
На днях состоялся Moscow Python Meetup #66 — сообщество продолжает обсуждать актуальные инструменты, которые усиливают язык и адаптируют его к разным окружениям. В том числе на митапе прозвучал и мой доклад. Меня зовут Наиль, я делаю Яндекс.Коннект.

Рассказ, который я подготовил, был посвящён uWSGI. Это многофункциональный сервер веб-приложений, а каждое современное приложение сопровождается метриками. Я постарался показать, как возможности uWSGI способны помочь в сборе метрик.
— Всем привет, рад вас всех приветствовать в стенах Яндекса. Приятно, что столько людей пришло посмотреть мой и другие доклады, что столько людей интересуются и живут Питоном. О чем мой доклад? Он называется «uWSGI в помощь метрикам». Немножко расскажу о себе. Питоном я занимаюсь последние шесть лет, работаю в команде Яндекс.Коннекта, мы пишем платформу для бизнеса, которая предоставляет сервисы Яндекса, разработанные внутри, для сторонних пользователей, то есть для всех. Любой человек или организация может воспользоваться продуктами, разработанными Яндексом для себя, для своих целей.
Мы поговорим о метриках, о том, как можно получать эти метрики, как мы используем у себя в команде uWSGI в качестве инструмента получения метрик, как он нам помогает. Затем расскажу небольшую историю оптимизации.
Пару слов о метриках. Как вы знаете, разработка современного приложения невозможна без тестов. Странно, если кто-то разрабатывает свои приложения без тестов. В то же время мне кажется, что эксплуатация современного приложения невозможна без метрик. Наше приложение — это живой организм. У человека можно снять какие-то метрики, например давление, частоту сердечных сокращений, — так же и у приложения есть показатели, за которыми нам интересно и хотелось бы наблюдать. В отличие от человека, у которого эти жизненные метрики обычно снимают, когда ему плохо, в случае приложения мы можем снимать их всегда.

Для чего мы снимаем метрики? Кстати, кто ими пользуется метриками? Надеюсь, после моего доклада рук станет больше, и люди заинтересуются и начнут собирать метрики, поймут, что это нужно и полезно.
Так для чего же нам нужны метрики? В первую очередь, мы видим, что происходит с системой, выделяем для нашей системы какие-то нормативные показатели и понимаем, выходим ли мы в процессе работы приложения за эти показатели или не выходим. Можно видеть какое-то аномальное поведение системы, например рост количества ошибок, понимать, что в системе не так, раньше наших пользователей и получать сообщения о происшествиях не от пользователей, а от системы мониторинга. На основе метрик мы можем настроить алертинг и получать смски, письма, звонки, кому как нравится.

Что же, как правило, из себя представляют метрики? Это какие-то числа, возможно, счетчик, возрастающий монотонно. К примеру, количество запросов. Какие-то единичные значения, которые меняются во времени, возрастают или убывают. Пример — количество задач в очереди. Или гистограммы — значения, попадающие в какие-то интервалы, так называемые корзины. Как правило, удобно считать эти данные, связанные со временем, и узнавать, в какой временной интервал сколько значений уложилось.

Какие мы можем снимать метрики? Я сделаю акцент на разработку веб-приложений, так как мне это ближе. К примеру, мы можем снимать количество запросов, наши эндпоинты, время ответов наших эндпоинтов, коды ответов смежных сервисов, если мы в них ходим и у нас микросервисная архитектура. Если мы используем кэш, то можем понимать, насколько эффективен кэш miss или hit, понимать распределение времен ответа как сторонних серверов, так и, к примеру, базы данных. Но чтобы метрики посмотреть, их надо как-то собрать.

Как мы можем их собрать? Есть несколько вариантов. Я хочу рассказать вам о первом варианте — push-схеме. В чем он состоит?
Допустим, к нам приходит запрос от пользователя. Мы локально с нашим приложением ставим какой-то, как правило, push-агент. Допустим, у нас Docker, в нем приложение, и еще параллельно стоит push-агент. push-агент получает локально от нас значение метрик, как-то их, возможно, буферизует, делает батчи и отправляет их в систему хранения метрик.
В чем преимущество использования push-схемы? Мы можем напрямую из приложения отправить какую-то метрику в систему метрик, но при этом мы получаем какое-то сетевое взаимодействие, latency, overhead на сбор метрик. В случае локального push-клиента это нивелируется.
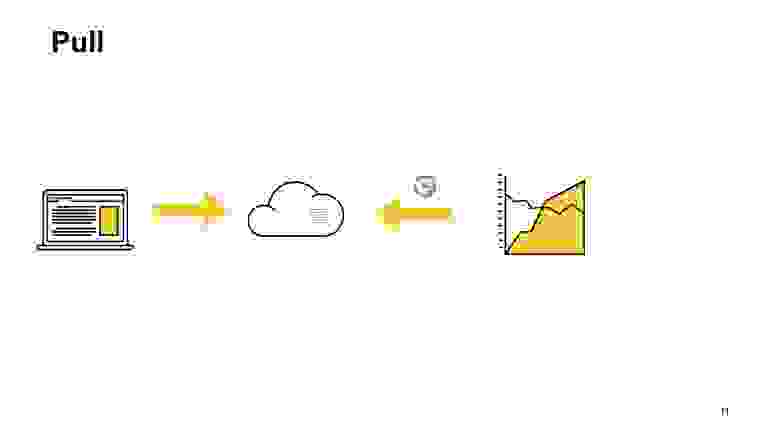
Другой вариант — pull-схема. При pull-схеме у нас тот же сценарий. Приходит к нам запрос от пользователя, мы его как-то сохраняем у себя. И потом с какой-то периодичностью — раз в секунду, раз в минуту, кому как удобно — система сбора метрик приходит в специальный эндпоинт нашего приложения и забирает эти показатели.

Еще один вариант — логи. Все мы пишем логи и куда-то их отправляем. Нам ничего не мешает взять эти логи, как-то их обработать и на основе логов получить метрики.
К примеру, мы пишем в лог факт запроса пользователя, потом берем логи, хоп-хоп, посчитали. Типичный пример — это ELK (Elasticsearch, Logstash, Kibana).

Как это устроено у нас? В Яндексе своя инфраструктура, своя система сбора метрик. Она ожидает стандартизированный ответ для ручки, реализующей pull-схему. Плюс у нас есть внутреннее облако, где мы запускаем наше приложение. И все это интегрировано в единую систему. Загружая в облако, мы просто указываем: «Ходи вот в эту ручку и получай метрики».

Вот пример ответа для pull-схемы, который ожидает наша система сбора метрик.
Для себя в команде мы решили выбрать более подходящий нам способ, выделить несколько критериев, по которым мы выберем лучший для нас вариант. Оперативность — это то, как быстро мы можем получить в системе метрик отображение факта какого-либо действия. Зависимость — нужно ли нам дополнительные тулзы ставить или еще как-то настраивать инфраструктуру для получения метрики. И универсальность — насколько этот способ подходит для разных типов приложений.

Вот что мы получили в итоге. Хотя по критериям оперативности и универсальности выиграет push-схема. Но мы разрабатываем веб-приложение, и наше облако уже имеет готовую инфраструктуру для работы с этой задачей, так что мы решили для себя выбрать pull-схему. О ней и поговорим.
Чтобы что-то отдать в pull-схему, нам надо это где-то предагрегировать, сохранить. Наша система мониторинга ходит в pull-ручки раз в пять секунд. Где мы можем сохранить? Локально у себя в памяти или в стороннем хранилище.

Если мы сохраняем локально, то как правило, это подходит для случая с одним процессом. А мы у себя в uWSGI запускаем несколько процессов параллельно. Или мы можем использовать какое-то разделяемое хранилище. Что нам приходит в голову при слове «разделяемое хранилище»? Это какой-то Redis, Memcached, реляционные или нереляционные базы данных или даже файл.

Про uWSGI. Напомню тем, кто мало или редко им пользуется: uWSGI — это веб-сервер приложений, который позволяет запускать под собой Python-приложения. Он реализует интерфейс, протокол uWSGI. Этот протокол описан в PEP 333, кому интересно, можете почитать.

Также нам поможет выбрать лучшее решение Яндекс.Танк. Это инструмент нагрузочного тестирования, позволяет обстреливать наше приложение различными профилями нагрузки и строит красивые графики. Или работает в консоли, кому как нравится.

Эксперименты. Мы создадим синтетическое приложение для наших синтетических тестов, будем его обстреливать Танком. uWSGI-приложение будет иметь простейший конфликт с 10 воркерами.

Вот наше приложение на Flask. Полезную нагрузку, которую выполняет наше приложение, мы будем эмулировать пустым циклом.
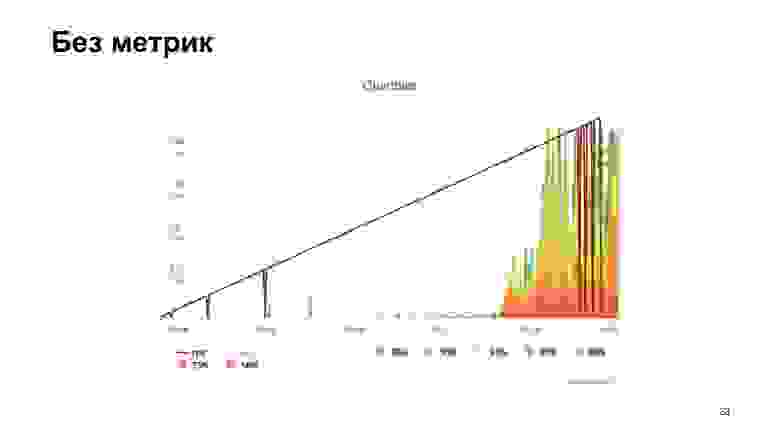
Производим обстрел, и Яндекс.Танк выдает нам один из таких графиков. Что он показывает? Персентили времен ответа. Наклонная линия — это RPS, которые растут, а гистограммки — это то, в какие персентили укладывался наш веб-сервер при такой нагрузке.
Мы будем брать этот вариант за эталонный и смотреть, как различные варианты хранения метрик влияют на производительность.

Простейший вариант — использовать PostgreSQL. Потому что мы работаем у себя с PostgreSQL, у нас он есть. Давайте используем то, что уже есть готовое.
Допустим, у нас есть табличка в PostgreSQL, в которой мы просто инкрементируем счетчик.

Уже на малых количествах RPS видим сильное ухудшение производительности. Можно сказать, просто огромное.

Следующий вариант — Redis. Но здесь мы поступаем умнее: ставим его локально и ходим к нему не по сети, а через Unix socket. Тоже увеличиваем счетчик.
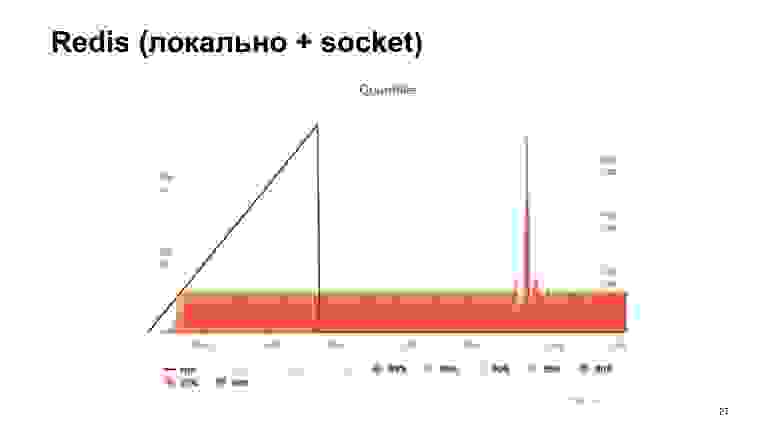
Получаем на выходе гистограмму времен ответов. Мы видим, что тут дела уже обстоят получше, но в какой-то момент мы упираемся в полочку, и дальше производительность уже не растет. Этот вариант кажется более оптимальным, но мы хотим сделать еще лучше.

Тут нам на помощь приходит uWSGI, настоящий комбайн. Там есть множество различных модулей. Mule для запуска подпроцессов, caching framework, cron, metrics subsystem и система alerting. «Cистема метрик subsystem» — звучит многообещающе.

Она умеет складывать какие-то метрики, увеличивать счетчик, уменьшать счетчик, умножать, делить — все что душе угодно.
Единственное, metric subsystem не умеет отдавать именно сложенные в нее metrics.
Почему для нас это важно? Как вы видели ранее, у нас есть ручка для отдачи статистики в определенном формате, и бежит несколько воркеров. Мы не знаем, в какой из воркеров придет запрос, а чтобы отдать все метрики, нам нужно делать какой-то реестр имен и как-то его шэрить между процессами. Это какой-то big deal, хочется такого избежать. Что еще у нас есть?

Конечно, cache subsystem. И тут мы видим: он умеет практически то же самое, а еще способен отдавать имена ключей, хранящихся в кэше. Это то, что нужно.

Сache subsystem — это кэш, встроенный в uWSGI. Быстрый и потокобезопасный модуль, который представляет из себя обычное хранилище типа ключ-значение.

Но поскольку это кэш, есть всем известная вторая проблема: как назвать переменную и как инвалидировать кэш? В нашем случае посмотрим, какие настройки у кэша по умолчанию. Он имеет ограничения на длину ключа. В нашем случае это имя метрики. По умолчанию 2048 байт. И можно в конфиге увеличить, если есть необходимость. Количество элементов, которое он хранит по умолчанию, — 65 536. Кажется, этого значения должно хватить всем. Вряд ли кто-то собирает такое количество метрик со своего приложения.
И ttl по умолчанию — 0. То есть значения хранящихся кэшей не инвалидируются по времени. Значит, мы сможем их получить из кэша и отдать в систему метрик.

Опять-таки, вариант — приложение, которое использует под коробкой uWSGI.
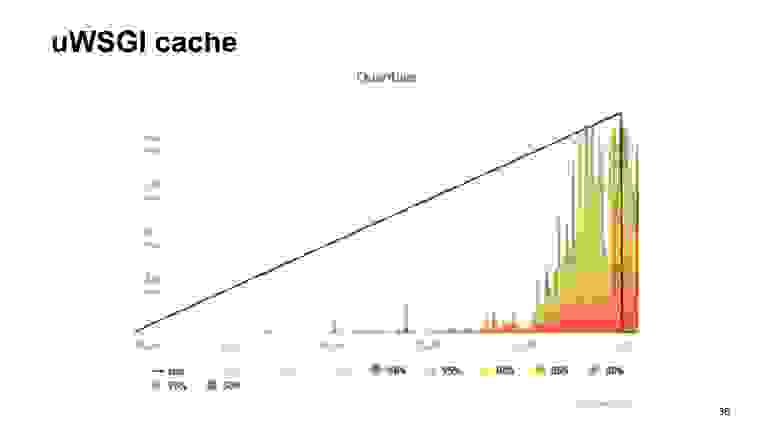
Вот результаты обстрела этого приложения.
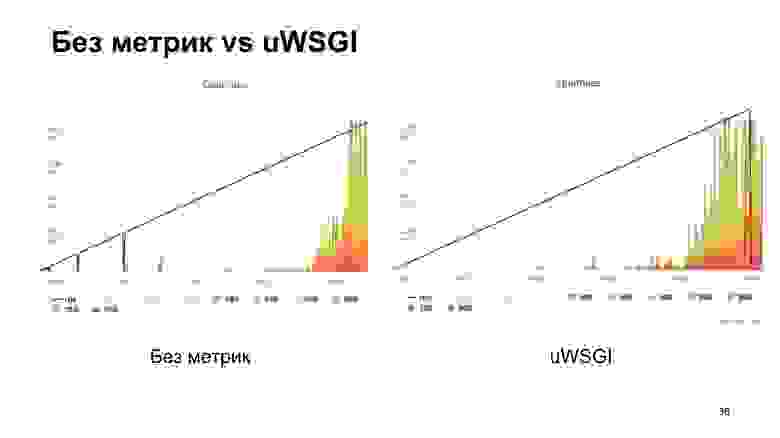
Результат без метрик, если с uWSGI, с натяжкой выглядит практически одинаково.

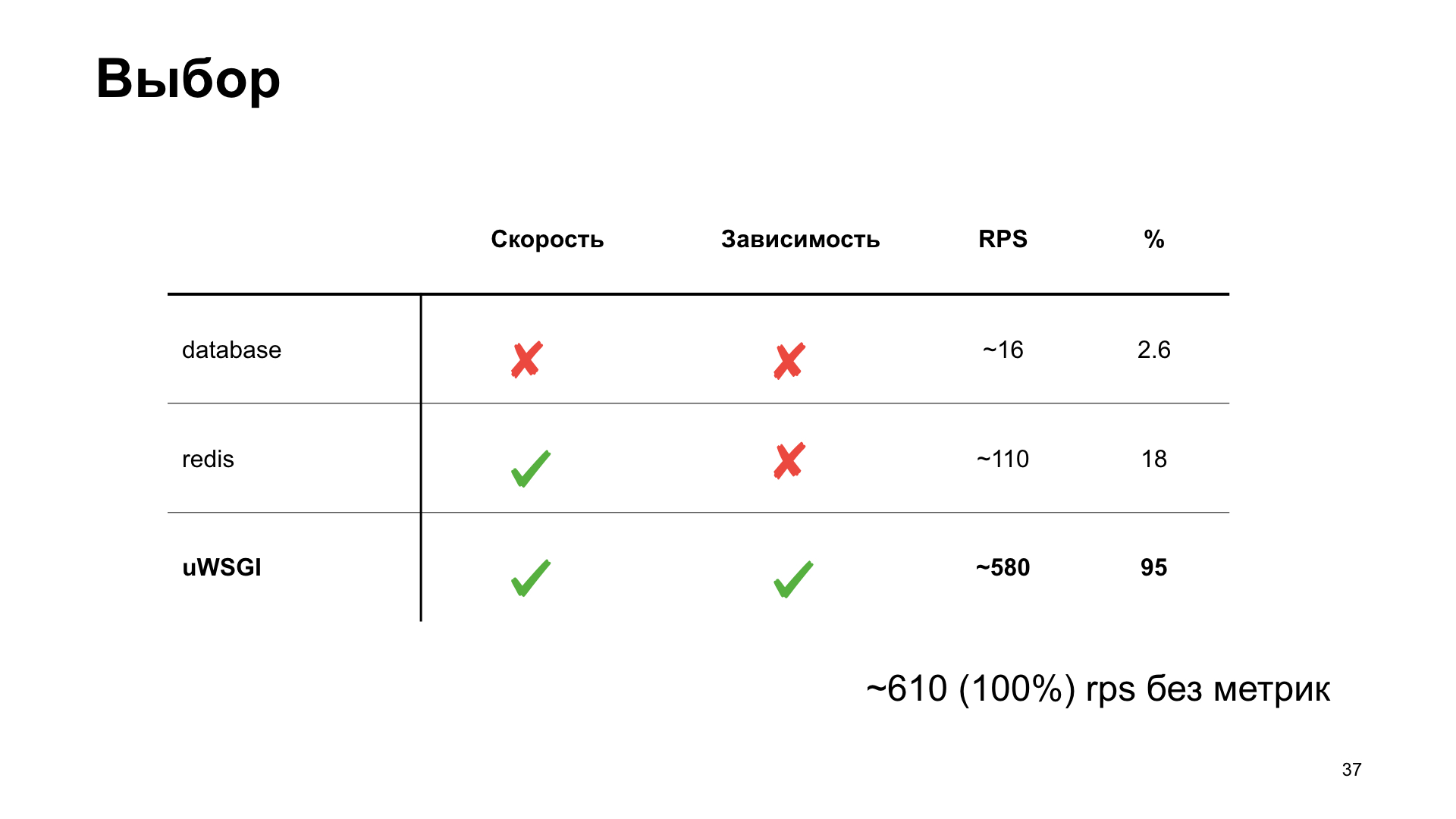
Как видно, в случае с uWSGI мы теряем всего 5% производительности относительно «ванильного» варианта без метрик. Другие варианты имеют довольно значительную просадку, и поэтому в результате зрительского голосования побеждает uWSGI.

Как мы это применили? Мы написали небольшую библиотечку, обертку вокруг uWSGI. К примеру, мы инстацируем экземпляр нашей библиотеки и тут на примере добавляем метрику «Время запросов базы».

Еще нам интересно отслеживать, как происходит работа с кэшем. Мы просто переопределяем методы клиента memcaсhe, сохраняем время на получение данных, время на загрузку и количество cache hit и cache miss.

Как мы это делаем внутри библиотеки? Для отгрузки значений мы получаем имена ключей, хранящихся в кэше, пробегаем по ним и просто отдаем в нужном формате в эндпоинт.

В итоге мы получаем график, в данном случае это 99-й персентиль времени доступа к кэшу, чтение и запись.

Или, как вариант, количество запросов стороннего сервиса в наше API.

У нас есть истории и провала, и успеха. Мы стали добавлять все большее и большее количество метрик и увидели падение производительности. Помогли нам сами метрики. Если вы собираете метрики, то вы можете увидеть, что что-то не в порядке. Поэтому я еще рекомендую вам ретроспективно смотреть метрики, которые вы накопили за неделю, месяц, полгода. И видеть, какая тенденция в каких показателях намечается у вашего приложения. Мы поняли, что стали упираться в подсчет метрик.

Нам помогло профилирование. Здесь вы видите flamegraph, он визуально нам показывает, сколько во время выполнения процесса заняли вызовы тех или иных функций, какие вызовы внесли наибольший вклад по времени. Мы поняли, что мы сделали в первой версии не очень хорошо, использовав pickle. Внутри нашей библиотеки она тратила значительное количество времени на pickling.

Мы отказались от pickling, перевели на caсhe inc, померили всё, стало быстрее.

В новой реализации мы тратим бо́льшую часть времени именно на работу с кэшем, а не на pickling.

К чему я это рассказываю? Я призываю вас начать собирать метрики, смотреть за метриками, ориентироваться на метрики. При выборе возможного варианта сбора метрик сравните варианты, посмотрети, какой для вас лучше подходит. И, конечно же, профилирование — это хорошо. Если вы видите, что что-то не так, что-то замедляется, — профилируйте.
Всем спасибо! Как я обещал, ссылочки:

Рассказ, который я подготовил, был посвящён uWSGI. Это многофункциональный сервер веб-приложений, а каждое современное приложение сопровождается метриками. Я постарался показать, как возможности uWSGI способны помочь в сборе метрик.
— Всем привет, рад вас всех приветствовать в стенах Яндекса. Приятно, что столько людей пришло посмотреть мой и другие доклады, что столько людей интересуются и живут Питоном. О чем мой доклад? Он называется «uWSGI в помощь метрикам». Немножко расскажу о себе. Питоном я занимаюсь последние шесть лет, работаю в команде Яндекс.Коннекта, мы пишем платформу для бизнеса, которая предоставляет сервисы Яндекса, разработанные внутри, для сторонних пользователей, то есть для всех. Любой человек или организация может воспользоваться продуктами, разработанными Яндексом для себя, для своих целей.
Мы поговорим о метриках, о том, как можно получать эти метрики, как мы используем у себя в команде uWSGI в качестве инструмента получения метрик, как он нам помогает. Затем расскажу небольшую историю оптимизации.
Пару слов о метриках. Как вы знаете, разработка современного приложения невозможна без тестов. Странно, если кто-то разрабатывает свои приложения без тестов. В то же время мне кажется, что эксплуатация современного приложения невозможна без метрик. Наше приложение — это живой организм. У человека можно снять какие-то метрики, например давление, частоту сердечных сокращений, — так же и у приложения есть показатели, за которыми нам интересно и хотелось бы наблюдать. В отличие от человека, у которого эти жизненные метрики обычно снимают, когда ему плохо, в случае приложения мы можем снимать их всегда.

Для чего мы снимаем метрики? Кстати, кто ими пользуется метриками? Надеюсь, после моего доклада рук станет больше, и люди заинтересуются и начнут собирать метрики, поймут, что это нужно и полезно.
Так для чего же нам нужны метрики? В первую очередь, мы видим, что происходит с системой, выделяем для нашей системы какие-то нормативные показатели и понимаем, выходим ли мы в процессе работы приложения за эти показатели или не выходим. Можно видеть какое-то аномальное поведение системы, например рост количества ошибок, понимать, что в системе не так, раньше наших пользователей и получать сообщения о происшествиях не от пользователей, а от системы мониторинга. На основе метрик мы можем настроить алертинг и получать смски, письма, звонки, кому как нравится.

Что же, как правило, из себя представляют метрики? Это какие-то числа, возможно, счетчик, возрастающий монотонно. К примеру, количество запросов. Какие-то единичные значения, которые меняются во времени, возрастают или убывают. Пример — количество задач в очереди. Или гистограммы — значения, попадающие в какие-то интервалы, так называемые корзины. Как правило, удобно считать эти данные, связанные со временем, и узнавать, в какой временной интервал сколько значений уложилось.

Какие мы можем снимать метрики? Я сделаю акцент на разработку веб-приложений, так как мне это ближе. К примеру, мы можем снимать количество запросов, наши эндпоинты, время ответов наших эндпоинтов, коды ответов смежных сервисов, если мы в них ходим и у нас микросервисная архитектура. Если мы используем кэш, то можем понимать, насколько эффективен кэш miss или hit, понимать распределение времен ответа как сторонних серверов, так и, к примеру, базы данных. Но чтобы метрики посмотреть, их надо как-то собрать.

Как мы можем их собрать? Есть несколько вариантов. Я хочу рассказать вам о первом варианте — push-схеме. В чем он состоит?
Допустим, к нам приходит запрос от пользователя. Мы локально с нашим приложением ставим какой-то, как правило, push-агент. Допустим, у нас Docker, в нем приложение, и еще параллельно стоит push-агент. push-агент получает локально от нас значение метрик, как-то их, возможно, буферизует, делает батчи и отправляет их в систему хранения метрик.
В чем преимущество использования push-схемы? Мы можем напрямую из приложения отправить какую-то метрику в систему метрик, но при этом мы получаем какое-то сетевое взаимодействие, latency, overhead на сбор метрик. В случае локального push-клиента это нивелируется.
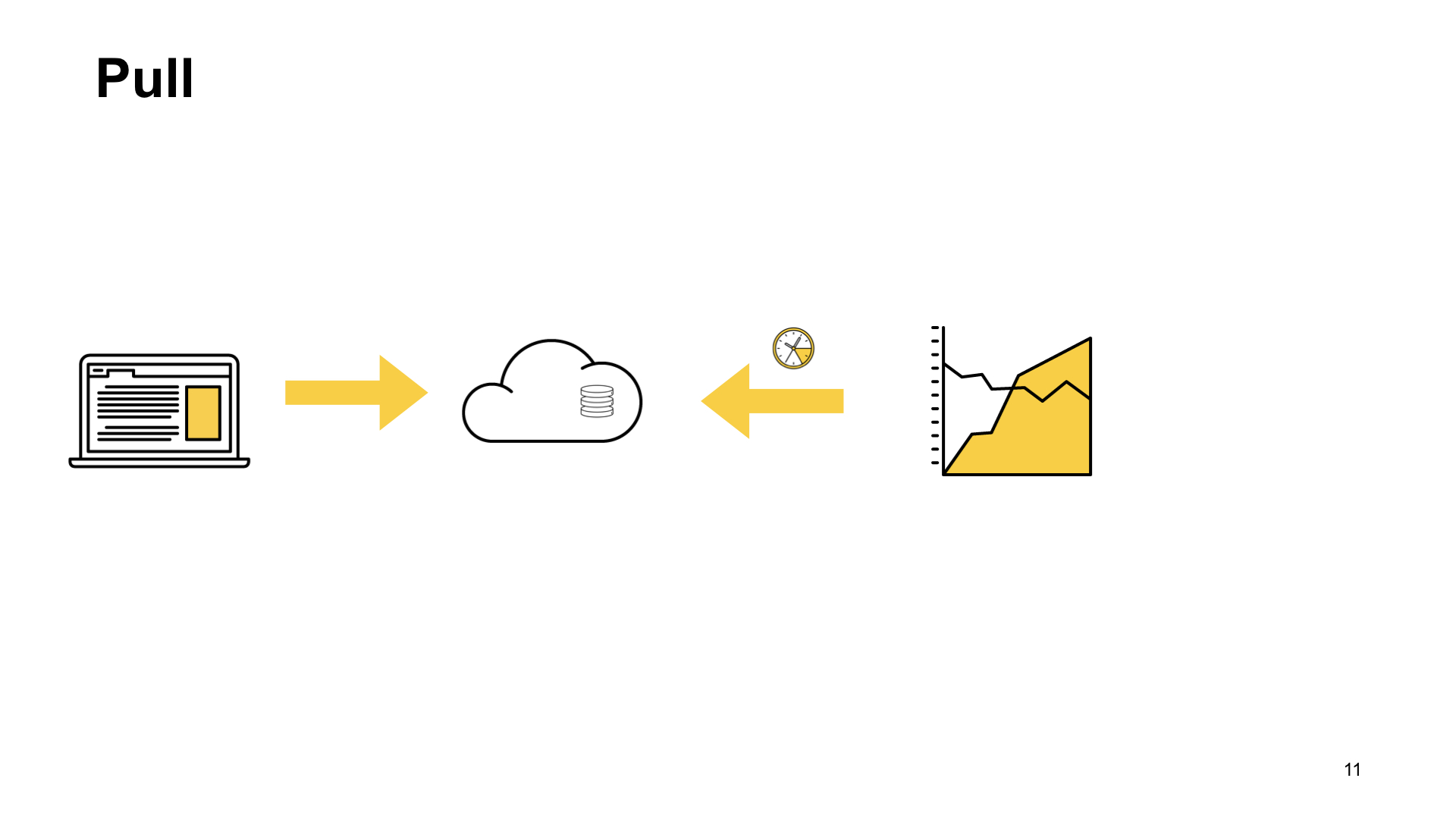
Другой вариант — pull-схема. При pull-схеме у нас тот же сценарий. Приходит к нам запрос от пользователя, мы его как-то сохраняем у себя. И потом с какой-то периодичностью — раз в секунду, раз в минуту, кому как удобно — система сбора метрик приходит в специальный эндпоинт нашего приложения и забирает эти показатели.

Еще один вариант — логи. Все мы пишем логи и куда-то их отправляем. Нам ничего не мешает взять эти логи, как-то их обработать и на основе логов получить метрики.
К примеру, мы пишем в лог факт запроса пользователя, потом берем логи, хоп-хоп, посчитали. Типичный пример — это ELK (Elasticsearch, Logstash, Kibana).

Как это устроено у нас? В Яндексе своя инфраструктура, своя система сбора метрик. Она ожидает стандартизированный ответ для ручки, реализующей pull-схему. Плюс у нас есть внутреннее облако, где мы запускаем наше приложение. И все это интегрировано в единую систему. Загружая в облако, мы просто указываем: «Ходи вот в эту ручку и получай метрики».

Вот пример ответа для pull-схемы, который ожидает наша система сбора метрик.
Для себя в команде мы решили выбрать более подходящий нам способ, выделить несколько критериев, по которым мы выберем лучший для нас вариант. Оперативность — это то, как быстро мы можем получить в системе метрик отображение факта какого-либо действия. Зависимость — нужно ли нам дополнительные тулзы ставить или еще как-то настраивать инфраструктуру для получения метрики. И универсальность — насколько этот способ подходит для разных типов приложений.
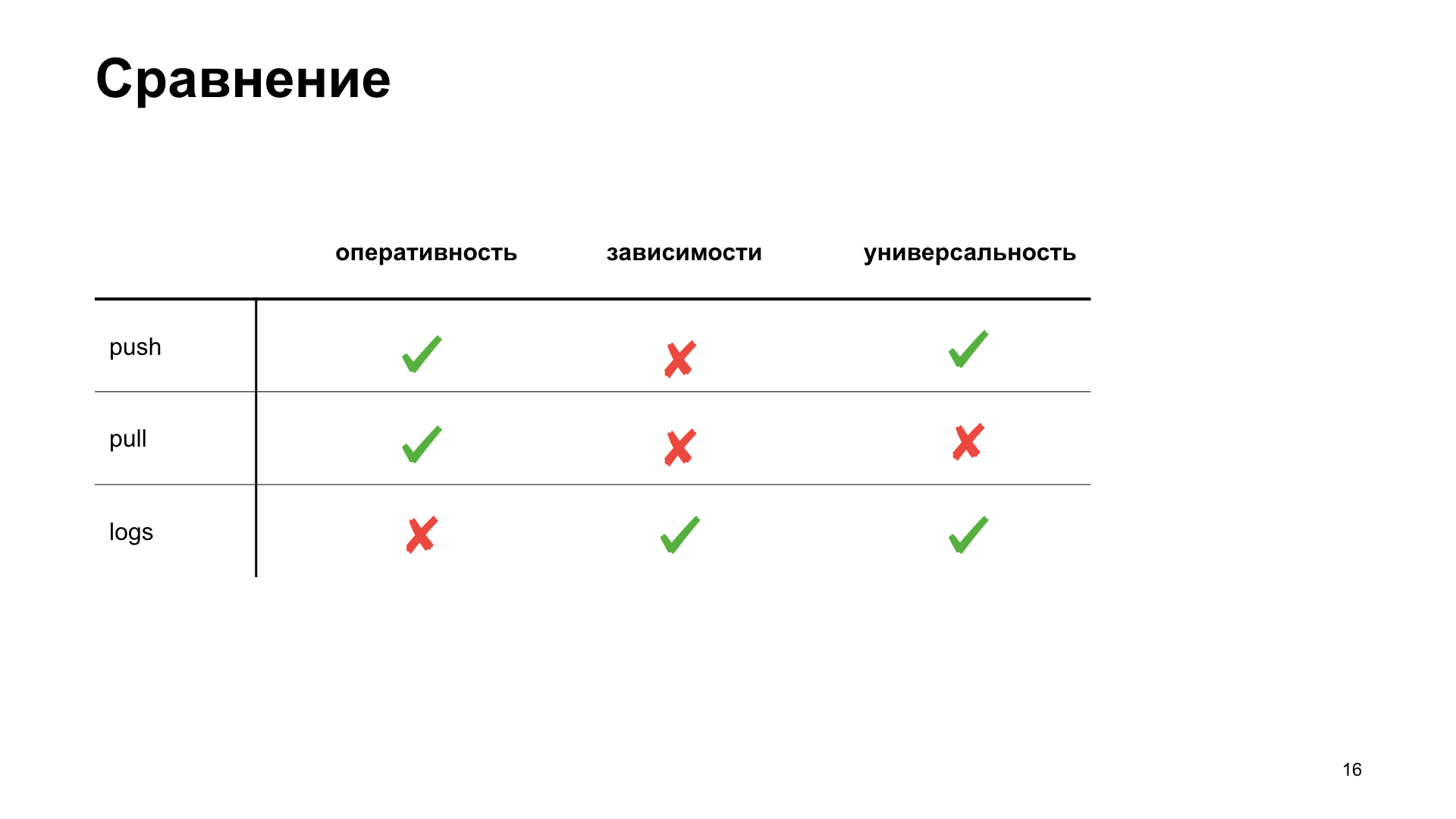
Вот что мы получили в итоге. Хотя по критериям оперативности и универсальности выиграет push-схема. Но мы разрабатываем веб-приложение, и наше облако уже имеет готовую инфраструктуру для работы с этой задачей, так что мы решили для себя выбрать pull-схему. О ней и поговорим.
Чтобы что-то отдать в pull-схему, нам надо это где-то предагрегировать, сохранить. Наша система мониторинга ходит в pull-ручки раз в пять секунд. Где мы можем сохранить? Локально у себя в памяти или в стороннем хранилище.

Если мы сохраняем локально, то как правило, это подходит для случая с одним процессом. А мы у себя в uWSGI запускаем несколько процессов параллельно. Или мы можем использовать какое-то разделяемое хранилище. Что нам приходит в голову при слове «разделяемое хранилище»? Это какой-то Redis, Memcached, реляционные или нереляционные базы данных или даже файл.

Про uWSGI. Напомню тем, кто мало или редко им пользуется: uWSGI — это веб-сервер приложений, который позволяет запускать под собой Python-приложения. Он реализует интерфейс, протокол uWSGI. Этот протокол описан в PEP 333, кому интересно, можете почитать.

Также нам поможет выбрать лучшее решение Яндекс.Танк. Это инструмент нагрузочного тестирования, позволяет обстреливать наше приложение различными профилями нагрузки и строит красивые графики. Или работает в консоли, кому как нравится.

Эксперименты. Мы создадим синтетическое приложение для наших синтетических тестов, будем его обстреливать Танком. uWSGI-приложение будет иметь простейший конфликт с 10 воркерами.

Вот наше приложение на Flask. Полезную нагрузку, которую выполняет наше приложение, мы будем эмулировать пустым циклом.

Производим обстрел, и Яндекс.Танк выдает нам один из таких графиков. Что он показывает? Персентили времен ответа. Наклонная линия — это RPS, которые растут, а гистограммки — это то, в какие персентили укладывался наш веб-сервер при такой нагрузке.
Мы будем брать этот вариант за эталонный и смотреть, как различные варианты хранения метрик влияют на производительность.

Простейший вариант — использовать PostgreSQL. Потому что мы работаем у себя с PostgreSQL, у нас он есть. Давайте используем то, что уже есть готовое.
Допустим, у нас есть табличка в PostgreSQL, в которой мы просто инкрементируем счетчик.

Уже на малых количествах RPS видим сильное ухудшение производительности. Можно сказать, просто огромное.

Следующий вариант — Redis. Но здесь мы поступаем умнее: ставим его локально и ходим к нему не по сети, а через Unix socket. Тоже увеличиваем счетчик.
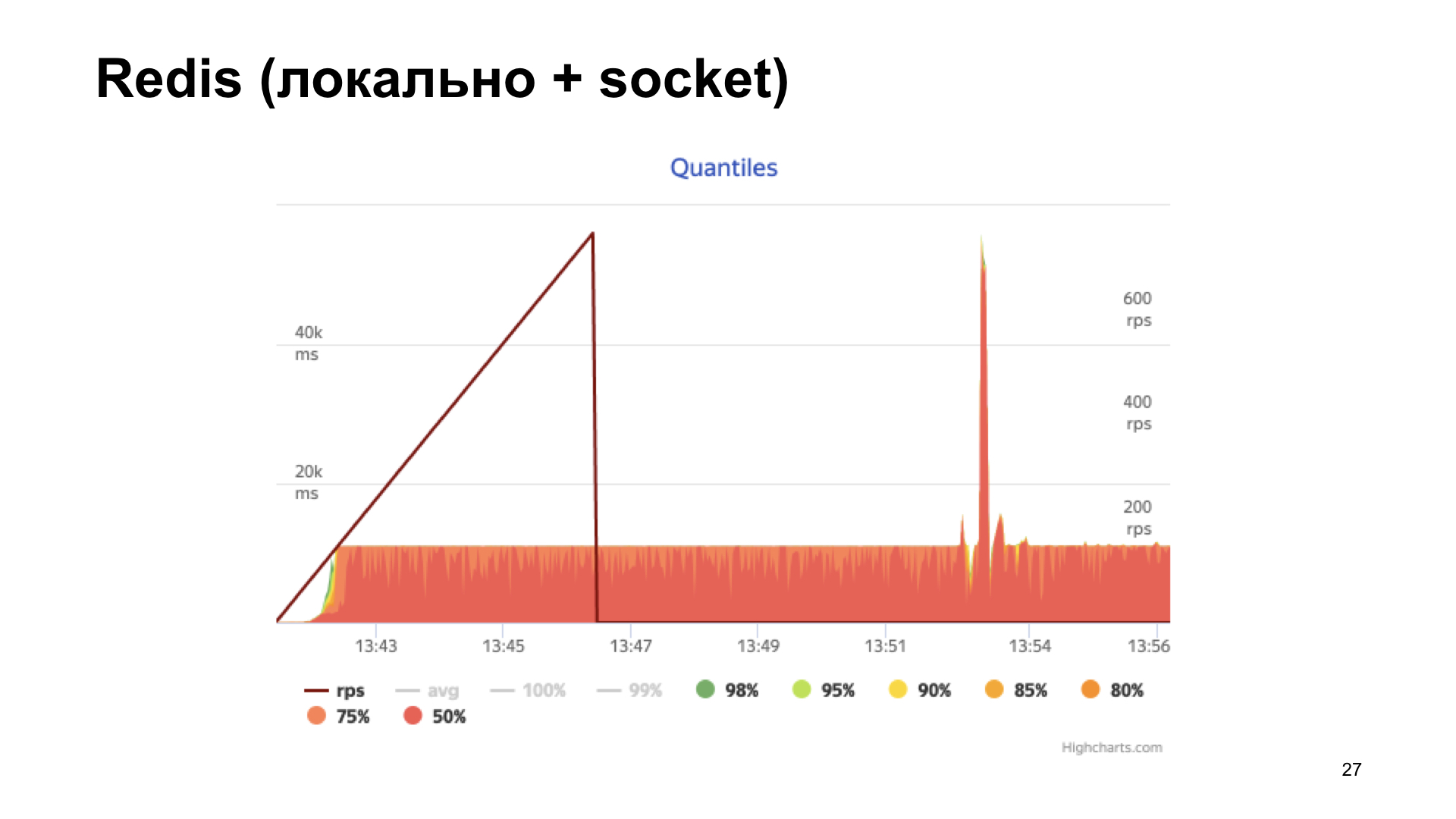
Получаем на выходе гистограмму времен ответов. Мы видим, что тут дела уже обстоят получше, но в какой-то момент мы упираемся в полочку, и дальше производительность уже не растет. Этот вариант кажется более оптимальным, но мы хотим сделать еще лучше.

Тут нам на помощь приходит uWSGI, настоящий комбайн. Там есть множество различных модулей. Mule для запуска подпроцессов, caching framework, cron, metrics subsystem и система alerting. «Cистема метрик subsystem» — звучит многообещающе.

Она умеет складывать какие-то метрики, увеличивать счетчик, уменьшать счетчик, умножать, делить — все что душе угодно.
Единственное, metric subsystem не умеет отдавать именно сложенные в нее metrics.
Почему для нас это важно? Как вы видели ранее, у нас есть ручка для отдачи статистики в определенном формате, и бежит несколько воркеров. Мы не знаем, в какой из воркеров придет запрос, а чтобы отдать все метрики, нам нужно делать какой-то реестр имен и как-то его шэрить между процессами. Это какой-то big deal, хочется такого избежать. Что еще у нас есть?

Конечно, cache subsystem. И тут мы видим: он умеет практически то же самое, а еще способен отдавать имена ключей, хранящихся в кэше. Это то, что нужно.

Сache subsystem — это кэш, встроенный в uWSGI. Быстрый и потокобезопасный модуль, который представляет из себя обычное хранилище типа ключ-значение.

Но поскольку это кэш, есть всем известная вторая проблема: как назвать переменную и как инвалидировать кэш? В нашем случае посмотрим, какие настройки у кэша по умолчанию. Он имеет ограничения на длину ключа. В нашем случае это имя метрики. По умолчанию 2048 байт. И можно в конфиге увеличить, если есть необходимость. Количество элементов, которое он хранит по умолчанию, — 65 536. Кажется, этого значения должно хватить всем. Вряд ли кто-то собирает такое количество метрик со своего приложения.
И ttl по умолчанию — 0. То есть значения хранящихся кэшей не инвалидируются по времени. Значит, мы сможем их получить из кэша и отдать в систему метрик.

Опять-таки, вариант — приложение, которое использует под коробкой uWSGI.
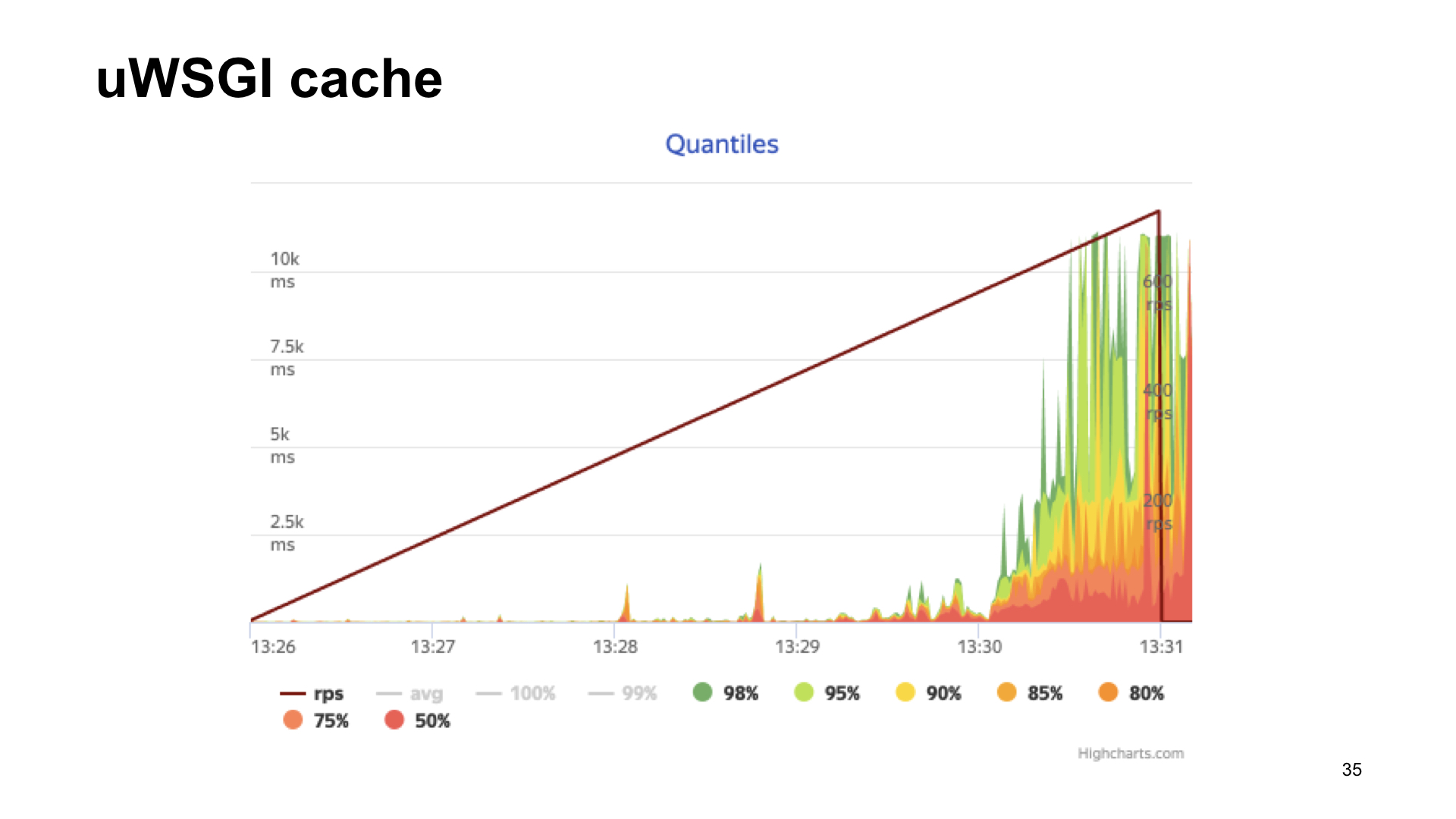
Вот результаты обстрела этого приложения.

Результат без метрик, если с uWSGI, с натяжкой выглядит практически одинаково.
Как видно, в случае с uWSGI мы теряем всего 5% производительности относительно «ванильного» варианта без метрик. Другие варианты имеют довольно значительную просадку, и поэтому в результате зрительского голосования побеждает uWSGI.

Как мы это применили? Мы написали небольшую библиотечку, обертку вокруг uWSGI. К примеру, мы инстацируем экземпляр нашей библиотеки и тут на примере добавляем метрику «Время запросов базы».

Еще нам интересно отслеживать, как происходит работа с кэшем. Мы просто переопределяем методы клиента memcaсhe, сохраняем время на получение данных, время на загрузку и количество cache hit и cache miss.

Как мы это делаем внутри библиотеки? Для отгрузки значений мы получаем имена ключей, хранящихся в кэше, пробегаем по ним и просто отдаем в нужном формате в эндпоинт.
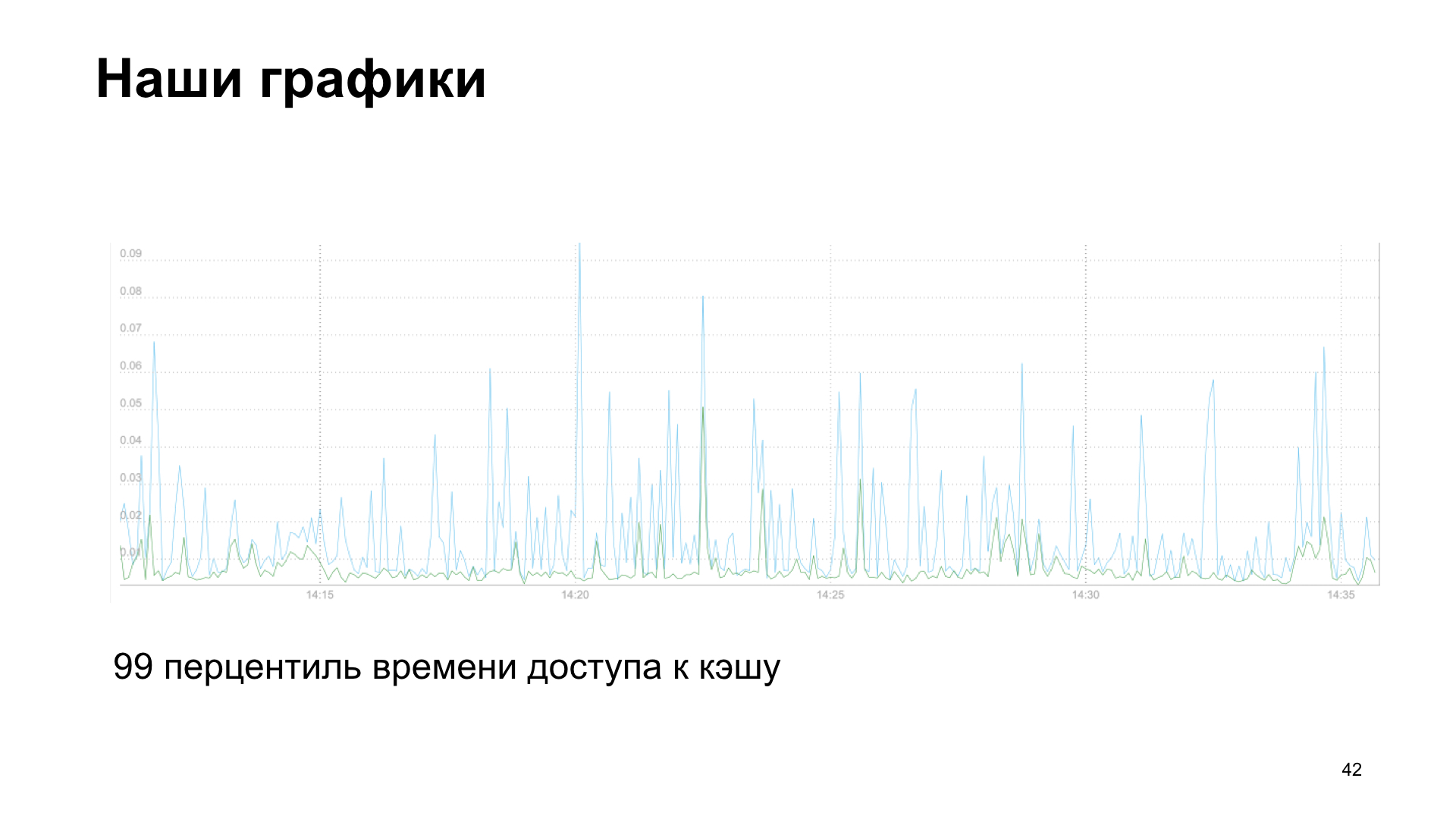
В итоге мы получаем график, в данном случае это 99-й персентиль времени доступа к кэшу, чтение и запись.

Или, как вариант, количество запросов стороннего сервиса в наше API.

У нас есть истории и провала, и успеха. Мы стали добавлять все большее и большее количество метрик и увидели падение производительности. Помогли нам сами метрики. Если вы собираете метрики, то вы можете увидеть, что что-то не в порядке. Поэтому я еще рекомендую вам ретроспективно смотреть метрики, которые вы накопили за неделю, месяц, полгода. И видеть, какая тенденция в каких показателях намечается у вашего приложения. Мы поняли, что стали упираться в подсчет метрик.

Нам помогло профилирование. Здесь вы видите flamegraph, он визуально нам показывает, сколько во время выполнения процесса заняли вызовы тех или иных функций, какие вызовы внесли наибольший вклад по времени. Мы поняли, что мы сделали в первой версии не очень хорошо, использовав pickle. Внутри нашей библиотеки она тратила значительное количество времени на pickling.

Мы отказались от pickling, перевели на caсhe inc, померили всё, стало быстрее.

В новой реализации мы тратим бо́льшую часть времени именно на работу с кэшем, а не на pickling.

К чему я это рассказываю? Я призываю вас начать собирать метрики, смотреть за метриками, ориентироваться на метрики. При выборе возможного варианта сбора метрик сравните варианты, посмотрети, какой для вас лучше подходит. И, конечно же, профилирование — это хорошо. Если вы видите, что что-то не так, что-то замедляется, — профилируйте.
Всем спасибо! Как я обещал, ссылочки:
- Яндекс.Танк,
- утилита профилирования py-spy, написана на Rust,
- доклад Александра Кошелева об использовании uWSGI.
