Суть рассказа о самом популярном пакетном менеджере для Kubernetes можно было бы изобразить с помощью эмоджи:

На самом же деле, все будет немножечко сложнее, и рассказ полон технических подробностей о том, как сделать Helm безопасным.
Все в этой статье относится к Helm 2. Эта версия сейчас находится в продакшене и, скорее всего, именно его вы сейчас используете, и именно в нем есть угрозы безопасности.
О спикере: Александр Хаёров (allexx) занимается разработкой 10 лет, помогает улучшать контент Moscow Python Conf++ и присоединился к комитету Helm Summit. Сейчас работает в Chainstack на позиции development lead — это гибрид между руководителем разработки и человеком, который отвечает за delivery конечных релизов. То есть находится на месте боевых действий, где происходит все от создания продукта до его эксплуатации.
Chainstack — небольшой, активно растущий, стартап, задачей которого является предоставить возможность клиентам забыть об инфраструктуре и сложностях оперирования децентрализованных приложений, команда разработки находится в Сингапуре. Не просите Chainstack продать или купить криптовалюту, но предложите поговорить об энтерпрайз блокчейн фреймовках, и вам с радостью ответят.
Это менеджер пакетов (чартов) для Kubernetes. Самый понятный и универсальный способ приносить приложения в Kubernetes-кластер.

Речь, конечно же, про более структурный и промышленный подход, нежели создание своих YAML-манифестов и написание маленьких утилит.
Почему Helm? В первую очередь потому, что он поддерживается CNCF. Cloud Native — большая организация, является материнской компанией для проектов Kubernetes, etcd, Fluentd и других.
Другой важный факт, Helm — очень популярный проект. Когда в январе 2019 я только задумал рассказать о том, как сделать Helm безопасным, у проекта была тысяча звездочек на GitHub. К маю их стало 12 тысяч.
Многие интересуются Helm, поэтому, даже если вы до сих пор его не используете, вам пригодятся знания относительно его безопасности. Безопасность — это важно.
Основную команду Helm поддерживает Microsoft Azure, и поэтому это довольно стабильный проект в отличие от многих других. Выход Helm 3 Alpha 2 в середине июля свидетельствует о том, что над проектом работает достаточно много людей, и у них есть желание и силы развивать и улучшать Helm.

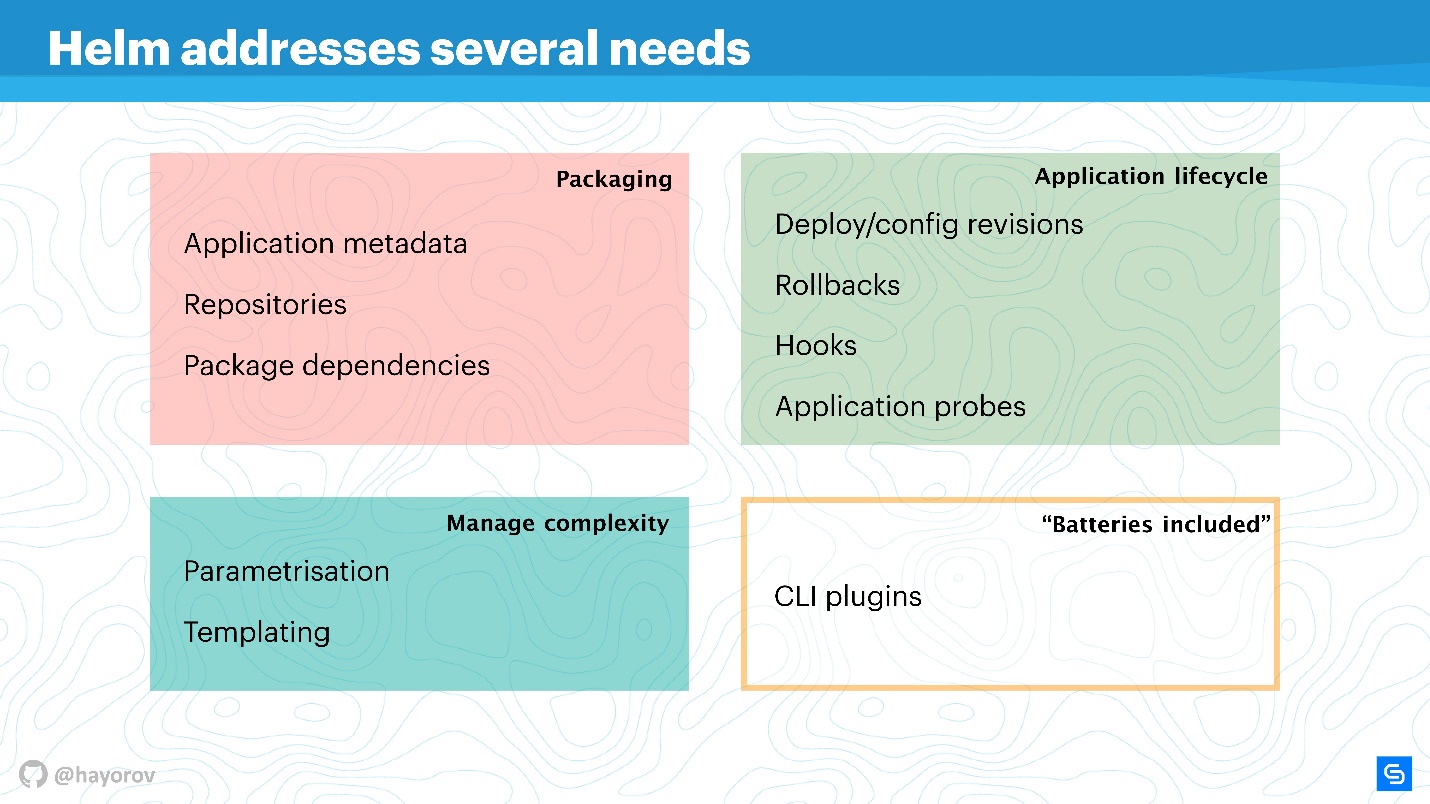
Helm решает несколько корневых проблем управления приложениями в Kubernetes.
Пакетирование устроено понятным образом: есть метаданные в полном соответствии с работой обычного пакетного менеджера для Linux, Windows или MacOS. То есть репозиторий, зависимости от различных пакетов, метаинформация для приложений, настройки, особенности конфигурирования, индексирование информации и т.п Все это Helm позволяет получить и использовать для приложений.
Управление сложностью. Если у вас много однотипных приложений, то нужна параметризация. Из этого вытекают шаблоны, но чтобы не придумывать свой способ создания шаблонов, можно использовать то, что Helm предлагает из коробки.
Менеджмент жизненного цикла приложения — на мой взгляд, это самый интересный и нерешенный вопрос. Это то, почему в свое время я пришел к Helm. Нам нужно было следить за жизненным циклом приложения, мы хотели перенести свой CI/CD и циклы приложений в эту парадигму.
Helm позволяет:
Кроме того у Helm есть «батарейки» — огромное количество вкусных вещей, которые можно включить в виде плагинов, упростив свою жизнь. Плагины можно писать самостоятельно, они достаточно изолированные и не требуют стройной архитектуры. Если вы хотите что-то реализовать, я рекомендую сделать это в виде плагина, а потом возможно включить в upstream.
Helm зиждется на трех основных концепциях:
На схеме концептуально отражена высокоуровневая архитектура Helm.

Напомню, что Helm — это нечто, что связано с Kubernetes. Поэтому нам не обойтись без Kubernetes-кластера (прямоугольник). Компонент kube-apiserver находится на мастере. Без Helm у нас есть Kubeconfig. Helm приносит одну небольшую бинарную, если можно так назвать, утилиту Helm CLI, которая устанавливается на компьютер, лэптоп, мейнфрейм — на все что угодно.
Но этого недостаточно. У Helm есть серверный компонент Tiller. Он представляет интересы Helm внутри кластера, это такое же приложение внутри кластера Kubernetes, как и любой другое.
Следующий компонент Chart Repo — репозиторий с чартами. Есть официальный репозиторий, и может быть приватный репозиторий компании или проекта.
Рассмотрим, как взаимодействуют компоненты архитектуры, когда мы хотим установить приложение с помощью Helm.
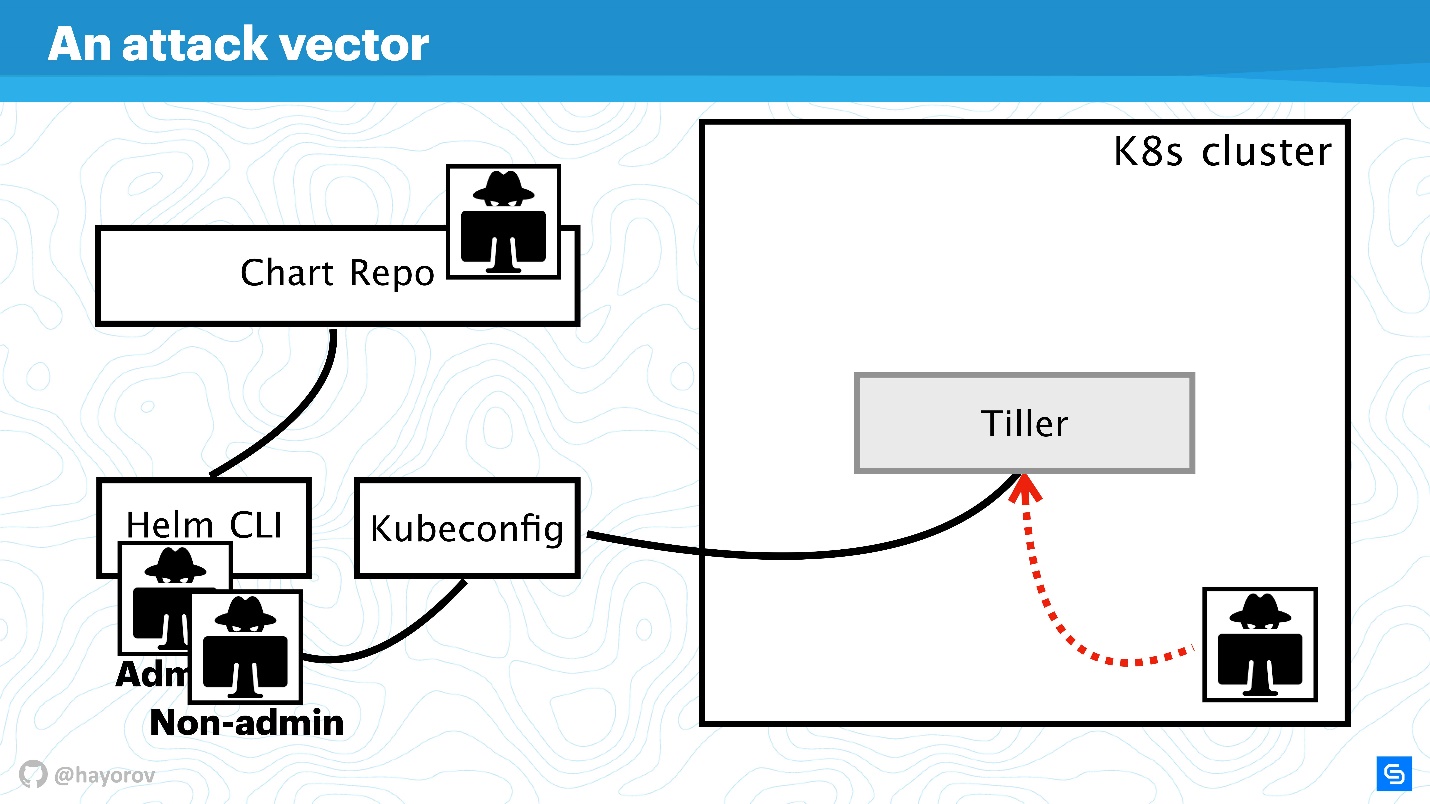
Далее мы усложним схему, чтобы увидеть вектор атак, которым может подвергнуться вся архитектура Helm в целом. А потом попробуем ее защитить.
Первое потенциально слабое место — привилегированный API-пользователь. В рамках схемы это хакер, получивший админский доступ к Helm CLI.
Непривилегированный API-пользователь тоже может представлять собой опасность, если находится где-то рядом. У такого пользователя будет другой контекст, например, он может быть зафиксирован в одном namespace кластера в настройках Kubeconfig.
Наиболее интересным вектором атаки может являться процесс, который находится внутри кластера где-то рядом с Tiller и может к нему обращаться. Это может быть веб-сервер или микросервис, который видит сетевое окружение кластера.
Экзотический, но набирающий популярность, вариант атаки связан с Chart Repo. Чарт, созданный недобросовестным автором, может содержать небезопасные ресурс, и вы выполните его, приняв на веру. Либо он может подменить чарт, который вы скачиваете с официального репозитория, и, например, создать ресурс в виде политик и эскалировать себе доcтуп.
Попробуем отбиться от атак со всех этих четырех сторон и разобраться, где здесь проблемы в архитектуре Helm, и где, возможно, их нет.
Укрупним схему, добавим больше элементов, но сохраним все базовые составляющие.
Helm CLI общается с Chart Repo, взаимодействует с Kubeconfig, работа передается в кластер в компонент Tiller.
Tiller представлен двумя объектами:
Для взаимодействия используются разные протоколы и схемы. С точки зрения безопасности нам наиболее интересны:

Обсудим все эти направления по порядку.
Кажется, это не сама свежая рекомендация, но уверен, до сих пор многие не включили RBAC даже в продакшене, потому что это большая возня и нужно много всего настроить. Тем не менее, призываю это сделать.

https://rbac.dev/ — сайт-адвокат для RBAC. Там собрано огромное количество интересных материалов, которые помогут настроить RBAC, покажут, почему он хорош и как с ним в принципе жить в продакшене.
Попробую объяснить, как работает Tiller и RBAC. Tiller работает внутри кластера под неким сервисным аккаунтом. Как правило, если не настроен RBAC, это будет суперпользователь. В базовой конфигурации Tiller будет админом. Именно поэтому часто говорят, что Tiller — это SSH-туннель к вашему кластеру. В действительности это так, поэтому можно использовать отдельный специализированный сервисный аккаунт вместо Default Service Account на схеме выше.
Когда вы инициализируете Helm, впервые устанавливаете его на сервер, то можете задать сервисный аккаунт с помощью

К сожалению, Helm не сделает это за вас. Вам или вашему администратору Kubernetes-кластера нужно заранее подготовить набор Role, RoleBinding для service-account, чтобы передать Helm.
Возникает вопрос — в чем различие между Role и ClusterRole? Разница в том, что ClusterRole действует для всех namespaces, в отличие от обычных Role и RoleBinding, которые работают только для специализированного namespace. Можно настроить политики как для всего кластера и всех namespaces, так и персонализировано для каждого namespace в отдельности.
Стоит упомянуть, что RBAC позволяет решить еще одну большую проблему. Многие жалуются, что Helm, к сожалению, не является multitenancy (не поддерживает мультиарендность). Если несколько команд потребляют кластер и используют Helm, невозможно в принципе настроить политики и разграничить их доступ в рамках этого кластера, потому что есть некий сервисный аккаунт, из-под которого работает Helm, и он создает из-под него все ресурсы в кластере, что порой очень неудобно. Это правда так — как сам бинарный файл, как процесс, Helm Tiller не имеет понятия о multitenancy.
Однако есть прекрасный способ, который позволяет запустить Tiller в кластере несколько раз. С этим нет никаких проблем, Tiller можно запустить в каждом namespace. Тем самым вы можете воспользоваться RBAC, Kubeconfig как контекстом, и ограничить доступ к специальному Helm.
Это будет выглядеть следующим образом.

Например, есть два Kubeconfig с контекстом для разных команд (два namespace): X Team для команды разработчиков и кластер админа. У кластера админа свой широкий Tiller, который находится в пространстве Kube-system namespace, соответственно продвинутый service-account. И отдельный namespace для команды разработчиков, они смогут деплоить свои сервисы в специальный namespace.
Это рабочий подход, Tiller не настолько прожорлив, чтобы это могло сильно повлиять на ваш бюджет. Это одно из быстрых решений.
Продолжая нашу историю, переключимся от RBAC и поговорим про ConfigMaps.
Helm использует ConfigMaps в качестве хранилища данных. Когда мы говорили об архитектуре, там нигде не было базы данных, в которой хранилась бы информация о релизах, конфигурациях, rollbacks и пр. Для этого используется ConfigMaps.
Основная проблема с ConfigMaps известна — они небезопасны в принципе, в них невозможно хранить sensitive-данные. Речь идет про все, что не должно попасть дальше сервиса, например, пароли. Самым нативным способом для Helm сейчас является переход от использования ConfigMaps к секретам.
Это делается очень просто. Переопределяете настройку Tiller и указываете, что хранилищем будут секреты. Тогда на каждый деплой вы будете получать не ConfigMap, а секрет.

Вы можете возразить, что сами секреты — странная концепция, и это не очень безопасно. Однако, стоит понимать, что этим занимаются сами разработчики Kubernetes. Начиная с версии 1.10, т.е. довольно давно, есть возможность, как минимум, в публичных облаках подключать правильный storage для хранения секретов. Сейчас команда работает над тем, чтобы еще лучше раздавать доступ к секретам, отдельным подам или другим сущностям.
Конечно, останется лимит для хранения данных в 1 Мбайт. Helm здесь использует etcd как распределенное хранилище для ConfigMaps. А там посчитали, что это подходящий чанк данных для репликаций и т.п. По этому поводу есть интересное обсуждение на Reddit, рекомендую найти это забавное чтиво на выходные или прочитать выжимку тут.
Чарты наиболее социально уязвимы и могут стать источником «Man in the middle», особенно если использовать стоковое решение. В первую очередь речь идет о репозиториях, которые выставлены по HTTP.
Обратите внимание на механизм подписей чартов. Технология проста до безобразия. Это то же самое, чем вы пользуетесь на GitHub, обычная PGP машинерия с публичными и приватными ключами. Настройте и будете уверены, имея нужные ключи и подписывая все, что это действительно ваш чарт.
Кроме того, Helm-клиент поддерживает TLS (не в смысле HTTP со стороны сервера, а взаимный TLS). Вы можете использовать серверные и клиентские ключи для того, чтобы общаться. Скажу честно, я не использую такой механизм из-за нелюбви к взаимным сертификатам. В принципе, chartmuseum — основной инструмент выставления Helm Repo для Helm 2 — поддерживает еще и basic auth. Можно использовать basic auth, если это удобнее и спокойнее.
Еще есть плагин helm-gcs, который позволяет размещать Chart Repos в Google Cloud Storage. Это довольно удобно, прекрасно работает и достаточно безопасно, потому что утилизируются все описанные механизмы.

Если включить HTTPS или TLS, использовать mTLS, подключить basic auth, чтобы еще снизить риски, получится безопасный канал общения Helm CLI и Chart Repo.
Следующий шаг очень ответственный — обезопасить Tiller, который находится в кластере и является, с одной стороны, сервером, с другой стороны — сам обращается к другим компонентам и пытается представляться кем-то.
Как я уже сказал, Tiller — сервис, который выставляет gRPC, Helm-клиент приходит к нему по gRPC. По умолчанию, естественно, TLS выключен. Зачем это сделано — вопрос дискуссионный, мне кажется, чтобы упростить настройку на старте.
На мой взгляд, в отличие от mTLS для чартов, тут это уместно и делается очень просто — генерируете PQI инфраструктуру, создаете сертификат, запускаете Tiller, передаете сертификат во время инициализации. После этого можно выполнять все Helm-команды, представляясь сгенерированным сертификатом и приватным ключом.
Тем самым вы обезопасите себя от всех запросов к Tiller извне кластера.
Итак, мы обезопасили канал подключения к Tiller, уже обсудили RBAC и отрегулировали права Kubernetes apiserver, уменьшили домен, с которым он может взаимодействовать.
Посмотрим на финальную схему. Это та же самая архитектура с теми же самыми стрелочками.

Все соединения теперь смело можно рисовать зеленым:
Мы заметно обезопасили кластер, но кто-то умный сказал:
Есть разные способы манипуляций данными и нахождения новых векторов атак. Однако я уверен, что эти рекомендации позволят реализовать базовый промышленный стандарт безопасности.
Эта часть не относится напрямую к безопасности, но тоже будет полезна. Покажу некоторые интересные вещи, о которых немногие знают. Например, как искать чарты — официальные и неофициальные.
В репозитории github.com/helm/charts сейчас порядка 300 чартов и два стрима: stable и incubator. Тот, кто контрибьютит, прекрасно знает, как тяжело попасть из incubator в stable, и как легко из stable вылететь. Однако, это не лучший инструмент, чтобы искать чарты для Prometheus и всего, что вам нравится, по одной простой причине — это не портал, где удобно искать пакеты.
Но есть сервис hub.helm.sh, с помощью которого находить чарты гораздо удобнее. Самое главное, там намного больше внешних репозиториев и доступно почти 800 чаротов. Плюс, вы можете подключить свой репозиторий, если по каким-то причинам не хотите отправлять свои чарты в stable.
Попробуйте hub.helm.sh и давайте вместе его развивать. Этот сервис под Helm-проектом, и вы можете контрибьютить даже в его UI, если вы фронтендер и хотите просто улучшить внешний вид.
Еще хочу обратить ваше внимание на Open Service Broker API integration. Звучит громоздко и непонятно, но решает задачи, с которым все сталкиваются. Поясню на простом примере.

Есть Kubernetes-кластер, в котором мы хотим запустить классическое приложение — WordPress. Как правило, для полной функциональности нужна база данных. Есть много разных решений,, например, можно запустить свой statefull-сервис. Это не очень удобно, но многие так поступают.
Другие, например, мы в Chainstack, используют managed базы данных, например, MySQL или PostgreSQL, для серверов. Поэтому у нас БД находятся где-то в облаке.
Но возникает проблема: нужно связать наш сервис с базой данных, создать flavor базы данных, передать credential и как-то им управлять. Все это обычно делается вручную системным администратором или разработчиком. И нет никакой проблемы, когда приложений мало. Когда их много, нужен комбайн. Такой комбайн есть — это Service Broker. Он позволяет использовать специальный плагин к кластеру публичного облака и заказывать ресурсы у провайдера через Broker, как будто это API. Для этого можно использовать нативные средства Kubernetes.
Это очень просто. Можно запросить, например, Managed MySQL в Azure с базовым tier (это можно настроить). С использованием API Azure база будет создана и подготовлена к использованию. Вам не понадобиться в это вмешиваться, за это отвечает плагин. Например, OSBA (плагин Azure) вернет credential в сервис, передаст это Helm. Вы сможете использовать WordPress с облачным MySQL, вообще не заниматься managed базами данных и не париться о statefull-сервисах внутри.
Можно написать свой плагин и использовать всю эту историю on-premise. Тогда у вас просто будет свой плагин к корпоративному Cloud-провайдеру. Я советую попробовать такой подход, особенно если у вас большой масштаб и вы хотите быстро развернуть dev, staging или всю инфраструктуру под фичу. Это упростит жизнь вашим operations или DevOps.
Еще одна находка, которую я уже упоминал — это плагин helm-gcs, который позволяет использовать Google-buckets (объектное хранилище), чтобы хранить Helm-чарты.
Нужно всего четыре команды, чтобы начать его использовать:
Прелесть в том, что будет использоваться нативный способ gcp для авторизации. Вы можете использовать сервисный аккаунт, аккаунт разработчика — все, что угодно. Это очень удобно и ничего не стоит в эксплуатации. Если вы, как и я, пропагандируете opsless-философию, то это будет очень удобно, особенно для небольших команд.
Helm — не единственное решение для управления сервисами. К нему много вопросов, наверное, поэтому так быстро появилась третья версия. Конечно, есть альтернативы.
Это могут быть как специализированные решения, например, Ksonnet или Metaparticle. Вы можете использовать свои классические средства управления инфраструктурой (Ansible, Terraform, Chef и пр.) для тех же целей, о которых я говорил.
Наконец, есть решение Operator Framework, популярность которого растет.
Оно более нативно для CNCF и Kubernetes, но порог вхождения намного выше, нужно больше программировать и меньше описывать манифесты.
Есть различные addons, такие, как Draft, Scaffold. Они сильно облегчают жизнь, например, разработчикам упрощают цикл отправки и запуска Helm для деплоя тестового окружения. Я бы назвал их расширителями возможностей.
Вот наглядный график о том, где что находится.
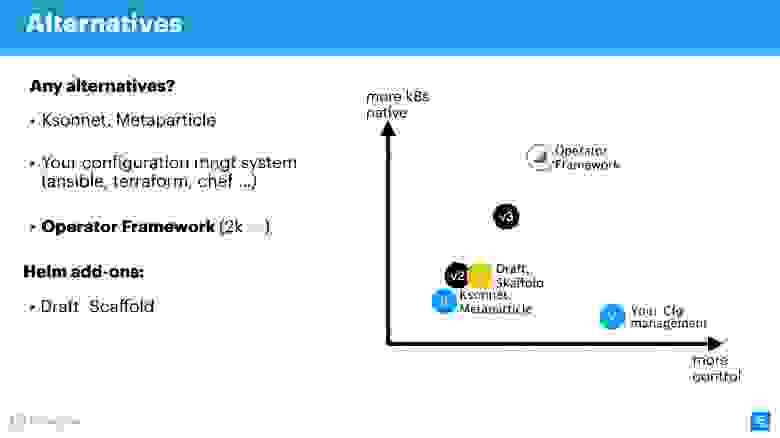
По оси абсцисс уровень вашего личного контроля над происходящим, по оси ординат — уровень нативности Kubernetes. Helm версии 2 находится где-то посерединке. В версии 3 не колоссально, но улучшены и контроль и уровень нативности. Решения уровня Ksonnet все-таки уступают даже Helm 2. Однако на них стоит посмотреть, чтобы знать, что еще есть в этом мире. Конечно, ваш менеджер конфигураций будет у вас под контролем, но абсолютно не нативен для Kubernetes.
Operator Framework абсолютно нативен для Kubernetes и позволяет управлять им намного элегантнее и скрупулёзнее (но помним про уровень вхождения). Скорее, это подойдет для специализированного приложения и создания для него менеджмента, нежели массового комбайна по упаковке огромного количества приложений с помощью Helm.
Расширители просто чуть улучшают контроль, дополняют workflow или срезают углы CI/CD pipelines.
Хорошая новость в том, что появляется Helm 3. Уже вышел релиз альфа-версии Helm 3.0.0-alpha.2, можно попробовать. Он достаточно стабилен, но функциональность пока ограничена.
Зачем нужен Helm 3? В первую очередь это история про исчезновение Tiller, как компонента. Это, как вы уже понимаете, огромный шаг вперед, потому что с точки зрения безопасности архитектуры все упрощается.
Когда создавался Helm 2, а это было во времена Kubernetes 1.8 или даже раньше, многие концепции были незрелые. Например, концепция CRD сейчас активно внедряется, и Helm будет использовать CRD, чтобы хранить структуры. Станет возможным использовать только клиент и не держать серверную часть. Соответственно, использовать нативные команды Kubernetes для работы со структурами и ресурсами. Это огромный шаг вперед.
Появится поддержка нативных репозиториев OCI (Open Container Initiative). Это огромная инициатива, и Helm она интересна в первую очередь для того, чтобы размещать свои чарты. Доходит до того, что, например, Docker Hub поддерживает многие стандарты OCI. Я не загадываю, но возможно, классические провайдеры Docker-репозиториев начнут давать возможность размещать вам свои Helm-чарты.
Спорная для меня история — это поддержка Lua, как templating engine для написания скриптов. Я не большой фанат Lua, но это будет полностью опциональной возможность. Я 3 раза это проверил — использование Lua будет не обязательно. Поэтому тот, кто хочет сможет использовать Lua, тот, кому нравится Go — присоединяйтесь к нашему огромному лагерю и используйте go-tmpl для этого.
Наконец то, чего мне точно не хватало — это появление схемы и валидация типов данных. Больше не будет проблем с int или string, не нужно будет оборачивать ноль в двойные кавычки. Появится JSONS-схема, которая позволит явно это описать для values.
Будет очень сильно переработана event-driven model. Она уже концептуально описана. Посмотрите в ветку Helm 3, и увидите, как много было добавлено событий и хуков и прочего, что сильно упростит и, с другой стороны, добавит контроля над процессами деплоя и реакций по ним.
Helm 3 будет проще, безопаснее и интереснее не потому, что мы не любим Helm 2, а потому что Kubernetes становится более продвинутым. Соответственно, Helm может использовать наработки Kubernetes и создавать на нем отличные менеджеры для Kubernetes.
- коробка — это Helm (это самое подходящее, что есть в последнем релизе Emoji);
- замок — безопасность;
- человечек — решение проблемы.

На самом же деле, все будет немножечко сложнее, и рассказ полон технических подробностей о том, как сделать Helm безопасным.
- Кратко, что такое Helm, если вы не знали или забыли. Какие проблемы он решает и где находится в экосистеме.
- Рассмотрим архитектуру Helm. Ни один разговор о безопасности и о том, как сделать инструмент или решение более безопасным, не может обойтись без понимания архитектуры компонента.
- Обсудим компоненты Helm.
- Самый животрепещущий вопрос — будущее — новая версия Helm 3.
Все в этой статье относится к Helm 2. Эта версия сейчас находится в продакшене и, скорее всего, именно его вы сейчас используете, и именно в нем есть угрозы безопасности.
О спикере: Александр Хаёров (allexx) занимается разработкой 10 лет, помогает улучшать контент Moscow Python Conf++ и присоединился к комитету Helm Summit. Сейчас работает в Chainstack на позиции development lead — это гибрид между руководителем разработки и человеком, который отвечает за delivery конечных релизов. То есть находится на месте боевых действий, где происходит все от создания продукта до его эксплуатации.
Chainstack — небольшой, активно растущий, стартап, задачей которого является предоставить возможность клиентам забыть об инфраструктуре и сложностях оперирования децентрализованных приложений, команда разработки находится в Сингапуре. Не просите Chainstack продать или купить криптовалюту, но предложите поговорить об энтерпрайз блокчейн фреймовках, и вам с радостью ответят.
Helm
Это менеджер пакетов (чартов) для Kubernetes. Самый понятный и универсальный способ приносить приложения в Kubernetes-кластер.

Речь, конечно же, про более структурный и промышленный подход, нежели создание своих YAML-манифестов и написание маленьких утилит.
Helm — это лучшее, что сейчас есть из доступного и популярного.
Почему Helm? В первую очередь потому, что он поддерживается CNCF. Cloud Native — большая организация, является материнской компанией для проектов Kubernetes, etcd, Fluentd и других.
Другой важный факт, Helm — очень популярный проект. Когда в январе 2019 я только задумал рассказать о том, как сделать Helm безопасным, у проекта была тысяча звездочек на GitHub. К маю их стало 12 тысяч.
Многие интересуются Helm, поэтому, даже если вы до сих пор его не используете, вам пригодятся знания относительно его безопасности. Безопасность — это важно.
Основную команду Helm поддерживает Microsoft Azure, и поэтому это довольно стабильный проект в отличие от многих других. Выход Helm 3 Alpha 2 в середине июля свидетельствует о том, что над проектом работает достаточно много людей, и у них есть желание и силы развивать и улучшать Helm.
Helm решает несколько корневых проблем управления приложениями в Kubernetes.
- Пакетирование приложения. Даже приложение типа «Hello, World» на WordPress уже представляет из себя несколько сервисов, и их хочется упаковать вместе.
- Управление сложностью, которая возникает с менеджментом этих приложений.
- Жизненный цикл, который не заканчивается после установки или деплоя приложения. Оно продолжает жить, его нужно обновлять, и помогает в этом Helm и старается принести для этого правильные меры и политики.
Пакетирование устроено понятным образом: есть метаданные в полном соответствии с работой обычного пакетного менеджера для Linux, Windows или MacOS. То есть репозиторий, зависимости от различных пакетов, метаинформация для приложений, настройки, особенности конфигурирования, индексирование информации и т.п Все это Helm позволяет получить и использовать для приложений.
Управление сложностью. Если у вас много однотипных приложений, то нужна параметризация. Из этого вытекают шаблоны, но чтобы не придумывать свой способ создания шаблонов, можно использовать то, что Helm предлагает из коробки.
Менеджмент жизненного цикла приложения — на мой взгляд, это самый интересный и нерешенный вопрос. Это то, почему в свое время я пришел к Helm. Нам нужно было следить за жизненным циклом приложения, мы хотели перенести свой CI/CD и циклы приложений в эту парадигму.
Helm позволяет:
- управлять деплоями, вводит понятие кофигурации и ревизии;
- успешно проводить rollback;
- использовать хуки на разные события;
- добавлять дополнительные проверки приложений и реагировать на их результаты.
Кроме того у Helm есть «батарейки» — огромное количество вкусных вещей, которые можно включить в виде плагинов, упростив свою жизнь. Плагины можно писать самостоятельно, они достаточно изолированные и не требуют стройной архитектуры. Если вы хотите что-то реализовать, я рекомендую сделать это в виде плагина, а потом возможно включить в upstream.
Helm зиждется на трех основных концепциях:
- Chart Repo — описание и массив параметризации, возможной для вашего манифеста.
- Config —то есть значения, которые будут применены (текст, численные значения и т.п.).
- Release собирает в себя два верхних компонента, и вместе они превращаются в Release. Релизы можно версионировать, тем самым добиваясь организации жизненного цикла: маленького на момент установки и крупного на момент upgrade, downgrade или rollback.
Архитектура Helm
На схеме концептуально отражена высокоуровневая архитектура Helm.
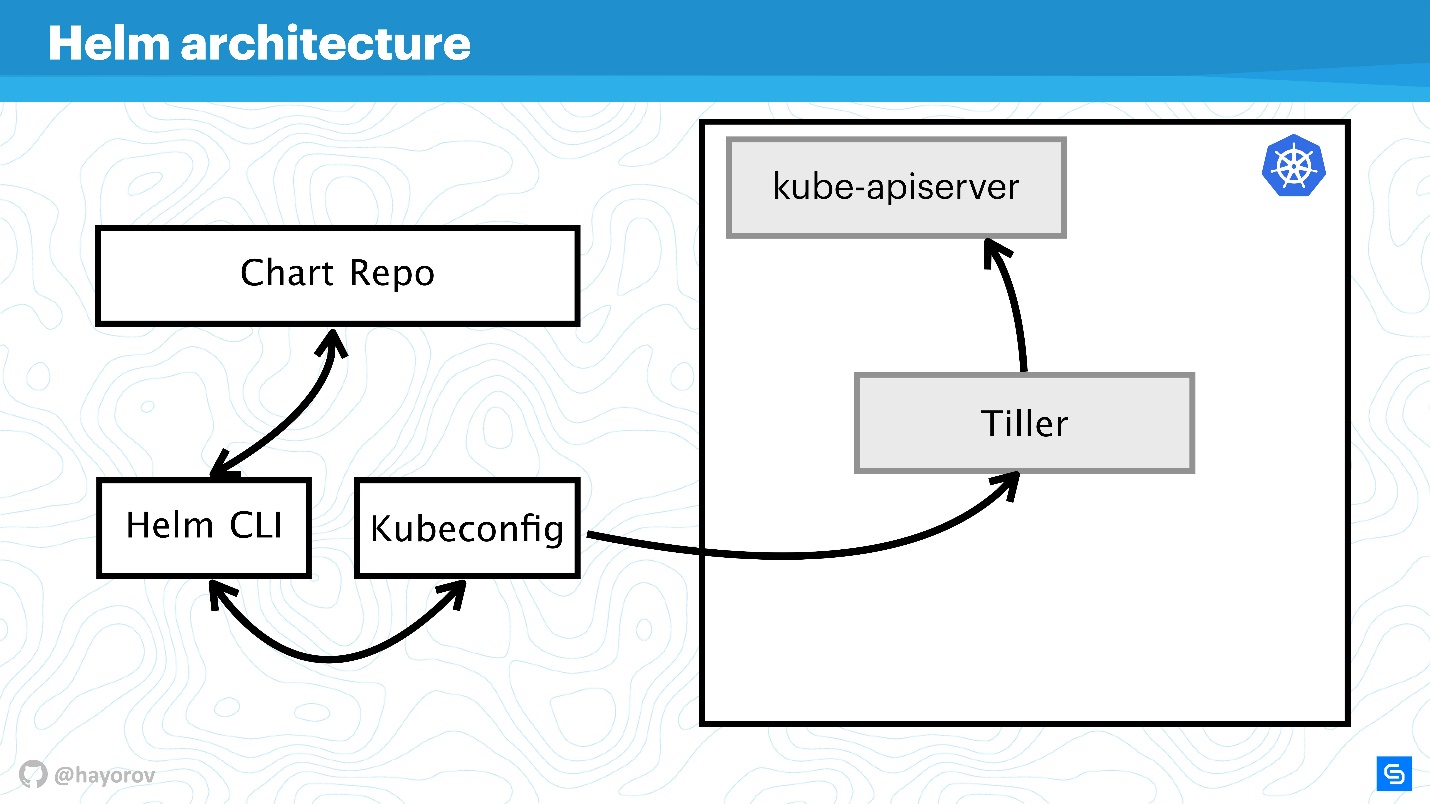
Напомню, что Helm — это нечто, что связано с Kubernetes. Поэтому нам не обойтись без Kubernetes-кластера (прямоугольник). Компонент kube-apiserver находится на мастере. Без Helm у нас есть Kubeconfig. Helm приносит одну небольшую бинарную, если можно так назвать, утилиту Helm CLI, которая устанавливается на компьютер, лэптоп, мейнфрейм — на все что угодно.
Но этого недостаточно. У Helm есть серверный компонент Tiller. Он представляет интересы Helm внутри кластера, это такое же приложение внутри кластера Kubernetes, как и любой другое.
Следующий компонент Chart Repo — репозиторий с чартами. Есть официальный репозиторий, и может быть приватный репозиторий компании или проекта.
Взаимодействие
Рассмотрим, как взаимодействуют компоненты архитектуры, когда мы хотим установить приложение с помощью Helm.
- Мы говорим
Helm install, обращаемся к репозиторию (Chart Repo) и получаем Helm-чарт.
- Helm-утилита (Helm CLI) взаимодействует с Kubeconfig, для того чтобы выяснить к какому кластеру обратиться.
- Получив эту информацию, утилита обращается к Tiller, который находится в нашем кластере, уже как к приложению.
- Tiller обращается к Kube-apiserver, чтобы произвести действия в Kubernetes, создать какие-то объекты (сервисы, поды, реплики, секреты и т.д.).
Далее мы усложним схему, чтобы увидеть вектор атак, которым может подвергнуться вся архитектура Helm в целом. А потом попробуем ее защитить.
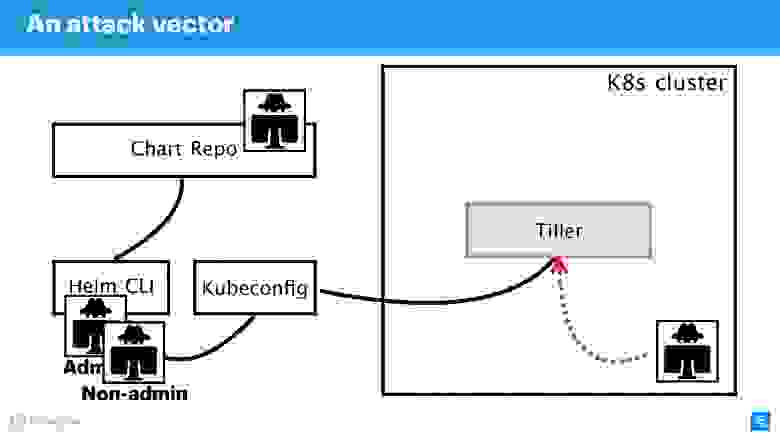
Вектор атак
Первое потенциально слабое место — привилегированный API-пользователь. В рамках схемы это хакер, получивший админский доступ к Helm CLI.
Непривилегированный API-пользователь тоже может представлять собой опасность, если находится где-то рядом. У такого пользователя будет другой контекст, например, он может быть зафиксирован в одном namespace кластера в настройках Kubeconfig.
Наиболее интересным вектором атаки может являться процесс, который находится внутри кластера где-то рядом с Tiller и может к нему обращаться. Это может быть веб-сервер или микросервис, который видит сетевое окружение кластера.
Экзотический, но набирающий популярность, вариант атаки связан с Chart Repo. Чарт, созданный недобросовестным автором, может содержать небезопасные ресурс, и вы выполните его, приняв на веру. Либо он может подменить чарт, который вы скачиваете с официального репозитория, и, например, создать ресурс в виде политик и эскалировать себе доcтуп.
Попробуем отбиться от атак со всех этих четырех сторон и разобраться, где здесь проблемы в архитектуре Helm, и где, возможно, их нет.
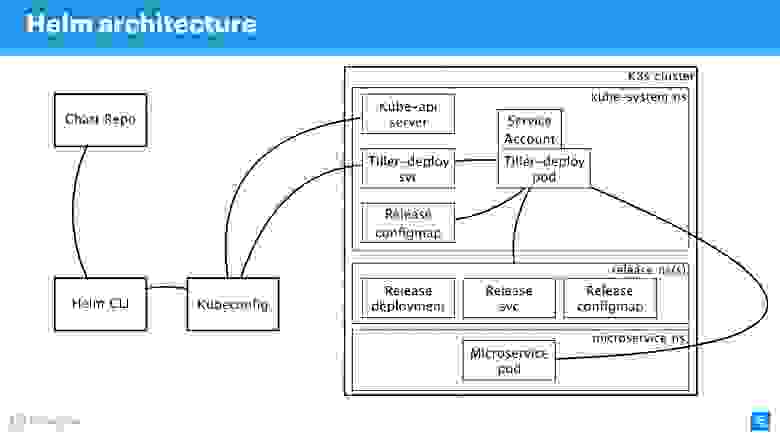
Укрупним схему, добавим больше элементов, но сохраним все базовые составляющие.
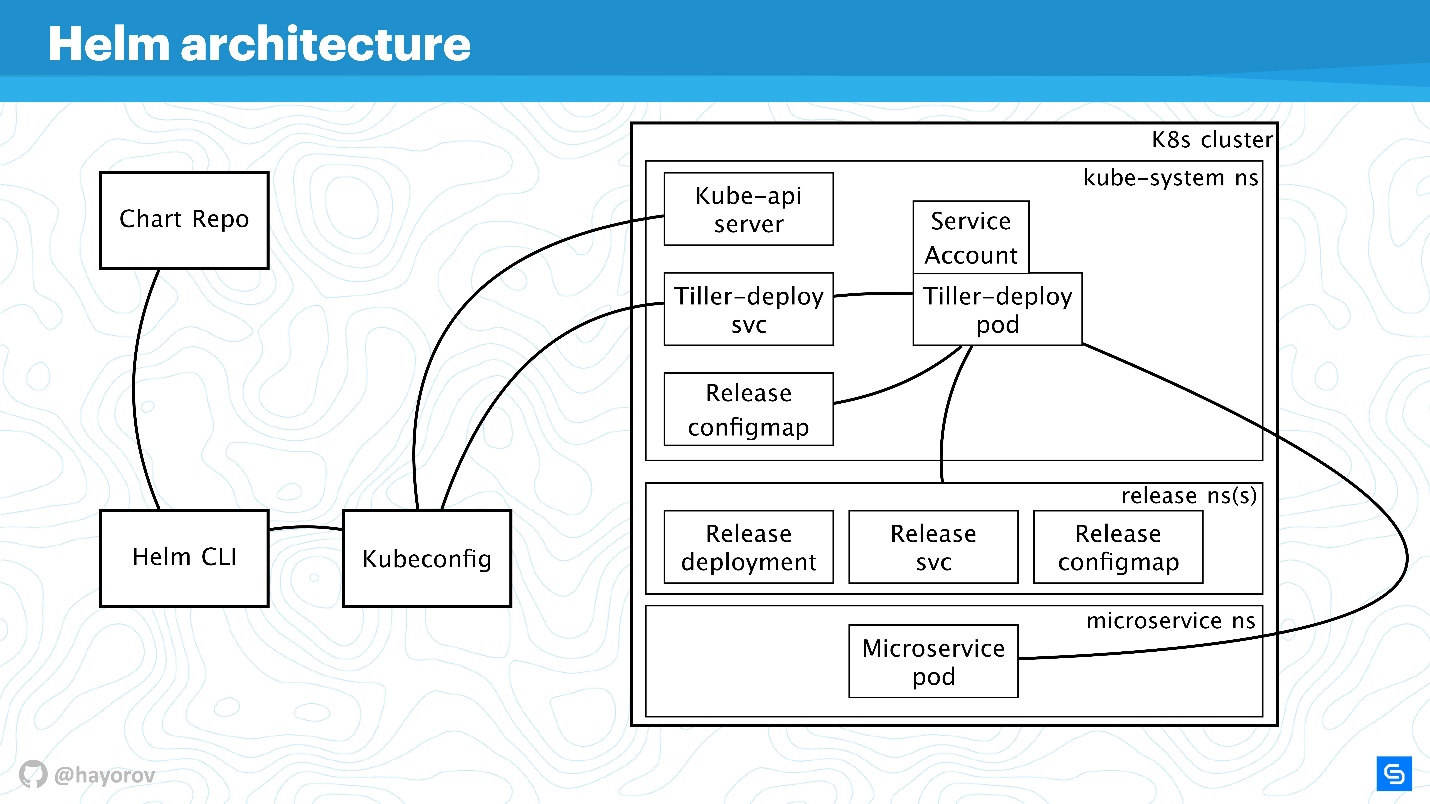
Helm CLI общается с Chart Repo, взаимодействует с Kubeconfig, работа передается в кластер в компонент Tiller.
Tiller представлен двумя объектами:
- Tiller-deploy svc, который выставляет некий сервис;
- Tiller-deploy pod (на схеме в единственном экземпляре в одной реплике), на котором работает вся нагрузка, который обращается к кластеру.
Для взаимодействия используются разные протоколы и схемы. С точки зрения безопасности нам наиболее интересны:
- Механизм, с помощью которого Helm CLI обращается к chart repo: какой протокол, есть ли аутентификация и что с этим можно сделать.
- Протокол по которому Helm CLI, используя kubectl, общается с Tiller. Это RPC-сервер, установленный внутри кластера.
- Сам Tiller доступен для микросервисов, которые находятся в кластере, и взаимодействует с Kube-apiserver.
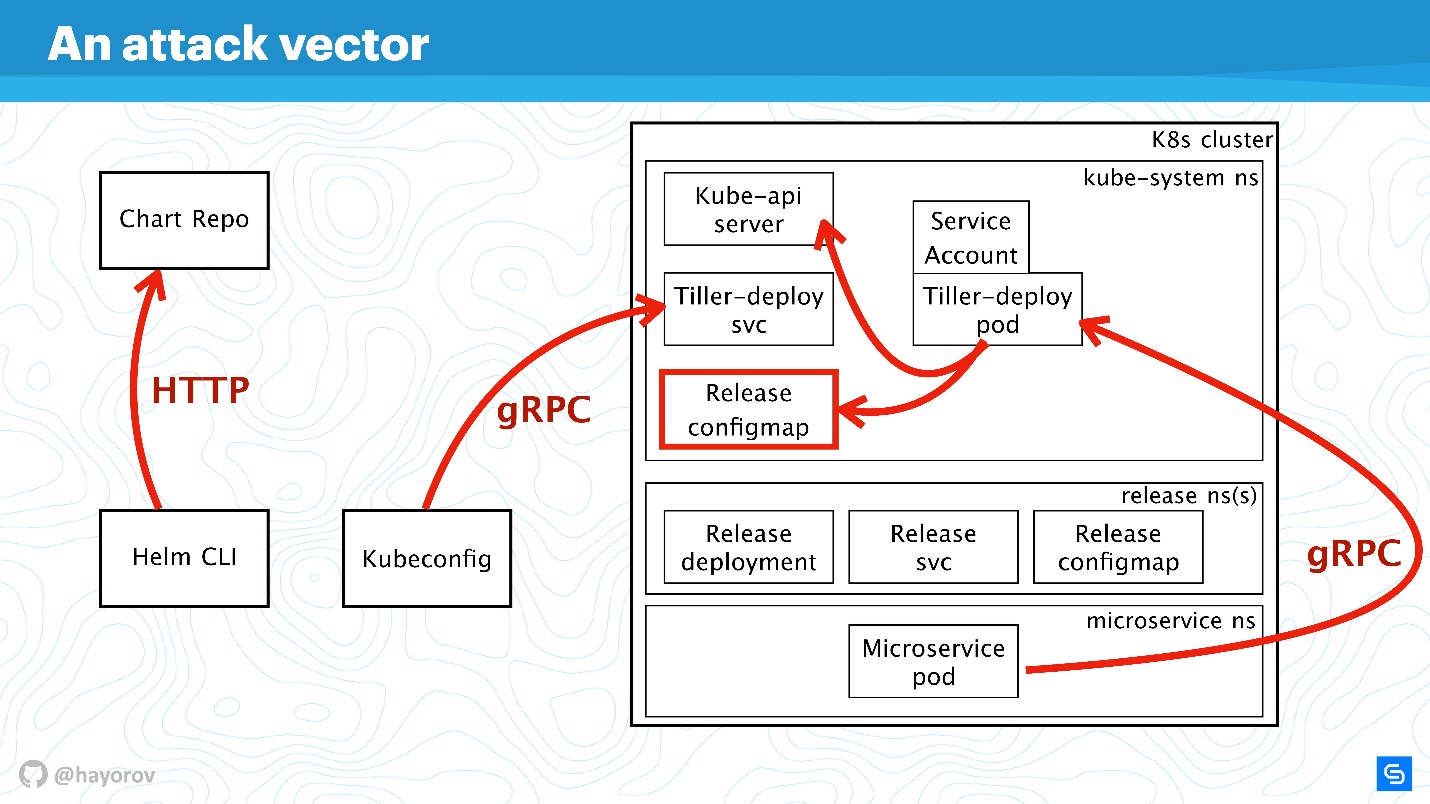
Обсудим все эти направления по порядку.
RBAC
Бесполезно говорить о какой-либо безопасности Helm или другого сервиса внутри кластера, если не включен RBAC.
Кажется, это не сама свежая рекомендация, но уверен, до сих пор многие не включили RBAC даже в продакшене, потому что это большая возня и нужно много всего настроить. Тем не менее, призываю это сделать.
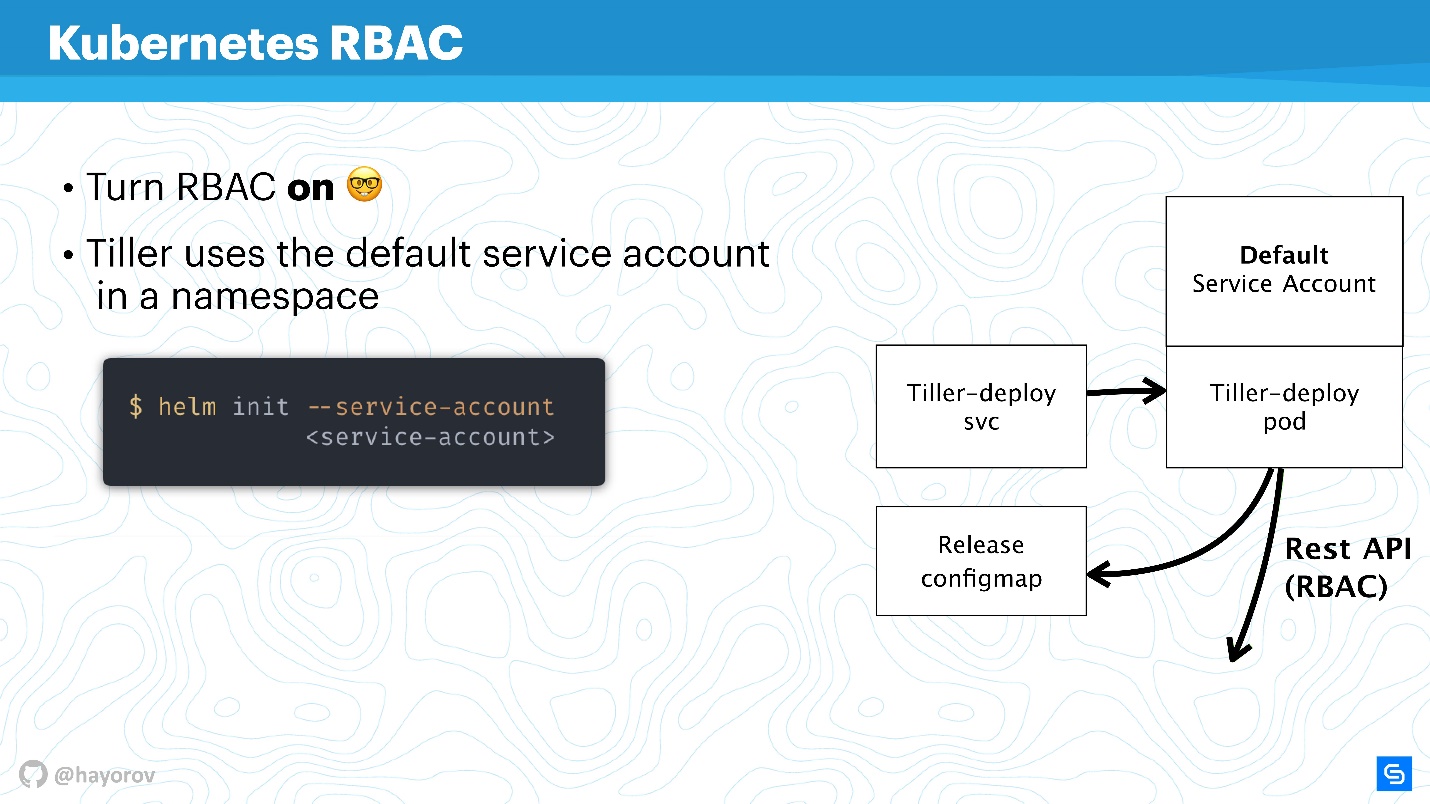
https://rbac.dev/ — сайт-адвокат для RBAC. Там собрано огромное количество интересных материалов, которые помогут настроить RBAC, покажут, почему он хорош и как с ним в принципе жить в продакшене.
Попробую объяснить, как работает Tiller и RBAC. Tiller работает внутри кластера под неким сервисным аккаунтом. Как правило, если не настроен RBAC, это будет суперпользователь. В базовой конфигурации Tiller будет админом. Именно поэтому часто говорят, что Tiller — это SSH-туннель к вашему кластеру. В действительности это так, поэтому можно использовать отдельный специализированный сервисный аккаунт вместо Default Service Account на схеме выше.
Когда вы инициализируете Helm, впервые устанавливаете его на сервер, то можете задать сервисный аккаунт с помощью
--service-account. Это позволит использовать пользователя с минимально необходимым набором прав. Правда, придется создать такую «гирлянду»: Role и RoleBinding.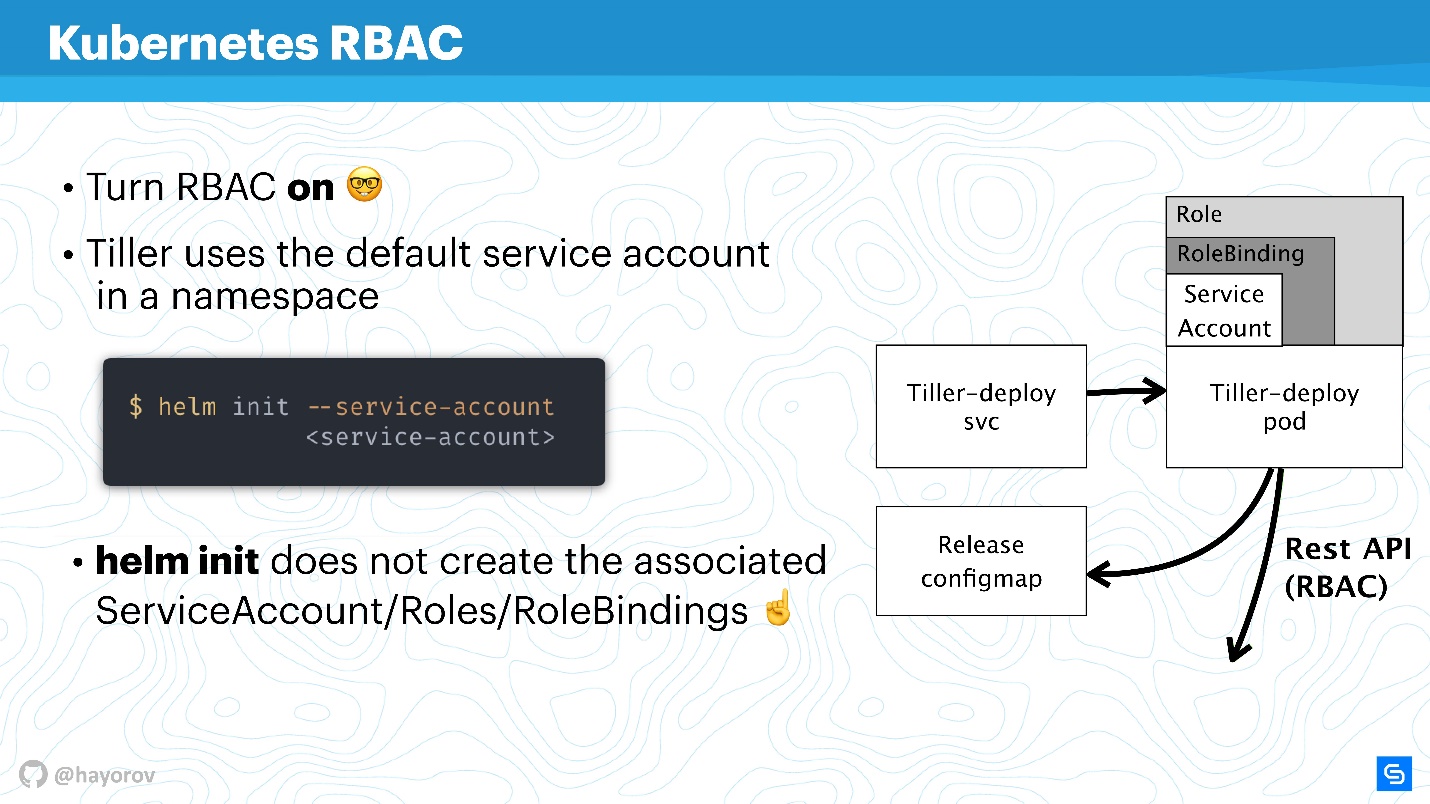
К сожалению, Helm не сделает это за вас. Вам или вашему администратору Kubernetes-кластера нужно заранее подготовить набор Role, RoleBinding для service-account, чтобы передать Helm.
Возникает вопрос — в чем различие между Role и ClusterRole? Разница в том, что ClusterRole действует для всех namespaces, в отличие от обычных Role и RoleBinding, которые работают только для специализированного namespace. Можно настроить политики как для всего кластера и всех namespaces, так и персонализировано для каждого namespace в отдельности.
Стоит упомянуть, что RBAC позволяет решить еще одну большую проблему. Многие жалуются, что Helm, к сожалению, не является multitenancy (не поддерживает мультиарендность). Если несколько команд потребляют кластер и используют Helm, невозможно в принципе настроить политики и разграничить их доступ в рамках этого кластера, потому что есть некий сервисный аккаунт, из-под которого работает Helm, и он создает из-под него все ресурсы в кластере, что порой очень неудобно. Это правда так — как сам бинарный файл, как процесс, Helm Tiller не имеет понятия о multitenancy.
Однако есть прекрасный способ, который позволяет запустить Tiller в кластере несколько раз. С этим нет никаких проблем, Tiller можно запустить в каждом namespace. Тем самым вы можете воспользоваться RBAC, Kubeconfig как контекстом, и ограничить доступ к специальному Helm.
Это будет выглядеть следующим образом.
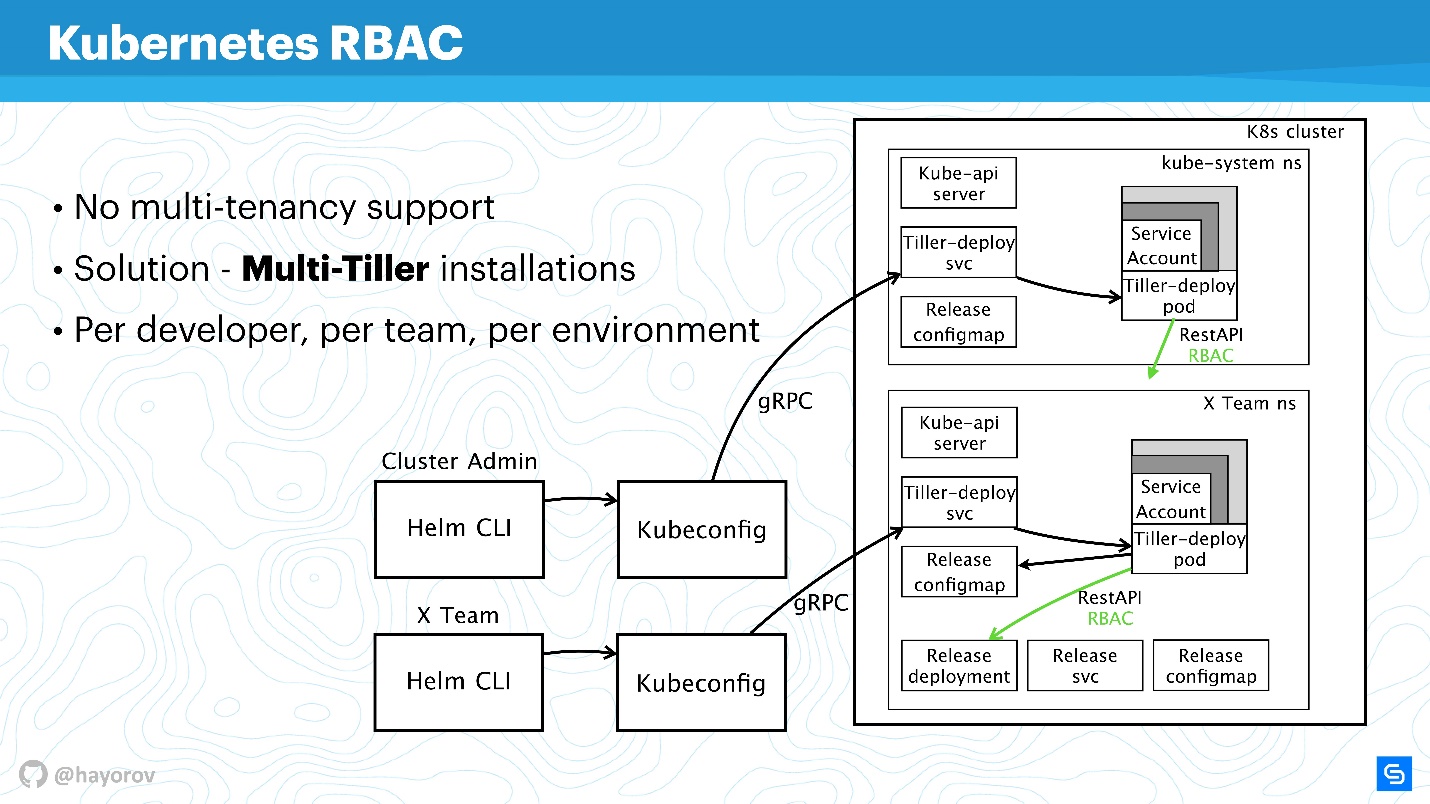
Например, есть два Kubeconfig с контекстом для разных команд (два namespace): X Team для команды разработчиков и кластер админа. У кластера админа свой широкий Tiller, который находится в пространстве Kube-system namespace, соответственно продвинутый service-account. И отдельный namespace для команды разработчиков, они смогут деплоить свои сервисы в специальный namespace.
Это рабочий подход, Tiller не настолько прожорлив, чтобы это могло сильно повлиять на ваш бюджет. Это одно из быстрых решений.
Не стесняйтесь настраивать отдельно Tiller и предоставлять Kubeconfig с контекстом для команды, для конкретного разработчика или для окружения: Dev, Staging, Production (сомнительно, что все будет на одном кластере, однако, сделать так можно).
Продолжая нашу историю, переключимся от RBAC и поговорим про ConfigMaps.
ConfigMaps
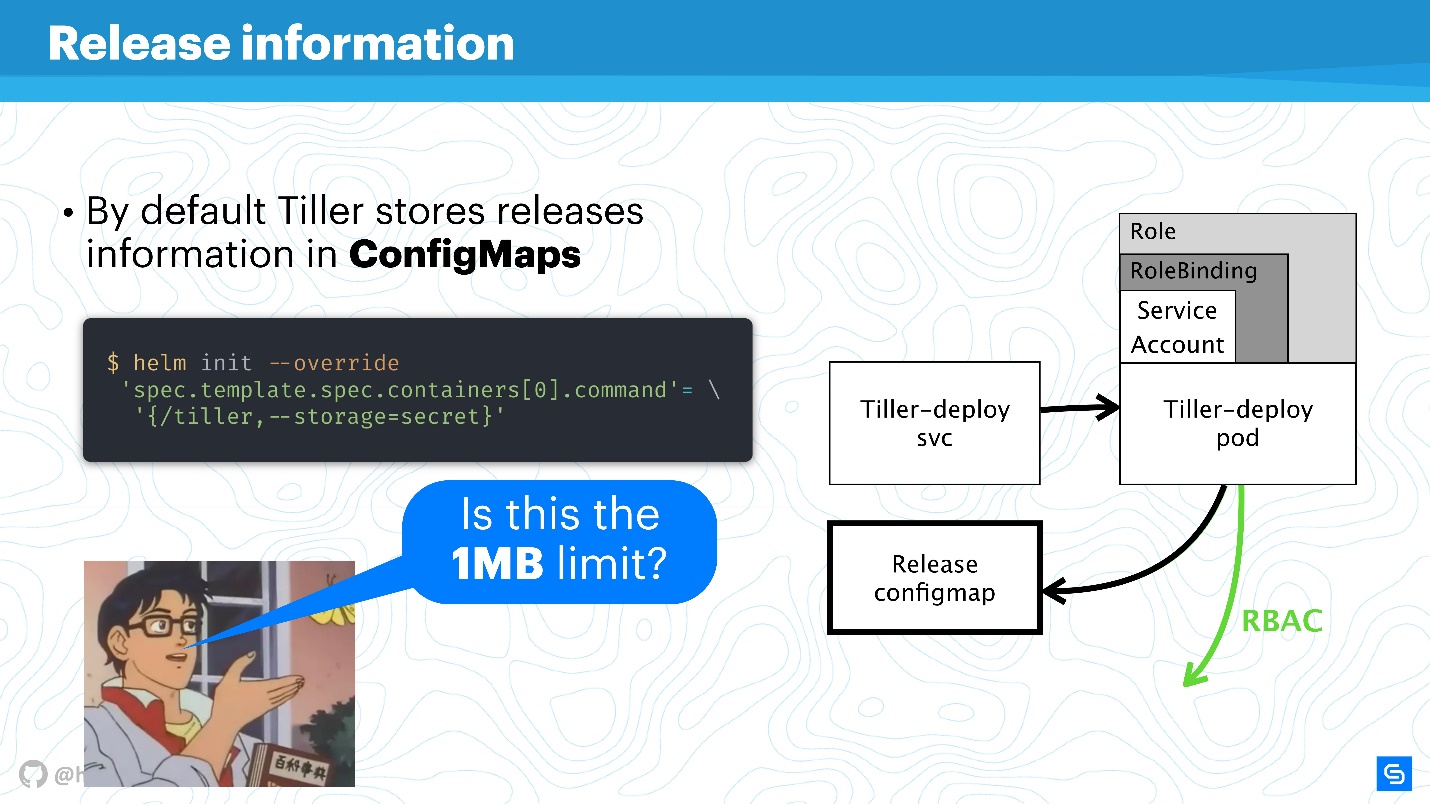
Helm использует ConfigMaps в качестве хранилища данных. Когда мы говорили об архитектуре, там нигде не было базы данных, в которой хранилась бы информация о релизах, конфигурациях, rollbacks и пр. Для этого используется ConfigMaps.
Основная проблема с ConfigMaps известна — они небезопасны в принципе, в них невозможно хранить sensitive-данные. Речь идет про все, что не должно попасть дальше сервиса, например, пароли. Самым нативным способом для Helm сейчас является переход от использования ConfigMaps к секретам.
Это делается очень просто. Переопределяете настройку Tiller и указываете, что хранилищем будут секреты. Тогда на каждый деплой вы будете получать не ConfigMap, а секрет.
Вы можете возразить, что сами секреты — странная концепция, и это не очень безопасно. Однако, стоит понимать, что этим занимаются сами разработчики Kubernetes. Начиная с версии 1.10, т.е. довольно давно, есть возможность, как минимум, в публичных облаках подключать правильный storage для хранения секретов. Сейчас команда работает над тем, чтобы еще лучше раздавать доступ к секретам, отдельным подам или другим сущностям.
Storage Helm лучше перевести на секреты, а их в свою очередь обезопасить централизованно.
Конечно, останется лимит для хранения данных в 1 Мбайт. Helm здесь использует etcd как распределенное хранилище для ConfigMaps. А там посчитали, что это подходящий чанк данных для репликаций и т.п. По этому поводу есть интересное обсуждение на Reddit, рекомендую найти это забавное чтиво на выходные или прочитать выжимку тут.
Chart Repos
Чарты наиболее социально уязвимы и могут стать источником «Man in the middle», особенно если использовать стоковое решение. В первую очередь речь идет о репозиториях, которые выставлены по HTTP.
Определенно, нужно выставлять Helm Repo по HTTPS — это лучший вариант и стоит недорого.
Обратите внимание на механизм подписей чартов. Технология проста до безобразия. Это то же самое, чем вы пользуетесь на GitHub, обычная PGP машинерия с публичными и приватными ключами. Настройте и будете уверены, имея нужные ключи и подписывая все, что это действительно ваш чарт.
Кроме того, Helm-клиент поддерживает TLS (не в смысле HTTP со стороны сервера, а взаимный TLS). Вы можете использовать серверные и клиентские ключи для того, чтобы общаться. Скажу честно, я не использую такой механизм из-за нелюбви к взаимным сертификатам. В принципе, chartmuseum — основной инструмент выставления Helm Repo для Helm 2 — поддерживает еще и basic auth. Можно использовать basic auth, если это удобнее и спокойнее.
Еще есть плагин helm-gcs, который позволяет размещать Chart Repos в Google Cloud Storage. Это довольно удобно, прекрасно работает и достаточно безопасно, потому что утилизируются все описанные механизмы.
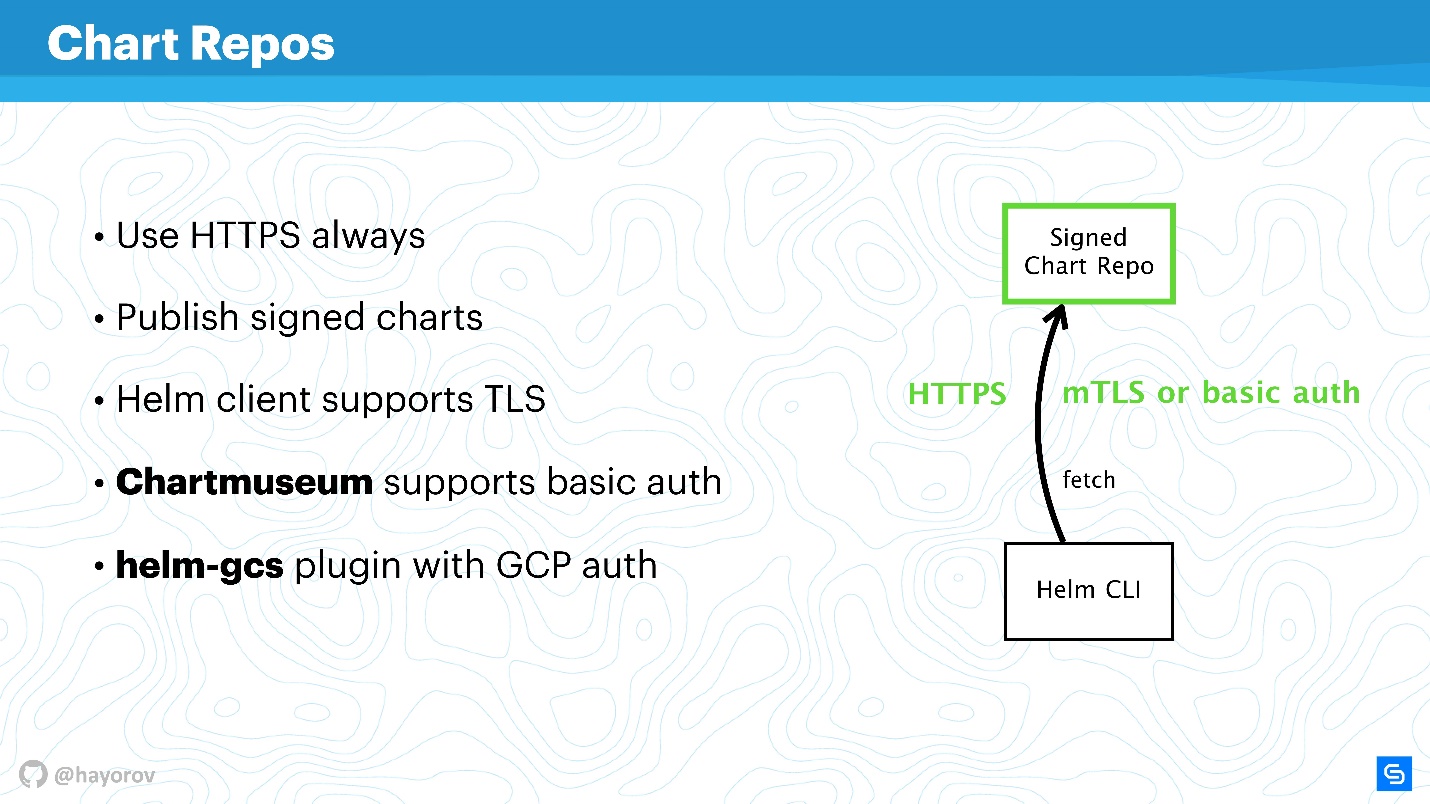
Если включить HTTPS или TLS, использовать mTLS, подключить basic auth, чтобы еще снизить риски, получится безопасный канал общения Helm CLI и Chart Repo.
gRPC API
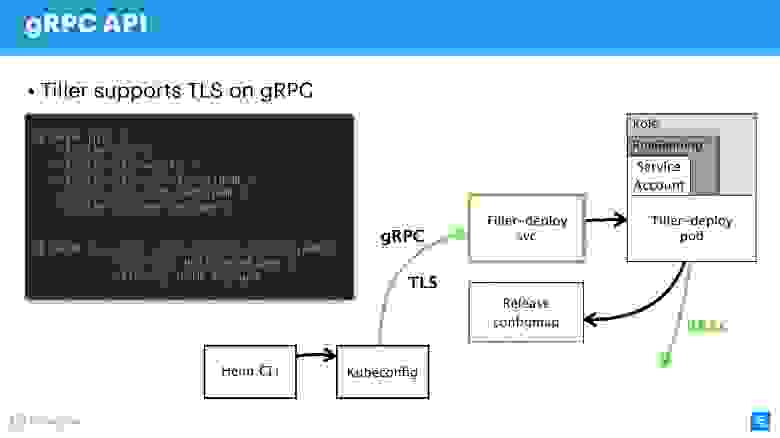
Следующий шаг очень ответственный — обезопасить Tiller, который находится в кластере и является, с одной стороны, сервером, с другой стороны — сам обращается к другим компонентам и пытается представляться кем-то.
Как я уже сказал, Tiller — сервис, который выставляет gRPC, Helm-клиент приходит к нему по gRPC. По умолчанию, естественно, TLS выключен. Зачем это сделано — вопрос дискуссионный, мне кажется, чтобы упростить настройку на старте.
Для production и даже для staging рекомендую включить TLS на gRPC.
На мой взгляд, в отличие от mTLS для чартов, тут это уместно и делается очень просто — генерируете PQI инфраструктуру, создаете сертификат, запускаете Tiller, передаете сертификат во время инициализации. После этого можно выполнять все Helm-команды, представляясь сгенерированным сертификатом и приватным ключом.
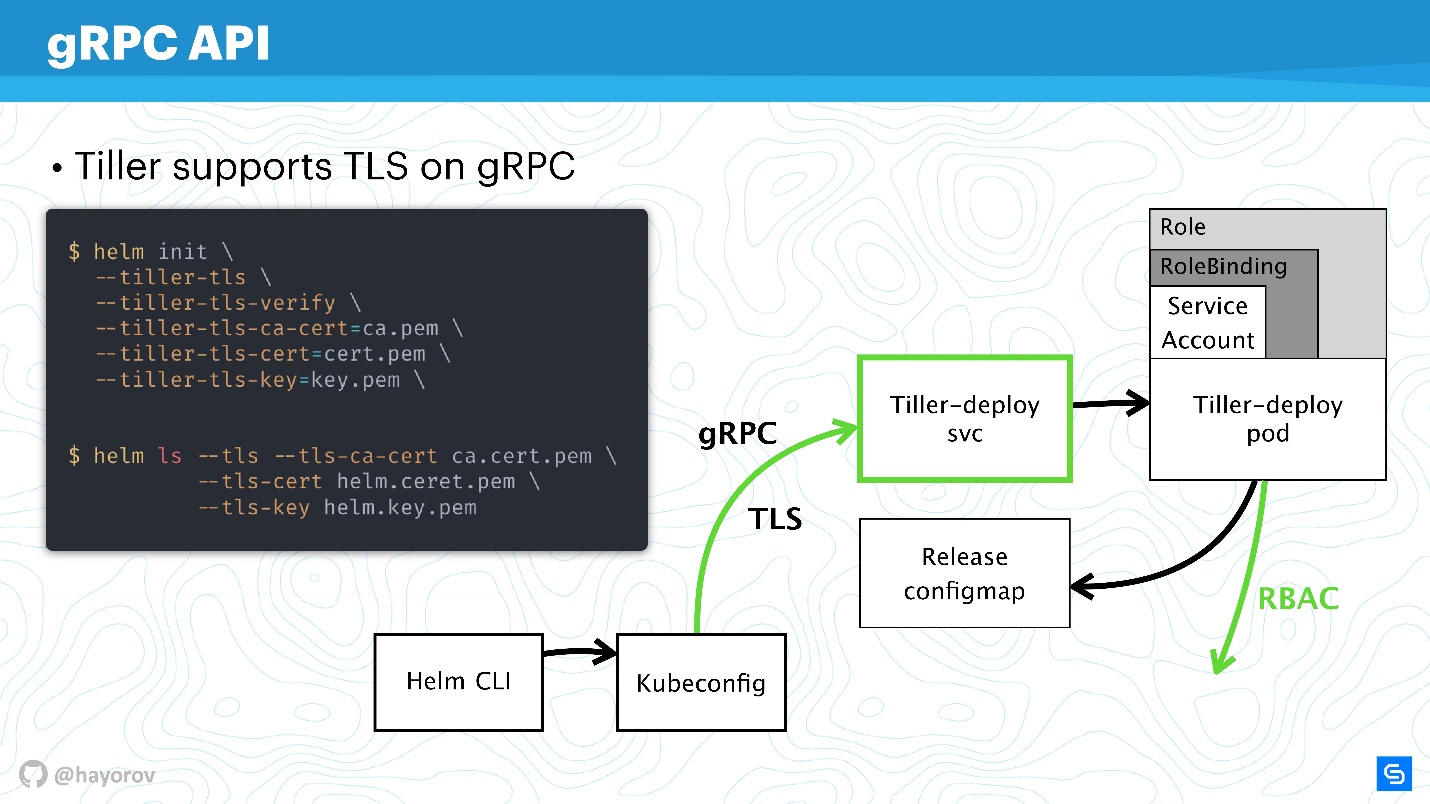
Тем самым вы обезопасите себя от всех запросов к Tiller извне кластера.
Итак, мы обезопасили канал подключения к Tiller, уже обсудили RBAC и отрегулировали права Kubernetes apiserver, уменьшили домен, с которым он может взаимодействовать.
Защищенный Helm
Посмотрим на финальную схему. Это та же самая архитектура с теми же самыми стрелочками.
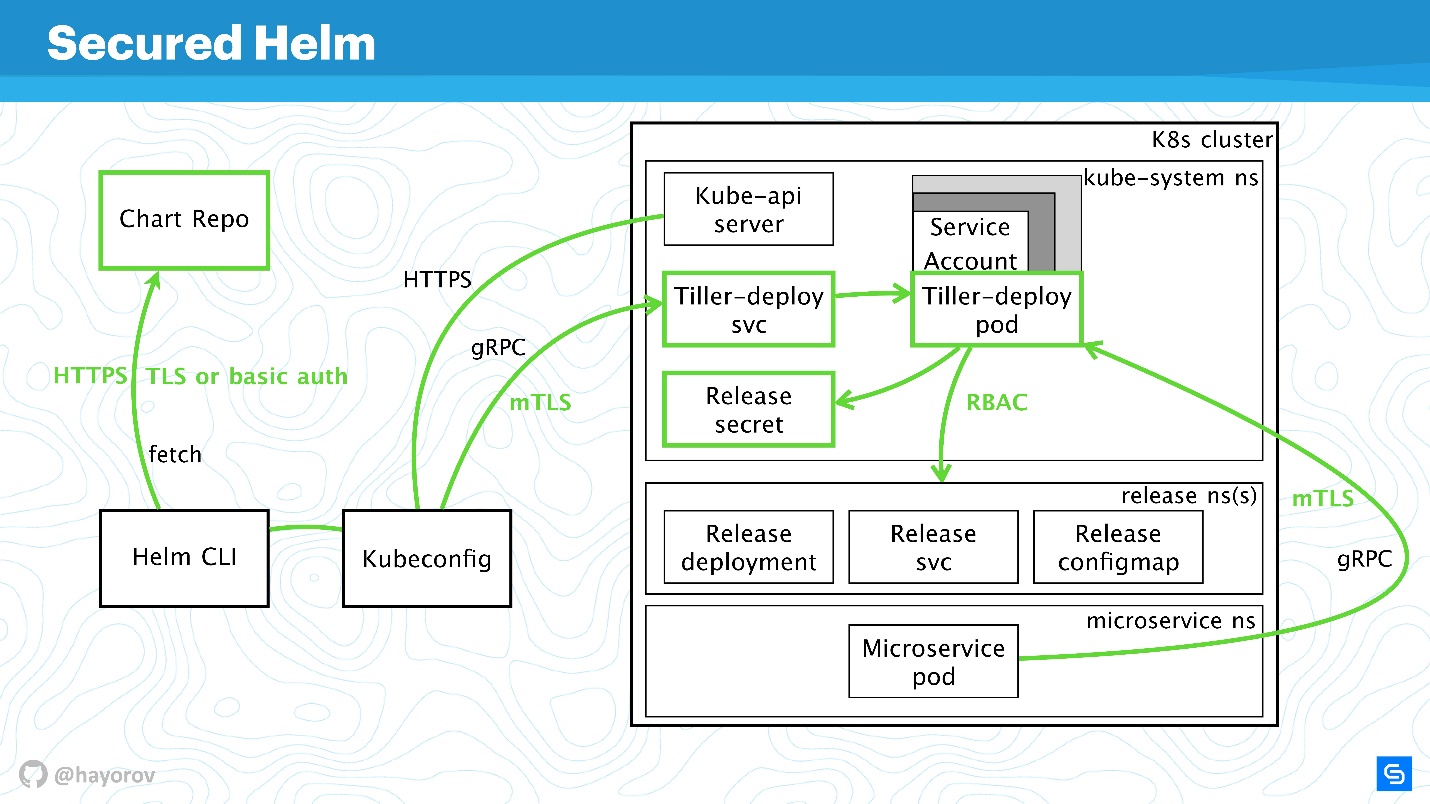
Все соединения теперь смело можно рисовать зеленым:
- для Chart Repo используем TLS или mTLS и basic auth;
- mTLS для Tiller, и он выставлен как gRPC-сервис с TLS, используем сертификаты;
- в кластере используется специальный сервис-аккаунт с Role и RoleBinding.
Мы заметно обезопасили кластер, но кто-то умный сказал:
«Абсолютно безопасное решение может быть только одно — выключенный компьютер, который находится в бетонной коробке и его охраняют солдаты».
Есть разные способы манипуляций данными и нахождения новых векторов атак. Однако я уверен, что эти рекомендации позволят реализовать базовый промышленный стандарт безопасности.
Бонус
Эта часть не относится напрямую к безопасности, но тоже будет полезна. Покажу некоторые интересные вещи, о которых немногие знают. Например, как искать чарты — официальные и неофициальные.
В репозитории github.com/helm/charts сейчас порядка 300 чартов и два стрима: stable и incubator. Тот, кто контрибьютит, прекрасно знает, как тяжело попасть из incubator в stable, и как легко из stable вылететь. Однако, это не лучший инструмент, чтобы искать чарты для Prometheus и всего, что вам нравится, по одной простой причине — это не портал, где удобно искать пакеты.
Но есть сервис hub.helm.sh, с помощью которого находить чарты гораздо удобнее. Самое главное, там намного больше внешних репозиториев и доступно почти 800 чаротов. Плюс, вы можете подключить свой репозиторий, если по каким-то причинам не хотите отправлять свои чарты в stable.
Попробуйте hub.helm.sh и давайте вместе его развивать. Этот сервис под Helm-проектом, и вы можете контрибьютить даже в его UI, если вы фронтендер и хотите просто улучшить внешний вид.
Еще хочу обратить ваше внимание на Open Service Broker API integration. Звучит громоздко и непонятно, но решает задачи, с которым все сталкиваются. Поясню на простом примере.
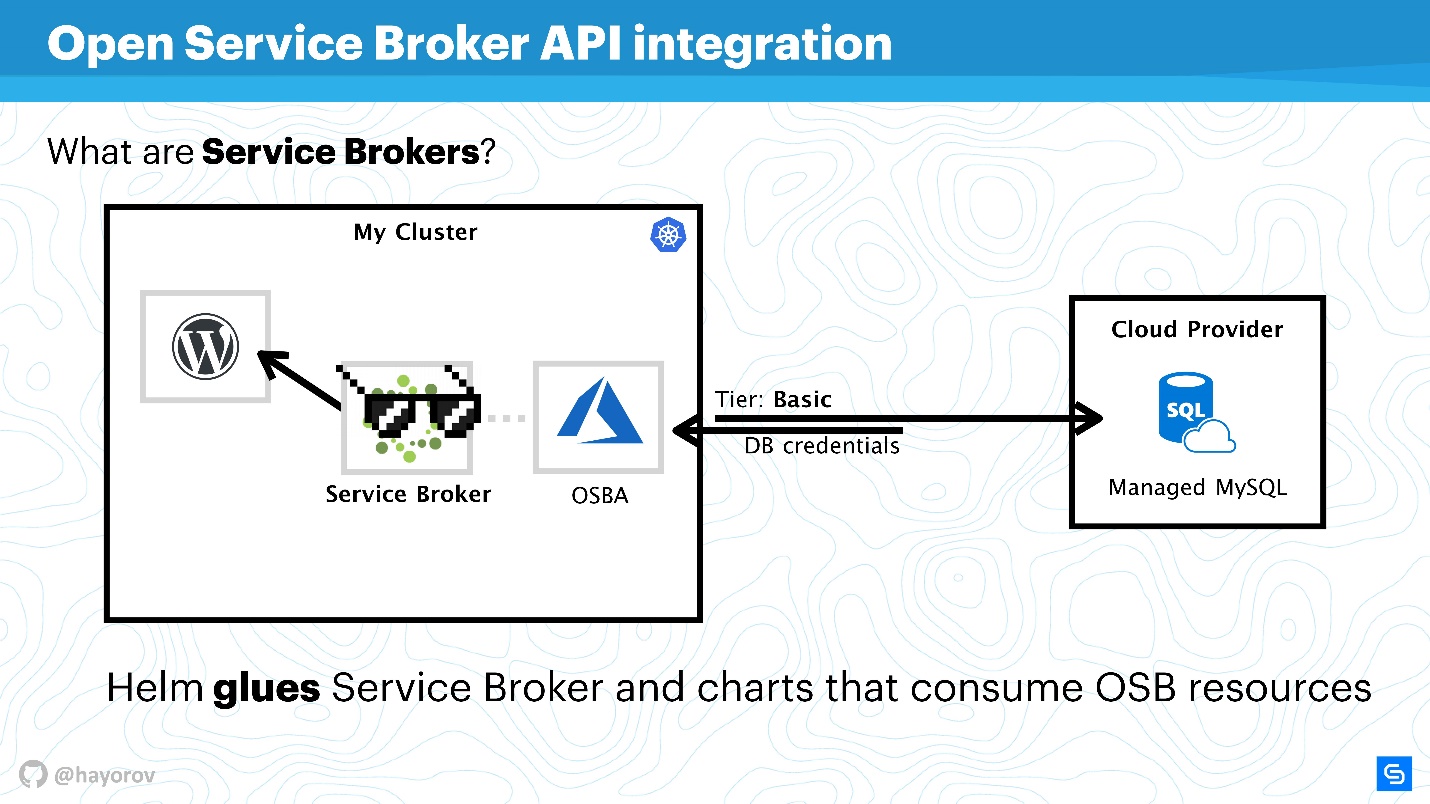
Есть Kubernetes-кластер, в котором мы хотим запустить классическое приложение — WordPress. Как правило, для полной функциональности нужна база данных. Есть много разных решений,, например, можно запустить свой statefull-сервис. Это не очень удобно, но многие так поступают.
Другие, например, мы в Chainstack, используют managed базы данных, например, MySQL или PostgreSQL, для серверов. Поэтому у нас БД находятся где-то в облаке.
Но возникает проблема: нужно связать наш сервис с базой данных, создать flavor базы данных, передать credential и как-то им управлять. Все это обычно делается вручную системным администратором или разработчиком. И нет никакой проблемы, когда приложений мало. Когда их много, нужен комбайн. Такой комбайн есть — это Service Broker. Он позволяет использовать специальный плагин к кластеру публичного облака и заказывать ресурсы у провайдера через Broker, как будто это API. Для этого можно использовать нативные средства Kubernetes.
Это очень просто. Можно запросить, например, Managed MySQL в Azure с базовым tier (это можно настроить). С использованием API Azure база будет создана и подготовлена к использованию. Вам не понадобиться в это вмешиваться, за это отвечает плагин. Например, OSBA (плагин Azure) вернет credential в сервис, передаст это Helm. Вы сможете использовать WordPress с облачным MySQL, вообще не заниматься managed базами данных и не париться о statefull-сервисах внутри.
Можно сказать, что Helm выступает клеем, который с одной стороны позволяет деплоить сервисы, а с другой — потреблять ресурсы облачных провайдеров.
Можно написать свой плагин и использовать всю эту историю on-premise. Тогда у вас просто будет свой плагин к корпоративному Cloud-провайдеру. Я советую попробовать такой подход, особенно если у вас большой масштаб и вы хотите быстро развернуть dev, staging или всю инфраструктуру под фичу. Это упростит жизнь вашим operations или DevOps.
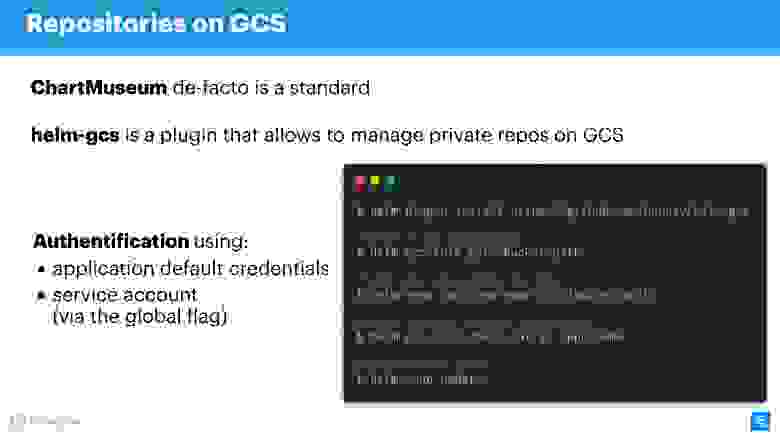
Еще одна находка, которую я уже упоминал — это плагин helm-gcs, который позволяет использовать Google-buckets (объектное хранилище), чтобы хранить Helm-чарты.

Нужно всего четыре команды, чтобы начать его использовать:
- установить плагин;
- инициировать его;
- задать путь к bucket, который находится в gcp;
- опубликовать чарты стандартным способом.
Прелесть в том, что будет использоваться нативный способ gcp для авторизации. Вы можете использовать сервисный аккаунт, аккаунт разработчика — все, что угодно. Это очень удобно и ничего не стоит в эксплуатации. Если вы, как и я, пропагандируете opsless-философию, то это будет очень удобно, особенно для небольших команд.
Альтернативы
Helm — не единственное решение для управления сервисами. К нему много вопросов, наверное, поэтому так быстро появилась третья версия. Конечно, есть альтернативы.
Это могут быть как специализированные решения, например, Ksonnet или Metaparticle. Вы можете использовать свои классические средства управления инфраструктурой (Ansible, Terraform, Chef и пр.) для тех же целей, о которых я говорил.
Наконец, есть решение Operator Framework, популярность которого растет.
Operator Framework — главная альтернатива Helm, на которую следует обратить внимание.
Оно более нативно для CNCF и Kubernetes, но порог вхождения намного выше, нужно больше программировать и меньше описывать манифесты.
Есть различные addons, такие, как Draft, Scaffold. Они сильно облегчают жизнь, например, разработчикам упрощают цикл отправки и запуска Helm для деплоя тестового окружения. Я бы назвал их расширителями возможностей.
Вот наглядный график о том, где что находится.
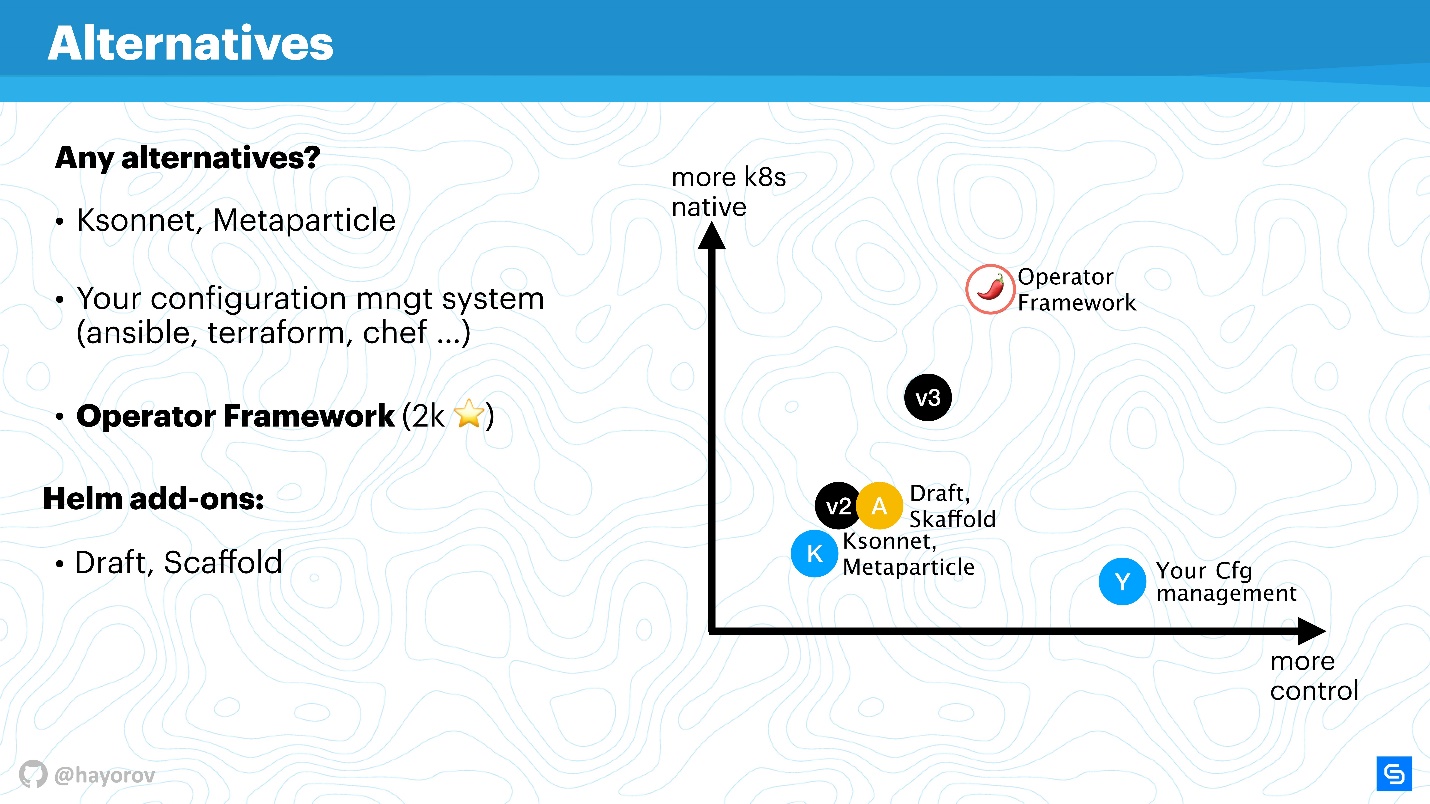
По оси абсцисс уровень вашего личного контроля над происходящим, по оси ординат — уровень нативности Kubernetes. Helm версии 2 находится где-то посерединке. В версии 3 не колоссально, но улучшены и контроль и уровень нативности. Решения уровня Ksonnet все-таки уступают даже Helm 2. Однако на них стоит посмотреть, чтобы знать, что еще есть в этом мире. Конечно, ваш менеджер конфигураций будет у вас под контролем, но абсолютно не нативен для Kubernetes.
Operator Framework абсолютно нативен для Kubernetes и позволяет управлять им намного элегантнее и скрупулёзнее (но помним про уровень вхождения). Скорее, это подойдет для специализированного приложения и создания для него менеджмента, нежели массового комбайна по упаковке огромного количества приложений с помощью Helm.
Расширители просто чуть улучшают контроль, дополняют workflow или срезают углы CI/CD pipelines.
Будущее Helm
Хорошая новость в том, что появляется Helm 3. Уже вышел релиз альфа-версии Helm 3.0.0-alpha.2, можно попробовать. Он достаточно стабилен, но функциональность пока ограничена.
Зачем нужен Helm 3? В первую очередь это история про исчезновение Tiller, как компонента. Это, как вы уже понимаете, огромный шаг вперед, потому что с точки зрения безопасности архитектуры все упрощается.
Когда создавался Helm 2, а это было во времена Kubernetes 1.8 или даже раньше, многие концепции были незрелые. Например, концепция CRD сейчас активно внедряется, и Helm будет использовать CRD, чтобы хранить структуры. Станет возможным использовать только клиент и не держать серверную часть. Соответственно, использовать нативные команды Kubernetes для работы со структурами и ресурсами. Это огромный шаг вперед.
Появится поддержка нативных репозиториев OCI (Open Container Initiative). Это огромная инициатива, и Helm она интересна в первую очередь для того, чтобы размещать свои чарты. Доходит до того, что, например, Docker Hub поддерживает многие стандарты OCI. Я не загадываю, но возможно, классические провайдеры Docker-репозиториев начнут давать возможность размещать вам свои Helm-чарты.
Спорная для меня история — это поддержка Lua, как templating engine для написания скриптов. Я не большой фанат Lua, но это будет полностью опциональной возможность. Я 3 раза это проверил — использование Lua будет не обязательно. Поэтому тот, кто хочет сможет использовать Lua, тот, кому нравится Go — присоединяйтесь к нашему огромному лагерю и используйте go-tmpl для этого.
Наконец то, чего мне точно не хватало — это появление схемы и валидация типов данных. Больше не будет проблем с int или string, не нужно будет оборачивать ноль в двойные кавычки. Появится JSONS-схема, которая позволит явно это описать для values.
Будет очень сильно переработана event-driven model. Она уже концептуально описана. Посмотрите в ветку Helm 3, и увидите, как много было добавлено событий и хуков и прочего, что сильно упростит и, с другой стороны, добавит контроля над процессами деплоя и реакций по ним.
Helm 3 будет проще, безопаснее и интереснее не потому, что мы не любим Helm 2, а потому что Kubernetes становится более продвинутым. Соответственно, Helm может использовать наработки Kubernetes и создавать на нем отличные менеджеры для Kubernetes.
Еще одна хорошая новость в том, что на DevOpsConf Александр Хаёров расскажет, могут ли контейнеры быть безопасными? Напомним, конференция по интеграции процессов разработки, тестирования и эксплуатации пройдет в Москве 30 сентября и 1 октября. До 20 августа еще можно подать доклад и рассказать о своем опыте решения одной из многих задач DevOps-подхода.
За чекпойнтами конференции и новостями следите в рассылке и telegram-канале.
