давайте взглянем на данные вот по этому смещению (в байтах):
2048 * 512 + 20128 * 4096 = 83492864. Извлечем отсюда любое значимое количество информации (например, 128 байт), вставим в новый файл, который назовем key.bin, запустим скрипт… Ничего не получилось.
Возможно, файл хранился не в текущей, а в предыдущей версии файловой системы (предыдущее форматирование) — не забывайте, что мы не видели записи об удаленном файле с таким именем. Какой раньше был размер у кластеров? Давайте поищем заголовок файловой системы с сигнатурой NTFS [4]. Может, нам повезет и мы действительно найдем заголовок от предыдущего форматирования.

Результаты поиска заголовка файловой системы
Первая и последняя позиции в выдаче относятся к нынешней файловой системе, а вот заголовки файловой системы, которые расположены между ними, кажется, принадлежат к предыдущему форматированию. И в них другой размер кластера!

Заголовок файловой системы из предыдущей версии
Вот такой размер сектора записан по смещению 0×4554800B: 00 02, или 512. А вот такой размер кластера записан по смещению 0×0x4554800D: F7, или 247.
Итак, размер кластера (в байтах) у нас 512 * 247 = 126464. Ерунда какая-то! Если верить парсеру NTFS [5], такое значение должно обладать знаком и обрабатываться специальным образом, значит реальный размер кластера (в секторах) — это 1 << –(–9) = 512. Или, если в байтах, 512 * 512 = 262144. Теперь звучит более правдоподобно.
Данные начинаются вот по этому смещению (в байтах):
2048 * 512 + 20128 * 262144 = 5277483008. Давайте еще раз попробуем провернуть тот же трюк с хранящейся там информацией… Опять провал! Что же не так? У нас тут CTF, значит «не так» может быть все что угодно.
Таск, над которым мы бьемся, называется In the Shadows. Не исключено, что он имеет какое-то отношение к теневым копиям тома. Итак, у нас есть файл из файловой системы, которая раньше существовала в этом томе. Просто взять и смонтировать ее теневую копию мы, к сожалению, не можем, зато знаем точное смещение, на котором начинаются данные! Это 5277483008, или, внутри раздела, 5277483008 – 2048 * 512 = 5276434432.
Согласно спецификациям формата VSS [6], перенаправленные блоки данных описываются в структуре Block descriptor, содержащей 64-битное поле, в котором хранится оригинальное смещение (внутри тома), а также 64-битное поле, описывающее целевое смещение блока (внутри тома). Давайте поищем 5276434432 как 64-битное число little endian.
В выдаче — только два результата, и лишь один из них расположен по четному смещению.

Найденный дескриптор блока
Смещение целевого блока: 00 00 9B 03 00 00 00 00, или просто 60489728. Окончательное смещение: 60489728 + 2048 * 512 = 61538304. Экспортируем отсюда некоторое количество данных в новый файл с именем key.bin, и…
Готово!
Вы начинаете с двумя файлами: decrypt_flag.py и ntfs_volume.raw. Давайте взглянем на скрипт. Он открывает файл c именем key.bin, а затем при помощи цикла пробует взять из каждого смещения внутри файла бинарную строку размером 34 байта, которая затем используется в качестве входных данных для функции PBKDF2. Каждый возвращенный ключ используется в качестве XOR-ключа для расшифровывания вшитой в код зашифрованной строки. Если в расшифрованной форме ее хеш MD5 совпадает с заранее определенным значением, скрипт использует полученные данные, чтобы сформировать и напечатать флаг.
Итак, вам нужно найти файл key.bin. Просто перебрать все смещения внутри файла образа (ntfs_volume.raw) нельзя, так как процесс поиска ключа будет слишком медленным. Правилами это не запрещено, но до конца CTF вы точно не успеете.
Файл образа содержит таблицу разделов MBR с одним разделом. Его смещение — 2048 512-байтовых секторов, а содержит он файловую систему NTFS, но файла key.bin там нет:
$ fls -o 2048 -r -p ntfs_volume.raw | grep -F key.bin | wc –l
0NTFS хранит имена файлов в кодировке UTF-16LE. Давайте попробуем поискать в ней!
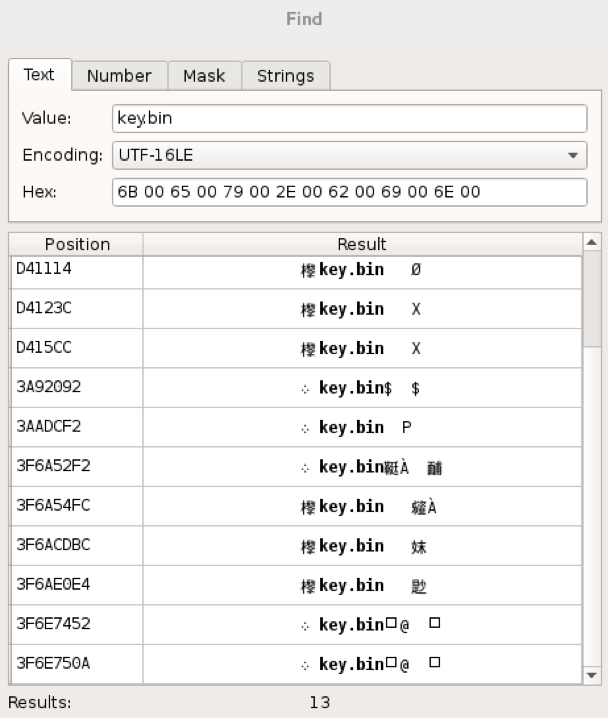
Результаты поиска записей о файле
Изучив результаты поиска, сфокусируемся на файловых записях, которые начинаются с сигнатуры FILE [1]. Вот единственная такая запись:

Найденная запись
Цель уже близка! Запись о файле у нас есть, но нам нужны данные. В NTFS они хранятся в атрибуте $DATA, который может быть резидентным или нерезидентным [2]. У записи, которую мы нашли, этот атрибут начинается по смещению 0×3AADD00 и указывает на нерезидентные данные (это означает, что информация хранится вне записи о файле).
Так где же именно находятся данные нужного файла? Чтобы ответить на этот вопрос, придется декодировать так называемые mapping pairs, или data runs (пары «длина блока — смещение блока») [3]. Data runs искомого файла следующие (обратите внимание на смещение 0×3AADD40): 22 53 01 A0 4E 21 05 31 C1 11 38 30 00. Или, если мы их перегруппируем:
1. 22 53 01 A0 4E
2. 21 05 31 C1
3. 11 38 30 00Файл состоит из трех фрагментов, размер первого из которых составляет 339 кластеров, а начинается он с кластера #20128. Для нашего кода, использующего PBKDF2, этот фрагмент крупноват. Как указано в заголовке файловой системы, размер одного кластера — 4096 байт:
$ fsstat -o 2048 ntfs_volume.raw | grep 'Cluster Size'
Cluster Size: 4096Давайте взглянем на данные вот по этому смещению (в байтах):
2048 * 512 + 20128 * 4096 = 83492864. Извлечем отсюда любое значимое количество информации (например, 128 байт), вставим в новый файл, который назовем key.bin, запустим скрипт… Ничего не получилось.
Возможно, файл хранился не в текущей, а в предыдущей версии файловой системы (предыдущее форматирование) — не забывайте, что мы не видели записи об удаленном файле с таким именем. Какой раньше был размер у кластеров? Давайте поищем заголовок файловой системы с сигнатурой NTFS [4]. Может, нам повезет и мы действительно найдем заголовок от предыдущего форматирования.
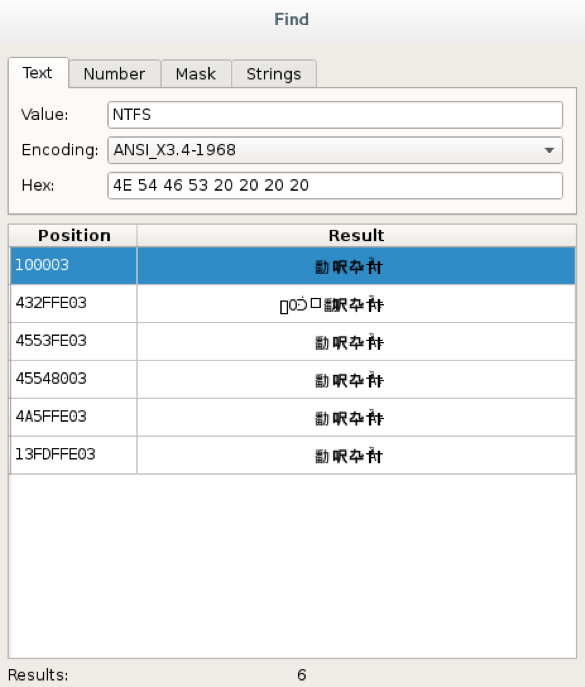
Результаты поиска заголовка файловой системы
Первая и последняя позиции в выдаче относятся к нынешней файловой системе, а вот заголовки файловой системы, которые расположены между ними, кажется, принадлежат к предыдущему форматированию. И в них другой размер кластера!

Заголовок файловой системы из предыдущей версии
Вот такой размер сектора записан по смещению 0×4554800B: 00 02, или 512. А вот такой размер кластера записан по смещению 0×0x4554800D: F7, или 247.
Итак, размер кластера (в байтах) у нас 512 * 247 = 126464. Ерунда какая-то! Если верить парсеру NTFS [5], такое значение должно обладать знаком и обрабатываться специальным образом, значит реальный размер кластера (в секторах) — это 1 << –(–9) = 512. Или, если в байтах, 512 * 512 = 262144. Теперь звучит более правдоподобно.
Данные начинаются вот по этому смещению (в байтах):
2048 * 512 + 20128 * 262144 = 5277483008. Давайте еще раз попробуем провернуть тот же трюк с хранящейся там информацией… Опять провал! Что же не так? У нас тут CTF, значит «не так» может быть все что угодно.
Таск, над которым мы бьемся, называется In the Shadows. Не исключено, что он имеет какое-то отношение к теневым копиям тома. Итак, у нас есть файл из файловой системы, которая раньше существовала в этом томе. Просто взять и смонтировать ее теневую копию мы, к сожалению, не можем, зато знаем точное смещение, на котором начинаются данные! Это 5277483008, или, внутри раздела, 5277483008 – 2048 * 512 = 5276434432.
Согласно спецификациям формата VSS [6], перенаправленные блоки данных описываются в структуре Block descriptor, содержащей 64-битное поле, в котором хранится оригинальное смещение (внутри тома), а также 64-битное поле, описывающее целевое смещение блока (внутри тома). Давайте поищем 5276434432 как 64-битное число little endian.
В выдаче — только два результата, и лишь один из них расположен по четному смещению.

Найденный дескриптор блока
Смещение целевого блока: 00 00 9B 03 00 00 00 00, или просто 60489728. Окончательное смещение: 60489728 + 2048 * 512 = 61538304. Экспортируем отсюда некоторое количество данных в новый файл с именем key.bin, и…
$ ./decrypt_flag.py
ctfzone{my_c0ngr4t5_t0_u,w311_d0n3_31337}Готово!
Ссылки
- https://flatcap.org/linux-ntfs/ntfs/concepts/file_record.html
- https://flatcap.org/linux-ntfs/ntfs/attributes/data.html
- https://flatcap.org/linux-ntfs/ntfs/concepts/data_runs.html
- https://flatcap.org/linux-ntfs/ntfs/files/boot.html
- https://github.com/msuhanov/dfir_ntfs/blob/94bb46d6600153071b0c3c507ef37c42ad62110d/dfir_ntfs/BootSector.py#L58
- https://github.com/libyal/libvshadow/blob/master/documentation/Volume%20Shadow%20Snapshot%20(VSS)%20format.asciidoc#431-block-descriptor
