
Привет, Хабровчане! Мы продолжаем знакомить вас с российской гиперконвергентной системой AERODISK vAIR. В этой статье речь пойдет об архитектуре данной системы. В прошлой статье мы разобрали нашу файловую систему ARDFS, а в данной статье пройдёмся по всем основным программным компонентам, из которых состоит vAIR, и по их задачам.
Описание архитектуры начнем снизу вверх — от хранения к управлению.
Файловая система ARDFS + Raft Cluster Driver
Основа vAIR – распределенная файловая система ARDFS, которая объединяет локальные диски всех нод кластера в единый логический пул, на базе которого из виртуальных блоков по 4MB формируются виртуальные диски с той или иной схемой отказоустойчивости (Replication factor или Erasure coding). Более подробное описание работы ARDFS приведено в предыдущей статье.
Raft Cluster Driver – это внутренняя служба ARDFS, которая решает задачу распределенного и надежного хранения метаданных файловой системы.
Метаданные ARDFS условно делятся на два класса.
- нотификации — информация об операциях с объектами хранения и информация о самих объектах;
- служебная информация – выставление блокировок и информация о конфигурации нод-хранилищ.
Для распределения этих данных как раз и используется служба RCD. Она автоматически назначает ноду с ролью лидера, задачей которого является получение и распространение метаданных по нодам. Лидер является единственно верным источником этой информации. Кроме того, лидер организовывает heart-beat, т.е. проверяет доступность всех нод-хранилищ (к доступности виртуальных машин это отношения не имеет, RCD — это только служба для хранения).
Если по какой-либо причине для одной из рядовых нод лидер стал недоступен более одной секунды, эта рядовая нода организовывает перевыборы лидера, запрашивая доступность лидера с других рядовых нод. Если собирается кворум, лидер переизбирается. После того как бывший лидер "проснулся", он автоматически становится рядовой нодой, т.к. ему новый лидер отправляет соответствующую команду.
Сама логика работы RCD не является чем-то новым. Подобной логикой также руководствуются многие сторонние и коммерческие, и свободные решения, но эти решения нам не подошли (как и существующие open-source ФС), потому что они достаточно тяжелые, и оптимизировать их под наши простые задачи весьма сложно, поэтому мы просто написали свою службу RCD.
Может показаться, что лидер является "узким горлышком", которое может замедлять работу в больших кластерах на сотни нод, но это не так. Описанный процесс происходит практически моментально и "весит" очень немного поскольку писали мы его сами и включили только самые необходимые функции. Кроме того, он происходит полностью автоматически, оставляя лишь сообщения в логах.
MasterIO – служба управления многопоточным вводом-выводом
После того как организован пул ARDFS с виртуальными дисками, он может быть использован для ввода-вывода. В этом моменте возникает вопрос, свойственный именно гиперконвергентным системам, а именно: сколько системных ресурсов (CPU / RAM) мы можем пожертвовать для IO?
В классических СХД этот вопрос не стоит так остро, потому что задача СХД только хранить данные (и большую часть системных ресурсов СХД можно спокойно отдавать под IO), а в задачи гиперконвергента, кроме хранения, ещё входит выполнение виртуальных машин. Соответственно в ГКС требуется использовать ресурсы CPU и RAM в первую очередь для виртуальных машин. Ну а как быть с вводом-выводом?
Для решения этой задачи в vAIR используется служба управления вводом-выводом: MasterIO. Задача службы проста — «взять всё и поделить» гарантированно забрать для ввода-вывода n-ное количество системных ресурсов и, исходя их них, запустить n-ное количество потоков ввода-вывода.
Изначально мы хотели предусмотреть «очень умный» механизм выделения ресурсов под IO. К примеру, если нагрузки на хранилище нет, то системные ресурсы могут быть использованы для виртуалок, а если нагрузка появляется, эти ресурсы у виртуалок «мягко» изымаются в заранее определенных пределах. Но эта попытка закончилась частичным провалом. Тесты показали, что если нагрузку повышать постепенно, то все ОК, ресурсы (помеченные для возможного изъятия) постепенно изымаются у ВМ в пользу ввода-вывода. Но вот резкие всплески нагрузок на хранилище провоцируют не совсем уж «мягкое» изъятие ресурсов у виртуалок, и в итоге на процессоры копятся очереди и, как результат, и волки голодные, и овцы сдохли и виртуалки виснут, и IOPS-ов нет.
Возможно, в будущем мы вернемся к этой проблеме, а пока мы реализовали выдачу ресурсов для IO старым добрым дедовским способом – руками.
Исходя из данных сайзинга администратор заранее выделяет n-ное количество ядер CPU и объема RAM под службу MasterIO. Эти ресурсы выделяются монопольно, т.е. они никак не могут быть задействованы для нужд ВМ, пока админ этого не разрешит. Ресурсы выделяются равномерно, т.е. с каждой ноды кластера изымается одинаковое количество системных ресурсов. В первую очередь для MasterIO интересны ресурсы процессора (RAM менее важна), особенно если мы используем Erasure coding.
Если с сайзингом вышла промашка, и мы слишком много ресурсов отдали MasterIO, то ситуация легко решается изъятием этих ресурсов обратно в пул ресурсов ВМ. Если ресурсы простаивают, то они почти сразу вернутся в пул ресурсов ВМ, если же эти ресурсы утилизированы, то придется некоторое время подождать, пока MasterIO их мягко освободит.
Обратная ситуация сложнее. Если нам потребовалось увеличить количество ядер для MasterIO, а они заняты виртуалками, то с виртуалками придется «договариваться», то есть отбирать их ручками, поскольку в автоматическом режиме в ситуации резкого всплеска нагрузки эта операция пока чревата зависаниями ВМ и прочим капризным поведением.
Соответственно, сайзингу производительности IO гиперконвергентных систем (не только наших) нужно уделять довольно много внимания. Чуть позднее в одной из статей обещаем этот вопрос рассмотреть подробнее.
Гипервизор
За выполнение виртуальных машин в vAIR отвечает гипервизор Аист. Этот гипервизор сделан на базе проверенного временем гипервизора KVM. В принципе про работу KVM-а написано достаточно много, поэтому нет особой нужды его расписывать, просто укажем, что все стандартные функции KVM-а сохранены в Аисте и прекрасно работают.
Поэтому тут мы опишем основные отличия от стандартного KVM-а, которые мы реализовали в Аисте. Аист является частью системы (предустановленным гипервизором) и управляется он из общей консоли vAIR через Web-GUI (русский и английский варианты) и SSH (очевидно, только английский).
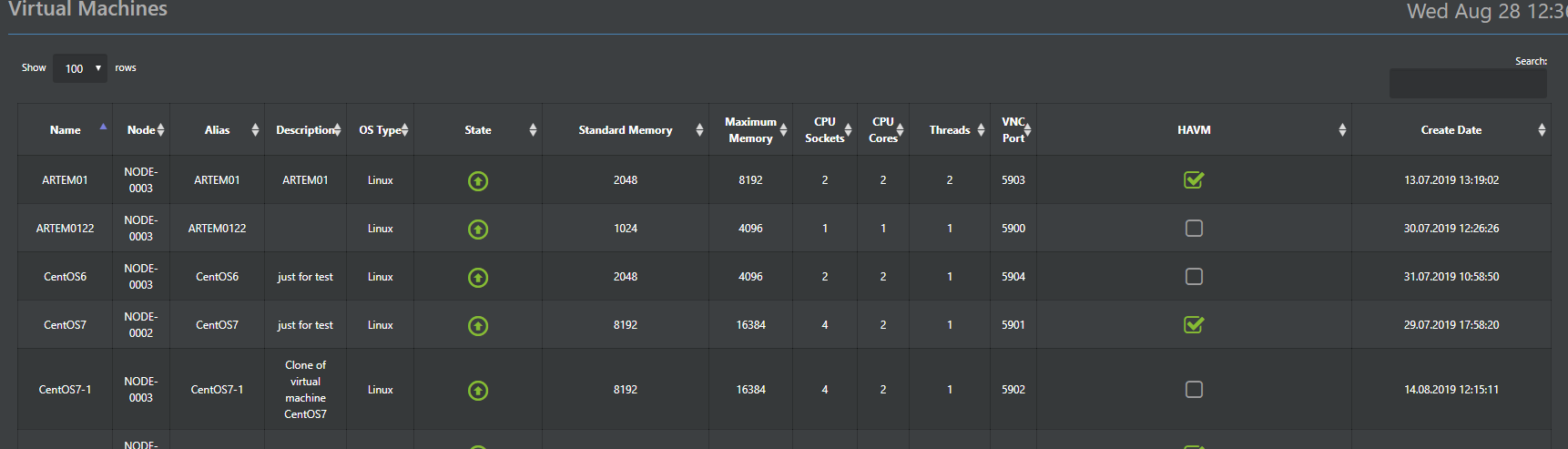
Кроме того, конфигурации гипервизора хранятся в распределенной базе ConfigDB (о ней чуть ниже), которая также является и единой точкой управления. То есть можно подключиться к любой ноде кластера и управлять всеми без необходимости выделения отдельного управляющего сервера.
Важным дополнением к штатному функционалу KVM является разработанный нами HA-модуль. Это простейшая реализация кластера высокой доступности виртуальных машин, которая позволяет в случае падения ноды автоматически перезапустить виртуалку на другом узле кластера.
Ещё полезной функцией является массовое развертывание виртуалок (актуально для VDI-сред), которая позволят автоматизировать разворачивание виртуальных машин с автоматическим распределением их между нодами в зависимости от нагрузки на них.
Распределение ВМ между нодами является основой для автоматической балансировки нагрузки (аля DRS). Эта функция в текущем релизе ещё недоступна, но над ней мы ведем активную работу и в одном из ближайших обновлений она обязательно появится.
Опционально поддерживается работы гипервизора VMware ESXi, на текущий момент его работа реализована с помощью протокола iSCSI, в будущем также планируются поддержка NFS.
Виртуальные коммутаторы
Для программной реализации коммутаторов предусмотрен отдельный компонент – Fractal. Как и в других наших компонентах мы идем от простого к сложному, поэтому в первой версии реализована простая коммутация, а маршрутизация и межсетевое экранирование пока отдаем сторонним устройствам. Принцип действия стандартный. Физический интерфейс сервера соединяется мостом с объектом Фрактала – группой портов. Группа портов, в свою очередь, с нужными виртуальными машинами кластера. Поддерживается организация VLAN-ов, а в одном из следующих релизов добавится поддержка VxLAN-ов. Все создаваемые коммутаторы по умолчанию распределенные, т.е. распределены по всем нодам кластера, поэтому какие виртуалки к каким коммутаторам подключать от ноды нахождения ВМ не зависит, это вопрос исключительно решения администратора.
Мониторинг и статистика
Компонент, отвечающий за мониторинг и статистику (рабочее название Monica), является, по сути, переработанным клоном с СХД ENGINE. В свое время он хорошо себя зарекомендовал и мы решили с легким тюнингом использовать его в vAIR. Также как и все остальные компоненты Моника выполняется и хранится на всех нодах кластера одновременно.
Круг нелегких обязанностей Моники можно очертить следующим образом:
Сбор данных:
- с аппаратных сенсоров (то, что может отдавать железо по IPMI);
- с логических объектов vAIR (ARDFS, Аист, Фрактал, MasterIO и другие объекты).
Коллекционирование данных в распределенной базе;
Интерпретация данных в виде:
- логов;
- оповещений;
- графиков.
Внешнее взаимодействие со сторонними системами по протоколам SMTP (отправка почтовых оповещений) и SNMP (взаимодействие со сторонними системами мониторинга).
Распределенная база конфигураций
В предыдущих абзацах упоминалось, что многие данные хранятся на всех нодах кластера одновременно. Для организации такого метода хранения предусмотрена специальная распределенная база данных ConfigDB. Как понятно из названия, база хранит конфигурации всех объектов кластера: гипервизора, виртуальных машин, HA-модуля, коммутаторов, файловой системы (не путать с базой метаданных ФС, это другая БД), а также статистику. Эти данные в синхронном режиме хранятся на всех нодах и консистентность этих данных является обязательным условием стабильной работы vAIR.
Важный момент: несмотря на то что функционирование ConfigDB жизненно важно для работы vAIR, выход её из строя хоть и остановит работу кластера, но никак не повлияет на консистентность данных, хранимых в ARDFS, что на наш взгляд – плюс к надежности решения в целом.
Также ConfigDB является единой точкой управления, поэтому можно зайти по IP-адресу на любую ноду кластера и полноценно управлять всеми нодами кластера, что довольно удобно.
Кроме того, для доступа внешних систем в ConfigDB предусмотрен Restful API, через который можно настроить интеграцию со сторонними системами. К примеру, недавно мы сделали пилотную интеграцию с несколькими российскими решениями в областях VDI и информационной безопасности. Когда проекты завершатся мы с удовольствием напишем тут технические детали.
Картина в целом
В итоге имеем два варианта архитектуры системы.
В первом — основном случае – используется наш KVM-based гипервизор Аист и программные коммутаторы Фрактал.
Сценарий 1. True
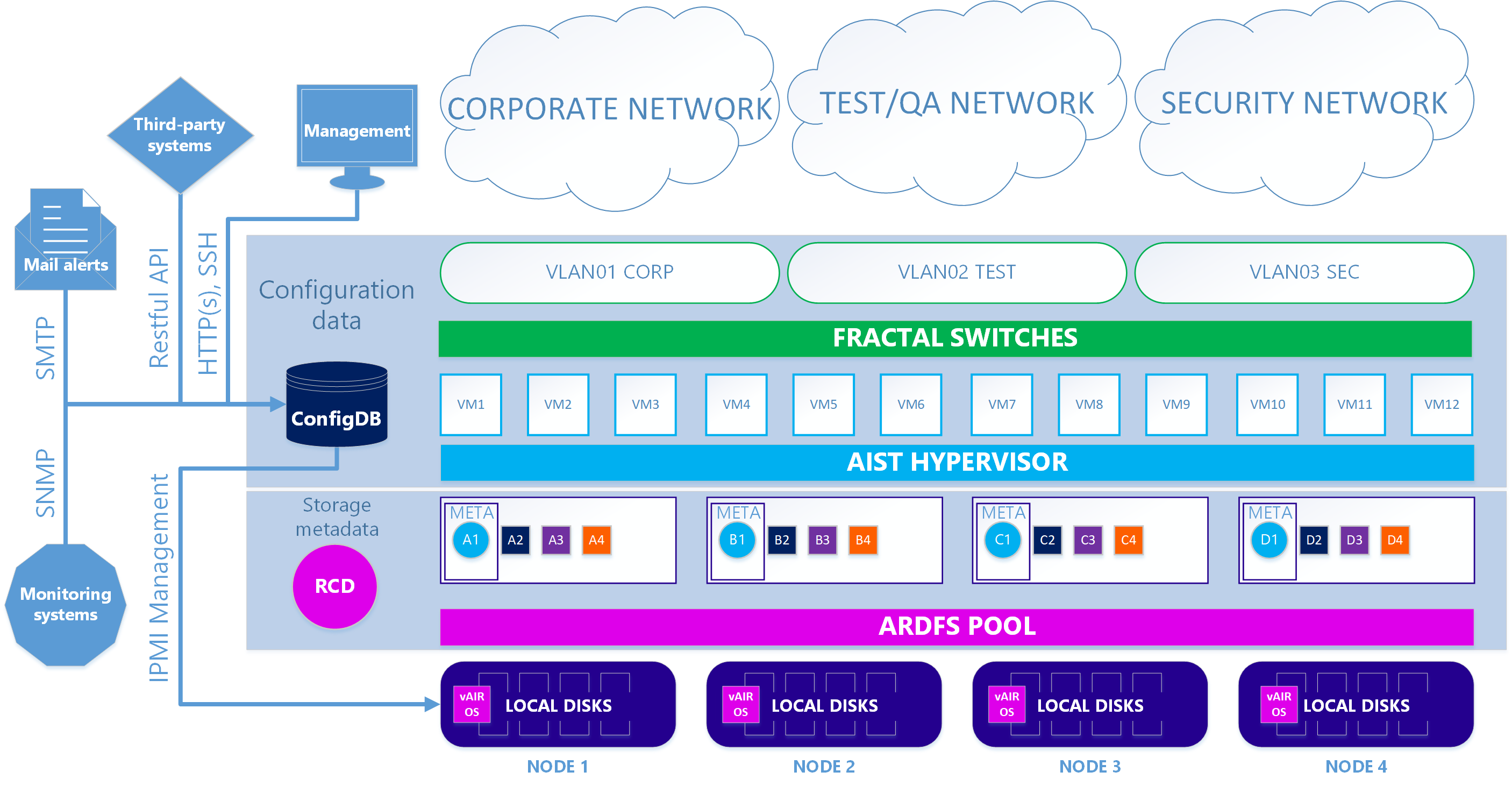
Во втором — опциональном варианте – когда требуется использовать гипервизор ESXi, схема несколько усложняется. Для того, чтобы использовать ESXi, его нужно установить стандартным образом на локальные диски кластера. Далее на каждой ноде ESXi устанавливается виртуалка vAIR MasterVM, которая содержит специальный дистрибутив vAIR для запуска в виде виртуальной машины VMware.
ESXi отдает все свободные локальные диски методом прямого их проброса в MasterVM. Внутри MasterVM эти диски уже стандартно форматируются в ARDFS и отдаются наружу (точнее, обратно в ESXi) по протоколу iSCSI (а в будущем ещё будет NFS) через выделенные в ESXi интерфейсы. Соответственно виртуальные машины и программная сеть в этом случае обеспечиваются средствами ESXi.
Сценарий 2. ESXi
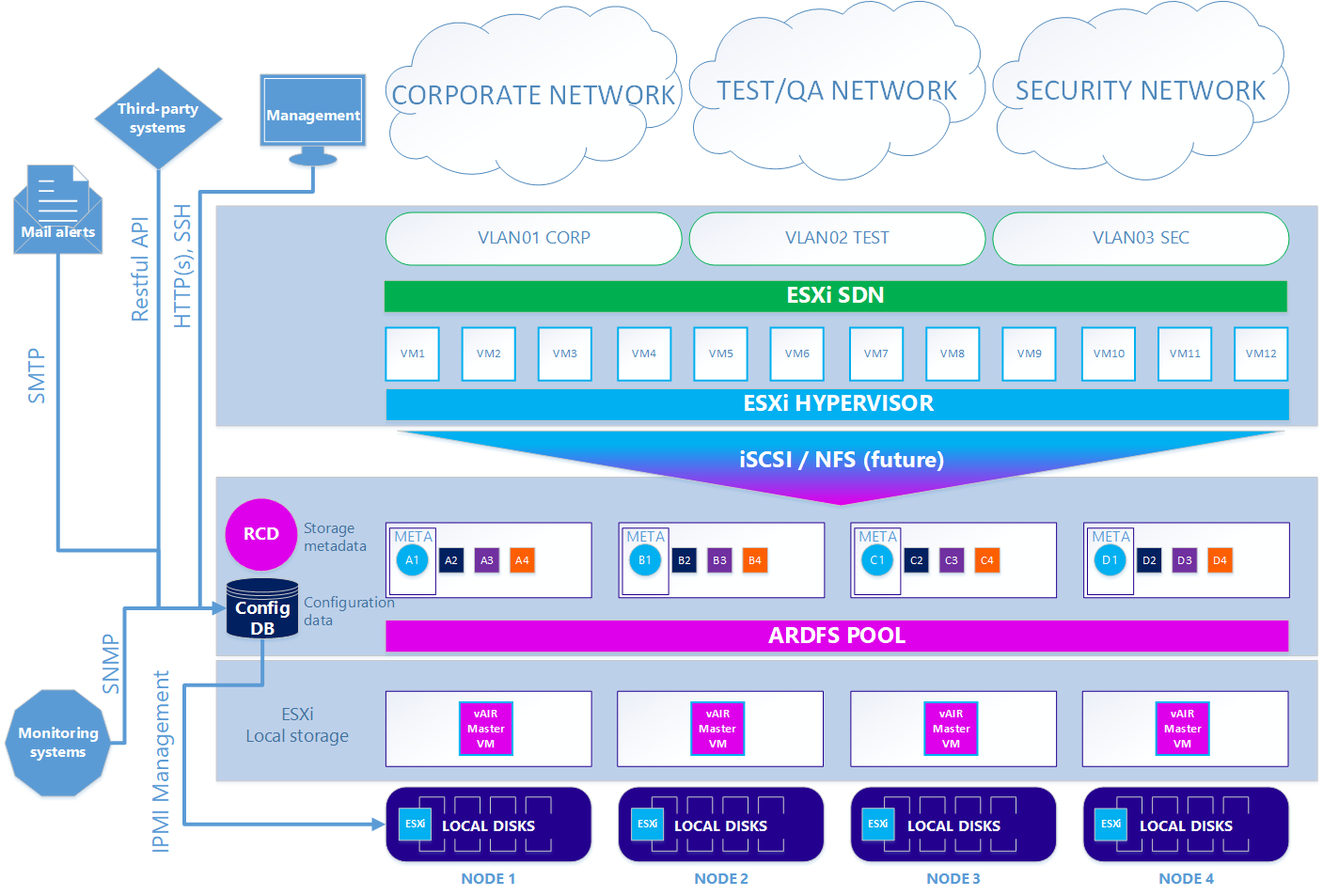
Итак, мы разобрали все основные компоненты архитектуры vAIR и их задачи. В следующей статье будем рассказывать об уже реализованном функционале и планах на ближайшее будущее.
Ждем комментариев и предложений.
