Все рассказывают про процессы разработки и тестирования, обучения персонала, повышение мотивации, но этих процессов мало, когда минута простоя сервиса стоит космических денег. Что делать, когда вы проводите финансовые транзакции под жесткий SLA? Как повысить надежность и отказоустойчивость ваших систем, вынося за скобки разработку и тестирование?

Следующая конференция HighLoad++ пройдет 6 и 7 апреля 2020 года в Санкт-Петербурге. Подробности и билеты по ссылке. 9 ноября, 18:00. HighLoad++ Moscow 2018, зал «Дели + Калькутта». Тезисы и презентация.
Евгений Кузовлев (далее – ЕК): – Друзья, привет! Меня зовут Кузовлев Евгений. Я из компании EcommPay, конкретное подразделение – EcommPay IT, айти-подразделение группы компаний. И сегодня мы с вами поговорим о даунтаймах – о том, как их избежать, о том, как минимизировать их последствия, если избежать не удастся. Тематика заявлена такая: «Что делать, когда минута простоя стоит 100 000 долларов»? У нас, забегая вперёд, цифры сравнимы.
Кто мы такие? Почему я тут перед вами стою? Почему я имею право вам здесь что-то рассказывать? И о чём поговорим здесь более подробно?
Группа компаний EcommPay – это международный эквайр. Мы процессим платежи по всему миру – в России, Европе, в Юго-Восточной Азии (All Around the World). У нас 9 офисов, 500 сотрудников всего и примерно чуть меньше половины среди них – это IT-специалисты. Всё, что мы делаем, всё, на чём мы зарабатываем деньги, мы сделали сами.
У нас все наши продукты (а их у нас достаточно много – в линейке больших IT-продуктов у нас порядка 16 различных компонент) мы написали сами; мы сами пишем, мы сами развиваем. И на данный момент мы проводим около миллиона транзакций в день (миллионы – наверное, так будет правильно сказать). Мы молодая компания достаточно – нам всего около шести лет.
6 лет назад это был такой стартап, когда пришли ребята вместе с бизнесом. Они были объединены идеей (больше ничего не было, кроме идеи), и мы побежали. Как и любой стартап, мы бежали быстрее… Для нас была важнее скорость, а не качество.
В какой-то момент мы остановились: осознали, что мы уже не можем с той скоростью и с тем качеством как-то жить и нам нужно делать в первую очередь именно качество. В этот момент мы приняли решение написать новую платформу, которая будет правильной, масштабируемой, надёжной. Эту платформу начали писать (начали вкладывать, развивать разработку, тестирование), но в какой-то момент поняли, что разработка, тестирование не позволяют выйти на новый уровень качества сервиса.
Вы делаете новый продукт, вы его выставляете на продакшн, но всё равно где-то что-то пойдёт не так. И сегодня мы поговорим о том, как выйти на новый качественный уровень (у нас как это получилось, про наш опыт), вынося за скобки разработку и тестирование; мы поговорим про то, что доступно эксплуатации – что эксплуатация может сделать сама, что она может предложить тестированию, чтобы повлиять на качество.
Всегда основной краеугольный камень, о чём мы сегодня, собственно, будем говорить – даунтайм. Страшное слово. Если у нас случился даунтайм – у нас всё плохо. Мы бежим поднимать, админы сервер держат – дай бог не упадёт, как в той песне поётся. Вот об этом мы сегодня поговорим.

Когда мы начали менять свои подходы, мы сформировали 4 заповеди. Они у меня представлены на слайдах:
Эти заповеди достаточно просты:

Обращу ваше внимание на пункт № 2. Мы избавляемся от проблемы, а не решаем её. Решить – это вторично. Для нас первично то, что пользователь ограждён от этой проблемы. Она будет существовать в некоем изолированном окружении, но это окружение никак не будет с ним контактировать. Собственно, мы с вами пройдёмся по этим четырём группам проблем (по каким-то подробнее, по каким-то менее подробно), я расскажу, что мы используем, какой у нас соответствующий опыт в решениях.
Но начнём мы не по порядку, начнём мы с пункта № 2 – как быстро избавиться от проблемы? Есть проблема – нам её надо устранить. «Что нам с этим делать?» – основной вопрос. И когда мы начали думать о том, как устранить проблему, мы для себя выработали некоторые требования, которым устранение проблем должно следовать.

Чтобы эти требования сформулировать, мы решили себе задать вопрос: «А когда у нас случаются проблемы»? И проблемы, как выяснилось, встречаются в четырёх случаях:

Про первые две мы с вами говорить не будем. Аппаратная неисправность решается достаточно просто: у вас должно быть всё дублировано. Если это диски – диски должны быть собраны в RAID, если это сервер – сервер должен быть дублирован, если у вас сетевая инфраструктура – вы должны поставить вторую копию сетевой инфраструктуры, то есть вы берёте и дублируете. И если у вас что-то отказывает, вы переключаетесь на резервные мощности. Здесь большее что-то сказать сложно.
Второе – это сбой внешних сервисов. Для большинства система это вообще не проблема, но не для нас. Так как мы процессим платежи, то мы такой агрегатор, который стоит между пользователем (который вводит свои карточные данные) и банками, платёжными системами («Виза», «МастерКард», «Мира» того же). Внешним нашим сервисам (платёжным системам, банкам) свойственно сбоить. Повлиять ни мы, ни вы (если у вас есть такие сервисы) на это не можем.
Что тогда делать? Здесь варианта два. Во-первых, если вы можете, вы должны задублировать этот сервис каким-то образом. Например, мы, если можем, перекидываем трафик с одного сервиса на другой: процессили, например, карты через «Сбербанк», у «Сбербанка» проблемы – мы переводим трафик [условно] на «Райффайзен». Второе, что мы можем сделать – это очень быстро заметить сбой внешних сервисов, и поэтому мы поговорим о скорости реакции в следующей части доклада.
По факту из этих четырёх мы можем конкретно повлиять на смену версий ПО – сделать действия, которые приведут к улучшению ситуации в контексте деплоеев и в контексте взрывного роста нагрузки. Собственно, мы это и сделали. Здесь, опять же, маленькая ремарка…
Из этих четырёх проблем несколько решаются сразу, если у вас есть облако. Если вы находитесь в облаках «Майкрософт Ажур», «Озон», используете наши облака, от «Яндекса» или «Мэйла», то как минимум аппаратная неисправность становится их проблемой и у вас сразу всё становится хорошо в контексте аппаратной неисправности.
Мы – немножечко нестандартная компания. Здесь все говорят про «Кубернетс», про облака – у нас нет ни «Кубернетса», ни облаков. У нас зато есть стойки с железом во множестве дата-центров, и на этом железе мы вынуждены жить, мы вынуждены отвечать за это всё. Поэтому в этом контексте будем разговаривать. Итак, про проблемы. Первые две вынесли за скобки.
У нас разработчики не имеют доступа к продакшну. Почему так? А просто мы сертифицированы по PCI DSS, и у нас разработчики просто не имеют право лазить в «прод». Всё, точка. Совсем. Поэтому ответственность разработки заканчивается ровно в тот момент, когда разработка передала билд на релиз.

Второй наш базис, который у нас есть, который тоже нам сильно помогает – это отсутствуют уникальные недокументированные знания. Я надеюсь, у вас так же. Потому что, если это не так – у вас возникнут проблемы. Проблемы возникнут тогда, когда эти уникальные недокументированные знания не будут присутствовать в нужное время в нужном месте. Допустим, у вас один человек знает как деплоить конкретный компонент – человека нет, он в отпуске или заболел – всё, у вас проблемы.
И третий базис, к которому мы пришли. Мы пришли к нему через боль, кровь, слёзы – мы пришли к тому, что любой наш билд содержит ошибки, даже если он без ошибок. Мы для себя так решили: когда мы что-то деплоим, когда мы что-то катим в прод – у нас билд с ошибками. Мы сформировали требования, которым наша система должна удовлетворять.
Этих требований три:


Следующая конференция HighLoad++ пройдет 6 и 7 апреля 2020 года в Санкт-Петербурге. Подробности и билеты по ссылке. 9 ноября, 18:00. HighLoad++ Moscow 2018, зал «Дели + Калькутта». Тезисы и презентация.
Евгений Кузовлев (далее – ЕК): – Друзья, привет! Меня зовут Кузовлев Евгений. Я из компании EcommPay, конкретное подразделение – EcommPay IT, айти-подразделение группы компаний. И сегодня мы с вами поговорим о даунтаймах – о том, как их избежать, о том, как минимизировать их последствия, если избежать не удастся. Тематика заявлена такая: «Что делать, когда минута простоя стоит 100 000 долларов»? У нас, забегая вперёд, цифры сравнимы.
Чем занимается EcommPay IT?
Кто мы такие? Почему я тут перед вами стою? Почему я имею право вам здесь что-то рассказывать? И о чём поговорим здесь более подробно?

Группа компаний EcommPay – это международный эквайр. Мы процессим платежи по всему миру – в России, Европе, в Юго-Восточной Азии (All Around the World). У нас 9 офисов, 500 сотрудников всего и примерно чуть меньше половины среди них – это IT-специалисты. Всё, что мы делаем, всё, на чём мы зарабатываем деньги, мы сделали сами.
У нас все наши продукты (а их у нас достаточно много – в линейке больших IT-продуктов у нас порядка 16 различных компонент) мы написали сами; мы сами пишем, мы сами развиваем. И на данный момент мы проводим около миллиона транзакций в день (миллионы – наверное, так будет правильно сказать). Мы молодая компания достаточно – нам всего около шести лет.
6 лет назад это был такой стартап, когда пришли ребята вместе с бизнесом. Они были объединены идеей (больше ничего не было, кроме идеи), и мы побежали. Как и любой стартап, мы бежали быстрее… Для нас была важнее скорость, а не качество.
В какой-то момент мы остановились: осознали, что мы уже не можем с той скоростью и с тем качеством как-то жить и нам нужно делать в первую очередь именно качество. В этот момент мы приняли решение написать новую платформу, которая будет правильной, масштабируемой, надёжной. Эту платформу начали писать (начали вкладывать, развивать разработку, тестирование), но в какой-то момент поняли, что разработка, тестирование не позволяют выйти на новый уровень качества сервиса.
Вы делаете новый продукт, вы его выставляете на продакшн, но всё равно где-то что-то пойдёт не так. И сегодня мы поговорим о том, как выйти на новый качественный уровень (у нас как это получилось, про наш опыт), вынося за скобки разработку и тестирование; мы поговорим про то, что доступно эксплуатации – что эксплуатация может сделать сама, что она может предложить тестированию, чтобы повлиять на качество.
Даунтаймы. Заповеди эксплуатации.
Всегда основной краеугольный камень, о чём мы сегодня, собственно, будем говорить – даунтайм. Страшное слово. Если у нас случился даунтайм – у нас всё плохо. Мы бежим поднимать, админы сервер держат – дай бог не упадёт, как в той песне поётся. Вот об этом мы сегодня поговорим.

Когда мы начали менять свои подходы, мы сформировали 4 заповеди. Они у меня представлены на слайдах:
Эти заповеди достаточно просты:

- Быстро выявить проблему.
- Ещё быстрее от неё избавиться.
- Помочь понять причину (потом, для разработчиков).
- И стандартизировать подходы.
Обращу ваше внимание на пункт № 2. Мы избавляемся от проблемы, а не решаем её. Решить – это вторично. Для нас первично то, что пользователь ограждён от этой проблемы. Она будет существовать в некоем изолированном окружении, но это окружение никак не будет с ним контактировать. Собственно, мы с вами пройдёмся по этим четырём группам проблем (по каким-то подробнее, по каким-то менее подробно), я расскажу, что мы используем, какой у нас соответствующий опыт в решениях.
Устранение проблем: когда они случаются и что с ними делать?
Но начнём мы не по порядку, начнём мы с пункта № 2 – как быстро избавиться от проблемы? Есть проблема – нам её надо устранить. «Что нам с этим делать?» – основной вопрос. И когда мы начали думать о том, как устранить проблему, мы для себя выработали некоторые требования, которым устранение проблем должно следовать.

Чтобы эти требования сформулировать, мы решили себе задать вопрос: «А когда у нас случаются проблемы»? И проблемы, как выяснилось, встречаются в четырёх случаях:

- Аппаратная неисправность.
- Сбой внешних сервисов.
- Смена версии ПО (тот самый деплой).
- Взрывной рост нагрузки.
Про первые две мы с вами говорить не будем. Аппаратная неисправность решается достаточно просто: у вас должно быть всё дублировано. Если это диски – диски должны быть собраны в RAID, если это сервер – сервер должен быть дублирован, если у вас сетевая инфраструктура – вы должны поставить вторую копию сетевой инфраструктуры, то есть вы берёте и дублируете. И если у вас что-то отказывает, вы переключаетесь на резервные мощности. Здесь большее что-то сказать сложно.
Второе – это сбой внешних сервисов. Для большинства система это вообще не проблема, но не для нас. Так как мы процессим платежи, то мы такой агрегатор, который стоит между пользователем (который вводит свои карточные данные) и банками, платёжными системами («Виза», «МастерКард», «Мира» того же). Внешним нашим сервисам (платёжным системам, банкам) свойственно сбоить. Повлиять ни мы, ни вы (если у вас есть такие сервисы) на это не можем.
Что тогда делать? Здесь варианта два. Во-первых, если вы можете, вы должны задублировать этот сервис каким-то образом. Например, мы, если можем, перекидываем трафик с одного сервиса на другой: процессили, например, карты через «Сбербанк», у «Сбербанка» проблемы – мы переводим трафик [условно] на «Райффайзен». Второе, что мы можем сделать – это очень быстро заметить сбой внешних сервисов, и поэтому мы поговорим о скорости реакции в следующей части доклада.
По факту из этих четырёх мы можем конкретно повлиять на смену версий ПО – сделать действия, которые приведут к улучшению ситуации в контексте деплоеев и в контексте взрывного роста нагрузки. Собственно, мы это и сделали. Здесь, опять же, маленькая ремарка…
Из этих четырёх проблем несколько решаются сразу, если у вас есть облако. Если вы находитесь в облаках «Майкрософт Ажур», «Озон», используете наши облака, от «Яндекса» или «Мэйла», то как минимум аппаратная неисправность становится их проблемой и у вас сразу всё становится хорошо в контексте аппаратной неисправности.
Мы – немножечко нестандартная компания. Здесь все говорят про «Кубернетс», про облака – у нас нет ни «Кубернетса», ни облаков. У нас зато есть стойки с железом во множестве дата-центров, и на этом железе мы вынуждены жить, мы вынуждены отвечать за это всё. Поэтому в этом контексте будем разговаривать. Итак, про проблемы. Первые две вынесли за скобки.
Смена версии ПО. Базисы
У нас разработчики не имеют доступа к продакшну. Почему так? А просто мы сертифицированы по PCI DSS, и у нас разработчики просто не имеют право лазить в «прод». Всё, точка. Совсем. Поэтому ответственность разработки заканчивается ровно в тот момент, когда разработка передала билд на релиз.

Второй наш базис, который у нас есть, который тоже нам сильно помогает – это отсутствуют уникальные недокументированные знания. Я надеюсь, у вас так же. Потому что, если это не так – у вас возникнут проблемы. Проблемы возникнут тогда, когда эти уникальные недокументированные знания не будут присутствовать в нужное время в нужном месте. Допустим, у вас один человек знает как деплоить конкретный компонент – человека нет, он в отпуске или заболел – всё, у вас проблемы.
И третий базис, к которому мы пришли. Мы пришли к нему через боль, кровь, слёзы – мы пришли к тому, что любой наш билд содержит ошибки, даже если он без ошибок. Мы для себя так решили: когда мы что-то деплоим, когда мы что-то катим в прод – у нас билд с ошибками. Мы сформировали требования, которым наша система должна удовлетворять.
Требования к смене версии ПО
Этих требований три:

- Мы должны быстро откатить деплой.
- Мы должны минимизировать влияние неуспешного деплоя.
- И мы должны иметь возможность быстро параллельно задеплоиться.
Именно в таком порядке! Почему? Потому что, в первую очередь, при деплое новой версии неважна скорость, но вам важно, если что-то пошло не так, быстро откатиться и оказать минимальное влияние. Но если у вас есть набор версий на продакшне, для которых выяснилось, что там содержится ошибка (как снег на голову, деплоя не было, но ошибка содержится) – вам важна скорость деплоя последующего. Что мы сделали, чтобы удовлетворить эти требования? Мы прибегли к такой методологии:
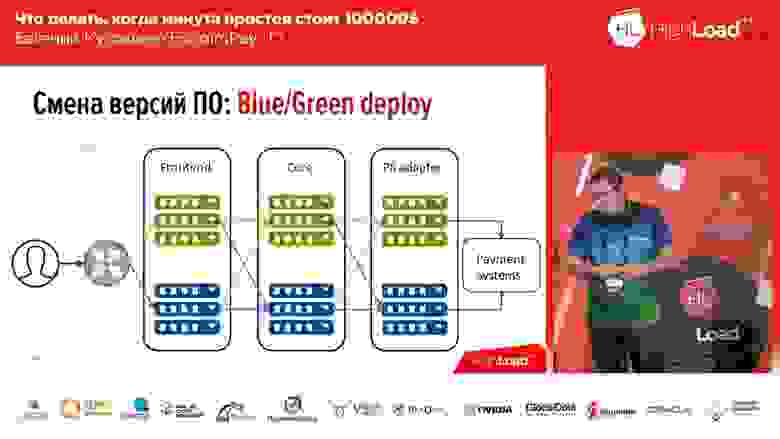
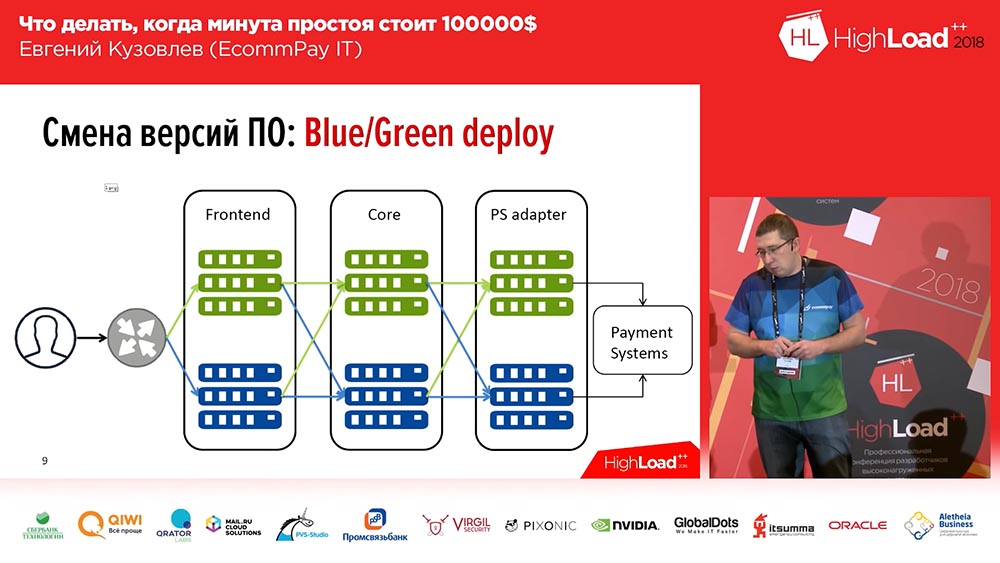
Она достаточно известна, мы не изобрели ни разу – это Blue/Green deploy. Что это такое? У вас для каждой группы серверов, на которых стоят ваши приложения, ваши аппликации, должна быть копия. Копия «тёплая»: на ней нет трафика, но в любой момент этот трафик на эту копию можно пустить. Эта копия содержит предыдущую версию. И в момент деплоя вы выкатываете код на неактивную копию. Потом переключаете часть трафика (или весь) на новую версию. Тем самым, для того чтобы изменить поток трафика со старой версии на новую, вам нужно сделать только одно действие: вам нужно в апстриме поменять балансировщика, поменять направление – с одного апстрима на другой. Это очень удобно и решает проблему быстрого переключения, быстрого отката.
Здесь же решение второго вопроса – минимизация: вы можете пустить на новую линию, на линию с новым кодом только часть вашего трафика (пускай, например, 2%). И эти 2% — они не 100%! Если у вас потерялось 100 % трафика при неудачном деплоее – это страшно, если у вас потеряло 2% трафика – это неприятно, но это не страшно. Мало того, пользователи даже, скорее всего, этого не заметят, потому что в некоторых случаях (не во всех) один тот же пользователь, нажав F5, он попадёт на другую, работающую версию.
Blue/Green deploy. Роутинг
При этом не всё так просто «Блю/Грин деплоеем»… Все наши компоненты можно разделить на три группы:
- это фронтенд (платёжные страницы, которые видят наши клиенты);
- ядро процессинга;
- адаптер для работы с платёжными системами (банки, «МастерКард», «Визу»…).
И здесь есть нюанс – нюанс заключается в роутинге между линиями. Если вы просто переключаете 100% трафика, у вас этих проблем нет. Но если вы хотите переключить 2%, у вас начинаются вопросы: «А как это сделать?» Самое простое, в лоб: вы можете по случайному выбору, Round Robin в nginx’е настроить, и у вас 2% – налево, 98% – направо. Но это не всегда подходит.
У нас, например, пользователь взаимодействует с системой не одним запросом. Это нормально: 2, 3, 4, 5 запросов – у вас системы могут быть такие же. И если вам важно, чтобы все запросы пользователя пришли на ту же самую линию, на которую пришёл первый запрос, или (второй момент) все запросы пользователя пришли на новую линию после переключения (работать он мог начать раньше с системой, до переключения), – тогда это случайное распределение вам не подходит. Тогда есть следующие варианты:

Первый вариант, самый простой – на основе базовых параметров клиента (IP Hash). У вас есть IP, и вы по айпишнику разделяете направо-налево. Тогда у вас сработает второй описанный мною случай, когда произошёл деплой, пользователь уже мог начать работать с вашей системой, и с момента деплоя все запросы пойдут на новую линию (на ту же самую, скажем).
Если это по каким-то причинам вам не подходит и вам надо обязательно отправлять запросы на ту линию, куда пришёл первичный, инитный запрос пользователя, тогда у вас есть два варианта…
Первый вариант: вы можете взять платный nginx+. Там есть механизм Sticky sessions, который при первичном запросе пользователя выставляет пользователю сессию и привязывает её к тому или иному апстриму. Все последующие запросы пользователя в рамках срока жизни сессии отправятся на тот же апстрим, куда была выставлена сессия.
Нам это не подошло, потому что у нас уже был nginx обычный. Переходить nginx+ – не то чтобы это дорого, просто это было для нас несколько больно и не очень правильно. «Стики сешнс» для нас, например, не сработали по той простой причине, что «Стики сешнс» не дают возможности роутить по признаку «Или-или». Там можно задать, что мы «Стики сешнс» делаем, например, по айпишнику или по айпишнику и по кукам или по постпараметру, а вот «Или-или» – там уже сложнее.
Поэтому мы пришли к четвёртому варианту. Мы взяли nginx на «стероидах» (это openresty) – это такой же nginx, который дополнительно поддерживает включение в себя last-скриптов. Вы можете написать last-скрипт, подсунуть этому «опенрести», и этот ластскрипт будет выполняться, когда придёт запрос пользователя.
И мы написали, собственно, такой скриптик, поставили себе «опенрести» и в этом скрипте перебираем 6 различных параметров по конкатенации «Или». В зависимости от наличия того или иного параметра, мы знаем, что пользователь пришёл на одну страницу или на другую, на одну линию или на другую.
Blue/Green deploy. Достоинства и недостатки
Конечно, можно было, наверное, сделать немного проще (те же «Стики сешнс» использовать), но у нас есть ещё такой нюанс, что с нами не только пользователь взаимодействует в рамках одного процессинга одной транзакции… Но с нами взаимодействуют ещё платёжные системы: мы, после того как процессим транзакцию (отправив запрос в платёжную систему), получаем кулбэк.
И допустим, если внутри нашего контура мы можем прокинуть айпишник пользователя во всех запросах и на основе айпишника пользователей разделять, то мы не скажем той же «Визе»: «Чуваки, мы такая вот ретро-компания, мы вроде международная (на сайте и в России)… А прокиньте нам, пожалуйста, айпишник пользователя дополнительно в дополнительное поле, ваш протокол стандартизированный»! Понятное дело, они не согласятся.

Поэтому для нас это не подошло – мы сделали openresty. Соответственно, с роутингом у нас получилось вот так:
У «Блю/Грин деплоя» есть, соответственно, достоинства, о которых я сказал, и недостатки.
Недостатка два:
- вам надо заморачиваться с роутингом;
- второй основной недостаток – это расходы.
Вам надо в два раза раза больше серверов, вам надо в два раза больше операционных ресурсов, вам надо тратить в два раза больше сил на поддержание всего этого зоопарка.
Кстати, среди достоинств – ещё одна вещь, о которой я до этого не упомянул: у вас есть резерв в случае роста нагрузки. Если у вас взрывной рост нагрузки, на вас повалило большое количество пользователей, то вы просто включаете вторую линию в распределение 50 на 50 – и у вас сразу х2 серверов в вашем кластере, пока вы не решите проблему наличия серверов ещё.
Как сделать быстрый деплой?
Мы поговорили, как решить проблему минимизации и быстрого отката, но вопрос остаётся: «А как быстро деплоиться»?

Здесь кратко и всё просто.
- У вас должна быть CD-система (Continuous Delivery) – без неё никуда. Если у вас один сервер, вы можете задеплоиться ручками. У нас серверов примерно полторы тысячи и ручками полторы тысячи, понятное дело – мы можем посадить отдел размером с этот зал, только чтобы деплоить.
- Деплой должен быть параллельным. Если у вас деплой последовательный, то всё плохо. Один сервер – нормально, полторы тысячи серверов вы будете деплоить весь день.
- Опять же, для ускорения, это уже необязательно, наверное. При десплоее обычно выполняется сборка проекта. Есть у вас веб-проект, есть фронтенд-часть (вы там делаете веб-пак, npm собираете – что-то такое), и это этот процесс в принципе недолгий – минут 5, но эти 5 минут могут быть критичными. Поэтому мы, например, так не делаем: мы эти 5 минут убрали, мы деплоим артефакты.
Что такое артефакт? Артефакт – это собранный билд, в котором уже выполнена вся сборочная часть. Этот артефакт мы храним в хранилище артефактов. Таких хранилищ мы в своё время использовали два – это был Nexus и сейчас jFrog Artifactory).«Нексус» мы изначально использовали потому, что начали этот подход практиковать в java-приложениях (он хорошо под это подходил). Потом туда же засунули часть приложений, которые написаны PHP; и «Нексус» уже не подходил, и мы поэтому выбрали jFrog Artefactory, который умеет артифакторить практически всё. Мы пришли даже к тому, что в этом хранилище артефактов храним собственные бинарные пакеты, которые мы для серверов собираем.
Взрывной рост нагрузки
Поговорили о смене версии ПО. Следующее, что у нас есть – это взрывной рост нагрузки. Здесь я, наверное, понимаю под взрывным ростом нагрузки не совсем правильную вещь…
Мы написали новую систему – она сервисоориентированная, модная красивая, везде воркеры, везде очереди, везде асинхронность. И в таких системах данные могут идти по разным flow. Для первой транзакции могут быть задействованы 1-й, 3-й, 10-й воркер, для второй транзакции – 2-й, 4-й, 5-й. И сегодня, допустим, с утра у вас идёт поток данных, который задействует первые три воркера, а вечером резко меняется, и всё задействует другие три воркера.
И здесь получается так, что вам нужно как-то масштабировать воркеры, нужно как-то масштабировать ваши сервисы, но при этом не допустить раздувания ресурсов.

Мы определили для себя требования. Эти требования достаточно простые: чтобы там был Service discovery, параметризация – всё стандартно для построения таких масштабируемых систем, кроме одного пункта – это амортизация ресурсов. Мы сказали, что мы не готовы ресурсы амортизировать, чтобы серверы воздух грели. Мы взяли «Консул», мы взяли «Номад», который управляет нашими воркерами.
Почему для нас это проблема? Давайте чуть назад откачусь. За нами стоит сейчас в районе 70 платёжных систем. С утра трафик идёт через «Сбербанк», потом «Сбербанк» упал, к примеру, и мы его переключаем на другую платёжную систему. У нас работало 100 воркеров до «Сбербанка», а после этого нам надо резко поднять 100 воркеров для другой платёжной системы. И это всё желательно чтобы происходило без человеческого участия. Потому что, если человеческое участие – там 24/7 должен сидеть инженер, который должен только этим и заниматься, потому что такие сбои, когда 70 систем за тобой, происходят регулярно.
Поэтому мы посмотрели на «Номад», у которого есть открытый IP и написали свою штуку Scale-Nomad – ScaleNo, которая делает примерно следующее: она следит за ростом очереди и уменьшает или увеличивает количество воркеров в зависимости от динамики изменения очереди. Когда сделали, мы подумали: «Может её заопенсорсить?» Потом на неё посмотрели – она простая, как две копейки.
До сих пор мы её опенсорсить не стали, но если вдруг у вас после доклада, после осознания, что вам нужна такая штука, появится необходимость в ней, в последнем слайде есть мои контакты – напишите мне, пожалуйста. Если наберётся хотя бы 3-5 человек – мы её заопенсорсим.
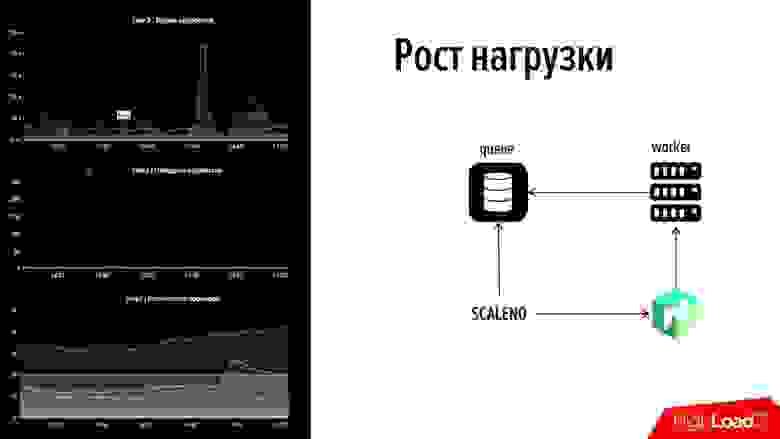
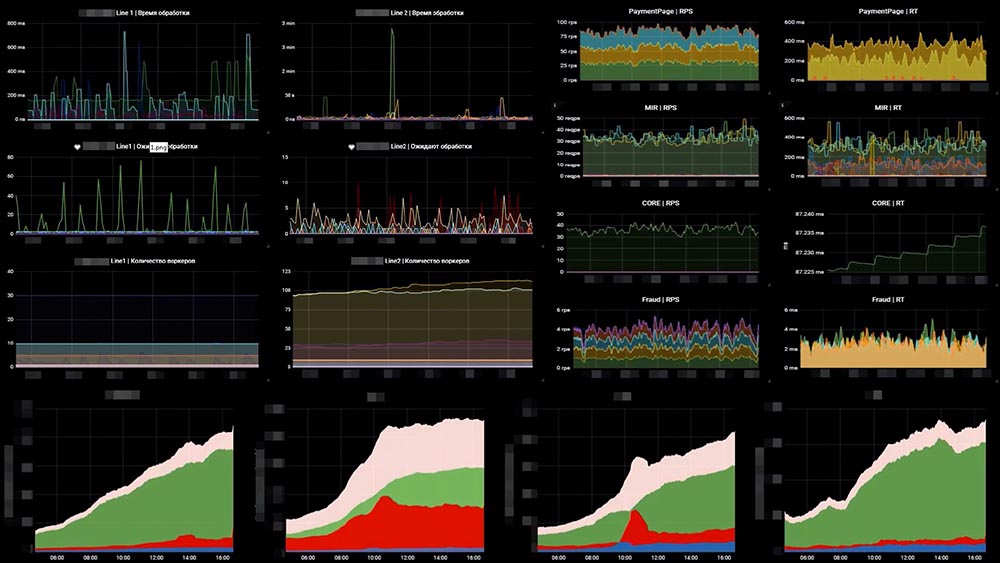
Как это работает? Давайте посмотрим! Забегая вперёд: с левой стороны есть кусочек нашего мониторинга: это одна линия, сверху – время обработки событий, в середине – количество транзакций, снизу – количество воркеров.
Если посмотреть, на этой картинке есть сбой. На верхнем графике один из графиков вылетел за 45 секунд – одна из платёжных систем легла. Тут же был приведён трафик за 2 минуты и пошёл рост очереди на другой платёжной системе, где не было воркеров (мы не утилизировали ресурсы – наоборот, утилизировали ресурс корректно). Мы не хотели греть – там было минимальное количество, около 5-10 воркеров, но они не справлялись.
На последнем графике виден «горб», который как раз говорит о том, что «Скалено» поднял это количество в два раза. И потом, когда график немного опустился, он немного уменьшил – количество воркеров было изменено в автоматическом режиме. Вот так эта штука работает. Поговорили о пункте № 2 – «Как быстро избавляться от причин».
Мониторинг. Как быстро выявить проблему?
Теперь первый пункт – «Как быстро выявить проблему?» Мониторинг! Мы должны быстро понимать определённые вещи. Какие вещи мы должны быстро понимать?

Три вещи!
- Мы должны быстро понимать и быстро понимать работоспособность наших собственных ресурсов.
- Мы должны быстро понимать выхождение из строя, мониторить работоспособность систем, которые для нас являются внешними.
- Третий пункт – выявление логических ошибок. Это когда система работает у вас, по всем показателям всё норм, но происходит что-то не так.
Здесь я, наверное, мало что расскажу такого крутого. Побуду капитаном Очевидность. Мы искали, что есть на рынке. У нас сложился «весёлый зоопарк». Вот такой зоопарк у нас сейчас сложился:

У нас «Заббикс» используется для мониторинга «железа», для мониторинга основных показателей серверов. «Окметер» мы используем для баз данных. «Графану» и «Прометей» мы используем для всех остальных показателей, которые не подошли под первые два, причём часть – с «Графаной» и «Прометеем», часть – «Графана» с «Инфлюксом» и Telegraf.
Год назад мы хотели использовать New Relic. Классная штука, она умеет всё. Но насколько она всё умеет, настолько она и дорогая. Когда мы выросли до объёма в 1,5 тысячи серверов, к нам пришёл вендор, сказал: «Давайте заключать договор на следующий год». Мы посмотрели на цену, что нет, мы так делать не будем. Сейчас мы от «Нью-Релика» отказываемся, у нас около 15 серверов осталось под мониторингом «Нью-Релика». Цена оказалась совершенно дикой.
И есть один инструмент, который мы реализовали сами – это Debugger. Сначала мы его назвали «Баггер», но потом прошёл у нас учитель английского, дико засмеялся, и переназвали на «Дебаггер». Что это такое? Это инструмент, который по факту в 15-30 секунд на каждом компоненте, как «чёрный ящик» системы, запускает тесты на общую работоспособность компонента.
Например, если внешняя страница (платёжная страница) – он просто её открывает и смотрит, как она должна выглядеть. Если это процессинг, он пуляет тестовую «транзаку» – смотрит, чтобы эта «транзака» дошла. Если это связь с платёжными системами – мы соответственно пуляем тестовый запрос, где можем, и смотрим, что у нас всё хорошо.
Какие показатели важны для мониторинга?
Что мы мониторим в основном? Какие показатели для нас важны?

- Response time / RPS на фронтах – очень важный показатель. Он сразу отвечает, что у вас что-то не так.
- Количество обработанных сообщений во всех очередях.
- Количество воркеров.
- Основные метрики корректности.
Последний пункт – «бизнесовый», «бизнесовая» метрика. Если вы хотите то же самое мониторить, вам надо определить одну-две метрики, которые для вас являются основными показателями. У нас такая метрика – это проходимость (это отношение количества успешных транзакций к общему потоку транзакций). Если в ней что-то меняется на интервале 5-10-15 минут – значит, у нас есть проблемы (если кардинально меняется).
Как это у нас выглядит – пример одного из наших бордов:
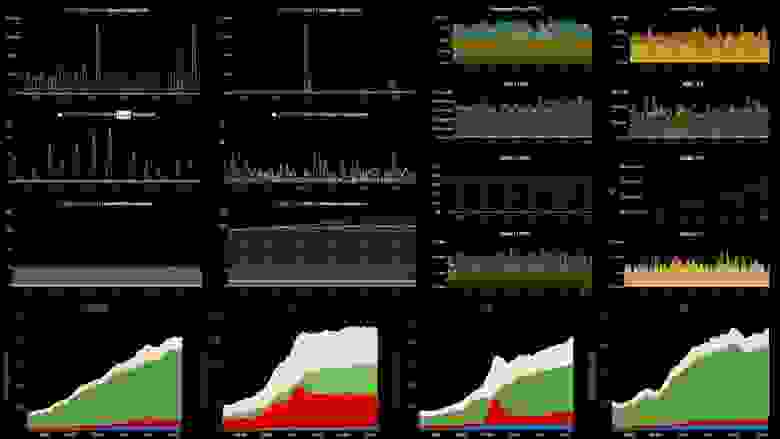
С левой стороны – 6 графиков, это соответственно по линиям – количество воркеров и количество сообщений в очередях. С правой стороны – RPS, RTS. Снизу – та самая метрика «бизнесовая». И на «бизнесовой» метрике у нас сразу видно, что что-то пошло не так на двух средних графиках… Это как раз упала очередная система, которая стоит за нами.
Второе, что нам надо было сделать – это следить за падением внешних платёжных систем. Здесь мы взяли OpenTracing – механизм, стандарт, парадигма, которая позволяет трассировать распределённые системы; и его немножко изменили. Стандартная OpenTracing-парадигма говорит о том, что мы строим трассировку каждого отдельного запроса. Нам это было не надо, и мы это завернули в трассировку суммарную, агрегационную. Сделали инструмент, который нам позволяет отслеживать скорость систем, стоящих за нами.

График показывает нам, что одна из платёжных систем стала отвечать за 3 секунды – у нас появились проблемы. При этом эта штука среагирует, когда проблемы начались, на интервале в 20-30 секунд.
И третий класс ошибок мониторинга, которые есть – это мониторинг логический.
Честно говоря, не знал, что на этом слайде нарисовать, потому что мы искали долго на рынке то, что нам подойдёт. Ничего не нашли, поэтому пришлось делать самим.

Что я подразумеваю под мониторингом логическим? Ну, представьте себе: вы делаете себе систему (например, клон «Тиндера»); вы её сделали, запустили. Успешный менеджер Вася Пупкин поставил её себе на телефон, видит там девушку, лайкает её… а лайк уходит не девушке – лайк уходит охраннику Михалычу из этого же бизнес-центра. Менеджер спускается вниз, а потом недоумевает: «А почему этот охранник Михалыч ему так приятно улыбается»?
В таких ситуациях… Для нас эта ситуация звучит немного по-разному, потому что (я писал) это такая репутационная потеря, которая косвенно ведёт к потерям финансовым. У нас ситуация обратная: мы прямые финансовые потери может понести – например, если мы провели транзакцию как успешную, а она была неуспешной (или наоборот). Пришлось написать собственный инструмент, который отслеживает по бизнес-показателям количество успешных транзакций в динамике на временном интервале. Не нашли ничего на рынке! Я именно эту мысль хотел донести. Для решения такого рода задач на рынке ничего нет.
Это было к вопросу о том, как быстро выявить проблему.
Как определить причины деплоя
Третья группа задач, которые мы решаем – это после того, как мы проблему выявили, после того, как мы от неё избавились, хорошо бы понять причину для разработки, для тестирования и что-то с этим сделать. Соответственно, нам надо исследовать, надо поднять логи.

Если мы говорим про логи (основная причина – логи), основная часть логов у нас в ELK Stack – практически у всех так. У кого-то, можем, не в ELK, но если вы пишите логи гигабайтами, то рано или поздно придёте к ELK. Мы пишем их терабайтами.

Здесь есть проблема. Мы пофиксили, исправили для пользователя ошибку, начали раскапывать, что же там было такое, залезли в «Кибану», ввели там id-шник транзакции и получили вот такую портянку (показывает много). И в этой портянке непонятно ничего ровным счётом. Почему? Да потому что непонятно, какая часть относится к какому воркеру, какая часть относится к какому компоненту. И в этот момент мы поняли, что нам нужна трассировка – та самая OpenTracing, о которой я говорил.
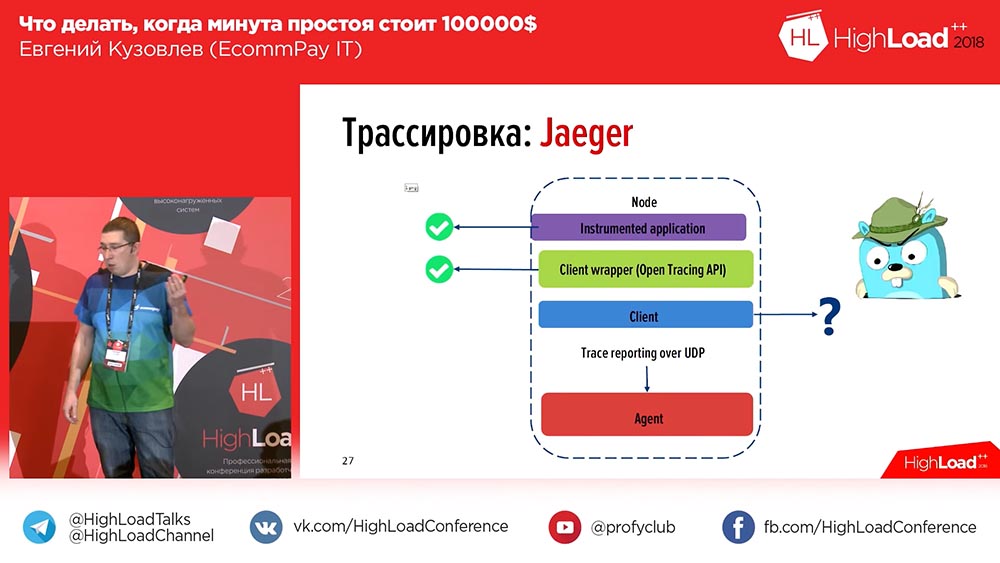
Подумали мы это год назад, обратили свой взор в сторону рынка, и там оказалось два инструмента – это «Зипкин» (Zipkin) и «Егерь» (Jaeger). «Егерь» – это по факту такой идеологический наследник, идеологический продолжатель «Зипкина». В «Зипкине» всё хороше, кроме того, что он не умеет агрегировать, не умеет включать в трассировку логи, только трассировку времени. А «Егерь» это поддерживал.
Посмотрели на «Егеря»: можно инструментировать приложения, можно писать в Api (стандарт Api для PHP на тот момент, правда, не был утверждён – это год назад, а сейчас уже утверждён), о абсолютно не было клиента. «Окей», – подумали мы, и написали собственный клиент. Что у нас получилось? Вот примерно так это выглядит:
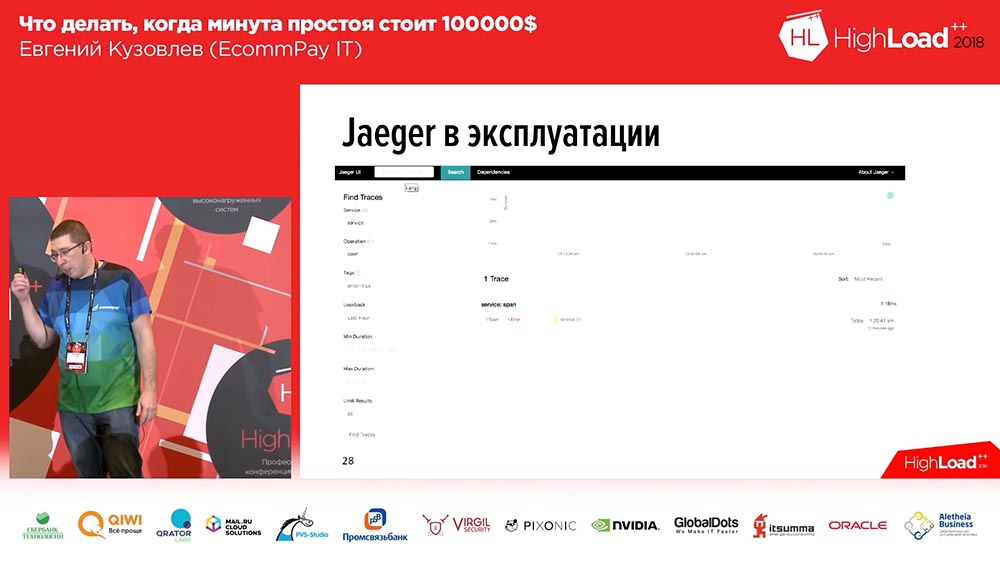
В «Егере» на каждое сообщение создаются span’ы. То есть, когда пользователь открывает систему, он видит один или два блока на каждый входящий запрос (1-2-3 – сколько входящих запросов от пользователя было, столько и блоков). Для того чтобы пользователям было легче, к логам и временной трассировке мы добавили теги. Соответственно, в случае ошибки наше приложение промаркирует лог соответствующим тегом Error. Можно отфильтровать по тегу Error и выведутся только спаны, которые содержат этот блок с ошибкой. Вот как это выглядит, если мы развернём span:

Внутри спана есть набор трейсов. В данном случае это три тестовых трейса, и третий трейс говорит нам о том, что произошла ошибка. При этом здесь же мы видим временную трассировку: у нас сверху – временная шкала, и мы видим, на каком временном интервале у нас тот или иной лог был записан.
Соответственно, у нас зашло отлично. Мы написали собственное расширение, и мы его заопенсорсили. Если вы захотите работать с трассировкой, если вы захотите работать с «Егерем» на языке PHP – есть наше расширение, welcome to use, как говорится:
У нас это расширение – это клиент для работы OpenTracing Api, сделано как php-extention, то есть вам его надо будет собрать и подложить систему. Год назад не было ничего другого. Сейчас появились ещё другие клиенты, которые как компоненты. Здесь дело ваше: либо вы композером выкачиваете компоненты, либо вы используете extention up to you.
Корпоративные стандарты
Про три заповеди поговорили. Четвёртая заповедь – это стандартизировать подходы. Про что это? Это примерно про это:

Почему здесь слово «корпоративные»? Не потому что мы большая или бюрократическая компания, нет! Слово «корпоративная» я здесь хотел употребить в контексте того, что у каждой компании, у каждого продукта эти стандарты должны быть свои, и у вас в том числе. Какие стандарты есть у нас?

- У нас есть регламент деплоеев. Мы без него никуда не движемся, не можем. Деплоимся мы порядка 60 раз в неделю, то есть у нас деплои происходят практически постоянно. При этом у нас есть, например, в регламенте деплоеев табу на деплои в пятницу – принципе, мы не деплоимся.
- У нас обязательна документация. Ни один новый компонент у нас не попадает в прод, если на него нет документации, даже если это рождено под пером наших RnD-шников. Мы требуем от них инструкцию по деплою, карту мониторинга и примерное описание (ну, как программисты могут написать) того, как этот компонент работает, как его траблшутить.
- Мы решаем не причину проблемы, а проблему – то, о чём я уже говорил. Для нас важно оградить пользователя от проблем.
- У нас есть допуски. Например, мы не считаем даунтаймом, если мы на протяжении двух минут потеряли 2 % трафика. Это в принципе не попадает в нашу статистику. Если больше в процентном соотношении или временном, мы уже считаем.
- И мы всегда пишем постмортемы. Чтобы у нас ни случилось, любая ситуация, когда повела себя не штатно на продакшне, она будет отражена в потсмортеме. Постмортем – это документ, в котором вы пишите, что у вас произошло, подробный тайминг, что вы сделали для исправления и (это обязательный блок!) что вы сделаете, чтобы такого не допустить в будущем. Это обязательно, необходимо для последующего анализа.
Что считать даунтаймом?

К чему это всё привело?
Это привело к тому, что (у нас были определённые проблемы со стабильностью, это не устраивало ни клиентов, ни нас) за последние 6 месяцев наш показатель стабильности составил 99,97. Можно сказать, что это не очень много. Да, нам есть к чему стремиться. Из этого показателя примерно половина – это стабильность как бы не наша, а нашего web application firewall, который перед нами стоит и используется как сервис, но клиентам на это всё равно.
Мы научились спать по ночам. Наконец-то! Полгода назад мы не умели. И на этой ноте с итогами мне хочется сделать одну ремарочку. Вчера вечером был замечательный доклад про систему управления ядерным реактором. Если меня слышат люди, которые писали эту систему – пожалуйста, забудьте о том, что я говорил про «2% – это не даунтайм». Для вас 2% — это даунтайм, даже если на две минуты"!
На это всё! Ваши вопросы.

О балансировщиках и миграции из базы данных
Вопрос из аудитории (далее – В): – Добрый вечер. Спасибо большое за такой админский доклад! Вопрос коротенький, на тему ваших балансировщиков. Вы обмолвились, что у вас есть WAF, то есть, как я понимаю в качестве балансировщика вы используете какой-то внешний…
ЕК: – Нет, в качестве балансировщика мы используем свои сервисы. В данном случае WAF является для нас исключительно инструментом защиты от DDoS.
В: – А можно пару слов о балансировщиках?
ЕК: – Как я уже сказал, это группа серверов в openresty. Их у нас сейчас 5 групп резервированных, которые отвечают исключительно… то есть сервер, на котором стоит исключительно openresty, он только проксирует трафик. Соответственно, для понимания, сколько мы держим: у нас сейчас штатный поток трафика – это несколько сотен мегабит. Они справляются, им хорошо, даже не напрягаются.
В: – Тоже простой вопрос. Вот есть Blue/Green deployment. А что вы делаете, например, с миграциями из базы данных?
ЕК: – Хороший вопрос! Смотрите, мы в Blue/Green deployment’е у нас есть отдельные очереди на каждую линию. То есть, если мы говорим об очередях событий, которые передаются от воркера к воркеру, там отдельные очереди на blue-линию и на green-линию. Если мы говорим о самой базе данных, то мы нарочно её сузили, как могли, переложили всё практически в очереди, в базе данных у нас только стэк транзакций хранится. И стэк транзакций у нас един для всех линий. С базой данных в данном контексте: мы её на blue и green не разделяем, потому что оба варианта кода должны знать, что происходит с транзакцией.
Друзья, у меня есть ещё такой маленький приз, чтобы вас подстегнуть – книжка. И мне её нужно вручить за самый лучший вопрос.
В: – Здравствуйте. Спасибо за доклад. Вопрос такой. Вы мониторите платежи, вы мониторите сервисы, с которыми вы общаетесь… Но как вы мониторите так, что человек каким-то образом пришёл на вашу платёжную страницу, выполнил оплату, а проект ему зачислил деньги? То есть как вы мониторите то, что marchant доступен и принял ваш callback?
ЕК: – «Мерчант» для нас в данном случае является точно таким же внешним сервисом, как и платёжная система. Мы мониторим скорость ответа «мерчанта».
О шифровании базы данных
В: – Здравствуйте. У меня чуть-чуть рядом вопрос. У вас чувствительные данные по PCI DSS. Хотел узнать, как вы в очередях храните PAN’ы, в которые вам необходимо прокидывать? Используете ли какое шифрование? И отсюда вытекающий второй вопрос: по PCI DSS необходимо периодически перешифровывать базу в случае изменений (увольнение админов и так далее) – как в этом случае происходит с доступностью?

ЕК: – Замечательный вопрос! Во-первых, мы в очередях не храним PAN’ы. Мы не имеем права хранить PAN где-либо в открытом виде, в принципе, поэтому мы используем специальный сервис (мы его называем «Кейдемон») – это сервис, который делает только одно: он принимает на вход сообщение и отдаёт сообщение зашифрованное. И мы этим зашифрованным сообщением всё и храним. Соответственно, длина ключа у нас под килобайт, чтобы это было прям серьёзно и надёжно.
В: – Сейчас уже 2 килобайта надо?
ЕК: – Вроде ещё вчера было 256… Ну куда ещё?!
Соответственно, это первое. А во-вторых, решение, которое есть, оно поддерживает процедуру перешифровки – там две пары «кеков» (ключей), которые дают «деки», которые зашифровывают (key – это ключи, dek – это производные от ключей, которые зашифровывают). И в случае инициации процедуры (проходит регулярно, от 3 месяцев до ± каких-то) мы загружаем новую пару «кеков», и у нас происходит перешифровка данных. У нас есть отдельные сервисы, которые все данные выдирают, шифруют по-новому; у данных рядом хранится идентификатор ключа, которым они зашифрованы. Соответственно, как только мы данные шифрованы новыми ключами, мы старые ключ удаляем.
Иногда платежи нужно проводить вручную…
В: – То есть если пришёл возврат по какой-то операции, то расшифруете пока старым ключом?
ЕК: – Да.
В: – Тогда ещё один маленький вопрос. Когда происходит какой-то сбой, падение, инцидент, то необходимо протолкнуть транзакцию в ручном режиме. Бывает такая ситуация.
ЕК: – Да, бывает.
В: – Откуда вы берёте эти данные? Или вы сами ходите ручками в это хранилище?
ЕК: – Нет, ну понятное дело – у нас есть некая бэк-офис-система, которая содержит интерфейс для нашего саппорта. Если мы не знаем, в каком статусе транзакция (например, пока платёжная система таймаутом не ответила) – мы априори не знаем, то есть мы финальный статус присваиваем только при полной уверенности. В этом случае мы транзакцию сваливаем в специальный статус на ручную обработку. С утра, на следующий день, как только саппорт получает информацию, что в платёжной системе остались такие-то транзакции, они вручную их обрабатывают в этом интерфейсе.

В: – У меня пара вопросов. Один из них – продолжение зоны PCI DSS: как вы выносите логи их контура? Такой вопрос потому, что разработчик в логи мог положить что угодно! Второй вопрос: как вы выкатываете хотфиксы? Ручками в базе – это один вариант, но могут быть free hot-fix’ы – какая там процедура? И третий вопрос, наверное, связан с RTO, RPO. У вас доступность была 99,97, почти четыре девятки, но я так понимаю, что у вас и второй дата-центр, и третий дата-центр, и пятый дата-центр… Как вы занимаетесь их синхронизацией, репликацией, всем остальным?
ЕК: – Давайте начнём с первого. Первый вопрос про логи был? У нас, когда пишутся логи, стоит прослойка, которая все сенситивные данные маскирует. Она по маске смотрит и по дополнительным полям. Соответственно, у нас логи выходят с уже замаскированными данными и контуром PCI DSS. Это одна из регулярных задач, которая вменена отделу тестирования. Они обязаны каждую задачу проверять в том числе на те логи, которые они пишут, и это – одна из регулярных задач при код-ревью, для того чтобы контролировать, что разработчик что-то не записал. Последующая проверка этого осуществляется регулярно отделом информационной безопасности примерно раз в неделю: выборочно берутся логи за последний день, и они прогоняются через специальный сканер-анализатор с тестовых серверов, чтобы проверять это всё.
Про hot-fix’ы. Это включено у нас в регламент деплоев. У нас отдельно вынесен пункт про хотфиксы. Мы считаем, что мы хотфиксы деплоим круглосуточно тогда, когда нам это надо. Как только версия собрана, как только она прогнана, как только у нас есть артефакт – у нас поднимается дежурный системный администратор по звонку из саппорта, и он деплоит это в тот момент, когда это необходимо.
Про «четыре девятки». Та цифра, которая у нас сейчас есть, по-настоящему она была достигнута, и мы к ней стремились ещё на одном дата-центре. Сейчас у нас появился второй дата-центр, и мы начинаем роутить между ними, и вопрос кросса дата-центр репликации – это действительно вопрос нетривиальный. Мы пытались решить его в своё время разными средствами: пытались использовать тот же «Тарантул» – у нас не зашло, сразу говорю. Поэтому мы пришли к тому, что делаем заказ «сенса» вручную. У нас каждое приложение по факту в асинхронном режиме необходимой синхронизации «change – done» гоняет между дата-центрами.
В: – Если у вас появился второй, то почему не появился третий? Потому что Split-brain ещё никто…
ЕК: – А у нас нет «Сплит-брейна». Из-за того, что каждое приложение у нас гоняет мультимастер, нам не важно, в какой центр пришёл запрос. Мы готовы к тому, что, в случае, если у нас один дата-центр упал (мы на это закладываемся) и в середине запроса пользователя переключил на второй дата-центр, мы готовы потерять этого пользователя, действительно; но это единицы будут, абсолютные единицы.
В: – Добрый вечер. Спасибо за доклад. Вы рассказывали про свой дебаггер, который в продакшне гоняет некие тестовые транзакции. А вот расскажите про тестовые транзакции! Как глубоко оно уходит?
ЕК: – Оно проходит полный цикл всего компонента. Для компонента нет различий между тестовой транзакцией и боевой. А с точки зрения логики это просто некий отдельный проект в системе, на котором только тестовые транзакции гоняются.
В: – А где вы её отсекаете? Вот Core отправил…
ЕК: – Мы за «Кором» в данном случае для тестовых транзакций… У нас есть такое понятие, как роутинг: «Кор» знает в какую платёжную систему надо отправить – мы отправляем в фейковую платёжную систему, которая просто http-отбивку даёт и всё.
В: – Скажите, пожалуйста, а у вас приложение написано одним огромным монолитом, или вы резали его на какие-то сервисы или даже микросервисы?
ЕК: – У нас не монолит, конечно, у нас сервис-ориентированное приложение. У нас шутка, что у нас сервис из монолитов – они действительно достаточно большие. Микросервисами назвать это язык не поворачивается от слова совсем, но это именно сервисы, внутри которых работают воркеры распределённых машин.
Если сервис на сервере скомпрометирован…
В: – Тогда у меня следующий вопрос. Даже если бы это был монолит, вы всё равно сказали, что у вас есть много этих instant-серверов, все они в принципе обрабатывают данные, и вопрос такой: «В случае компрометации одного из instant-серверов либо приложения, какого-либо отдельного звена, у них есть какой-то контроль доступа? Кто из них что может делать? К кому обращаться, за какими данными?

ЕК: – Да, несомненно. Требования безопасности достаточно серьёзные. Во-первых, у нас открытые движения данных, и порты только те, по которым мы заранее предполагаем движение трафика. Если компонент общается с базой данных (скажем, с «Муськулем») по 5-4-3-2, ему будут открыты только 5-4-3-2, и другие порты, другие направления движения трафика не будут доступны. Кроме этого надо понимать, что у нас в продакшне существует около 10 различных контуров безопасности. И даже если скомпрометировано было приложение каким-то образом, не дай бог, то злоумышленник не сможет получить доступ к консоли управления сервером, потому что это другая сетевая зона безопасности.
В: – А мне в данном контексте больше интересен момент, что у вас же есть некие контракты с сервисами – что они могут делать, через какие «экшны» они могут обращаться друг к другу… И в нормальном flow какие-то определённые сервисы запрашивают какой-то ряд, перечень «экшнов» на другом. К другим они как бы не обращаются в нормальной ситуации, и другие зоны ответственности у них. Если же один из них будет компрометирован, сможет ли он дёрнуть «экшны» того сервиса?..
ЕК: – Я понимаю. Если в нормальной ситуации с другим сервером коммуникация вообще была разрешена, то – да. По SLA-контракту мы не мониторим, что тебе разрешены только первые 3 «экшна», а 4 «экшна» тебе не разрешены. Это, наверное, для нас избыточно, потому что у нас итак 4-уровневая система защиты в принципе для контуров. Мы предпочитаем защищаться контурами, а не на уровне внутренностей.
Как работают Visa, MasterCard и «Сбербанк»
В: – Я хочу уточнить момент по поводу переключения пользователя с одного дата-центра на другой. Насколько я знаю, «Виза» и «МастерКард» работают по бинарному синхронному протоколу 8583, там стоят миксы. И хотел узнать, сейчас имеется в виду переключение – это непосредственно «Виза» и «МастерКард» или до платёжных систем, до процессингов?
ЕК: – Это до миксов. Миксы у нас стоят в одном дата-центре.
В: – Грубо говоря, у вас одна точка подключения?
ЕК: – «Визе» и «МастерКарду» – да. Просто потому, что «Виза» и «МастерКард» требуют достаточно серьёзных вложений в инфраструктуру для заключения отдельных контрактов для получения второй пары миксов, например. Они резервированы в рамках одного дата-центра, но если у нас, не дай бог, сдохнет дата-центр, где стоят миксы для подключения к «Визе» и «МастерКард», то связь с «Визой» и «МастерКард» у нас будет потеряна…
В: – Как они могут быть резервированы? Я знаю, что «Виза» разрешает только один коннект держать в принципе!
ЕК: – Они сами поставляют оборудование. Во всяком случае, нам пришло оборудование, которое внутри железно резервировано.
В: – То есть стойка от их Connects Orange?..
ЕК: – Да.
В: – А вот как в этом случае: если у вас дата-центр пропадает, еак дальше использовать? Или просто трафик останавливается?
ЕК: – Нет. Мы в этом случае просто переключим трафик на другой канал, который, естественно, будет дороже нам, дороже клиентам. Но трафик пойдёт не через наше прямое подключение к «Визе», «МастерКарду», а через условный «Сбербанк» (очень утрированно).
Я дико извиняюсь, если я задел сотрудников «Сбербанка». Но по нашей статистике из российских банков «Сбербанк» падает чаще всего. Не проходит месяца, чтобы у «Сбербанка» что-нибудь не отвалилось.

Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?