Синтаксический анализ текста всегда начинается с лексического анализа или tokenizing-а. Существует простой способ решить эту задачу практически для любого языка с помощью регулярных выражений. Еще одно применение старым добрым regexp-ам.
Я часто сталкиваюсь с задачей синтаксического анализа текстов. Для простых задач, вроде анализа введенного пользователем значения, достаточно базового функционала регулярных выражений. Для сложных и тяжелых задач вроде написания компилятора или статического анализа кода можно использовать специализированные инструменты (AntLR, JavaCC, Yacc). Но мне часто попадаются задачи промежуточного уровня, когда регулярных выражений не хватает, а тянуть в проект тяжеловесный инструментарий не хочется. К тому же эти инструменты обычно работают на этапе compile-time и в run-time не позволяют изменить параметры анализа (например сформировать список ключевых слов из файла или таблицы БД).
Как пример приведу задачу, которая возникла у нас в процессе ускорения SQL запросов. Мы анализировали логи наших SQL запросов и хотели по определенным правилам находить "плохие" запросы. Например запросы, в которых одно и тоже поле проверяется на набор значений с помощью OR
name = 'John' OR name = 'Michael' OR name = 'Bob'Мы хотели заменить такие запросы на
name IN ('John', 'Michael', 'Bob')Регулярные выражения уже не справляются, но создавать полноценный SQL парсер с помощью AntLR тоже не хотелось. Можно было бы разбить текст запроса на токены и простым кодом, без всяких специализированных инструментов сделать синтаксический анализ.
Эту задачу можно решить с помощью базового функционала регулярных выражений. Попробуем разбить на токены SQL запрос. Мы рассмотрим упрощенный вариант SQL, чтобы не перегружать текст деталями. Для создания полноценного SQL лексера придется написать чуть более сложные регулярные выражения.
Вот набор выражений для основных лексем языка SQL:
1. keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b
2. id : [A-Za-z][A-Za-z0-9]*
3. real_number : [0-9]+\.[0-9]*
4. number : [0-9]+
5. string : '[^']*'
6. space : \s+
7. comment : \-\-[^\n\r]*
8. operation : [+\-\*/.=\(\)]Хочу обратить внимание на регулярное выражение для keyword
keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\bВ нем есть две особенности.
- Используется оператор \b в начале и в конце, чтобы например не отсекать от слова organization префикс or, который является ключевым словом и который некоторые regex engine выделят в отдельную лексему без использования оператора \b .
- все слова сгруппированы non-capturing скобками (?: ), которые не захватывают совпадение. Это в дальнейшем будет использоваться, чтобы не нарушать индекcирование частичных регулярных выражений внутри общего выражения.
Теперь можно объединить все эти выражения в одно целое, с помощью группировки и оператора |
(\b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b)|([A-Za-z][A-Za-z0-9]*)|([0-9]+\.[0-9]*)|([0-9]+)|('[^']*')|(\s+)|(\-\-[^\n\r]*)|([+\-\*/.=\(\)])Теперь можно попробовать применить это выражение к SQL выражению, например к такому
SELECT count(id) -- count of 'Johns'
FROM person
WHERE name = 'John'Вот результат на Regex Tester. Перейдя по ссылке можно поиграться с выражением и результатом анализа. Видно, что например SELECT соответствует сразу 1- группе, которая соответствует типу keyword.
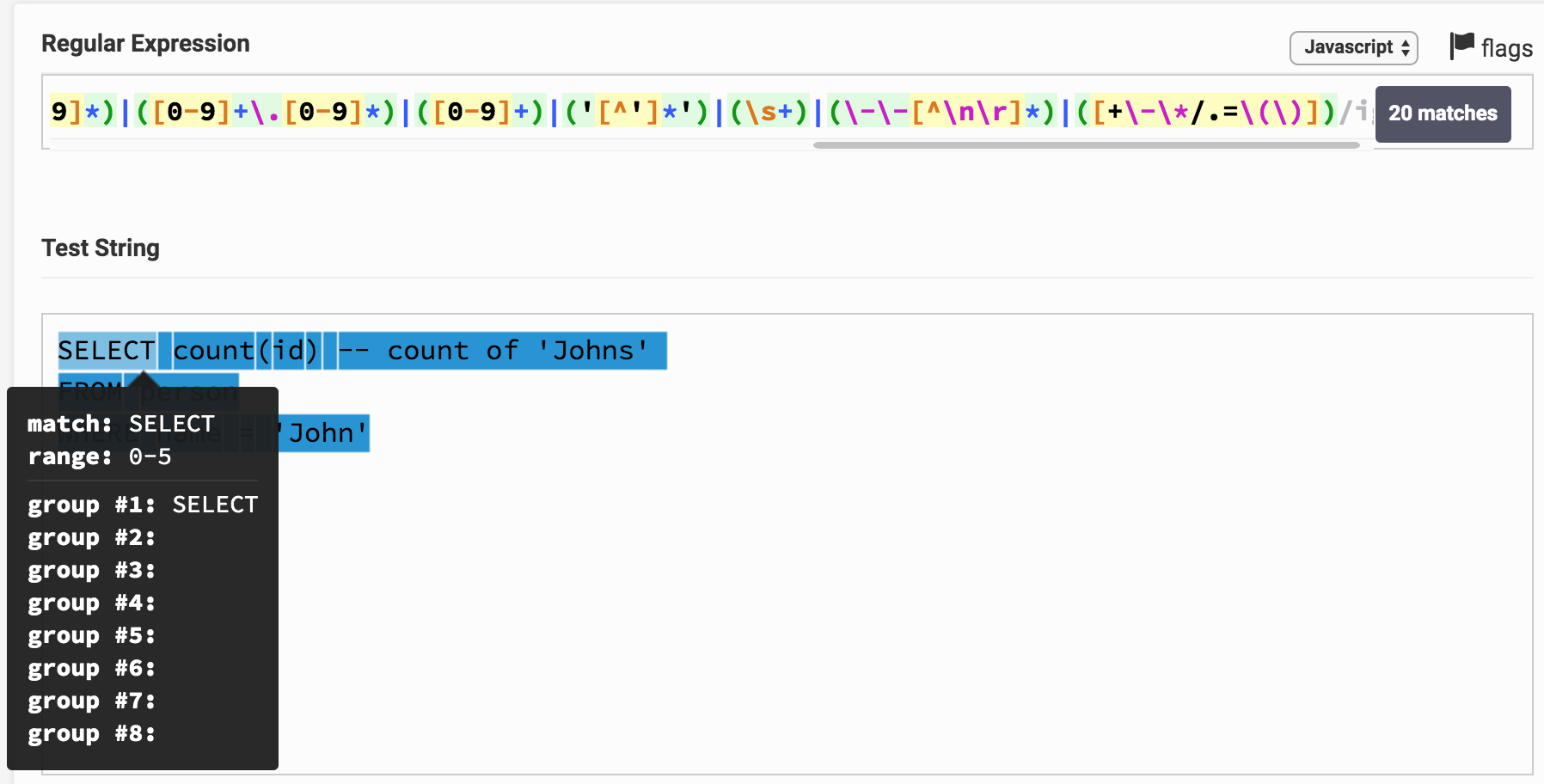
Вы можете заметить, что весь текст запроса оказался разбит на подстроки и каждая соответствует какой-то группе. По номеру группы можно соотнести ее с типом лексемы (токена).
Оформить приведенный алгоритм в программу на любом языке программирования, который поддерживает регулярные выражения не составит особого труда. Вот небольшой класс, который реализует это на Java.
package org.example;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
/**
* Токенайзер на регулярных выражениях.
* Использует именованные группы, чтобы не зависеть от способа группировки базовых регулярных выражений.
*/
public class RegexTokenizer implements Enumeration<Token> {
// Строка, которую необходимо разбить на лексемы
private final String content;
// Массив типов токенов с регулярными выражениями для анализа
private final ITokenType[] tokenTypes;
private final Matcher matcher;
// Текущая позиция анализа
private int currentPosition = 0;
/**
* @param content строка для анализа
* @param tokenTypes Массив типов токенов с регулярными выражениями для анализа
*/
public RegexTokenizer(String content, ITokenType[] tokenTypes) {
this.content = content;
this.tokenTypes = tokenTypes;
// Формируем общее регулярное выражение для анализа
List<String> regexList = new ArrayList<>();
for (int i = 0; i < tokenTypes.length; i++) {
ITokenType tokenType = tokenTypes[i];
regexList.add("(?<g" + i + ">" + tokenType.getRegex() + ")");
}
String regex = regexList.stream().collect(Collectors.joining("|"));
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
// Запускаем первый поиск
matcher = pattern.matcher(content);
matcher.find();
}
@Override
public boolean hasMoreElements() {
return currentPosition < content.length();
}
@Override
public Token nextElement() {
boolean found = currentPosition > matcher.start() ? matcher.find() : true;
int start = found ? matcher.start() : content.length();
int end = found ? matcher.end() : content.length();
if(found && currentPosition == start) {
currentPosition = end;
// Лексема найдена- определяем тип
for (int i = 0; i < tokenTypes.length; i++) {
String si = "g" + i;
if (matcher.start(si) == start && matcher.end(si) == end) {
return createToken(content, tokenTypes[i], start, end);
}
}
}
throw new IllegalStateException("Не удается определить лексему в позиции " + currentPosition);
}
/**
* Создаем токен-лексему по параметрам, можно переопределить этот метод, чтобы например ускорить работу алгоритма,
* например не вырезать текст токена из оригинальной строки для некоторых токенов (пробел, комментарий)
* @param content оригинальная строка для анализа
* @param tokenType тип токена
* @param start начало токена в оригинальной строке
* @param end конец токена в оригинальной строке
* @return объект токена-лексемы
*/
protected Token createToken(String content, ITokenType tokenType, int start, int end) {
return new Token(content.substring(start, end), tokenType, start);
}
/**
* Список типов токенов для SQL
*/
public enum SQLTokenType implements ITokenType {
KEYWORD("\\b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\\b"),
ID("[A-Za-z][A-Za-z0-9]*"),
REAL_NUMBER("[0-9]+\\.[0-9]*"),
NUMBER("[0-9]+"),
STRING("'[^']*'"),
SPACE("\\s+"),
COMMENT("\\-\\-[^\\n\\r]*"),
OPERATION("[+\\-\\*/.=\\(\\)]");
private final String regex;
SQLTokenType(String regex) {
this.regex = regex;
}
@Override
public String getRegex() {
return regex;
}
}
public static void main(String[] args) {
String s = "select count(id) -- count of 'Johns' \n" +
"FROM person\n" +
"where name = 'John'";
RegexTokenizer tokenizer = new RegexTokenizer(s, SQLTokenType.values());
while(tokenizer.hasMoreElements()) {
Token token = tokenizer.nextElement();
System.out.println(token.getText() + " : " + token.getType());
}
}
}
/**
* Класс- токен (лексема)
*/
public class Token {
// Текст токена
private final String text;
// Тип токена
private final ITokenType type;
// Начало токена в исходном тексте
private final int start;
public Token(String text, ITokenType type, int start) {
this.text = text;
this.type = type;
this.start = start;
}
public String getText() {
return text;
}
public ITokenType getType() {
return type;
}
public int getStart() {
return start;
}
}
/**
* Интерфейс для типа токена
*/
public interface ITokenType {
/**
* Регулярное выражение для данного типа токена
*/
String getRegex();
}
В этом классе алгоритм реализован с помощью именованных групп, которые присутствуют не во всех движках. Эта возможность позволяет обращаться к группам не по индексам, а по имени, что немного удобнее чем обращение по индексу.
На моем I7 2.3GHz этот класс демонстрирует скорость анализа 5-20 МБ в секунду (зависит от сложности выражений). Алгоритм можно распараллелить, анализируя сразу несколько файлов, увеличивая общую скорость работы.
В сети я нашел несколько подобных алгоритмов, но мне попадались варианты, которые не формируют общего регулярного выражения, а последовательно применяют регулярные выражения для каждого типа лексем к началу строки, потом отбрасывают найденный токен из начала строки и снова пытаются применить все регэкспы. Это работает примерно в 10-20 раз медленнее, требует больше памяти и алгоритм получается сложнее. Я добивался большей скорости работы лишь используя свою реализацию регулярных выражений основанную на ДКА (детерминированный конечный автомат). В regex движках обычно используется НКА — недетерминированный конечный автомат). ДКА в 2-3 раза быстрее, но регулярные выражения для него писать сложнее из-за ограниченного набора операторов.
В своем примере для SQL я немного упростил регулярные выражения и полученный токенайзер нельзя считать полноценным лексическим анализатором SQL запросов, но цель статьи- показать принцип, а не создать реальный SQL tokenizer. Я же в своей практике применял этот подход и создавал полноценные лексические анализаторы для SQL, Java, C, XML, HTML, JSON, Pascal и даже COBOL (с ним пришлось повозиться).
Приведу еще несколько простых правил для написания регулярных выражений для лексического анализа.
- Если одна и та же лексема может быть отнесена к разным типам (например любое ключевое слово может быть распознано как идентификатор), то более узкий тип нужно определять в начале. Тогда регулярное выражение для него будет применяться первым и именно оно определит тип лексемы. Например в моем примере keyword определены раньше id и лексема select будет распознана как keyword, а не id
- Определяйте сначала более длинные лексемы, потом более короткие. Например сначала нужно определить <=, >= и потом уже отдельные >, <, = В этом случае текст <= правильно будет распознан как единая лексема оператора "меньше либо равно", а не две отдельные лексемы < и =
- Научитесь использовать lookahead и lookbehind. Например, символ * в SQL имеет значение оператора умножения и указания всех полей в таблице. Можно в помощью простого lookbehind отделить эти два случая, например здесь регэксп (?<=.\s|select\s)* находит символ * только в значении "все поля таблицы".
- Иногда полезно определить регулярные выражения для ошибок, которые бывают в тексте. Например если вы делаете подсветку синтаксиса, можно определить тип лексемы "незаконченная строка" как
'[^\n\r]*. В процессе редактирования текста пользователь может не успеть закрыть кавычку в строке, но ваш токенайзер сможет правильно распознать такую ситуацию и правильно подсветить ее.
Используя эти правила и применяя данный алгоритм вы быстро сможете разбивать текст на токены практически для любого языка.
