

Платформа .NET предоставляет множество готовых примитивов синхронизации и потокобезопасных коллекций. Если при разработке приложения нужно реализовать, например, потокобезопасный кэш или очередь запросов — обычно используются эти готовые решения, иногда сразу несколько. В отдельных случаях это приводит к проблемам с производительностью: долгим ожиданием на блокировках, избыточному потреблению памяти и долгим сборкам мусора.
Эти проблемы можно решить, если учесть, что стандартные решения сделаны достаточно общими — они могут иметь избыточный в наших сценариях оверхед. Соответственно, можно написать, например, собственную эффективную потокобезопасную коллекцию для конкретного случая.
Под катом — видео и расшифровка моего доклада с конференции DotNext, где я разбираю несколько примеров, когда использование средств из стандартной библиотеки .NET (Task.Delay, SemaphoreSlim, ConcurrentDictionary) привело к просадкам производительности, и предлагаю решения, заточенные под конкретные задачи и лишённые этих недостатков.
На момент доклада работал в Контуре. Контур разрабатывает различные приложения для бизнеса, а команда, в которой работал я, занимается инфраструктурой и разрабатывает различные вспомогательные сервисы и библиотеки, помогающие разработчикам в других командах делать продуктовые сервисы.
Команда Инфраструктуры делает свое хранилище данных, систему хостинга приложений под Windows и различные библиотеки для разработки микросервисов. Наши приложения основаны на микросервисной архитектуре — все сервисы взаимодействуют между собой по сети, и, естественно, в них используется довольно много асинхронного и многопоточного кода. Некоторые из этих приложений довольно критичны по производительности, им нужно уметь обрабатывать много запросов.
О чём мы сегодня будем говорить?
- Многопоточность и асинхронность в .NET;
- Начинка примитивов синхронизации и коллекций;
- Что делать, если стандартные подходы не справляются с нагрузкой?
Разберем некоторые особенности работы с многопоточным и асинхронным кодом в .NET. Разберём некоторые примитивы синхронизации и concurrent-коллекции, посмотрим, как они устроены внутри. Обсудим, что делать, если не хватило производительности, если стандартные классы не справляются с нагрузкой и можно ли в этой ситуации что-либо сделать.
Расскажу четыре истории, которые произошли у нас на продакшене.
История 1: Task.Delay & TimerQueue
Эта история уже довольно известная, о ней рассказывали в том числе и на предыдущих DotNext. Тем не менее, она получила довольно интересное продолжение, поэтому я её добавил. Итак, в чём суть?
1.1 Polling и long polling
Сервер выполняет долгие операции, клиент – ждет их.
Polling: клиент периодически спрашивает сервер про результат.
Long polling: клиент отправляет запрос с большим таймаутом, а сервер отвечает по завершению операции.
Преимущества:
- Меньший объем трафика
- Клиент узнает о результате быстрее
Представьте, что у нас есть сервер, который умеет обрабатывать какие-то долгие запросы, например, приложение, которое конвертирует XML-файлы в PDF, и есть клиенты, которые запускают эти задачи на обработку и хотят дожидаться их результата асинхронно. Как такое ожидание можно реализовать?
Первый способ — это polling. Клиент запускает задачу на сервере, дальше периодически проверяет статус этой задачи, при этом сервер возвращает статус задачи («выполнена»/«не выполнена»/«завершилась с ошибкой»). Клиент периодически отправляет запросы, пока не появится результат.
Второй способ — long polling. Здесь отличие в том, что клиент отправляет запросы с большими таймаутами. Сервер, получая такой запрос, не сразу сообщит о том, что задача не выполнена, а попробует некоторое время подождать появления результата.
Так в чем же преимущество long polling'а перед обычным polling'ом? Во-первых, генерируется меньший объём трафика. Мы делаем меньше сетевых запросов — меньше трафика гоняется по сети. Также клиент сможет узнать о результате быстрее, чем при обычном polling'е, потому что ему не надо ждать промежутка между несколькими запросами polling'а. Что мы хотим получить — понятно. Как мы будем реализовывать это в коде?
Задача: timeoutНапример, у нас есть Task, который отправляет запрос на сервер, и мы хотим подождать его результата с таймаутом, то есть мы либо вернём результат этого Task'а, либо отправим какую-то ошибку. Код на С# будет выглядеть так:
Хотим подождать Task с таймаутом
await SendAsync ();
var sendTask = SendAsync();
var delayTask = Task.Delay(timeout);
var task = await Task.WhenAny(sendTask, delayTask);
if (task == delayTask)
return Timeout;Данный код запускает наш Task, результат которого хотим ждать, и Task.Delay. Далее, используя Task.WhenAny, ждём либо наш Task, либо Task.Delay. Если получится так, что первым выполнится Task.Delay, значит, время вышло и у нас случился таймаут, мы должны вернуть ошибку.
Этот код, конечно, не идеален и его можно доработать. Например, здесь бы не помешало отменить Task.Delay, если SendAsync вернулся раньше, но это нас сейчас не очень интересует. Суть в том, что, если мы напишем такой код и применим его при long polling'е с большими таймаутами, мы получим некоторые перформансные проблемы.
1.2 Проблемы при long polling
- Большие таймауты
- Много параллельных запросов
- => Высокая загрузка CPU
В этом случае, проблема — высокое потребление ресурсов процессора. Может получиться так, что процессор загрузится полностью на 100%, и приложение вообще перестанет работать. Казалось бы, мы вообще не потребляем ресурсов процессора: мы делаем какие-то асинхронные операции, дожидаемся ответа с сервера, а процессор у нас всё равно загружен.
Когда мы с этой ситуацией столкнулись, мы сняли дамп памяти с нашего приложения:
~*e!clrstack
System.Threading.Monitor.Enter(System.Object)
System.Threading.TimerQueueTimer.Change(…)
System.Threading.Timer.TimerSetup(…)
System.Threading.Timer..ctor(…)
System.Threading.Tasks.Task.Delay(…)Для анализа дампа мы использовали инструмент WinDbg. Ввели команду, которая показывает stack trace'ы всех managed-потоков, и увидели такой результат. У нас есть очень много потоков в процессе, которые ждут на некотором lock'е. Метод Monitor.Enter — это то, во что разворачивается конструкция lock в C#. Этот lock захватывается внутри классов под названием Timer и TimerQueueTimer. В Timer'ы мы пришли как раз из Task.Delay при попытке их создания. Что получается? При запуске Task.Delay захватывается блокировка внутри TimerQueue.
1.3 Lock convoy
- Много потоков пытаются захватить один lock
- Под lock'ом выполняется мало кода
- Время тратится на синхронизацию потоков, а не на выполнение кода
- Блокируются потоки из тредпула – они не бесконечны
У нас произошёл lock convoy в приложении. Много потоков пытаются захватить один и тот же lock. Под этим lock'ом выполняется довольно мало кода. Ресурсы процессора здесь расходуются не на сам код приложения, а именно на операции по синхронизации потоков между собой на этом lock'е. Надо ещё отметить особенность, связанную с .NET: потоки, которые участвуют в lock convoy, — это потоки из тредпула.
Соответственно, если у нас блокируются потоки из тредпула, они могут закончиться — количество потоков в тредпуле ограничено. Его можно настроить, но при этом верхний предел всё равно есть. После его достижения все тредпульные потоки будут участвовать в lock convoy, и в приложении перестанет выполняться вообще какой-либо код, задействующий тредпул. Это значительно ухудшает ситуацию.
1.4 TimerQueue
- Управляет таймерами в .NET-приложении.
- Таймеры используются в:
— Task.Delay
— CancellationTocken.CancelAfter
— HttpClient
TimerQueue — это некоторый класс, который управляет всеми таймерами в .NET-приложении. Если вы когда-то программировали на WinForms, возможно, вы создавали таймеры вручную. Для тех, кто не знает, что такое таймеры: они используются в Task.Delay (это как раз наш случай), также они используются внутри CancellationToken, в методе CancelAfter. То есть замена Task.Delay на CancellationToken.CancelAfter нам бы никак не помогла. Кроме этого, таймеры используются во многих внутренних классах .NET, например, в HttpClient.
Насколько я знаю, в некоторых реализациях HttpClient handler'ов задействованы таймеры. Даже если вы ими не пользуетесь явно, не запускаете Task.Delay, скорее всего, вы их всё равно так или иначе используете.
Теперь давайте посмотрим на то, как TimerQueue устроен внутри.
- Global state (per-appdomain):
— Double linked list of TimerQueueTimer
— Lock object - Routine, запускающая коллбэки таймеров
- Таймеры не упорядочены по времени срабатывания
- Добавление таймера: O(1) + lock
- Удаление таймера: O(1) + lock
- Запуск таймеров: O(N) + lock
Внутри TimerQueue есть глобальное состояние, это двусвязный список объектов типа TimerQueueTimer. TimerQueueTimer содержит в себе ссылку на другие TimerQueueTimer, на соседние в связном списке, также он содержит время срабатывания таймера и callback, который будет вызван при срабатывании таймера. Этот двусвязный список защищается lock-объектом, как раз тем, на котором в нашем приложении случился lock convoy. Также внутри TimerQueue есть Routine, которая запускает callback'и, привязанные к нашим таймерам.
Таймеры никак не упорядочены по времени срабатывания, вся структура оптимизирована под добавление/удаление новых таймеров. Когда запускается Routine, она пробегается по всему двусвязному списку, выбирает те таймеры, которые должны сработать, и вызывает для них callback'и.
Сложности операции здесь получаются такие. Добавление и удаление таймера происходит за O от единицы, а запуск таймеров происходит за линию. При этом если с алгоритмической сложностью здесь всё приемлемо, есть одна проблема: все эти операции захватывают блокировку, что не очень хорошо.
Какая ситуация может произойти? У нас в TimerQueue скопилось слишком много таймеров, соответственно, когда запускается Routine, она захватывает lock на свою долгую линейную операцию, в это время те, кто пытается запустить или удалить таймеры из TimerQueue, ничего с этим сделать не могут. Из-за этого происходит lock convoy. Эта проблема была исправлена в .NET Core.
Reduce Timer lock contention (coreclr#14527)Как её исправили? Расшардили TimerQueue: вместо одной TimerQueue, которая была статической на весь AppDomain, на всё приложение, сделали несколько TimerQueue. Когда туда приходят потоки и пытаются запустить свои таймеры, эти таймеры попадут в случайную TimerQueue, и у потоков будет меньше вероятность столкнуться на одной блокировке.
- Lock sharding
— Environment.ProcessorCount TimerQueue's TimerQueueTimer- Separate queues for short/long-living timers
- Short timer: time <= 1/3 second
https://github.com/dotnet/coreclr/issues/14462
https://github.com/dotnet/coreclr/pull/14527
Также в .NET Core применили некоторые оптимизации. Разделили таймеры на долгоживущие и короткоживущие, для них теперь используются отдельные TimerQueue. Время короткоживущего таймера выбрали меньше 1/3 секунды. Не знаю, почему именно такую константу выбрали. В .NET Core проблемы с таймерами нам поймать никак не удалось.

https://github.com/Microsoft/dotnet-framework-early-access/blob/master/release-notes/NET48/dotnet-48-changes.md
https://github.com/dotnet/coreclr/labels/netfx-port-consider
Этот фикс бэкпортнули в .NET Framework, в версию 4.8. Выше в ссылке указан тег netfx-port-consider, если зайдёте в репозиторий .NET Core, CoreCLR, CoreFX, по этому тегу можете поискать issue, которые будут бэкпортиться в .NET Framework, сейчас их там порядка пятидесяти. То есть опенсорс .NET сильно помог, довольно много багов было исправлено. Можете почитать changelog .NET Framework 4.8: исправлено очень много багов, гораздо больше, чем в других релизах .NET. Что интересно, этот фикс по умолчанию в .NET Framework 4.8 выключен. Он включается во всем вам известном файле под названием App.config
Настройка в App.config, которая включает этот фикс, называется UseNetCoreTimer. До того, как вышел .NET Framework 4.8, чтобы наше приложение работало и не уходило в lock convoy, приходилось использовать свою реализацию Task.Delay. В ней мы попробовали использовать бинарную кучу, чтобы более эффективно понимать, какие таймеры нужно сейчас вызывать.
1.5 Task.Delay: собственная реализация
- BinaryHeap
- Sharding
- Помогло, но не во всех случаях
Использование бинарной кучи позволяет оптимизировать Routine, которая вызывает callback'и, но ухудшает время удаления произвольного таймера из очереди — для этого нужно перестраивать кучу. Скорее всего, именно поэтому в .NET используется двусвязный список. Конечно, только лишь использование бинарной кучи нам здесь бы не помогло, также пришлось расшардить TimerQueue. Это решение какое-то время работало, но потом всё равно всё снова упало в lock convoy из-за того, что таймеры используются не только там, где они запускаются в коде явно, но и в сторонних библиотеках и коде .NET. Чтобы полностью исправить эту проблему, необходимо обновиться до .NET Framework версии 4.8 и включить фикс от разработчиков .NET.
1.6 Task.Delay: выводы
- Подводные камни везде — даже в самых используемых вещах
- Проводите нагрузочное тестирование
- Переходите на Core, получайте багфиксы (и новые баги) первыми :)
Какие выводы из всей этой истории? Во-первых, подводные камни могут находиться реально везде, даже в тех классах, которые вы используете каждый день, не задумываясь, например, те же Task'и, Task.Delay.
Рекомендую проводить нагрузочное тестирование ваших предложений. Вот эту проблему мы как раз выявили ещё на этапе нагрузочного тестирования. Она у нас потом ещё несколько раз выстрелила на продакшне в других приложениях, но, тем не менее нагрузочное тестирование нам помогло отдалить время до того, как мы столкнулись с этой проблемой в реальности.
Переходите на .NET Core — вы будете получать исправления багов (и новые баги) самыми первыми. Куда же без новых багов?
На этом история про таймеры закончилась, и мы переходим к следующей.
История 2: SemaphoreSlim
Следующая история про широко известный SemaphoreSlim.
2.1 Серверный троттлинг
- Требуется ограничить число параллельно обрабатываемых запросов на сервере
Мы хотели реализовать троттлинг на сервере. Что это такое? Наверное, вы все знаете троттлинг по CPU: когда процессор перегревается, он сам снижает свою частоту, чтобы охладиться, и у него за счет этого ограничивается производительность. Так же и здесь. Мы знаем, что наш сервер умеет обрабатывать параллельно N запросов и не падать при этом. Что мы хотим сделать? Ограничить количество одновременно обрабатываемых запросов этой константой и сделать так, что, если к нему приходит больше запросов, они встают в очередь и ждут, пока выполнятся те запросы, которые пришли раньше. Как эту задачу можно решать? Надо использовать какой-то примитив синхронизации.
Semaphore — примитив синхронизации, на котором можно подождать N раз, после чего тот, кто придёт N + первым и так далее, будет ждать на нём, пока Semaphore не освободят те, кто зашли под него раньше. Получается примерно вот такая картина: два потока выполнения, два воркера прошли под Semaphore, остальные — встали в очередь.
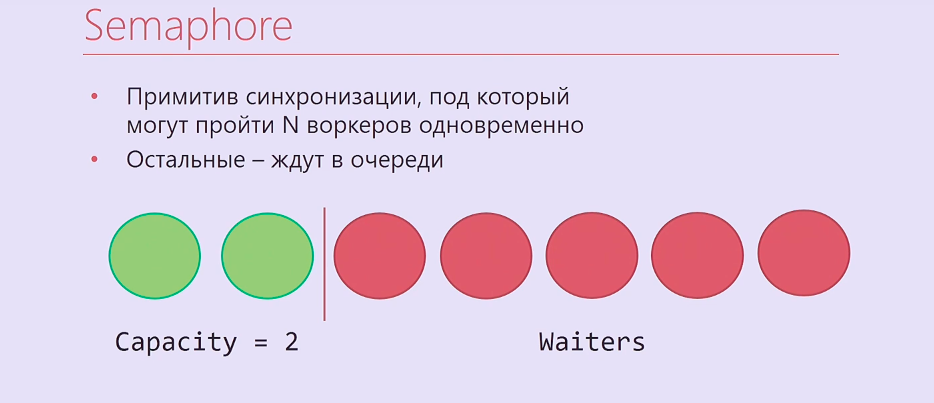
Конечно, просто Semaphore нам не очень подойдёт, он в .NET синхронный, поэтому мы взяли SemaphoreSlim и написали такой код:
var semaphore = new SemaphoreSlim(N);
…
await semaphore.WaitAsync();
await HandleRequestAsync(request);
semaphore.Release();Создаём SemaphoreSlim, ждём на нём, под Semaphore обрабатываем ваш запрос, после этого Semaphore освобождаем. Казалось бы, это идеальная реализация серверного троттлинга, и лучше быть уже не может. Но всё гораздо сложнее.
2.2 Серверный троттлинг: усложнение
- Обработка запросов в LIFO порядке
- SemaphoreSlim
- ConcurrentStack
- TaskCompletionSource
Мы немного забыли про бизнес-логику. Запросы, которые приходят на троттлинг, являются реальными http-запросами. У них есть, как правило, некоторый таймаут, который задан тем, кто отправил этот запрос автоматически, или таймаут пользователя, который нажмёт F5 через какое-то время. Соответственно, если обрабатывать запросы в порядке очереди, как обычный Semaphore, то в первую очередь будут обрабатываться те запросы из очереди, у которых таймаут, возможно, уже истёк. Если же работать в порядке стека — обрабатывать в первую очередь те запросы, которые пришли самыми последними, такой проблемы не возникнет.
Кроме SemaphoreSlim нам пришлось использовать ConcurrentStack, TaskCompletionSource, навернуть очень много кода вокруг всего этого, чтобы всё работало в том порядке, как нам нужно. TaskCompletionSource — это такая штука, которая похожа на CancellationTokenSource, только не для CancellationToken, а для Task'а. Вы можете создать TaskCompletionSource, вытащить из него Task, отдать его наружу и потом сказать TaskCompletionSource, что надо выставить результат этому Task'у, и об этом результате узнают те, кто на этом Task'е ждёт.
Мы всё это реализовали. Код получился ужасным. и, что хуже всего, он оказался нерабочим.
Спустя несколько месяцев с начала его использования в довольно высоконагруженном приложении мы столкнулись с проблемой. Точно так же, как и в предыдущем случае, возросло потребление CPU до 100 %. Мы проделали аналогичные действия, сняли дамп, посмотрели его в WinDbg, и снова обнаружили lock convoy.

В этот раз Lock convoy произошёл внутри SemaphoreSlim.WaitAsync и SemaphoreSlim.Release. Выяснилось, что внутри SemaphoreSlim есть блокировка, он не lock-free. Это оказалось для нас довольно серьезным недостатком.

Внутри SemaphoreSlim есть внутреннее состояние (счётчик того, сколько под него ещё могут пройти воркеров), и двусвязный список тех, кто на этом Semaphore ждёт. Идеи здесь примерно такие же: можно подождать на этом Semaphore, можно отменить своё ожидание — удалиться из этой очереди. Есть блокировка, которая как раз нам жизнь и попортила.
Мы решили: долой весь ужасный код, который нам пришлось написать.

Давайте напишем свой Semaphore, который сразу будет lock-free и который будет сразу работать в порядке стека. Отмена ожидания при этом нам не важна.

Определим данное состояние. Здесь будет число currentCount — это сколько ещё мест осталось в Semaphore. Если мест в Semaphore не осталось, то это число будет отрицательным и будет показывать, сколько воркеров находится в очереди. Также будет ConcurrentStack, состоящий из TaskCompletionSource'ов — это как раз стек waiter'ов, из которых они при необходимости будут вытаскиваться. Напишем метод WaitAsync.
var decrementedCount = Interlocked.Decrement(ref currentCount);
if (decrementedCount >= 0)
return Task.CompletedTask;
var waiter = new TaskCompletionSource<bool>();
waiters.Push(waiter);
return waiter.Task;Сначала мы уменьшаем счётчик, забираем себе одно место в Semaphore, если у нас были свободные места, и потом говорим: «Всё, ты прошёл под Semaphore».
Если мест в Semaphore не было, мы создаём TaskCompletionSource, кидаем его в стек waiter'ов и возвращаем во внешний мир Task'у. Когда придёт время, эта Task'а отработает, и воркер сможет продолжить свою работу и пройдёт под Semaphore.
Теперь напишем метод Release.
var countBefore = Interlocked.Increment(ref currentCount) - 1;
if (countBefore < 0)
{
if (waiters.TryPop(out var waiter))
waiter.TrySetResult(true);
}Метод Release выглядит следующим образом:
- Освобождаем одно место в Semaphore
- Инкрементим currentCount
Если по currentCount можно сказать, есть ли внутри стека waiter'ы, о которых нужно сигнализировать, мы такие waiter'а вытаскиваем из стека и сигнализируем. Здесь waiter — это TaskCompletionSource. Вопрос к этому коду: он вроде бы логичный, но он вообще работает? Какие здесь есть проблемы? Есть нюанс, связанный с тем, где запускаются continuation'ы и TaskCompletionSource'ы.

Рассмотрим этот код. Мы создали TaskCompletionSource и запустили два Task'а. Первый Task выводит единицу, выставляет результат в TaskCompletionSource, а дальше выводит на консоль двойку. Второй Task ждёт на этом TaskCompletionSource, на его Task'е, а затем навсегда блокирует свой поток из тредпула.
Что здесь произойдёт? Task 2 при компиляции разделится на два метода, второй из которых — continuation, содержащий Thread.Sleep. После выставления результата TaskCompletionSource, этот continuation выполнится в том же потоке, в котором выполнялся первый Task. Соответственно, поток первого Task'а будет навсегда заблокирован, и двойка на консоль уже не напечатается.
Что интересно, я пробовал поменять этот код, и если я убирал вывод на консоль единицы, continuation запускался на другом потоке из тредпула и двойка печаталась. В каких случаях continuation будет выполнен в том же потоке, а в каких — попадёт на тредпул — вопрос для читателей.
var tcs = new TaskCompletionSource<bool>(
TaskCreationOptions.RunContinuationsAsynchronously);
/* OR */
Task.Run(() => tcs.TrySetResult(true));Для решения этой проблемы мы можем либо создавать TaskCompletionSource с соответствующим флагом RunContinuationsAsynchronously, либо вызывать метод TrySetResult внутри Task.Run/ThreadPool.QueueUserWorkItem, чтобы он выполнялся не на нашем потоке. Если он будет выполняться на нашем потоке, у нас могут возникнуть нежелательные side effect'ы. Вдобавок здесь есть вторая проблема, остановимся на ней подробнее.

Посмотрите на методы WaitAsync и Release и попробуйте найти в методе Release ещё одну проблему.
Скорее всего, найти ее так просто невозможно. Здесь есть гонка.

Она связана с тем, что в методе WaitAsync изменение состояния не атомарно. Вначале мы декрементим счётчик и только потом пушим waiter'а на стек. Если так получится, что Release выполнится между декрементом и пушем, то может выйти так, что он ничего не вытащит из стека. Это нужно учесть, и в методе Release дожидаться появления waiter'а в стеке.
var countBefore = Interlocked.Increment(ref currentCount) - 1;
if (countBefore < 0)
{
Waiter waiter;
var spinner = new SpinWait();
while (!waiter.TryPop(out waiter))
spinner.SpinOnce();
waiter.TrySetResult(true);
}Здесь мы это делаем в цикле, пока у нас не получается его вытащить. Чтобы лишний раз не тратить циклы процессора, мы используем SpinWait.
В первые несколько итераций он будет крутиться по циклу. Если итераций станет много, waiter долго не будет появляться, то наш поток уйдет в Thread.Sleep, чтобы лишний раз не расходовать ресурсы CPU.
На самом деле, Semaphore с LIFO-порядком — это не только наша идея.
LowLevelLifoSemaphoreТакой Semaphore есть в самом .NET, но не в CoreCLR, не в CoreFX, а в CoreRT. Иногда бывает довольно полезно заглядывать в репозитории .NET. Здесь есть Semaphore под названием LowLevelLifoSemaphore. Этот Semaphore нам бы всё равно не подошёл: он синхронный.
- Синхронный
- На Windows использует в качестве стека Windows IO Completion port
https://github.com/dotnet/corert/blob/master/src/System.Private.CoreLib/src/System/Threading/LowLevelLifoSemaphore.cs
Что примечательно, на Windows он работает через IO Completion-порты. У них есть свойство, что на них могут ждать потоки, и эти потоки будут релизиться как раз в LIFO-порядке. Эта особенность там используется, он действительно LowLevel.
2.3 Выводы:
- Не надейтесь, что начинка фреймворка выживет под вашей нагрузкой
- Проще решать конкретную задачу, чем общий случай
- Нагрузочное тестирование помогает не всегда
- Опасайтесь блокировок
Какие выводы из всей этой истории? Во-первых, не надейтесь, что какие-то классы из фреймворка, которые вы используете из стандартной библиотеки, справятся с вашей нагрузкой. Я не хочу сказать, что SemaphoreSlim плохой, просто он оказался неподходящим конкретно в данном сценарии.
Нам оказалась гораздо проще написать свой Semaphore для конкретной задачи. Например, он не поддерживает отмену ожидания. Эта возможность есть в обычном SemaphoreSlim, у нас её нет, но это позволило упростить код.
Нагрузочное тестирование, хоть оно и помогает, может помочь далеко не всегда.
.NET известен тем, что у него довольно часто в неожиданных местах есть блокировки — их лучше опасаться. Если в своём коде вы пишете конструкцию lock, лучше задуматься: «Какая реально здесь будет нагрузка?» И если вдруг потребление CPU 100%, все потоки стоят на lock'е, то, возможно, это происходит где-то внутри .NET. Просто имейте в виду такую возможность.
Переходим к следующей истории.
История 3: (A)sync IO
История про асинхронный ввод/вывод, который оказался не таким уж асинхронным.

Здесь также случился lock convoy, он произошёл по stack trace внутри класса под названием Overlapped и PinnableBufferCache. Там оказался lock. Что же это за классы: Overlapped и PinnableBufferCache?
OVERLAPPED — это структура в Windows, которая используется для всех операций ввода/вывода. У нас было довольно нагруженное приложение, это один из шардов нашей распределённой файловой системы. Он много работает и с файлами на диске, и сетью. И таких структур ему понадобилось очень много, вследствие этого и выявился lock convoy. Мы стали разбираться, в чём вообще причина этого lock convoy, почему раньше всё работало, а сейчас перестало.

Надо заметить, что эта история произошла уже довольно давно, во времена .NET 4.5.1 и 4.5.2. Тогда как раз вышел .NET 4.5.2, и отличие оказалось в изменениях, которые появились в .NET 4.5.2. В .NET 4.5.1 был класс под названием OverlappedDataCache, представлявший собой пул этих объектов Overlapped — действительно, зачем их создавать на каждую асинхронную операцию, проще сделать пул. Этот пул был хороший, был lock-free, основанный на ConcurrentStack, и с ним не возникало никаких проблем. В .NET 4.5.2 решили оптимизировать пуллинг этих объектов: убрали OverlappedDataCache и сделали PinnableBufferCache.
В чём отличие? PinnableBufferCache сделан с расчётом на то, что объекты Overlapped нужно передавать в нативный код, при этом объекты пиннятся, а пиннить объекты в младших поколениях — это дополнительная нагрузка на сборщик мусора. Соответственно, наружу бы неплохо отдавать объекты, которые уже попали во второе поколение. PinnableBufferCache был разбит на две части. Первая часть хорошая, lock-free, основанная на ConcurrentStack. Она предназначена для тех объектов, которые уже попали во второе поколение. Внутри этого пула есть вторая часть для объектов, которые ещё находятся в нулевом и первом поколении, и почему-то для них вместо lock-free структуры используется обычный list с lock'ом.
3.1 PinnableBufferCache
LockConvoy:
- Если закончились буферы
- При возврате объектов в пул
Здесь lock convoy происходил тогда, когда заканчивались буфер-объекты и нужно было создавать новые. В таком случае они попадают в плохой list при возврате этих объектов в пул, поскольку при возврате объектов lock захватывается для того, чтобы проверить, а не пора ли объекты из пула для нулевого и первого поколения переносить во второе поколение.
Мы стали изучать код PinnableBufferCache и обнаружили, что в нём есть обращение к недокументированной переменной окружения. Она называлась вот так:
PinnableBufferCache_System.ThreadingOverlappedData_MinCountЭта переменная позволяла задать количество объектов, которые будут находиться в пуле изначально. Мы решили: «Отличная возможность! Давайте ей воспользуемся и поставим в эту переменную какое-нибудь большое число». Теперь у нас в приложении появился вот такой вуду-код:
Environment.SetEnvironmentVariable(
"PinnableBufferCache_System.Threading.OverlappedData_MinCount", "10000");
new Overlapped().GetHashCode();
for (int i = 0; i < 3; i++)
GC.Collect(GC.MaxGeneration, GCCollectionMode.Forced);Что мы здесь делаем? Мы вначале выставляем переменную окружения, затем создаём объект Overlapped для того, чтобы пул инициализировался, а затем несколько раз вручную вызываем сборку мусора. Сборка мусора вызывается для того, чтобы все объекты, которые находятся в этом пуле, попали уже во второе поколение, и PinnableBufferCache от нас отстал со своим lock convoy'ем. Это решение оказалось рабочим, и оно до сих пор живо в нашем коде для фреймворка.
На .NET Core от PinnableBufferCache избавились тем, что перенесли OverlappedData в нативную память. Соответственно, пиннинг их в памяти уже стал не нужен, Garbage collector их никуда передвинуть не может, так как они в нативной памяти. На этом история в .NET Core и закончилась. В .NET Framework, если не ошибаюсь, ещё этот фикс не перенесли.
3.2 Выводы:
- Не все оптимизации одинаково полезны
- На этот раз просто повезло
- И снова .NET Core
Здесь явно хотели сделать как лучше, уменьшив нагрузку на сборщик мусора. Нам очень повезло, что разработчиками .NET была предусмотрена возможность задать минимальное количество объектов для этого пула через переменную, иначе нам бы пришлось писать хак пострашнее. И, опять же, попробуйте .NET Core. Возможно, это решит ваши перформансные проблемы, и вам даже не придётся для этого писать вуду-код.
Теперь перейдём к key-value коллекциям.
История 4: Concurrent key-value collections
В .NET есть несколько concurrent-коллекций. Это lock-free коллекции ConcurrentStack и ConcurrentQueuе, с которыми у нас не возникало проблем. Есть коллекция ConcurrentDictionary, с ней всё интереснее. Она не lock-free на запись, там есть блокировки, но сейчас речь не о них. Почему вообще используют ConcurrentDictionary?
4.1 ConcurrentDictionary
Применения:
- Кэш
- Индекс
Плюсы:
- Входит в стандартную библиотеку
- Удобные операции (TryAdd/TryUpdate/AddOrUpdate)
- Lock-free чтения
- Lock-free enumeration
Его часто используют под различные кэши, memory-индексы, прочие структуры, в которые нужно уметь обращаться из нескольких потоков. Его любят за то, что он абсолютно стандартный, есть даже в .NET Framework. У него есть довольно удобные операции именно для работы из нескольких потоков. И, что важно, у него чтение и перечисление (enumeration) lock-free. Конечно, есть и подвохи.
Давайте рассмотрим, как устроена коллекция, основанная на хэш-таблице в .NET. Большинство key-value коллекций основано на хэш-таблицах и выглядят примерно так:

Вычисляется хэш-код, берётся по модулю количество bucket'ов. В самой коллекции есть несколько bucket'ов, в которых хранятся элементы. Если происходит коллизия, то в один bucket попадает несколько элементов, связанных между собой по принципу связанного списка.
Здесь каждый квадрат — это отдельный объект, почти ConcurrentDictionary. В ConcurrentDictionary на каждую пару «ключ-значение» создаётся отдельный объект. Причем при замене значений, если сами значения больше определённого размера, они постоянно пересоздаются, и от этого возникает ещё и memory traffic. Чтобы это был совсем ConcurrentDictionary, я нарисовал lock'и. Один квадрат — это один объект.
Теперь посмотрим на то, как устроен обычный Dictionary.
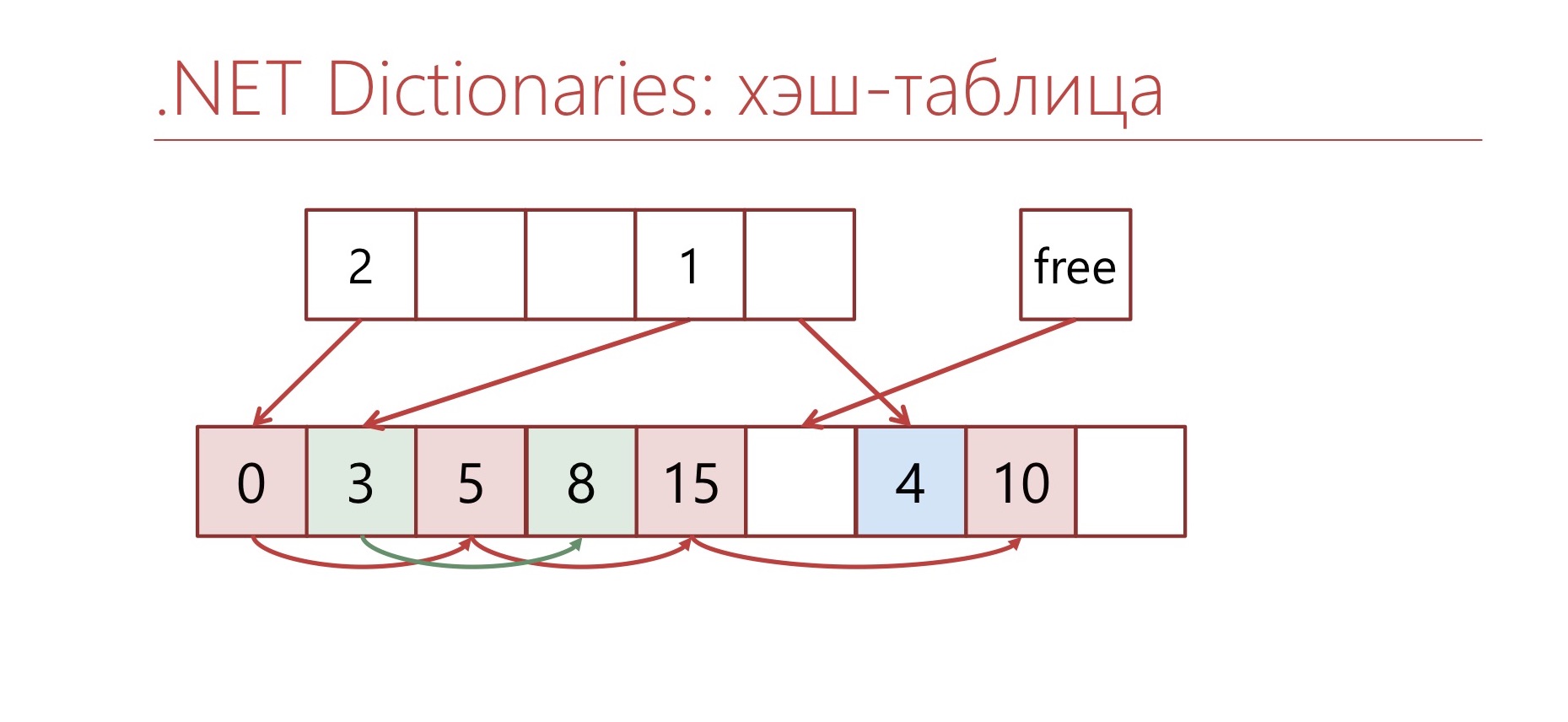
Обычный Dictionary устроен похитрее, чем Concurrent, но он более компактный по памяти. В нём есть два массива: массив buckets, массив entries. В массиве buckets находится индекс первого элемента в этом bucket'е в массиве entries. Все пары «ключ-значение» хранятся в массиве entries. Связные списки здесь организованы через ссылки на индексы в массиве. То есть дополнительно с парой «ключ-значение» хранится число int, индекс следующего элемента в bucket'е.
Давайте сравним memory overhead, который возникает при использовании ConcurrentDictionary и обычного Dictionary.

Начнём с обычного Dictionary. Memory overhea'ом я называю здесь всё, что не является самими ключами и значениями. В случае обычного Dictionary этот overhead составляет хэш-код и индекс следующего элемента, два int'а. Это 8 байт.
Теперь посмотрим на ConcurrentDictionary. В ConcurrentDictionary элемент хранится внутри объекта ConcurrentDictionary.Node. Это именно объект, класс. В этом классе находятся int hashCode и ссылка на следующий объект в связном списке. То есть у нас есть заголовки объекта, ссылка на метод table (это уже 16 байт), есть int hashCode и есть ссылка на объект. Если я не перепутал никакие размеры, то на 64-битной платформе это будет 28 байт overhead'а. Довольно много по сравнению с обычным Dictionary.
Кроме memory overhead'а, ConcurrentDictionary способен создавать нагрузку на GC за счёт того, что в нём есть очень много объектов. Я написал очень простой Benchmark. Я создаю ConcurrentDictionary определённого размера, а дальше замеряю время работы метода GC.Collect. Что же я получил?
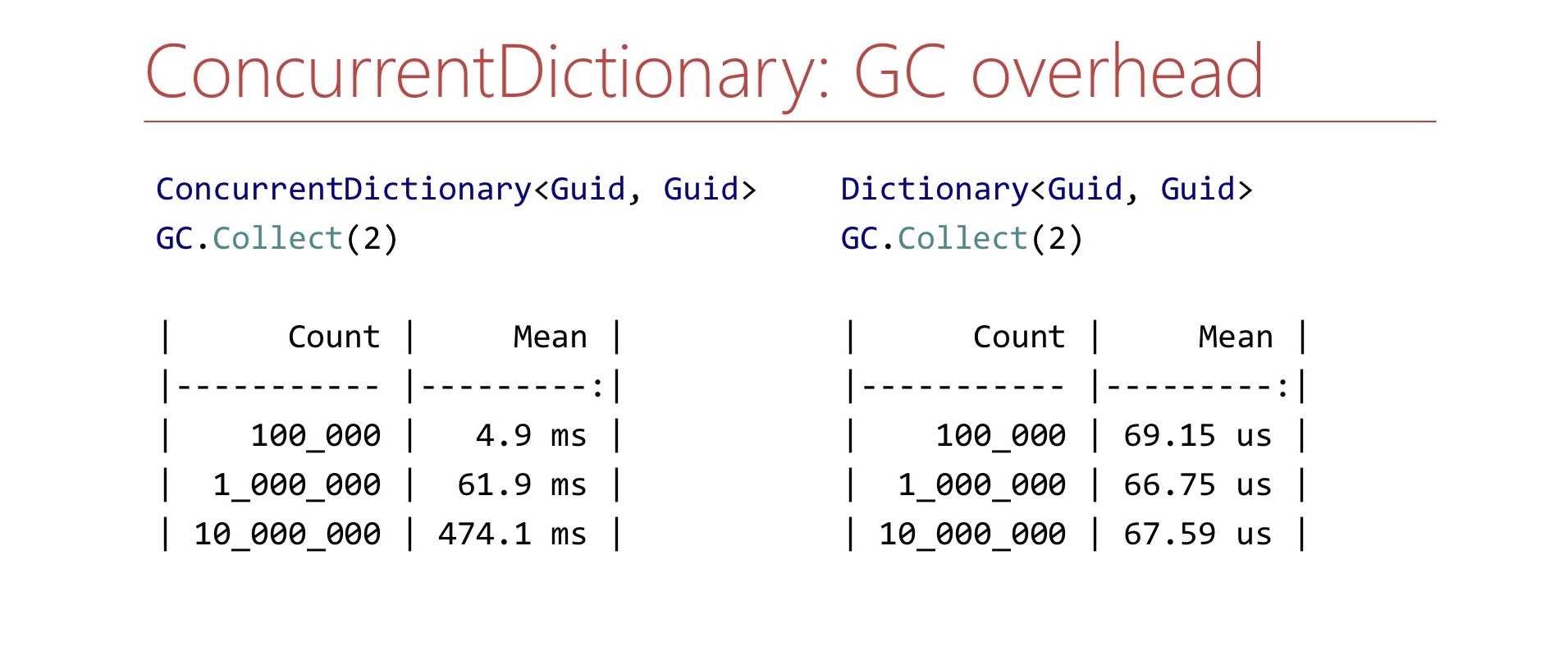
Я получил вот такие результаты. Если у нас в процессе есть ConcurrentDictionary размером 10 млн элементов, то сборка мусора на моём компьютере занимает полсекунды, на сервере при этом эти полсекунды вполне могут уже превратиться в несколько секунд, что уже может быть довольно неприемлемо. С обычным Dictionary такого не происходит. Сколько элементов в него ни клади, там обычные массивы, два объекта, и всё очень хорошо. На время работы сборщика мусора не влияет.
Как можно справиться с проблемами, которые возникают при использовании ConcurrentDictionary?
4.2 Простые решения
- Ограничение на размер
- TTL
- Dictionary+lock
- Sharding
Давайте разберём простые эффективные решения. Мы можем ограничить размер нашего ConcurrentDictionary. Вряд ли нам нужно держать кэш на 10 миллионов элементов. Можно держать тысячу, и никаких проблем не будет. Можно сделать TTL для элементов, и периодически их вычищать. В некоторых случаях довольно эффективно использовать обычный Dictionary с lock'ом. Естественно, надо убедиться, что lock здесь не ухудшит производительность. Можно развить этот подход и расшардировать Dictionary с lock'ом самостоятельно перед размещением элементов по словарям, по некоторому хэш-коду раскладывать их в несколько словарей, тогда мы не будем конкурировать за один и тот же lock. Но при этом иногда бывает так, что простые решения не работают.
4.3 Индекс
- Нужно хранить in-memory индекс <Guid,Guid>
- В индексе >106 элементов
- Постоянно происходят чтения из нескольких потоков
- Записи редкие
- Нужно уметь перечислять все элементы в коллекции
Мы столкнулись с подобной ситуацией. У нас очень важное приложение — это мастер нашей распределённой файловой системы, и ему нужно хранить в памяти in-memory индекс из Guid'а в Guid, помнить расположение файлов на серверах. В этом индексе было порядка миллиона элементов. Из этого индекса постоянно кто-то что-то читает, пишут в этот индекс редко. Получилось так, что сборка мусора у нас стала занимать в этом приложении порядка 15 секунд для второго поколения. Это было неприемлемо. Мы решили поступить аналогично Semaphore и написать свой аналог ConcurrentDictionary.

Надо, чтобы он был lock-free на чтение и перечисление, чтобы был меньший overhead по памяти и нагрузка на GC. Также нам достаточно, чтобы он поддерживал сценарий с одним писателем и несколькими читателями. То есть пишут в него редко, и нам не нужно, чтобы он был очень хорош на запись, достаточно на чтение. Можно даже так, чтобы он приходил в какое-то невалидное состояние, если в него придут сразу несколько писателей, их можно синхронизировать извне. И пусть, по возможности, всё это не попадает в Large Object Heap. Почему бы и нет?
Когда мы решили попробовать сделать такую штуку, то начали с исследования того, можно ли доработать обычный Dictionary под эти требования.

В обычном Dictionary есть массив bucket'ов, массив Entry. В Entry хранится ключ, значение, хэш и ссылка, индекс следующего элемента.

Обычный Dictionary потокобезопасен на чтение, если нет писателей, читатели не могут поменять его состояние. Возможно, это тоже может решить какие-то проблемы.
Что же может пойти не так, если всё-таки будут записи параллельно с чтениями? Во-первых, при ресайзе, когда массивы заменяются на массивы размеров больше, читатель может увидеть два массива, относящиеся к разным версиям нашей коллекции. Эта проблема решается довольно просто. У нас есть Dictionary, у него есть два массива, buckets, entries, мы объединяем эти массивы в один объект и при необходимости подменяем его через Interlocked. Соответственно, читатель никогда не увидит два массива из разных версий.
DictionaryВ интернете есть такая страшилка, что при многопоточном доступе к обычному Dictionary в нём может получиться цикл через индекс-ссылки внутри bucket'ов. На самом деле этот цикл может появиться, только если будет несколько конкурентных писателей. Если конкурентный писатель один, то сломаться могут только читатели, а писатель приведёт коллекцию в нужное ему состояние. Если у нас будет два параллельных писателя, то они могут образовать цикл внутри коллекции, это довольно легко воспроизвести.
- Потокобезопасен на чтение, если нет писателей
- Что может пойти не так, если будут записи?
— При Resize увидели buckets и entries разных версий
— Поток зациклился при переходе по индексам-ссылкам
— Прочитали мусор вместо Dictionary.Entry
— Перешли по индексам-ссылкам в мусор
https://blogs.msdn.microsoft.com/tess/2009/12/21/high-cpu-in-net-app-using-a-static-generic-dictionary/
Мы можем почитать мусор вместо Entry в Dictionary. Можем случайно перескочить по индекс-ссылкам куда-то не туда в коллекции. Давайте посмотрим, как эти проблемы можно решить.

Решение пришло из .NET Framework версии 1.1. В нём появился класс Hashtable, недженериковая версия Dictionary, которая работает с object'ами. Про неё прямо на MSDN сказано, что она реализует нужный нам сценарий. Она потокобезопасна, если из неё будут параллельно читать и при этом будет только один поток-писатель. Это нас заинтересовало. Стали разбирать, как Hashtable устроен внутри. Давайте посмотрим, как он решает некоторые обозначенные проблемы.
4.4 Чтение мусора вместо Dictionary.Entry

Почему так может произойти? Dictionary.Entry большой, он больше, чем 8 байт, его, казалось бы, не прочитать атомарно, хотя на самом деле можно. Как это сделать?
bool writing;
int version;
this.writing = true;
buckets[index] = …;
this.version++;
this.writing = false;Заводятся две переменные: флаг (пишут ли сейчас в структуру, которую мы хотим читать) и int-версия. Очень стандартное решение, прикрутили версию. Писатель выставляет флаг, что он сейчас будет писать, пишет, обновляет версию, снимает флаг.
bool writing;
int version;
while (true)
{
int version = this.version;
bucket = bickets[index];
if (this.writing || version != this.version)
continue;
break;
}Читатель делает чистое чтение, крутится в цикле и проверяет, поменялась ли версия и состояние этого флага при чтении. Если элемент поменялся или его меняют сейчас, надо попробовать перечитать. Такое решение позволяет считать атомарно структуры больше, чем 8 байт.
4.5 Переход по индексам-ссылкам в мусор
Давайте посмотрим, как это происходит.

В Dictionary можно перескочить на другой bucket при чтении из него, если при этом есть запись.
Есть Dictionary, состоящий из двух элементов. Я здесь для простоты написал ключи: 0 и 2. Это один bucket, 1 остаток у них от деления на 2. Что мы делаем? Читатель приходит и читает 0. После чего запоминает, что ему дальше нужно перейти в ячейку, где сейчас находится 2. После этого его поток прерывается. Дальше приходит писатель, удаляет 2, после чего добавляет на место этой двойки, например, 1. 1 даёт другой остаток от деления на 2 — это будет уже другой bucket. Наш читатель запомнил, что ему надо перейти в ячейку, где находилась двойка. Он читает оттуда 1 — всё, мы перескочили на другой bucket. В Hashtable от этой проблемы защитились тем, что вообще отказались от bucket'ов и индекс-ссылок. Там используется другой подход к разрешению коллизий — double hashing.
4.6 Обработка коллизий
- Элементы хранятся в массиве
- По хэшкоду определяется порядок обхода
Запись
- В первую свободную ячейку в порядке обхода
- Если нет свободных ячеек, то resize
Чтение
- Ищем элемент в порядке обхода, пока не найдем пустую ячейку
Обработка коллизий идет через так называемый порядок обхода. Все элементы точно так же лежат в одном массиве, но при этом уже нет массива Buckets, а есть только массив Entries (он там называется Buckets, хотя должен бы называться Entries). Дальше берётся хэш-код от элемента, который мы хотим найти в этой структуре, и мы понимаем, в каком порядке надо пройти по ячейкам в этом массиве, чтобы искать наш элемент.
При записи мы запишем наш элемент в первую свободную ячейку в порядке обхода. Если свободных ячеек нет, то будем ресайзить коллекцию.
Про чтение: будем идти в порядке обхода, пока не найдём нужный нам элемент, либо не найдём элемент, в котором записан признак того, что элементов дальше явно нет. Возможно, идея с порядком обхода показалась довольно смутной, поэтому разберем пример.

Рассмотрим самый простой порядок обхода, который может быть, — последовательный обход.
Как он работает? Есть некоторый ключ, и хэш-код от него равен 2. Мы берём хэш-код по модулю Capacity нашей коллекции, чтобы можно было и дальше использовать его как индекс в этом массиве. У нас хэш — 2. Мы хотим найти элемент с таким хэшом, с определённым ключом. Посмотрим на ячейку с индексом 2. Там есть этот элемент? Если есть, то значит, что мы его уже нашли, его и вернём. Если там оказался какой-то другой элемент, то мы идём в следующую ячейку по счёту, а именно в ячейку с индексом 3. Смотрим, есть ли там элемент, если нет, то идём в четвёртую, в нулевую, в первую.
Порядок обхода, который используется в Hashtable, не последовательный. Он более сложный, там используется так называемый double hashing. Он отличается от последовательного тем, что в качестве шага взята не единица, а другое число, которое вычисляется с использованием хэша.
Если размер шага, с которым мы идём по массиву, и размер этого массива — взаимно простые числа, то при обходе массива мы пройдём все его элементы ровно один раз. Это и используется в Hashtable. Там сделано так, что размер массива — это всегда простое число — любое число подходит в качестве размера шага. Мы начинаем идти с произвольной ячейки и дальше в неё же по циклу по массиву и приходим. Таким образом, у нас нет никаких bucket'ов, нам никуда не перескочить или прочитать что-то не то, у нас эти ссылки не могут поломаться. Становится лучше.
Здесь уже реализовали почти всё, что хотели, осталось реализовать lock-free перечисление и избежать попадания в LOH.

Как сделать lock-free перечисления? На MSDN в документации про Hashtable сказано, что на перечисление он не потокобезопасен. Проблема возникает с тем, что в силу особенностей структуры данных могут повторяться элементы с одинаковыми ключами, в случае если они были удалены и добавлены заново во время перечисления.

Если мы хотим избежать подобного поведения, то можем использовать чистое чтение, но не для отдельных элементов в нашей коллекции, а для bucket'ов. Можно положить в основу нашей коллекции идеи обычного Dictionary с bucket'ами, обычную хэш-таблицу, но эти bucket'ы всегда зачитывать целиком с чистым чтением. То есть если кто-то успел записать в bucket, то bucket придётся перечитать. Так как записи не такие частые, то это не очень критично.
Мы хотим, чтобы наша структура не попадала в Large Object Heap.

Для этого мы можем её расшардить. Заменим CustomDictionary на CustomDictionarySegment и поверх сделаем обёртку. Есть наш Dictionary, состоящий из нескольких сегментов, в которых элементы распределены по хэшу. Каждый сегмент — это тот Dictionary, о котором мы говорили до этого. В каждом из этих сегментов массив маленький, и он не попадает в Large Object Heap. Так как сами по себе эти массивы маленькие, то и bucket'ы в них маленькие. Соответственно, мы можем позволить себе такую роскошь, как их чистое чтение, перечитать целый bucket, если вдруг в него кто-то что-то записал.
Как развитие этой идеи мы можем сделать блокировки на наши сегменты. В итоге получится почти тот самый ConcurrentDictionary, который и есть в .NET, но с более ограниченной применимостью для конкретных сценариев, где не нужны все фичи обычного.
4.7 Выводы
- .NET не идеален
- Ничто не идеально
- Проводите тестирование
- Знайте, как работают стандартные классы
- Изобретайте велосипеды
- Тестируйте велосипеды
Какие из всего этого выводы? .NET не идеален. Ничто не идеально. Все те структуры, которые есть в стандартной библиотеке, служат для работы в наибольшем количестве сценариев. Есть у вас какой-то свой сценарий — вам нужно что-то другое. Когда пишете код, проведите тестирование, убедитесь, подходит ли вам стандартное решение.
Если что-то идёт не так, изучите, как оно работает, что находится внутри стандартного класса, который вы используете. Если вы изучили, как оно работает, и не поняли, что именно вам надо поменять в своём коде, возможно, вам нужно пойти на некоторый внутренний конфликт и изобрести велосипед. Изобрели велосипед — протестируйте свой велосипед, убедитесь, что он работает.
Полезные ссылки
- Интересные сюрпризы ConcurrentDictionary: https://habr.com/ru/company/skbkontur/blog/348508/
- https://github.com/vostok/commons.threading
- https://github.com/epeshk/dotnext-2019-threading
Первая ссылка — на статью моего коллеги Ильи Локтионова про некоторые подвохи ConcurrentDictionary. Кстати, надо сказать спасибо команде инфраструктуры Контура, Илье Локтионову (Diafilm), без них этот доклад бы не состоялся.
Также приведу здесь ссылки на GitHub. Вторая ссылка — это ссылка на нашу библиотеку, которая лежит в опенсорсе, содержит в себе LIFO-Semaphore, о котором было рассказано. Третья ссылка на репозиторий с примерами кода, которые были в докладе.
6-7 ноября я выступлю на DotNext 2019 Moscow с докладом «.NET: Лечение зависимостей» и расскажу про случаи, когда возникают ошибки с подключаемыми библиотеками на .NET Framework и .NET Core, и объясню, какие можно использовать подходы к решению этих проблем.
