
Как Dailymotion использует Kubernetes: развертывание приложений
Мы в Dailymotion начали использовать Kubernetes в продакшене 3 года назад. Но развертывать приложения на нескольких кластерах то еще удовольствие, поэтому в последние несколько лет мы старались улучшить наши инструменты и рабочие процессы.
С чего началось
Здесь мы расскажем, как мы развертываем наши приложения на нескольких кластерах Kubernetes по всему миру.
Чтобы развернуть несколько объектов Kubernetes разом, мы используем Helm, и все наши чарты хранятся в одном репозитории git. Чтобы развернуть полный стек приложения из нескольких сервисов, мы используем так называемый обобщающий чарт. По сути, это чарт, который объявляет зависимости и позволяет инициализировать API и его сервисы одной командой.
Еще мы написали небольшой скрипт Python поверх Helm, чтобы делать проверки, создавать чарты, добавлять секреты и развертывать приложения. Все эти задачи выполняются на центральной платформе CI с помощью образа docker.
Перейдем к сути.
Примечание. Когда вы это читаете, первый релиз-кандидат Helm 3 уже был объявлен. Основная версия содержит целый набор улучшений, призванных решить некоторые проблемы, с которыми мы сталкивались в прошлом.
Рабочий процесс разработки чартов
Для приложений мы используем ветвление, и этот же подход решили применить к чартам.
- Ветвь dev используется для создания чартов, которые будут тестироваться на кластерах разработки.
- Когда пул-реквест передается в master, они проверяются в стейджинге.
- Наконец, мы создаем пул-реквест, чтобы передать изменения в ветвь prod и применить их в продакшене.
У каждой среды есть свой частный репозиторий, который хранит наши чарты, и мы используем Chartmuseum с очень полезными API. Таким образом мы гарантируем строгую изоляцию между средами и проверку чартов в реальных условиях, прежде чем использовать их в продакшене.
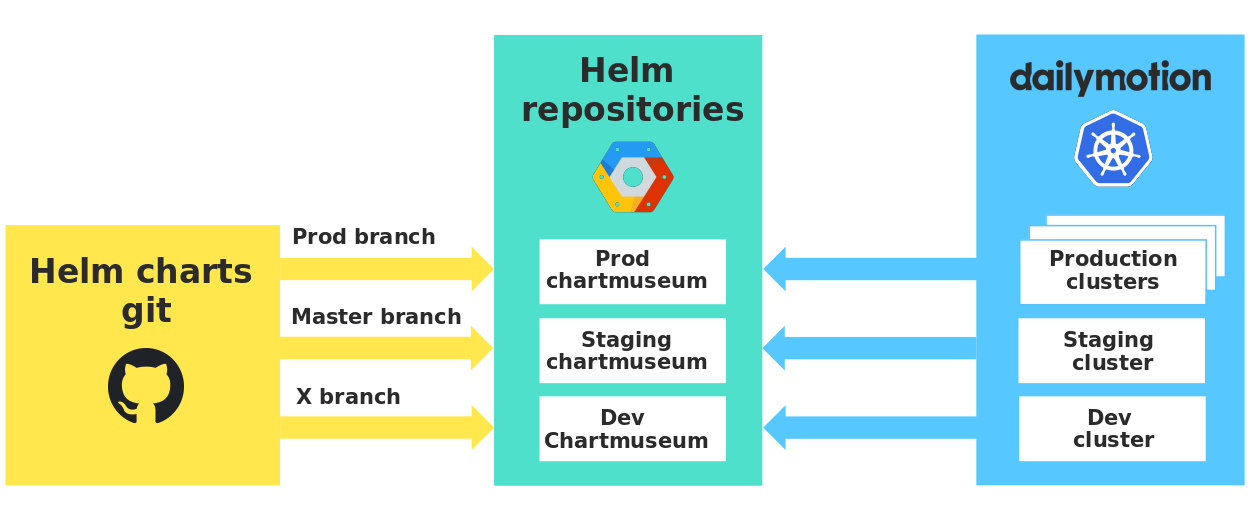
Репозитории чартов в разных средах
Стоит отметить, что когда разработчики отправляют ветвь dev, версия их чарта автоматически отправляется в dev Chartmuseum. Таким образом все разработчики используют один репозиторий dev, и нужно внимательно указывать свою версию чарта, чтобы случайно не использовать чьи-нибудь изменения.
Более того, наш небольшой скрипт Python проверяет объекты Kubernetes по спецификациям Kubernetes OpenAPI с помощью Kubeval, прежде чем опубликовать их в Chartmusem.
Общее описание рабочего процесса разработки чарта
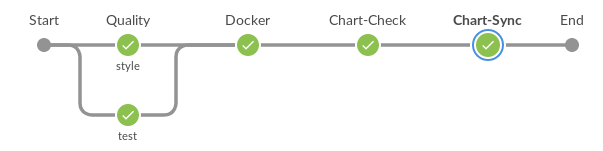
- Настройка задач пайплайна по спецификации gazr.io для контроля качества (lint, unit-test).
- Отправка образа docker с инструментами Python, которые развертывают наши приложения.
- Настройка среды по имени ветви.
- Проверка файлов yaml Kubernetes с помощью Kubeval.
- Автоматическое увеличение версии чарта и его родительских чартов (чартов, которые зависят от изменяемого чарта).
- Отправка чарта в Chartmuseum, который соответствует его среде
Управление различиями в кластерах
Федерация кластеров
Было время, когда мы использовали федерацию кластеров Kubernetes, где можно было объявлять объекты Kubernetes из одной конечной точки API. Но возникли проблемы. Например, некоторые объекты Kubernetes нельзя было создать в конечной точке федерации, поэтому было сложно обслуживать объединенные объекты и другие объекты для отдельных кластеров.
Чтобы решить проблему, мы стали управлять кластерами независимо, что значительно упростило процесс (использовали первую версию federation; во второй что-то могло поменяться).
Геораспределенная платформа
Сейчас наша платформа распределена по 6 регионам — 3 локально и 3 в облаке.
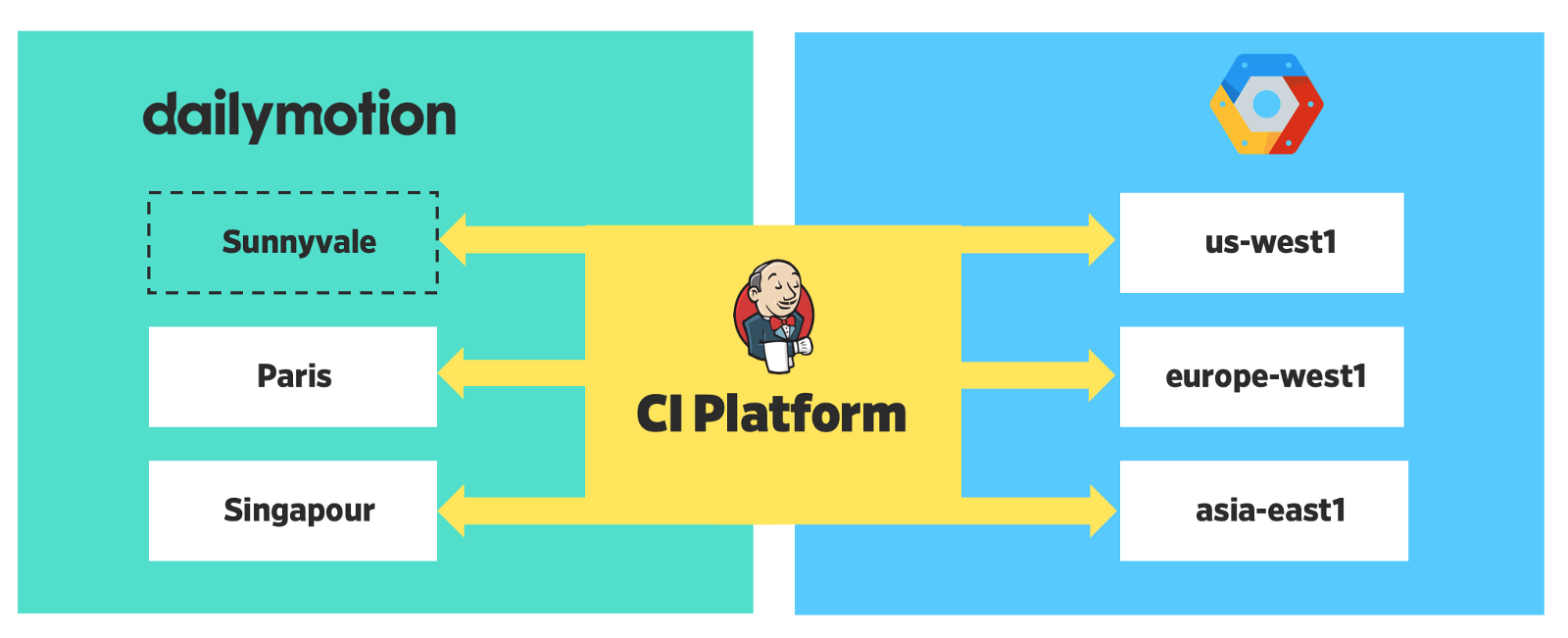
Распределенное развертывание
Глобальные значения Helm
4 глобальных значения Helm позволяют определять различия между кластерами. Для всех наших чартов есть минимальные значения по умолчанию.
global:
cloud: True
env: staging
region: us-central1
clusterName: staging-us-central1Глобальные значения
Эти значения помогают определить контекст для наших приложений и используются для разных задач: мониторинг, трассировка, логирование, совершение внешних вызовов, масштабирование и т. д.
- «cloud»: у нас есть гибридная платформа Kubernetes. Например, наш API развертывается в зонах GCP и в наших датацентрах.
- «env»: некоторые значения могут меняться для нерабочих сред. Например, определения ресурсов и конфигурации автомасштабирования.
- «region»: эта информация помогает определять расположение кластера и может использоваться для определения ближайших конечных точек для внешних сервисов.
- «clusterName»: если и когда мы хотим определить значение для отдельного кластера.
Вот конкретный пример:
{{/* Returns Horizontal Pod Autoscaler replicas for GraphQL*/}}
{{- define "graphql.hpaReplicas" -}}
{{- if eq .Values.global.env "prod" }}
{{- if eq .Values.global.region "europe-west1" }}
minReplicas: 40
{{- else }}
minReplicas: 150
{{- end }}
maxReplicas: 1400
{{- else }}
minReplicas: 4
maxReplicas: 20
{{- end }}
{{- end -}}Пример шаблона Helm
Эта логика определена во вспомогательном шаблоне, чтобы не засорять Kubernetes YAML.
Объявление приложения
Наши инструменты развертывания основаны на нескольких файлах YAML. Ниже приведен пример того, как мы объявляем сервис и его топологию масштабирования (количество реплик) в кластере.
releases:
- foo.world
foo.world: # Release name
services: # List of dailymotion's apps/projects
foobar:
chart_name: foo-foobar
repo: git@github.com:dailymotion/foobar
contexts:
prod-europe-west1:
deployments:
- name: foo-bar-baz
replicas: 18
- name: another-deployment
replicas: 3Определение сервиса
Это схема всех шагов, которые определяют наш рабочий процесс развертывания. Последний шаг развертывает приложение одновременно на нескольких рабочих кластерах.
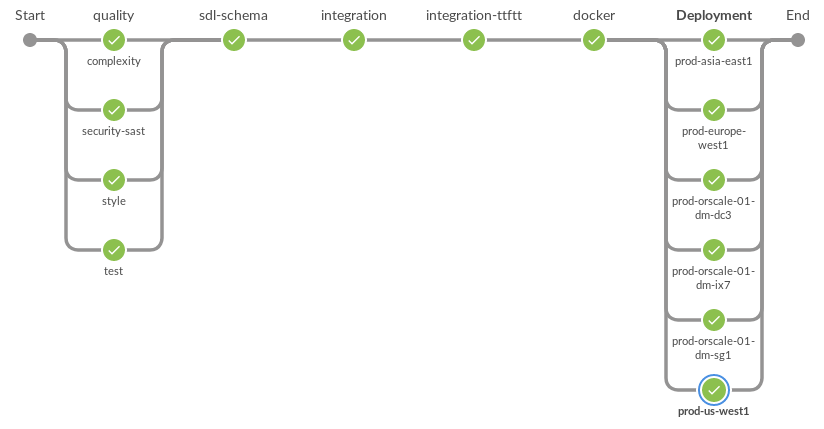
Шаги развертывания в Jenkins
А секреты?
Что касается безопасности, мы отслеживаем все секреты из разных мест и храним их в уникальном хранилище Vault в Париже.
Наши инструменты развертывания извлекают значения секретов из Vault и, когда приходит время развертывания, вставляют их в Helm.
Для этого мы определили сопоставление между секретами в Vault и секретами, которые нужны нашим приложениям:
secrets:
- secret_id: "stack1-app1-password"
contexts:
- name: "default"
vaultPath: "/kv/dev/stack1/app1/test"
vaultKey: "password"
- name: "cluster1"
vaultPath: "/kv/dev/stack1/app1/test"
vaultKey: "password"- Мы определили общие правила, которым необходимо следовать при записи секретов в Vault.
- Если секрет относится к определенному контексту или кластеру, нужно добавить конкретную запись. (Здесь у контекста cluster1 есть собственное значение для секрета stack-app1-password).
- В противном случае используется значение по умолчанию.
- Для каждого пункта в этом списке в секрет Kubernetes вставляется пара ключ-значение. Поэтому шаблон секрета в наших чартах очень прост.
apiVersion: v1
data:
{{- range $key,$value := .Values.secrets }}
{{ $key }}: {{ $value | b64enc | quote }}
{{ end }}
kind: Secret
metadata:
name: "{{ .Chart.Name }}"
labels:
chartVersion: "{{ .Chart.Version }}"
tillerVersion: "{{ .Capabilities.TillerVersion.SemVer }}"
type: OpaqueПроблемы и ограничения
Работа с несколькими репозиториями
Сейчас мы разделяем разработку чартов и приложений. Это значит, что разработчикам приходится работать в двух репозиториях git: один для приложения, а второй — для определения его развертывания в Kubernetes. 2 репозитория git — это 2 рабочих процесса, и новичку легко запутаться.
Управлять обобщенными чартами хлопотно
Как мы уже говорили, обобщенные чарты очень удобны для определения зависимостей и быстрого развертывания нескольких приложений. Но мы используем --reuse-values, чтобы избежать передачи всех значений каждый раз, когда мы развертываем приложение, входящее в этот обобщенный чарт.
В рабочем процессе непрерывной поставки у нас всего два значения, которые меняются регулярно: количество реплик и тег образа (версия). Другие, более стабильные значения, изменяются вручную, и это довольно сложно. Более того, одна ошибка в развертывании обобщенного чарта может привести к серьезным сбоям, как мы убедились на собственном опыте.
Обновление нескольких файлов конфигурации
Когда разработчик добавляет новое приложение, ему приходится изменять несколько файлов: объявление приложения, список секретов, добавление приложения в зависимости, если оно входит в обобщенный чарт.
Разрешения Jenkins слишком расширены в Vault
Сейчас у нас есть один AppRole, который читает все секреты из Vault.
Процесс отката не автоматизирован
Для отката нужно выполнить команду на нескольких кластерах, а это чревато ошибками. Мы выполняем эту операцию вручную, чтобы гарантированно указать правильный идентификатор версии.
Мы движемся в сторону GitOps
Наша цель
Мы хотим вернуть чарт в репозиторий приложения, которое он развертывает.
Рабочий процесс будет таким же, как для разработки. Например, когда ветвь отправляется в мастер, развертывание будет запускаться автоматически. Основная разница между таким подходом и текущим рабочим процессом будет в том, что все будет управляться в git (само приложение и способ его развертывания в Kubernetes).
Преимуществ несколько:
- Гораздо понятнее для разработчика. Проще научиться применять изменения в локальном чарте.
- Определение развертывания службы можно указать там же, где код службы.
- Управление удалением обобщенных чартов. У сервиса будет свой выпуск Helm. Это позволит управлять жизненным циклом приложения (откат, апгрейд) на мельчайшем уровне, чтобы не затрагивать другие сервисы.
- Преимущества git для управления чартами: отмена изменений, журнал аудита и т. д. Если нужно отменить изменение чарта, это можно сделать с помощью git. Развертывание запускается автоматически.
- Можно подумать об усовершенствовании рабочего процесса разработки с помощью таких инструментов, как Skaffold, с которым разработчики могут тестировать изменения в контексте, приближенном к продакшену.
Двухэтапная миграция
Наши разработчики используют этот рабочий процесс уже 2 года, так что нам нужна максимально безболезненная миграция. Поэтому мы решили добавить промежуточный этап на пути к цели.
Первый этап простой:
- Мы сохраняем похожую структуру для настройки развертывания приложений, но в одном объекте с именем DailymotionRelease.
apiVersion: "v1"
kind: "DailymotionRelease"
metadata:
name: "app1.ns1"
environment: "dev"
branch: "mybranch"
spec:
slack_channel: "#admin"
chart_name: "app1"
scaling:
- context: "dev-us-central1-0"
replicas:
- name: "hermes"
count: 2
- context: "dev-europe-west1-0"
replicas:
- name: "app1-deploy"
count: 2
secrets:
- secret_id: "app1"
contexts:
- name: "default"
vaultPath: "/kv/dev/ns1/app1/test"
vaultKey: "password"
- name: "dev-europe-west1-0"
vaultPath: "/kv/dev/ns1/app1/test"
vaultKey: "password"- 1 релиз на приложение (без обобщенных чартов).
- Чарты в репозитории git приложения.
Мы поговорили со всеми разработчиками, так что процесс миграции уже начался. Первый этап по-прежнему контролируется с использованием платформы CI. Скоро я напишу еще один пост о втором этапе: как мы перешли на рабочий процесс GitOps с Flux. Я расскажу, как мы все настроили и с какими трудностями столкнулись (несколько репозиториев, секреты и т. д.). Следите за новостями.
Здесь мы попытались описать наш прогресс в рабочем процессе развертывания приложений за последние годы, который привел к мыслям о подходе GitOps. Мы еще не достигли цели и будем сообщать о результатах, но сейчас убеждены, что правильно сделали, когда решили все упростить и приблизить к привычкам разработчиков.
