
Жил был Роберт Бонд — 65-летний программист из Калифорнии. И была у него жена-садовница, которая очень любила свою чистенькую лужайку. Но это Калифорния, там нет двухметровых заборов с системой защиты от котов. На лужайку ходят соседские коты и гадят!

Проблему нужно было решать. Как же решил её Роберт? Он докупил немного железа к своему компьютеру, подключил к нему камеру наружного наблюдения, смотрящую за лужайкой, и дальше проделал несколько необычную вещь, он загрузил доступный бесплатный Open Source софт — нейросеть, и начинал обучать её распознавать котов на изображении с камеры. И задача в начале кажется тривиальной, ведь если чему-то учить и легко — это котам, потому что котами завален Интернет, их там десятки миллионов. Если было всё так просто, но дела обстоят хуже, в реальной жизни коты ходят гадить в основном ночью. Картинок ночных котов, писающих на лужайке, в Интернете практически нет. И некоторые из котов умудряются даже пить из системы полива во время работы, но всё же потом сваливают.

Ниже мы приводим описание проекта от автора, англоязычный вариант можно найти здесь.
Этот проект был мотивирован двумя вещами: желанием узнать больше о программном обеспечении нейронной сети и желанием поощрить соседских кошек болтаться где-нибудь ещё, кроме моей лужайки.
Проект включает в себя только три аппаратных компонента: плату Nvidia Jetson TX1, IP-камеру Foscam FI9800P и Particle Photon, подключенный к реле. Камера установлена на стороне дома со стороны лужайки. Она связывается с точкой доступа WI-FI, сопровождаемой Jetson. Particle Photon и реле установлены в блоке управления моей системы полива и подключены к точке доступа WI-FI на кухне.
В процессе работы камера настроена следить за изменениями во дворе. Когда что-то меняется, камера передает Jetson набор из 7 изображений, по одному в секунду. Служба, работающая на Jetson, отслеживает входящие изображения, передавая их в глубокую обучающую нейронную сеть Caffe. Если сеть обнаруживает кошку, Jetson сигнализирует серверу Particle Photon в облаке, который отправляет сообщение в Photon. Photon отвечает, включив разбрызгиватели на две минуты.
Здесь кот зашел в кадр, включив камеру:

Через несколько секунд кот выбрался на середину двора, снова включив камеру и активировал разбрызгиватели системы полива:

В установке камеры не было ничего необычного. Единственное постоянное соединение — это 12-вольтовое проводное подключение, которое проходит через небольшое отверстие под карнизом. Я установил камеру на деревянный ящик, чтобы захватить передний двор с лужайкой. К камере подключена куча проводов, которые я спрятал в коробке.
Следуйте указаниям Foscam, чтобы связать его с AP Джетсона (см. ниже). В моей настройке Jetson находится на 10.42.0.1. Я выделил камере фиксированный IP-адрес 10.42.0.11, чтобы его было легко найти. Как только это будет сделано, подключите ноутбук с Windows к камере и настройте параметр «Предупреждение», чтобы активировать изменение. Настройте загрузку 7 изображений по FTP по предупреждению (алерту). Затем дайте ему идентификатор пользователя и пароль на Jetson. Моя камера отправляет изображения 640x360, отправляя их по FTP в свой домашний каталог.
Ниже Вы можете видеть параметры, которые были выбраны для конфигурации камеры.

Photon был прост в настройке. Я поместил его в блок управления поливом.

Черный ящик слева с синим светодиодом представляет собой преобразователь 24 В переменного тока (AC) в 5 В постоянного тока (DC), куплен на еBay. Вы можете увидеть белое реле на плате реле и синий разъем спереди. Сам Photon находится справа. Оба приклеены к куску картона, чтобы скрепить их.
5 В выход с преобразователя подключен к VIN-разъему Particle Photon. Релейная плата в основном аналоговая: она имеет NPN-транзистор с открытым коллектором с номинальным 3,3 В входом на базу транзистора и 3 В реле. Регулятор фотона не мог подавать достаточный ток для управления реле, поэтому я подключил коллектор входа транзистора к 5 В через резистор с сопротивлением 15 Ом и мощностью 1/2 Вт, ограничивающий ток. Контакты реле подключаются к водяному вентелю параллельно с нормальной цепью управления.
Вот схема подключения:
24VAC converter 24VAC <---> Control box 24VAC OUT
24VAC converter +5V <---> Photon VIN, resistor to relay board +3.3V
24VAC converter GND <---> Photon GND, Relay GND
Photon D0 <---> Relay board signal input
Relay COM <---> Control box 24VAC OUT
Relay NO <---> Front yard water valve
Единственными аппаратными компонентами, добавленными в Jetson, являются накопитель SATA SSD и небольшой USB-концентратор Belkin. Концентратор имеет два беспроводных ключа, при помощи которых подключается клавиатура и мышь.
SSD подошел без проблем. Я переформатировал его в EXT4 и установил его как /caffe. Я настоятельно рекомендую удалить весь код вашего проекта, git-репозитории и данные приложений с внутренней SD-карты Jetson, потому что часто проще всего стереть систему во время обновления Jetpack.

Настройка беспроводной точки доступа была довольно простой (правда!), если вы будете следовать этому руководству. Просто используйте меню Ubuntu, как указано, и обязательно добавьте этот параметр конфигурации.
Я установил vsftpd в качестве FTP-сервера. Конфигурация в значительной степени стоковая. Я не включил анонимный FTP. Я дал камере имя пользователя и пароль, которые больше ни для чего не используются.
Я установил Caffe применив рецепт JetsonHacks. Я полагаю, что в текущих выпусках больше нет проблемы LMDB_MAP_SIZE, поэтому попробуйте собрать ее, прежде чем вносить изменения. Вы должны быть способны запустить тесты и timing demo, упомянутые в шелл-скрипте JetsonHacks. В настоящее время я использую Cuda 7.0, но я не уверен, что это имеет большое значение на данном этапе. Используйте CDNN, это экономит значительный объем памяти в этих небольших системах. Как только он будет собран, добавьте каталог сборки в переменную PATH, чтобы сценарии могли найти Caffe. Также добавьте каталог Caffe Python lib в вашу PYTHONPATH.
Я использую вариант Fully Convolutional Network for Semantic Segmentation (FCN). Смотрите Berkeley Model Zoo, github.
Я попробовал несколько других сетей и, наконец, остановился на FCN. Подробнее о процессе выбора в следующей статье. Fcn32s хорошо работает на TX1 — он занимает чуть более 1 ГБ памяти, запускается примерно за 10 секунд и сегментирует изображение 640x360 примерно за треть секунды. В текущем репозитории github есть хороший набор сценариев, и настройка не зависит от размера изображения — он изменяет размер сети, чтобы соответствовать тому, что вы вбрасываете в неё.
Чтобы попробовать, вам понадобится развернуть уже обученные модели Caffe. Это займет несколько минут: размер файла fcn32s-heavy-pascal.caffemodel превышает 500 МБ.
Отредактируйте infer.py, изменив путь в команде Image.open () на соответствующий .jpg. Измените строку «net», чтобы она указывала на только что загруженную модель:
Вам понадобится файл voc-fcn32s / deploy.prototxt. Он легко генерируется из voc-fcn32s / train.prototxt. Посмотрите на изменения между voc-fcn8s / train.prototxt и voc-fcn8s / deploy.prototxt, чтобы увидеть, как это сделать, или вы можете получить это из моего репозитория chasing-cats на github. Теперь вы должны быть в состоянии запустить.
Мой репозиторий включает в себя несколько версий infer.py, несколько утилит Python, которые знают о сегментированных файлах, коде Photon и сценариях управления и операционных сценариях, которые я использую для запуска и мониторинга системы. Подробнее о программном обеспечении далее.
Нейронные сети для распознавания изображений обычно обучаются распознавать набор объектов. Допустим, мы даем каждому объекту индекс от одного до n. Сеть классификации отвечает на вопрос «Какие объекты на этом изображении?» возвращая массив от нуля до n-1, где каждая запись массива имеет значение от нуля до единицы. Ноль означает, что объект не находится на изображении. Ненулевое значение означает, что оно может быть там с возрастающей вероятностью, когда значение приближается к единице. Вот кот и человек в массиве из 5 элементов:

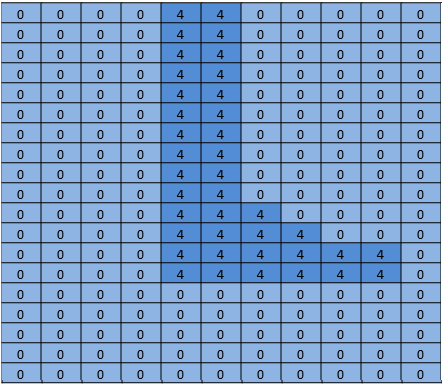
Сегментная сеть сегментирует пиксели изображения областей, которые заняты объектами из нашего списка. Она отвечает на вопрос, возвращая массив с записью, соответствующей каждому пикселю в изображении. Каждая запись имеет значение ноль, если это фоновый пиксель, или значение от одного до n для n различных объектов, которые она способна распознавать. Этот выдуманный пример может быть ногой человека:
Этот проект является частью более крупного проекта, нацеленного на управление радиоуправляемым автомобилем при помощи компьютера. Идея состоит в том, чтобы использовать нейронную сеть, чтобы определить позицию (глобальное трехмерное положение и ориентацию) автомобиля для передачи ему навигационных команд. Камера закреплена, а газон в основном ровный. Я могу немного использовать триггер для изменения 3d-положения, чтоб нейронная сеть смогла найти пиксели экрана и ориентацию. Роль кошки во всем этом — «предполагаемое назначение».
Я начал с того, что думал в первую очередь об автомобиле, так как не знал, как это получится, предполагая, что распознать кошку с предварительно обученной сетью будет тривиально. После множества работ, которые я не буду подробно описывать в этой заметке, я решил, что можно определить ориентацию автомобиля с достаточно высокой степенью достоверности. Вот тренировочный снимок под углом 292,5 градуса:

Большая часть этой работы была проделана с сетью классификации, моделью Caffe bvlc_reference_caffenet. Поэтому я решил дать задании сети сегментации определить положение машины на экране.
Первой сетью, которую я использовал, является Faster R-CNN [1]. Он возвращает ограничивающие рамки для объектов на изображении, а не пикселей. Но работа сети на Jetson была слишком медленной для этого приложения. Идея ограничивающей рамки была очень привлекательной, поэтому я также посмотрел на ориентированную на вождение сеть [2]. Она также была слишком медленной. FCN [3] оказалась самой быстрой сетью сегментации, которую я попробовал. «FCN» означает «Полностью сверточная сеть», fully convolutional network, так как она больше не требует на вход какого-либо определенного размера изображения и состоит только из сверток/пулингов. Переключение только на сверточные слои приводит к значительному ускорению, классифицируя мои изображения примерно на 1/3 секунды на Jetson. FCN включает в себя хороший набор скриптов Python для обучения и простого развертывания. Сценарии Python изменяют размер сети, чтобы приспособиться к любому размеру входящего изображения, упрощая обработку основного изображения. У меня был победитель!
Релиз FCN GitHub имеет несколько вариантов. Сначала я попробовал voc-fcn32s. Он работал отлично. Voc-fcn32s был предварительно обучен на 20 стандартных voc-классах. Так как это слишком просто, я попробовал pascalcontext-fcn32s. Он был обучен на 59 классах, включая траву и деревья, поэтому я подумал, что это должно быть лучше. Но оказалось, что не всегда — на выходных изображениях было гораздо больше наборов пикселей, и сегментация кошек и людей, наложенных на траву и кусты, была не такой точной. Сегментация из siftflow была еще более сложной, поэтому я быстро вернулся к вариантам voc.
Выбор voc-сетей все еще означает, что нужно рассмотреть три: voc-fcn32s, voc-fcn16s и voc-fcn8s. Они отличаются «шагом» сегментации выходных данных. Шаг 32 является основным шагом сети: изображение 640x360 уменьшается до сети 20x11 к моменту завершения сверточных слоев. Эта грубая сегментация затем «деконволюционирует» обратно к 640x360, как описано в [3]. Шаг 16 и шаг 8 достигаются путем добавления большего количества логики в сеть для лучшей сегментации. Я даже не пробовал — 32-сегментная сегментация — первая, которую я попробовал и она подошла, и я придерживался её, потому что сегментация выглядит достаточно хорошо для этого проекта, а обучение, как описано, выглядит более сложным для двух других сетей.
Первое, что я заметил, когда включил и запустил систему, это то, что только около 30% кошек были опознаны сетью. Я нашел две причины этого. Во-первых, кошки часто приходят ночью, поэтому камера видит их в инфракрасном свете. Это можно легко исправить — просто добавьте несколько сегментированных инфракрасных изображений кошек для тренировки. Вторая проблема, которую я обнаружил после обзора нескольких сотен фотографий кошек из учебного набора, состоит в том, что многие фотографии относятся к разнообразию «взгляни на мою милую кошечку». Это фронтальные изображения кота на уровне кошачьего глаза. Или кошка лежит на спине или лежит на коленях у хозяина. Они не похожи на кошек, слоняющихся по моему двору. Опять же, можно легко исправить с помощью некоторых сегментированных дневных изображений.

Как сегментировать объект на тренировочном изображении? Мой подход состоит в том, чтобы вычесть фоновое изображение, а затем обработать пиксели переднего плана, чтобы указать отследить объект. На практике это работает довольно хорошо, потому что в моем архиве с камеры обычно есть изображение, которое было снято за несколько секунд до сегментируемого изображения. Но есть артефакты, которые нужно очистить, и сегментация часто нуждается в уточнении, поэтому я написал утилиту грубой подготовки для редактирования сегментов изображения, src / extract_fg.cpp. Смотрите примечание в верхней части исходного файла для использования. Она немного неуклюжа и имеет небольшие погрешности проверки и нуждается в некоторой доработке, но работает достаточно хорошо для задачи.
Теперь, когда у нас есть несколько изображений для обучения, давайте посмотрим, как это сделать. Я клонировал voc-fcn32s в каталог rgb_voc_fcn32s. Все имена файлов будут ссылаться на этот каталог до конца этого урока.
Код в моем github, включая пример учебного файла в data / rgb_voc. Основные изменения указаны далее.
Слой распределенных данных ожидает жестко закодированных изображений и каталогов сегментации. Учебный файл имеет одну строку на файл; затем слой данных получает имена файлов изображений и сегментов, добавляя жестко закодированные имена каталогов. Это не сработало для меня, потому что у меня есть несколько классов данных обучения. Мои тренировочные данные имеют набор строк, каждая из которых содержит изображение и сегментацию для этого изображения.
Я заменил voc_layers.py на rgb_voc_layers.py, который понимает новую схему:
И изменил train.prototxt, чтобы использовать мой код rgb_voc_layers. Обратите внимание, что аргументы тоже разные.
Почти то же самое изменение в val.prototxt:
Выполните solve.py, чтобы начать тренировку:
Он изменяет некоторые из нормальных механизмов Caffe. В частности, количество итераций задается в нижней части файла. В этой конкретной настройке итерация представляет собой одно изображение, потому что размер сети изменяется для каждого изображения, и изображения пропускаются по одному за раз.
Одна из замечательных особенностей работы в Nvidia — это то, что доступно действительно отличное оборудование. У меня есть Titan, встроенный в рабочую станцию, и мое руководство было не против разрешить мне использовать её для чего-то столь сомнительного, как этот проект. Мой последний тренировочный запуск составил 4000 итераций, что заняло чуть более двух часов на Титане.
Как видите, процесс итеративный.
[1] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun abs/1506.01497v3.
[2] An Empirical Evaluation of Deep Learning on Highway Driving Brody Huval, Tao Wang, Sameep Tandon, Jeff Kiske, Will Song, Joel Pazhayampallil, Mykhaylo Andriluka, Pranav Rajpurkar, Toki Migimatsu, Royce Cheng-Yue, Fernando Mujica, Adam Coates, Andrew Y. Ng arXiv:1504.01716v3, github.com/brodyh/caffe.git.
[3] Fully Convolutional Networks for Semantic Segmentation Jonathan Long, Evan Shelhamer, Trevor Darrell arXiv:1411.4038v2, github.com/shelhamer/fcn.berkeleyvision.org.git.
Для того, чтоб научить нейросеть распознавать ночных котов пришлось добавить необходимые данные, накопив их. После этого был проделан последний шаг — система подключается к вентилю, который запускает опрыскиватель. Идея в том, что как только кот заходит на лужайку и хочет приспособиться — его начинает поливать. Кот сваливает. Задача таким образом решена, жена довольна, а всё это странное чудо — нейронная сеть, обучающая распознавать котов, выяснившая, что в Интернете не хватает исходных изображений для тренировки и которая доучилась этому, стала единственной в мире нейронной сеткой, умеющей распознавать ночных котов.
Стоит отметить, что всё это было сделано человеком не являющимся гиперпрограммистом, который проработал в Яндексе или Google всю свою жизнь и с помощью железа, достаточно дешевого, компактного и простого.
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?

Проблему нужно было решать. Как же решил её Роберт? Он докупил немного железа к своему компьютеру, подключил к нему камеру наружного наблюдения, смотрящую за лужайкой, и дальше проделал несколько необычную вещь, он загрузил доступный бесплатный Open Source софт — нейросеть, и начинал обучать её распознавать котов на изображении с камеры. И задача в начале кажется тривиальной, ведь если чему-то учить и легко — это котам, потому что котами завален Интернет, их там десятки миллионов. Если было всё так просто, но дела обстоят хуже, в реальной жизни коты ходят гадить в основном ночью. Картинок ночных котов, писающих на лужайке, в Интернете практически нет. И некоторые из котов умудряются даже пить из системы полива во время работы, но всё же потом сваливают.

Ниже мы приводим описание проекта от автора, англоязычный вариант можно найти здесь.
Этот проект был мотивирован двумя вещами: желанием узнать больше о программном обеспечении нейронной сети и желанием поощрить соседских кошек болтаться где-нибудь ещё, кроме моей лужайки.
Проект включает в себя только три аппаратных компонента: плату Nvidia Jetson TX1, IP-камеру Foscam FI9800P и Particle Photon, подключенный к реле. Камера установлена на стороне дома со стороны лужайки. Она связывается с точкой доступа WI-FI, сопровождаемой Jetson. Particle Photon и реле установлены в блоке управления моей системы полива и подключены к точке доступа WI-FI на кухне.
В процессе работы камера настроена следить за изменениями во дворе. Когда что-то меняется, камера передает Jetson набор из 7 изображений, по одному в секунду. Служба, работающая на Jetson, отслеживает входящие изображения, передавая их в глубокую обучающую нейронную сеть Caffe. Если сеть обнаруживает кошку, Jetson сигнализирует серверу Particle Photon в облаке, который отправляет сообщение в Photon. Photon отвечает, включив разбрызгиватели на две минуты.
Здесь кот зашел в кадр, включив камеру:

Через несколько секунд кот выбрался на середину двора, снова включив камеру и активировал разбрызгиватели системы полива:

Установка камеры
В установке камеры не было ничего необычного. Единственное постоянное соединение — это 12-вольтовое проводное подключение, которое проходит через небольшое отверстие под карнизом. Я установил камеру на деревянный ящик, чтобы захватить передний двор с лужайкой. К камере подключена куча проводов, которые я спрятал в коробке.
Следуйте указаниям Foscam, чтобы связать его с AP Джетсона (см. ниже). В моей настройке Jetson находится на 10.42.0.1. Я выделил камере фиксированный IP-адрес 10.42.0.11, чтобы его было легко найти. Как только это будет сделано, подключите ноутбук с Windows к камере и настройте параметр «Предупреждение», чтобы активировать изменение. Настройте загрузку 7 изображений по FTP по предупреждению (алерту). Затем дайте ему идентификатор пользователя и пароль на Jetson. Моя камера отправляет изображения 640x360, отправляя их по FTP в свой домашний каталог.
Ниже Вы можете видеть параметры, которые были выбраны для конфигурации камеры.

Настройка Particle Photon
Photon был прост в настройке. Я поместил его в блок управления поливом.

Черный ящик слева с синим светодиодом представляет собой преобразователь 24 В переменного тока (AC) в 5 В постоянного тока (DC), куплен на еBay. Вы можете увидеть белое реле на плате реле и синий разъем спереди. Сам Photon находится справа. Оба приклеены к куску картона, чтобы скрепить их.
5 В выход с преобразователя подключен к VIN-разъему Particle Photon. Релейная плата в основном аналоговая: она имеет NPN-транзистор с открытым коллектором с номинальным 3,3 В входом на базу транзистора и 3 В реле. Регулятор фотона не мог подавать достаточный ток для управления реле, поэтому я подключил коллектор входа транзистора к 5 В через резистор с сопротивлением 15 Ом и мощностью 1/2 Вт, ограничивающий ток. Контакты реле подключаются к водяному вентелю параллельно с нормальной цепью управления.
Вот схема подключения:
24VAC converter 24VAC <---> Control box 24VAC OUT
24VAC converter +5V <---> Photon VIN, resistor to relay board +3.3V
24VAC converter GND <---> Photon GND, Relay GND
Photon D0 <---> Relay board signal input
Relay COM <---> Control box 24VAC OUT
Relay NO <---> Front yard water valve
Установка Jetson
Единственными аппаратными компонентами, добавленными в Jetson, являются накопитель SATA SSD и небольшой USB-концентратор Belkin. Концентратор имеет два беспроводных ключа, при помощи которых подключается клавиатура и мышь.
SSD подошел без проблем. Я переформатировал его в EXT4 и установил его как /caffe. Я настоятельно рекомендую удалить весь код вашего проекта, git-репозитории и данные приложений с внутренней SD-карты Jetson, потому что часто проще всего стереть систему во время обновления Jetpack.

Настройка беспроводной точки доступа была довольно простой (правда!), если вы будете следовать этому руководству. Просто используйте меню Ubuntu, как указано, и обязательно добавьте этот параметр конфигурации.
Я установил vsftpd в качестве FTP-сервера. Конфигурация в значительной степени стоковая. Я не включил анонимный FTP. Я дал камере имя пользователя и пароль, которые больше ни для чего не используются.
Я установил Caffe применив рецепт JetsonHacks. Я полагаю, что в текущих выпусках больше нет проблемы LMDB_MAP_SIZE, поэтому попробуйте собрать ее, прежде чем вносить изменения. Вы должны быть способны запустить тесты и timing demo, упомянутые в шелл-скрипте JetsonHacks. В настоящее время я использую Cuda 7.0, но я не уверен, что это имеет большое значение на данном этапе. Используйте CDNN, это экономит значительный объем памяти в этих небольших системах. Как только он будет собран, добавьте каталог сборки в переменную PATH, чтобы сценарии могли найти Caffe. Также добавьте каталог Caffe Python lib в вашу PYTHONPATH.
~ $ echo $PATH
/home/rgb/bin:/caffe/drive_rc/src:/caffe/drive_rc/std_caffe/caffe/build/tools:/usr/local/cuda-7.0/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
~ $ echo $PYTHONPATH
/caffe/drive_rc/std_caffe/caffe/python:
~ $ echo $LD_LIBRARY_PATH
/usr/local/cuda-7.0/lib:/usr/local/lib
Я использую вариант Fully Convolutional Network for Semantic Segmentation (FCN). Смотрите Berkeley Model Zoo, github.
Я попробовал несколько других сетей и, наконец, остановился на FCN. Подробнее о процессе выбора в следующей статье. Fcn32s хорошо работает на TX1 — он занимает чуть более 1 ГБ памяти, запускается примерно за 10 секунд и сегментирует изображение 640x360 примерно за треть секунды. В текущем репозитории github есть хороший набор сценариев, и настройка не зависит от размера изображения — он изменяет размер сети, чтобы соответствовать тому, что вы вбрасываете в неё.
Чтобы попробовать, вам понадобится развернуть уже обученные модели Caffe. Это займет несколько минут: размер файла fcn32s-heavy-pascal.caffemodel превышает 500 МБ.
$ cd voc-fcn32s
$ wget `cat caffemodel-url`
Отредактируйте infer.py, изменив путь в команде Image.open () на соответствующий .jpg. Измените строку «net», чтобы она указывала на только что загруженную модель:
-net = caffe.Net('fcn8s/deploy.prototxt', 'fcn8s/fcn8s-heavy-40k.caffemodel', caffe.TEST)
+net = caffe.Net('voc-fcn32s/deploy.prototxt', 'voc-fcn32s/fcn32s-heavy-pascal.caffemodel', caffe.TEST)
Вам понадобится файл voc-fcn32s / deploy.prototxt. Он легко генерируется из voc-fcn32s / train.prototxt. Посмотрите на изменения между voc-fcn8s / train.prototxt и voc-fcn8s / deploy.prototxt, чтобы увидеть, как это сделать, или вы можете получить это из моего репозитория chasing-cats на github. Теперь вы должны быть в состоянии запустить.
$ python infer.py
Мой репозиторий включает в себя несколько версий infer.py, несколько утилит Python, которые знают о сегментированных файлах, коде Photon и сценариях управления и операционных сценариях, которые я использую для запуска и мониторинга системы. Подробнее о программном обеспечении далее.
Выбор сети
Нейронные сети для распознавания изображений обычно обучаются распознавать набор объектов. Допустим, мы даем каждому объекту индекс от одного до n. Сеть классификации отвечает на вопрос «Какие объекты на этом изображении?» возвращая массив от нуля до n-1, где каждая запись массива имеет значение от нуля до единицы. Ноль означает, что объект не находится на изображении. Ненулевое значение означает, что оно может быть там с возрастающей вероятностью, когда значение приближается к единице. Вот кот и человек в массиве из 5 элементов:

Сегментная сеть сегментирует пиксели изображения областей, которые заняты объектами из нашего списка. Она отвечает на вопрос, возвращая массив с записью, соответствующей каждому пикселю в изображении. Каждая запись имеет значение ноль, если это фоновый пиксель, или значение от одного до n для n различных объектов, которые она способна распознавать. Этот выдуманный пример может быть ногой человека:

Этот проект является частью более крупного проекта, нацеленного на управление радиоуправляемым автомобилем при помощи компьютера. Идея состоит в том, чтобы использовать нейронную сеть, чтобы определить позицию (глобальное трехмерное положение и ориентацию) автомобиля для передачи ему навигационных команд. Камера закреплена, а газон в основном ровный. Я могу немного использовать триггер для изменения 3d-положения, чтоб нейронная сеть смогла найти пиксели экрана и ориентацию. Роль кошки во всем этом — «предполагаемое назначение».
Я начал с того, что думал в первую очередь об автомобиле, так как не знал, как это получится, предполагая, что распознать кошку с предварительно обученной сетью будет тривиально. После множества работ, которые я не буду подробно описывать в этой заметке, я решил, что можно определить ориентацию автомобиля с достаточно высокой степенью достоверности. Вот тренировочный снимок под углом 292,5 градуса:

Большая часть этой работы была проделана с сетью классификации, моделью Caffe bvlc_reference_caffenet. Поэтому я решил дать задании сети сегментации определить положение машины на экране.
Первой сетью, которую я использовал, является Faster R-CNN [1]. Он возвращает ограничивающие рамки для объектов на изображении, а не пикселей. Но работа сети на Jetson была слишком медленной для этого приложения. Идея ограничивающей рамки была очень привлекательной, поэтому я также посмотрел на ориентированную на вождение сеть [2]. Она также была слишком медленной. FCN [3] оказалась самой быстрой сетью сегментации, которую я попробовал. «FCN» означает «Полностью сверточная сеть», fully convolutional network, так как она больше не требует на вход какого-либо определенного размера изображения и состоит только из сверток/пулингов. Переключение только на сверточные слои приводит к значительному ускорению, классифицируя мои изображения примерно на 1/3 секунды на Jetson. FCN включает в себя хороший набор скриптов Python для обучения и простого развертывания. Сценарии Python изменяют размер сети, чтобы приспособиться к любому размеру входящего изображения, упрощая обработку основного изображения. У меня был победитель!
Релиз FCN GitHub имеет несколько вариантов. Сначала я попробовал voc-fcn32s. Он работал отлично. Voc-fcn32s был предварительно обучен на 20 стандартных voc-классах. Так как это слишком просто, я попробовал pascalcontext-fcn32s. Он был обучен на 59 классах, включая траву и деревья, поэтому я подумал, что это должно быть лучше. Но оказалось, что не всегда — на выходных изображениях было гораздо больше наборов пикселей, и сегментация кошек и людей, наложенных на траву и кусты, была не такой точной. Сегментация из siftflow была еще более сложной, поэтому я быстро вернулся к вариантам voc.
Выбор voc-сетей все еще означает, что нужно рассмотреть три: voc-fcn32s, voc-fcn16s и voc-fcn8s. Они отличаются «шагом» сегментации выходных данных. Шаг 32 является основным шагом сети: изображение 640x360 уменьшается до сети 20x11 к моменту завершения сверточных слоев. Эта грубая сегментация затем «деконволюционирует» обратно к 640x360, как описано в [3]. Шаг 16 и шаг 8 достигаются путем добавления большего количества логики в сеть для лучшей сегментации. Я даже не пробовал — 32-сегментная сегментация — первая, которую я попробовал и она подошла, и я придерживался её, потому что сегментация выглядит достаточно хорошо для этого проекта, а обучение, как описано, выглядит более сложным для двух других сетей.
Обучение
Первое, что я заметил, когда включил и запустил систему, это то, что только около 30% кошек были опознаны сетью. Я нашел две причины этого. Во-первых, кошки часто приходят ночью, поэтому камера видит их в инфракрасном свете. Это можно легко исправить — просто добавьте несколько сегментированных инфракрасных изображений кошек для тренировки. Вторая проблема, которую я обнаружил после обзора нескольких сотен фотографий кошек из учебного набора, состоит в том, что многие фотографии относятся к разнообразию «взгляни на мою милую кошечку». Это фронтальные изображения кота на уровне кошачьего глаза. Или кошка лежит на спине или лежит на коленях у хозяина. Они не похожи на кошек, слоняющихся по моему двору. Опять же, можно легко исправить с помощью некоторых сегментированных дневных изображений.

Как сегментировать объект на тренировочном изображении? Мой подход состоит в том, чтобы вычесть фоновое изображение, а затем обработать пиксели переднего плана, чтобы указать отследить объект. На практике это работает довольно хорошо, потому что в моем архиве с камеры обычно есть изображение, которое было снято за несколько секунд до сегментируемого изображения. Но есть артефакты, которые нужно очистить, и сегментация часто нуждается в уточнении, поэтому я написал утилиту грубой подготовки для редактирования сегментов изображения, src / extract_fg.cpp. Смотрите примечание в верхней части исходного файла для использования. Она немного неуклюжа и имеет небольшие погрешности проверки и нуждается в некоторой доработке, но работает достаточно хорошо для задачи.
Теперь, когда у нас есть несколько изображений для обучения, давайте посмотрим, как это сделать. Я клонировал voc-fcn32s в каталог rgb_voc_fcn32s. Все имена файлов будут ссылаться на этот каталог до конца этого урока.
$ cp -r voc-fcn32s rgb_voc_fcn32s
Код в моем github, включая пример учебного файла в data / rgb_voc. Основные изменения указаны далее.
Формат обучающего файла
Слой распределенных данных ожидает жестко закодированных изображений и каталогов сегментации. Учебный файл имеет одну строку на файл; затем слой данных получает имена файлов изображений и сегментов, добавляя жестко закодированные имена каталогов. Это не сработало для меня, потому что у меня есть несколько классов данных обучения. Мои тренировочные данные имеют набор строк, каждая из которых содержит изображение и сегментацию для этого изображения.
$ head data/rgb_voc/train.txt
/caffe/drive_rc/images/negs/MDAlarm_20160620-083644.jpg /caffe/drive_rc/images/empty_seg.png
/caffe/drive_rc/images/yardp.fg/0128.jpg /caffe/drive_rc/images/yardp.seg/0128.png
/caffe/drive_rc/images/negs/MDAlarm_20160619-174354.jpg /caffe/drive_rc/images/empty_seg.png
/caffe/drive_rc/images/yardp.fg/0025.jpg /caffe/drive_rc/images/yardp.seg/0025.png
/caffe/drive_rc/images/yardp.fg/0074.jpg /caffe/drive_rc/images/yardp.seg/0074.png
/caffe/drive_rc/images/yard.fg/0048.jpg /caffe/drive_rc/images/yard.seg/0048.png
/caffe/drive_rc/images/yard.fg/0226.jpg /caffe/drive_rc/images/yard.seg/0226.png
Я заменил voc_layers.py на rgb_voc_layers.py, который понимает новую схему:
--- voc_layers.py 2016-05-20 10:04:35.426326765 -0700
+++ rgb_voc_layers.py 2016-05-31 08:59:29.680669202 -0700
...
- # load indices for images and labels
- split_f = '{}/ImageSets/Segmentation/{}.txt'.format(self.voc_dir,
- self.split)
- self.indices = open(split_f, 'r').read().splitlines()
+ # load lines for images and labels
+ self.lines = open(self.input_file, 'r').read().splitlines()
И изменил train.prototxt, чтобы использовать мой код rgb_voc_layers. Обратите внимание, что аргументы тоже разные.
--- voc-fcn32s/train.prototxt 2016-05-03 09:32:05.276438269 -0700
+++ rgb_voc_fcn32s/train.prototxt 2016-05-27 15:47:36.496258195 -0700
@@ -4,9 +4,9 @@
top: "data"
top: "label"
python_param {
- module: "layers"
- layer: "SBDDSegDataLayer"
- param_str: "{\'sbdd_dir\': \'../../data/sbdd/dataset\', \'seed\': 1337, \'split\': \'train\', \'mean\': (104.00699, 116.66877, 122.67892)}"
+ module: "rgb_voc_layers"
+ layer: "rgbDataLayer"
+ param_str: "{\'input_file\': \'data/rgb_voc/train.txt\', \'seed\': 1337, \'split\': \'train\', \'mean\': (104.00699, 1
Почти то же самое изменение в val.prototxt:
--- voc-fcn32s/val.prototxt 2016-05-03 09:32:05.276438269 -0700
+++ rgb_voc_fcn32s/val.prototxt 2016-05-27 15:47:44.092258203 -0700
@@ -4,9 +4,9 @@
top: "data"
top: "label"
python_param {
- module: "layers"
- layer: "VOCSegDataLayer"
- param_str: "{\'voc_dir\': \'../../data/pascal/VOC2011\', \'seed\': 1337, \'split\': \'seg11valid\', \'mean\': (104.00699, 116.66877, 122.67892)}"
+ module: "rgb_voc_layers"
+ layer: "rgbDataLayer"
+ param_str: "{\'input_file\': \'data/rgb_voc/test.txt\', \'seed\': 1337, \'split\': \'seg11valid\', \'mean\': (104.00699, 116.66877, 122.67892)}"
Solver.py
Выполните solve.py, чтобы начать тренировку:
$ python rgb_voc_fcn32s / solve.py
Он изменяет некоторые из нормальных механизмов Caffe. В частности, количество итераций задается в нижней части файла. В этой конкретной настройке итерация представляет собой одно изображение, потому что размер сети изменяется для каждого изображения, и изображения пропускаются по одному за раз.
Одна из замечательных особенностей работы в Nvidia — это то, что доступно действительно отличное оборудование. У меня есть Titan, встроенный в рабочую станцию, и мое руководство было не против разрешить мне использовать её для чего-то столь сомнительного, как этот проект. Мой последний тренировочный запуск составил 4000 итераций, что заняло чуть более двух часов на Титане.
Я узнал несколько вещей
- Горстки изображений (менее 50) было достаточно, чтобы обучить сеть распознавать ночных нарушителей.
- Ночные снимки обучили сеть думать, что тени на пешеходной дорожке — это кошки.
- Негативные снимки, то есть изображения без сегментированных пикселей, помогают бороться с проблемой теней.
- Легко переобучить сеть с помощью стационарной камеры, чтобы все, что отличается, классифицировалось как нечто случайное.
- Кошки и люди, наложенные на случайные фоны, помогают с проблемами, возникающими при перетренировке.
Как видите, процесс итеративный.
Рекомендации
[1] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun abs/1506.01497v3.
[2] An Empirical Evaluation of Deep Learning on Highway Driving Brody Huval, Tao Wang, Sameep Tandon, Jeff Kiske, Will Song, Joel Pazhayampallil, Mykhaylo Andriluka, Pranav Rajpurkar, Toki Migimatsu, Royce Cheng-Yue, Fernando Mujica, Adam Coates, Andrew Y. Ng arXiv:1504.01716v3, github.com/brodyh/caffe.git.
[3] Fully Convolutional Networks for Semantic Segmentation Jonathan Long, Evan Shelhamer, Trevor Darrell arXiv:1411.4038v2, github.com/shelhamer/fcn.berkeleyvision.org.git.
Выводы
Для того, чтоб научить нейросеть распознавать ночных котов пришлось добавить необходимые данные, накопив их. После этого был проделан последний шаг — система подключается к вентилю, который запускает опрыскиватель. Идея в том, что как только кот заходит на лужайку и хочет приспособиться — его начинает поливать. Кот сваливает. Задача таким образом решена, жена довольна, а всё это странное чудо — нейронная сеть, обучающая распознавать котов, выяснившая, что в Интернете не хватает исходных изображений для тренировки и которая доучилась этому, стала единственной в мире нейронной сеткой, умеющей распознавать ночных котов.
Стоит отметить, что всё это было сделано человеком не являющимся гиперпрограммистом, который проработал в Яндексе или Google всю свою жизнь и с помощью железа, достаточно дешевого, компактного и простого.
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
