Тема анализа данных и Data Science в наши дни развивается с поразительной скоростью. Для того, чтобы понимать актуальность своих методов и подходов, необходимо быть в курсе работ коллег, и именно на конференциях удается получить информацию о трендах современности. К сожалению, не все мероприятия можно посетить, поэтому статьи о прошедших конференциях представляют интерес для специалистов, не нашедших времени и возможности для личного присутствия. Мы рады представить вам перевод статьи Чип Хен (Chip Huyen) о конференции ICLR 2019, посвященной передовым веяниям и подходам в области Data Science.

Learning Representations (обучение представлениям) — это набор методов, техник и подходов, позволяющих в автоматическом режиме обнаружить представления, необходимые для выявления признаков из сырых данных. Обучение представлениям заменяет ручное изобретение признаков и позволяет как изучать ключевые свойства объектов по их признакам, так и использовать их для решения специфичных задач.
В статье дан субъективный взгляд на ряд проблем отрасли. Однако хочется надеяться, что даже субъективный обзор даст достаточно пищи для размышлений интересующемуся специалисту. Далее речь пойдет о следующем:
Детальный обзор конференции от Чип Хен можно найти ниже.
Организаторы [International Conference on Learning Representations 2019 — ред.] подчеркнули важность инклюзивности в области искусственного интеллекта. Первые два основных доклада — вступительное слово Александра Раша и приглашенного докладчика Синтии Дворк — были посвящены справедливости и равенству.
Несколько тревожных статистических данных ICLR 2019:

К сожалению [автора женского пола], основная часть исследователей искусственного интеллекта совершенно не интересуется вопросом равенства. Если семинары по остальным тематикам были переполнены, то мастерская ИИ для социального блага была довольно пустой, пока не появился Йошуа Бенжио. Во время многочисленных бесед, проведенных мной на ICLR, никто не упоминал о «diversity». Исключением стал один случай: меня пригласили на неподходящее мне техническое мероприятие, чему я громко удивилась, и мой хороший друг ответил: «Немного оскорбительный ответ: тебя пригласили, потому что ты — женщина».
Причина наблюдаемого положения дел в том, что тема diversity не является «технической», и поэтому не поможет в продвижении научной карьеры. Другая причина заключается в том, что существует отторжение социальной-общественной пропаганды. Один мой друг однажды посоветовал мне не обращать внимание на чувака, который троллил меня в групповом чате, потому что «ему нравится высмеивать людей, которые говорят о равенстве и разнообразии». У меня есть друзья, которые не любят обсуждать вопрос diversity в Интернете, потому что не хотят быть «ассоциированными с этой темой».
Основная цель обучения представлениям без учителя (Unsupervised Representation learning) — обнаружение признаков в неразмеченных данных, полезных для использования в последующих задачах. В области Natural Language Processing обучение представлениям часто производится с помощью языкового моделирования. Полученные представления затем используются для таких задач, как анализ эмоциональной окраски (sentiment analysis), распознавание имен (name entity recognition) и машинный перевод (machine translation).
Некоторые из наиболее интересных работ прошлого года по обучению представлениям без учителя начинаются с ELMo (Peters et al.), ULMFiT (Howard et al.), GPT OpenAI (Radford et al.), BERT. (Devlin et al.) И, конечно, в высшей степени опасный GPT-2 (Radford et al.).
Полная модель GPT-2 была продемонстрирована на ICLR, и она восхитительна. Вы можете ввести произвольный набросок начала текста, а модель напишет остальную часть статьи. Модель может писать новостные статьи, фанфики, научные статьи, даже определения выдуманных слов. Пока что результат все еще смотрится не по-человечески, однако команда усердно трудится над GPT-3. Я жду с нетерпением возможности посмотреть на способности новой модели.
Подход transfer learning был в первую очередь взят на вооружение сообществом специалистов по компьютерному зрению. Однако обучение модели классификации на картинках ImageNet все еще происходит в режиме обучения с учителем. Вопрос, который постоянно можно услышать от представителей обоих сообществ, звучит так: «Как бы нам использовать обучение представлениям без учителя в работе с изображениями?»
Хотя большинство известных исследовательских лабораторий уже работают над этой задачей, на ICLR была представлена только одна статья «Обновление правил мета-обучения для обучения представлениям без учителя» (Metz et al.). Вместо обновления весов алгоритм обновляет правило обучения (learning rule). Представления, полученные из learning rule, затем доводятся на небольшой выборке размеченных данных в режиме классификации изображений. Исследователи смогли найти learning rules, которые позволили достичь точности (accuracy) более 70% на MNIST и Fashion MNIST.
Авторы открыли часть кода, но не весь, потому что «он привязан к вычислениям». Внешний цикл требует около 100 тыс. шагов обучения и 200 часов на 256 процессорах.

У меня есть ощущение, что в ближайшем будущем мы увидим еще много подобных работ. Использовать обучение без учителя возможно в таких задачах, как автокодирование, прогнозирование поворота изображения (документ Gidaris et al. был хитом на ICLR 2018), прогнозирование следующего кадра в видео и др.
Идеи в машинном обучении подобны моде: они цикличны. Просмотреть сессию постеров сейчас все равно что прогуляться по историческому музею. Даже долгожданные дебаты на ICLR закончились тем, что спор пришел к вопросу «priors vs structure», что возвращает к дискуссии Янна ЛеКуна и Кристофера Мэннинга в прошлом году и напоминает вековые дебаты между сторонниками Байесовой теории и сторонниками фреквентистского (частотного) подхода к вероятностям.
Проект «Grounded Language Learning and Understanding» в MIT Media Lab был прекращен в 2001 году, но в этом году Grounded Language Learning представило две работы, завернутые в обложку «обучение с подкреплением».
Мои мысли об этих двух статьях отлично обобщил AnonReviewer4:
DFA (Deterministic Finite Automata) также нашли свое место в мире глубокого обучения в этом году в двух статьях:
Основная мотивация обеих работ состоит в следующем: в связи с огромным пространством скрытых состояний в RNNs можно ли сократить число состояний до конечного? Я скептически отношусь к тому, что DFA сможет эффективно представлять RNN в языковых задачах, но мне нравится идея обучения RNN в процессе тренировки, а затем преобразования его в DFA для логических выводов, как это представлено в статье Koul et al. Итоговые конечные представления требуют для игры в понг всего трех дискретных состояний памяти и 10 наблюдений. DFA также помогает в интерпретации RNN.

При рассмотрении графика прироста статей по различным тематикам в 2019 году относительно 2018 года становится понятно, что RNN характеризуется наибольшим падением. Это не удивительно, потому что, даже если использование RNNs интуитивно понятны для последовательных типов данных, они страдают от серьезного недостатка: их нельзя распараллелить. Следственно, не получается воспользоваться преимуществом самого важного фактора, стимулирующего прогресс в исследованиях с 2012 года: вычислительной мощностью. RNN никогда не были популярны в CV или RL, а для NLP их заменяют архитектуры, основанные на Attention.
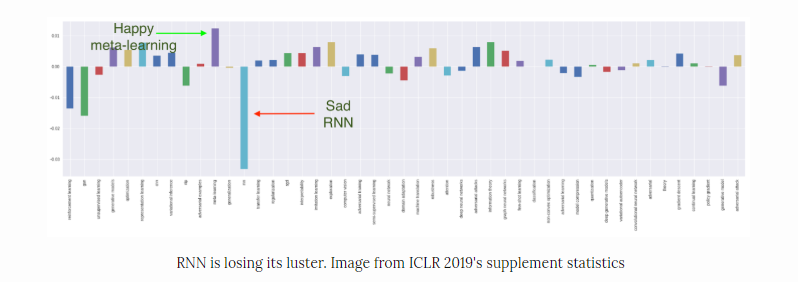
Значит ли это, что RNN мертв? На самом деле, нет. Статья «Ordered neurons: Integrating tree structures into Recurrent Neural Networks» (Shen et al.). получила одну из высших наград в этом году. Помимо этой и двух упомянутых выше статей об автоматах, в этом году рассмотрено еще девять работ по RNN, большинство из которых углубляются в математические основы, а не открывают новые возможности.
RNNs остаются полными жизни и являются драйверами в отрасли, особенно для компаний, имеющих дело с временными рядами, такими, как торговые фирмы. К сожалению, торговые фирмы обычно не публикуют детали своей работы. Даже если RNN сейчас мало привлекают исследователей, они могут вернуть свою популярность в будущем.
Несмотря на то, что тематика GAN в относительной шкале по сравнению с прошлым годом показывает отрицательный рост, в абсолютной шкале количество работ возросло с ~70 до ~100. Йен Гудфеллоу выступал с докладом о GAN и был всё время окружен поклонниками. В последний день ему пришлось перевернуть свой бейджик, чтобы люди не могли видеть его имя.
Вся первая постерная сессия была посвящена GAN. Появились новые архитектуры GAN, улучшения старой архитектуры GAN, анализ GAN, приложения GAN от генерации изображений до генерации текста и синтеза аудио. Существуют PATE-GAN, GANSynth, ProbGAN, InstaGAN, RelGAN, MisGAN, SPIGAN, LayoutGAN, KnockoffGAN и т. д. и я понятия не имею, что это значит. К сожалению, Эндрю Брок назвал свою гигантскую модель BigGAN, а не giGANtic :)

Постерная сессия продемонстрировала, насколько предвзято сообщество, когда речь заходит о GAN. Некоторые из комментариев, которые я слышала от противников GAN, выглядели так: «Я не могу дождаться, когда вся эта шумиха с GAN затихнет», «Когда кто-то упоминает термин «adversarial», мой мозг просто отключается». На мой взгляд, они просто завидуют.
Учитывая большой ажиотаж, вызванный у публики определением последовательности генов в ДНК, а также появлением модифицированных детей с помощью технологии CRISPR, [мне] показалось удивительным, что на ICLR нет прироста работ по применению глубокого обучения в биологии. Всего по теме было шесть статей.
Две – по вопросам архитектур заимствованных из биологии:
Одна работа по обучению проектированию РНА (Рунге и др.).
Три работы по манипуляциям с белком:

По теме геномов не было ни одной статьи, а также не проводилось семинаров. Как бы печально это не выглядело, однако для исследователей глубокого обучения в биологии и биологов в области глубокого обучения открываются огромные возможности.
Один из фактов: Джек Линдси, первый автор упомянутой выше статьи о сечатке, еще не окончил Стэнфордский колледж.
Представленные на конференции работы демонстрируют, что сообщество RL переходит от model-free-методов к model-based-алгоритмам с эффективным сэмплированием и алгоритмам на основе meta-learning. Сдвиг, вероятно, был обусловлен чрезвычайно высокими результатами на Mujoco бенчмарках, установленными TD3 (Fujimoto et al., 2018) и SAC (Haarnoja et al., 2018), а также на дискретном пространстве операций в Atari, установленным R2D2 (Kapturowski et al., ICLR 2019).
Model-based-алгоритмы в процессе обучения на имеющихся данных получают модель окружающей среды и используют ее для планирования стратегии агентов в этой среде или для генерации новых данных. Model-based-алгоритмы наконец достигли асимптотической точности своих model-free аналогов, используя в 10-100 раз меньше данных (MB-MPO (Rothfuss et al.)). Новое преимущество делает model-based методы пригодными для задач реального уровня сложности. Если после тренировки симулятор среды будет обладать изъянами, что весьма вероятно, то его недостатки могут быть нивелированы при использовании более сложных моделей, таких, как ансамбль симуляторов (Rajeswaran et al.). Другой способ применения RL в решении задач реального уровня сложности — позволить симулятору поддерживать сложные схемы рандомизации. Полученная на разнообразных симуляторах окружающей среды стратегия может рассматривать реальный мир как «еще одну рандомизацию» и способна добиться успеха в задачах реального уровня сложности (OpenAI).
Алгоритмы мета-обучения, позволяющие получить быстрый learning transfer на новые задачи, также были усовершенствованы как с точки зрения производительности, так и с точки зрения эффективности выборки (ProMP (Rothfuss et al.), PEARL (Rakelly et al.)). Эти улучшения приблизили нас к «моменту ImageNet для RL», в котором мы сможем использовать извлеченные из других задач стратегии принятия решений, вместо того, чтобы обучать их с нуля (что невозможно для сложных задач).

Внушительная часть принятых работ вкупе с семинаром по структуре и априорной вероятности в RL были посвящены интеграции знаний об окружающей среде в алгоритмы обучения. Если одной из основных сильных сторон ранних алгоритмов глубокого RL была обобщенность (например, DQN использует одну и ту же архитектуру для всех игр Atari, ничего не зная о какой-либо конкретной игре), то сейчас новые алгоритмы используют интеграцию априорных знаний для решения более сложных задач. Например, в Transporter Network (Jakab et al.) агент использует априорные знания для проведения более информативной поисково-разведочной работы.
Подводя итог, можно сказать, что за последние 5 лет сообщество RL разработало множество эффективных инструментов для решения проблем обучения с подкреплением в model-free-режиме. Теперь пришло время придумать более транспортабельные и эффективные по выборке алгоритмы с целью применения RL к реальным задачам.
Один из фактов: Сергей Левин, вероятно, является человеком с наибольшим количеством работ на ICLR в этом году, в частности, к публикации принято 15 его статей.
Когда я спросила известного исследователя, что он думает о принятых работах в этом году, он посмеивался: «Большинство из них будут забыты, как только конференция закончится». В такой быстро развивающейся области, как машинное обучение достигнутые результаты опровергаются через недели, если не дни. Не удивительно, что большинство принятых работ уже устаревают к моменту представления. Например, согласно данным Borealis AI для ICLR 2018, "семь из восьми статей на тему защиты от adversarial атаки были опровергнуты еще до начала конференции ICLR. Это показывает, что эвристические методы без какой-либо теоретической основы далеко не так надежны, как могут казаться."
Я часто слышала во время конференции комментарии, отмечающие ощутимый вклад случайности в решении о принятии/отклонении работы. Я не буду называть конкретные статьи, однако некоторые из наиболее обсуждаемых и наиболее цитируемых работ за последние несколько лет были отклонены конференциями при первой отправке. Тем не менее, многие из принятых работ будут актуальны годами, даже не цитируясь.
Как человек, занимающийся исследованиями в этой области, я часто сталкиваюсь с экзистенциальным кризисом. Какая бы идея ко мне ни пришла, кажется, что кто-то другой уже реализует это, при том лучше и быстрее. Какой смысл публиковать статью, если она никогда никому не понадобится?
Конечно, есть еще тенденции, которые я хотела бы охватить.
Однако этот пост затягивается, а мне нужно вернуться к работе. Если вы хотите узнать больше, Дэвид Абель опубликовал свои подробные заметки (55 страниц). Я считаю особенно показательным приведенный ниже график из прикладной статистики ICLR 2019 для тех, кто хочет узнать, что еще любопытного было на конференции.
Самые ожидаемые слова в заголовках

Мне действительно понравилась ICLR. Конференция достаточно объемная, чтобы встретить множество людей и поучаствовать в интересных беседах, но при этом достаточно небольшая, чтобы не ждать в очереди. Продолжительность четырехдневной конференции тоже в самый раз. NeurIPS слишком долгая, и обычно к концу четвертого дня я брожу между постерами и думаю: «Посмотрите на все те замечательные знания, которые я могла бы получить прямо сейчас, но не хочу».
Самый большой трофей, который я привезла с конференции, — это не только идеи, но и мотивация. Наблюдая за исследователями моего возраста, делающими замечательные вещи, я получаю возможность различить красоту исследовательской работы и мотивацию усердно работать. Также приятно располагать целой неделей на то, чтобы наверстать упущенное в статьях и в общении со старыми друзьями. 10 из 10, я бы порекомендовала [ICLR — ред.].
Этот пост не отражает точку зрения какой-либо организации, с которой я связана, и, вероятно, приправлен моими личными и институциональными предубеждениями. Раздел «Подкрепленное обучение» был написан моим замечательным стажером и коллегой Олексием Гринчуком (Oleksii Hrinchuk)
На этом заканчивается оригинальная статья. Со стороны сотрудников нашей компании CleverDATA хочется согласиться с автором в том, что конференции по машинному обучению действительно дают мотивацию для дальнейших работ, позволяют сравнить свои результаты и получить профессиональную обратную связь от коллег. Участие в подобных мероприятиях необходимо для профессионального роста. Скорость развития Data Science растет, работы устаревают еще до момента их презентаций на конференции, а большая часть работ оказывается забытой после завершения конференции. Нужно бежать со всех ног, чтобы только оставаться на месте, а чтобы куда-то попасть, надо бежать как минимум вдвое быстрее!

Learning Representations (обучение представлениям) — это набор методов, техник и подходов, позволяющих в автоматическом режиме обнаружить представления, необходимые для выявления признаков из сырых данных. Обучение представлениям заменяет ручное изобретение признаков и позволяет как изучать ключевые свойства объектов по их признакам, так и использовать их для решения специфичных задач.
В статье дан субъективный взгляд на ряд проблем отрасли. Однако хочется надеяться, что даже субъективный обзор даст достаточно пищи для размышлений интересующемуся специалисту. Далее речь пойдет о следующем:
- Искусственные методы коррекции социально-демографического состава конференции вызывают спектр чувств у сообщества: от агрессивного негодования до трусливого игнорирования. Выбор оптимального поведения в такой среде был бы интересной задачей для специалиста по теории игр.
- Работы в областях Representation learning и transfer learning находятся на взлете популярности и вызывают активный интерес со стороны сообщества.
- Рекуррентные нейронные сети продолжают терять популярность среди исследователей, однако на практике от них еще не скоро откажутся.
- Область GAN-ов продолжает бурно развиваться, пусть этот факт и не всем исследователям нравится. Потенциал GAN-ов только раскрывается и можно ожидать в ближайшее время ряд интересных работ в этом направлении.
- Обучение с подкреплением продолжает будоражить умы исследователей, оставаясь самой популярной темой на конференции. Специалисты становятся все ближе к возможности применения методов RL к реальным задачам, чего так не хватает приверженцам этого направления.
- Удивительно, что в последнее время наблюдается мало интереса к биологическим и генетическим направлениям применения машинного обучения. Открывается хорошая возможность занять свою нишу для исследователей, ищущих тему для дальнейшего роста.
- Общепринятым статьям и статьям по ретро-методам удается еще попасть на конференцию, однако конкуренция среди них выше и для получения интересных результатов исследователям приходится прилагать больше усилий, чем в более модных и популярных направлениях. В пору задуматься о том, что материалы для применения классического машинного обучения исчерпаны.
Детальный обзор конференции от Чип Хен можно найти ниже.
1. Инклюзивность
Организаторы [International Conference on Learning Representations 2019 — ред.] подчеркнули важность инклюзивности в области искусственного интеллекта. Первые два основных доклада — вступительное слово Александра Раша и приглашенного докладчика Синтии Дворк — были посвящены справедливости и равенству.
Несколько тревожных статистических данных ICLR 2019:
- женщин только 8,6% докладчиков и 15% участников,
- 2/3 всех LGBTQ+ исследователей не раскрывают собственную ориентацию на работе,
- все 8 приглашенных докладчиков – представители европеоидной расы.

К сожалению [автора женского пола], основная часть исследователей искусственного интеллекта совершенно не интересуется вопросом равенства. Если семинары по остальным тематикам были переполнены, то мастерская ИИ для социального блага была довольно пустой, пока не появился Йошуа Бенжио. Во время многочисленных бесед, проведенных мной на ICLR, никто не упоминал о «diversity». Исключением стал один случай: меня пригласили на неподходящее мне техническое мероприятие, чему я громко удивилась, и мой хороший друг ответил: «Немного оскорбительный ответ: тебя пригласили, потому что ты — женщина».
Причина наблюдаемого положения дел в том, что тема diversity не является «технической», и поэтому не поможет в продвижении научной карьеры. Другая причина заключается в том, что существует отторжение социальной-общественной пропаганды. Один мой друг однажды посоветовал мне не обращать внимание на чувака, который троллил меня в групповом чате, потому что «ему нравится высмеивать людей, которые говорят о равенстве и разнообразии». У меня есть друзья, которые не любят обсуждать вопрос diversity в Интернете, потому что не хотят быть «ассоциированными с этой темой».
2. Representation learning & transfer learning
Основная цель обучения представлениям без учителя (Unsupervised Representation learning) — обнаружение признаков в неразмеченных данных, полезных для использования в последующих задачах. В области Natural Language Processing обучение представлениям часто производится с помощью языкового моделирования. Полученные представления затем используются для таких задач, как анализ эмоциональной окраски (sentiment analysis), распознавание имен (name entity recognition) и машинный перевод (machine translation).
Некоторые из наиболее интересных работ прошлого года по обучению представлениям без учителя начинаются с ELMo (Peters et al.), ULMFiT (Howard et al.), GPT OpenAI (Radford et al.), BERT. (Devlin et al.) И, конечно, в высшей степени опасный GPT-2 (Radford et al.).
Полная модель GPT-2 была продемонстрирована на ICLR, и она восхитительна. Вы можете ввести произвольный набросок начала текста, а модель напишет остальную часть статьи. Модель может писать новостные статьи, фанфики, научные статьи, даже определения выдуманных слов. Пока что результат все еще смотрится не по-человечески, однако команда усердно трудится над GPT-3. Я жду с нетерпением возможности посмотреть на способности новой модели.
Подход transfer learning был в первую очередь взят на вооружение сообществом специалистов по компьютерному зрению. Однако обучение модели классификации на картинках ImageNet все еще происходит в режиме обучения с учителем. Вопрос, который постоянно можно услышать от представителей обоих сообществ, звучит так: «Как бы нам использовать обучение представлениям без учителя в работе с изображениями?»
Хотя большинство известных исследовательских лабораторий уже работают над этой задачей, на ICLR была представлена только одна статья «Обновление правил мета-обучения для обучения представлениям без учителя» (Metz et al.). Вместо обновления весов алгоритм обновляет правило обучения (learning rule). Представления, полученные из learning rule, затем доводятся на небольшой выборке размеченных данных в режиме классификации изображений. Исследователи смогли найти learning rules, которые позволили достичь точности (accuracy) более 70% на MNIST и Fashion MNIST.
Авторы открыли часть кода, но не весь, потому что «он привязан к вычислениям». Внешний цикл требует около 100 тыс. шагов обучения и 200 часов на 256 процессорах.

У меня есть ощущение, что в ближайшем будущем мы увидим еще много подобных работ. Использовать обучение без учителя возможно в таких задачах, как автокодирование, прогнозирование поворота изображения (документ Gidaris et al. был хитом на ICLR 2018), прогнозирование следующего кадра в видео и др.
3. Ретро ML
Идеи в машинном обучении подобны моде: они цикличны. Просмотреть сессию постеров сейчас все равно что прогуляться по историческому музею. Даже долгожданные дебаты на ICLR закончились тем, что спор пришел к вопросу «priors vs structure», что возвращает к дискуссии Янна ЛеКуна и Кристофера Мэннинга в прошлом году и напоминает вековые дебаты между сторонниками Байесовой теории и сторонниками фреквентистского (частотного) подхода к вероятностям.
Проект «Grounded Language Learning and Understanding» в MIT Media Lab был прекращен в 2001 году, но в этом году Grounded Language Learning представило две работы, завернутые в обложку «обучение с подкреплением».
- DOM-Q-NET: Grounded RL on Structured Language (Jia et al.) — RL алгоритм для навигации по веб-страницам путем переходов по ссылкам и заполнением полей, при этом цель навигации выражается на естественном языке.
- BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning (Chevalier-Boisvert et al.) — совместимая с OpenAI Gym платформа с рукотворным бот-агентом, который имитирует преподавателя-человека, помогающего агентам в изучении синтетического языка.
Мои мысли об этих двух статьях отлично обобщил AnonReviewer4:
«… предложенные здесь методы очень похожи на методы, которые довольно давно рассматривались в литературе по семантическому парсингу. Только эта работа ссылается на статьи о глубоком RL. Я думаю, что авторам было бы очень полезно ознакомиться с этой литературой. Я думаю, что сообщество семантического анализа также выиграет от этого… Но эти два сообщества, по-видимому, мало общаются друг с другом, хотя в некоторых случаях работают над очень схожими проблемами».
DFA (Deterministic Finite Automata) также нашли свое место в мире глубокого обучения в этом году в двух статьях:
- Representing Formal Languages: A Comparison Between Finite Automata and Recurrent Neural Networks (Михаленко и др.),
- Learning Finite State Representations of Recurrent Policy Networks (Koul et al.).
Основная мотивация обеих работ состоит в следующем: в связи с огромным пространством скрытых состояний в RNNs можно ли сократить число состояний до конечного? Я скептически отношусь к тому, что DFA сможет эффективно представлять RNN в языковых задачах, но мне нравится идея обучения RNN в процессе тренировки, а затем преобразования его в DFA для логических выводов, как это представлено в статье Koul et al. Итоговые конечные представления требуют для игры в понг всего трех дискретных состояний памяти и 10 наблюдений. DFA также помогает в интерпретации RNN.

4. RNN теряет популярность среди исследователей
При рассмотрении графика прироста статей по различным тематикам в 2019 году относительно 2018 года становится понятно, что RNN характеризуется наибольшим падением. Это не удивительно, потому что, даже если использование RNNs интуитивно понятны для последовательных типов данных, они страдают от серьезного недостатка: их нельзя распараллелить. Следственно, не получается воспользоваться преимуществом самого важного фактора, стимулирующего прогресс в исследованиях с 2012 года: вычислительной мощностью. RNN никогда не были популярны в CV или RL, а для NLP их заменяют архитектуры, основанные на Attention.

Значит ли это, что RNN мертв? На самом деле, нет. Статья «Ordered neurons: Integrating tree structures into Recurrent Neural Networks» (Shen et al.). получила одну из высших наград в этом году. Помимо этой и двух упомянутых выше статей об автоматах, в этом году рассмотрено еще девять работ по RNN, большинство из которых углубляются в математические основы, а не открывают новые возможности.
RNNs остаются полными жизни и являются драйверами в отрасли, особенно для компаний, имеющих дело с временными рядами, такими, как торговые фирмы. К сожалению, торговые фирмы обычно не публикуют детали своей работы. Даже если RNN сейчас мало привлекают исследователей, они могут вернуть свою популярность в будущем.
5. GANs все еще на высоте
Несмотря на то, что тематика GAN в относительной шкале по сравнению с прошлым годом показывает отрицательный рост, в абсолютной шкале количество работ возросло с ~70 до ~100. Йен Гудфеллоу выступал с докладом о GAN и был всё время окружен поклонниками. В последний день ему пришлось перевернуть свой бейджик, чтобы люди не могли видеть его имя.
Вся первая постерная сессия была посвящена GAN. Появились новые архитектуры GAN, улучшения старой архитектуры GAN, анализ GAN, приложения GAN от генерации изображений до генерации текста и синтеза аудио. Существуют PATE-GAN, GANSynth, ProbGAN, InstaGAN, RelGAN, MisGAN, SPIGAN, LayoutGAN, KnockoffGAN и т. д. и я понятия не имею, что это значит. К сожалению, Эндрю Брок назвал свою гигантскую модель BigGAN, а не giGANtic :)

Постерная сессия продемонстрировала, насколько предвзято сообщество, когда речь заходит о GAN. Некоторые из комментариев, которые я слышала от противников GAN, выглядели так: «Я не могу дождаться, когда вся эта шумиха с GAN затихнет», «Когда кто-то упоминает термин «adversarial», мой мозг просто отключается». На мой взгляд, они просто завидуют.
6. Нехватка биологических тем в глубинном изучении
Учитывая большой ажиотаж, вызванный у публики определением последовательности генов в ДНК, а также появлением модифицированных детей с помощью технологии CRISPR, [мне] показалось удивительным, что на ICLR нет прироста работ по применению глубокого обучения в биологии. Всего по теме было шесть статей.
Две – по вопросам архитектур заимствованных из биологии:
- Biologically-Plausible Learning Algorithms Can Scale to Large Datasets (Xiao et al.),
- A Unified Theory of Early Visual Representations from Retina to Cortex through Anatomically Constrained Deep CNNs (Lindsey et al.).
Одна работа по обучению проектированию РНА (Рунге и др.).
Три работы по манипуляциям с белком:
- Human-level Protein Localization with Convolutional Neural Networks (Rumetshofer et al.),
- Learning Protein Structure with a Differentiable Simulator (Ingraham et al.),
- Learning protein sequence embeddings using information from structure (Bepler et al.).

По теме геномов не было ни одной статьи, а также не проводилось семинаров. Как бы печально это не выглядело, однако для исследователей глубокого обучения в биологии и биологов в области глубокого обучения открываются огромные возможности.
Один из фактов: Джек Линдси, первый автор упомянутой выше статьи о сечатке, еще не окончил Стэнфордский колледж.
7. Обучение с подкреплением остается самой популярной темой
Представленные на конференции работы демонстрируют, что сообщество RL переходит от model-free-методов к model-based-алгоритмам с эффективным сэмплированием и алгоритмам на основе meta-learning. Сдвиг, вероятно, был обусловлен чрезвычайно высокими результатами на Mujoco бенчмарках, установленными TD3 (Fujimoto et al., 2018) и SAC (Haarnoja et al., 2018), а также на дискретном пространстве операций в Atari, установленным R2D2 (Kapturowski et al., ICLR 2019).
Model-based-алгоритмы в процессе обучения на имеющихся данных получают модель окружающей среды и используют ее для планирования стратегии агентов в этой среде или для генерации новых данных. Model-based-алгоритмы наконец достигли асимптотической точности своих model-free аналогов, используя в 10-100 раз меньше данных (MB-MPO (Rothfuss et al.)). Новое преимущество делает model-based методы пригодными для задач реального уровня сложности. Если после тренировки симулятор среды будет обладать изъянами, что весьма вероятно, то его недостатки могут быть нивелированы при использовании более сложных моделей, таких, как ансамбль симуляторов (Rajeswaran et al.). Другой способ применения RL в решении задач реального уровня сложности — позволить симулятору поддерживать сложные схемы рандомизации. Полученная на разнообразных симуляторах окружающей среды стратегия может рассматривать реальный мир как «еще одну рандомизацию» и способна добиться успеха в задачах реального уровня сложности (OpenAI).
Алгоритмы мета-обучения, позволяющие получить быстрый learning transfer на новые задачи, также были усовершенствованы как с точки зрения производительности, так и с точки зрения эффективности выборки (ProMP (Rothfuss et al.), PEARL (Rakelly et al.)). Эти улучшения приблизили нас к «моменту ImageNet для RL», в котором мы сможем использовать извлеченные из других задач стратегии принятия решений, вместо того, чтобы обучать их с нуля (что невозможно для сложных задач).

Внушительная часть принятых работ вкупе с семинаром по структуре и априорной вероятности в RL были посвящены интеграции знаний об окружающей среде в алгоритмы обучения. Если одной из основных сильных сторон ранних алгоритмов глубокого RL была обобщенность (например, DQN использует одну и ту же архитектуру для всех игр Atari, ничего не зная о какой-либо конкретной игре), то сейчас новые алгоритмы используют интеграцию априорных знаний для решения более сложных задач. Например, в Transporter Network (Jakab et al.) агент использует априорные знания для проведения более информативной поисково-разведочной работы.
Подводя итог, можно сказать, что за последние 5 лет сообщество RL разработало множество эффективных инструментов для решения проблем обучения с подкреплением в model-free-режиме. Теперь пришло время придумать более транспортабельные и эффективные по выборке алгоритмы с целью применения RL к реальным задачам.
Один из фактов: Сергей Левин, вероятно, является человеком с наибольшим количеством работ на ICLR в этом году, в частности, к публикации принято 15 его статей.
8. Общепринятые статьи быстро уходят на второй план
Когда я спросила известного исследователя, что он думает о принятых работах в этом году, он посмеивался: «Большинство из них будут забыты, как только конференция закончится». В такой быстро развивающейся области, как машинное обучение достигнутые результаты опровергаются через недели, если не дни. Не удивительно, что большинство принятых работ уже устаревают к моменту представления. Например, согласно данным Borealis AI для ICLR 2018, "семь из восьми статей на тему защиты от adversarial атаки были опровергнуты еще до начала конференции ICLR. Это показывает, что эвристические методы без какой-либо теоретической основы далеко не так надежны, как могут казаться."
Я часто слышала во время конференции комментарии, отмечающие ощутимый вклад случайности в решении о принятии/отклонении работы. Я не буду называть конкретные статьи, однако некоторые из наиболее обсуждаемых и наиболее цитируемых работ за последние несколько лет были отклонены конференциями при первой отправке. Тем не менее, многие из принятых работ будут актуальны годами, даже не цитируясь.
Как человек, занимающийся исследованиями в этой области, я часто сталкиваюсь с экзистенциальным кризисом. Какая бы идея ко мне ни пришла, кажется, что кто-то другой уже реализует это, при том лучше и быстрее. Какой смысл публиковать статью, если она никогда никому не понадобится?
Заключение
Конечно, есть еще тенденции, которые я хотела бы охватить.
- Оптимизация и регуляризация: дебаты Адам против SGD продолжаются. Предложено много новых методов, и некоторые из них довольно захватывающие. Кажется, что в наши дни каждая лаборатория разрабатывает свой собственный оптимизатор — даже наша команда работает над новым оптимизатором, который должен быть выпущен в ближайшее время.
- Метрики качества: поскольку генеративные модели становятся все более и более популярными, нам необходимо придумать какие-то метрики качества для оценки сгенерированных объектов. Метрики для сгенерированных данных, обладающих структурой, достаточно сомнительны. Метрики для сгенерированных неструктурированных данных, таких, как диалоги на общую эрудицию и сгенерированные GAN изображения, являются не паханным полем.
Однако этот пост затягивается, а мне нужно вернуться к работе. Если вы хотите узнать больше, Дэвид Абель опубликовал свои подробные заметки (55 страниц). Я считаю особенно показательным приведенный ниже график из прикладной статистики ICLR 2019 для тех, кто хочет узнать, что еще любопытного было на конференции.
Самые ожидаемые слова в заголовках

Мне действительно понравилась ICLR. Конференция достаточно объемная, чтобы встретить множество людей и поучаствовать в интересных беседах, но при этом достаточно небольшая, чтобы не ждать в очереди. Продолжительность четырехдневной конференции тоже в самый раз. NeurIPS слишком долгая, и обычно к концу четвертого дня я брожу между постерами и думаю: «Посмотрите на все те замечательные знания, которые я могла бы получить прямо сейчас, но не хочу».
Самый большой трофей, который я привезла с конференции, — это не только идеи, но и мотивация. Наблюдая за исследователями моего возраста, делающими замечательные вещи, я получаю возможность различить красоту исследовательской работы и мотивацию усердно работать. Также приятно располагать целой неделей на то, чтобы наверстать упущенное в статьях и в общении со старыми друзьями. 10 из 10, я бы порекомендовала [ICLR — ред.].
Этот пост не отражает точку зрения какой-либо организации, с которой я связана, и, вероятно, приправлен моими личными и институциональными предубеждениями. Раздел «Подкрепленное обучение» был написан моим замечательным стажером и коллегой Олексием Гринчуком (Oleksii Hrinchuk)
На этом заканчивается оригинальная статья. Со стороны сотрудников нашей компании CleverDATA хочется согласиться с автором в том, что конференции по машинному обучению действительно дают мотивацию для дальнейших работ, позволяют сравнить свои результаты и получить профессиональную обратную связь от коллег. Участие в подобных мероприятиях необходимо для профессионального роста. Скорость развития Data Science растет, работы устаревают еще до момента их презентаций на конференции, а большая часть работ оказывается забытой после завершения конференции. Нужно бежать со всех ног, чтобы только оставаться на месте, а чтобы куда-то попасть, надо бежать как минимум вдвое быстрее!
